AnchorWeave: World-Consistent Video Generation with Retrieved Local Spatial Memories
Abstract: Maintaining spatial world consistency over long horizons remains a central challenge for camera-controllable video generation. Existing memory-based approaches often condition generation on globally reconstructed 3D scenes by rendering anchor videos from the reconstructed geometry in the history. However, reconstructing a global 3D scene from multiple views inevitably introduces cross-view misalignment, as pose and depth estimation errors cause the same surfaces to be reconstructed at slightly different 3D locations across views. When fused, these inconsistencies accumulate into noisy geometry that contaminates the conditioning signals and degrades generation quality. We introduce AnchorWeave, a memory-augmented video generation framework that replaces a single misaligned global memory with multiple clean local geometric memories and learns to reconcile their cross-view inconsistencies. To this end, AnchorWeave performs coverage-driven local memory retrieval aligned with the target trajectory and integrates the selected local memories through a multi-anchor weaving controller during generation. Extensive experiments demonstrate that AnchorWeave significantly improves long-term scene consistency while maintaining strong visual quality, with ablation and analysis studies further validating the effectiveness of local geometric conditioning, multi-anchor control, and coverage-driven retrieval.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper introduces AnchorWeave, a new way to make long videos where the camera can move around a scene while everything stays consistent. Think of flying a virtual camera through a house: when you leave a room and come back later, the furniture should still be in the same place and look the same. Many current video AI models forget or drift over time. AnchorWeave keeps a “memory” of what the world looked like before, so it can stay consistent for a long time.
The key questions the authors ask
- How can we keep a video world consistent over long stretches, even as the camera moves a lot?
- Why do methods that stitch together one big 3D model of the scene often break or create “ghosts” and glitches?
- Can we replace that fragile big 3D memory with many small, clean, per-frame “memories,” and then smartly combine them during generation?
How AnchorWeave works (explained simply)
First, a quick idea: a “3D point cloud” is like a bunch of colorful dots in 3D that mark where surfaces are. A “camera pose” says where the camera is and what it’s looking at. A “diffusion model” is an AI art program that turns noisy images into clean ones, step by step, guided by instructions.
Here’s the approach, using everyday analogies:
Why one big 3D scene often goes wrong
- Imagine you’re trying to build a perfect 3D model of a room by gluing together photos taken from many angles. If your camera positions or depths are slightly off, the same wall might be placed in slightly different spots. When you fuse all those photos into one big 3D model, small errors stack up into “ghosts” and noisy edges. If you then render new views from this messy model, your video gets artifacts and drift.
Local memories instead of one big memory
- AnchorWeave keeps many small, per-frame “local memories.” Each memory is just the 3D points captured from a single frame plus the camera’s position for that frame.
- Because each memory comes from a single view, it’s clean and doesn’t suffer from cross-view “double walls” or ghosting.
- Think of it like saving neat, accurate snapshots with depth, rather than one giant, error-prone collage.
Choosing which memories to use (coverage-driven retrieval)
- When you plan the next camera path, you don’t need every old memory—just the ones that help you see what the camera will pass by.
- AnchorWeave picks a small set of the most useful local memories that together “cover” as much of the upcoming view as possible.
- Analogy: If you’re planning a tour through a city, you choose the few photos that best cover the streets you’ll walk next—not every photo you’ve ever taken.
Rendering “anchor videos” and weaving them together
- From the selected local memories, the system renders short “anchor” clips that show what those memories predict along the upcoming camera path.
- However, these anchors may still disagree a bit. So AnchorWeave uses a “multi-anchor weaving controller” to blend them:
- Shared attention across anchors: like putting all tour guides in one room to hear everyone’s input at once and cross-check facts.
- Pose-aware fusion: it gives more weight to anchors captured from camera angles closer to the target view. If a guide took a photo from almost the same angle you’re about to see, trust that guide more.
- The blended result becomes a strong, stable control signal for the diffusion model to generate the final frames.
The long-horizon loop
- The system repeats a simple loop: 1) Update: Turn the newest generated frames into new local memories. 2) Retrieve: Pick the best memories for the next camera segment. 3) Generate: Weave selected anchors and produce the next video chunk.
- This lets the video continue for a long time while staying consistent.
What they found (main results)
- AnchorWeave keeps scenes more consistent over long videos compared to strong existing methods. Objects reappear correctly when revisited; walls and furniture don’t “drift” or change shape.
- Visual quality is high: motion is smoother, and flickering is reduced.
- Using many clean local memories works better than using a single global 3D scene. The paper shows clear gains in standard scores that measure both image quality and consistency.
- The “weaving” matters:
- Pose-guided fusion beats simple averaging of anchors, because it smartly trusts anchors seen from better angles.
- Joint attention across all anchors helps the model combine information and reject bad hints, leading to sharper, more stable results.
- More retrieved anchors generally help, up to a point, because they add complementary views that fill in gaps.
Why this matters
- For creators, this means more reliable camera-controlled videos where scenes feel like real places you can revisit without everything changing or glitching.
- For robotics, AR/VR, and simulation, this helps build steadier “world models” that remember what places look like over time, even with complex camera motion.
- The big idea—prefer many accurate small memories over one fragile big model, and then learn to reconcile them—could inspire better long-term memory designs in other AI systems, not just video.
In short: AnchorWeave trades one noisy global memory for multiple clean local memories, then smartly selects and “weaves” them together during generation. This simple shift leads to more consistent, higher-quality long videos where the world stays put, even as the camera roams.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of gaps and open questions left unresolved by the paper. Each item is phrased to be actionable for future research.
- Robustness to local geometry errors: The method assumes reliable per-frame depth and pose from TTT3R; there is no sensitivity analysis or robustness modeling when local point clouds contain noise, bias, or outlier geometry (e.g., specular surfaces, low-texture areas). How do reconstruction errors propagate through retrieval, rendering, and fusion?
- Confidence-aware retrieval and fusion: Anchor importance is determined by retrieved-to-target relative pose only; visibility, occlusion, and per-anchor geometry confidence are not incorporated. Can per-pixel visibility/confidence maps or uncertainty estimates improve retrieval and fusion weighting?
- Occlusion handling in fusion: The pose-guided weighted sum does not explicitly model occlusions or disocclusions across anchors, which can cause ghosting. Can a visibility-aware, per-pixel gating or compositing strategy reduce artifacts?
- Closed-loop camera alignment: Retrieval is based on planned target camera poses; the method does not correct anchors when the generated trajectory deviates from the target. How can online pose refinement and closed-loop re-retrieval be integrated mid-chunk?
- Coverage metric fidelity: Coverage is computed with coarse FoV overlap filtering and greedy maximization; the paper does not detail how occlusions, depth uncertainty, or scene scale affect coverage estimation. Can more faithful visibility models or probabilistic coverage improve retrieval quality?
- Theoretical guarantees for retrieval: The greedy coverage-driven retrieval is not analyzed for optimality or approximation bounds (e.g., submodular set cover). Is there a principled formulation with provable guarantees under realistic visibility assumptions?
- Memory scalability and management: Storing per-frame local point clouds leads to unbounded memory growth over long horizons. What are effective compression, downsampling, indexing, deduplication, or forgetting policies to bound storage and maintain retrieval speed?
- Retrieval latency and system efficiency: The computational overhead of (i) maintaining many local point clouds, (ii) FoV filtering, (iii) anchor rendering, and (iv) multi-anchor attention/fusion is not measured. What are the trade-offs for interactive use, and how can the pipeline be made real-time?
- Generalization to dynamic scenes: The approach and evaluation focus on static environments; handling moving objects, deformable surfaces, and time-varying lighting is not addressed. How can local memory track and reconcile dynamic geometry?
- Camera intrinsics estimation: The method presumes accurate intrinsics; open-domain inputs typically lack calibration. How sensitive is performance to intrinsics errors, and can intrinsics be estimated online or learned jointly?
- Long-horizon quantitative evaluation: Beyond qualitative examples, there is no quantitative assessment of consistency across very long sequences (e.g., drift metrics, revisit accuracy, cycle-consistency) exceeding the backbone’s native context window.
- Camera control accuracy: The paper does not report explicit metrics for viewpoint tracking error relative to target trajectories (e.g., pose deviation or reprojection error). Can camera-control fidelity be quantified and optimized?
- Effects of chunking parameters: Chunk length D=8 and retrieval frequency are fixed; their impact on consistency, compute, and latency is not studied. What are optimal schedules for different motion regimes?
- Controller scheduling and placement: The controller is injected into the first third of backbone layers and used for the first 90% of denoising steps without ablation. Which layers/denoising schedules maximize performance with minimal overhead?
- Handling missing anchors: Invisible or padded anchors are used to maintain a fixed K, but their effect on training dynamics and inference robustness is not analyzed. Are there better strategies (e.g., dynamic K, learned “no-anchor” tokens)?
- Scaling number of anchors (K): Results are shown up to K=4; scalability, diminishing returns, or instability with larger K are not explored. How does performance and compute scale with K, and can adaptive K be learned?
- Alternative local 3D representations: Only point clouds are used; other local formats (e.g., surfels, Gaussian splats, meshes, neural fields) are unexplored. Which local representation offers the best trade-off between fidelity, speed, and robustness?
- End-to-end geometric learning: Geometry is estimated by a fixed 3D model and used as external memory; there is no end-to-end training to adapt reconstruction to the generator or controller. Can joint training reduce misalignment and improve anchor quality?
- Appearance consistency and photometric drift: The memory is primarily geometric; color/appearance variations across time are not explicitly modeled. Can an appearance memory or color-calibration module reduce photometric drift?
- Duplicate anchors across chunks: Retrieval allows duplicates across chunks, potentially wasting budget and compute; deduplication or diversity constraints are not considered. Can diversity-aware retrieval improve coverage and robustness?
- Memory update reliability from generated frames: Newly generated frames are added to the memory; the risk of compounding hallucinations or pose errors over many iterations is not quantified. Can quality gates, re-scoring, or refinement prevent error accumulation?
- Domain coverage and data scale: Training is on 10K videos from RealEstate10K and DL3DV; generalization to outdoor, crowded, or non-photorealistic domains is only shown qualitatively. What are failure modes in out-of-distribution scenes, and how can training be scaled or diversified?
- Interaction beyond camera control: While the introduction mentions actions and controls beyond camera motion, AnchorWeave is only evaluated for camera trajectories. How can local memory and multi-anchor weaving be extended to action-conditioned or agent-centric video generation?
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods and insights (local geometric memories, coverage-driven retrieval, multi-anchor weaving controller), assuming access to per-frame depth/pose estimation and a modern video diffusion backbone.
- Real estate: world-consistent extended walkthroughs from sparse footage
- Sectors: real estate, media/marketing
- Tools/products/workflows: “AnchorWeave SDK” for MLS platforms to auto-extend listings into longer tours; coverage-driven retrieval selects the most informative past views; multi-anchor conditioning preserves geometry when revisiting rooms; workflow integrates with Matterport-style inputs or standard camera footage
- Assumptions/dependencies: static scenes; reliable per-frame pose/depth (e.g., TTT3R); camera intrinsics or calibration; disclosure/watermarking for synthetic segments; sufficient GPU
- Film/TV and VFX: previsualization and set-consistent B‑roll synthesis
- Sectors: entertainment, VFX, virtual production
- Tools/products/workflows: pre-viz tool that plans and simulates long camera trajectories (dollies/cranes) using multi-anchor weaving to keep set geometry consistent across shots; “AnchorWeave ControlNet” plugin for Unreal/Nuke/Houdini to generate missing B‑roll from rehearsal footage
- Assumptions/dependencies: access to rehearsal or test footage for local memory construction; static or slowly changing sets; alignment to studio pipelines; compute budget
- Game promotion and level flythroughs with precise camera control
- Sectors: gaming, software
- Tools/products/workflows: Unity/Unreal plugin to render long-horizon, camera-controlled trailers from a few in-game captures; coverage-driven retrieval minimizes drift across revisits; multi-anchor controller resists hallucinations in repeating corridors or large arenas
- Assumptions/dependencies: engine integration; assets are mostly static or motion segmented; GPU capacity
- AR/VR tours and educational field trips from sparse captures
- Sectors: education, tourism, cultural heritage
- Tools/products/workflows: generate extended, revisit-consistent tours of museums/campuses from short handheld video; “AnchorWeave Tour Builder” creates segments aligned to target camera paths; supports keyboard-style navigation
- Assumptions/dependencies: scene mostly static; headset/app integration; camera intrinsics; user disclosure that portions are generative
- E‑commerce 360° product videos from a few frames
- Sectors: retail, advertising
- Tools/products/workflows: Shopify/Adobe plugins to produce consistent rotational product videos preserving texture and logo alignment; coverage-driven retrieval avoids drift in repeating rotations
- Assumptions/dependencies: macro product captures yield usable local geometry; strong lighting consistency; clear calibration; labeling requirements for synthetic augmentation
- Robotics perception training: synthetic long-horizon navigation videos
- Sectors: robotics, autonomy
- Tools/products/workflows: dataset augmentation pipeline that generates extended, revisit-consistent scenes for visual navigation/SLAM pretraining; multi-anchor fusion maintains scene layout over long paths
- Assumptions/dependencies: domain gap to real sensors; better results in quasi-static environments; integration with downstream training loops; pose/depth estimation quality impacts fidelity
- Sports broadcast replays with custom camera paths
- Sectors: media, broadcasting
- Tools/products/workflows: post-production tool that reconstructs stadium geometry from multiple broadcast frames, then generates custom flythroughs (e.g., “follow the play then swing back”); pose-aware fusion downweights misaligned anchors
- Assumptions/dependencies: dynamic players introduce non-rigid changes—requires segmentation or motion filters; static field/background helps
- Personal and professional video editing: “return to the same spot” shots
- Sectors: daily life, creator economy
- Tools/products/workflows: consumer editors (Premiere, CapCut) add a “revisit scene” feature to synthesize consistent callbacks to earlier viewpoints; iterative update–retrieve–generate loop produces multiple segments with minimal drift
- Assumptions/dependencies: adequate device/cloud compute; camera parameter estimation; clear labeling to avoid misleading edits
Long-Term Applications
These applications require further R&D, scaling, or systems integration (e.g., dynamic-scene modeling, real-time inference, larger-scale memory management, or policy frameworks).
- Interactive world models for embodied agents and teleoperation
- Sectors: robotics, industrial automation
- Tools/products/workflows: real-time AnchorWeave tightly coupled with SLAM and scene semantics to provide persistent, controllable video worlds for planning, rehearsal, and operator assistance
- Assumptions/dependencies: dynamic objects and non-rigid motion modeling; low-latency inference; synchronization with sensor streams; robust occlusion handling
- City-scale autonomous driving simulators with generative, revisit-consistent worlds
- Sectors: mobility, safety engineering
- Tools/products/workflows: generative simulators that maintain consistent urban geometry across long trajectories and sessions; memory banks keyed by map tiles; multi-anchor fusion extended to multi-agent scenarios
- Assumptions/dependencies: handling traffic dynamics and weather; scalable memory indexing; evaluation against safety metrics; substantial compute/storage
- Enterprise digital twins: persistent generative overlays and scenario testing
- Sectors: manufacturing, energy, facilities
- Tools/products/workflows: AnchorWeave-backed twin that can rewind/fast-forward camera paths, simulate maintenance procedures, and revisit equipment bays with consistent geometry
- Assumptions/dependencies: integration with CAD/BIM and IoT sensors; strict change management in dynamic plants; governance for synthetic scenarios
- Persistent AR cloud and cross-session spatial memory
- Sectors: AR platforms, consumer tech
- Tools/products/workflows: cross-device spatial memory enabling users to re-enter scenes with consistent generative extensions (e.g., “show me the path back to the cafe”); coverage-driven retrieval from shared local geometry caches
- Assumptions/dependencies: privacy-preserving shared memory; device calibration standards; on-device acceleration; robust mapping in crowdsourced environments
- World-aware video editors with timeline navigation and semantic “goto”
- Sectors: creative tools, software
- Tools/products/workflows: editors where users issue commands like “go back to the lobby and pan left” and get consistent generative segments; controller integrates semantic cues with pose signals
- Assumptions/dependencies: multimodal understanding (text/scene semantics); dynamic-scene handling; scalable project memory
- Healthcare and surgical training simulations
- Sectors: healthcare, medical education
- Tools/products/workflows: OR simulations that maintain consistent room geometry, instrumentation layout, and camera paths over long sessions; scenario replay with anchor weaving
- Assumptions/dependencies: modeling of deformable tissues and instruments; regulatory validation; domain-specific datasets; high-fidelity physics
- Forensics, provenance, and policy tooling for high-fidelity synthetic video
- Sectors: policy/regulation, cybersecurity
- Tools/products/workflows: watermarking and provenance pipelines tailored to world-consistent video; standards to label and audit generative revisit segments; detection tools that leverage memory retrieval traces
- Assumptions/dependencies: cross-industry standards; legal mandates for disclosure; balancing privacy with traceability; adversarial robustness
- Academic infrastructure and benchmarks for long-horizon world consistency
- Sectors: academia, open research
- Tools/products/workflows: standardized datasets and metrics (e.g., coverage, revisit fidelity, drift) built around coverage-driven retrieval and multi-anchor fusion; modular repos for ablation across memory designs
- Assumptions/dependencies: community adoption; open implementations; diverse dynamic-scene testbeds; sustained funding and compute access
- Real-time, on-device AnchorWeave for mobile capture and editing
- Sectors: mobile, creator tools
- Tools/products/workflows: compressed backbones, hardware-accelerated retrieval, and controller pruning to achieve interactive generation during capture (e.g., live “revisit shot” assistance)
- Assumptions/dependencies: model distillation/quantization; efficient pose/depth estimation on-device; thermal/power constraints; UX for disclosure
- Multimodal “world OS” for creators and educators
- Sectors: creative industries, education
- Tools/products/workflows: platform that unifies spatial memory (video), narrative (text), and interaction (keyboard/actions), enabling long-form, consistent experiences (virtual labs, historical reconstructions)
- Assumptions/dependencies: robust alignment across modalities; content governance; accessibility and curriculum integration
Glossary
- 3D VAE: A spatiotemporal variational autoencoder used to encode video into latent features for diffusion models. "each retrieved anchor video is first encoded into latent features using the same 3D VAE as the backbone diffusion model."
- Ablation study: An experimental analysis where components are removed or altered to assess their individual contributions. "Ablation study."
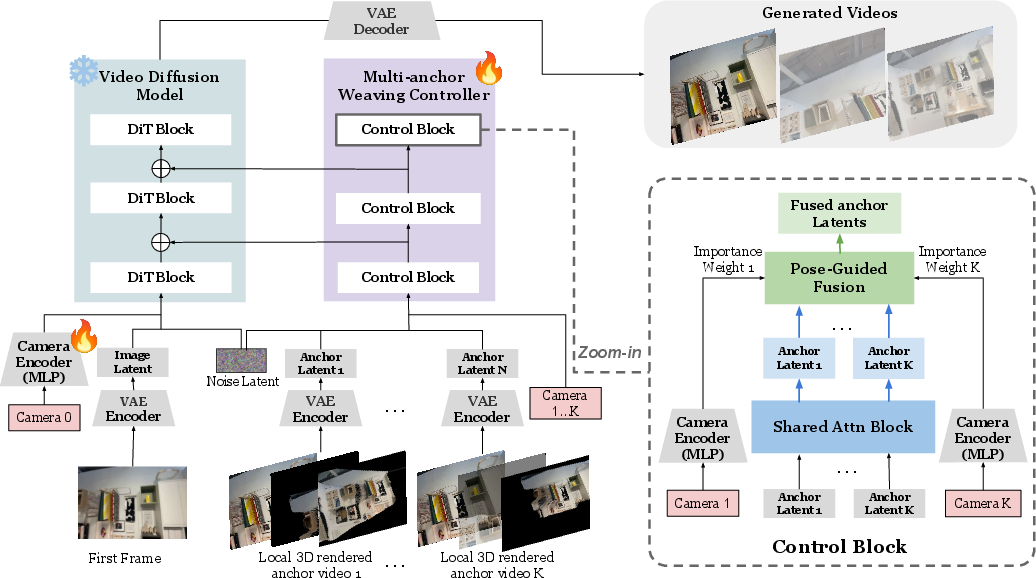
- Anchor video: A video rendered from 3D geometry along a target camera path, used to condition generation for spatial consistency. "Generation is then conditioned on anchor videos (i.e., videos rendered from the reconstructed 3D scene under target camera trajectories) to enable spatial consistency."
- Autoregressive generation: Generating sequences iteratively so each segment depends on previously generated content. "enabling clip-by-clip autoregressive generation~\cite{huang2025selfforcing, zhang2025packing, chendiffusion} that follows user-specified camera trajectories."
- Camera encoder: A neural module that transforms target camera parameters into embeddings for control signals. "The target camera pose is encoded by a trainable camera encoder to produce camera embeddings"
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) used in projection and rendering. "and extra camera intrinsics and anchor videos"
- Camera pose: The position and orientation (extrinsics) of a camera in 3D space. "we estimate per-frame local geometry and camera pose with a pretrained 3D reconstruction model"
- Camera trajectory: A time sequence of camera poses specifying motion during generation. "Given a target camera trajectory of length for the next video segment"
- ControlNet: An auxiliary conditioning network inserted alongside diffusion layers to inject control signals. "a stack of DiT-based ControlNet blocks that operate alongside the backbone model."
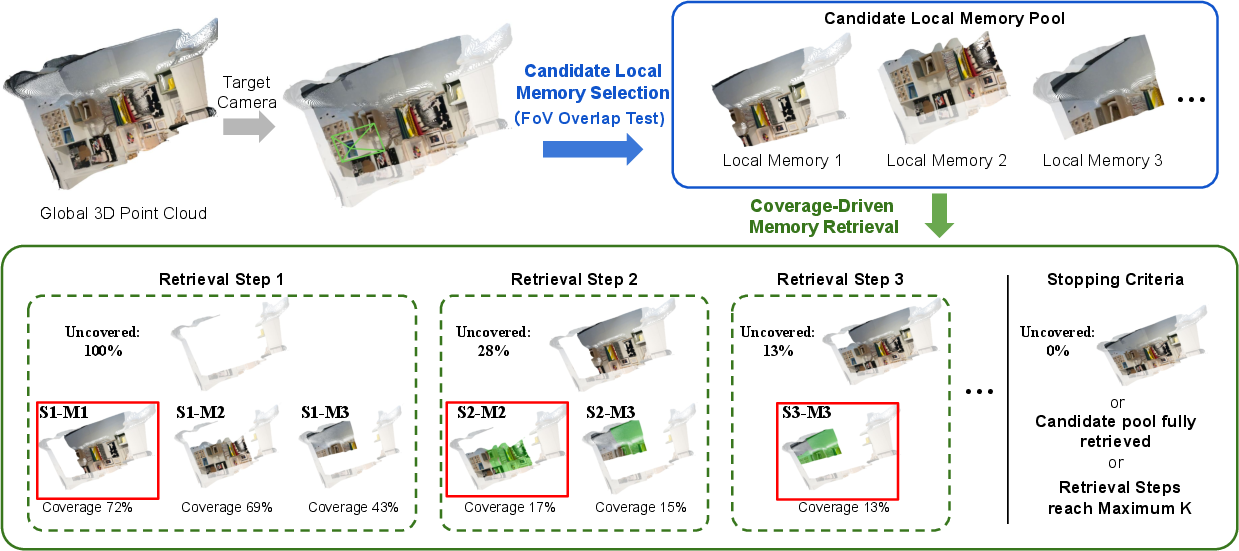
- Coverage-driven memory retrieval: A retrieval strategy that selects memories to maximally cover what the target views will see. "AnchorWeave introduces a coverage-driven memory retrieval formulation that iteratively selects the local memory that maximizes additional visibility coverage along the target trajectory."
- Cross-view misalignment: Inconsistencies in reconstructed geometry across different views due to pose or depth errors. "reconstructing a global 3D scene from multiple views inevitably introduces cross-view misalignment"
- DiT: Diffusion Transformer; a transformer architecture adapted for diffusion models. "We use standard DiT-based latent diffusion models (LDMs)~\citep{rombach2022high} as backbone."
- Field-of-view (FoV): The angular extent of the observable scene captured by the camera. "we first construct a candidate local memory pool using a coarse field-of-view (FoV) overlap test"
- Flow Matching: A continuous-time training objective for generative modeling that matches probability flow. "such as DDPM~\citep{ho2020denoising} or Flow Matching~\citep{lipmanflow}, producing a noisy latent"
- Ghosting artifacts: Double-exposure-like visual artifacts arising from misaligned multi-view fusion. "leading to ghosting or drift artifacts that degrade generation quality"
- Global point cloud: A single fused 3D point set representing the entire scene, constructed from multiple views. "fuse them into a unified 3D representation such as a global point cloud."
- Greedy strategy: An iterative selection method that chooses the locally best option at each step without global optimization. "This greedy strategy yields a compact and complementary set of local memories per chunk"
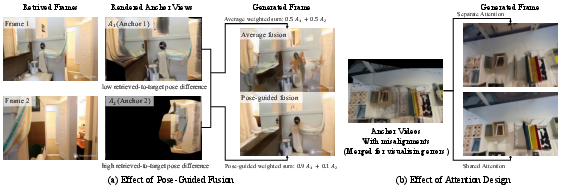
- Hallucinations: Spurious or non-existent content produced by the generative model due to poor conditioning. "propagate to the generated video as hallucinations ((b), red boxes)."
- Shared multi-anchor attention: An attention mechanism that jointly processes multiple anchor features to exchange information across them. "a shared multi-anchor attention module that jointly processes all anchor features"
- Latent diffusion model (LDM): A diffusion model that operates in a compressed latent space rather than pixel space. "We use standard DiT-based latent diffusion models (LDMs)~\citep{rombach2022high} as backbone."
- Local geometric memory: Per-frame, view-aligned 3D representations (e.g., point clouds) stored as independent memories. "multiple clean local geometric memories"
- Multi-anchor weaving controller: A module that fuses multiple anchor conditions via shared attention and pose-guided fusion into a single control signal. "integrates the selected local memories through a multi-anchor weaving controller during generation."
- Multi-view fusion: Combining geometric information from multiple viewpoints into a unified 3D representation. "do not accumulate ghosting or drift from multi-view fusion"
- Plücker embeddings: Line-parameterization-based embeddings (from Plücker coordinates) used for camera representation. "inject explicit camera parameterizations (e.g., Pl\"ucker embeddings or pose tokens)"
- Point cloud: A set of 3D points representing scene geometry used for rendering and conditioning. "each frame's memory is represented as a local point cloud together with its camera pose"
- Pose-guided fusion: A fusion method that weights anchors by their relative pose proximity to the target view. "a camera-pose-guided fusion module that aggregates anchor features into a single control signal."
- PSNR: Peak Signal-to-Noise Ratio; a pixel-wise reconstruction quality metric (in dB). "we use PSNR and SSIM to measure reconstruction fidelity and consistency"
- Relative camera pose: The transformation relating one camera’s coordinate frame to another’s. "we compute the retrieved-to-target relative camera pose sequence"
- Rendering-based conditioning: Guiding generation using images rendered from geometry as conditional inputs. "provide cleaner geometric signals for rendering-based conditioning."
- Rigid transformations: Transformations composed of rotation and translation that preserve distances. "defined as the rigid transformations between the camera pose at which the local memory was captured and the target camera poses"
- SSIM: Structural Similarity Index; a metric assessing perceptual similarity between images. "we use PSNR and SSIM to measure reconstruction fidelity and consistency"
- Temporal chunk: A fixed-length segment of consecutive frames used for chunk-wise retrieval and conditioning. "we divide it into temporal chunks"
- VBench protocol: A benchmark suite and evaluation protocol for perceptual video quality metrics. "the VBench protocol~\cite{huang2024vbench} is adopted"
- Video autoencoder: A neural encoder–decoder that compresses and reconstructs videos into and from latent tensors. "a pretrained video autoencoder first compresses the input into a lower-dimensional latent tensor"
- Visibility coverage: The extent of the target view’s visible region that is covered by retrieved memories. "visibility coverage along the target camera trajectory"
- World coordinate system: A global 3D reference frame into which all camera poses and geometry are transformed. "transformed into a shared world coordinate system"
Collections
Sign up for free to add this paper to one or more collections.

