ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Abstract: Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Insights from Multilingual Curation for a 20-Trillion-Token Dataset”
Overview
This paper is about teaching LLMs to be good in many different languages, not just English. The authors show that the main problem isn’t that models can’t handle many languages; it’s that the training data in those languages is often messy, uneven, or low-quality. By carefully cleaning and selecting better text for each language (a process they call “curation”), they can train models that are strong in multiple languages while using less computing power.
Key Objectives
Here are the main questions the researchers wanted to answer:
- Can improving the quality of English training data help the model perform better in other languages?
- Does improving data quality in non-English languages also help the model perform better in English?
- Is it most effective to curate data separately for each language, instead of using one generic recipe?
- Do translations help—and if so, does translating higher-quality English text make a bigger difference than translating random text?
- Can careful multilingual curation make training more compute-efficient, so models learn more with fewer resources?
How the Study Was Done
Think of training a LLM like teaching a student using a giant library. If the library is messy, full of junk, or missing books for certain subjects (languages), the student won’t learn well. “Curation” is like cleaning the library: removing bad books, organizing good ones, and making sure each subject has the right materials.
The researchers did this in three main ways:
- Small, controlled experiments:
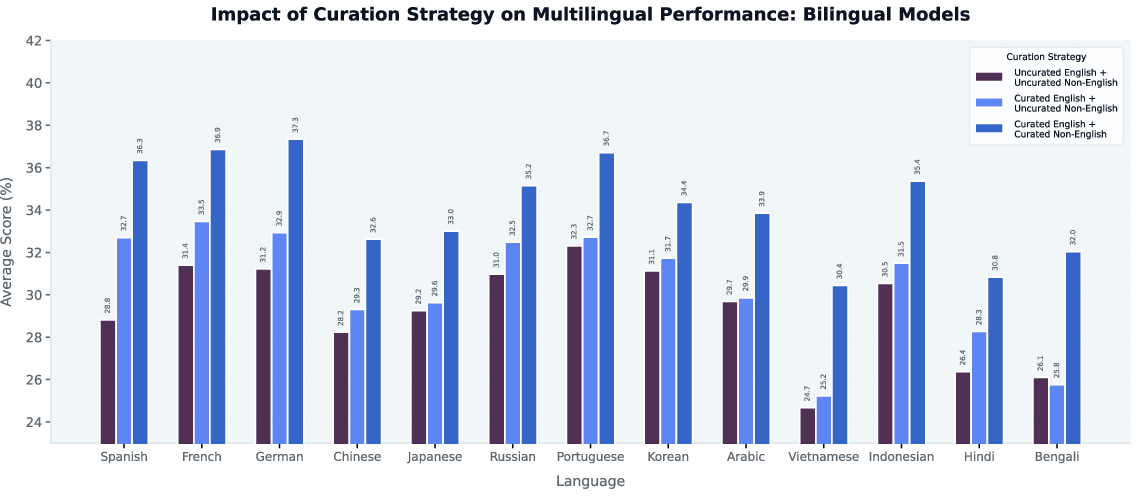
- They trained many “bilingual” models (English paired with one other language), using the same size and settings so the only difference was the data quality.
- They tried three setups: no curation at all; curate only English; curate both English and the other language.
- Languages included: Russian, Chinese, German, Spanish, Japanese, French, Portuguese, Indonesian, Arabic, Vietnamese, Korean, Hindi, and Bengali.
- Translation experiments:
- They tested whether translating English text into other languages helps.
- They compared translating random English text versus translating carefully chosen, high-quality English text.
- Large-scale training:
- They built a huge dataset with 20 trillion “tokens” (tiny pieces of text, like words or parts of words).
- They trained 3-billion and 8-billion parameter models on a 1-trillion-token slice of this dataset.
- They used a multi-phase training plan where the amount of multilingual data increased over time, but still used under 8% of the total tokens for non-English languages.
They measured performance on tests like:
- MMLU and ARC-Challenge: multiple-choice questions that test knowledge and reasoning.
- Belebele: reading comprehension across many languages.
They also looked at “FLOPs,” which is the amount of math the computer has to do during training. Less FLOPs for the same (or better) performance means the approach is more efficient.
Main Findings
The authors report several clear results:
- Improving English data helps other languages:
- When they cleaned and curated English training data, models got better in 12 out of 13 non-English languages, with about a 3.9% average improvement.
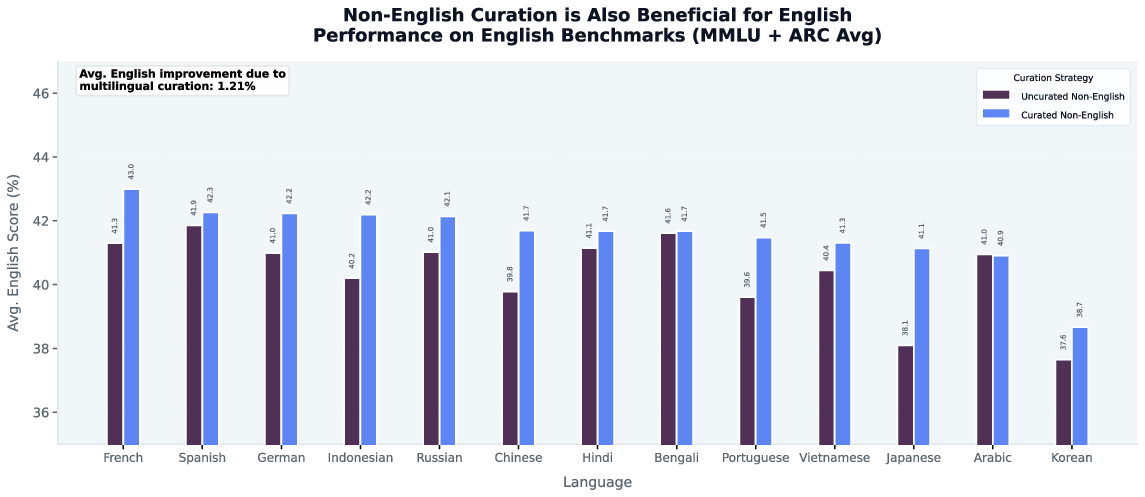
- Improving non-English data helps English:
- When they curated the non-English side of the training mix, English performance also improved in 12 out of 13 cases, with about a 1.2% average improvement.
- Best results come from per-language curation:
- Curating each language separately (instead of using one English-based recipe for all) gave much bigger gains—up to about 16.9% improvement over uncurated training.
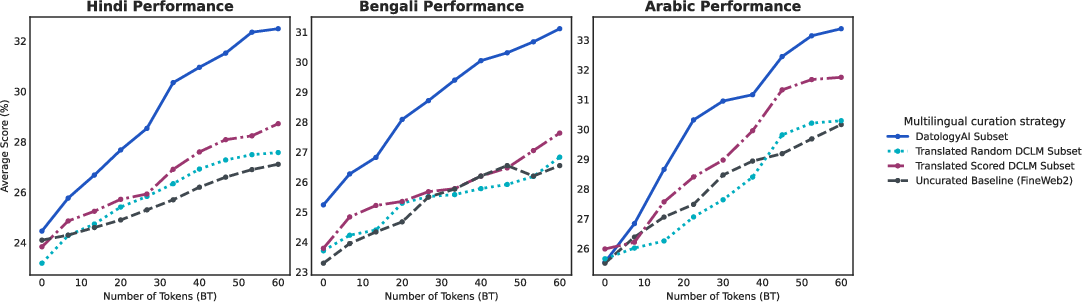
- Translation works best with high-quality source text:
- Translating randomly chosen English text gave only small gains.
- Translating high-quality English documents led to stronger improvements (about 5.1% on average).
- Even so, the best results came from full, per-language curation—not translation alone.
- Strong performance with surprisingly few multilingual tokens:
- Allocating under 8% of training tokens to well-curated multilingual data was enough for competitive results.
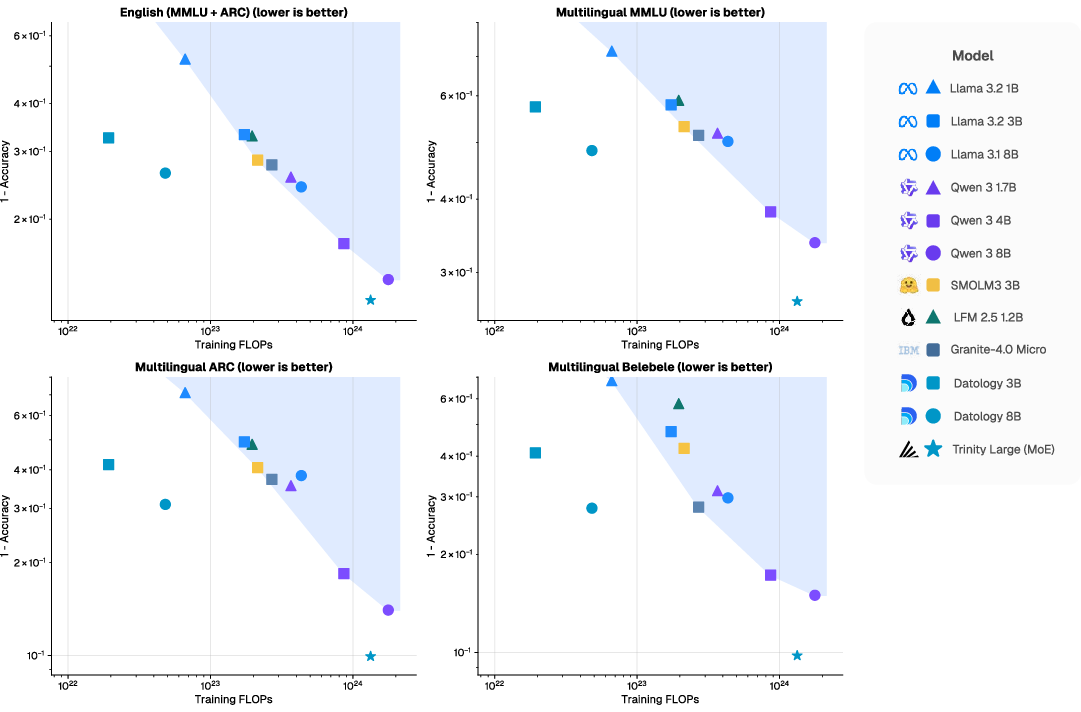
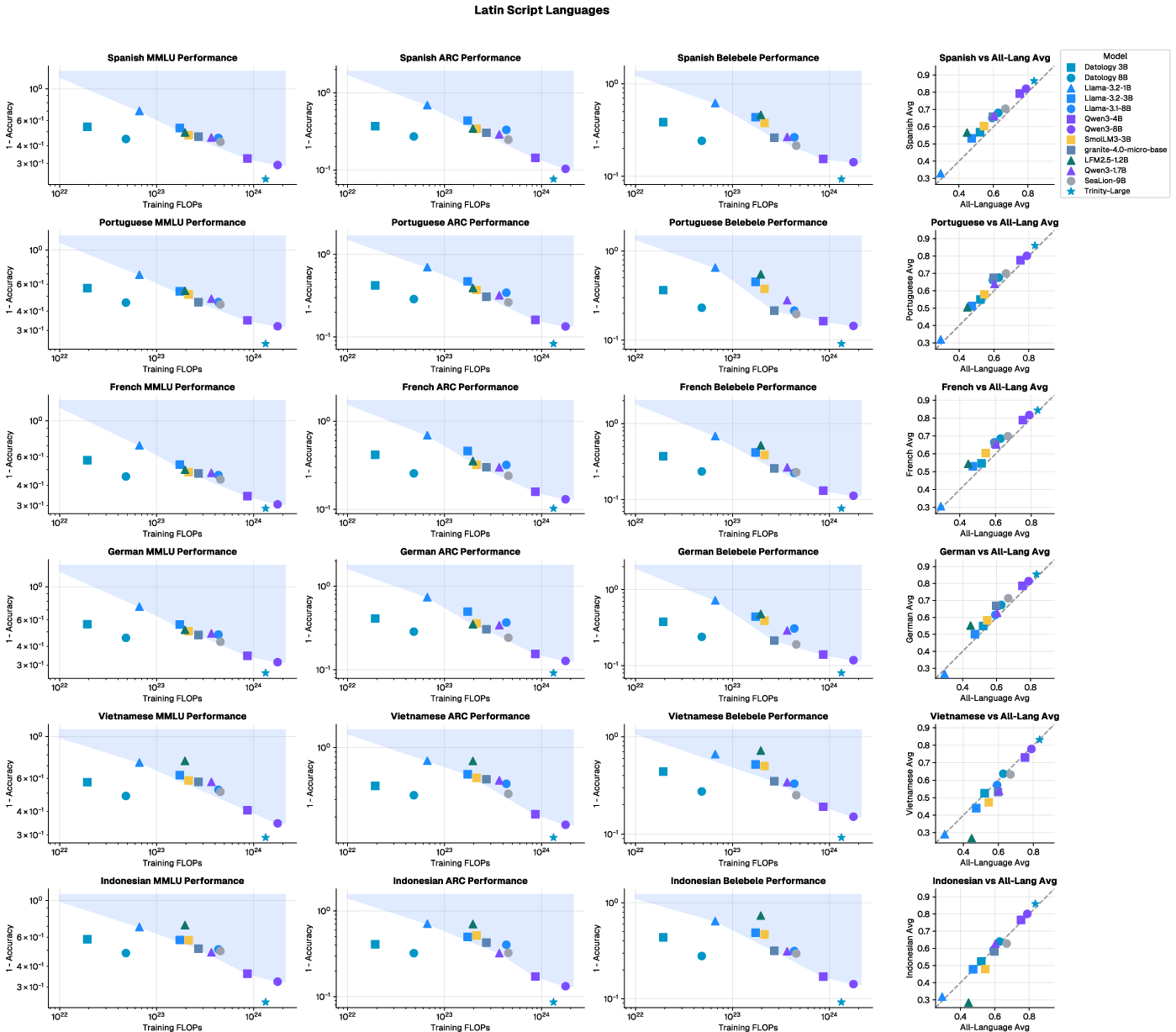
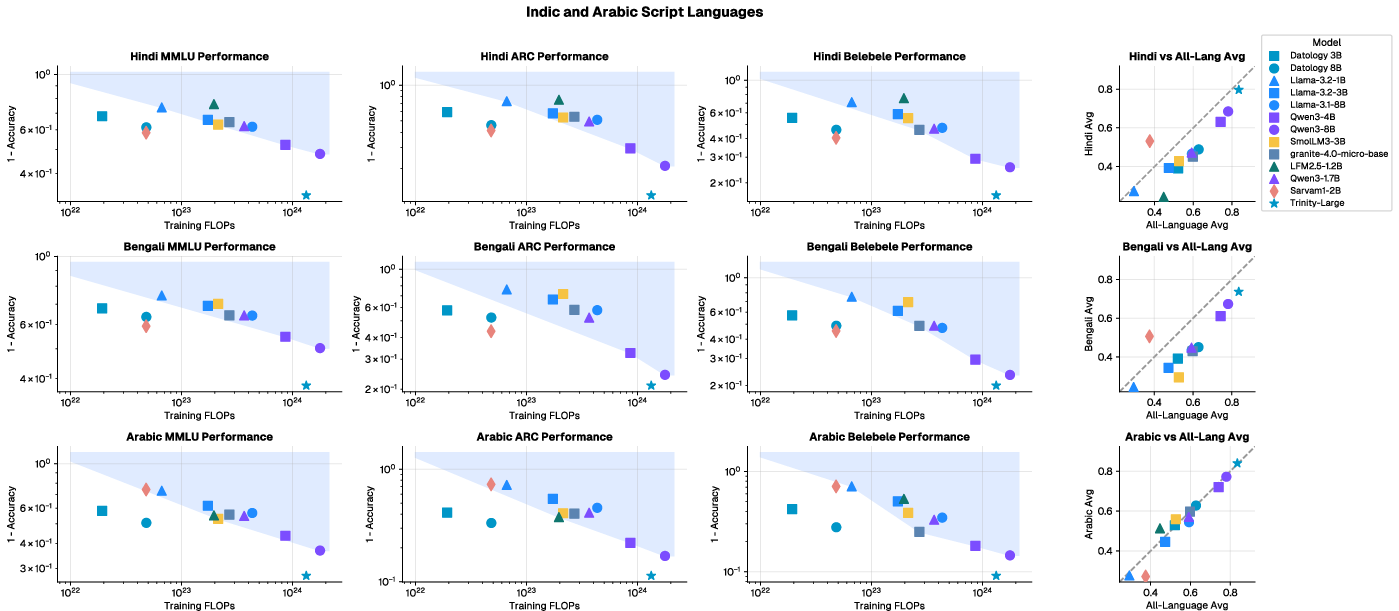
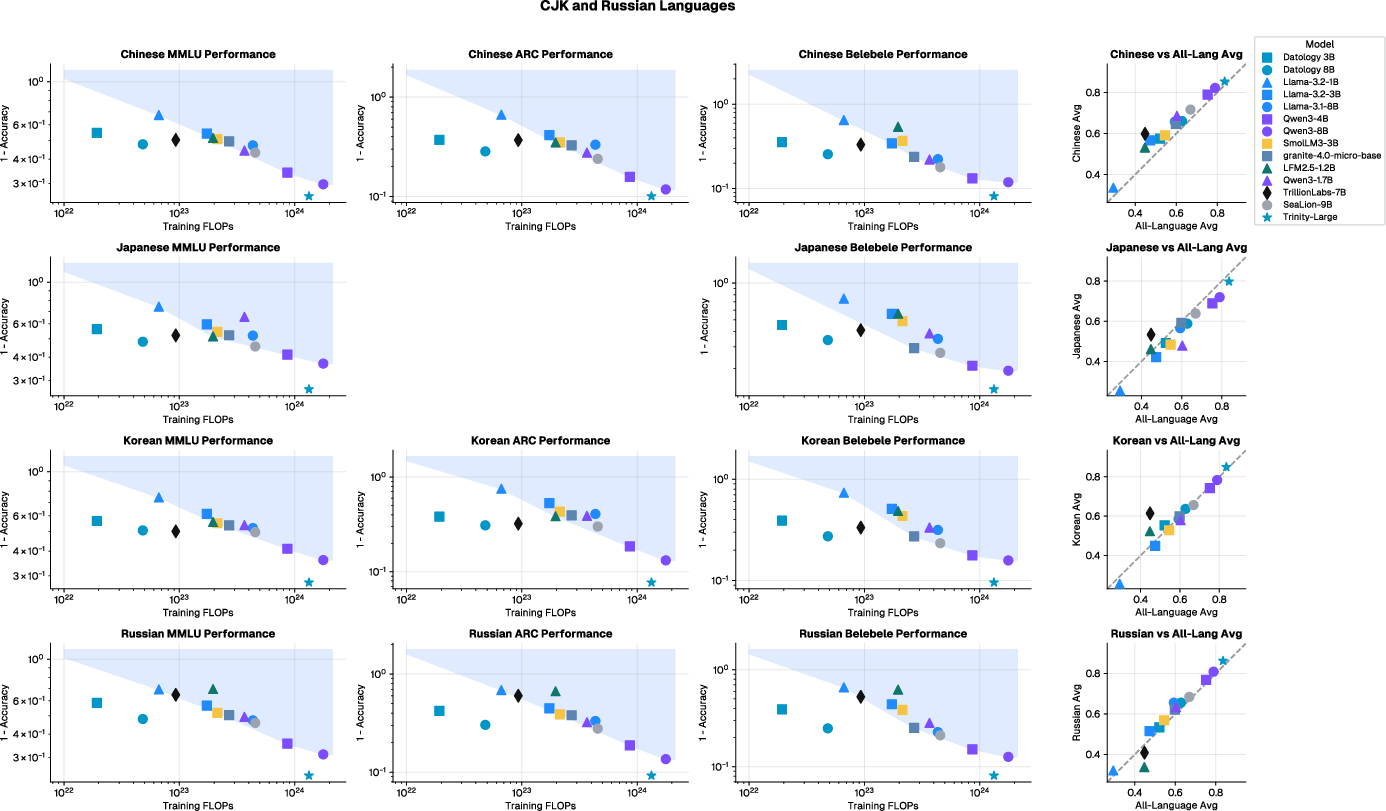
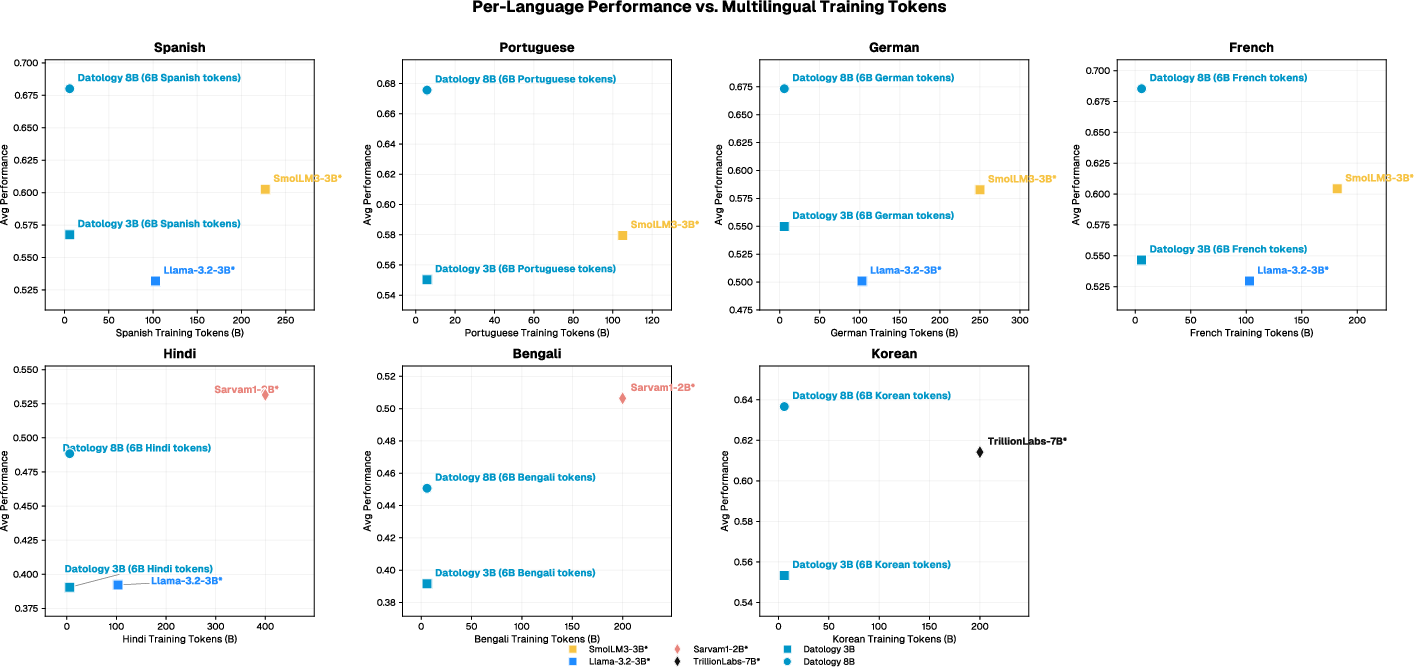
- Their 3B and 8B models matched or beat other strong public models while using about 4–10 times less training compute.
- Their curated dataset also helped train a much larger “frontier” model (Trinity Large), which performed strongly in multiple languages relative to the compute used.
Why This Matters
This research shows that the “curse of multilinguality” (the idea that models get worse when trained on many languages) is not a hard limit—it’s mostly a data quality problem. The impact is important:
- Fairness and access: Better multilingual models mean people who don’t speak English can benefit more from AI.
- Efficiency: Cleaning the data is often cheaper and smarter than just using more compute and bigger models.
- Help for low-resource languages: Careful curation and smart translation can lift performance in languages with less good text available online.
- Practical guidance: Teams building LLMs can get better multilingual results by investing in language-specific curation strategies, using high-quality texts, and thoughtfully mixing data over training phases.
In short, training strong multilingual models isn’t just about size—it’s about teaching with the right materials. By carefully curating text for each language, we can build models that understand many languages well, while using less computing power and making AI more inclusive worldwide.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future work:
- Limited language coverage: results are shown for 13 languages; generalization to the long tail (e.g., African, Austronesian beyond Indonesian, indigenous, morphologically rich or low-web-presence languages) is untested.
- Token allocation policy per language is unspecified: were tokens distributed uniformly or weighted by resource/quality; what are optimal per-language allocations under fixed budgets?
- Mixture-ratio sensitivity is unexamined: bilingual runs fix 50/50 and large-scale runs fix 7.75% multilingual; ablations over ratios, temperature sampling, UniMax, and dynamic sampling are missing.
- Curriculum design not optimized: only a 3-phase schedule (5%→10%→20% multilingual) is evaluated; no ablation on phase durations, ramp rates, or per-language staging.
- Attribution of curation gains is unclear: no component-wise ablation of filters (model-based vs embedding-based), deduplication strength, synthetic rephrasing, or source selection to identify which steps drive improvements.
- Cross-lingual deduplication is not described: how near-duplicates across languages/scripts are detected/removed and how this affects transfer and contamination.
- Data contamination audits are not reported: no documented leakage checks for multilingual MMLU/ARC/Belebele (especially given web-scale sources and synthetic data).
- Translation augmentation is tested on only 3 languages (Hindi, Bengali, Arabic): scalability to more languages, language families, and scripts remains unknown.
- Translation pipeline details are under-specified: MT systems used, quality estimation, post-editing, filtering of “translationese,” and error profiles are not reported.
- Alternative translation strategies are unexplored: back-translation, pivot languages other than English, multilingual round-trip consistency checks, and mixing ratios between native and translated data.
- Source-quality selection for translation uses a fastText score only: comparisons to stronger selectors (e.g., LLM-rankers, cross-lingual perplexity, semantic diversity criteria) are absent.
- Tokenizer effects are not analyzed: a fixed Llama-3.2 tokenizer is used for all languages; impacts on token efficiency for CJK, Indic, Arabic, agglutinative languages, and alternative tokenizers are untested.
- Architectural generality is unclear: results are shown on Llama-based dense models; do findings hold for MoE during base training, hybrid architectures, or alternative pretraining objectives?
- Scaling-law quantification is missing: no explicit, data-quality-aware scaling curves (loss vs tokens/params) per language or family; no trade-off curves between number of languages and per-language performance.
- Compute comparisons may be confounded: cross-model claims (error vs FLOPs) could be affected by differences in optimizer, sequence packing, learning rates, context lengths, or data mixing; no controlled ablation.
- Curation cost-benefit is unquantified: compute and engineering costs for curation (filtering, synthetic generation, translation) vs training savings are not reported.
- Evaluation scope is narrow: only zero-shot multiple-choice/cloze for MMLU, ARC-Challenge, Belebele; no free-form generation, instruction-following, long-form reasoning, QA, or downstream task benchmarks.
- Post-training effects are unknown: whether pretraining curation gains persist, amplify, or attenuate after instruction tuning/RLHF is untested.
- Safety, bias, and fairness impacts are unmeasured: potential demographic/dialectal bias shifts introduced by per-language curation and translation are not assessed.
- Dialect and code-switching robustness is not evaluated: e.g., Arabic dialects, Hindi-English code-switching, orthographic variants, and script mixing.
- Domain balance is under-specified: web-dominant sources may skew domains; contributions of books, news, legal, conversational, and academic texts per language are not characterized.
- Error analysis is absent: per-language failure modes (by subject, domain, script, or reasoning type) and interference patterns are not dissected.
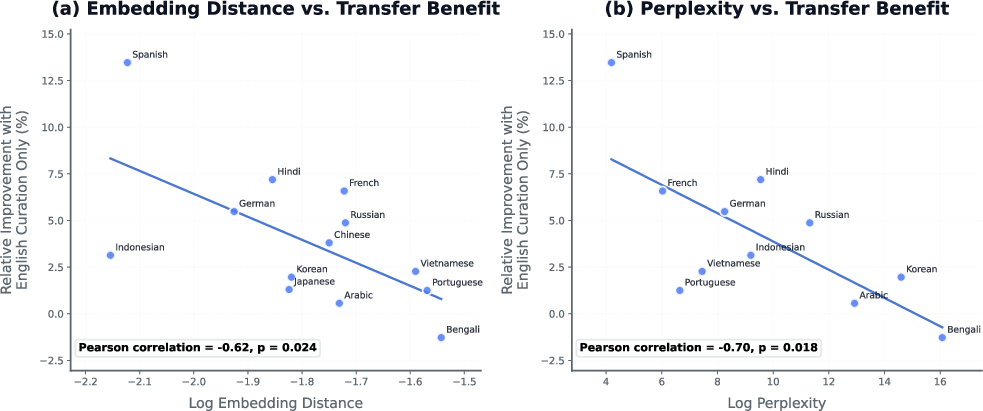
- Language similarity analysis is correlational only: proxies (embedding distance, perplexity) correlate with transfer, but causal mechanisms and confounders (tokenization, domain match) remain unresolved.
- Unseen-language generalization is untested: does curated multilingual training improve zero-shot performance on languages not present in the training mix?
- Token-efficiency thresholds are unknown: minimal tokens per language (given high-quality curation) needed to meet target accuracy are not mapped; no Pareto frontier of tokens-per-language vs accuracy.
- Per-language evaluation coverage may be uneven: benchmark availability and difficulty vary across languages; no calibration for comparability or test-set artifacts.
- Synthetic rephrasing risks are not measured: potential unnatural style, distribution shifts, or bias amplification introduced by synthetic augmentations are unassessed.
- Selection-model bias is unaddressed: model-based filters trained on English or high-resource languages may mis-rank low-resource texts; need audits of selection bias per language.
- Robustness to noisy orthography and Unicode quirks is not reported: e.g., ZWJ/ZWNs in Indic scripts, Arabic diacritics/normalization, simplified vs traditional Chinese.
- Deduplication strength vs coverage trade-offs are not explored: how varying dedup thresholds affects diversity, overfitting, and transfer across languages.
- Code and STEM curation is claimed but unevaluated: cross-lingual code and math benchmarks (e.g., MBPP-x, GSM8K-x, math word problems in target languages) are not presented.
- Reproducibility is limited: per-language token counts, source shares, filter thresholds, and released curation artifacts/pipelines/datasets are not provided.
- Interaction between similarity-aware sampling and low-resource support is unstudied: how to allocate tokens to maximize both aggregate performance and fairness for distant/low-resource languages.
- Long-context and retrieval effects are unexplored: models trained with 4k context only; impact of curation on retrieval-augmented tasks and longer contexts is unknown.
- Adverse side-effects of aggressive filtering are unmeasured: potential loss of dialectal, cultural, or minority registers; guidelines for preserving linguistic diversity are not given.
Practical Applications
Immediate Applications
The following applications can be deployed today by adapting the paper’s data-centric multilingual curation methods to existing model training and product pipelines.
- Cost-efficient multilingual model training for products (software)
- Use bespoke per-language curation and a multi-phase curriculum with ~8% of total tokens reserved for multilingual data to achieve strong performance with 4–10× less training FLOPs than common baselines. Train 3B–8B models on 1T tokens or fine-tune existing models with curated data for target markets.
- Tools/workflows: model-based filtering, embedding-based selection, per-language synthetic rephrasing, source-scored translation, lighteval for MMLU/ARC/Belebele.
- Assumptions/dependencies: access to open corpora (e.g., DCLM, FineWeb2), language-appropriate filters/embedders, compute to run curation; quality audits to minimize contamination.
- Rapid launch of multilingual customer support/chatbots in long-tail languages (software, finance, retail, public services)
- Apply English-only curation to boost non-English performance (average 3.9% relative uplift across 12/13 languages) and complement with tailored curation for target languages for larger gains (up to 16.9% relative).
- Tools/workflows: bilingual training mixtures (50/50 English–target) for 60B-token runs to quickly stand up language-specific capabilities; language similarity heuristics (FLoRes-based embeddings/perplexity) to choose rollout order (e.g., start with Spanish/French/German for higher immediate transfer).
- Assumptions/dependencies: domain adaptation data (support logs, FAQs), governance to handle PII and compliance, evaluation beyond multiple-choice tasks for dialogue quality.
- Source-scored translation to expand low-resource training data (education, public sector, software localization)
- Augment scarce language corpora by translating high-quality English documents selected via fasttext-like scoring, which outperforms blind translation; embed this within a broader per-language curation pipeline.
- Tools/workflows: source-scoring gate, batch MT pipeline, contamination checks, de-duplication; integration with per-language filters/embeddings.
- Assumptions/dependencies: reliable MT systems for target pairs; legal permission for translation; coverage for non-Latin scripts; monitoring for translation artifacts.
- Compute-aware data procurement and training planning (industry MLOps, academia)
- Adopt a multi-phase training curriculum gradually increasing multilingual token ratios (e.g., 5%→10%→20%) while keeping total multilingual allocation under ~8%; plan FLOPs budgets against the improved performance–compute Pareto frontier.
- Tools/workflows: curriculum schedulers, sampling caps (e.g., UniMax-style repetition limits), mixture dashboards; per-language token accounting.
- Assumptions/dependencies: mixture transparency from data vendors; reliable tokenization across scripts (Llama-3.2 or equivalent).
- Language equity upgrades for public-facing portals (policy, public services)
- Deploy smaller, curated multilingual models in government portals, social services, and legal aid with better accuracy in Hindi, Bengali, Arabic, etc., at lower infrastructure cost.
- Tools/workflows: curated domain-specific corpora, evaluation harnesses, phased deployment by similarity/need, human-in-the-loop QA.
- Assumptions/dependencies: public data licensing and privacy reviews; community feedback loops; accessibility standards.
- Multilingual content moderation and safety review (software platforms, media)
- Use curated multilingual pretraining to improve reading comprehension and semantic reasoning (Belebele) across 13+ languages for moderation queues and policy enforcement.
- Tools/workflows: per-language curation, reading-comprehension probes, threshold calibration per language; lightweight 3B–8B inference for scale.
- Assumptions/dependencies: robust labeling policies; adversarial robustness checks; continuous drift monitoring.
- Academic labs: reproducible low-cost multilingual model building (academia)
- Replicate bilingual 60B-token studies to quantify transfer and interference, then scale to small general-purpose mixtures with ~8% multilingual tokens; prioritize per-language pipelines over English-centric recipes.
- Tools/workflows: lighteval, FLoRes-based similarity analysis, open curation scripts; public corpora integration.
- Assumptions/dependencies: compute access; ethical sourcing; cross-lingual benchmark coverage.
- Sustainability-aligned training (energy, ESG)
- Lower training energy and carbon by shifting to curated mixtures yielding similar multilingual accuracy with fewer FLOPs; report efficiency improvements along the Pareto frontier.
- Tools/workflows: energy/FLOPs tracking, mixture optimization, per-language curation gates.
- Assumptions/dependencies: accurate energy metering; procurement aligned to low-carbon compute.
Long-Term Applications
The following applications are feasible with further research, scaling, tooling, and standardization.
- Frontier-scale inclusive foundation models with tens of trillions of tokens (software, public interest)
- Extend the 20T-token corpus approach to larger, more diverse language sets while maintaining low multilingual token ratios via better curation and curricula; generalize beyond 13 languages to hundreds.
- Tools/workflows: scalable per-language curation orchestration, model-in-the-loop data selection, adaptive sampling laws.
- Assumptions/dependencies: expanded open corpora; robust decontamination; governance for global data sourcing.
- Automated, dynamic curation loops (software, MLOps)
- Build continuous pipelines where models score and select training data per language, adapting mixtures over time to minimize interference and maximize transfer.
- Tools/workflows: active/data-in-the-loop selection, drift detection, curriculum optimizers; multilingual data QA dashboards.
- Assumptions/dependencies: reliable online evaluation signals; guardrails against self-reinforcing biases; reproducibility and auditability.
- National or regional language infrastructure as digital public goods (policy, education)
- Publicly funded, audited per-language corpora and curation standards for low-resource languages, enabling equitable AI access without excessive compute.
- Tools/workflows: open curation reference pipelines, shared evaluation sets, translation hubs for high-quality source-scored MT.
- Assumptions/dependencies: policy frameworks for consent and licensing; community partnerships; recurring funding.
- Domain-specialized multilingual models (healthcare, law, finance)
- Combine per-language curation with domain corpora to build compact models for clinical triage, legal aid, and compliance across languages, leveraging improved reading comprehension and reasoning.
- Tools/workflows: domain-specific curation gates, expert review, risk controls; on-prem deployment for regulated settings.
- Assumptions/dependencies: high-quality domain data in target languages; safety testing; regulatory approval.
- On-device multilingual assistants for underserved regions (consumer devices, education)
- Deploy small curated models (3B–8B) for offline or low-bandwidth scenarios with improved performance in local languages; power education and civic information access.
- Tools/workflows: edge inference stacks, quantization/distillation from curated bases, local evaluation packs.
- Assumptions/dependencies: device memory/compute constraints; localized UX; continued curation updates.
- Multimodal, multilingual vision–LLMs (software, robotics, accessibility)
- Port data-centric curation principles to multimodal corpora, addressing uneven quality in non-English captions and OCR; improve cross-lingual grounding.
- Tools/workflows: per-language caption/OCR curation, image–text alignment checks, multilingual VLM evaluation suites.
- Assumptions/dependencies: high-quality multimodal data; script-aware tokenization; new benchmarks.
- Formal data-centric scaling laws and mixture optimizers (academia, software tooling)
- Derive and operationalize scaling laws that treat data quality as the bottleneck, guiding optimal token allocations per language and phase.
- Tools/workflows: mixture optimizers, transfer/interference predictors using similarity proxies, automated curriculum tuning.
- Assumptions/dependencies: broader empirical studies across languages and tasks; agreement on evaluation protocols.
- Industry standards for multilingual data governance and transparency (policy, industry consortia)
- Establish reporting norms for per-language token counts, curation steps, contamination checks, and mixture ratios; improve comparability and safety.
- Tools/workflows: standardized curation manifests, audit trails, certification programs.
- Assumptions/dependencies: multi-stakeholder coordination; incentives for disclosure; privacy and IP safeguards.
Glossary
- Adaptive transfer scaling law: A principled model that predicts how adding languages affects performance per parameter in massively multilingual training. "Their work derives an adaptive transfer scaling law that explicitly models the trade-off between adding languages and maintaining performance per parameter."
- ARC Challenge: A benchmark of difficult grade-school science multiple-choice questions used to evaluate multi-step reasoning. "We restrict our English-language evaluations to MMLU and ARC-{Challenge} for parity with the multilingual evaluations"
- ATLAS: A large-scale multilingual study examining cross-lingual transfer and scaling behavior across hundreds of languages. "the ATLAS project recently conducted the largest study to date, covering over 400 languages and exploring cross-lingual transfer across 38 languages"
- Belebele: A multilingual reading comprehension benchmark assessing semantic reasoning over aligned passages. "Belebele measures multilingual reading comprehension and semantic reasoning over aligned passages, with minimal dependence on memorized factual knowledge."
- Capacity bottleneck: The idea that limited model parameters constrain performance when training on many languages. "Historically, the consensus view attributed this phenomenon to a capacity bottleneck, framing multilingual modeling as a zero-sum game in which distinct languages compete for finite parameters"
- Cloze formulation: An evaluation setup where models fill in missing words or tokens in context, providing a dense learning signal. "For smaller runs (e.g., our 3B, 60B-token setting), we instead use the cloze formulation."
- Cosine distance: A metric for measuring similarity between embeddings by the angle between vectors. "For embedding distance, we report the average cosine distance between English and the target language across three distinct models"
- Cross-lingual transfer: The phenomenon where improvements in one language lead to better performance in other languages. "Cross-lingual transfer refers to the observation that improving representations in one language can benefit performance in other languages."
- Curriculum (multi-phase training curriculum): A staged training schedule that gradually alters mixture proportions (e.g., increasing multilingual token density). "we implemented a multi-phase training curriculum that progressively increases the density of multilingual tokens."
- Data curation: The process of selecting, filtering, and assembling high-quality datasets tailored to specific languages or tasks. "we develop language-specific data curation pipelines for each of the languages above."
- Embedding-based selection: Choosing documents based on their vector representations to improve dataset quality and diversity. "integrates complementary strategies including model-based filtering, embedding-based selection, and targeted synthetic data generation"
- fastText classifier: A lightweight text classification tool used for scoring and filtering documents. "When scoring English data, we used a fasttext classifier similar to \cite{penedo2024fineweb}."
- FLOPs: Floating point operations; a measure of compute used or required for model training. "We report error rate (log-scale; 1-accuracy, lower is better) as a function of training FLOPs (log-scale)"
- Geometry-based curation: Data selection methods that leverage the geometric structure of embedding spaces (e.g., distances, clustering). "embedding for geometry-based curation"
- LaBSE: Language-Agnostic BERT Sentence Embedding model used for cross-lingual similarity measurement. "across three distinct models: LaBSE \citep{feng2022language}, e5-small \citep{wang2022text}, and sentence-transformers \citep{reimers2019sentence}."
- lighteval: An evaluation framework used to run standardized benchmark tests. "Throughout this work, we rely on the lighteval \citep{lighteval} framework for all our evaluations."
- Llama-based architecture: A transformer model family used as the base architecture for experiments. "We present results on both 3B and 8B parameter models using a Llama-based architecture"
- Mixture of Experts (MoE): A model architecture that routes inputs through a subset of specialized expert networks to increase capacity efficiently. "Trinity Large Base (400B-parameter MoE, 13B active; \citet{TrinityLarge})"
- Model-based filtering: Using trained models to score and select high-quality documents for pretraining. "integrates complementary strategies including model-based filtering, embedding-based selection, and targeted synthetic data generation"
- Multiple-choice formulation (MCF): An evaluation style where models pick from discrete options, often used for standardized benchmarks. "we adopt the multiple-choice formulation (MCF), following common practice"
- Negative interference: Degradation in one language’s performance caused by training jointly with others. "drive positive transfer across languages while minimizing negative interference"
- Open-weight baselines: Publicly released models whose parameters are available for use and comparison. "The shaded gray region summarizes the performance–compute envelope of representative open-weight baselines (e.g., Qwen3-4B/8B, Granite-4.0-3B)."
- Pareto frontier: The set of optimal trade-offs where improving one metric (e.g., accuracy) requires sacrificing another (e.g., compute). "A new compute-performance Pareto frontier for English and multilingual capabilities."
- Perplexity: A measure of how well a probability model predicts a sample; lower values indicate better language modeling. "Our perplexity proxy is defined as the average log perplexity per word as measured on the target language samples under a model trained exclusively on curated English data."
- Phased curricula: Training schedules that introduce changes in data mixtures in stages to manage transfer and interference. "including per-language sampling strategies and phased curricula that balance improvements in one language against interference in others"
- Sampling ratio: The proportion of tokens from a given language or source in the training mixture. "the test loss for a language family is primarily determined by its own sampling ratio"
- Temperature-based sampling: A heuristic that adjusts sampling probabilities (often to favor low-resource languages), controlled by a temperature parameter. "While temperature-based sampling is a standard heuristic, it often leads to overfitting in low-resource regimes."
- Token budget: The total number of training tokens allocated to pretraining. "Under a 1T-token training budget drawn from a curated general-purpose pretraining corpus"
- UniMax: A sampling strategy that caps repetition to ensure fairer coverage across languages. "Strategies like UniMax \citep{chung2023unimax} address this by capping repetition to ensure more representative coverage."
- Zero-shot performance: Evaluation without task-specific fine-tuning or examples, assessing generalization. "We report zero-shot performance."
- Zero-sum game: A framing where gains in one area necessarily cause losses elsewhere (e.g., languages competing for capacity). "framing multilingual modeling as a zero-sum game in which distinct languages compete for finite parameters"
Collections
Sign up for free to add this paper to one or more collections.