Controlling Your Image via Simplified Vector Graphics
Abstract: Recent advances in image generation have achieved remarkable visual quality, while a fundamental challenge remains: Can image generation be controlled at the element level, enabling intuitive modifications such as adjusting shapes, altering colors, or adding and removing objects? In this work, we address this challenge by introducing layer-wise controllable generation through simplified vector graphics (VGs). Our approach first efficiently parses images into hierarchical VG representations that are semantic-aligned and structurally coherent. Building on this representation, we design a novel image synthesis framework guided by VGs, allowing users to freely modify elements and seamlessly translate these edits into photorealistic outputs. By leveraging the structural and semantic features of VGs in conjunction with noise prediction, our method provides precise control over geometry, color, and object semantics. Extensive experiments demonstrate the effectiveness of our approach in diverse applications, including image editing, object-level manipulation, and fine-grained content creation, establishing a new paradigm for controllable image generation. Project page: https://guolanqing.github.io/Vec2Pix/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
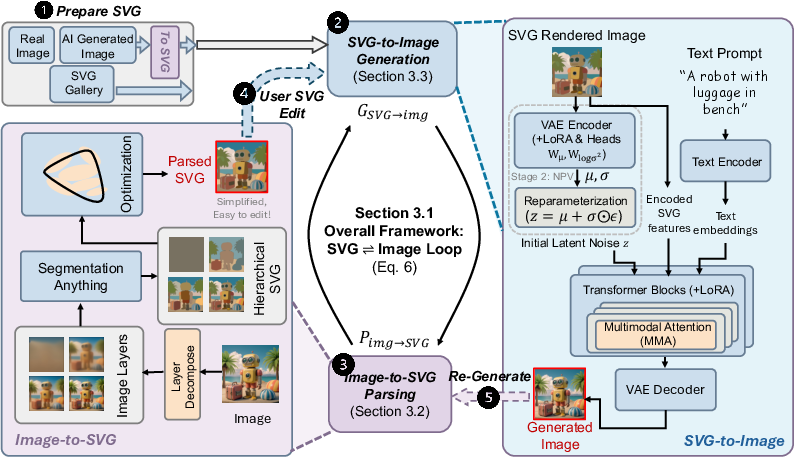
This paper introduces a new way to control how AI creates and edits images. Instead of only using text prompts (which can be vague), it uses simple vector drawings—think clean, editable shapes and lines, like in a digital sticker book—to tell the AI exactly where things should be, what shape they are, and what colors they should be. The system is called Vec2Pix.
What questions are the researchers trying to answer?
The authors focus on three easy-to-understand goals:
- Can we control AI-made images at the “object” level—like changing a hat’s shape, moving a chair, or recoloring a shirt—without messing up the rest of the picture?
- Can we turn a normal photo into a simple, layered drawing (like cut-out shapes) that’s easy to edit, and then turn those edits back into a realistic image?
- Can we get AI to follow these edited drawings closely so the final picture looks both photorealistic and exactly how the user wants?
How does their method work?
Think of their system as a two-way loop between drawings and photos:
- Turning an image into a simple, editable drawing (Image → SVG)
- What’s a vector graphic (SVG)? Instead of pixels, it uses math-defined shapes—smooth curves and lines—like a precise coloring book. You can resize and edit them without blur.
- The system finds meaningful parts (like “head,” “shirt,” “trees,” “background”) and organizes them into layers (like a paper collage). Bigger, simpler shapes go on lower layers; smaller details go on top.
- It uses smart tools to find object boundaries and simplify them into smooth curves called Bézier curves (imagine a rubber band pulled by pegs to outline shapes).
- It uses a fast “differentiable renderer” (a way to convert shapes into images while still allowing fine adjustments) to clean up the shapes so they match the original image, without breaking the layer structure.
- Turning an editable drawing into a realistic image (SVG → Image)
- The system trains a powerful image generator (based on a diffusion/flow model—imagine starting from TV static and gradually “painting in” the picture) to follow both:
- the user’s drawing (the SVG layers), and
- an optional text prompt (like “sunny beach with a red umbrella”).
- Key idea: Noise Prediction from Vectors (NPV). Normally, image generators start from random noise. Here, the model learns to pick a smart “starting static” based on your drawing, so the final image more faithfully follows the shapes and colors you set. It predicts both the average and uncertainty of that starting noise, using lightweight plug-ins (LoRA) to avoid retraining everything.
Because it can go both ways (Image ⇄ SVG), you can:
- generate an image,
- convert it to layered shapes,
- tweak those shapes (move an eye, change a tree’s color),
- and regenerate an updated, photorealistic picture that follows your edits.
What did they find, and why does it matter?
The main results show that Vec2Pix:
- Gives precise control: You can insert, remove, resize, recolor, or reshape objects layer by layer without breaking the background.
- Keeps high quality: The images look realistic and match the edited shapes and colors closely.
- Aligns edits and outputs well: Because the model “understands” your vector shapes and predicts the right starting noise, the final image strongly matches your edits.
- Works for many tasks: Layer-wise generation (build scenes piece by piece), object-level editing, combining real photos with vector drawings, and fixing small errors (like wrong finger count) by adjusting the vector layer and regenerating.
- Is fast to vectorize: Their image-to-SVG step is about 7× faster than a prior layered vectorization method while staying accurate.
- Outperforms other controls: Compared with using edges, depth maps, strokes, or segmentation masks for control, their SVG-based approach generally reconstructs and edits images more faithfully.
- Offers a “control dial”: You can adjust how strongly the model follows the SVG geometry—useful for tricky effects like reflections, smoke, or lighting where you want realism without being “over-locked” to the drawing.
Why is this important?
This research points to a more intuitive future for creative tools:
- For artists and designers: You can edit with familiar shapes and layers (like in vector design apps) and instantly turn those into photorealistic results.
- For students and hobbyists: You don’t need perfect prompts—just draw or tweak simple shapes and colors.
- For production workflows: It connects editable design assets (SVG libraries) with realistic image generation, making mockups, variations, and corrections much faster.
In short, Vec2Pix bridges the gap between simple, editable drawings and high-quality AI images, giving people fine-grained, reliable control over what the AI creates.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of specific gaps and unresolved questions that future work could address to strengthen the Vec2Pix framework and its evaluation.
- Semantic mask initialization depends on SAM and diffusion-prior simplification, but the robustness of this pipeline on cluttered/low-contrast scenes, heavy occlusions, or unusual object categories is not quantified; establish failure mode analysis and confidence-aware selection of masks.
- Hierarchical mask assignment (based on simplification level, mask size, and overlap) is heuristic; develop and evaluate a learning-based parent–child inference that is robust across diverse scenes and object interactions.
- The renderer enforces opacity = 1.0 to preserve exclusivity, precluding semi-transparency, soft shadows, reflections, smoke/fog, and overlapping materials; design an occlusion-aware compositing or z-buffered layering that retains semantics while supporting alpha blending.
- Vector representation restricts regions to closed cubic Bèzier paths with ≤8 segments per side; quantify fidelity loss on fine, high-frequency boundaries (hair, foliage, text, lace) and explore adaptive complexity (dynamic segment counts) with editability guarantees.
- Open stroke/line primitives (outlines, thin wires, typography) are not natively supported in the conditioning representation; add stroke-level vector primitives and evaluate their impact on shape alignment and fine detail synthesis.
- Overlapping and interpenetrating objects are handled via draw order, but automatic z-order inference and self-occlusion handling are not addressed; develop occlusion-aware hierarchical models with learned depth ordering.
- Noise Prediction from Vectors (NPV) encodes rendered SVG images via a VAE, potentially losing explicit vector semantics (control points, topology); investigate encoders operating directly on vector primitives (e.g., graph transformers over paths) and study benefits vs rasterized conditioning.
- NPV predicts only the initial noise (mean/variance) at ; evaluate predicting a time-dependent noise schedule or conditioning the velocity network across timesteps to improve structure adherence without over-constraining appearance.
- Trade-off between structural adherence and physical plausibility is observed (e.g., implausible reflections with strong conditioning); formalize constraints (symmetry, lighting, perspective) or physics-informed priors to prevent non-physical generations.
- Conflict resolution between text prompts and SVG conditioning is not analyzed; quantify and model how to prioritize or reconcile contradictory cues (e.g., textual appearance vs vector geometry) with controllable weights or constraint-based decoding.
- No quantitative metric for “edit compliance” (shape/color/position alignment) beyond global FID/PSNR/SSIM/LPIPS; introduce object-level alignment metrics (IoU/Chamfer distance on masks, boundary displacement, color ΔE) to measure SVG-to-image adherence.
- User-centric evaluation of controllability and usability is missing; conduct task-based studies measuring edit success rate, time-to-edit, number of iterations, and subjective satisfaction vs text-only editors.
- Dataset construction (≈5M LAION 512×512 triplets) lacks quality assessment of parsed SVGs and semantic correctness; measure parsing noise rates and their effects on training, and curate benchmarks with human-verified SVG annotations.
- Comparative baselines are limited and not fully matched for training budgets; add strong controls (e.g., ControlNet variants, state-of-the-art segmentation/stroke-conditioned models, commercial vector-to-image tools) under standardized training/inference settings.
- Resolution and scalability are not evaluated beyond 512×512; benchmark high-resolution (1K–4K) synthesis, multi-scale consistency, and memory/runtime, including impact of vector complexity on latency.
- End-to-end loop latency (image→SVG→edit→image) on commodity hardware is unreported; provide timing breakdowns (vectorization, editing, generation) and memory footprints for interactive use.
- Robustness to domain shift (line art, cartoons, CAD, medical, satellite), thin structures, heavy textures, and extreme occlusions is untested; perform stress tests and propose augmentations or specialized vector primitives for non-photorealistic inputs.
- Closed-loop stability across multiple refinement iterations is not studied; assess whether SVG complexity drifts or artifacts accumulate, and introduce simplicity regularizers or topology-preserving constraints.
- Color/appearance control is limited to fills in rendered SVGs; support gradient fills, patterns, texture maps, and per-region material parameters, and evaluate color fidelity (e.g., ΔE) under complex lighting.
- The covariance loss hyperparameters (patch count/size) are chosen ad hoc; ablate their effects on stability, artifacts, and convergence, and develop principled or adaptive regularization of latent channel correlations.
- Theoretical grounding for aligning NPV’s with structural guidance is lacking; analyze the relation between geometry and noise statistics and derive principled objectives or consistency constraints.
- Integration details for text–SVG multimodal attention (fusion points, LoRA ranks/scales) have limited ablation; systematically study where/how to inject SVG tokens for optimal alignment vs diversity.
- Automatic conditioning strength (vector scale) selection is manual; design estimators that adapt conditioning strength to scene complexity, vector confidence, and desired fidelity/creativity trade-offs.
- Asset-level composition (mixing library SVGs with real images) is shown qualitatively but lacks quantitative harmonization metrics (lighting/color matching, boundary blending); propose measures and blending strategies to avoid seams.
- Generalization to video and multi-view/3D consistency is unexplored; extend to temporal/pose-consistent generation with vector-guided trajectories and evaluate flicker, identity preservation, and geometry stability.
- Data/code/UI release and reproducibility details are missing; provide open resources and standardized editing protocols to facilitate benchmarking and user studies.
- Safety and misuse considerations (e.g., editing identities or sensitive content) are not discussed; incorporate content filters and ethical guidelines for controllable editing.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, organized by sector and grounded in the paper’s methods (hierarchical SVG parsing, efficient Bézier Splatting vectorization, and the Vector-Guided Noise Prediction module).
- Creative production (Advertising, Media, Publishing)
- What: Fine-grained image editing and compositing with per-object, per-layer control (shape, color, position), including artifact removal on localized regions (e.g., fingers, small props).
- Tools/Workflow: “Vec2Pix Editor” plugin for Photoshop/Illustrator/Figma; SVG-to-image microservice API; DAM integration to batch-generate variations from brand-safe SVG templates; vector-scale “knob” to tune conditioning strength.
- Assumptions/Dependencies: Reliable segmentation (SAM), GPU access for inference, brand style guides encoded as SVG layers, licensing-compliant training data.
- E-commerce and product configurators
- What: Generate photorealistic product imagery from parametric SVGs (colorways, minor shape variants), reduce reliance on physical photoshoots, enable instant A/B testing of backgrounds and placements.
- Tools/Workflow: CAD/parametric data → SVG paths → Vec2Pix render → CMS ingestion; per-layer object insertion/removal for accessories.
- Assumptions/Dependencies: Accurate SVG exports from CAD, consistent material/color mapping, GPU-backed rendering for scale.
- Fashion and apparel design
- What: Rapid visualization of pattern placement, colorways, trims, and small silhouette tweaks with controllable layer ordering (e.g., print under/over garment folds).
- Tools/Workflow: Pattern illustrator → hierarchical SVG (top/stitches/prints) → Vec2Pix photorealistic sampling for lookbooks and internal reviews.
- Assumptions/Dependencies: Robust mask hierarchy, fabric/lighting priors from base model; potential manual touch-ups when physics priors conflict with edits.
- Interior design and real estate staging
- What: Layer-wise scene composition (background walls, mid-level furniture, foreground decor), object repositioning, and color/material trials.
- Tools/Workflow: Floor-plan/room mockup → hierarchical SVG layers → text prompt (style/mood) → image; per-layer re-render for quick iterations.
- Assumptions/Dependencies: Good semantic masks for occlusions; consistency of perspective; GPU access for real-time client demos.
- Game development and concept art
- What: Controlled layout-driven environment or character concept art; semantic editing of silhouettes and colors; artifact-free refinement of generated assets.
- Tools/Workflow: Level blockout as SVG (terrain, props) → Vec2Pix scenes; per-object layer trees for rapid iteration; reference-based styling via IP-Adapter-like pipelines alongside SVG guidance.
- Assumptions/Dependencies: Stable multimodal attention fusion (text + SVG), consistent training priors; additional guardrails to avoid over-constraint artifacts.
- UI/UX and software product marketing
- What: Photorealistic device mockups and screenshots composed from vector UI assets; brand-consistent palettes enforced via hierarchical SVG.
- Tools/Workflow: Figma/Sketch SVG export → Vec2Pix render → marketing pages, app store assets; automated palette swaps (layer-level color locks).
- Assumptions/Dependencies: Accurate vector exports of UI; policy guardrails for authenticity and disclosure when images simulate product usage.
- Education (Art and Design instruction)
- What: Interactive learning of vector vs. raster concepts; shape editing that directly produces realistic outcomes; assignment workflows where students edit SVG paths and iterate on photorealistic renderings.
- Tools/Workflow: Classroom IDE integrating SVG editing + Vec2Pix; shared galleries of hierarchical SVG examples.
- Assumptions/Dependencies: Access to curated datasets; institutional GPU resources or cloud credits.
- Synthetic dataset creation for CV tasks
- What: Generate images with aligned semantic masks (from hierarchical SVG), useful for training segmentation and detection models with controllable object configurations.
- Tools/Workflow: Programmatic scene assembly (SVG) → controlled variations → labeled outputs; automated export of mask layers per SVG hierarchy.
- Assumptions/Dependencies: Domain-specific styling needs additional fine-tuning; ensure label alignment when opacity is fixed (as per method).
- Publishing (Children’s books, technical illustration)
- What: Consistent character and scene variations; per-part adjustments (e.g., facial expressions, clothing items); precise color control across editions.
- Tools/Workflow: Character SVG rig → Vec2Pix render; per-layer editorial workflows; version-controlled SVG palettes.
- Assumptions/Dependencies: Editorial QA to ensure realism and appropriateness; provenance tracking for revisions.
- Brand compliance and governance
- What: Guardrail generation where allowed shapes/palettes are enforced via SVG layers; automated rejection of off-brand edits at render time.
- Tools/Workflow: “Brand Guardrails” service that validates SVG trees before rendering; logging of SVG edits for audit.
- Assumptions/Dependencies: Corporate DAM integration; policy definitions mapped to layer constraints.
- Photo retouching and artifact repair (Daily life and pros)
- What: Clean-up of small defects in AI-generated or real images by converting local regions to SVG paths and re-rendering with precise geometry and color control.
- Tools/Workflow: Light-weight “De-artifact” tool: Image → local SVG mask → edit curve/color → Vec2Pix re-render.
- Assumptions/Dependencies: User familiarity with minimal SVG editing; fast local inference.
- Marketing analytics (A/B testing imagery)
- What: Systematic generation of visual variants strictly controlled via SVG (object placement, sizes, colors) to isolate causal effects on CTR/conversion.
- Tools/Workflow: Variant generator that sweeps SVG parameters; analytics loop with DAM and campaign platform.
- Assumptions/Dependencies: Reliable mapping from SVG changes to meaningful visual deltas; data governance for synthetic imagery.
Long-Term Applications
These applications require further research, scaling, or development (e.g., domain adaptation, temporal consistency, compliance frameworks, or real-time performance).
- Video generation and editing with temporal SVG layers
- What: A timeline-aware SVG sequence enabling object-level control across frames (positions, shapes, colors), with temporal consistency and physics-aware priors.
- Tools/Workflow: SVG-keyframed video editor → Vec2Pix video renderer with cross-frame coherence modules.
- Assumptions/Dependencies: Temporal diffusion/flow extensions, motion-aware NPV, computational scaling; robust mask tracking.
- 3D and CAD-to-photorealistic marketing pipelines
- What: Bridge parametric CAD surfaces to controlled 2D photorealistic renders via SVG projections (UV/editor layers), later extended to neural rendering.
- Tools/Workflow: CAD → UV unwrap → SVG layer maps → Vec2Pix texture renders → product visuals.
- Assumptions/Dependencies: Projection consistency, material priors; potential integration with NeRF/SDF methods.
- Domain-specific healthcare illustration and patient education
- What: Precise, customizable medical illustrations and patient materials generated under strict semantic control (layered anatomy structures).
- Tools/Workflow: Medical SVG libraries (organs, systems) → controlled renderings for communication and training.
- Assumptions/Dependencies: Clinical validation, privacy and ethical review; domain-specific model tuning.
- Robotics and autonomous systems dataset synthesis (complex scenes)
- What: Programmatic generation of photorealistic road or household scenes with granular masks for training perception models, including rare events simulated at layer level.
- Tools/Workflow: Scenario DSL → hierarchical SVG → Vec2Pix render + mask export; policy-driven constraints (e.g., safety-critical event frequency).
- Assumptions/Dependencies: Robust realism under varied weather/lighting; domain adaptation to reduce sim-to-real gap.
- Collaborative cloud platform for controllable generative pipelines
- What: Multi-user SVG editing with role-based permissions (brand/creative/legal), audit trails, and provenance preserving C2PA metadata in outputs.
- Tools/Workflow: Cloud IDE with SVG tree, text prompts, references, NPV controls; comprehensive revision history.
- Assumptions/Dependencies: Standardization (C2PA), storage and compute orchestration, legal policies for synthetic content.
- Standards and policy frameworks for editable AI imagery
- What: Governance around disclosure, watermarking, and edit provenance when precise element-level modifications are possible; enforcement of acceptable content edits via layer constraints.
- Tools/Workflow: Policy engines that validate SVG layers/palettes; content authenticity pipelines embedding edit logs and signatures.
- Assumptions/Dependencies: Regulator and industry alignment; interoperable metadata standards.
- Real-time and mobile deployment
- What: On-device controllable generation from compact hierarchical SVGs; instant edits in consumer apps (e.g., social or AR filters).
- Tools/Workflow: Distilled Vec2Pix variants; hardware-aware rasterization (Bezier Splatting on mobile GPU); low-latency NPV.
- Assumptions/Dependencies: Model compression, latency budgets; UX simplifications for non-expert users.
- New academic benchmarks and metrics for element-level controllability
- What: Datasets and metrics that evaluate geometry/color alignment, layer-wise edit fidelity, and physical plausibility under SVG-driven constraints.
- Tools/Workflow: Public triplets (image, SVG, text); standardized protocols for edit localization and evaluation; ablation suites for NPV impact.
- Assumptions/Dependencies: Community adoption; fair-use licensing for data.
- Textures and materials authoring for 3D pipelines
- What: Precise texture atlas generation where editable SVG regions map to UV islands; controlled variation for material libraries.
- Tools/Workflow: 3D UV → SVG overlays → Vec2Pix texture baking; integration with DCC tools (Blender, Maya).
- Assumptions/Dependencies: Accurate UV correspondence; material realism; extended training with PBR priors.
- Cartography and data storytelling
- What: Stylized, photorealistic map scenes or infographics composed from vector primitives with strict semantic layering (roads, water, terrain, labels).
- Tools/Workflow: GIS vector export → hierarchical SVG → controlled rendering; thematic variations by swapping palettes or layer order.
- Assumptions/Dependencies: Domain adaptation for satellite/terrain realism; label legibility and accessibility compliance.
General assumptions and dependencies across applications
- Model availability and performance: Access to the trained Vec2Pix (Flux.1-dev + LoRA + NPV), GPUs for interactive throughput, and the Bézier Splatting renderer.
- Semantic initialization quality: SAM and diffusion priors must provide robust masks; fixed opacity (as used) preserves hierarchy but may limit transparent/overlapping effects.
- Data governance and bias: LAION-derived priors may introduce distribution biases; domain-specific fine-tuning may be necessary.
- Physical consistency trade-offs: Strong structural adherence (via NPV and vector-scale) can occasionally reduce realism; careful tuning is required per scenario.
- User expertise: Basic familiarity with vector editing improves outcomes; UI abstractions can reduce the learning curve for non-experts.
Glossary
- Alpha blending: A compositing technique that combines colors and opacities of overlapping layers; in this context, changing opacity can break semantic exclusivity of regions. Example: "the standard alpha blending formulation permits opacity manipulation, which may corrupt the exclusivity of semantic regions"
- Bézier curves: Parametric curves defined by control points, widely used to represent smooth shapes and boundaries in vector graphics. Example: "Bézier curves are widely used for representing smooth boundaries."
- Bézier Splatting: A fast, differentiable rendering approach that treats Bézier primitives as splats for optimization and rasterization. Example: "we adopt Bézier Splatting~\cite{liu2025b} as an efficient differentiable renderer."
- Canny edges: Edge maps produced by the Canny edge detector, often used as structural conditioning for image generation. Example: "including Canny edges, depth maps, strokes"
- ControlNet: A diffusion model extension that injects spatial condition features to control generation. Example: "spatially guided methods such as ControlNet~\citep{zhang2023adding}"
- Covariance loss: A regularizer that penalizes cross-channel correlations to encourage independence in learned latent statistics. Example: "and a covariance loss $\mathcal{L}_{\text{cov}$ to encourage spatially independence across latent channels:"
- DiT: A Diffusion Transformer architecture that treats image latents as tokens for transformer-based denoising. Example: "adopting a DiT~\citep{peebles2023scalable}-style design where latent patches are treated as tokens."
- DiffVG: A differentiable vector graphics renderer enabling gradient-based optimization of vector primitives. Example: "differentiable vector graphics rendering (DiffVG~\citep{li2020differentiable} and Bézier Splatting \citep{liu2025b})"
- Differentiable rasterization: Rendering that is differentiable with respect to scene parameters, enabling gradient-based fitting and learning. Example: "which pioneered differentiable rasterization and enabled gradient-based optimization of arbitrary Bézier curves"
- Douglas--Peucker: A polygon simplification algorithm that reduces points while preserving shape. Example: "we simplify the polygon (Douglas--Peucker), and if it remains overly complex, we split it at the longest diagonal"
- FID: Fréchet Inception Distance; a metric that compares distributions of real and generated images for perceptual quality. Example: "we measure reconstruction quality with FID~\citep{heusel2017gans}, PSNR~\citep{hore2010image}, SSIM~\citep{wang2004image}, and LPIPS~\citep{zhang2018unreasonable}"
- FLUX.1-dev: A latent rectified flow transformer model used as the base text-to-image generator. Example: "Our Vec2Pix builds on FLUX.1-dev~\citep{flux2024}, a latent rectified flow transformer for text-to-image generation."
- Flow matching: A training objective for flow models where a network learns the velocity field connecting noise and data distributions. Example: "the flow matching loss $\mathcal{L}_{\text{FM}$ from Eq. \ref{eq:fm_loss}"
- Flow models: Generative models that learn continuous dynamics (velocity fields) transforming noise into data. Example: "Flow models~\citep{liu2022flow,lipman2022flow,bortoli2022riemannian} parameterize the velocity field ."
- GroupNorm: A normalization technique that normalizes features over groups of channels, improving training stability. Example: "a GroupNorm layer followed by a SiLU activation"
- IP-Adapter: An auxiliary cross-attention adapter for diffusion models to better preserve identity or reference image features. Example: "IP-Adapter~\citep{ye2023ip} (cross-attention with an auxiliary encoder) strengthens identity preservation"
- KL loss: Kullback–Leibler divergence term used to regularize latent distributions toward a standard normal prior. Example: "the KL loss $\mathcal{L}_{\text{KL}$ to minimize the divergence from the standard normal distribution"
- LPIPS: Learned Perceptual Image Patch Similarity; a deep feature-based metric for perceptual similarity. Example: "LPIPS~\citep{zhang2018unreasonable}"
- LoRA: Low-Rank Adapters that efficiently fine-tune large models by injecting low-rank updates into selected layers. Example: "We apply LoRA~\citep{hu2022lora} to the transformer blocks of the base model"
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert subnetworks to improve capacity and specialization. Example: "Mixture-of-Experts (MoE) paradigm."
- Multimodal attention: Attention mechanism that jointly processes and fuses information from multiple modalities (e.g., text and image). Example: "These two branches are fused through multimodal attention, allowing the model to jointly attend to visual and textual cues~\citep{tan2025ominicontrol}."
- Noise Prediction from Vectors (NPV): A module that predicts the initial noise distribution (mean and variance) conditioned on SVGs to improve alignment. Example: "We then propose Noise Prediction from Vectors (NPV) as the second stage"
- ODE: Ordinary Differential Equation; here, solved to transform noise into data latents along a learned velocity field. Example: "Sampling starts from Gaussian noise by solving the ODE"
- Prodigy optimizer: An optimization algorithm used for training with features like safeguard warmup and bias correction. Example: "We employ the Prodigy optimizer with safeguard warmup and bias correction enabled"
- PSNR: Peak Signal-to-Noise Ratio; a reconstruction metric measuring fidelity relative to ground truth. Example: "PSNR~\citep{hore2010image}"
- Reparameterization trick: A method to enable backpropagation through stochastic nodes by expressing sampling as a deterministic function plus noise. Example: "via the reparameterization trick:"
- Rectified flow: A flow-based generative modeling variant with improved training dynamics used in FLUX. Example: "a latent rectified flow transformer"
- Segment Anything (SAM): A foundation model for generic object segmentation used to obtain semantic masks. Example: "followed by SAM to generate semantic masks for each layer"
- SiLU: Sigmoid Linear Unit; an activation function also known as the Swish function. Example: "a GroupNorm layer followed by a SiLU activation"
- SSIM: Structural Similarity Index Measure; a perceptual metric comparing structural similarity between images. Example: "SSIM~\citep{wang2004image}"
- UniControl: A unified diffusion framework that handles diverse spatial controls under a single model. Example: "UniControl~\citep{qin2023unicontrol} further unifies diverse spatial conditions under a Mixture-of-Experts (MoE) paradigm."
- Variational autoencoder (VAE): A probabilistic autoencoder that encodes images into a latent distribution and reconstructs them via a decoder. Example: "by a Variational autoencoder (VAE) encoder "
- Velocity field: A vector field that defines the instantaneous direction and speed of transformation from noise to data in flow models. Example: "parameterize the velocity field ."
Collections
Sign up for free to add this paper to one or more collections.

