- The paper presents a unified multimodal framework combining entity-aware pretraining, tool-augmented reasoning, and structured evaluation to enhance clinical diagnostics.
- It introduces a Medical Entity Tree and scalable data synthesis pipeline to ensure comprehensive coverage of both common and rare clinical conditions.
- Empirical results across 30+ benchmarks demonstrate state-of-the-art performance in visual diagnosis, report generation, and reasoning with minimized hallucinations.
MedXIAOHE: A Technical Overview of a Comprehensive Recipe for Medical Multimodal LLMs
Introduction and Motivation
MedXIAOHE presents a unified, multimodal medical vision–language large model (MLLM) with the objective of advancing accurate, robust, and evidence-grounded medical understanding and reasoning. The work aims to bridge benchmark performance and true clinical usability, addressing real-world challenges such as long-tail diagnostic coverage, multimodal and multi-turn reasoning, low-hallucination generation, and strict instruction adherence. The approach is characterized by (i) extensive entity-aware continual pretraining, (ii) agentic and tool-augmented reasoning reinforcement, (iii) advanced data synthesis and evaluation infrastructure, and (iv) an explicit focus on standardized, reproducible, and actionable evaluation across 30+ benchmarks.
Model Architecture
MedXIAOHE is constructed atop the Seed-ViT encoder and a large autoregressive LLM decoder, linked by an MLP adapter. This native-resolution multimodal architecture enables unified processing of high-resolution imaging modalities (X-ray, CT, pathology), free-form clinical text, OCR document understanding, and structured report generation. The architecture supports interleaved token fusion and multi-turn dialogue, permitting seamless integration of longitudinal patient records, visual context, entity cues, and external knowledge.
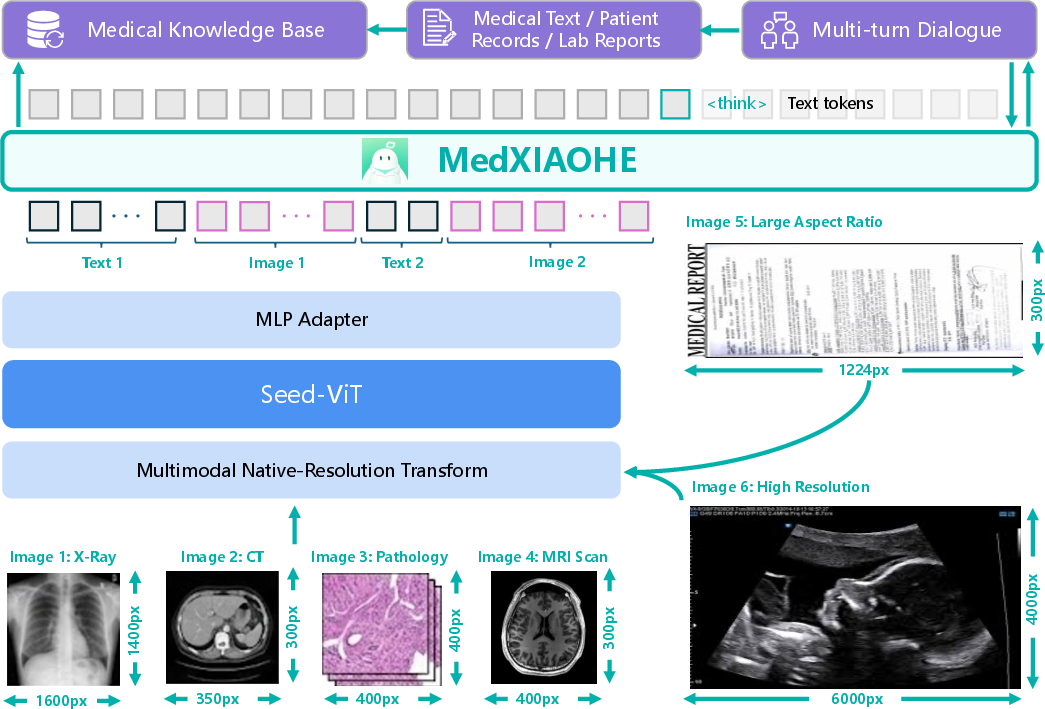
Figure 1: Model architecture operationalizes native-resolution multimodal fusion, integrating Seed-ViT encoded images into the LLM context.
This design choice enables MedXIAOHE to natively support clinical visual inspection, diagnostic multi-modal reasoning, and long-form report synthesis within a single, conversation-centric interface—eschewing brittle task-specific modules or heavy architectural modifications.
Continual Pretraining and Entity-Centric Data Strategy
A central component is entity-aware continual pretraining on a rigorously filtered, ~640B-token multimodal corpus. The data pipeline features (i) global deduplication, (ii) hybrid rule/model-based quality control, and (iii) advanced relevance filtering, maximizing both breadth and depth of medically relevant supervision.
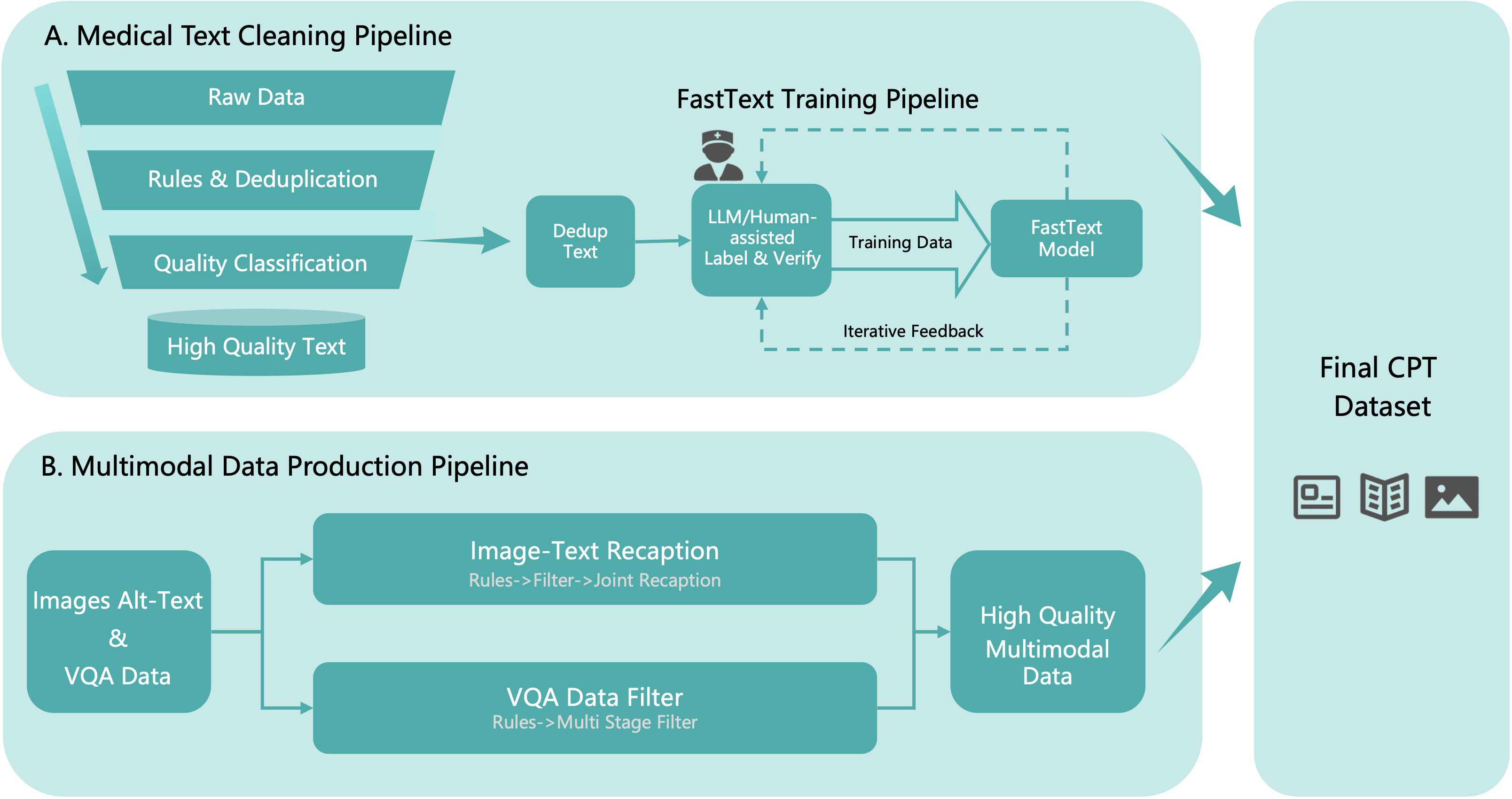
Figure 2: Data cleaning pipeline for pretraining corpus, including content-based deduplication and model-based filtering.
To mitigate long-tail knowledge gaps, the Medical Entity Tree (MET) is introduced—a five-tier, 1.4M-entity taxonomy extracted using parallelized LLM-based entity extraction, joint typing, and hierarchical clustering with conflict arbitration enabled by ReAct agents and retrieval-augmented generation. The MET provides balanced, comprehensive entity coverage, verified quantitatively against established clinical and knowledge graph baselines via semantic AMCS metrics, showing Forward AMCS>0.95 against all comparators—a claim that establishes near-superset coverage of clinical concepts relative to prior ontologies.
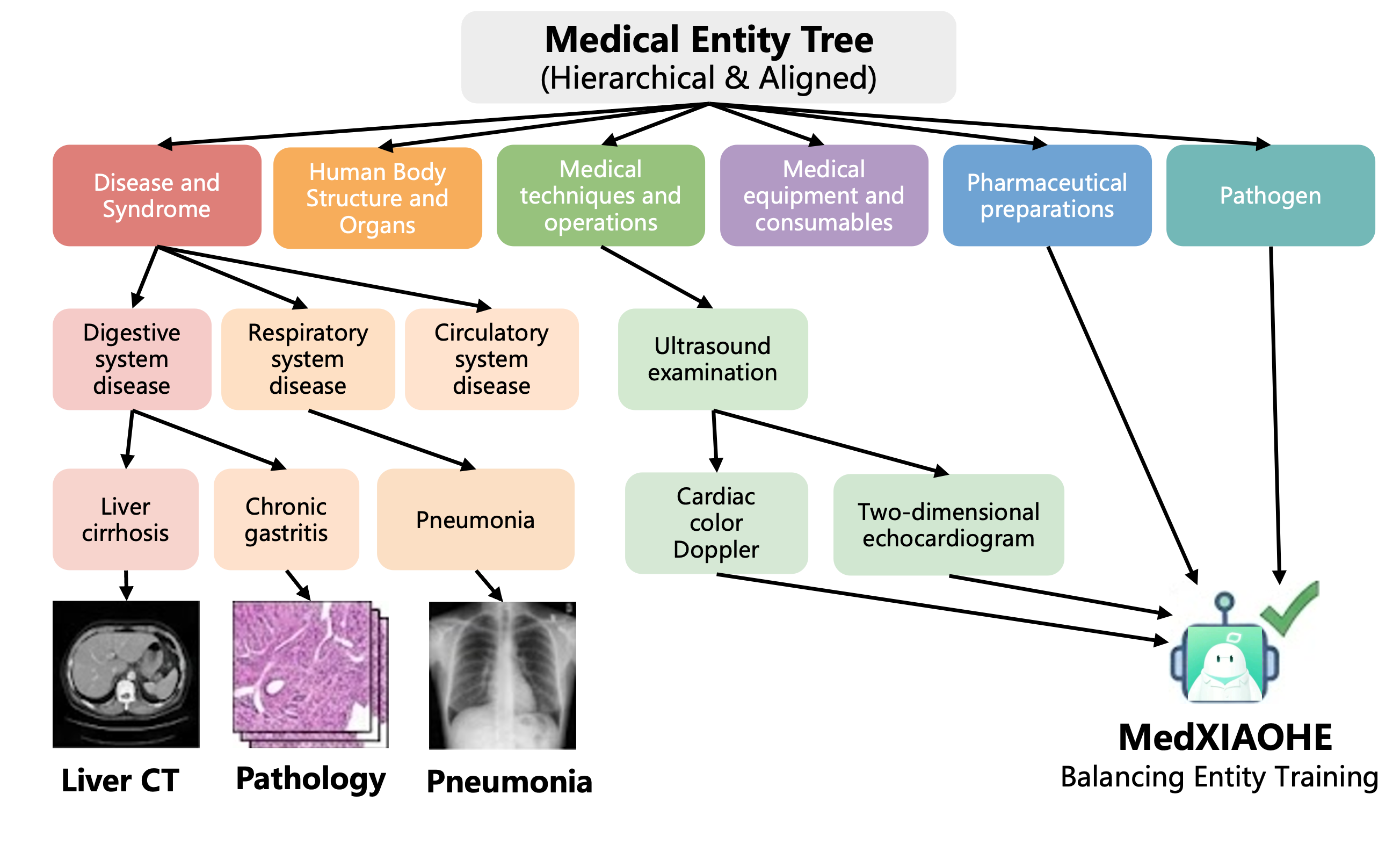
Figure 3: Hierarchical organization of the Medical Entity Tree—the backbone of entity-driven data synthesis and coverage analysis.
Efficient corpus-to-entity mapping is achieved via an Aho-Corasick automaton, enabling O(N) scalability even with a million-entity index.
Mid-Training: Advanced Reasoning and Agentic Data Synthesis
MedXIAOHE's mid-training focuses on strengthening compositional reasoning, personalized CoT, and agentic tool use capability. The data synthesis framework integrates KG-guided multi-hop QA, rejection sampling across multi-expert trajectories, and rigorous thinking-verify modules to filter reasoning chains for clinical correctness and causality.
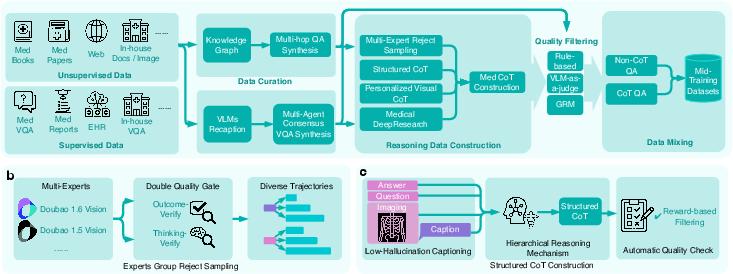
Figure 4: Multi-pronged mid-training data pipeline for high-fidelity medical reasoning and Chain-of-Thought supervision.
A dual-track curriculum distinguishes concise perception CoT (preserving visual localization) from abstract logical CoT (for high-level deduction), countering the common perception-reasoning conflict that erodes fine-grained accuracy under verbose logical supervision.
The agentic RL stage introduces real-world tool interfaces: general/medical web search, image manipulation (zoom, rotate), and document navigation. This is coupled with a dynamic difficulty filter and iterative SFT/RL hybrid optimization, producing behavior traces with explicit thought/action/result tuples and supporting verifiable solution decomposition for challenging queries.
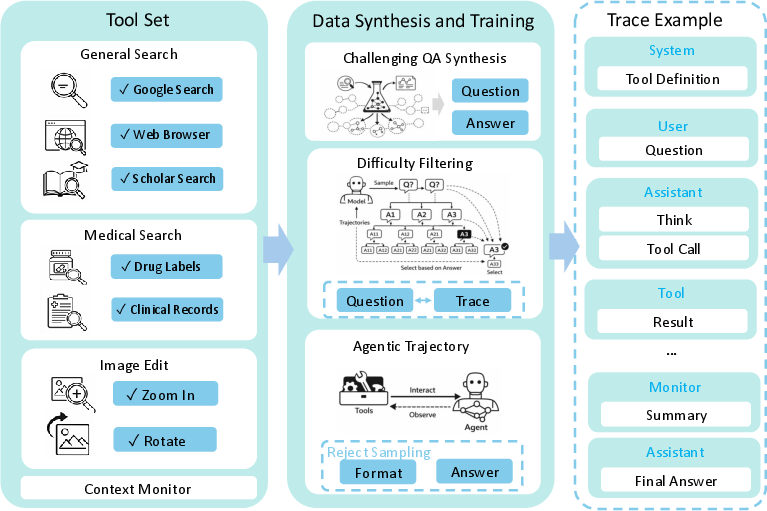
Figure 5: Tool-augmented pipeline with agentic RL–incorporated tool use traces and multi-hop evidence building.
Post-Training and Reward Modeling
Post-training consolidates clinical alignment and reliability via supervised fine-tuning on expert-ranked preference data and an RL curriculum guided by a multi-layered, hybrid reward system.
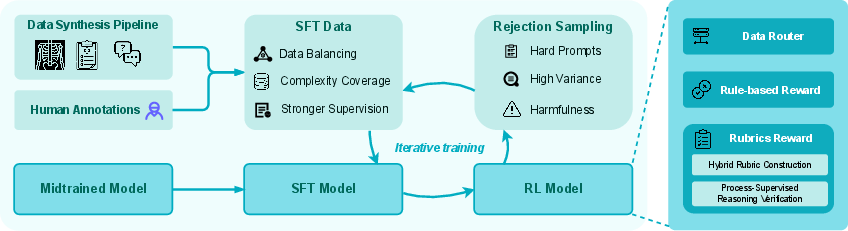
Figure 6: Post-training pipeline integrates SFT, RL optimization, and hard-negative feedback through rejection sampling.
The hybrid reward architecture employs a data router dispatching instances to rule-based evaluators (for exact-match tasks) or rubric-based graders (for open-form and reasoning tasks). High-fidelity rubrics are synthesized using model–expert consensus, domain specialization, and dynamic context adaptation; reward fusion is then performed under strict safety gating to strongly up-weight clinical correctness.
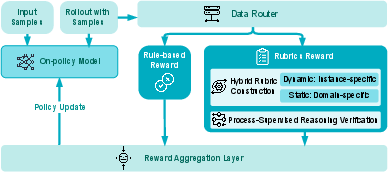
Figure 7: Multi-layered hybrid reward system—combining rule-based measures with rubric-evaluated open-form criteria for RL stage policy shaping.
Iterative curriculum learning with RFT (Rejection Sampling Fine-Tuning) alternates between SFT and RL phases, explicitly mitigating gradient interference and entropy collapse documented in standard staged/fused pipelines.
MedXIAOHE demonstrates consistent and strong results across visual, textual, diagnostic, report generation, and instruction-following axes, outperforming or matching leading models such as GPT-5.2 Thinking, Gemini 3.0/2.5 Pro on 30+ unified public and inhouse medical benchmarks.
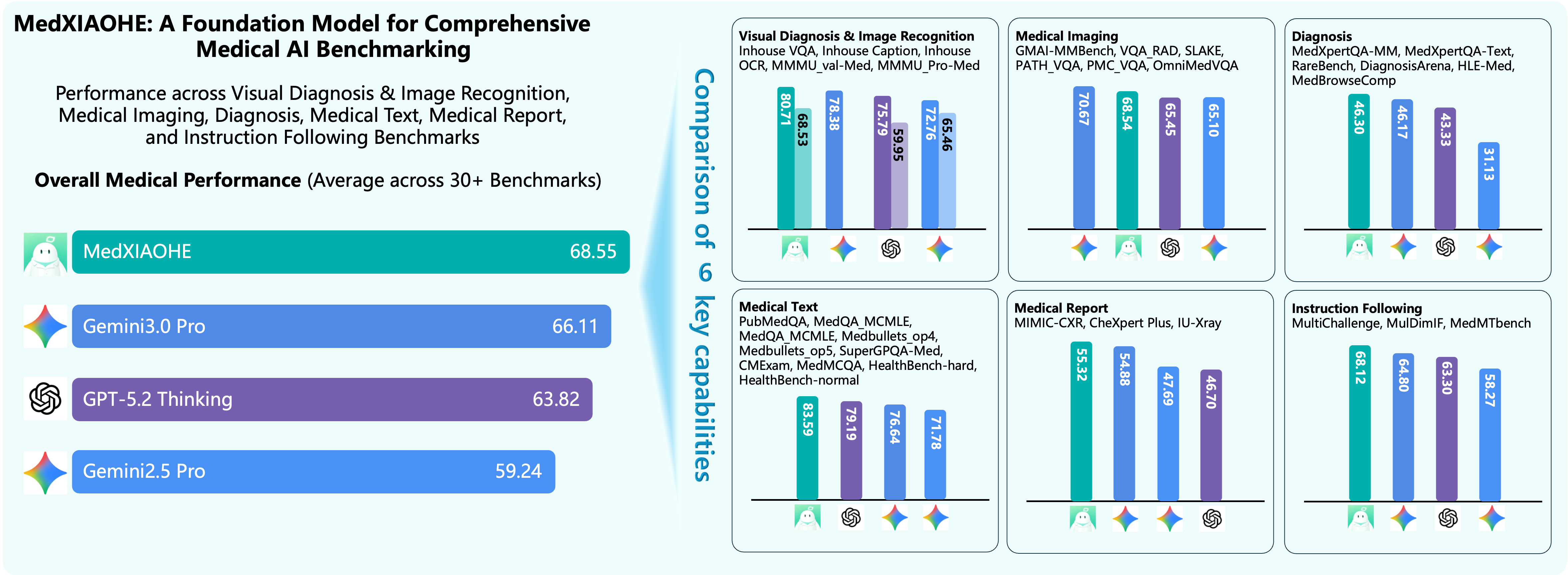
Figure 8: SOTA comparison—MedXIAOHE achieves or surpasses competitive baselines on comprehensive public and inhouse medical benchmarks.
Key performance highlights:
- Robust visual diagnosis: Outperforms on Inhouse VQA/Caption/OCR and public Multimodal Medical Understanding (MMMU val/Pro-Med: 87.5/73.9 vs. 79.7/71.9 for GPT-5.2).
- Medical imaging: Achieves dominant scores on SLAKE (82.6), PATH_VQA (59.1), and OmniMedVQA (83.4).
- Textual and clinical reasoning: Leading MedQA USMLE (97.9), MedQA MCMLE (96.2), and HealthBench-hard (46.1).
- Report generation: Excels on MIMIC-CXR (50.8), CheXpert Plus (49.4).
- Instruction following: Top-tier results on MedMTbench (63.8) and MulDimIF (78.7).
Notably, MedXIAOHE claims broader entity and knowledge coverage—quantitatively exceeding CMeKG and Common Crawl Medical Corpus by backward AMCS margin (e.g., CMeKG backward AMCS: 0.79), addressing the long-tail and rare-disease generalization bottleneck observed in non-entity-centric approaches.
Qualitative Analysis
Selected case studies (not shown here; see Figures 9–14 in the supplement) demonstrate MedXIAOHE's capacity for verifiable, tool-augmented, multistep clinical reasoning and faithful report synthesis, including:
- Retrieval-verifiable answering in tool-assisted DeepResearch paradigms.
- Chain-of-Thought–driven diagnosis with explicit image zoom for localization and confirmation.
- Grounding of abnormalities in X-ray via output of explicit bounding boxes.
- Extraction from distorted, non-uniform OCR images enabled by ZOOM-based reading and numerate reasoning.
Theoretical and Practical Implications
MedXIAOHE advances the state of medical MLLMs by showing:
- Structured, entity-centric curation and mapping are critical to robust knowledge coverage and rare disease handling.
- Hybrid RL reward, multi-stage reasoning alignment, and curriculum cycling can reconcile perception-reasoning trade-offs, avoiding capability oscillation and catastrophic forgetting.
- Unified, reproducible protocol design is essential for credible, product-relevant benchmarking, facilitating meaningful cross-model comparison within the medical VLM ecosystem.
Future Directions
Open research challenges identified in the analysis include: further reduction of hallucination rates, increased robustness under hospital/domain shift, handling of complex multi-modal multi-hop reasoning in agentic workflows, and improved real-time evidence retrieval and grounding. Future work is indicated in deeper evidence tracing, expanded tool integration, and scaling to even broader knowledge ontologies and imaging modalities.
Conclusion
MedXIAOHE delivers a technical recipe—comprising curriculum-ordered continual pretraining, entity-driven data construction, sophisticated mid-training with agentic RL, and a robust evaluation suite—demonstrating state-of-the-art multimodal clinical competence and competitive robustness on an extensive set of benchmarks. The framework establishes practical and theoretical underpinnings for the next generation of trustworthy, standardized, and clinically relevant medical MLLMs and provides an evaluation blueprint for the broader research community.