- The paper demonstrates that standard SAE metrics like explained variance do not reliably indicate true feature recovery.
- It uses synthetic experiments and frozen decoder methods to compare trained SAEs with strong random baselines.
- The findings challenge conventional interpretability claims and recommend rigorous sanity checks for meaningful feature validation.
Critical Assessment of SAE Feature Learning: Evidence from Sanity Checks and Random Baselines
Motivation and Background
Sparse Autoencoders (SAEs) have been widely adopted for mechanistic interpretability of neural networks due to their ability to decompose high-dimensional activations into sparse, putatively human-interpretable features. Across multiple SAE architectures, prior studies have showcased high interpretability, strong reconstruction, and successful scaling to frontier LLMs. However, this paper systematically interrogates the implicit assumption that high scores on standard proxy metrics reliably indicate meaningful feature learning. The authors leverage synthetic experiments with known ground-truth features and introduce strong randomization baselines (“frozen” SAEs) on real LLM activation data, directly testing whether learned features are indeed aligned to model mechanisms or if competitive results can emerge from chance alone.
Synthetic Evaluation: Disconnect between Reconstruction and Feature Recovery
The first case study contextualizes SAE learning with a synthetic dataset explicitly constructed from sparse superpositions of known feature vectors. The expansion factor mimics realistic values (k=32), with both constant and heavy-tailed activation frequency regimes. Despite SAEs achieving high explained variance (up to 71%), their feature recovery rate is extremely low (less than 9%), with successful alignment restricted to only the most frequently activated features. This demonstrates that the canonical SAE losses drive recovery of high-variance directions but do not yield complete or faithful ground-truth decomposition—even in controlled settings. The results directly contradict the premise that explained variance is a reliable proxy for true feature discovery.
Systematic Null Tests: Frozen SAE Baselines
The second case study introduces three baselines that freeze or constrain key SAE components (decoder or encoder) at random initialization: Frozen Decoder, Soft-Frozen Decoder (restricted cosine similarity to random initialization), and Frozen Encoder. On real LLM activations (Gemma-2-2B, Llama-3-8B), these variants are benchmarked alongside fully trained SAEs using four standard metrics: explained variance, automated interpretability (AutoInterp), sparse probing, and causal editing (RAVEL).
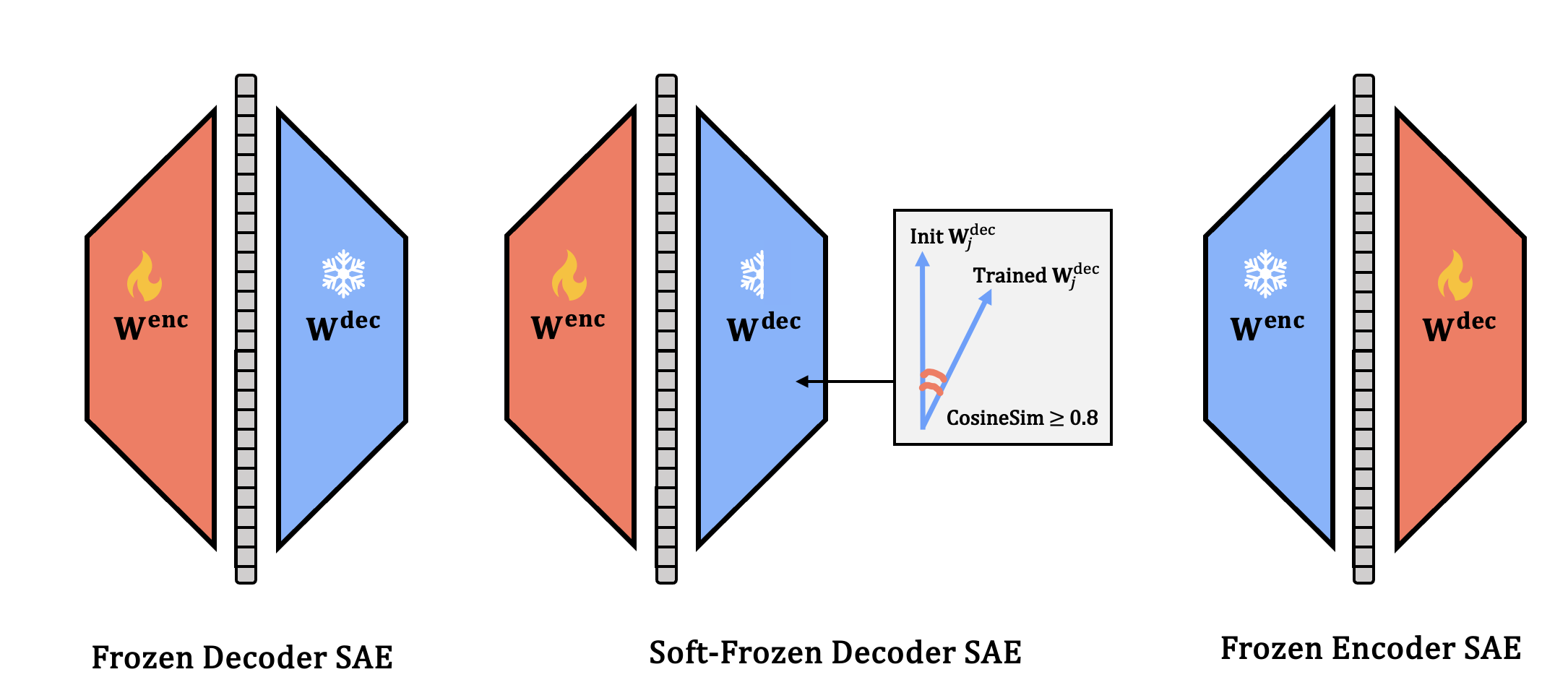
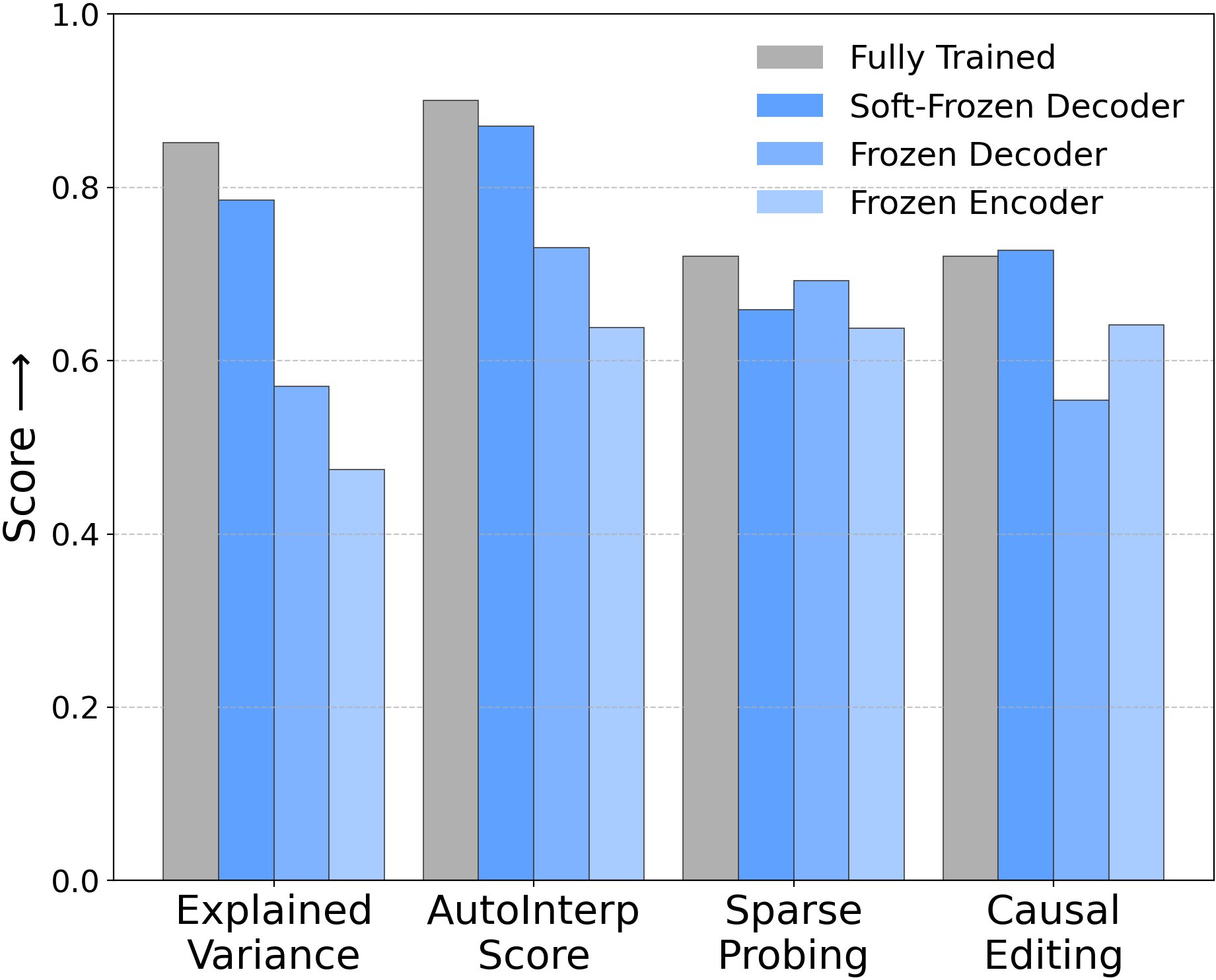
Figure 1: Three conceptual frozen SAE variants and performance across four metrics, challenging the assumption that strong performance implies meaningful feature learning.
The results reveal that these frozen baselines remain competitive with fully trained SAEs, often matching or approaching the original models’ performance. Specifically:
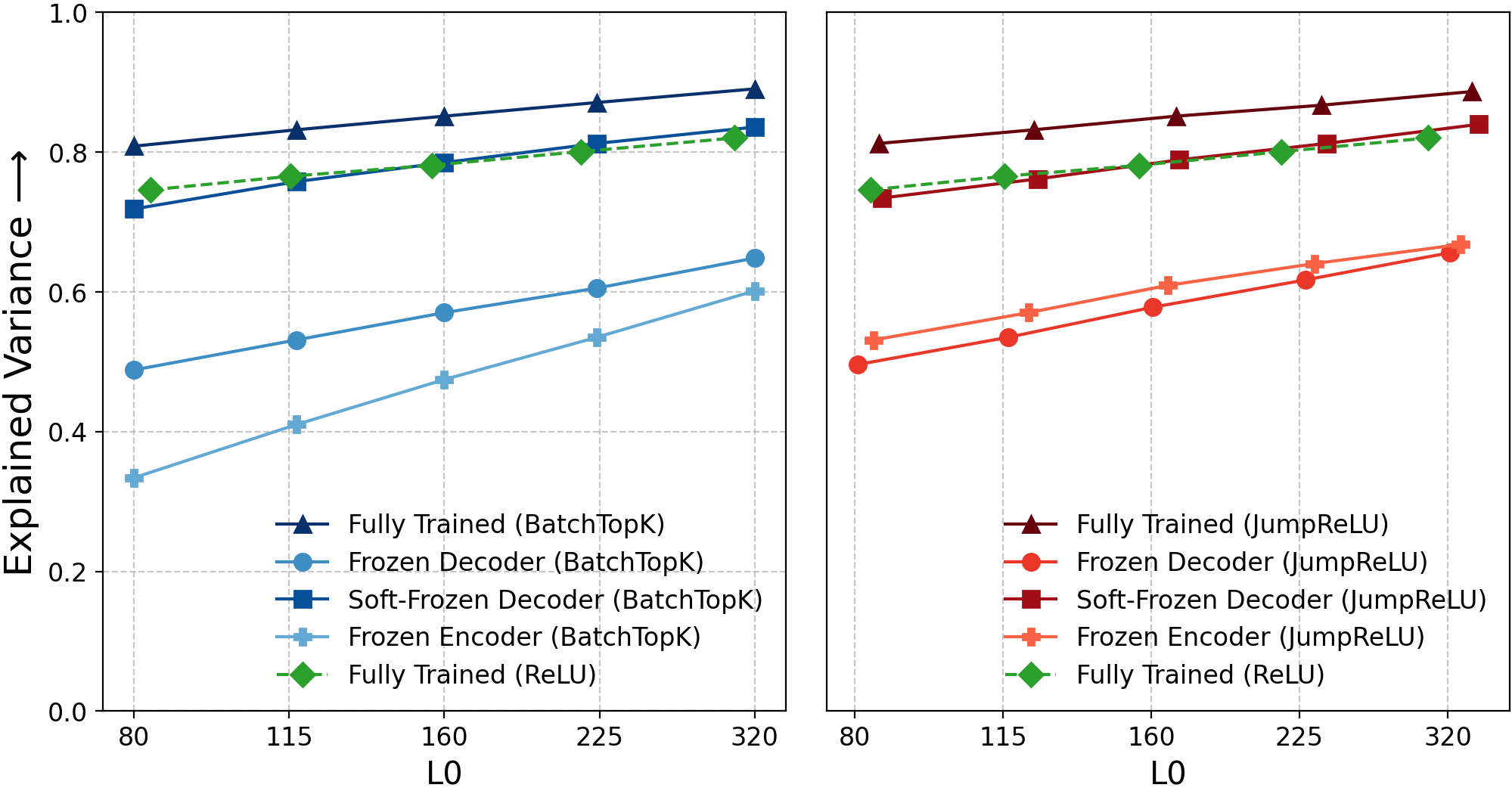
Figure 2: Explained variance for frozen-component SAEs, with Soft-Frozen Decoder matching original variants and losing only 6%.
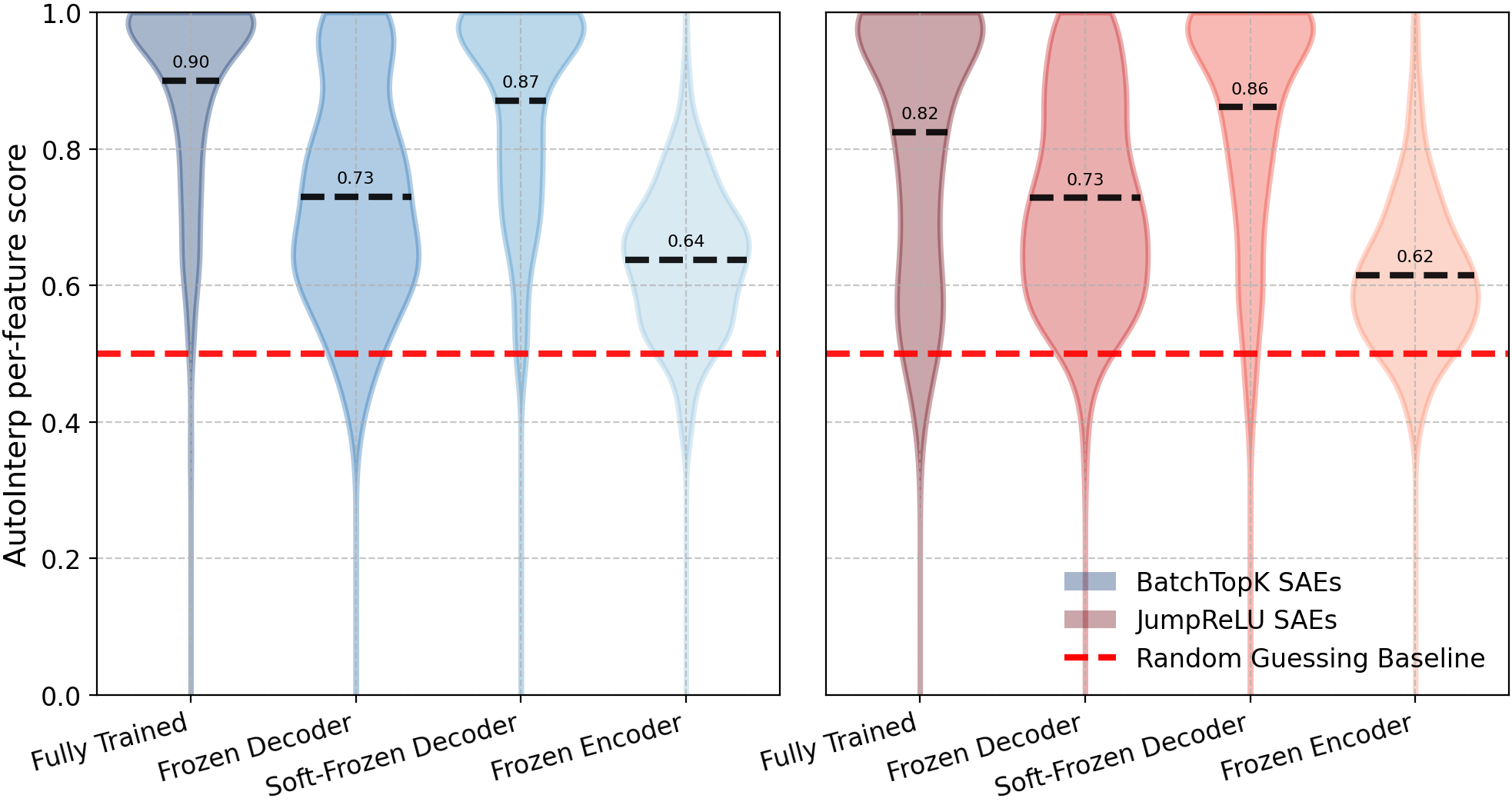
Figure 3: AutoInterp distributions, showing high interpretability scores for frozen variants and parity with original SAEs.

Figure 4: Qualitative examples of interpretable latents from frozen SAEs, capturing abstract concepts and monosemantic high-level features.
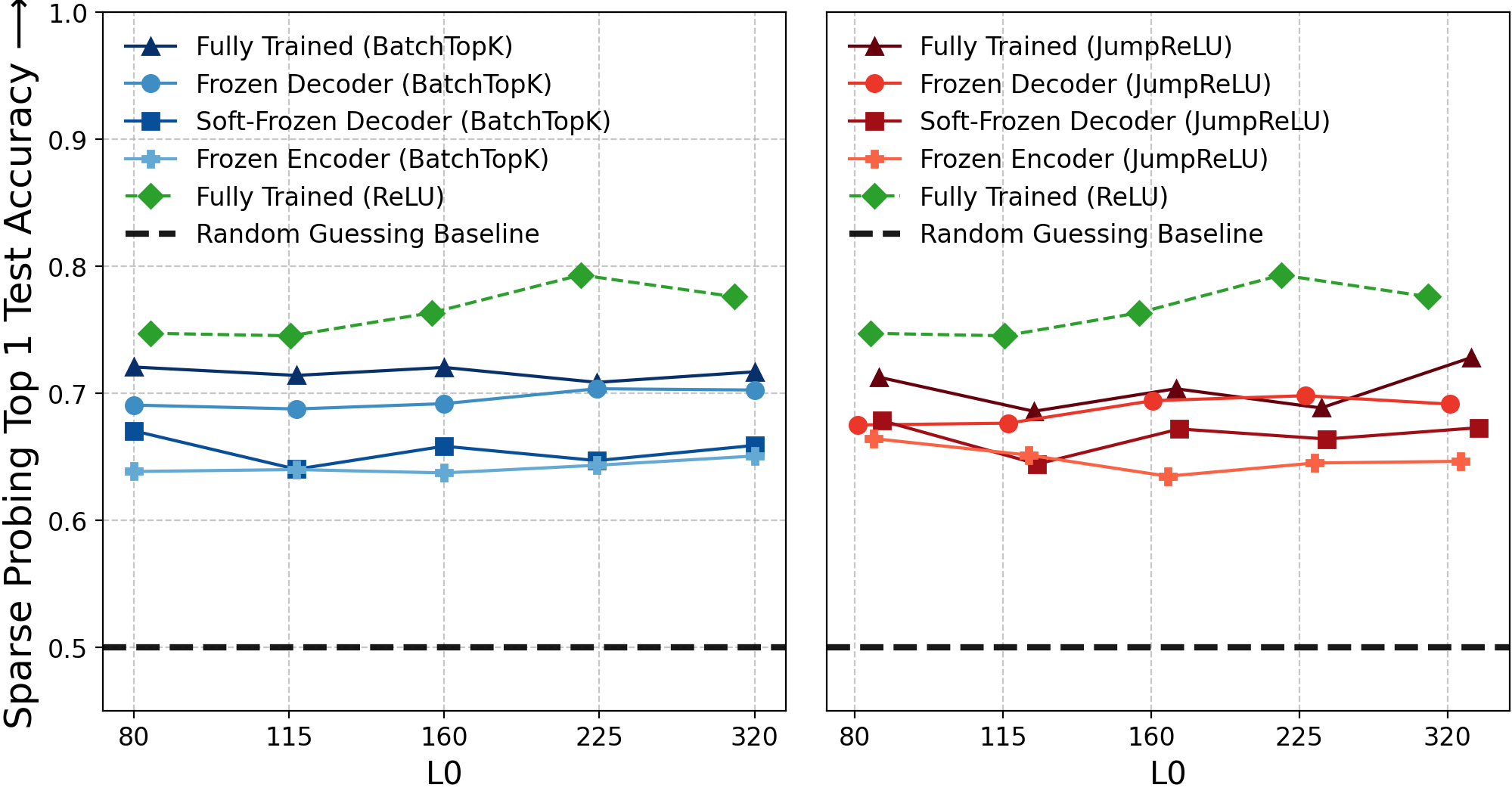
Figure 5: Sparse probing accuracy for single-top-latent, with frozen baselines comparable to fully-trained SAEs.
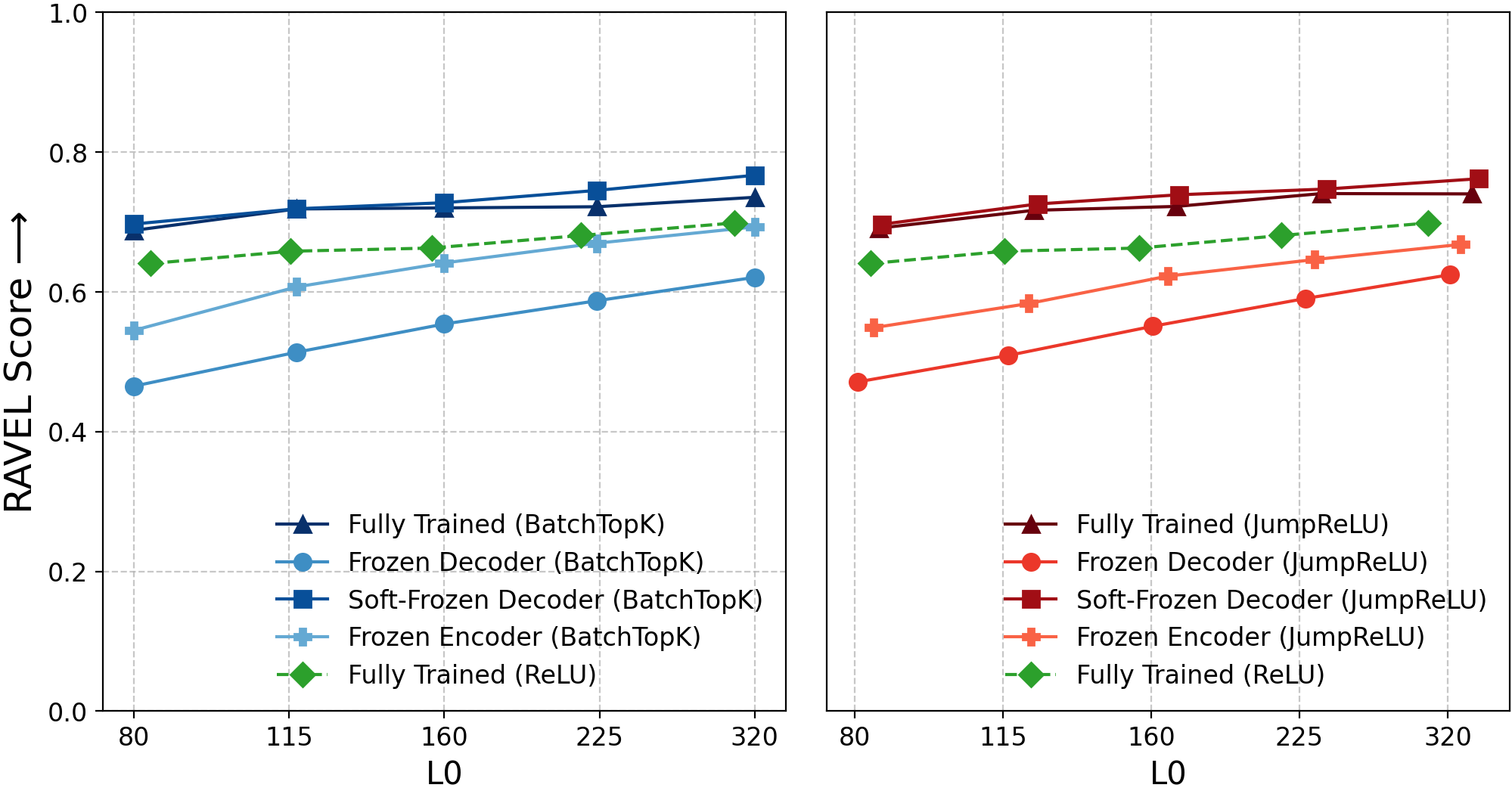
Figure 6: RAVEL causal editing scores, indicating equivalent disentanglement scores for frozen and fully-trained SAEs.
Quantitative and Qualitative Findings
- Reconstruction Fidelity: Frozen variants—including those with minimal parameter updates—achieve explained variance and cross-entropy losses similar to trained SAEs; reconstruction fidelity alone is insufficient to validate feature learning.
- Interpretability and Monosemanticity: Both automated and qualitative analyses demonstrate that high-level, monosemantic features can emerge from randomly initialized/frozen directions, undermining claims that interpretability scores indicate learned feature alignment.
- Sparse Probing: With large dictionaries (m≫n), random latents achieve strong correlations with target concepts, suggesting that chance alignment—not learning—may explain competitive probing results.
- Causal Editing: Disentanglement scores in causal editing (RAVEL) for frozen baselines match or exceed fully-trained SAEs; causal editing capability does not require meaningful feature decomposition.
Additional metrics (KL divergence, multi-latent probing) reinforce these conclusions, showing larger gaps only for tasks requiring aggregation across features, suggesting the principal weakness of random baselines is combinatorial, not semantic.
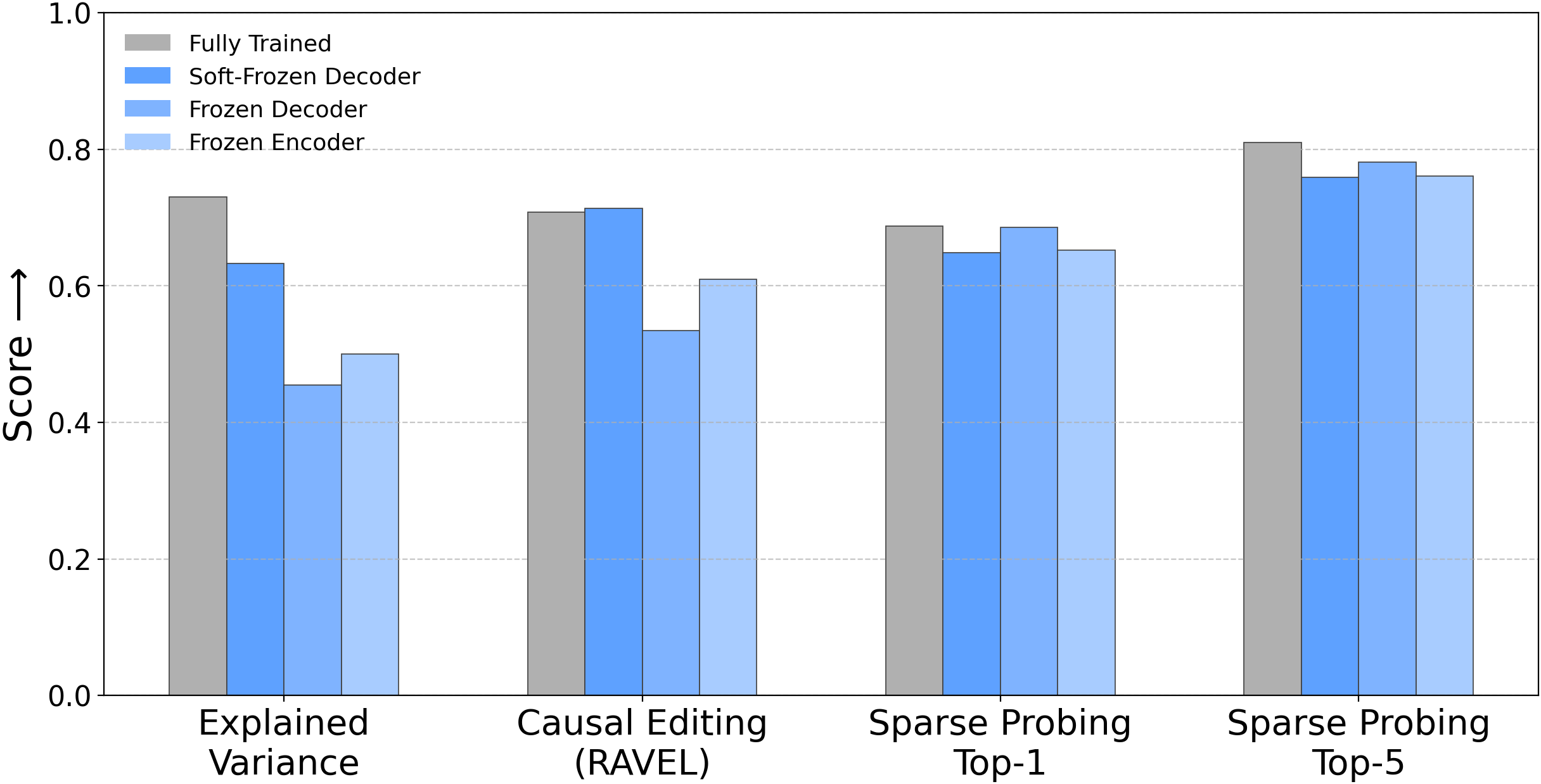
Figure 7: Performance of frozen baselines for TopK SAE on real Gemma-2-2B activations demonstrates competitive results across metrics.
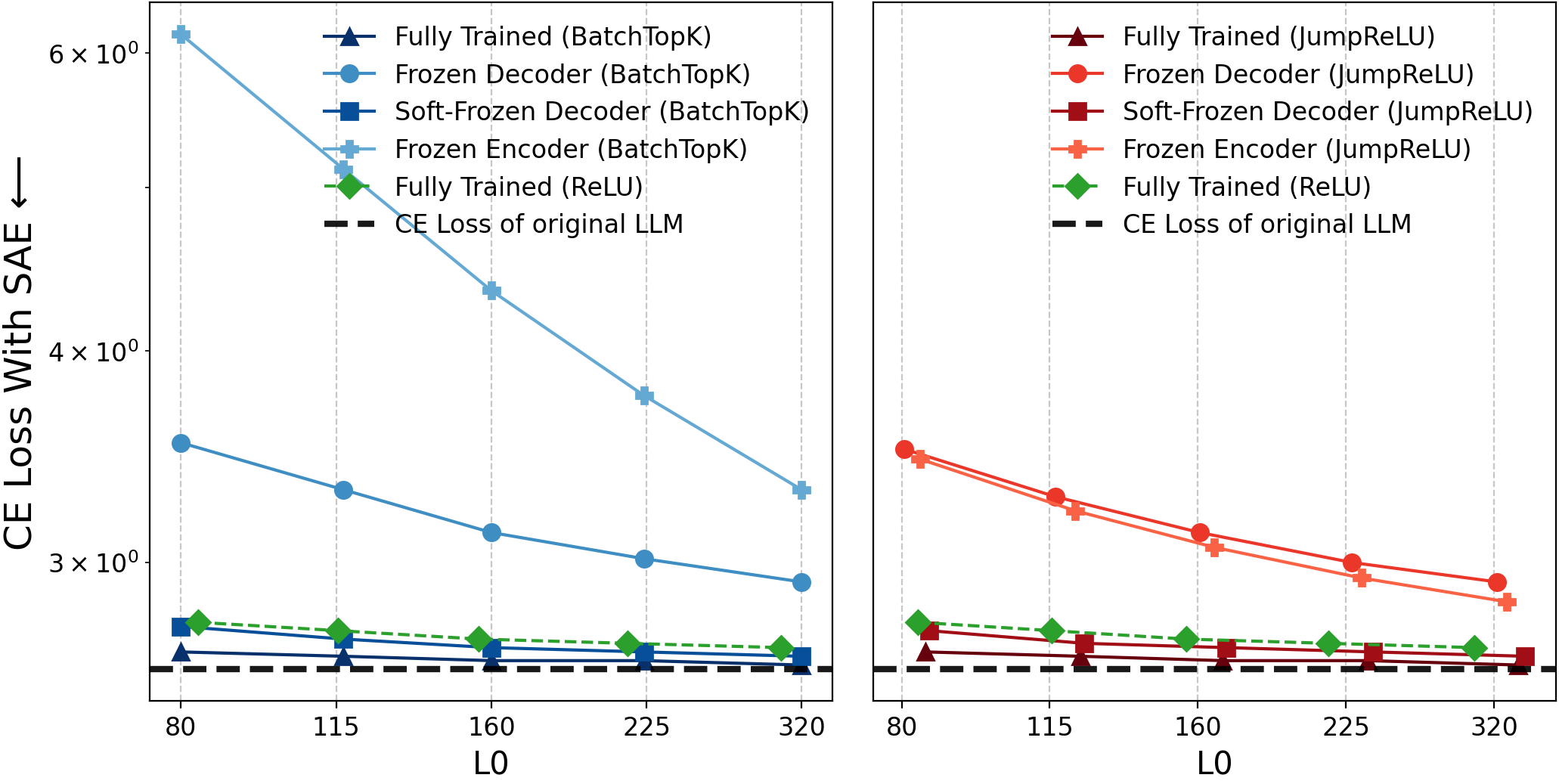
Figure 8: Cross-entropy loss parity for frozen and trained SAEs.
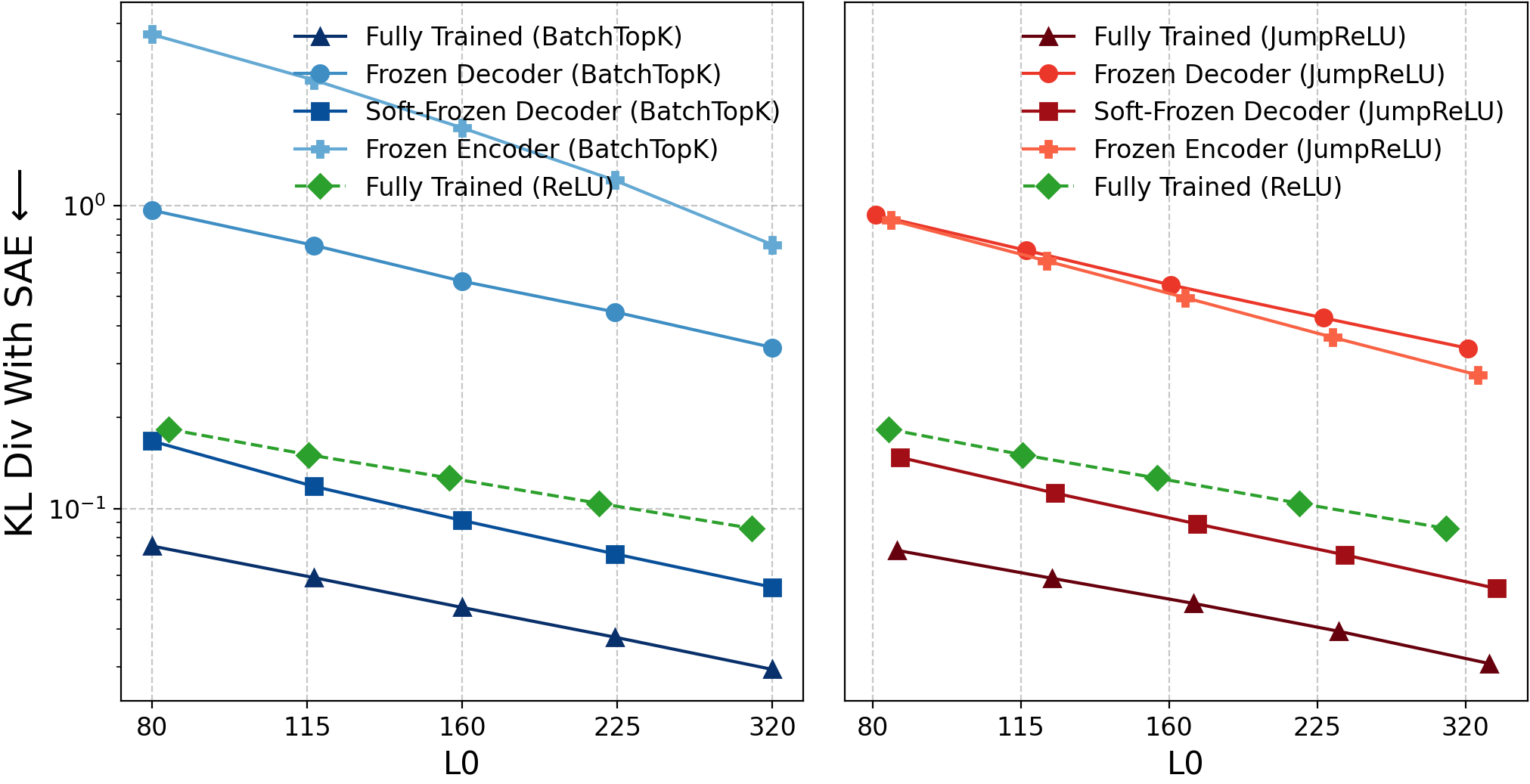
Figure 9: KL-divergence comparison; similar distributions for random and learned SAEs.
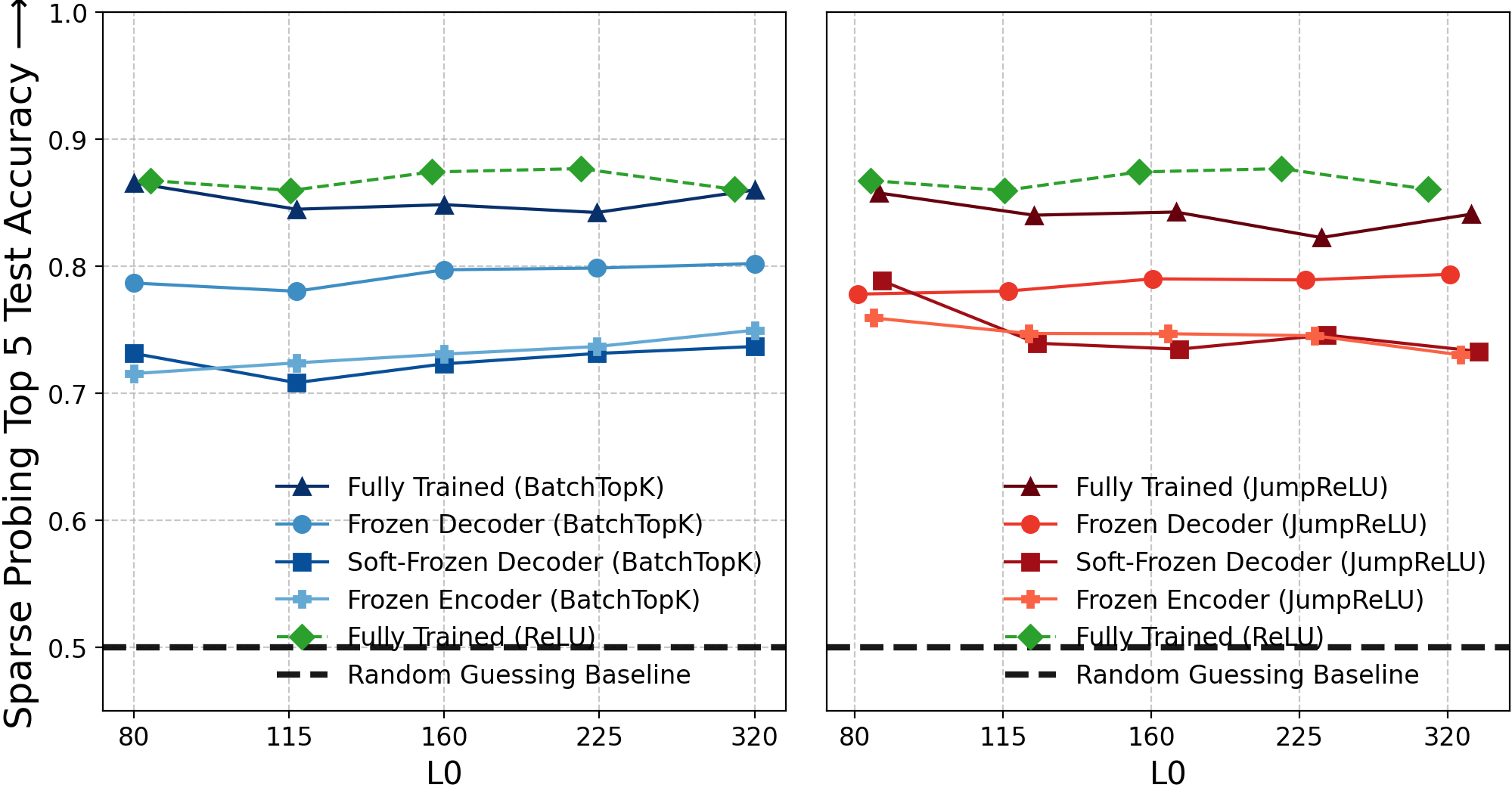
Figure 10: Sparse probing accuracy (top-5), with larger gaps for frozen baselines vs. fully-trained, indicating aggregation limitations.
Theoretical Analysis and Lazy Training Hypothesis
The “Soft-Frozen Decoder” baseline is informed by empirical evidence that SAE decoder weights barely move during training, suggesting a lazy training dynamic à la Chizat et al. (2019). The authors provide mathematical analysis showing that, for high-dimensional spaces and strong cosine constraints, the probability that a random decoder direction aligns with an arbitrary semantic feature decays exponentially—implying competitive performance must arise from efficient recombination rather than genuine feature learning.
Implications for Mechanistic Interpretability
The paper rigorously argues that standard SAE evaluation practices (reconstruction, interpretability, probing, causal editing) can be matched by strong randomization baselines, thus failing as evidence for meaningful feature recovery. The findings challenge the current paradigm in dictionary learning for deep interpretability:
- Theoretical: Demonstrates the inadequacy of reconstruction-based objectives for feature alignment; points towards the need for new learning objectives that reward fidelity to true generative features rather than statistical coverage.
- Practical: Advocates for systematic sanity checks (frozen/randomized baselines) as mandatory for validating feature learning in interpretability research; future SAE variants must outperform these baselines for claims about meaningful decomposition.
- Broader Scope: Raises the possibility that purported interpretability breakthroughs (e.g., monosemanticity in scaled LLMs) may be artefacts of chance alignment and the scale of overcomplete dictionaries, not genuine insight into model internals.
The evidence suggests that current SAE design and eval regimes are fundamentally flawed for mechanistic purposes, and that future progress will require objectives or evaluation schemes directly tied to knowledge of true features—potentially via synthetic benchmarks, causal interventions, or integrated contrastive objectives.
Conclusion
The paper provides a comprehensive critical evaluation of SAE-based interpretability, exposing a fundamental disconnect between standard metrics and meaningful feature learning. Strong numerical results—high explained variance, interpretability, probing, and causal editing—can be matched by simple frozen/random baselines, falsifying the proxy assumption underlying current practice. Theoretical analyses corroborate empirical findings, and the work emphasizes the necessity for rigorous, baseline-aware evaluation in future interpretability research. The authors’ baselines are straightforward to implement, establishing a minimal standard that must be overcome for credible claims of interpretability. Without outperforming these sanity checks, SAE-based methods cannot be relied upon to decompose internal mechanisms of large models.
Figure 1: SAE baselines’ competitiveness across evaluation metrics demonstrates the necessity for rigorous randomization comparisons and challenges the interpretation of numerical scores as evidence for meaningful feature learning.