- The paper introduces Generalized On-Policy Distillation (G-OPD) by integrating a flexible reference policy with a reward scaling factor, allowing students to potentially surpass teacher performance.
- It reformulates on-policy distillation as a dense reinforcement learning objective that balances KL divergence and reward signals, providing a principled framework for model alignment.
- Empirical evaluations on math reasoning and code generation benchmarks show that reward extrapolation (λ > 1) enhances accuracy, sequence length, and sample efficiency across various distillation scenarios.
Theoretical Contributions and Framework
This paper presents a rigorous theoretical analysis of On-Policy Distillation (OPD) and introduces the Generalized On-Policy Distillation (G-OPD) framework. The main insight is that OPD, wherein a student aligns its behavior with a teacher’s logit distribution over student-generated samples, can be reformulated as a dense KL-constrained reinforcement learning (RL) objective. Specifically, OPD is shown to be a special case where the reward function and KL regularization are weighted equally, and the reference policy can be any model.
G-OPD generalizes OPD by (1) introducing a flexible reference policy and (2) adding a reward scaling factor λ, modulating the reward-KL trade-off. The new objective becomes:
JG−OPD(θ)=Ex,y∼πθ[λlogπref(y∣x)π∗(y∣x)−KL(πθ(⋅∣x)∥πref(⋅∣x))]
Varying λ allows interpolation (0<λ<1) between behaviors, and, notably, extrapolation (λ>1), which pushes the student beyond the teacher’s apparent empirical performance boundary. These theoretical generalizations are supported by comprehensive mathematical derivations and further extended to analysis of policy reference selection, particularly in strong-to-weak (large-to-small) distillation regimes.
Empirical Evaluation: Math Reasoning and Code Generation
The paper empirically examines single-teacher, multi-teacher, and strong-to-weak distillation scenarios using benchmarks from math reasoning and code generation. The proposed ExOPD (Extrapolated OPD, λ>1) is systematically compared to off-policy distillation (SFT), standard OPD (λ=1), and weight extrapolation (ExPO).
In single-teacher distillation (where student and teacher are identically derived except for domain RL):
- Standard OPD nearly matches the teacher on accuracy and output length.
- Reward interpolation (0<λ<1) yields students interpolating between the reference and teacher in both length and accuracy.
- Reward extrapolation (λ>1) yields students that can surpass the teacher on all evaluated benchmarks, achieving the strongest numerical gains at λ=1.25 before instability for large λ settings.
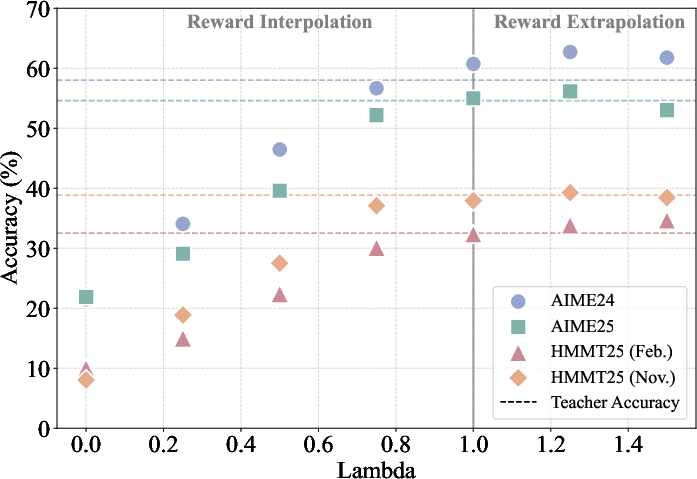
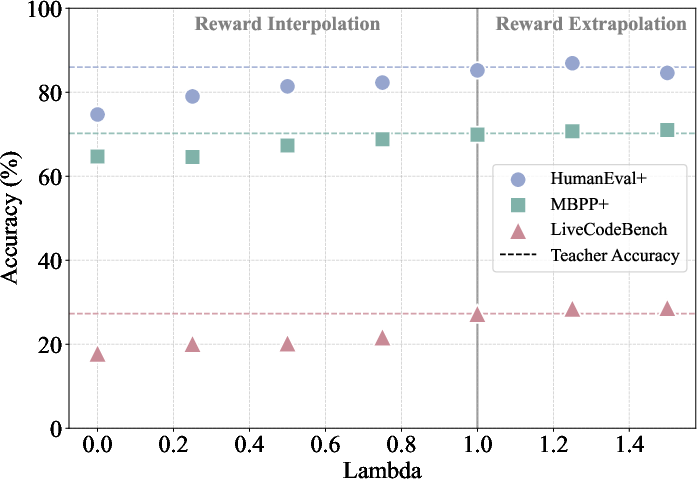
Figure 1: On-policy distillation results on four math reasoning benchmarks under different choices of reward scaling factor λ.
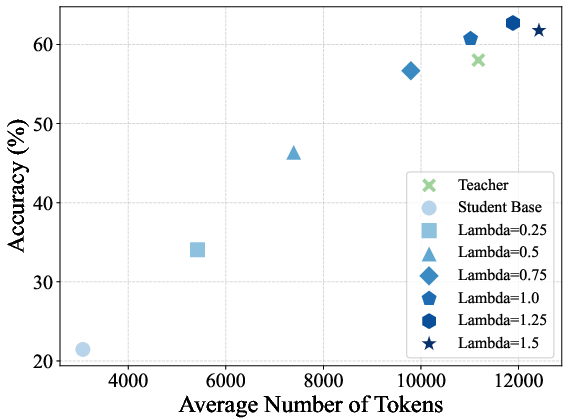
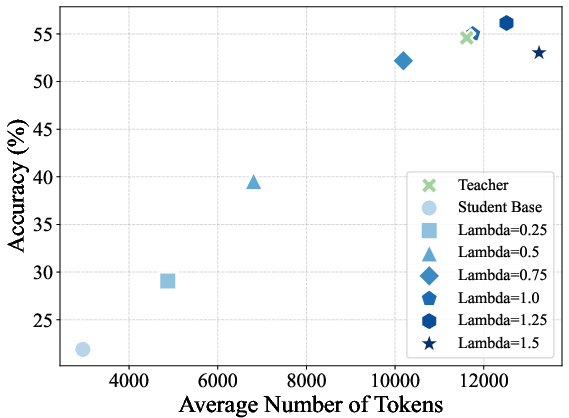
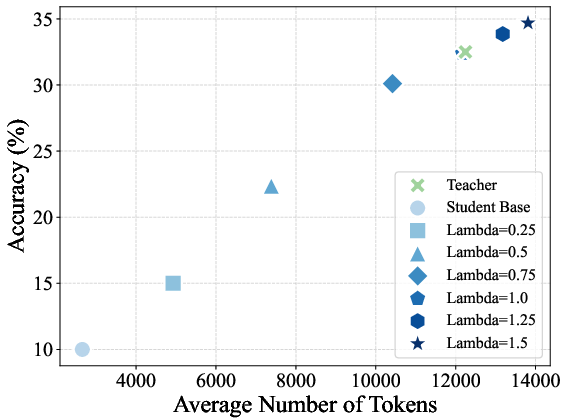
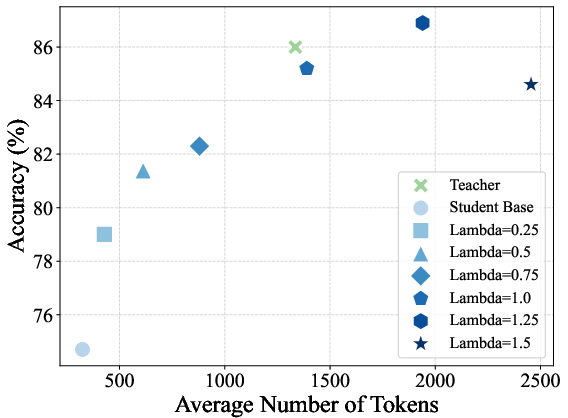
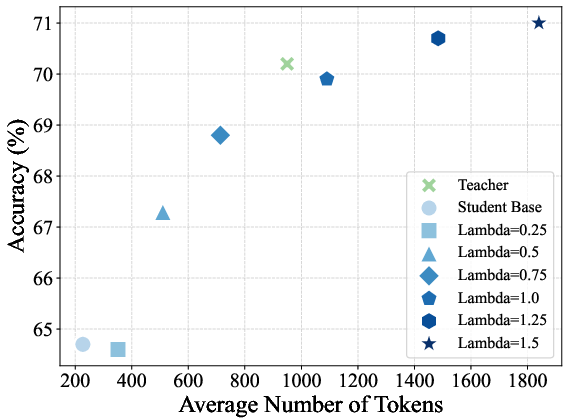
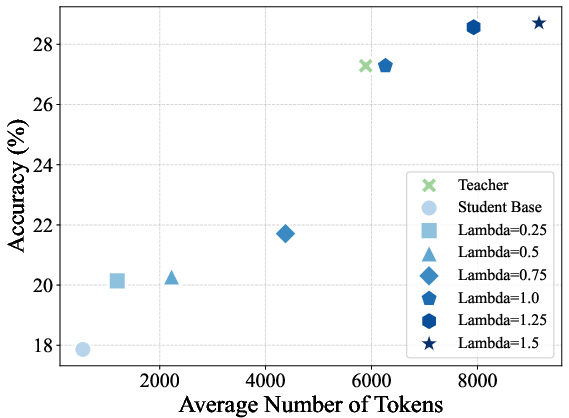
Figure 2: Trends in average sequence length and accuracy versus reward scaling factor across benchmarks for on-policy distilled models.
In multi-teacher distillation, ExOPD demonstrates capability to robustly unify and exceed the best of several domain-specific teacher models, outperforming competing approaches and providing consistent gains:
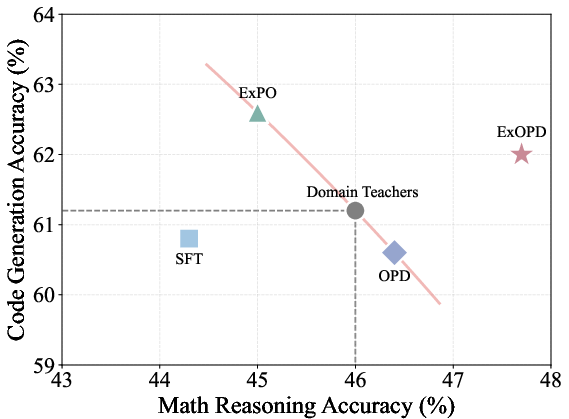
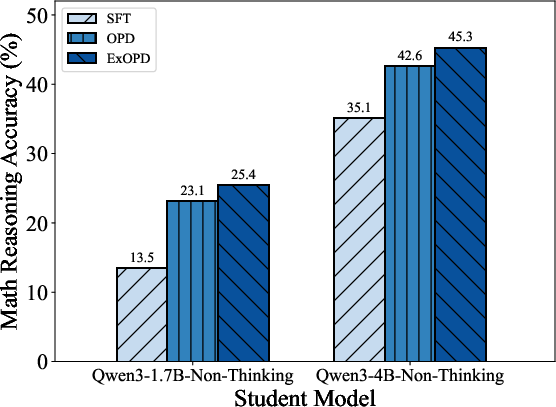
Figure 3: The empirical effectiveness of ExOPD compared with off-policy distillation (SFT), standard OPD, and ExPO in multi-teacher and strong-to-weak distillation.
Training dynamics illustrate ExOPD’s higher reward accumulation, increased response length, and higher response entropy, supporting the hypothesis that reward extrapolation not only improves sample efficiency but also model expressiveness.

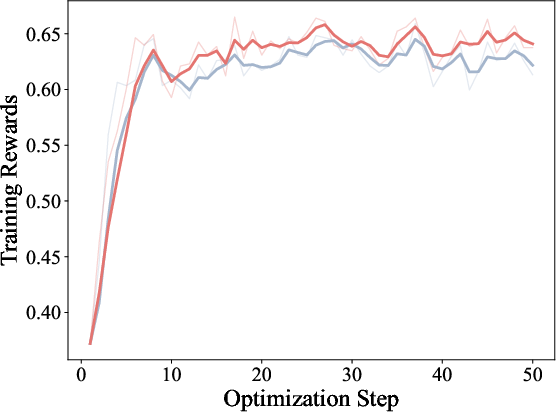
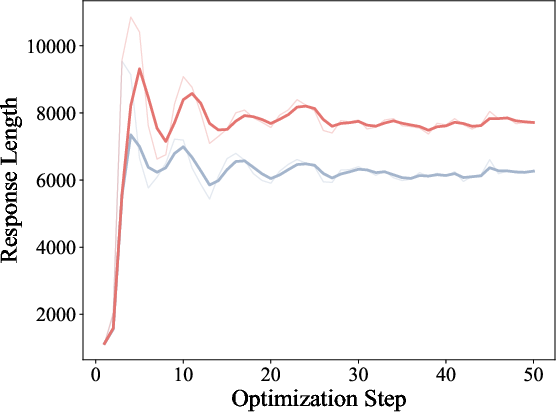
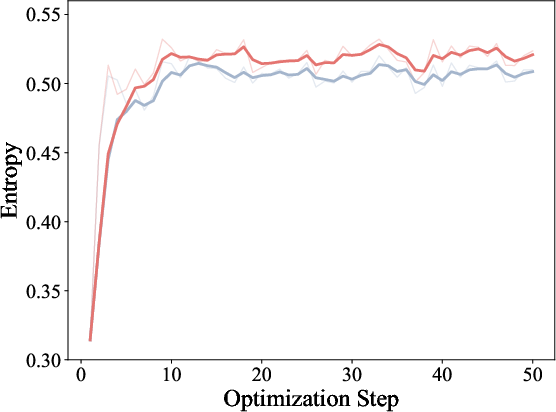
Figure 4: Training dynamics of OPD and ExOPD in multi-teacher distillation, with ExOPD showing higher training rewards and response entropy.
In strong-to-weak distillation, where a smaller student is distilled from a much larger teacher, ExOPD again achieves substantial improvements over OPD and SFT. Performance can be further improved via reward correction, i.e., using the teacher’s pre-RL checkpoint as the reward reference model, at the cost of increased computational demands and requiring access to the teacher’s training history.
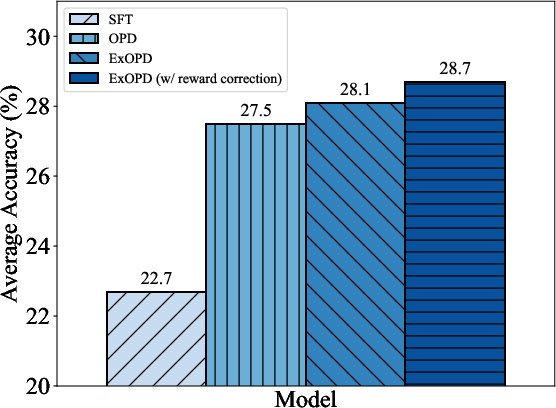
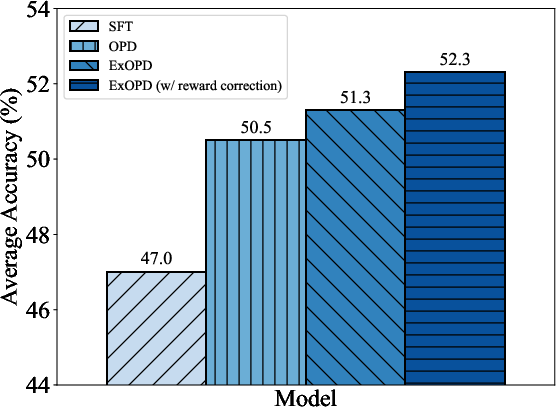
Figure 5: Effect of reward correction in the strong-to-weak distillation setting; using the teacher's pre-RL variant as reference further boosts performance.
Practical and Theoretical Implications
G-OPD establishes a formal link between dense RL and student-teacher distillation, providing a principled mechanism for controlling the transfer strength and reference distribution. ExOPD’s empirical ability to consistently surpass domain teachers suggests that reward extrapolation is an effective means to push beyond the conventional knowledge boundary imposed by teacher models. This is particularly impactful for multi-task post-training and heterogeneous expert merging, and offers significant improvements in strong-to-weak transfer scenarios difficult with classical distillation.
The reward correction strategy in strong-to-weak distillation introduces an additional degree of freedom, further increasing alignment fidelity, though at the expense of additional compute and model access constraints.
Limitations and Future Directions
While G-OPD and ExOPD are demonstrated extensively on math reasoning and code generation, practical validation on substantially larger models and with a broader or more heterogeneous teacher ensemble remains an open avenue. The notable length bias and possibility of instability for large λ highlight the need for further work in regularization and reward shaping. Finally, cross-family (heterogeneous) policy distillation and adoption for continual/post-training reinforcement present promising directions, building upon the demonstrated flexibility of the G-OPD framework.
Conclusion
The paper provides a theoretical foundation and empirically validated recipe for generalizing on-policy distillation via reward extrapolation. By precisely modulating the incentive structure through λ and reference choice, ExOPD can reliably exceed teacher performance in challenging tasks and enable multi-expert capability integration, setting a strong precedent for future advances in efficient and effective LLM post-training and distillation.