- The paper introduces RSIR, a recursive framework that bootstraps recommendation quality by generating and filtering synthetic user interactions.
- It employs fidelity control to ensure generated data remains on the user preference manifold, mitigating off-distribution drift and model bias.
- Empirical results show up to 14% recall improvements across benchmarks, demonstrating RSIR's robustness, scalability, and weak-to-strong transfer capability.
Recursive Self-Improvement with Fidelity Control in Recommender Systems
Introduction and Motivation
Conventional recommender systems suffer from chronic data sparsity—users interact with a minute subset of possible items, yielding brittle optimization and suboptimal generalization. Attempts to alleviate this via side information (metadata, LLM-generated labels) or naïve augmentation (reordering, insertion) introduce their own challenges: they are costly, may not respect user preference manifolds, or amplify model biases. The paper "Can Recommender Systems Teach Themselves? A Recursive Self-Improving Framework with Fidelity Control" (2602.15659) introduces the Recursive Self-Improving Recommendation (RSIR) framework, an architecture-agnostic, data-centric paradigm wherein a model recursively generates, filters, and trains on synthetic user interactions—bootstrapping its own generalization without external teachers.
The central thesis is that even weak recommenders encode latent knowledge sufficient to generate, after principled regularization, high-fidelity data that can catalyze cumulative self-improvement for themselves or more expressive architectures.
The RSIR Framework
The RSIR process is defined as a model-centric closed loop comprising four main stages at each recursive iteration: (1) model training on the current dataset, (2) synthetic interaction generation, (3) fidelity-based quality control, and (4) data augmentation and successor training.
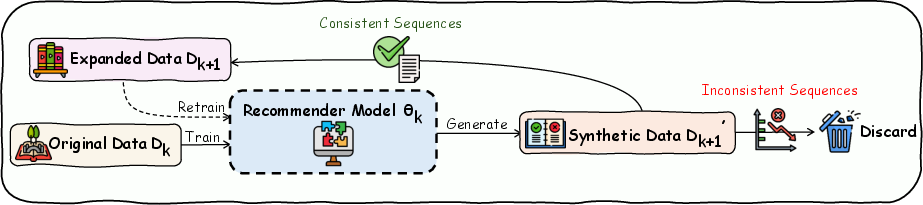
Figure 1: Overview of the RSIR framework, detailing the recursive generate-filter-augment-train loop with fidelity control.
Synthetic Sequence Generation. For each user's existing interaction su, the model autoregressively generates multiple synthetic continuations, employing a hybrid candidate pool for the next-item selection. With probability p, candidates are drawn from the user’s own history (exploitation); with probability $1-p$, from the global item corpus (exploration). Top-k sampling constrains diversity within plausible candidate sets.
Fidelity-Based Quality Control. Each generated step is only accepted if, after appending the item, at least one of that user’s real withheld items is still ranked among the model’s top τ predictions. If the constraint is violated, generation terminates. This ensures all synthetic data closely adheres to the user preference manifold, aggressively filtering off-distribution or bias-amplifying trajectories.
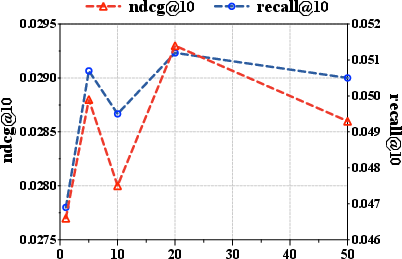
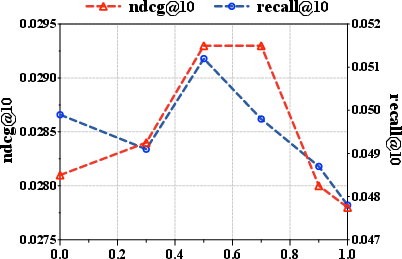
Figure 2: RSIR performance sensitivity as a function of the fidelity threshold τ; optimality is obtained at intermediate τ.
Theoretical Analysis: Implicit Regularization, Error Contraction, and Manifold Geometry
RSIR does more than regularize via classical smoothness; it enforces smoothness tangential to the empirical preference manifold. Mathematically, the fidelity check filters perturbations to lie in the manifold tangent space TsM, and the composite loss minimized at each iteration includes an implicit penalty:
Ω(θ)∝∥PM∇sfθ∥2
where PM is the orthogonal projector onto TsM.
This establishes RSIR as a data-driven, manifold-aware regularizer, contrasting with generic L2/Laplacian penalties that overly restrict expressiveness off-manifold.
Furthermore, the recursive dynamic yields a generalization error bound at iteration k+1:
E(θk+1)≤(1−λ)E0+λ[(1−p~k)ρE(θk)+p~kEmax]
With strict fidelity control (small p~k), self-generated data contracts error linearly each round until dominated by the (low) irreducible noise floor set by occasional fidelity violations.
Empirical Evaluation
Across Amazon-Toy, Amazon-Beauty, Amazon-Sport, and Yelp benchmarks—and across SASRec, CL4SRec, and HSTU backbones—RSIR delivers consistent, architecture-agnostic, statistically significant gains over both classical data augmentation (reordering, insertion) and recent learnable generative augmentation methods (ASReP, DiffuASR, DR4SR). Cumulative improvements reach up to ~14% recall lift after three iterations.
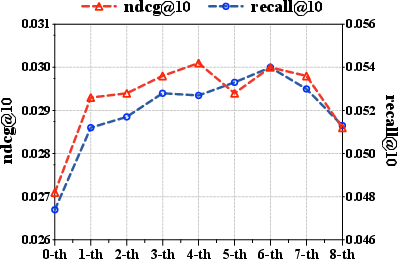
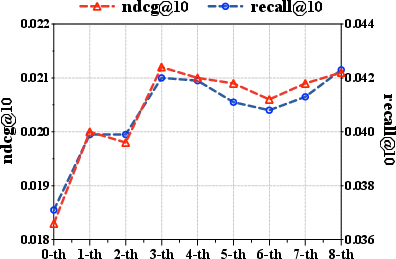
Figure 3: Performance improvement with RSIR on the Amazon-Sport dataset.
Performance gains are robust to whether the successor model is fine-tuned or initialized anew, confirming that densification, not mere memorization, underlies the improvement.
Ablation: Quality Control and Exploration
Without fidelity filtering, uncontrolled recursive generation yields catastrophic performance collapse within a few rounds due to error amplification and off-manifold drift. The importance of the exploration probability p is likewise validated—optimality arises at p≈0.5, balancing exploitation of proven interests with careful expansion. Both overly-strict (choking diversity) and overly-permissive (admitting noise) fidelity thresholds degrade performance.
Weak-to-Strong Transfer: Data Curricula
A central empirical finding is that synthetic data generated by weak models can still effect measurable improvement for strong successors (e.g., small Transformer generates data that boosts SOTA generative model). Stronger teachers amplify gains, but the benefit is not restricted to high-capacity models—implicitly regularized model-agnostic data densification fundamentally lowers the error floor.
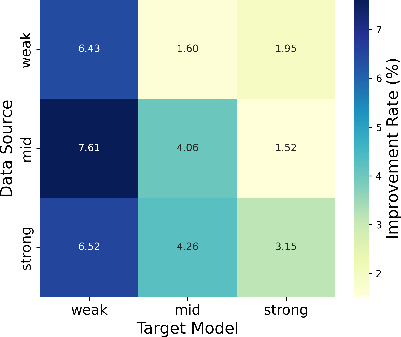
Figure 4: Improvement rate heatmap for weak-to-strong transfer; weaker teacher models still yield substantial student improvement, validating RSIR's utility beyond large models.
Quality Analysis of Generated Data
RSIR-trajectories not only increase data density (+342% over eight iterations), but substantially increase the generated data's Approximate Entropy, indicating information-richness and genuine diversity expansion, avoiding the degenerate modes introduced by insertion-type augmentation.
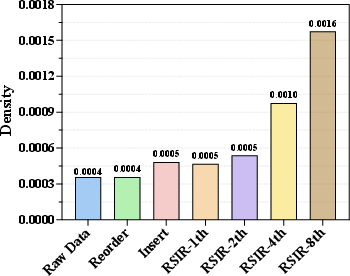
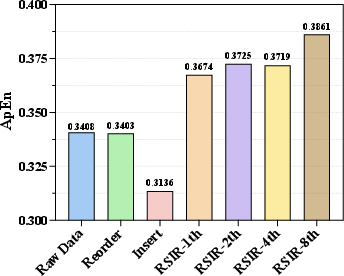
Figure 5: Data density increases sharply with each RSIR iteration, validating the framework's effectiveness at mitigating extreme sparsity.
Computational Complexity and Scalability
Per-iteration compute is dominated by model training—data generation is efficient, as synthetic sequence creation leverages cached autoregressive decoding and is truncated early thanks to the fidelity "break" condition. The cost of fidelity checks (potentially a MIPS over the vocabulary) is minimized via clustering-based or ANN-based acceleration. RSIR's end-to-end wall-clock time is competitive or superior to other advanced generative augmentation methods, remaining industrially practical even with retraining from scratch.
Robustness to Data Noise
RSIR exhibits enhanced robustness under growing annotation noise; its gains over baseline increase as the original interaction log is contaminated, confirming the effectiveness of the quality control as a denoising filter and as a credible practical safeguard.
Implications and Future Directions
The RSIR framework fundamentally repositions self-improvement from an emergent behavior of large, complex models to a model- and scale-agnostic regularization property deliverable via recursive, fidelity-constrained, closed-loop data generation and retraining. This opens a trajectory for:
- Efficient curriculum generation using weak or small-scale recommenders—crucial for industrial scenarios with limited deployment resources.
- Stackable improvement alongside external content-based, metadata, or LLM-injected augmentation; RSIR is not redundant with external knowledge.
- Scalable application in extremely sparse domains, as appropriate fidelity control and manifold targeting naturally mitigate distributional drift and prevent model collapse.
- Extensions to other generative and sequential modeling domains (e.g., vision, language) where user- or task-specific preference manifolds admit reliable fidelity-based filtering.
Conclusion
RSIR operationalizes recursive, self-regularizing data densification in recommender systems, delivering statistically significant, cumulative performance boosts by enforcing both diversity and high-fidelity adherence to user preference structure. The theoretical and empirical findings generalize across datasets, architectures, and augmentation baselines, setting a principled path towards robust self-improving systems unconstrained by the limitations of external data or teacher dependencies.
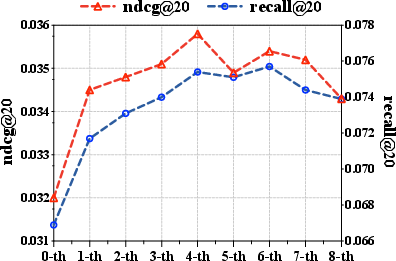
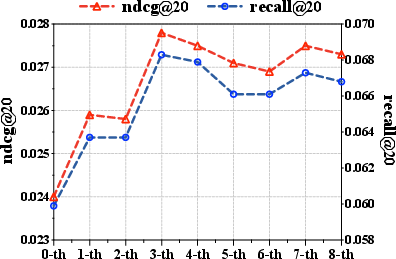
Figure 6: RSIR persistently outperforms baselines on Amazon-Sport, validating recursive multi-stage self-improvement.
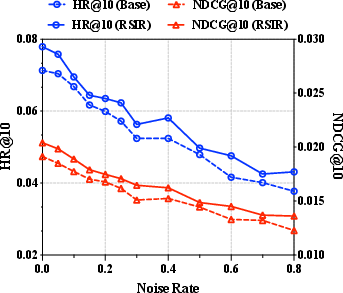
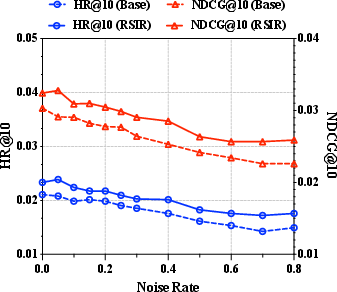
Figure 7: RSIR preserves performance stability and improvement even as interaction datasets are increasingly contaminated by noise.
Cited as: "Can Recommender Systems Teach Themselves? A Recursive Self-Improving Framework with Fidelity Control" (2602.15659)