FactorMiner: A Self-Evolving Agent with Skills and Experience Memory for Financial Alpha Discovery
Abstract: Formulaic alpha factor mining is a critical yet challenging task in quantitative investment, characterized by a vast search space and the need for domain-informed, interpretable signals. However, finding novel signals becomes increasingly difficult as the library grows due to high redundancy. We propose FactorMiner, a lightweight and flexible self-evolving agent framework designed to navigate this complex landscape through continuous knowledge accumulation. FactorMiner combines a Modular Skill Architecture that encapsulates systematic financial evaluation into executable tools with a structured Experience Memory that distills historical mining trials into actionable insights (successful patterns and failure constraints). By instantiating the Ralph Loop paradigm -- retrieve, generate, evaluate, and distill -- FactorMiner iteratively uses memory priors to guide exploration, reducing redundant search while focusing on promising directions. Experiments on multiple datasets across different assets and Markets show that FactorMiner constructs a diverse library of high-quality factors with competitive performance, while maintaining low redundancy among factors as the library scales. Overall, FactorMiner provides a practical approach to scalable discovery of interpretable formulaic alpha factors under the "Correlation Red Sea" constraint.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about FactorMiner, a smart computer “agent” that helps discover new, simple formulas (called alpha factors) that might predict short‑term price moves in financial markets. Think of it like an organized treasure hunter: it uses a toolbox of testing skills, keeps a memory of past attempts, and learns over time to avoid dead ends and focus on promising ideas.
What questions did the researchers ask?
They asked:
- How can we automatically find many useful, easy‑to‑understand trading signals (formulas) in a huge search space?
- How can we stop finding “more of the same” signals that are just copies of each other?
- Can an agent remember what worked (and what didn’t) so it gets better over time instead of repeating mistakes?
How did they do it?
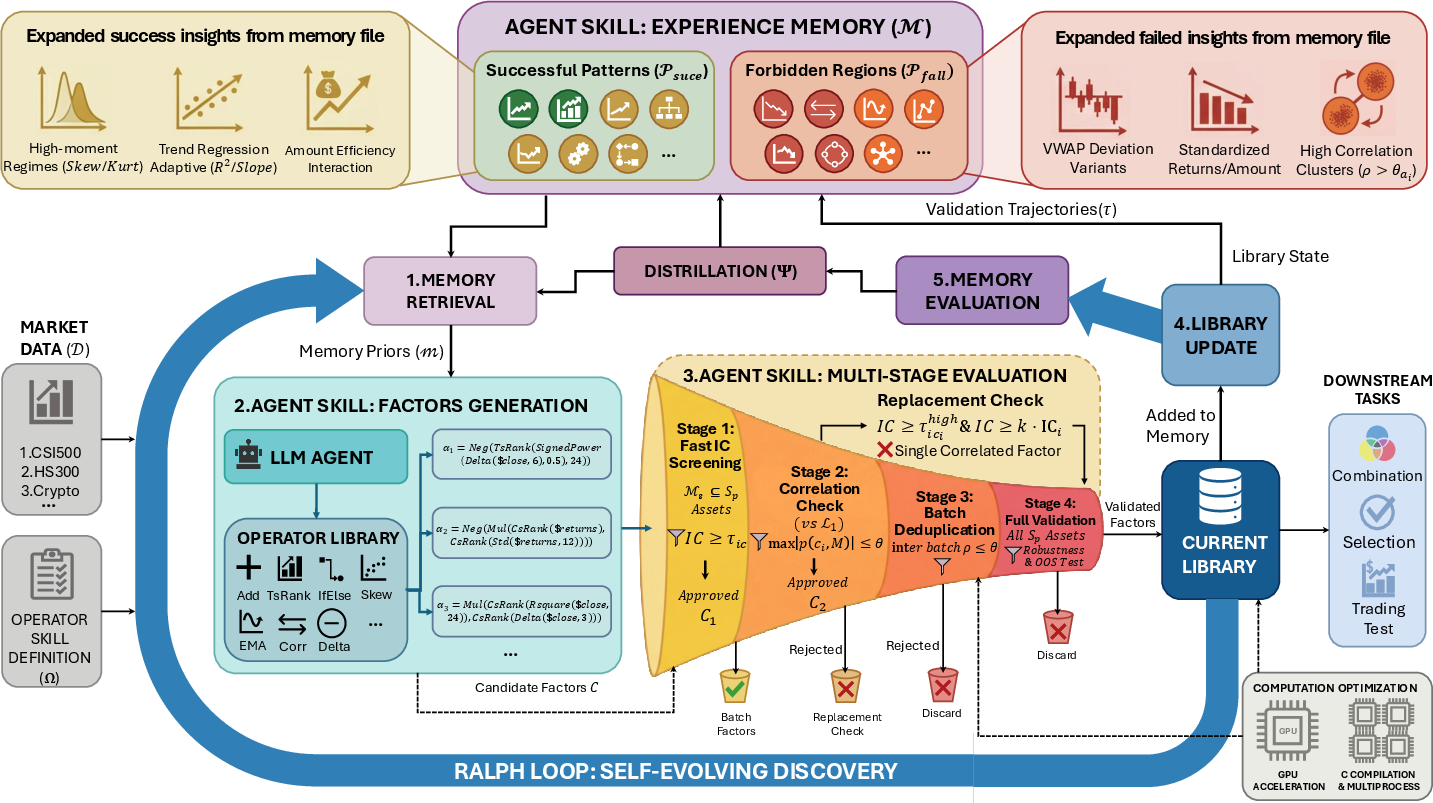
The researchers built a self‑improving “agent” with two big ideas: a toolbox of skills and an experience memory.
- Skills toolbox (Modular Skill Architecture)
- Imagine cooking with a set of reliable kitchen tools and a tasting station. The agent has:
- A large set of safe, fast “operators” (like building blocks) to assemble formulas from market data (such as price and volume).
- A strict testing pipeline that checks each formula’s quality and removes ones that are too similar to the ones already discovered.
- This keeps the process reliable and transparent, rather than a mysterious black box.
- Experience memory
- Like a journal that records what recipes turned out tasty and which ones were flops.
- It stores:
- Successful patterns: templates that often make good signals.
- Forbidden regions: patterns that usually fail or are too similar to what’s already in the library.
- Next time, the agent starts closer to good ideas and avoids known dead ends.
- The four-step “Ralph Loop”
- You can think of the agent’s work cycle as:
- 1) Retrieve: Look up helpful memories.
- 2) Generate: Propose new formulas guided by those memories.
- 3) Evaluate: Test them quickly and rigorously.
- 4) Distill: Save the lessons—what to try more of, what to avoid.
- This loop helps the agent learn “how to search,” not just “what to find.”
- Building a diverse library
- The agent keeps a growing library of formulas. Before adding a new one, it checks how similar it is to the existing ones (using correlation—how much two signals move in similar ways). New entries must be good and not too similar to what’s already there.
- Fast computation
- They use clever coding, multiple processes, and GPUs (graphics processors) to test lots of ideas quickly—like running many taste tests in parallel.
Helpful plain‑language definitions:
- Alpha factor: a formula that turns past market data into a score predicting the next move (for example, the next 10 minutes).
- Information Coefficient (IC): a number that tells how well the factor’s ranking of assets matches the actual ranking of their future returns (higher is better).
- Correlation: a measure of similarity. If two factors give very similar signals, they’re highly correlated, which is not useful when you want variety.
What did they find and why does it matter?
Here’s what their experiments showed across multiple markets (Chinese A‑shares like CSI500/1000/HS300, and cryptocurrencies):
- Better signals, less copying
- FactorMiner found many high‑quality factors that were not just repeats of each other. This keeps the library fresh and useful, rather than cluttered with look‑alikes.
- Learns from experience
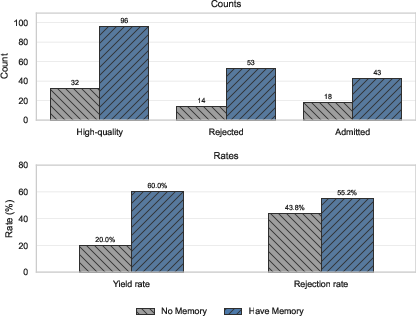
- With memory turned on, the agent produced more good candidates and filtered out more redundant ones compared to a version without memory. In other words, it explored smarter, not just harder.
- Works across different markets
- The factors discovered on stocks also worked reasonably well on crypto, which trades 24/7 and has different rules. This suggests the agent is learning patterns that are more general and not overfitted to one market.
- Simple combinations already strong
- Just combining the discovered factors with simple rules often performed well, meaning the individual signals were already robust and complementary.
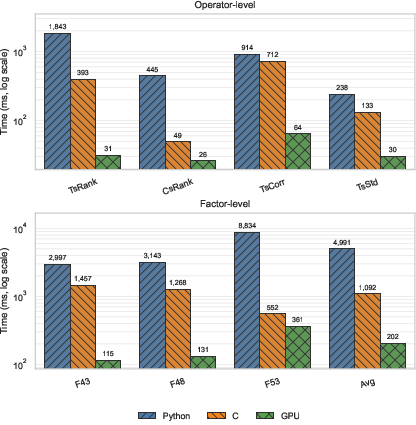
- Much faster testing
- GPU speedups made the “try‑and‑test” loop fast enough to search at scale, turning hours of computation into minutes.
Why it matters:
- In finance, having many diverse, understandable signals is valuable for research, risk control, and regulation. This system produces interpretable (formula-based) signals, not black‑box predictions, which helps humans check the logic behind them.
What’s the bigger impact?
- For researchers and practitioners: FactorMiner is a practical way to continuously discover and maintain a library of clear, useful trading signals while avoiding duplicates.
- For the broader field: It shows how AI agents with tools and memory can tackle huge search spaces, learn from experience, and produce interpretable results—an idea that can be used beyond finance.
- Future directions: The authors plan to add transaction‑cost‑aware tests, expand to more assets and time scales, and keep memory updated in changing markets, helping the agent stay useful as market conditions evolve.
In short, the paper introduces a smart, memory‑driven system that finds many good, different, and understandable trading formulas efficiently—making ongoing discovery faster, less repetitive, and more reliable.
Knowledge Gaps
Unresolved Gaps and Open Questions
The paper advances agent-based formulaic alpha discovery but leaves several concrete gaps that future work can address:
- Out-of-sample economic performance: No transaction-cost-aware backtesting (fees, slippage, market impact), turnover, capacity/crowding analysis, drawdown, or Sharpe/Sortino of portfolios constructed from the mined factors.
- Limited time span: Training on 2024 and testing on 2025 only; no multi-year, multi-regime evaluation, rolling/out-of-time tests, or stability analysis across market stress periods.
- Label horizon scope: Only next 10-minute open-to-close returns are considered; no exploration of alternative horizons (e.g., 30/60 min, end-of-day, multi-day) or horizon-specific factor robustness.
- Multiple testing control: The large-scale search lacks statistical corrections (e.g., SPA, White’s Reality Check, Benjamini–Hochberg) and p-value reporting to mitigate data snooping and false discoveries.
- Orthogonality design choices: The correlation budget and choice of Spearman cross-sectional correlation for redundancy are not stress-tested; impact of alternative dependence measures (partial correlation, Kendall’s , distance correlation, tail dependence) and dynamic/lagged correlations remains unexplored.
- Replacement mechanism sensitivity: Stage 2.5 “replacement check” uses a margin but provides no sensitivity analysis for , library churn dynamics, or downstream effects on stability and diversity as replacements accumulate.
- Fast screening bias: Stage 1 screens candidates on a reduced asset subset ; no analysis of screening-induced selection bias, missed signals, or calibration of vs. final library quality.
- Memory operators and retrieval: The Formation/Evolution/Retrieval operators are described qualitatively; no quantitative ablations on each operator’s contribution, memory capacity constraints, conflict resolution, or retrieval accuracy vs. alternatives (e.g., embedding-based retrieval, structured rule stores).
- Memory representation: Experience is stored as natural-language templates; robustness to LLM parsing errors, ambiguity, and drift is not evaluated, nor are structured symbolic formats or programmatic constraints compared.
- Theoretical characterization: No formal analysis of “probability measure contraction” over the program space or sample complexity/efficiency gains attributable to memory-guided search (e.g., bounds on exploration efficiency in the “Correlation Red Sea”).
- Decay and non-stationarity: No temporal decay analysis of factor IC/ICIR within 2025 (e.g., monthly breakdowns), nor online/streaming memory updates under regime shifts or adversarial market adaptation.
- Cross-market microstructure: Crypto vs. A-shares differences (24/7 trading, price limits, short-sale constraints, suspensions) are not modeled; factor transfer robustness, adaptations for market-specific frictions, and per-market operator tailoring are untested.
- Data hygiene and biases: Handling of survivorship bias, corporate actions, reconstitutions, halts/suspensions, outliers, and missing data is not detailed; potential lookahead and leakage controls are not audited.
- Portfolio construction breadth: Only IC-driven ensembles (EW/ICW) and basic learned selection (Lasso/XGBoost) are reported; no evaluation of risk-aware optimizers (e.g., ridge/elastic net with turnover penalties, constrained mean–variance, robust optimization) or transaction-cost-aware selection.
- Interpretability auditing: While formulas are explicit, economic narratives/mechanisms, practitioner audits, and regulatory-aligned documentation for complex nested expressions are not provided.
- Reproducibility: Full release of code, operator implementations, prompts, seeds, and evaluation scripts is not specified; sensitivity to LLM choice (e.g., Gemini 3.0 Flash vs. alternatives), prompting strategies, and randomness is unquantified.
- Operator library scope: The 60+ operator set is curated but not stress-tested; impact of adding/removing operators, operator redundancy, and domain-specific operators (e.g., microstructure/limit-order-book primitives) remains open.
- Backend determinism: Potential numerical discrepancies across Pandas/C/GPU backends (ordering, precision, ties in ranks) are not assessed; reproducibility under parallelization and multi-process execution is not audited.
- Library correlation structure: The orthogonality constraints are enforced pairwise; no exploration of higher-order dependence (e.g., partial correlations within clusters), library pruning strategies, or graph-based methods to manage redundancy.
- Selection on CSI500 only: Top-40 factor selection on CSI500 (2024) is transferred to other universes and crypto; no study of whether universe-specific selection improves performance or avoids unintended biases.
- Robustness to adversarial decay: No analysis of factor crowding, front-running risks, or performance deterioration under adoption by other market participants.
- Memory drift and forgetting: Continual learning trade-offs (stability vs. plasticity), memory pruning, and safeguards against accumulating spurious “forbidden directions” are not characterized.
- Evaluation metrics: Reliance on absolute IC and ICIR; no signed-IC analyses, directional hit ratios, calibration, or distributional diagnostics (e.g., skew/kurt of IC_t) to understand reliability and tail behavior.
- Stage-wise throughput vs. quality: GPU/C speedups are quantified, but the throughput–quality trade-off (e.g., batch sizes, operator latency constraints, real-time mining feasibility) for live deployment is not studied.
- Compliance and ethics in deployment: Concrete risk controls, monitoring, and compliance checks for factor usage in production (given manipulation concerns) are not designed or validated.
- Open library utility: The 110 A-share factor library is released, but licensing, data dependencies, and reproducible pipelines for third-party verification and extension are not documented.
- Generalization beyond intraday: Extension to daily/weekly frequencies, other asset classes (futures, options, bonds), and multi-asset interactions (cross-sectional spillovers) is untested.
- Alternative search paradigms: Comparisons to meta-RL, Bayesian program synthesis, grammar-guided evolutionary search, or constraint-based solvers for symbolic factors are absent.
- Downstream integration: How mined factors integrate with full trading systems (signal smoothing, risk models, execution, hedging, capacity management) and their end-to-end contribution to portfolio outcomes is not assessed.
Glossary
- A-share equities: Mainland China stocks denominated in RMB and traded on domestic exchanges; used as a specific market universe in the study. "For A-share equities, we utilize intraday 10-minute bars of three index universes"
- Alpha factor: A predictive signal intended to capture excess returns (alpha) in quantitative trading. "Formulaic alpha factor mining is a critical yet challenging task in quantitative investment"
- Backtesting: Simulating a strategy on historical data to assess performance before deployment. "transaction-cost-aware backtesting"
- Catastrophic forgetting: The tendency of a model to lose previously learned information when trained on new data or tasks. "retain knowledge without catastrophic forgetting"
- Correlation budget: A predefined threshold that limits allowable correlation between factors to ensure diversity. "θ is the correlation budget."
- Correlation Red Sea: The phenomenon where growing correlation constraints make it increasingly hard to find new orthogonal factors. "under the "Correlation Red Sea" constraint"
- Cross-sectionally standardized: Normalized across assets at each time to make signals comparable within a cross-section. "cross-sectionally standardized realized factor signals"
- CSI 1000: A Chinese stock index of small- and mid-cap stocks used as a dataset. "the CSI 500 and CSI 1000 index constituents"
- CSI 500: A Chinese stock index of mid-cap stocks used as a dataset. "the CSI 500 and CSI 1000 index constituents"
- Equal-weight (EW): A portfolio or ensemble that assigns the same weight to each component. "EW and ICW (weights/signs determined on 2024)"
- Experience memory: A structured store of past outcomes and patterns that guides future exploration by the agent. "we introduce experience memory that enables the agent to self-evolve through accumulated knowledge"
- Factor library: The curated set of admitted alpha factors maintained with diversity constraints. "as the factor library grows and correlation constraints tighten"
- Factor mining: The automated discovery of candidate alpha formulas from an operator set and data. "formulaic factor mining as a task for self-evolving AI agents"
- Forbidden regions: Parts of the search space known to lead to redundant or invalid factors, avoided in future exploration. "forbidden regions (factor families with high mutual correlation to existing library members)"
- HS300: A Chinese large-cap stock index used as a dataset. "and the HS300 index constituents"
- IC (Information Coefficient): The cross-sectional Spearman rank correlation between a factor signal and subsequent returns. "Information Coefficient (IC), defined as the cross-sectional Spearman rank correlation"
- IC screening: A fast initial filter that selects candidates whose IC exceeds a threshold. "Stage 1: Fast IC screening"
- IC thresholds: Minimum IC levels used as screening criteria in the validation pipeline. "with IC thresholds and correlation checks"
- IC-weighted combination (ICW): An ensemble where factor weights are proportional to their IC or related statistics. "EW and ICW (weights/signs determined on 2024)"
- Information Ratio (ICIR): Stability measure computed as the mean IC divided by its standard deviation over time. "Information Ratio (ICIR)"
- Intraday: Within the trading day; refers to high-frequency data such as 10-minute bars. "intraday 10-minute bars"
- Kurt (Kurtosis): A higher-order moment measuring tail heaviness; used for regime switching. "Skew/Kurt"
- Liquidity-constrained reversals: Return patterns where short-term price reversals are influenced by liquidity conditions. "liquidity-constrained reversals"
- Market microstructure: The mechanisms and frictions of how markets operate at high frequency. "market microstructure inefficiencies"
- Non-stationary markets: Markets whose statistical properties change over time, requiring adaptive methods. "non-stationary markets"
- Open-to-close price change ratio: The percentage change from the market open to close within a bar or day; used as prediction target. "open-to-close price change ratio"
- Orthogonal Library Synthesis: The objective of building a high-quality factor set under low-correlation (orthogonality) constraints. "Objective: Orthogonal Library Synthesis."
- Orthogonality constraints: Requirements that new factors remain sufficiently uncorrelated with existing ones. "while maintaining orthogonality constraints."
- Partial correlation: A dependence measure controlling for the influence of other variables. "partial correlation"
- Rsquare: Operator measuring goodness-of-fit (coefficient of determination) in time-series regressions. "via Rsquare/Slope/Resi"
- Sharpe ratio: Risk-adjusted performance metric defined as mean return divided by return volatility. "Sharpe ratio"
- Skew (Skewness): A higher-order moment measuring asymmetry of a distribution; used for regime switching. "Skew/Kurt"
- Spearman rank correlation: A nonparametric correlation measure based on ranked data. "Spearman rank correlation"
- Tool hallucination: LLM mis-calling or fabricating API/tool outputs; mitigated by grounding and proper tool schemas. "reduce tool hallucination"
- TsRank: An operator that computes ranks over a rolling time window (time-series rank). "TsRank: 1,843ms (Pandas) → 393ms (C) → 31ms (GPU)"
- VWAP (Volume-Weighted Average Price): Average price weighted by traded volume over a period; a common reference price. "VWAP"
- VWAP Deviation: A family of factors measuring deviations from VWAP; often redundant with existing signals. "VWAP Deviations"
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now by leveraging the paper’s released factor library, the skill-based mining pipeline, and the memory-guided search paradigm.
- Interpretable alpha discovery and library maintenance
- Sectors: Finance (quant funds, prop trading, asset managers), Software (quant research platforms)
- Use case: Mine new formulaic intraday factors and maintain an orthogonal factor library under correlation budgets; apply the replacement rule to upgrade weak factors while controlling redundancy.
- Potential tools/workflows:
- “Factor Explorer” module built on the modular skill (operator library + multi-stage validation + correlation checks).
- Automated admission pipeline with library-level diagnostics (pairwise heatmaps, Avg |ρ|, replacement events).
- Assumptions/dependencies: High-quality intraday data; reliable Spearman-IC/ICIR evaluation; correlation threshold design; governance for model changes and audit logs.
- Rapid cross-market factor screening
- Sectors: Finance
- Use case: Port vetted factor templates to new markets (A-shares → Crypto) using configuration-based reparameterization; triage performance via the same skill and admission criteria.
- Potential tools/workflows: Market “profiles” (feature fields, liquidity filters, universes) to reuse operators; batch screening and cross-market scorecards.
- Assumptions/dependencies: Market-specific data fields and microstructure differences; re-tuned thresholds; survivorship and look-ahead bias controls.
- Compliance-ready, auditable signal research
- Sectors: Finance, RegTech
- Use case: Prefer interpretable formulaic signals for auditability and regulatory reviews compared to black-box models.
- Potential tools/workflows: Versioned formula registry; evaluation reports with IC/ICIR, rejection reasons, and memory-based “forbidden directions.”
- Assumptions/dependencies: Internal model risk policies; documentation standards; sign-off workflow; periodic reviews under changing market regimes.
- Compute-efficient research acceleration
- Sectors: Finance, Software/Platforms
- Use case: Reduce end-to-end factor evaluation time via GPU-accelerated operators and C-compiled backends; enable larger candidate batches and faster Ralph Loop iterations.
- Potential tools/workflows: Operator runtime registry with backend selection (Pandas/C/GPU); multi-process batch evaluation; throughput dashboards.
- Assumptions/dependencies: Access to GPUs or optimized CPU nodes; reproducible operator implementations; monitoring for numerical edge cases.
- Team knowledge capture to reduce redundant exploration
- Sectors: Finance (quant R&D), Software (MLOps/knowledge management)
- Use case: Persist “recommended” and “forbidden” factor families in a shared memory to avoid repeatedly rediscovering correlated/low-yield regions.
- Potential tools/workflows: Memory KB (natural-language templates + canonical examples + rejection reasons); retrieval to condition LLM prompts; change logs of memory evolution.
- Assumptions/dependencies: Clear taxonomy of operator patterns; curation of memory entries; guardrails to avoid over-pruning genuinely novel variants.
- Factor combination baselines for portfolio construction
- Sectors: Finance
- Use case: Use simple ensemble baselines (EW, IC-weighted) with orthogonalized factors as a robust benchmark; compare against learned selection (Lasso/XGBoost).
- Potential tools/workflows: Frozen “Top-K” libraries; cross-year train/test evaluation harness; ensemble-vs-learned selection scorecards.
- Assumptions/dependencies: Out-of-sample validation; turnover constraints; production risk overlays (exposure/sector caps, liquidity filters).
- Academic benchmark and teaching lab
- Sectors: Academia (finance, ML, program synthesis)
- Use case: Reproducible studies of interpretable intraday factors; memory-guided symbolic program synthesis; curriculum modules on agent skills and experience memory.
- Potential tools/workflows: Released 110-factor library; standardized IC/ICIR protocol; ablation exercises (with/without memory).
- Assumptions/dependencies: Access to academic data; course infrastructure; ethical use policies around trading strategies.
- Regulator/research sandbox for microstructure hypothesis testing
- Sectors: Policy/Regulation, Academia
- Use case: Use explicit formulas to test hypotheses about liquidity, reversals, and volatility clustering; examine crowdedness via correlation structure.
- Potential tools/workflows: Stress tests of factor exposures; concentrated-crowding indicators; historical regime analysis using interpretable signals.
- Assumptions/dependencies: Regulatory data access; proper anonymization; careful interpretation (signals ≠ trading recommendations).
- Advanced retail/education tooling
- Sectors: Education, Fintech (advanced retail)
- Use case: Educational interfaces that demystify formulaic factors and orthogonalization; safe paper-trading with interpretable signals.
- Potential tools/workflows: Didactic UIs showing operator trees, IC histories, and redundancy checks; sandbox without live execution.
- Assumptions/dependencies: Strong disclaimers; no live-trading by unsophisticated users; simplified datasets and risk warnings.
Long-Term Applications
The following require further research, scaling, or integration (e.g., online learning, cost/latency awareness, broader assets).
- Live, self-evolving “alpha factory” with online memory
- Sectors: Finance
- Use case: Continuous Ralph Loop in production that adapts memory to non-stationary markets, rotates factors, and prevents crowding via library-level constraints.
- Potential tools/workflows: Streaming evaluation and memory updates; drift/change-point detectors; auto-deprecation of factors; library capacity management.
- Assumptions/dependencies: Robust online validation; transaction cost/latency models; guardrails to avoid overfitting to recent noise.
- Execution- and cost-aware discovery
- Sectors: Finance (HFT, intraday)
- Use case: Integrate transaction-cost analytics (TCA), market impact, and slippage into admission criteria and replacement rules.
- Potential tools/workflows: Cost-adjusted IC/ICIR; turnover-aware constraints; liquidity filters embedded in the skill; post-trade analytics feedback into memory.
- Assumptions/dependencies: High-fidelity tick data; stable execution infrastructure; robust cost models.
- Multi-asset, multi-frequency global deployment
- Sectors: Finance
- Use case: Extend operator sets and configurations across equities, futures, FX, fixed income; harmonize features at different sampling frequencies.
- Potential tools/workflows: Asset-class-specific operator packs; unified feature schema; hierarchical memory conditioned on venue and regime.
- Assumptions/dependencies: Diverse, clean data feeds; cross-venue normalization; latency and calendar heterogeneity handling.
- Factor marketplace and knowledge-sharing consortium
- Sectors: Finance, Data/Model marketplaces
- Use case: Curate and license audited formulaic factors and memory artifacts; offer orthogonality auditing as a service.
- Potential tools/workflows: API for factor discovery, testing, and correlation audits; provenance tracking; usage telemetry and decay monitoring.
- Assumptions/dependencies: IP/licensing frameworks; compliance review; incentives for sharing without revealing sensitive edge.
- RegTech for crowding and systemic risk monitoring
- Sectors: Policy/Regulation, Market infrastructure
- Use case: Monitor convergence of formulaic signals across participants; detect crowded trades and potential flash-risk pockets.
- Potential tools/workflows: Periodic submissions of factor exposures; anonymized correlation/crowding indices; early-warning dashboards.
- Assumptions/dependencies: Regulatory mandates/cooperation; privacy-preserving aggregation; industry standards for factor/exposure reporting.
- Cross-domain “FeatureMiner” for interpretable feature discovery
- Sectors: Healthcare, Energy, Manufacturing, Retail, Software analytics
- Use case: Apply the skill + experience memory paradigm to discover low-redundancy, interpretable features for tabular forecasting/classification under domain-specific operator libraries.
- Potential tools/workflows: Domain-tailored operators (e.g., clinical time-series transforms, load-curve operators); multi-stage validation with domain metrics; memory of forbidden/redundant feature families.
- Assumptions/dependencies: High-quality labeled data; expert-curated operator sets; strict privacy and compliance (HIPAA/GDPR); careful causal/ethical guardrails.
- Agentic scientific discovery for symbolic hypotheses
- Sectors: Scientific research (e.g., materials, climate, neuroscience)
- Use case: Use memory-guided symbolic program synthesis to generate falsifiable, interpretable hypotheses and avoid redundant lines of inquiry.
- Potential tools/workflows: Operator libraries grounded in domain laws; staged validation against simulations/benchmarks; memory capturing successful/failed motifs.
- Assumptions/dependencies: Accurate simulators/benchmarks; expert oversight; reproducibility standards.
- Industry standards for interpretable, auditable factor pipelines
- Sectors: Finance, Policy/Regulation
- Use case: Formalize best practices (operator typing, evaluation thresholds, correlation budgeting, replacement policies) for factor R&D and audit.
- Potential tools/workflows: Reference implementations; conformance tests; audit trails for factor lifecycle management.
- Assumptions/dependencies: Cross-firm collaboration; standard-setting bodies; regulator engagement.
- Education-at-scale for interpretable ML in finance
- Sectors: Academia, Professional training
- Use case: Large-scale courses and certifications on interpretable factor engineering, memory-guided agents, and reproducible evaluation.
- Potential tools/workflows: MOOCs with hands-on labs; open datasets with scaffolding; competitions using standardized protocols.
- Assumptions/dependencies: Sustainable data access; competition governance; ethical trading guidelines.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Data, evaluation, and bias
- Clean, survivorship-bias-free, and latency-corrected data; rigorous out-of-sample and regime-aware testing; careful IC/ICIR interpretation at intraday horizons.
- Infrastructure and compute
- Access to GPUs/optimized CPUs; reproducible operator implementations; orchestration for parallel evaluation; model registry and observability.
- Governance, risk, and ethics
- Compliance and audit requirements; documentation of formula changes; controls against manipulative strategies; privacy protections in cross-domain adaptations.
- Model and memory quality
- Well-typed operator libraries; calibrated thresholds (IC, ρ); high-signal memory entries that don’t over-restrict exploration; periodic memory pruning to prevent ossification.
- Generalization and maintenance
- Continuous monitoring for factor decay; mechanisms for deprecation/replacement; cautious cross-market transfer with localized validation.
Collections
Sign up for free to add this paper to one or more collections.