- The paper introduces a gauge-decoupled model that separates local pose, global scale, and memory management to enable robust real-time 3D reconstruction in long sequences.
- It employs cache-consistent transformer training with periodic cache refresh to ensure constant memory use and stable tracking over extended trajectories.
- Empirical evaluations on KITTI, TUM, and 7Scenes benchmarks demonstrate state-of-the-art accuracy with less than 0.74 ATE and minimal drift in challenging environments.
LongStream: Long-Sequence Streaming Autoregressive Visual Geometry
Introduction and Motivation
The "LongStream" framework targets the ultra-challenging problem of long-sequence, real-time 3D scene reconstruction from video—a foundational demand for autonomous driving, AR/VR, and robotics scenarios. Prior streaming autoregressive methods such as Stream3R and StreamVGGT exhibit catastrophic drift or collapse when extending trajectories beyond short subsequences due to "gauge coupling": rigid anchoring to a global first-frame coordinate and metric frame. This rigid anchoring leads to extrapolation errors, scale drift, and domain gaps, primarily due to the inability to generalize from short training windows to much longer test-time streams. Additionally, state-of-the-art SLAM and transformer-based offline methods are intractable in real time and encounter exponential memory growth on long sequences.
LongStream introduces a theoretically motivated, "gauge-decoupled" visual geometry model that explicitly separates local pose, global scale, and memory management, enabling robust, real-time, kilometer-scale metric 3D scene reconstruction. Its contributions are threefold: (1) keyframe-relative pose regression, (2) orthogonal/explicit scale prediction, and (3) cache-consistent transformer training, all of which together eliminate dependence on any fixed global frame and enable stable, drift-free long-horizon operation.
Conventional streaming 3D geometry models suffer from "gauge coupling," regressing absolute poses in a fixed world frame and directly supervising metrics entangled with global scale. This approach induces an extrapolation regime for unseen indices at inference time, making long-sequence prediction fundamentally unstable.
LongStream systematically decouples SE(3) and Sim(3) gauges:
- Pose is predicted as keyframe-relative: Every frame predicts its pose with respect to the latest keyframe, reformulating the ill-posed global extrapolation into a local, in-distribution estimation task where the frame-to-keyframe gap remains bounded across the entire sequence. The regression objective, Ti←k=Ti∘Tk−1, is strictly invariant to any global reparameterization.
- Metric scale is predicted orthogonally: All geometric predictions (depth, point map) are supervised with scale-invariant losses. A dedicated scale head receives its own learned token and predicts a log-scale factor, used exclusively for rescaling translation, depth, and pointmap outputs. This architectural and objective orthogonality ensures the shape backbone is disentangled from the metric scale estimator.
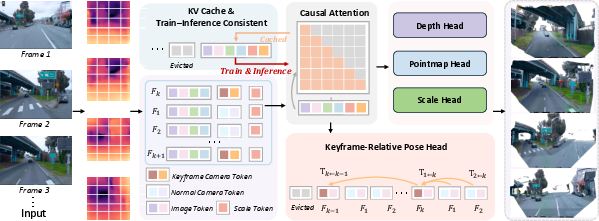
Figure 1: Overview of LongStream pipeline: streaming visual inputs are encoded via ViT, augmented with keyframe/scale tokens, and processed with causal attention. All predictions are locally referenced and cache-consistent, yielding stable metric-scale 3D reconstruction even on very long sequences.
LongStream addresses the core issue with streaming transformers: "attention sink" reliance and long-term KV cache contamination, which causes attention to collapse onto the first input frame, resulting in degradation over long streams. Standard procedures cause a mismatch between training and streaming inference, especially when windowed or causal masking is employed.
Empirical Evaluation and Analysis
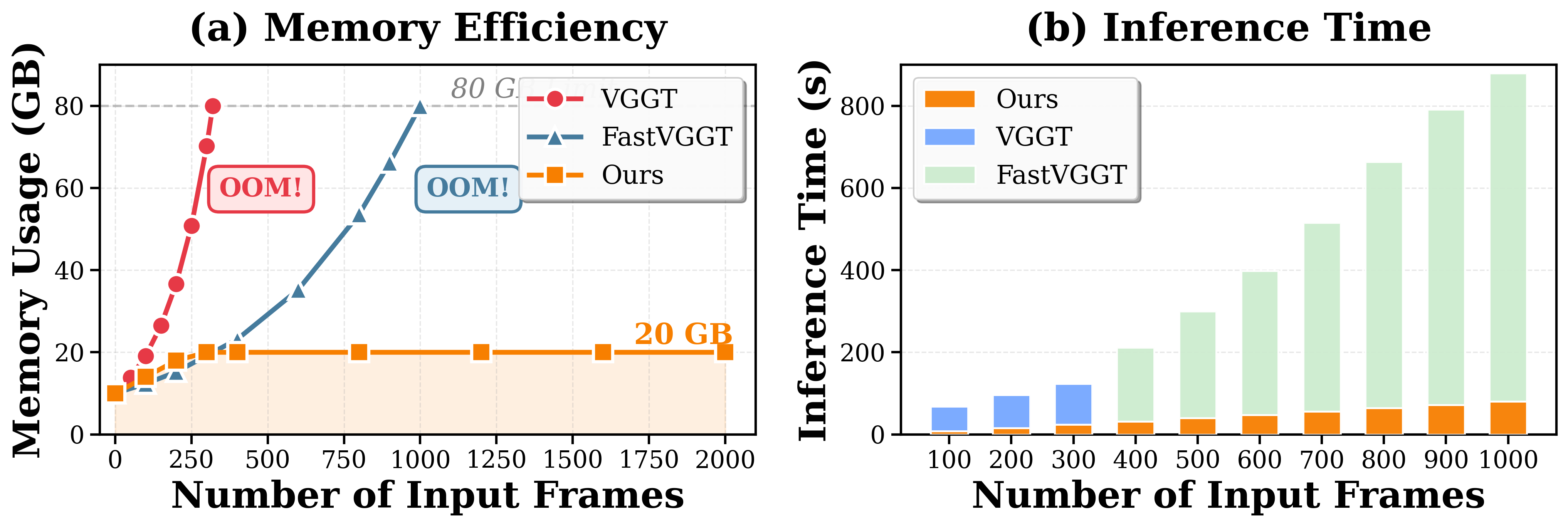
Memory, Latency, and Robustness
LongStream's architectural choices yield orders-of-magnitude improvements in both stability and efficiency:
Long-Range Trajectory and Geometry
LongStream consistently outperforms both offline SLAM and all prior streaming methods:
- KITTI/vKITTI/Waymo Benchmarks: The model delivers state-of-the-art tracking accuracy, maintaining <0.74 ATE (average trajectory error) even on held-out, multi-kilometer, outdoor driving datasets, where baselines such as Stream3R, StreamVGGT, and various online SLAMs drift or fail catastrophically.
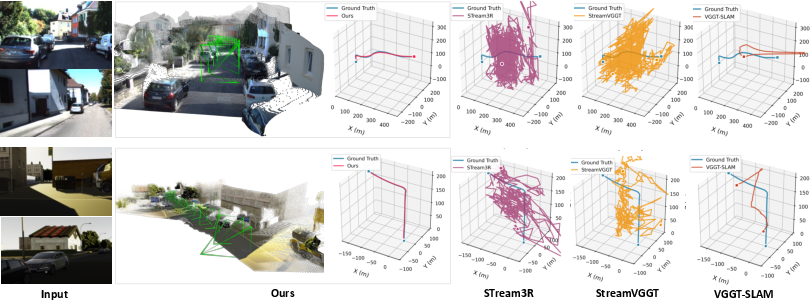
Figure 4: LongStream vs. baselines on KITTI/vKITTI: only LongStream maintains trajectory continuity and metric consistency on extended trajectories; others accumulate strong drift or OOM.
- Indoor (TUM/7Scenes): On complex indoor loops, fold-backs, and heavy occlusion, LongStream avoids repeated tracking loss and maintains a coherent global structure, while baselines lose tracking and accumulate significant error.
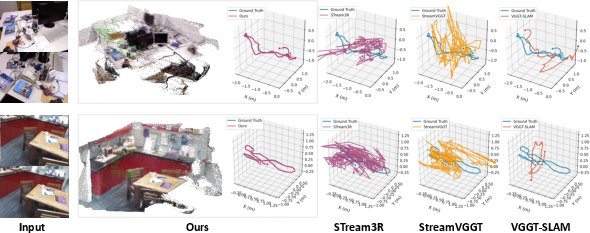
Figure 5: Qualitative pose consistency on highly challenging indoor sequences—LongStream avoids severe drift where all other methods degrade or fail.
Ablation—Necessity of Gauge Decoupling and CCT
A detailed ablation isolates the impact of key modules:
- Gauge-decoupled pose and scale yield an order-of-magnitude reduction in ATE compared to absolute pose regression with entangled scaling.
- CCT and periodic cache refresh eliminate long-horizon saturation, shown by a reduction in both ATE and relative pose error (RPE) to near zero. Disabling any of these components catastrophically degrades performance.
Loop Closure Limitation
LongStream's strictly causal pose estimation induces mild drift in large-scale global loop closures due to the lack of an explicit global correction or bundle adjustment module.
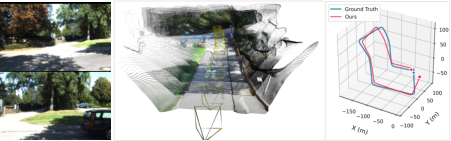
Figure 6: Mild drift in repeated-place revisiting scenarios reveals LongStream's current lack of loop-closure; online loop-closure cues are an explicit direction for future work.
Theoretical and Practical Implications
LongStream offers a principled foundation for large-scale, robust streaming geometry in visually rich, unconstrained environments. By decoupling gauge degrees of freedom, it provides a direct path to alleviate extrapolation-induced failure modes and aligns model training/inference. Its framework can be expanded to incorporate online loop-closure or dynamic scene adaptation modules, which are critical for true lifelong mapping and general 3D scene understanding in the wild.
On the practical side, LongStream represents a significant step toward deployable, high-fidelity, real-time 3D perception stacks for autonomous platforms, removing key bottlenecks for applications requiring reliable long-horizon operation.
Conclusion
LongStream represents a state-of-the-art paradigm for long-sequence, streaming, metric-scale 3D reconstruction. Its gauge-decoupled autoregressive architecture, explicit scale separation, and cache-consistent transformer training systematically remove key sources of failure responsible for drift and collapse in prior methods. Empirical results validate robust and stable operation on both large-scale outdoor and complex indoor benchmarks. While current limitations include the lack of explicit loop-closure and a heuristic keyframe schedule, the framework's rigorous theoretical underpinning provides a solid foundation for future advances in lifelong streaming geometry and AI-driven scene understanding (2602.13172).