- The paper introduces ThunderAgent, a system that achieves up to 3.92× throughput gains by mitigating KV cache thrashing and memory imbalance.
- The paper presents a program-centric abstraction with dynamic scheduling, shortest-first eviction, and lifecycle-aware tool management.
- The paper demonstrates significant reductions in end-to-end latency and enhanced resource efficiency across diverse RL and agentic serving tasks.
ThunderAgent: A Simple, Fast, and Program-Aware Agentic Inference System
Motivation and Limitations of Prior Agentic Inference Systems
Modern agentic systems using LLMs are increasingly deployed in complex, multi-turn workflows involving alternating reasoning and acting phases, frequent tool calls, and heterogeneous resource demands. Existing agentic inference stacks, often constructed from separate LLM engines (e.g., vLLM) and orchestration frameworks (e.g., Kubernetes), allocate resources on a per-request basis without program-level awareness, resulting in profound inefficiencies. These include KV cache thrashing, cross-node memory imbalance, unmanaged tool lifecycles, and throughput bottlenecks at scale.
Throughput degradation for agentic workloads rises sharply with increased parallelism due to poor KV cache hit rates and high latency from re-prefill operations. RL rollouts further amplify these bottlenecks, as rollout dominates wall-clock training time and affects policy staleness and convergence. Autellix and Continuum partially mitigate these issues but fail to optimally manage program locality, tool execution time variability, and cross-node resource distribution—especially under heavy stochastic tool workloads.
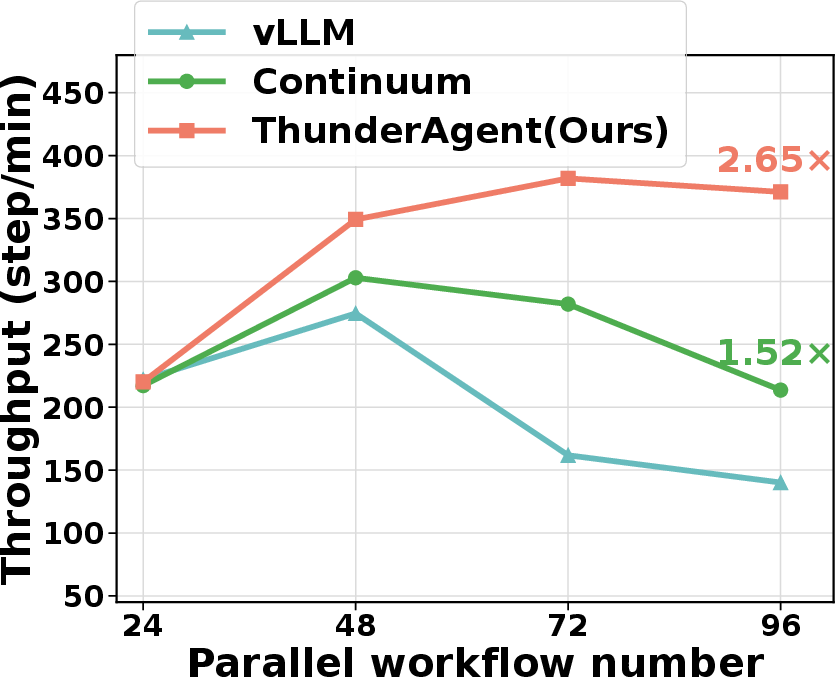
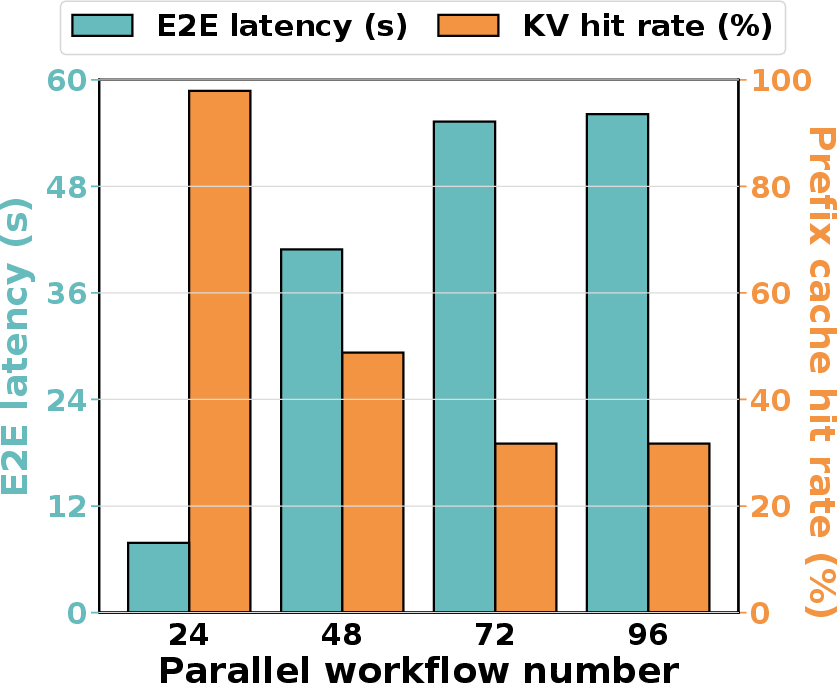
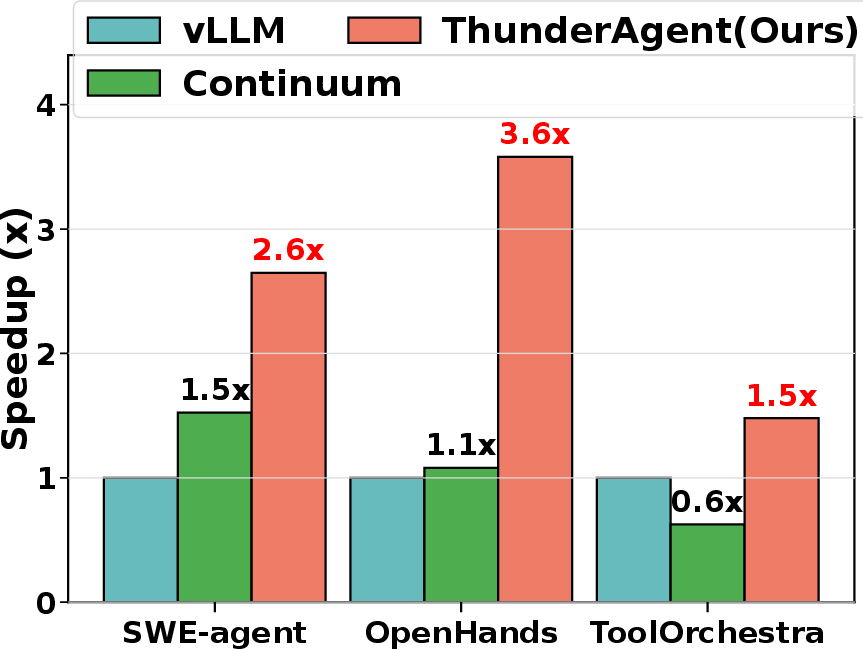
Figure 1: Throughput degradation as batch size increases in existing systems, driven by KV cache thrashing and memory mismanagement.
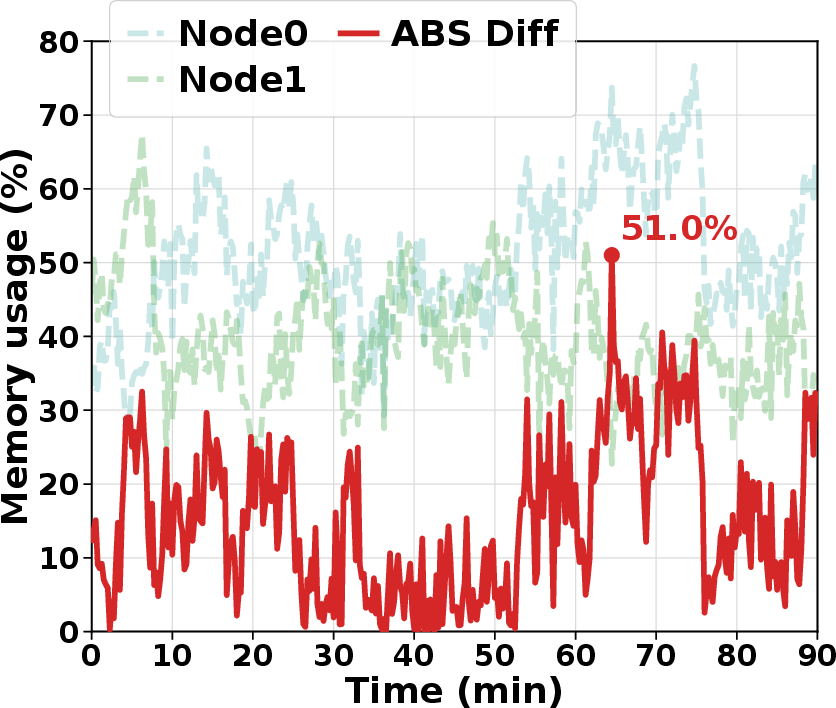
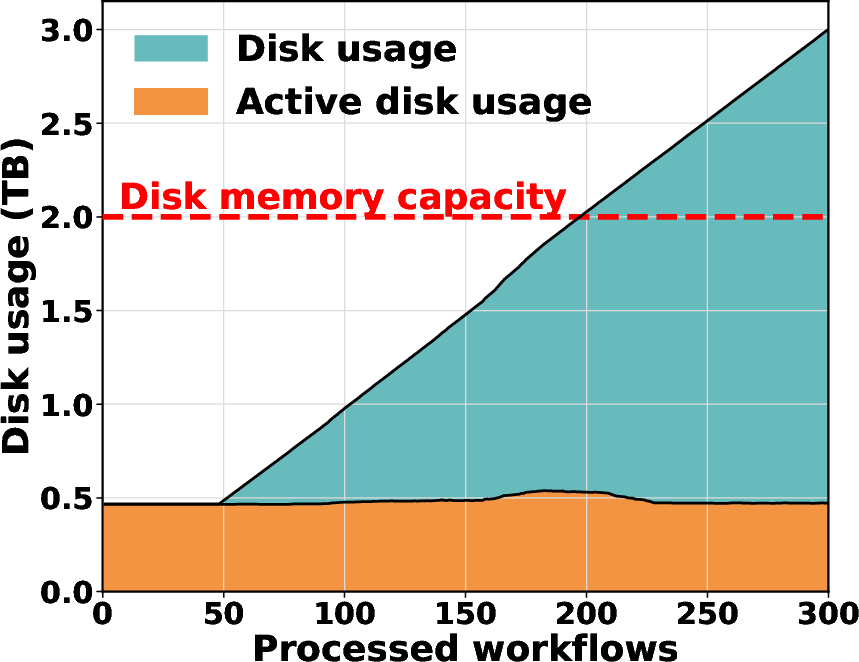
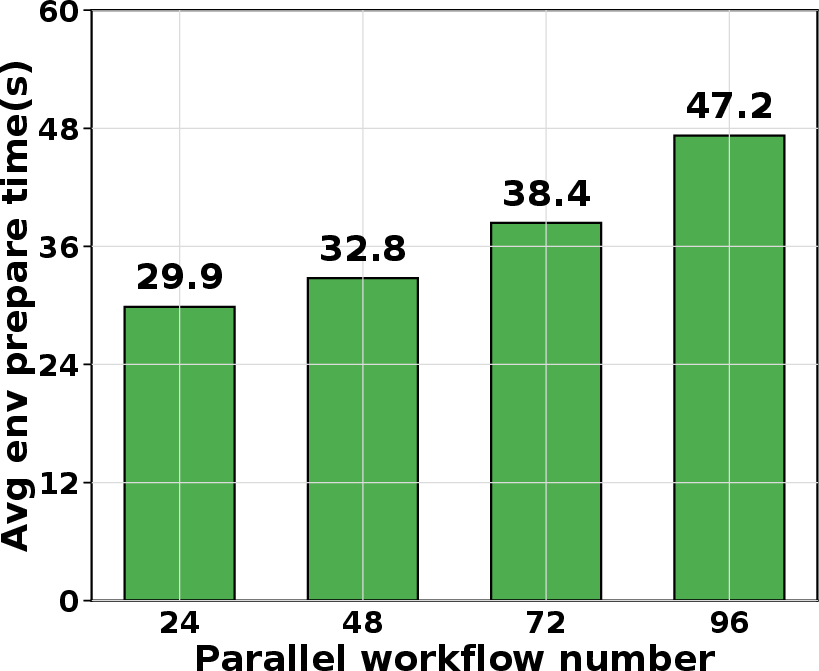
Figure 2: Memory imbalance in RL rollout due to fixed routing policies; some GPU nodes are over-committed while others remain idle.
ThunderAgent Architecture: Program Abstraction and Unified Resource Management
ThunderAgent introduces a program-centric abstraction, representing each agentic workflow as an “agentic program” that persists across multiple model invocations and tool executions. Each program maintains explicit metadata (identifier, context length, tool environments, node placement, execution phase, scheduling state), decoupling scheduling from backend inference engines.
The program-aware scheduler operates under a space-time product (STP) cost model, actively optimizing the sum of decoding, prefilling, recomputation, unused capacity, and idle caching. ThunderAgent’s key mechanisms include:
- Periodic thrashing detection: Memory usage is monitored at fixed intervals, allowing proactive pausing of acting-phase programs and restoring reasoning-phase programs, minimizing both thrashing and idle memory.
- Shortest-first eviction: When thrashing is detected, programs with minimal context lengths are paused first, minimizing quadratic recomputation costs.
- Global waiting queue: Paused programs are globally pooled, enabling dynamic migration across DP nodes to rebalance memory usage and mitigate cross-node idle capacity.
- Lifecycle-aware tool resource management: ThunderAgent implements hook-based garbage collection and asynchronous environment preparation. Tool environments are reclaimed on program termination, and environment initialization is overlapped with LLM reasoning to reduce latency.
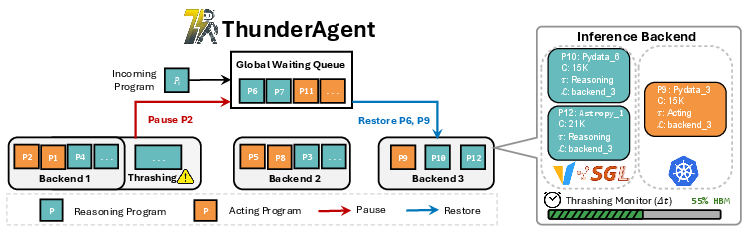
Figure 3: Overview of ThunderAgent showing state transitions, periodic backend memory checks, thrashing mitigation, and global program queue.
Experimental Evaluation: Throughput Gains and Resource Efficiency
ThunderAgent was benchmarked across diverse agentic serving and RL rollout tasks (coding, routing, scientific discovery) with both OpenHands and SWEAgent frameworks, and state-of-the-art LLMs (GLM-4.6, Qwen-3). Models were deployed with Tensor Parallelism on H100 clusters, and tools executed on dedicated CPU clusters.
Serving throughput (steps/min) under high concurrency: ThunderAgent achieved 1.48–3.58× speedup over vLLM and 1.17–3.31× over Continuum. Improvements are attributed to sustained KV cache hit rates, efficient asynchronous environment preparation, and robust adaptation to deterministic and stochastic tool workloads.
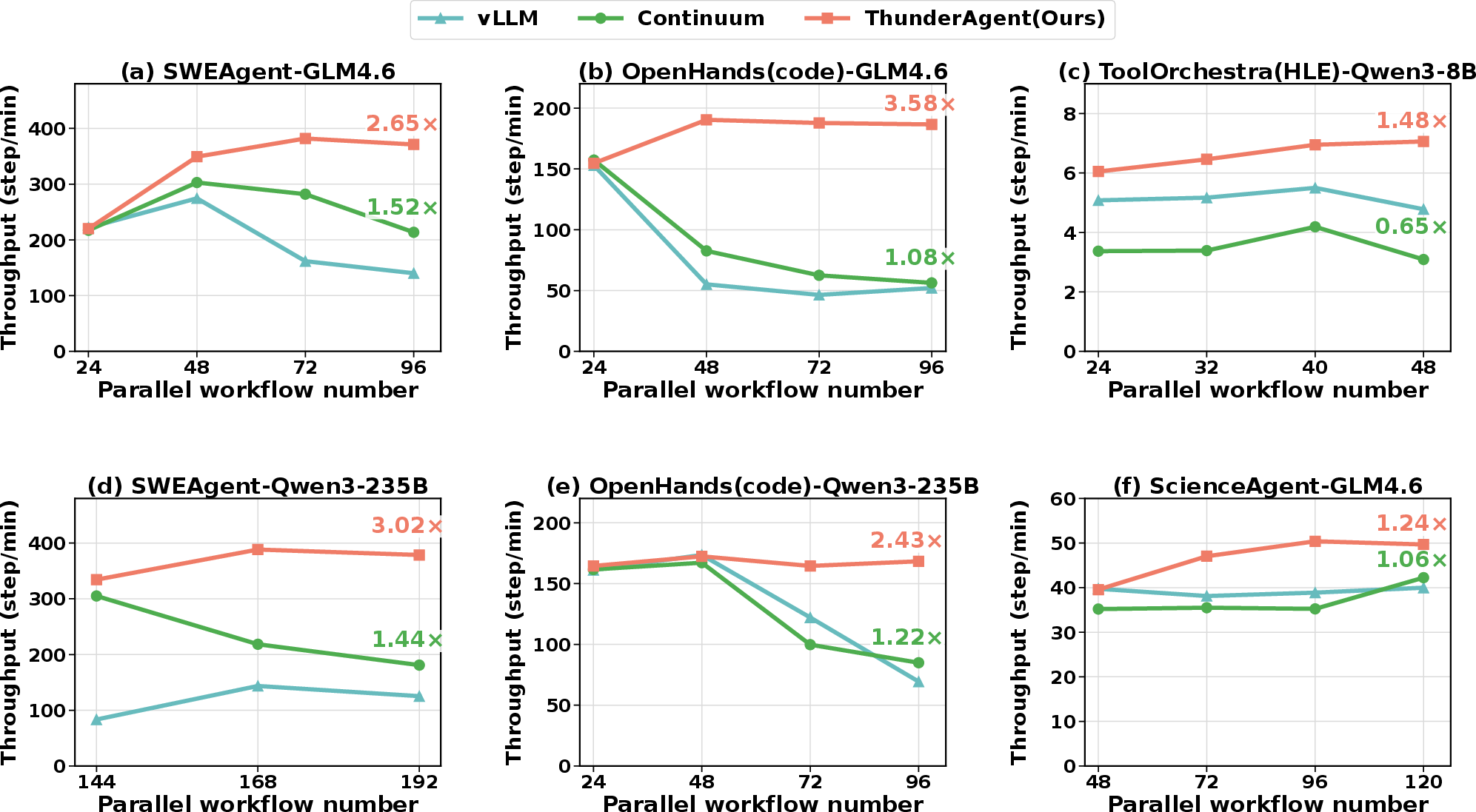
Figure 4: Serving evaluation results for ThunderAgent versus vLLM and Continuum; consistent throughput gains across models, workflows, and datasets.
RL rollout throughput: On distributed H100 nodes, ThunderAgent delivered 1.79–3.92× improvements over vLLM+Gateway, critical for scaling RL with agentic workflows.
KV cache statistics: ThunderAgent maintains near-optimal hit rates for predictable tool call times and dynamically trades hit rate for reduced idle caching in stochastic contexts, yielding superior throughput even when baselines have higher nominal hit rates.
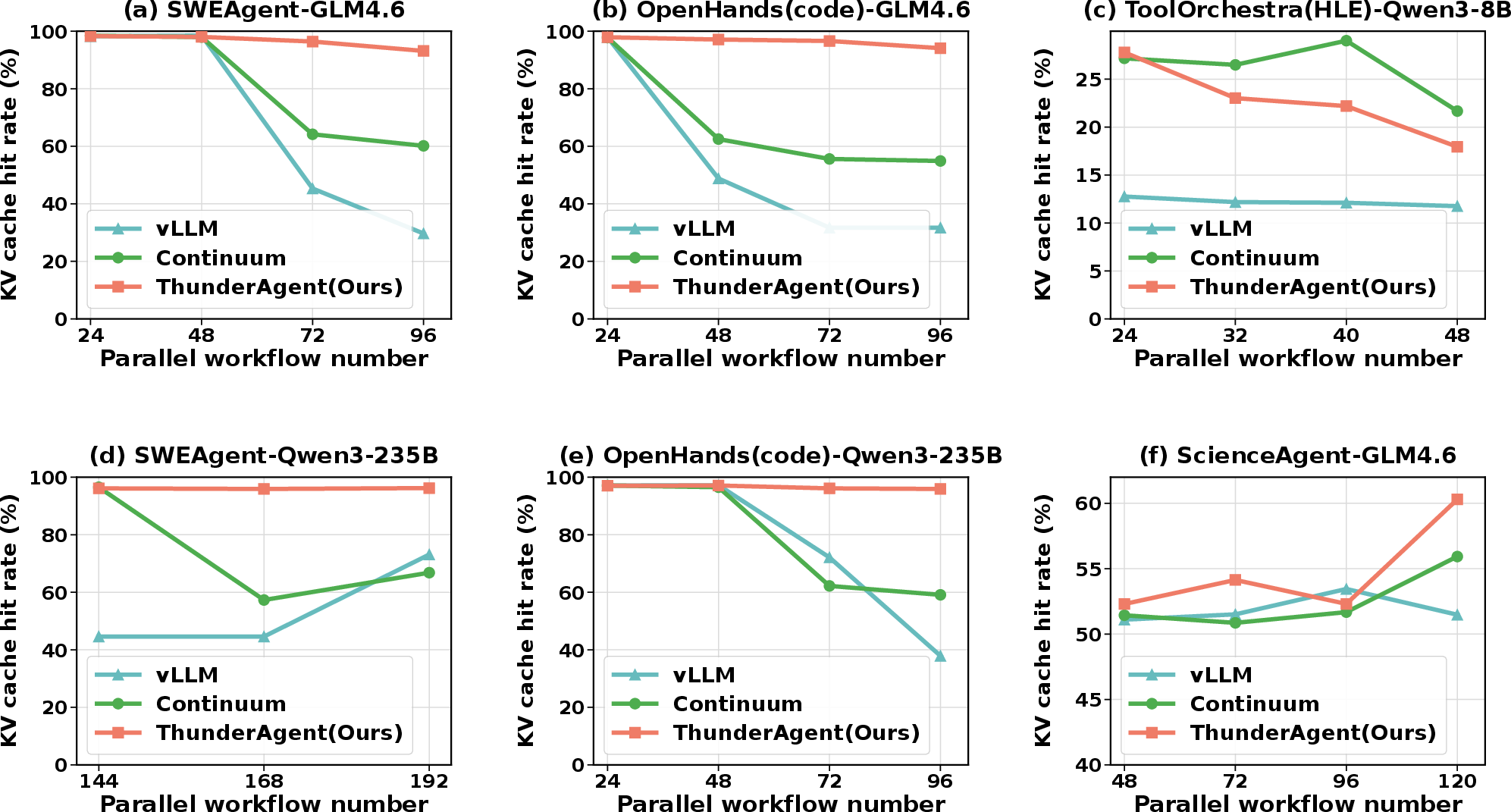
Figure 5: KV cache hit rate statistics; ThunderAgent’s scheduler balances cache reuse and idle memory under stochastic tool times.
End-to-end latency: Prefill and decode latency are substantially reduced. Improved tool resource management delivers up to 4.2× disk memory savings.
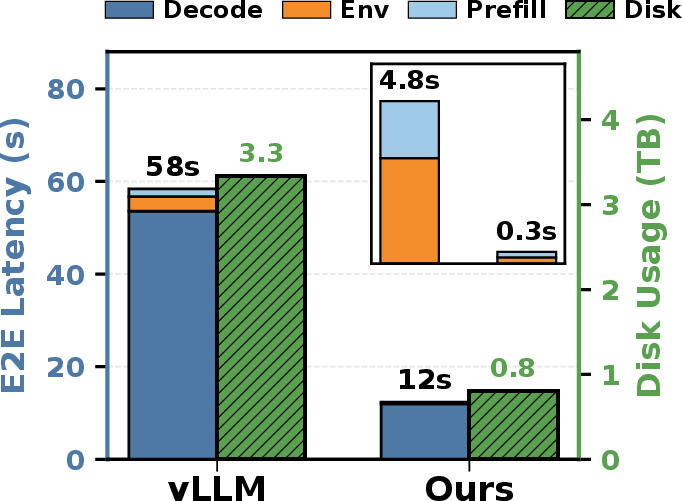
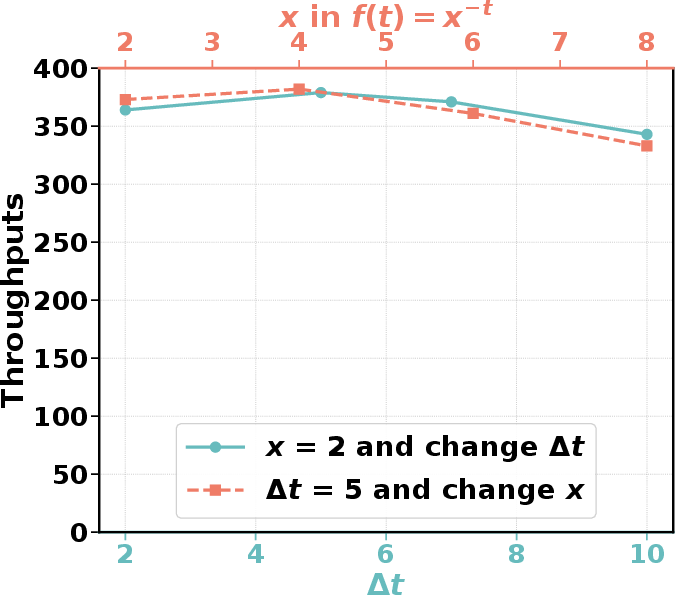
Figure 6: End-to-end latency breakdown in RL agentic workflows; ThunderAgent reduces prefill, decode, and tool preparation times.
Tool execution time distribution: Empirical analysis confirms that tool runtimes can exhibit high variance and heavy tails, undermining static TTL-based cache pinning and motivating ThunderAgent’s dynamic decay-based eviction policy.
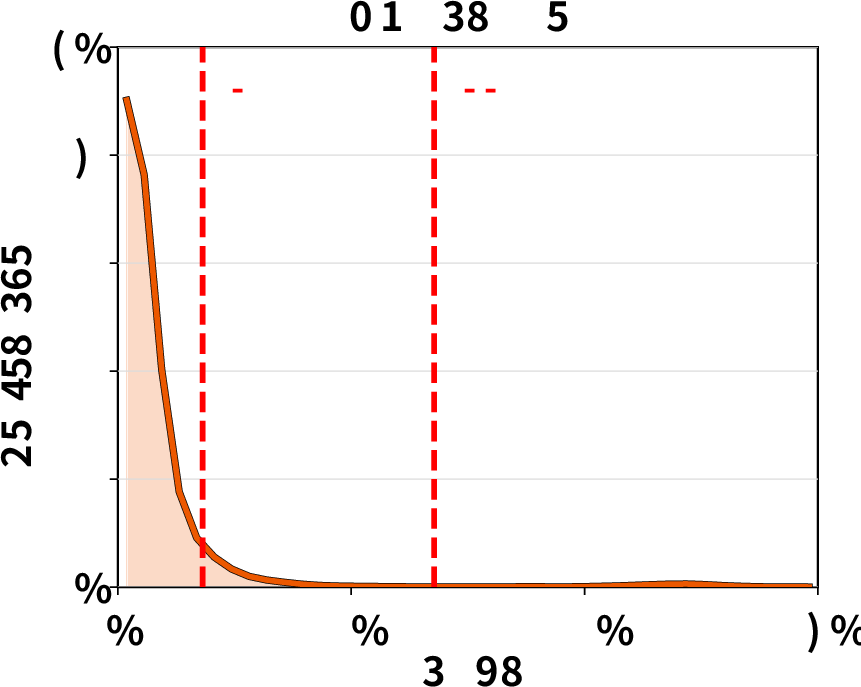
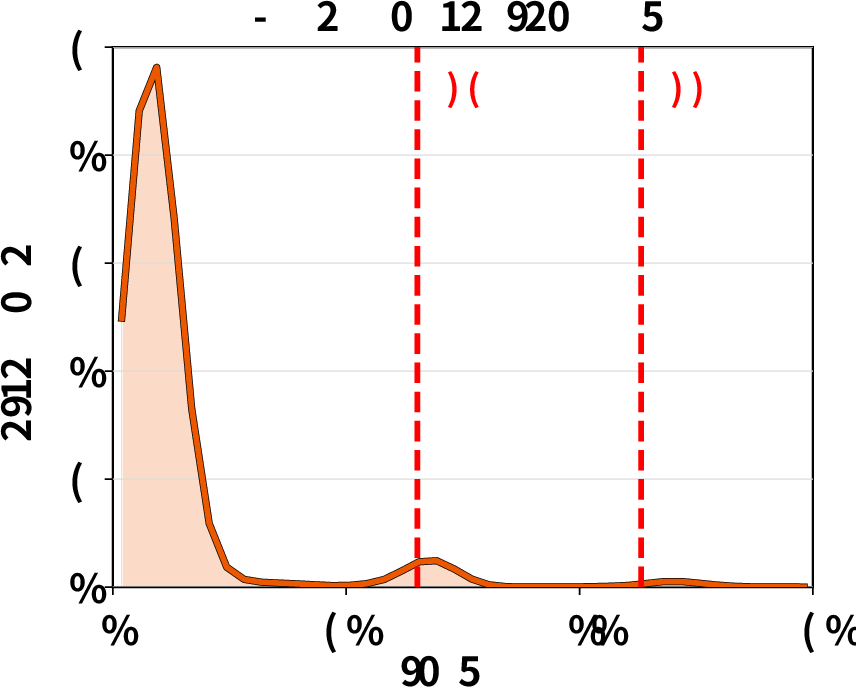
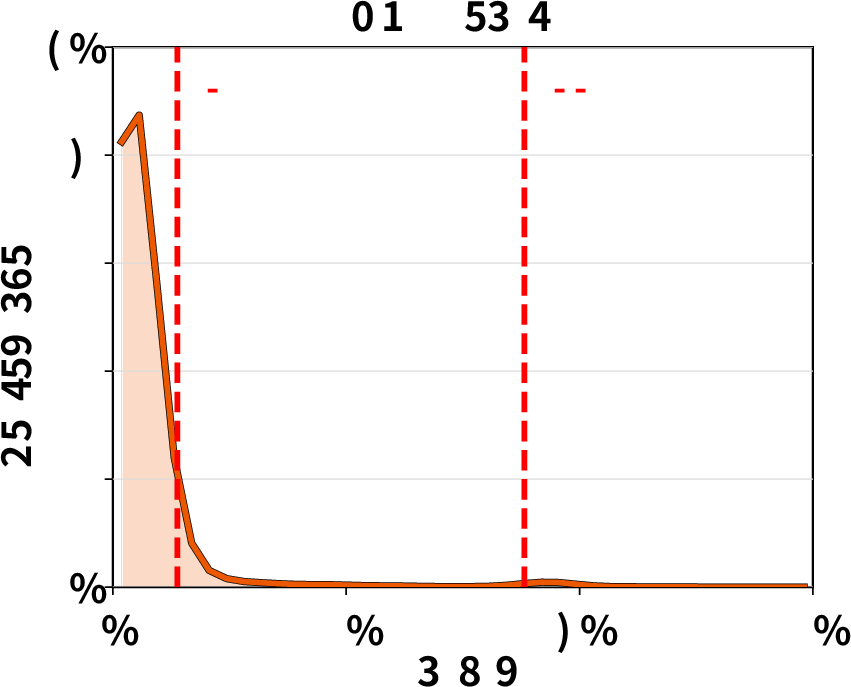
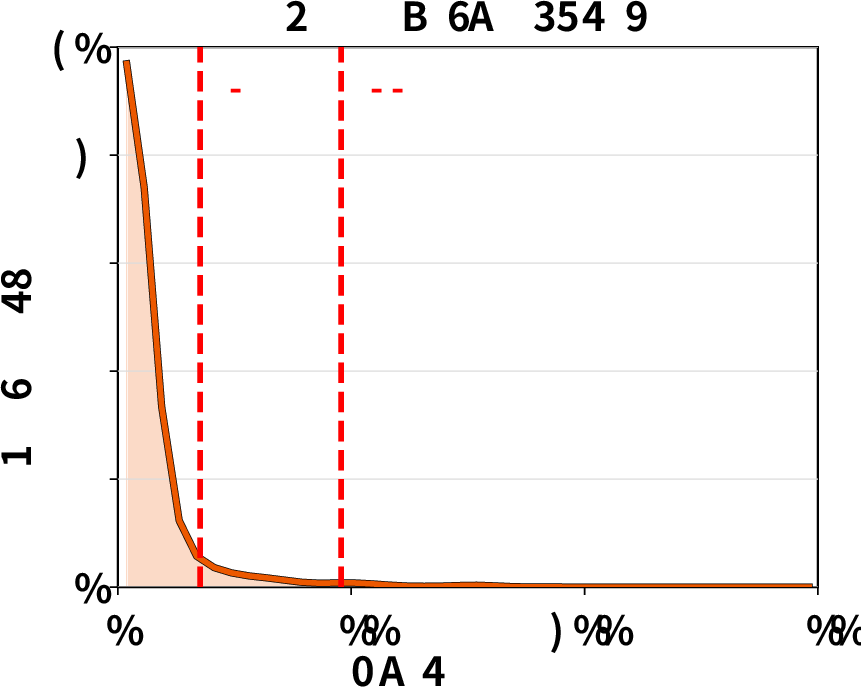
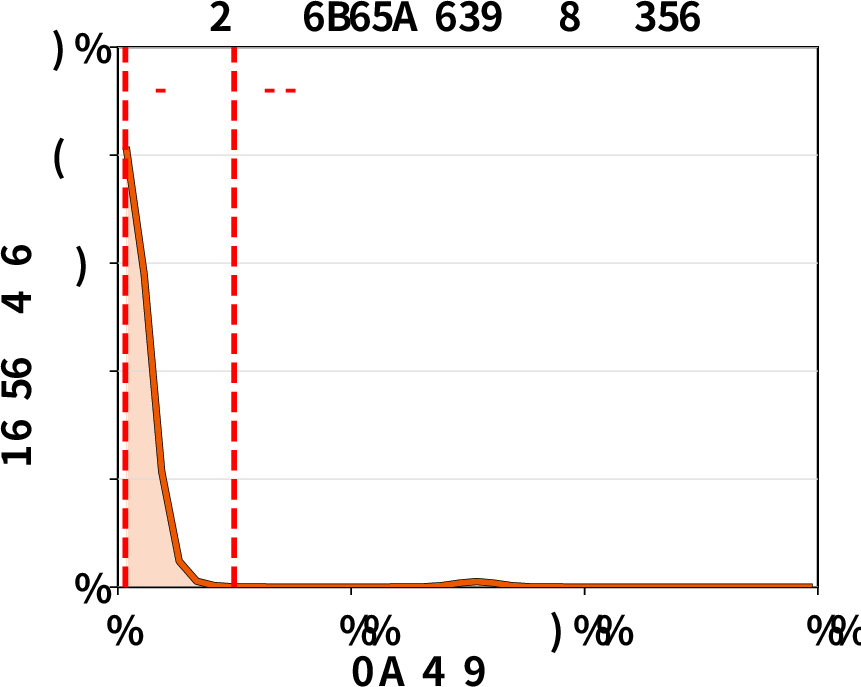
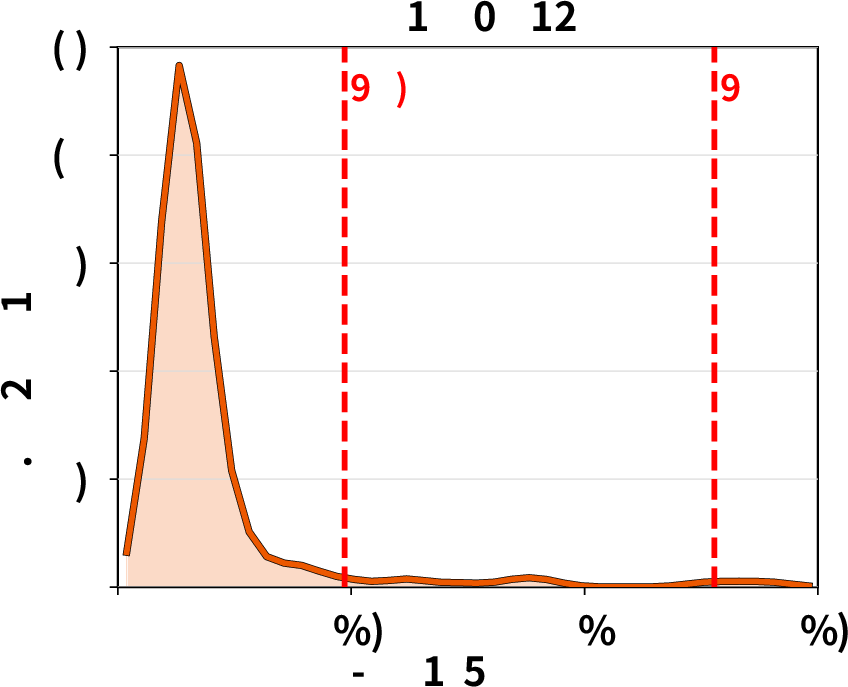
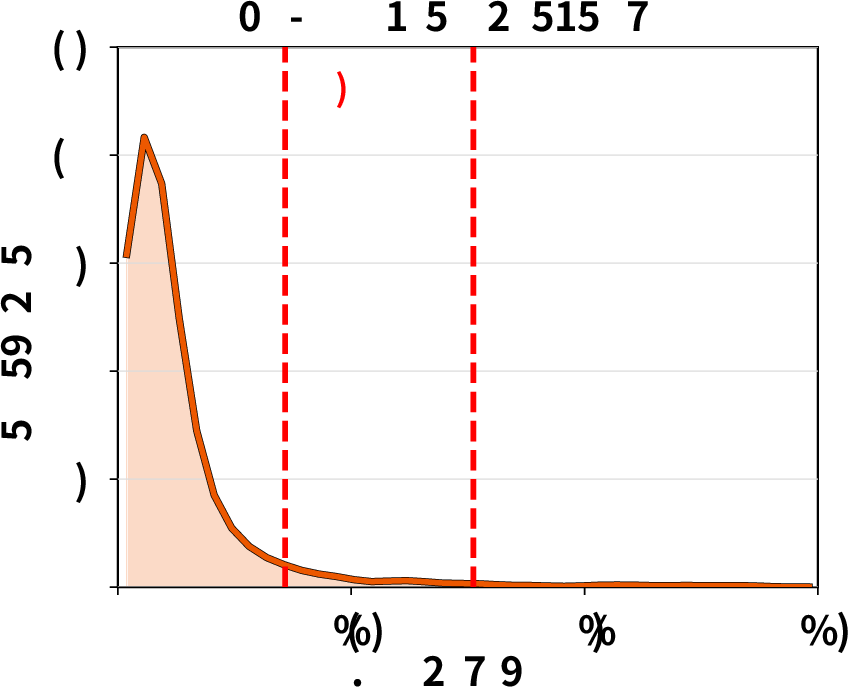
Figure 7: Tool execution time distributions exhibit heavy-tailed variability, complicating cache management for agentic workloads.
Comparative Analysis and Ablations
ThunderAgent’s superiority emerges not only from its throughput numbers but from its dynamic adaptability. Ablation studies show robust performance across a range of scheduler detection intervals and decay parameters. Attempts to remedy memory constraints with LMCache offloading or PD disaggregation (splitting prefill/decode nodes) introduce substantial new bottlenecks (PCIe bandwidth, memory fragmentation), further underscoring the necessity of program-centric scheduling.
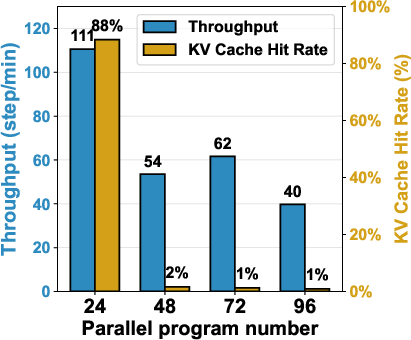
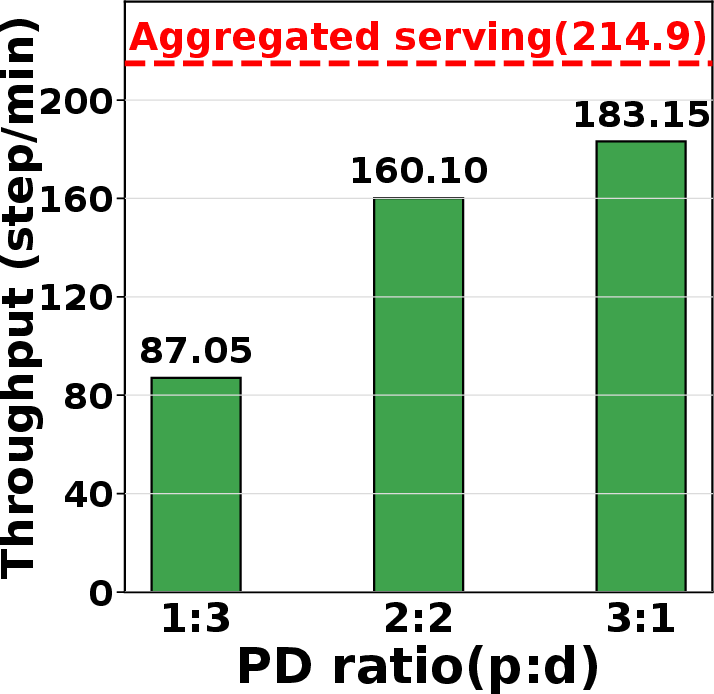
Figure 8: KV cache hit rate with LMCache offloading; offloading adds latency and reduces throughput for agentic tasks.
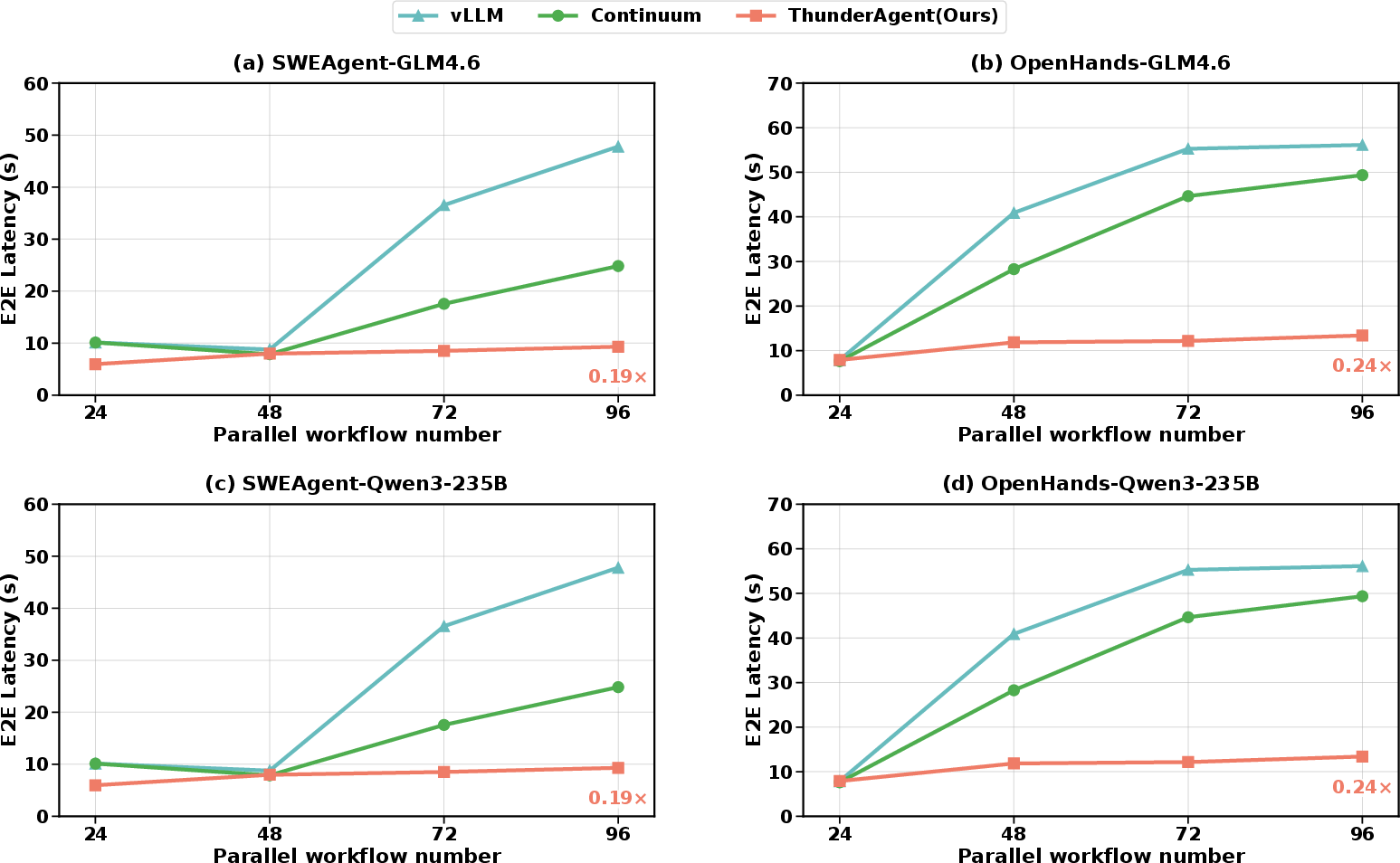
Figure 9: End-to-end latency comparison; ThunderAgent maintains competitive per-step latency across all workflows.
Implications, Theoretical Insights, and Future Directions
ThunderAgent’s explicit program abstraction and unified resource management enable principled scheduling, minimizing quadratic recomputation penalties and balancing throughput with idle memory—particularly crucial in large-scale autonomous agentics and RL. By dynamically allocating memory and offloading workloads across GPU nodes, ThunderAgent achieves scalable, memory-efficient inference and serving.
Program-centric scheduling opens new optimization avenues for agentic orchestration in future distributed systems (e.g., MegaFlow (Zhang et al., 12 Jan 2026)), RL scaling (RollArt (Gao et al., 27 Dec 2025)), and hierarchical memory architectures (Pensieve [Yu_2025], Strata (Xie et al., 26 Aug 2025)). Theoretical frameworks for time decay, empirical analyses on tool variability, and shortest-first eviction extend generalizability to increasingly complex agentic workloads. As agentic RL, tool orchestration, and persistent environment management become central to next-generation AI systems, program-aware inference stacks like ThunderAgent are poised to supplant request-level schedulers.
Conclusion
ThunderAgent establishes a new paradigm for high-throughput agentic inference, leveraging an explicit program abstraction for scheduling and heterogeneous resource management. It systematically alleviates KV cache thrashing, memory imbalance, and tool resource leakage, resulting in substantial throughput and efficiency gains over contemporary systems. Its design is robust to stochastic tool latencies and adaptable for large-scale agentic deployments and RL rollouts. This work advances state-of-the-art agentic inference and motivates future research in scalable orchestration and unified memory management for autonomous LLM agents.
(2602.13692)