- The paper conducts an anatomical analysis of the SAM3 text encoder, revealing significant redundancy and paving the way for aggressive, domain-aware compression.
- It empirically shows that segmentation prompts are short and object-centric, justifying a reduced context window of 16 tokens to optimize computation.
- The study demonstrates that a MobileCLIP student encoder retains 98.1% of teacher performance while achieving an 88% parameter reduction through effective distillation.
Anatomical Study and Compression of SAM3 Text Encoder for Efficient Vision-Language Segmentation
SAM3-LiteText interrogates the architectural appropriateness of foundation model text encoders for vision-language segmentation. SAM3 and related systems inherit large generic text encoders (CLIP-style transformer stacks) optimized for broad, open-ended language, incurring significant computational/memory overhead regardless of prompt complexity. The paper empirically establishes that segmentation domain prompts are short, object-centric, and exhibit severe redundancy, suggesting a mismatch between encoder capacity and task requirements (75.5% context padding waste, sparse vocabulary usage, and embedding collapse to a low intrinsic manifold). The central contribution is an anatomical analysis of prompt, vocabulary, and embedding space, leading to domain-aware knowledge distillation and aggressive model compression without degradation in grounding performance.
Prompt Structure, Context Utilization, and Vocabulary Dynamics
The study aggregates 404,796 prompts across six segmentation datasets, mapping their statistical characteristics and context window utilization. The mean prompt length is μ=7.9 tokens, dominated by noun phrases/descriptive labels, diverging sharply from general NLP corpora. Token length distribution reveals LVIS category names (μ=3.3), SA-Co datasets (μ≈5.7), RefCOCO referring expressions (μ=9.4), with negligible syntactic complexity.
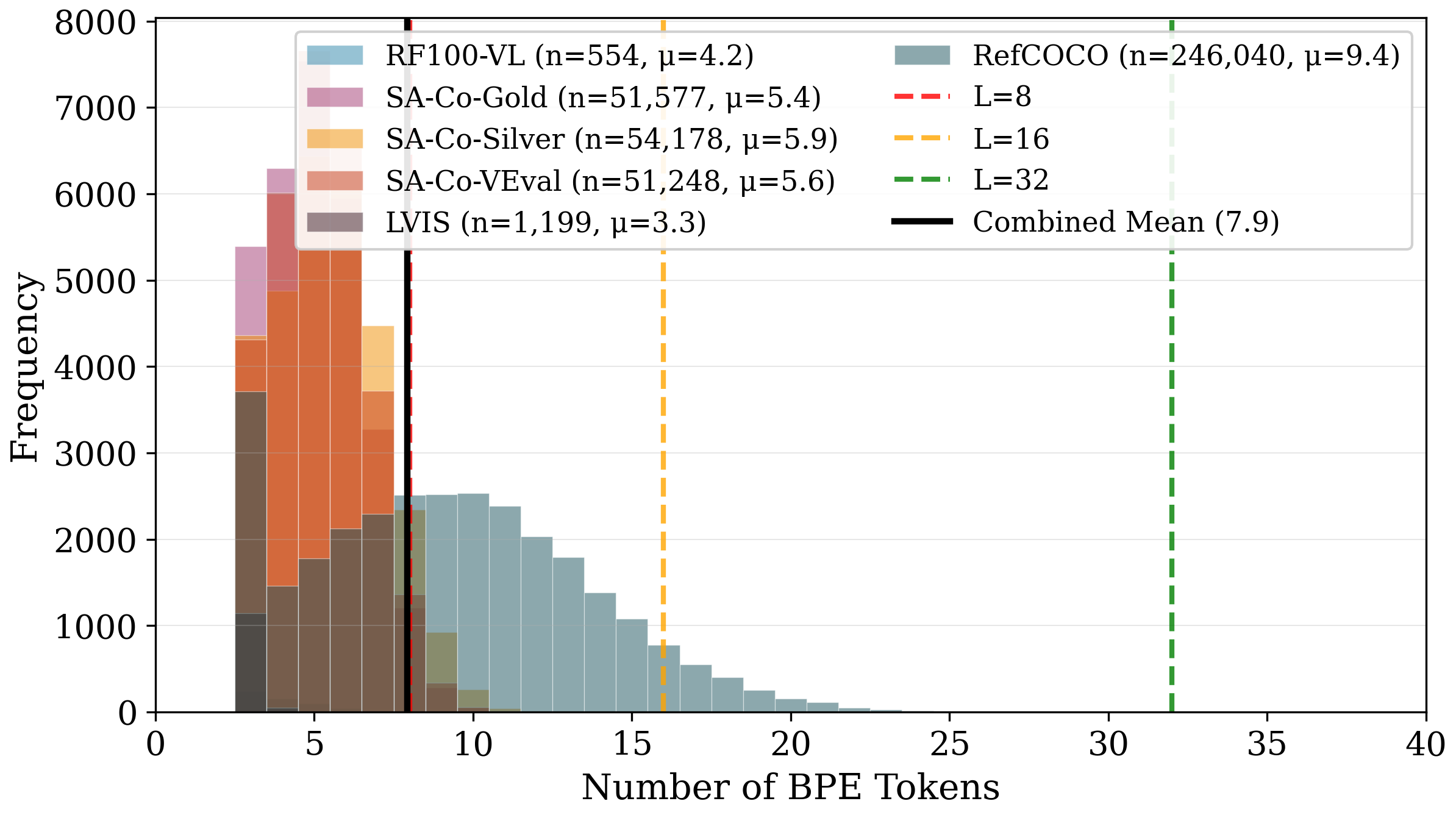
Figure 1: Token length distribution across segmentation datasets; mean prompt length μ=7.9 tokens demonstrates extreme brevity and structural regularity.
At context length L=32, 75.5% of positions are wasted on padding. Truncation at L=16 affects only 2.1% of total tokens, marking this window as optimal for attention computation and distillation.
Vocabulary coverage analysis reveals sparsity: only 35% of the 49,408 BPE tokens appear across all prompts; frequency distribution is highly skewed, with top 100 tokens covering 58.5% of total occurrences and dominant classes being general attributes (colors, sizes, determiners).
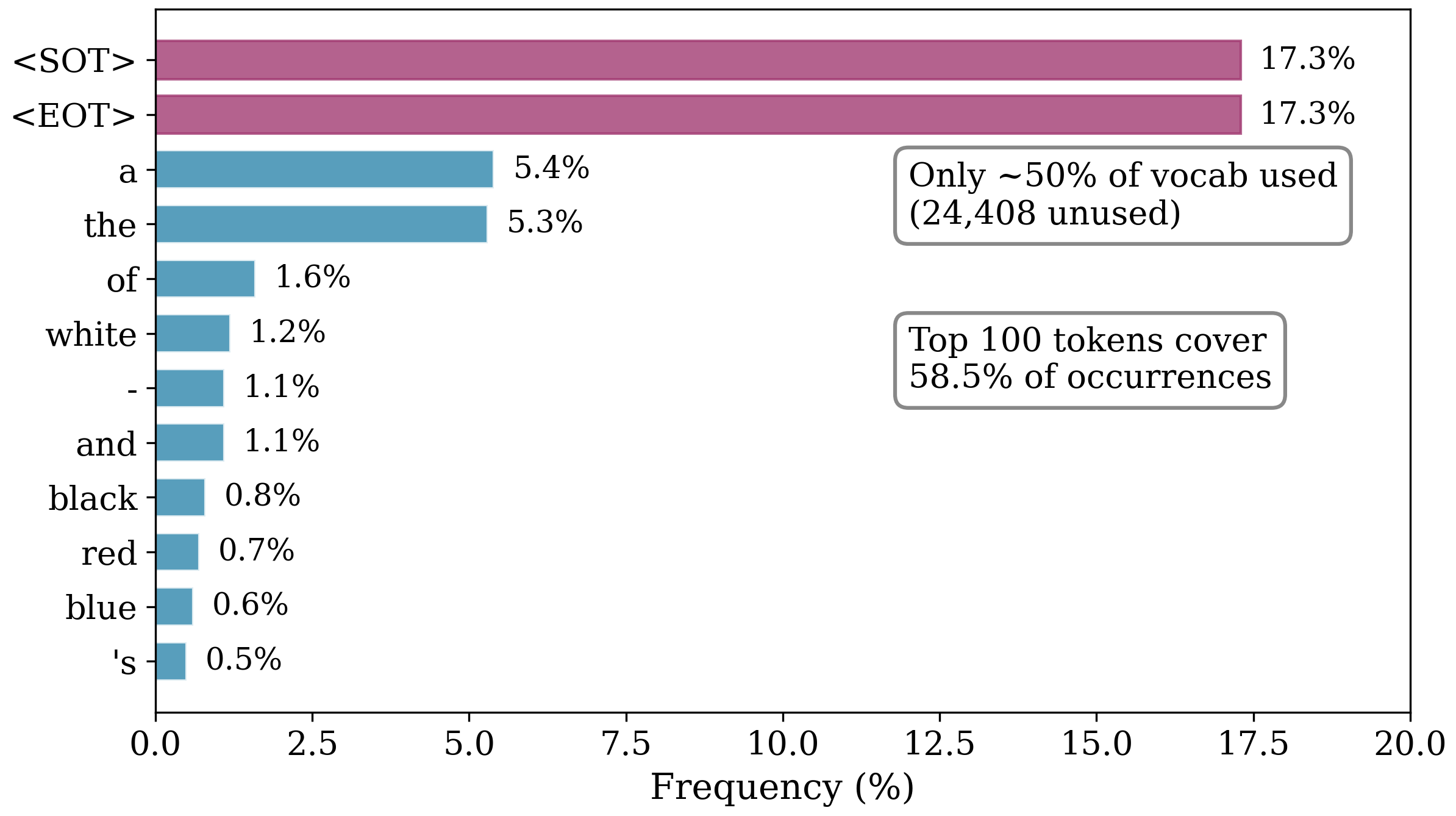
Figure 2: Vocabulary coverage; only a minority of BPE tokens are relevant, and token frequency is exceptionally concentrated.
These statistics substantiate aggressive context window truncation and vocabulary reduction: most computation over unused tokens or positions is functionally superfluous.
Embedding Analysis: Spectral Orthogonality and Positional Redundancy
Token embedding spectral analysis (SVD) reveals high effective rank (88.5% for active vocabulary), consistent with contrastive pretraining pushing tokens onto orthogonal directions, not amenable to low-rank factorization. However, positional embedding analysis illustrates redundancy beyond index 8; cosine similarity among late positions (8+) is 1.5× higher than among early positions, indicating collapsed semantic differentiation due to gradient starvation during training.
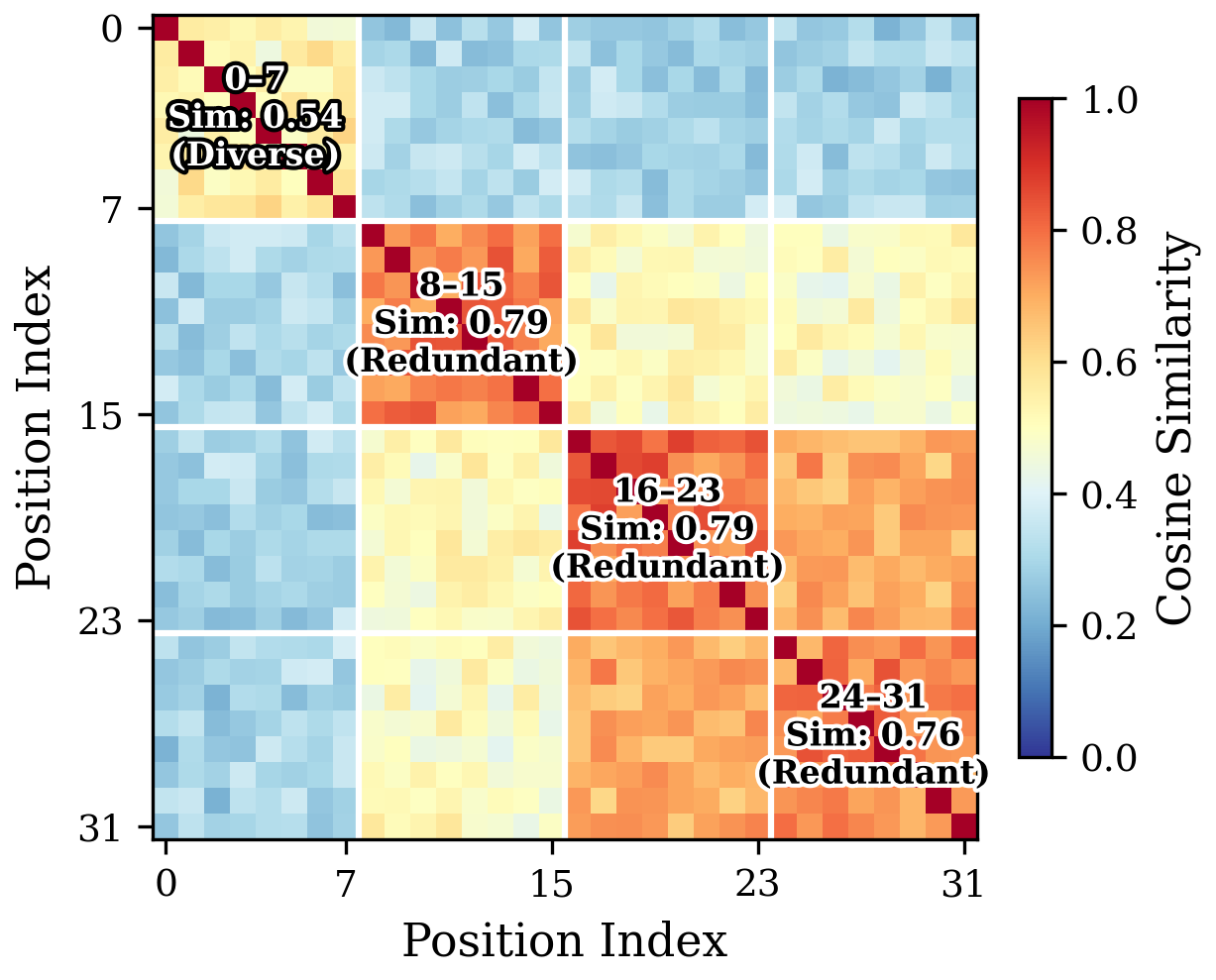
Figure 3: Heatmap of positional embedding cosine similarity; late positions converge to redundant representations, validating structural context window collapse.
SVD of the positional matrix reveals variance concentration in only seven principal components, effective rank of 20 (out of 32). This empirically justifies the design choice of L=16 for student architectures.
Intrinsic Dimensionality of Output Embedding
The text encoder's 256-dimensional output space exhibits collapse to a low-dimensional nonlinear manifold. Intrinsic dimensionality estimated via TwoNN and MLE converges at ∼16--19, linear SVD effective rank at 85.3, showing only ∼6--8% of the embedding space is actually utilized.
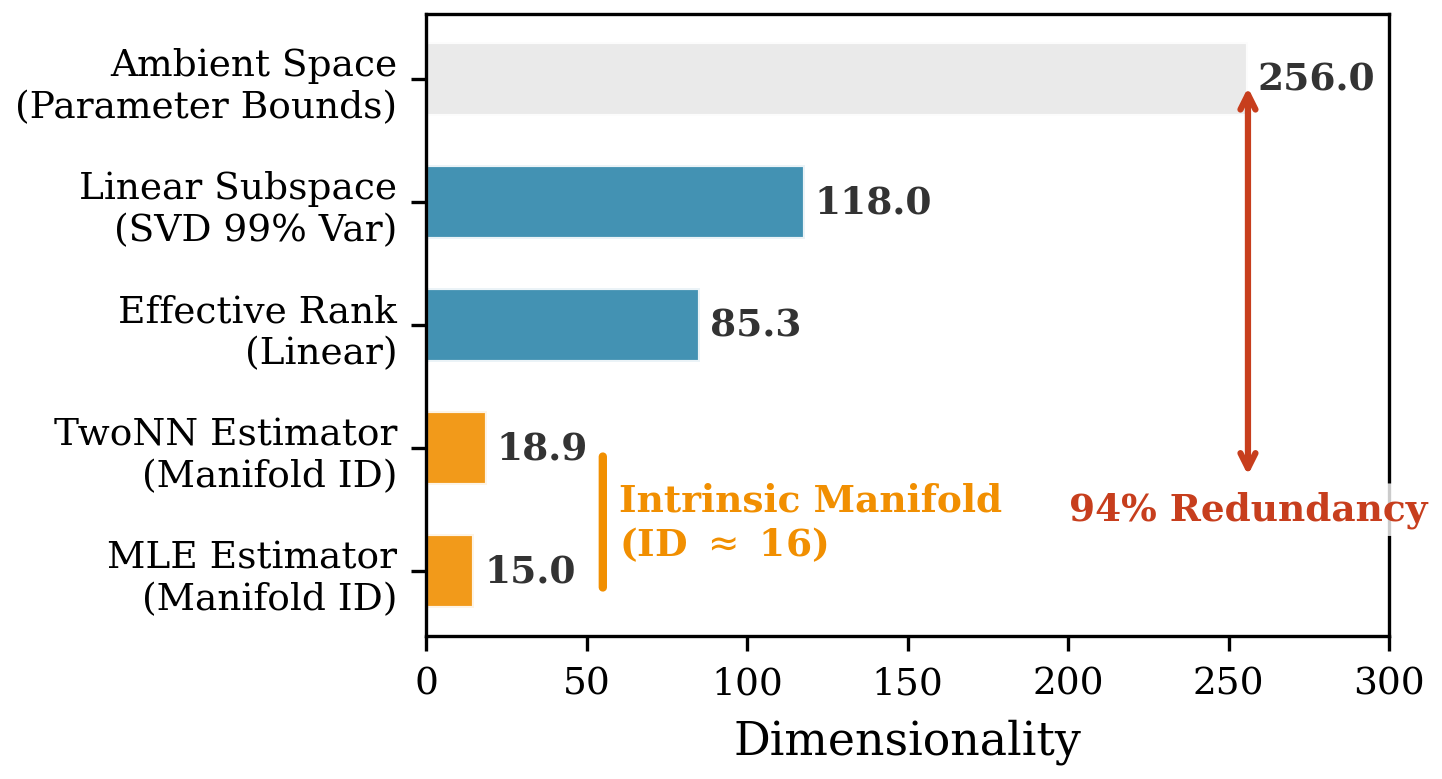
Figure 4: Output embedding intrinsic dimensionality; student architectures mapping to a low-dimensional manifold are theoretically justified.
This validates matching student architecture width to the empirically observed capacity, ensuring no significant semantic loss during aggressive compression.
SAM3-LiteText: Domain-Aware Distillation and Student Architecture
SAM3-LiteText replaces the SAM3 text encoder with a MobileCLIP student, compacted via spectral compression (L=16, 512-768 width, 4/12 transformer layers), and trained by knowledge distillation. The distillation objective incorporates:
- Coordinate alignment (MSE): Maintains compatibility with cross-attention fusion modules.
- Direction alignment (cosine similarity): Forces semantic orientation preservation.
- Permutation-invariant consistency loss ("Bag of Concepts" prior): Enforces order robustness by minimizing embedding difference between original and syntactically permuted prompts.
Architectures achieve 88% parameter reduction (42M vs 353M), with negligible accuracy loss (<2% drop in CG_F1).
Empirical Results and Ablation
Comprehensive benchmarking on SA-Co Gold and video segmentation datasets confirms that MobileCLIP student encoders retain 98.1% of teacher performance. Quantitative metrics (CG_F1, IL_MCC, pmF1, pHOTA, pDetA) are nearly saturated relative to the teacher, outperforming prior baselines (gDino-T, OWLv2, LLMDet-L, Gemini 2.5, etc.).
Efficiency analysis demonstrates a throughput increase up to 3.7× and massive parameter reduction. Qualitative results show visually indistinguishable masks between the high-capacity teacher and compact student models.
Ablations confirm that L=16 is the optimal tradeoff for context window, and that including consistency loss improves grounding robustness by enforcing syntactic order invariance. The text encoder is no longer the bottleneck for segmentation on edge devices and video applications.
Softmax Robustness Phenomenon
Analysis reveals that downstream attention fusion modules are highly error-tolerant due to softmax's error-correcting properties: embedding deviations are attenuated by up to 282×, and attention weights remain stable if embeddings are semantically close. This allows students to maintain high segmentation accuracy despite only approximate alignment with teacher embeddings.
Practical and Theoretical Implications
The primary practical implication is the democratization of advanced segmentation models on resource-constrained hardware. This is enabled by domain-aware anatomical reduction and distillation, fundamentally challenging the default assumption that general-purpose (CLIP/BERT-size) encoders are necessary for vision-language tasks. Theoretically, the work validates the Manifold Hypothesis for segmentation prompts—semantic information resides on a considerably lower-dimensional space than architecturally provisioned, suggesting future research into task-specific compression and distillation techniques for vision-language fusion.
Future Directions
Potential avenues include:
- Application of anatomical compression to other prompt-driven modalities (medical imaging, robotics, or domain-specific retrieval).
- Exploration of adaptive encoder expansion for linguistically complex prompts beyond object-centric nomenclature.
- Integration with quantization/pruning techniques to further reduce model footprint for edge deployment.
- Extension of permutation-invariant distillation for reasoning-over-syntax tasks (scene graph prediction, chain-of-thought fusion).
Conclusion
SAM3-LiteText provides an authoritative anatomical analysis of text encoder redundancy in vision-language segmentation and demonstrates high-fidelity, aggressive compression via domain-aware knowledge distillation. Empirical and structural evidence establish that foundational text encoders are massively over-provisioned for prompt-driven segmentation, unlocking real-time, resource-efficient deployment with negligible performance degradation. The framework generalizes to various segmentation and tracking tasks, and the paradigmatic shift toward prompt-centric compression poses promising directions for sustainable foundation model development (2602.12173).