The Information Geometry of Softmax: Probing and Steering
Abstract: This paper concerns the question of how AI systems encode semantic structure into the geometric structure of their representation spaces. The motivating observation of this paper is that the natural geometry of these representation spaces should reflect the way models use representations to produce behavior. We focus on the important special case of representations that define softmax distributions. In this case, we argue that the natural geometry is information geometry. Our focus is on the role of information geometry on semantic encoding and the linear representation hypothesis. As an illustrative application, we develop "dual steering", a method for robustly steering representations to exhibit a particular concept using linear probes. We prove that dual steering optimally modifies the target concept while minimizing changes to off-target concepts. Empirically, we find that dual steering enhances the controllability and stability of concept manipulation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but deep question: how do AI models store meaning inside their “brains,” and what is the right way to poke or steer those meanings? The authors show that for many common AI parts that turn scores into probabilities (using something called “softmax”), the natural way to measure distance and make changes is not the usual straight-line geometry. Instead, it’s a special “information geometry” that cares about how output probabilities change. Using this idea, they create a new steering method—called dual steering—that changes a target concept (like turning “dog” into “cat”) while keeping everything else as unchanged as possible.
What questions are the authors asking?
- How should we measure “closeness” between two internal AI states so that “close” really means “the model will produce similar outputs”?
- When you move between two states inside the model, are there different kinds of “in-between paths,” and do they mean different things?
- How can we steer a model toward a concept (like “female” instead of “male,” or “third-person verb” instead of “base verb”) without breaking other unrelated parts of its behavior?
- Can a geometry that focuses on output probabilities make steering more stable and controllable?
How do they study it?
First, a bit of background in simple terms:
- Representations: Inside an AI, each step turns words, pictures, or contexts into vectors (lists of numbers). These vectors capture meaning.
- Softmax: The model turns its final scores into probabilities that add up to 1. Think of it like turning raw “preference points” into a fair pie chart.
- Geometry: Usually, we measure distance with straight lines in a flat space (Euclidean). But the authors argue we should measure distance by how different the output probabilities are. That’s information geometry.
Here are the main ideas and tools they use:
Two “views” of the same space: primal and dual
- There are two linked coordinate systems for these vectors:
- Primal space: the usual vector space you’re used to.
- Dual space: a “probability-aware” view that lines up with the model’s output probabilities.
- These two views are connected by a special mapping based on the softmax’s math. Moving in one view can look non-straight in the other.
Analogy: Imagine city navigation with two maps. One is a street map (primal), the other is a subway map (dual). A straight line on the subway map is not a straight line on the street map, and vice versa—but they describe the same city.
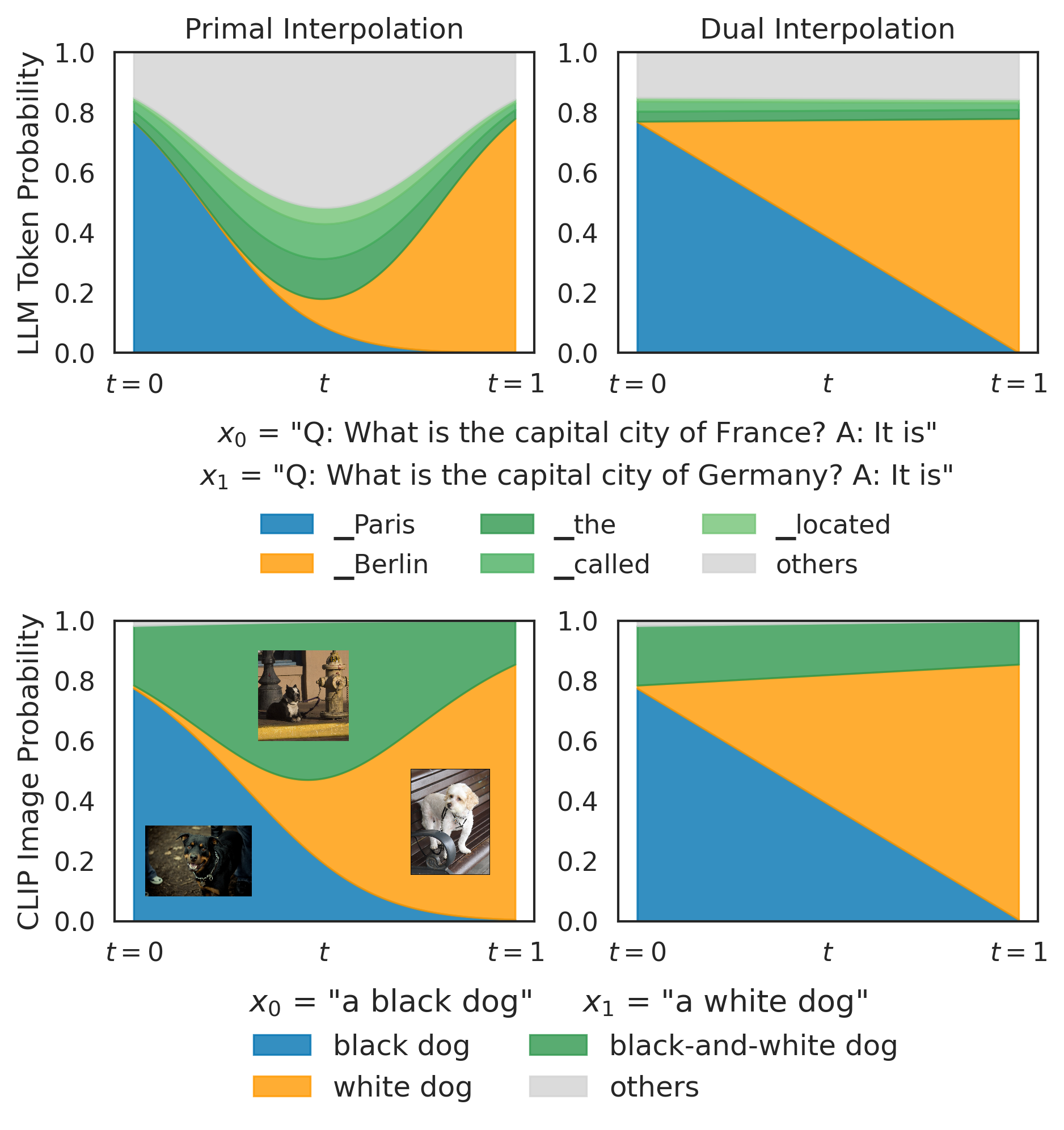
Two kinds of “in between”: primal vs. dual interpolation
If you want to move from meaning A to meaning B, there are two natural paths:
- Primal interpolation (street-map straight line): tends to highlight what A and B have in common. It acts like an AND—emphasizing overlap.
- Dual interpolation (subway-map straight line): tends to mix A and B. It acts like an OR—preserving both sides more evenly.
Example:
- Between “a black dog” and “a white dog”:
- Primal path boosts things like “a black-and-white dog” (the overlap).
- Dual path blends the two, keeping both black and white dog options prominent.
Probing and steering a concept
- Linear probe: a simple test that checks if a single direction in the model’s vector space reliably signals a concept (like “male vs. female,” or “verb vs. third-person verb”). You can think of it as a “concept detector.”
- Traditional steering (Euclidean): add the probe direction directly to the vector to push the model toward the target concept. This often works but can cause “leaks,” where unrelated outputs accidentally get boosted.
- Dual steering (the new method): add the probe direction in the dual space (the probability-aware view), then map back. This targets the concept while minimizing changes to everything else.
Why dual steering helps: It solves a “change the concept but keep off-target stuff the same” problem directly, using a distance that measures changes in probabilities. So it’s more loyal to the original behavior outside the concept you want to change.
How do they make dual steering work in practice?
- They take small steps that correspond to straight moves in the dual space.
- Each step uses a matrix that captures how spread out the model’s current probability-weighted outputs are (a covariance). Solving a small system gives the right direction to move.
- Sometimes the model is “stuck” because it’s too confident about a few options (the math becomes unstable). They fix this with gentle regularization, which slightly “widens the view” so steering can continue smoothly.
What did they find, and why does it matter?
Main findings:
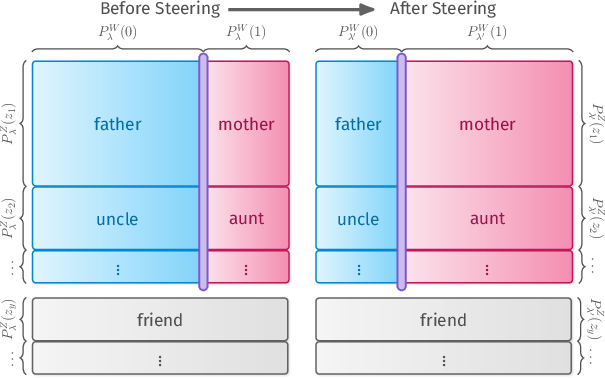
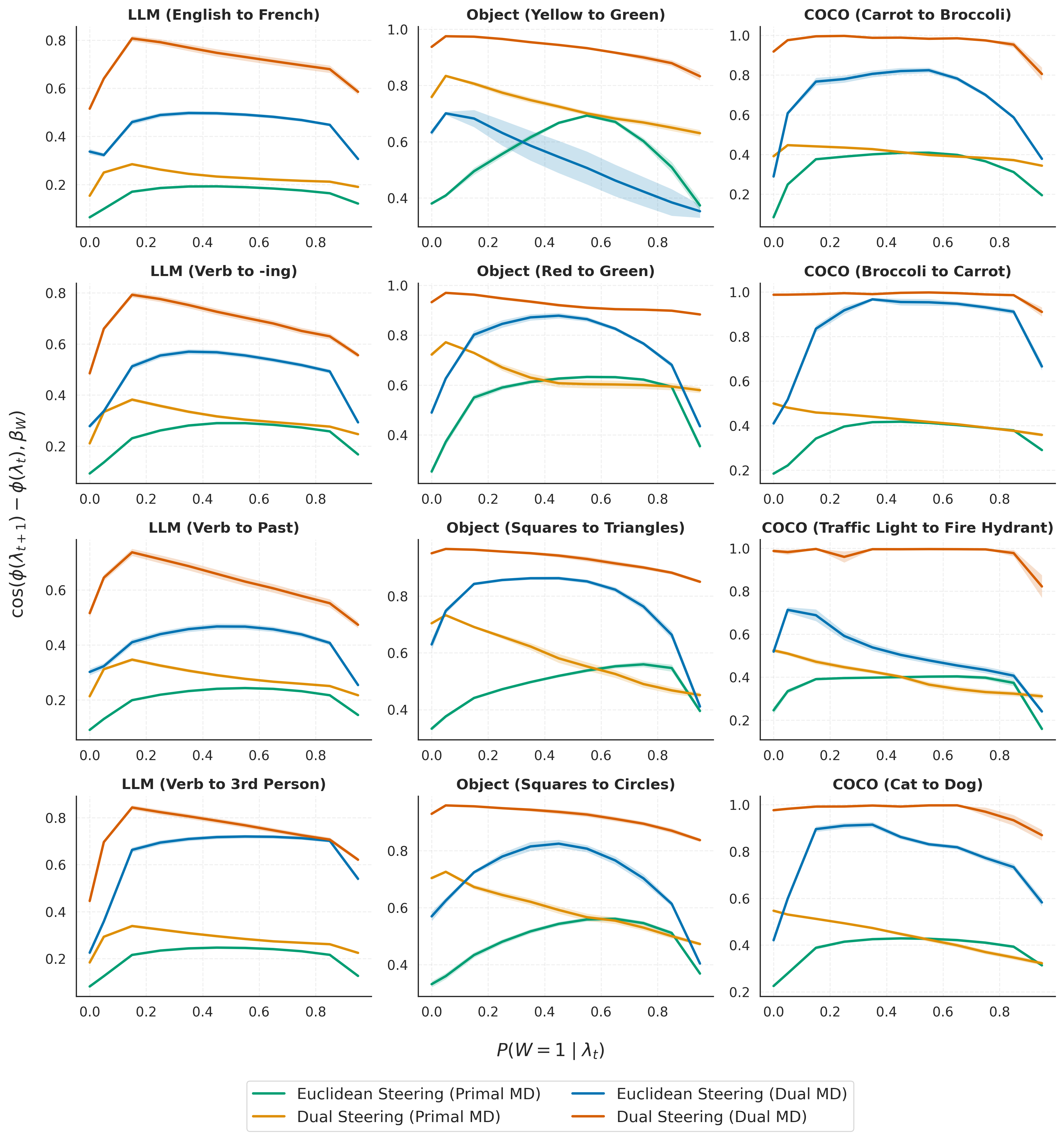
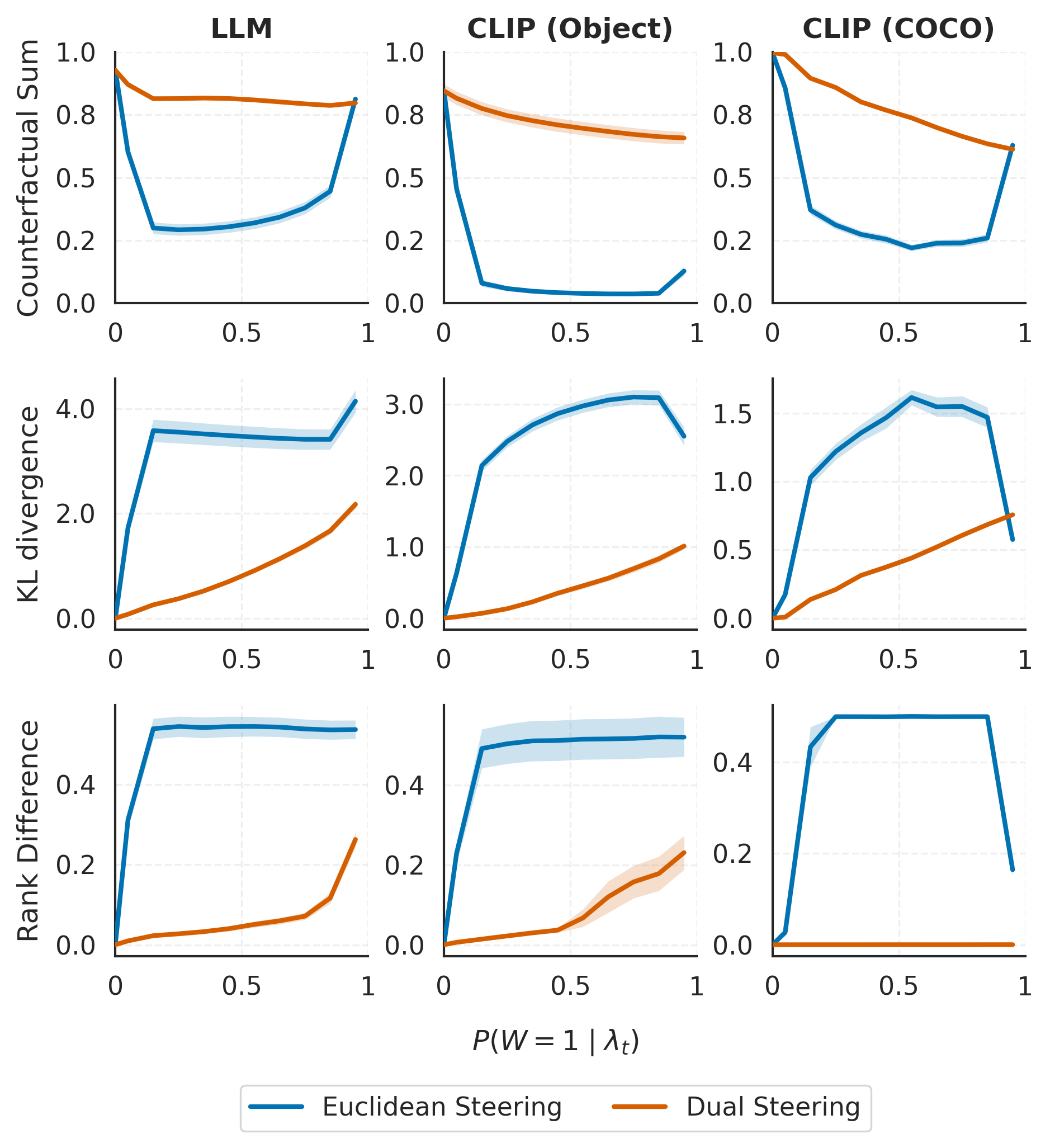
- Dual steering changes the target concept strongly while keeping unrelated parts steady. For example, pushing “verb” to “third-person verb” shifts “operate” to “operates” without accidentally boosting unrelated words like “to.”
- Traditional Euclidean steering often “leaks” probability to unrelated outputs during the process. Dual steering redirects probability mostly within the intended concept pairs (e.g., “father” ↔ “mother”).
- These results hold across both LLMs and vision-LLMs:
- Gemma-3-4B (an open-source LLM).
- MetaCLIP-2 (used for matching images and text).
- Measured in multiple ways—like how stable the off-target distribution stays, how little it changes rank order, and how consistent the total mass on counterfactual pairs is—dual steering is more stable and controllable.
Why it matters:
- If you want to reliably change one attribute (like tone, tense, or object type) without messing up others, dual steering gives you a principled way to do it.
- It connects meaning and geometry: measuring distance using output probabilities better reflects how the model behaves, not just how vectors look.
What’s the impact of this research?
- Better control: Dual steering is a step toward safer, more predictable model edits. You can turn one “knob” without accidentally bumping the others.
- Stronger theory for interpretability: It shows that the right geometry for softmax-based models is information geometry, not plain Euclidean. That explains why some past steering attempts were fragile.
- A template for future tools: This approach could guide new methods for editing and understanding models in a way that respects how they actually produce outputs.
- Practical notes and limits:
- You still need a good probe (a reliable concept detector). If the probe is weak or entangled with other concepts, steering can be harder.
- Sometimes traditional steering works okay—especially when the model already places most probability on the concept pairs you want to swap.
- This paper mainly studies the final layers that feed into softmax. Extending these ideas to deeper, earlier layers is a promising next step.
Overall, the paper shows that thinking in the model’s “probability geometry” leads to a better way to steer concepts: stronger control of what you change, and gentler impact on everything else.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored in the paper, intended to guide future research.
- Extension beyond softmax: How to generalize the information-geometric framework and dual steering to non-softmax mechanisms (e.g., sparsemax/entmax, top-k/nucleus sampling, temperature scaling, mixture-of-experts gating, or non-exponential-family outputs).
- Intermediate layer geometry: How to pull back the softmax-layer information geometry to intermediate hidden layers (e.g., via Jacobians or learned decoders), and whether practical, stable steering can be done at earlier layers where interventions are typically applied.
- Probe validity and invariance: Theorems assume a linear probe with constant on hyperplanes; develop methods to learn probes that approximate this invariance, quantify violations, and provide error bounds on steering robustness when the assumption fails.
- Automating concept-factorizability: The concept-factorizable assumption requires partitioning the output into counterfactual pairs and neutral elements; propose data-driven procedures to construct, validate, or learn such partitions for both text and vision outputs.
- Relaxations and diagnostics for factorization: Provide diagnostics to test factorization on real data and derive relaxations with guarantees (e.g., approximate factorization with bounded residuals) to make Theorem 1 applicable in practice.
- Beyond binary concepts: Generalize the theory and algorithms to multi-class, multi-label, continuous, or hierarchical concepts, and formalize off-target preservation in those settings.
- Multi-concept steering: Formulate and solve dual-space projections under multiple simultaneous concept constraints (potentially conflicting), including feasibility, prioritization, and interference analysis.
- Algorithmic scalability: Solving Cov v = β each step is expensive at LLM scale; develop scalable solvers (e.g., low-rank approximations, preconditioned conjugate gradients, sketching) and analyze time/memory costs.
- Convergence guarantees: Provide theoretical convergence guarantees for the regularized Newton updates (choice of α and step size η), including conditions ensuring iterates remain within the feasible dual set (interior of the convex hull) and avoid oscillations or divergence.
- Boundary behavior: Analyze the behavior when the dual point approaches the convex hull boundary (rank-deficient covariance), quantify how regularization-induced “entropy-increasing” detours affect off-target preservation, and design safeguards.
- Step-size and regularization selection: Provide principled, adaptive strategies (e.g., line search, trust-region) to choose η and α, and characterize sensitivity and robustness across tasks and contexts.
- Probe construction methods: Compare and formalize alternatives to mean-difference probes (e.g., logistic regression, SVMs, CCA, HSIC-based directions, causal probes) for producing β in the dual space and study their impact on off-target robustness.
- Alternative divergences and geometries: Investigate whether other divergences (e.g., Jensen–Shannon, α-divergences, Wasserstein) or Riemannian/Fisher-Rao metrics yield better empirical off-target preservation or more favorable steering trade-offs.
- Attention-level application: Extend dual steering to softmaxes in attention (query–key) and other internal softmax modules, and assess whether preserving off-target distributions at the output carries over to attention distributions.
- Temperature and calibration effects: Characterize how temperature scaling or logit biases alter the geometry (via ) and whether dual steering retains its robustness across different calibration regimes and decoding strategies.
- Tokenization and pairing biases: Develop methods to construct counterfactual token/image pairs robustly across subword tokenization, morphology, polysemy, and compositional visual attributes, including automatic detection of neutrals.
- Candidate set dependence (CLIP retrieval): Analyze how off-target preservation and steering quality vary with the retrieval pool (set of γ_y), and design methods that remain stable under changes in candidate sets or open-vocabulary expansions.
- Sequence-level effects: Study how dual steering applied at one step affects multi-step generation (accumulated drift, exposure bias), and design schedules that maintain off-target stability across long contexts.
- Generalization and OOD robustness: Evaluate across broader datasets, domains, languages, and adversarial prompts to assess how well dual steering generalizes and where it fails.
- Comparative baselines: Benchmark against stronger steering/editing methods (e.g., LoRA fine-tuning, causal direction methods, ROME/MEMIT, control vectors) on identical tasks, including human assessments of semantic fidelity and fluency.
- Downstream task impact: Measure the effect of dual steering on downstream performance (QA, summarization, captioning) and user-centric quality metrics, not just next-token or retrieval probabilities.
- Uniqueness and existence assumptions: Specify conditions ensuring existence/uniqueness of the KL projection on the hyperplane and examine how degeneracies (e.g., tied logits, low-rank γ_y structure) affect theoretical claims.
- Context dependence of concept directions: Investigate whether concept directions are globally consistent or vary across the manifold; if varying, develop geodesic “concept fields” or local-to-global stitching methods.
- Safety and misuse: Analyze how geometry-aware steering could be used or misused for harmful manipulations and propose safeguards or policy constraints compatible with the proposed framework.
- Reproducibility and hyperparameter guidance: Provide detailed protocols for setting t, η, α, stopping criteria, and diagnostics to detect failure modes; analyze sensitivity and report robust defaults.
- Causality claims: Validate claims of “off-target preservation” with causal evaluations (interventions and counterfactual tests) rather than correlational proxies, and connect the framework to causal abstraction formalisms.
Glossary
- Affine connections: A type of geometric structure that defines straightness on manifolds, used to define geodesics without a Riemannian metric. "These ``geodesics'' are not the shortest path with respect to a Riemannian metric, but rather they are defined by specific affine connections"
- Bregman divergence: A measure of dissimilarity associated with a convex function, generalizing squared Euclidean distance and KL divergence. "the right-hand side is the Bregman divergence induced by the convex function ."
- Bregman geometry (dually flat): The geometric structure induced by Bregman divergences, featuring dual affine coordinate systems. "We identify the natural geometry as a Bregman (dually flat) geometry."
- Concept-factorizable distribution: A distribution that decomposes into a concept component and an off-target component over paired and neutral outputs. "A probability distribution over is concept-factorizable with respect to if there exists a concept distribution over and an off-target distribution over such that"
- Convex conjugate: The dual function associated with a convex function via the Legendre transform, mapping between primal and dual coordinates. "where is a convex conjugate of over the image of :"
- Convex hull: The smallest convex set containing a collection of points; here, the feasible region for dual coordinates. "each dual vector must be in the convex hull of those items."
- Counterfactual pairs: Pairs of outputs differing only in the target binary concept, used to isolate and manipulate specific semantics. "we partition the output space into a set of counterfactual pairs corresponding to a binary concept "
- Dual interpolation (m-geodesic): Linear interpolation in the dual coordinate space that corresponds to mixing (forward KL minimization) of endpoint distributions. "the straight line between the dual coordinates and in the dual space is called an -geodesic:"
- Dual map: The gradient of the log-normalizer that maps primal parameters to expected sufficient statistics in the dual space. "the dual map is defined by the gradient of :"
- Dual space: The space of expected features (or sufficient statistics) associated with the primal parameter space via the dual map. "Together, these mappings provide a bijection between the primal space and the dual space ."
- Dual steering: Steering method that adds the probe direction in the dual space to minimally affect off-target behavior. "This observation motivates us to introduce dual steering, which adds the probe vector in the dual space:"
- e‑geodesic (primal interpolation): Linear interpolation in the primal parameter space that emphasizes shared mass (reverse KL minimization). "the straight line between them in the primal space is called an -geodesic:"
- Fisher‑Rao metric: A Riemannian metric on statistical manifolds derived from the Fisher information, capturing intrinsic curvature of probability models. "they pull back the Fisher-Rao metric in the parameter space to the latent space and find the shortest path (geodesic with respect to Levi-Civita connection)."
- Forward KL divergence: The KL divergence evaluated as KL(P||Q), penalizing omission of P’s mass in Q and promoting mixture-like behavior. "whereas the dual interpolation minimizes a weighted sum of forward KL divergences:"
- Hessian: The matrix of second derivatives of a scalar function; here, of the log-normalizer, governing local curvature and dual updates. "we can approximate the change in dual coordinates via the Hessian of the log-normalizer:"
- Hyperplane: A linear constraint set in parameter space used to specify target concept levels during steering. "Given a context embedding and a hyperplane "
- Information geometry: A field studying the differential-geometric structure of families of probability distributions and their parameters. "Information geometry provides a powerful framework for formalizing and studying the innate geometry of parameters of probability distributions"
- Kullback‑Leibler (KL) divergence: A measure of discrepancy between probability distributions central to defining geometry and interpolation behavior. "Our starting observation is that the Kullback-Leibler (KL) divergence between softmax distributions \Cref{eq:softmax} can be expressed as"
- Levi‑Civita connection: The canonical Riemannian connection used to define geodesics as shortest paths under a metric. "(geodesic with respect to Levi-Civita connection)"
- Linear probe: A linear classifier or regressor applied to representations to detect or control a concept. "We will assume that we have identified a linear probe that captures the concept."
- Logistic regression: A probabilistic linear model for binary outcomes used to formalize concept probes via sigmoid of linear scores. "This relation is basically the defining property of logistic regression, matching a standard approach to designing linear probes"
- Regularized Newton method: An optimization update that stabilizes ill-conditioned Newton steps by adding a positive-definite regularization. "To overcome this singularity, we employ a regularized Newton method as detailed in \Cref{alg:dual}."
- Reverse KL divergence: The KL divergence evaluated as KL(Q||P), penalizing assigning mass where P has little and emphasizing intersections. "The primal interpolation minimizes a weighted sum of reverse KL divergences:"
- Statistical manifold: A differentiable manifold of probability distributions endowed with geometric structures such as connections and metrics. "The - and -geodesics represent two distinct interpolation paths on the statistical manifold;"
Practical Applications
Immediate Applications
The paper’s findings and methods enable several deployable workflows that improve controllability and stability of softmax-based models (LLMs, CLIP-like models, RL policies) by exploiting information geometry rather than Euclidean assumptions.
- Robust inference-time steering for LLMs
- Sector: software, content generation, customer support, compliance
- Application: Use dual steering to increase/decrease a specific binary attribute (e.g., sentiment, tense, formality, language, toxicity) while preserving unrelated content (facts, entities, topic).
- Tools/Products: “SafeSteer” runtime hook for HuggingFace Transformers; dual-steering plugin that intercepts logits/unembeddings and applies regularized Newton updates during decoding.
- Assumptions/Dependencies: Requires access to hidden representations and unembedding weights; high-quality linear probes for the target concept; softmax over known candidate set; additional compute for solving linear systems.
- Attribute-preserving image retrieval and zero-shot classification
- Sector: e-commerce search, media, vision-language systems
- Application: Steer CLIP-like embeddings to toggle one attribute (e.g., dog→cat, blue→red) without disrupting other attributes (e.g., “+ bicycle,” background), improving search facet precision.
- Tools/Products: Query-embedding steering middleware for vector search; dual steering layer inside CLIP-based retrieval.
- Assumptions/Dependencies: Access to image/text embeddings and unembeddings; binary or contrastive concept probes; careful step-size/regularization for rank-deficient covariances.
- Counterfactual data generation with preserved off-target semantics
- Sector: ML evaluation, fairness/bias testing, academia
- Application: Use dual steering to generate controlled counterfactuals (e.g., gender swap, tense swap) while minimally changing everything else, enabling stronger causal evaluations and bias audits.
- Tools/Products: “Counterfact Kit” that pairs source/steered samples and logs off-target drift metrics (KL, rank stability, counterfactual mass).
- Assumptions/Dependencies: Good probe construction; concept-factorizability approximates; access to sampling from steered distributions.
- Auditing and interpretability via dual vs. primal interpolation
- Sector: ML governance, research
- Application: Use primal (AND) vs. dual (OR) interpolation to diagnose whether two prompts/contexts have overlapping vs. complementary outputs; identify entangled concepts.
- Tools/Products: “InterpScope” visualization that compares distributions along e- and m-geodesics; automated reports on intersection vs. union semantics.
- Assumptions/Dependencies: Access to embeddings and unembedding matrix; sufficient compute to sample and visualize distributions.
- Safer policy/behavior adjustment in reinforcement learning
- Sector: robotics, game AI, autonomous systems
- Application: For softmax action policies, raise or lower the probability of unsafe actions (or encourage safe ones) via dual steering to avoid undesired shifts in other actions.
- Tools/Products: “PolicySteer” wrapper that applies dual steering to logits pre-softmax during policy execution; safety monitor with off-target drift metrics.
- Assumptions/Dependencies: Policy represented by softmax over discrete actions; interpretable action concepts with probes; low-latency linear solves.
- RAG and summarization control with minimized off-target drift
- Sector: enterprise AI, knowledge management
- Application: Steer models to increase probability of citation tokens, section markers, or extractive spans while preserving topical content, reducing hallucinations and style drift.
- Tools/Products: Decoding-time controller for RAG that targets “citation present” or “verbatim extraction” probes; monitoring dashboards of off-target stability.
- Assumptions/Dependencies: Probes for structural features (citations, quotes); access to decoding internals; evaluation harness for off-target change.
- Content moderation and policy enforcement with locality guarantees
- Sector: platforms, compliance, advertising
- Application: Toggle disallowed attributes (e.g., profanity, personal data expression) while minimizing changes to allowed content; reduce overblocking by preserving neutral outputs.
- Tools/Products: Moderation control layer using dual steering for binary policy tags; rule-based orchestration of probes for composite policies.
- Assumptions/Dependencies: Reliable probes for policy dimensions; careful composition if multiple controls are applied; logging of off-target metrics for audits.
- Prompt blending and creative tools with semantics-aware mixing
- Sector: creative AI, design
- Application: Offer two interpolation modes: primal for “intersection” blends (common elements emphasized) and dual for “mixture” blends (union of features) in text or image generation.
- Tools/Products: “BlendModes” UX in creative apps that internally trace e- vs. m-geodesics; sliders mapped to t in the two geometries.
- Assumptions/Dependencies: Access to context representations and geodesic tracing; user-friendly probe presets or automatic discovery.
- MLOps monitoring for steering and probe quality
- Sector: ML infrastructure, QA
- Application: Deploy off-target drift metrics (KL divergence, rank stability, counterfactual mass) alongside target hit-rate to evaluate probes and steering setups during A/B tests.
- Tools/Products: “ProbeBench” and “SteerAudit” dashboards that integrate with inference logs.
- Assumptions/Dependencies: Telemetry on token/image distributions; labeled counterfactual pairs for chosen concepts.
- Privacy and redaction assistance with minimal content distortion
- Sector: legal, healthcare documentation, enterprise
- Application: Steer probability away from PII-bearing tokens or toward anonymized forms while preserving factual structure and meaning.
- Tools/Products: Redaction assistant that toggles PII concepts; audit logs of preserved off-target distributions.
- Assumptions/Dependencies: Probes for PII categories; policy-compliant evaluation; access to model internals.
Long-Term Applications
Beyond immediate integrations, the framework suggests broader tooling, training methodologies, and policy practices that leverage information geometry for controllability.
- Geometry-aware training and architectures
- Sector: AI research, foundation models
- Application: Incorporate information-geometric objectives (e.g., dual-space regularizers, off-target preservation losses) into fine-tuning or pretraining to bake in steerability.
- Tools/Products: “GeoTrain” modules that penalize off-target drift during concept supervision; natural-gradient or dual-connection optimizers.
- Assumptions/Dependencies: Differentiable access to dual mappings; scalable approximations for Hessians; new benchmarks.
- Multi-concept, constrained steering with guarantees
- Sector: compliance, enterprise AI
- Application: Simultaneously steer multiple binary concepts under explicit constraints on off-target divergence across a slate of protected attributes.
- Tools/Products: Constrained optimization layer in dual space (projected or augmented Lagrangian solvers); policy rule compilers to probes.
- Assumptions/Dependencies: High-quality, non-overlapping probe sets; feasible convex regions within dual-space hull; tractable solvers at inference time.
- Extending dual steering beyond the output layer
- Sector: research, applied AI
- Application: Pull back Fisher/dually flat structure from softmax layers to intermediate representations to enable layer-local steering with end-to-end guarantees.
- Tools/Products: Estimators for local Fisher pullbacks; layerwise surrogate dual mappings.
- Assumptions/Dependencies: Theoretical advances connecting hidden-layer geometry to output-space information geometry; stable numerical procedures.
- Closed-model and API-compatible surrogates
- Sector: SaaS, platform integrations
- Application: Approximate dual-space operations using observable logits and sampling when unembeddings are inaccessible (e.g., API-only LLMs).
- Tools/Products: Black-box covariance estimators (via top-k logits and Monte Carlo); reduced-rank steering modules.
- Assumptions/Dependencies: Adequate signal from limited logits; variance control via sampling; vendor terms permitting post-processing.
- Standardized controllability benchmarks and regulation
- Sector: policy, standards bodies, risk management
- Application: Define tests and thresholds for off-target drift (KL, rank stability, counterfactual mass) in safety-critical settings (finance, health, civic information).
- Tools/Products: Controllability certification suite; model cards that report steering metrics and bounds.
- Assumptions/Dependencies: Agreement on concepts/probes across domains; sector-specific risk matrices.
- Human-in-the-loop editing with locality guarantees
- Sector: productivity, creative tools
- Application: Editors that let users toggle aspects (tone, gendered references, tense) with provable minimal change elsewhere, useful for sensitive writing or localization.
- Tools/Products: Word processors and IDE plugins backed by dual steering; per-change diff plus off-target stability score.
- Assumptions/Dependencies: Robust probes for varied writing dimensions; latency acceptable for interactive editing.
- Healthcare and scientific decision support with calibrated adjustments
- Sector: healthcare, scientific discovery
- Application: Adjust diagnostic or hypothesis probabilities based on context factors (e.g., risk profile) while minimizing unintended shifts among other differentials.
- Tools/Products: Clinical decision support wrappers with dual steering; audit trails of off-target preservation for clinical safety review.
- Assumptions/Dependencies: Regulatory approval; rigorously validated probes; domain shift considerations.
- Education and personalization
- Sector: edtech
- Application: Adapt reading level, tone, or scaffolding style while preserving curricular content; toggle specific pedagogical strategies with minimal off-target shifts.
- Tools/Products: Tutor controllers with concept probes for difficulty, scaffolding, or language register.
- Assumptions/Dependencies: Probes trained on diverse educational data; fairness and accessibility evaluations.
- Autonomous systems with layered safety controls
- Sector: robotics, autonomous vehicles
- Application: Stack dual-steered policy filters to forbid narrow unsafe behavior classes while preserving task competence, with continuous monitoring of off-target action distributions.
- Tools/Products: Safety supervisor with multi-probe policy constraints and drift alarms.
- Assumptions/Dependencies: Robust mapping from safety concepts to action-space probes; real-time compute budgets.
- Probe discovery and concept-factorization research
- Sector: academia
- Application: Systematic methods to learn probes that satisfy concept-factorizability and generalize out-of-distribution; tests for when the assumption breaks.
- Tools/Products: Probe discovery pipelines; diagnostics for entanglement and factorization validity.
- Assumptions/Dependencies: Curated datasets of counterfactual pairs; theoretical advances in disentanglement.
Cross-cutting dependencies and assumptions
- High-quality linear probes: Many applications assume probes that generalize and accurately isolate a binary concept (logistic relation to representations). Weak probes reduce guarantees and can degrade outcomes.
- Concept-factorizability: The strongest robustness results assume distributions can be factorized into on-target and off-target components; this may hold approximately and warrants validation.
- Access to internals: Most immediate deployments require access to representations, unembeddings, and logits; closed-source APIs may require black-box approximations.
- Computational overhead: Regularized Newton updates involve solving linear systems per step; production use may need low-rank approximations, caching, or batching.
- Scope: Methods are most directly applicable to softmax-based distributions (LLM decoding, attention, contrastive retrieval, discrete-action policies); extensions to other settings require additional research.
Collections
Sign up for free to add this paper to one or more collections.