MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Abstract: Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MeshMimic: Teaching Humanoid Robots from Regular Videos
What is this paper about?
This paper shows how to teach a humanoid robot to move over real, bumpy, and messy ground by learning directly from normal videos (like phone videos), instead of expensive motion-capture systems. The key idea is to recover both the person’s movement and the shape of the surrounding scene in 3D from a single video, then train a robot to copy those movements while respecting the terrain (so it doesn’t slip or walk through obstacles).
What questions are the researchers trying to answer?
- Can a robot learn human-like movements directly from regular videos without special suits or sensors?
- Can we also recover the 3D shape of the ground and objects so the robot knows where to step or grab?
- How do we clean up noisy video reconstructions to make sure feet really touch surfaces and don’t go through them?
- How can we transfer a human’s movement to a robot with different body proportions while keeping the same contacts (like where the foot lands)?
- Will a robot trained this way perform better on tricky, uneven terrains compared to older “flat-ground only” methods?
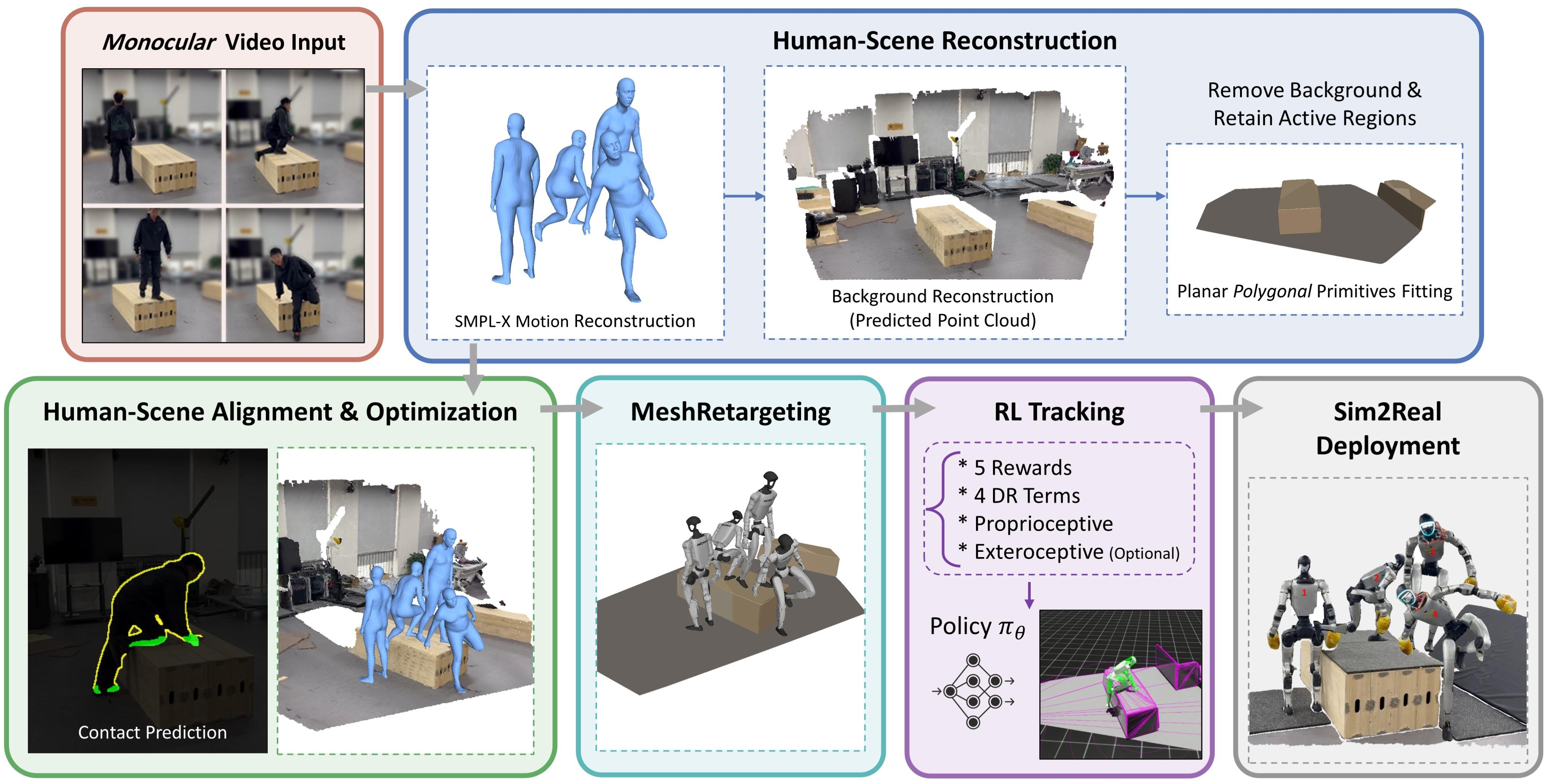
How does MeshMimic work? (In simple steps)
The whole process is “Real → Sim → Real”: learn from real video, train in simulation, then deploy on a real robot.
Step 1: From a single video to 3D motion and scene
- Monocular video: They start with a single camera video (like one phone video).
- Separate person and background: Using modern vision tools, they segment the human from the environment.
- Build a 3D scene: They reconstruct the scene as a 3D mesh (a digital shape of floors, steps, boxes, etc.).
- Build a 3D person: They turn the person into a 3D “puppet” with joints (think of a digital action figure) that matches the video pose at each frame.
Everyday analogy: Imagine flipping through a video like a flipbook, but instead of flat pictures, you rebuild the scene as a 3D diorama and the person as a poseable figurine.
Step 2: Make motion and scene match physically
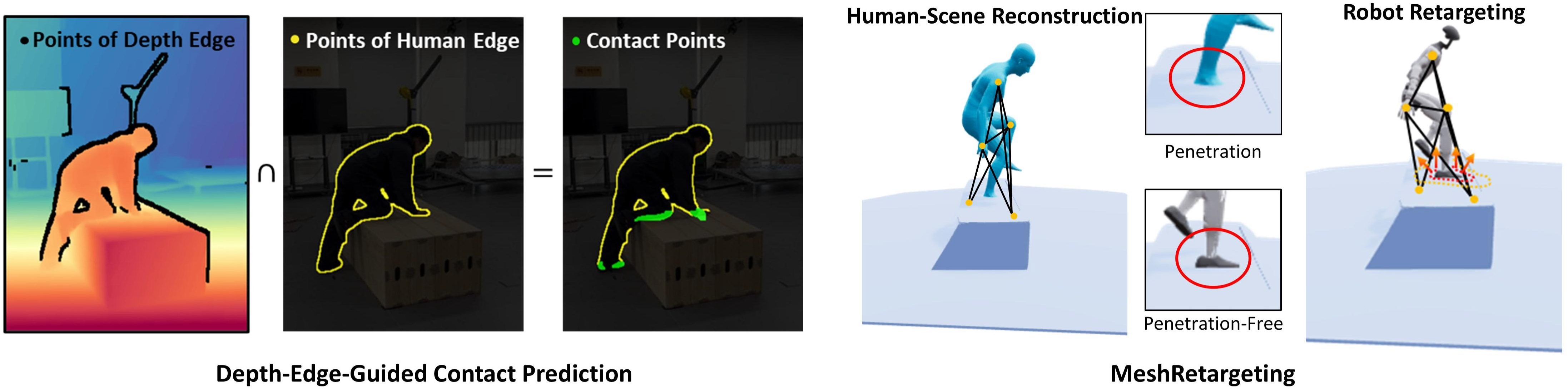
Video reconstructions are often noisy: feet drift (“foot skating”), slip, or sink into the ground. MeshMimic fixes this by optimizing for “kinematic consistency”—making sure movement and contact with the ground make sense.
- Contact detection: The system finds where the person should be touching surfaces (like foot on ground or hand on a box) by looking at edges in the depth and silhouette. This helps pick realistic contact points.
- Scale alignment: The video doesn’t know exact sizes (meters). They use known human body sizes to scale the whole scene to the right size.
- No-penetration checks: They build a 3D “distance map” of the scene (called a TSDF), which tells how far a point is from the surface; positive means outside, negative means inside the object. They push the human mesh out if any part is inside the terrain.
- Smooth trajectory: They reduce jitter so the movement looks natural over time.
- Foot snapping: If a foot is just barely above the surface, they gently move it onto the surface to avoid hovering.
Everyday analogy: Think of placing a toy figurine onto a model landscape: you nudge it so the feet land squarely on steps, not floating or clipping through.
Step 3: Retarget the motion to a robot body
Humans and robots have different proportions and joint limits. “Retargeting” means mapping the human movement to the robot’s body while keeping important contacts in place.
- Interaction mesh: They build a simple “scaffold” of points linking body and nearby terrain, then preserve its shape while adapting to the robot’s proportions. This helps keep feet and hands in the right places on uneven surfaces.
- Local focus: They sample lots of terrain points near the human, so small but important contacts (like a foot on an edge) are preserved, not lost.
- Collision correction: If the robot still penetrates the terrain after retargeting, a quick fix shifts the robot slightly to become collision-free.
Step 4: Train the robot in simulation, deploy in real life
- Reinforcement Learning (RL): The robot learns to follow the cleaned-up, contact-correct movements in a physics simulator by trial-and-error with rewards for tracking the motion well and staying stable.
- Minimal reward shaping: Because the references and scene are accurate, they don’t need fancy, hand-crafted rewards—just standard tracking and stability terms.
- Pretrain + finetune: They first train on lots of general motion, then finetune on the specific scene-interaction moves.
- Real robot: They run the learned policy on a Unitree G1 humanoid robot at 50 Hz and test on the same kinds of terrains captured in the videos.
What did they find, and why does it matter?
Better 3D reconstructions of motion and terrain
- Compared to recent methods (like VideoMimic), MeshMimic reconstructs the person’s movement and the scene more accurately:
- Lower joint position errors (94 vs 112 for local accuracy; 519 vs 697 for long-horizon stability; lower is better).
- More accurate scene geometry (Chamfer distance 0.61 vs 0.75; lower is better).
- Why it matters: Cleaner reconstructions mean fewer physics problems (less slipping, less sinking into surfaces) and better training data for the robot.
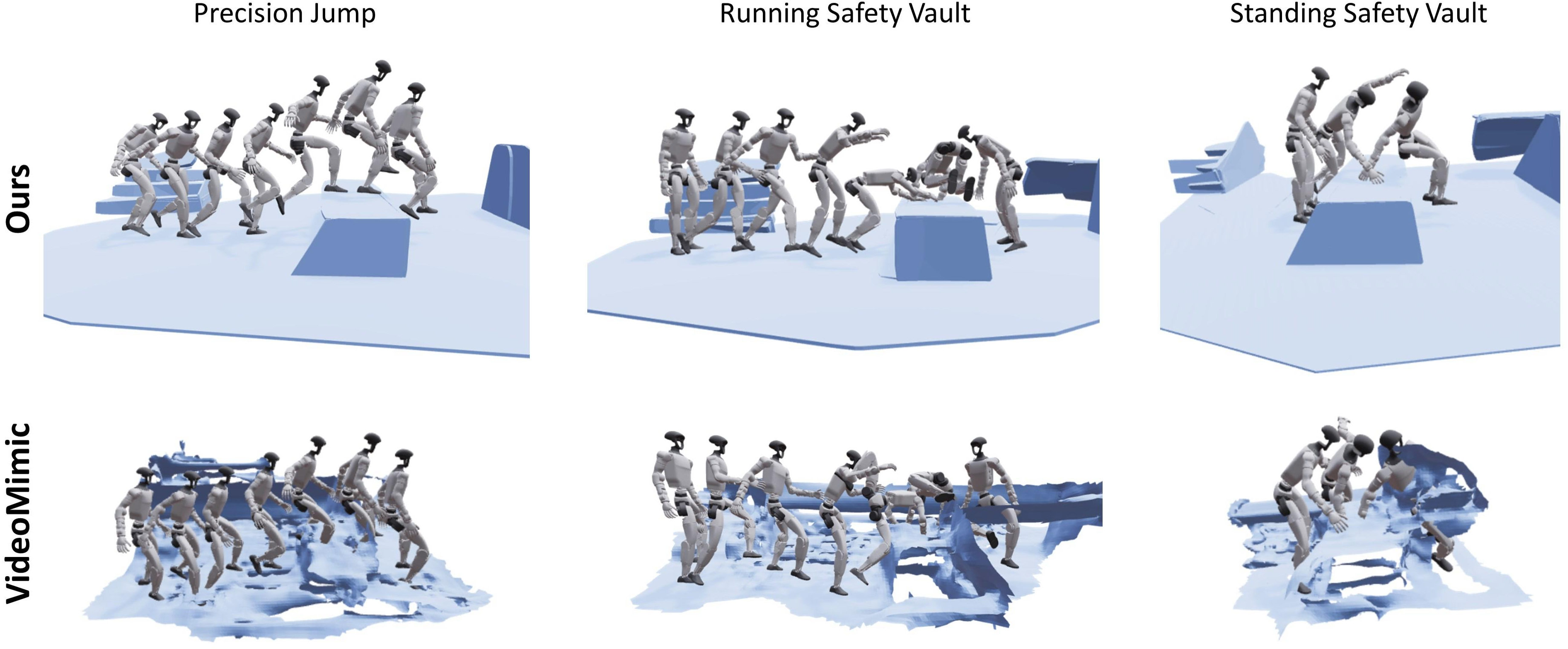
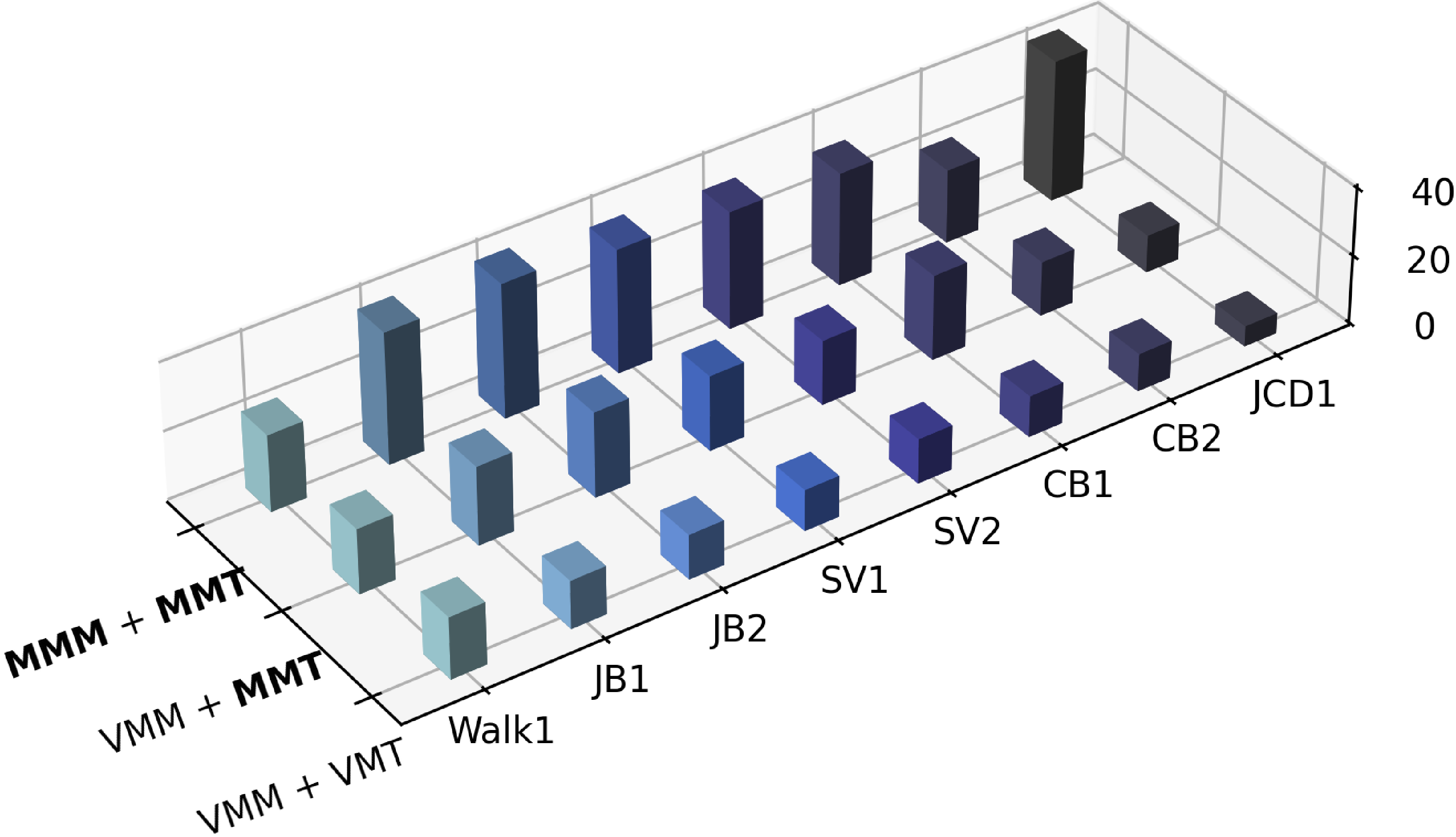
Stronger training and real-world performance
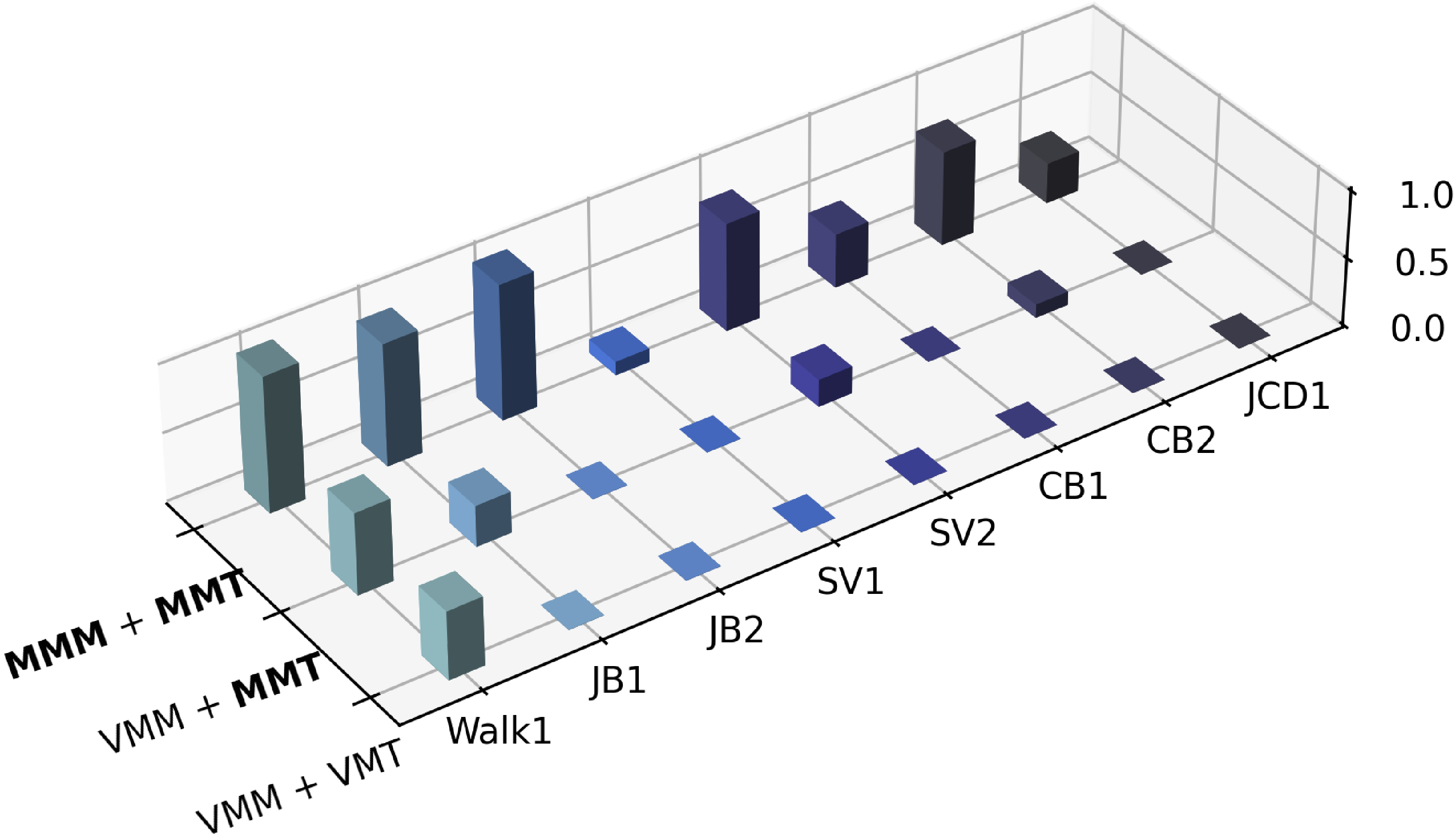
They tested on eight terrain-interaction tasks (walking, jumping onto boxes, climbing, and vaulting). Using MeshMimic motion and terrain (“MMM+MMT”) gave:
- Higher simulation training rewards.
- Higher real-world success rates across most tasks.
- Baselines struggled when scene geometry was messy (e.g., floating or hollow surfaces cause training failures or unsafe deployments).
Global position helps some tasks
- Adding the robot’s global torso position as an input helped long, multi-step tasks (reduced drift and improved success), but sometimes hurt very fast, dynamic moves (noise in position sensing can confuse the controller). This suggests global cues are great for long paths but can be risky for quick, explosive actions if the signal is noisy.
Why is this important?
- Learning from ordinary videos: No need for expensive motion-capture studios. You can learn from in-the-wild videos, making data collection much cheaper and more flexible.
- Scene-aware skills: Robots learn not just “how to move” but “how to move in this exact place,” stepping on edges, climbing up boxes, and vaulting over obstacles without breaking physics rules.
- Towards real-world agility: This paves the way for robots that can handle unpredictable, unstructured environments—useful for search-and-rescue, inspection, or helping in homes and outdoors.
Takeaway
MeshMimic shows a practical way to teach humanoid robots complex, terrain-aware movements by:
- Turning regular videos into accurate 3D human-and-scene reconstructions,
- Cleaning and aligning the motion to respect real-world contacts,
- Retargeting the movement to a robot while preserving crucial foot and hand placements,
- And training a controller that transfers to real hardware.
It’s a step toward affordable, scalable learning of real-world agility—moving from controlled lab floors to the varied, uneven places where robots will actually need to help.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research:
- Metric scale alignment is limited to a single global factor (α); per-frame or spatially varying scale inconsistencies (e.g., due to monocular reconstruction drift, rolling shutter, or lens distortion) are not modeled or corrected.
- Human reconstruction refinement optimizes only global translations; SMPL-X global orientations and joint angles remain fixed, leaving misestimated limb poses, contact normals, and local kinematics uncorrected.
- Depth-edge–guided contact prediction depends on silhouette boundaries and monocular depth edges; failure modes for non-silhouette contacts (e.g., palms, knees), heavy occlusions, specular/textureless surfaces, and low-light scenarios are unaddressed and unquantified.
- TSDF construction from monocular background points and normals lacks detail on normal estimation and volume resolution; sensitivity to TSDF voxel size, truncation parameters, and point-cloud noise is not analyzed.
- Scene representation via planar polygonal primitives may underfit highly curved, rough, or cluttered geometries; the trade-off between simplicity and contact fidelity versus more expressive models (e.g., 3DGS/NeRF-derived meshes or learned SDFs) remains unexplored.
- Contact quality is not directly evaluated; there are no metrics for contact timing accuracy, foot slip, stance duration, clearance margins, or penetration depth distributions compared to ground truth.
- MeshRetarget solves per-frame SQP without explicit temporal smoothness or dynamic feasibility constraints (e.g., ZMP, momentum, feasible contact forces), risking retargeted trajectories that are kinematically valid but dynamically infeasible.
- TSDF-based robot translation correction adjusts only global translation; rotational offsets, foot orientation alignment, and joint-level corrections are not addressed, potentially leaving residual tangential penetrations or poor contact normals.
- Terrain point sampling in the interaction mesh is described qualitatively; there is no ablation or rule for density, locality, or sampling strategy effects on retarget quality and robustness.
- Actor policy largely relies on reference tracking and lacks onboard exteroceptive terrain perception at runtime; the ability to adapt online to reconstruction errors, terrain changes, or unseen obstacles is not evaluated.
- Real deployment leverages external optical MoCap for global torso position; sim-to-real performance without external tracking (e.g., using onboard visual-inertial odometry) is not quantified.
- Generalization is tested on the same real scenes used for reconstruction; cross-scene transfer to new terrains, altered obstacle layouts, or material/friction changes is not evaluated.
- Domain randomization covers limited factors (e.g., materials, torso COM, small joint offsets, pushes); calibration and randomization of contact parameters (friction, restitution, compliance), sensor noise, and terrain pose variations are not studied.
- The privileged critic uses detailed scene information; robustness when both actor and critic are deprived of privileged inputs (or given noisy/partial exteroception) is untested.
- Reconstruction evaluation on SLOPER4D is limited to sequences where SAM2 tracking succeeds and to locomotion-related activities; performance under heavier occlusions, crowds, multi-agent scenes, or complex interactions with objects is not assessed.
- Quantitative evaluation omits computational cost, latency, and throughput; end-to-end pipeline timing, memory footprint, and feasibility for near real-time or online operation are not reported.
- Pretraining uses ~50 hours of non-interactive motion data; data composition, diversity, and domain mismatch effects on downstream interactive fine-tuning are not analyzed.
- Only a single robot platform (Unitree G1) is used; cross-morphology transfer (e.g., different link lengths, actuation limits, foot geometry) and policy retargeting across robots are not evaluated.
- Safety analysis for highly dynamic tasks (vaults, climbs) is limited; quantitative assessments of failure modes, torque saturation, thermal limits, and mechanical stress are missing.
- The effect of training reward design choices (weights, components) and kinematic-consistency loss hyperparameters (λ terms, τ thresholds) lacks ablations and sensitivity studies.
- Sim2sim validation (IsaacLab → MuJoCo) is used as a gating step, but the root causes of sim2sim failures (physics parameter mismatches, integrator differences, contact models) are not diagnosed or mitigated.
- Assumption of static, rigid terrains is implicit; deformable or movable surfaces, compliant obstacles, and environment changes over time are not considered in reconstruction, retargeting, or control.
- Long-horizon memory is limited to short observation histories (5 steps); the benefits of recurrent or transformer architectures for multi-contact sequences and drift mitigation are not explored.
- Robustness to camera artifacts (motion blur, rolling shutter), extreme viewpoints, and narrow-baseline videos is largely unquantified; failure cases and fallback strategies are not presented.
- Reproducibility and openness are unclear: code, models, and datasets for the full pipeline (including pi³, SAM3D integrations, TSDF tooling, training configs) are not specified as publicly available.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s methods (monocular video-to-skill pipeline, kinematic consistency optimization, MeshRetarget, TSDF-based contact checks, and Real–Sim–Real training with IsaacLab).
- Site-specific video-to-skill training for terrain-aware humanoid locomotion
- Description: Record a target site with a phone, reconstruct the terrain and human demonstration from the video, generate contact-consistent references, train in sim (IsaacLab), and deploy to a humanoid (e.g., Unitree G1) to execute the same path over the same obstacles.
- Sectors: robotics, manufacturing, logistics, construction, public safety training.
- Potential tools/workflows: “MeshMimic for IsaacLab” plugin; reference generator exporting TSDF, collision meshes, and retargeted trajectories; onboard 50 Hz controller deployment.
- Assumptions/dependencies: Mostly static terrain during deployment; sufficient robot actuation and similar friction to the reconstructed scene; short to medium horizon tasks can be done purely proprioceptively, while long-horizon tasks may require external global position (MoCap/VIO); GPU compute for reconstruction (3DGS/NeRF/SAM3D) and PPO training.
- On-site digital twin rehearsal for acceptance testing and QA
- Description: Convert a video of a target environment (warehouse aisles, temporary ramps, steps) into a physics-ready digital twin and rehearse robot runs in simulation before field tests.
- Sectors: robotics, manufacturing, logistics.
- Potential tools/workflows: TSDF-based penetration checks and “sim2sim gating” (IsaacLab → MuJoCo) as a go/no-go safety gate; automated regression tests for robot firmware updates.
- Assumptions/dependencies: Accurate scale alignment (metric priors), comparable surface compliance and friction; consistent lighting for robust recon.
- Contact-consistent character animation from monocular video
- Description: Use MeshRetarget to transfer human motion with terrain contacts (no “foot skating,” no penetration) to digital characters in games/VFX.
- Sectors: media/entertainment, gaming, AR/VR, software.
- Potential tools/workflows: DCC plugins (Blender/Maya) for “MeshRetarget SDK” that ingests a scene mesh and outputs contact-consistent animation; per-shot TSDF “foot snap” fix.
- Assumptions/dependencies: Rigid, mostly static environment; reasonable camera coverage; licensing/use of SAM3D/3DGS; GPU for fast turnaround.
- Low-cost academic data generation and benchmarking for terrain-aware imitation learning
- Description: Build contact-rich human–terrain datasets from in-the-wild videos for benchmarking WA-MPJPE/W-MPJPE and Chamfer metrics, and for training whole-body controllers.
- Sectors: academia (robotics, computer vision, RL), open-source toolchains.
- Potential tools/workflows: Public dataset curation pipeline; IsaacLab training recipes; ablation harness for contact prediction (depth-edge vs learned), TSDF penalties, and retargeting strategies.
- Assumptions/dependencies: Dataset curation and consent; stable releases of foundational 3D vision models; compute for processing and training.
- Sports and movement analytics on uneven terrains
- Description: Analyze parkour/running/climbing from broadcast or phone videos with reconstructed foot/hand contacts and terrain shape to quantify technique and risk.
- Sectors: sports science, coaching, biomechanics.
- Potential tools/workflows: “Contact heatmap” and “clearance diagnostics” derived from TSDF distances; per-frame stability/jitter metrics; progression tracking over similar obstacles.
- Assumptions/dependencies: Adequate video quality and viewpoints; static-ish obstacles; not for medical diagnosis without validation.
- AR/VR avatar grounding to real surfaces from a single video
- Description: Drive an avatar with environment-aware contacts that “stick” to stairs/furniture reconstructed from a short capture of a room.
- Sectors: AR/VR, social telepresence, consumer software.
- Potential tools/workflows: Mobile capture → mesh reconstruction → contact-aware retarget; runtime foot/hand TSDF snapping.
- Assumptions/dependencies: Rigid surfaces; mobile device capture quality; acceptable latency if used interactively.
- Factory/field readiness checks for humanoid capabilities
- Description: Standardized obstacle courses encoded from quick smartphone videos (boxes, steps, rails) to evaluate new robot builds or firmware against consistent contact-rich tasks.
- Sectors: robotics manufacturing, systems integration.
- Potential tools/workflows: “Skill cards” that package terrain meshes, references, and safety thresholds; automated pass/fail with success rate targets.
- Assumptions/dependencies: Repeatable environmental setups; consistent surface properties; access to training infrastructure.
- Teaching in robotics courses and bootcamps with minimal hardware
- Description: Students capture videos, reconstruct scenes, train policies, and evaluate sim-to-real performance on campus robots or in sim only.
- Sectors: education, workforce development.
- Potential tools/workflows: Course kits (Dockerized pipeline, IsaacLab configs); ready-made example scenes and tasks.
- Assumptions/dependencies: GPU access; campus safety policies for robot use; curated tasks for safe execution.
Long-Term Applications
The following applications benefit from the paper’s trajectory but require additional research, scaling, or productization (e.g., generalization, online perception, safety certification, and large-scale data engines).
- Generalized, vision-in-the-loop parkour/navigation over unseen terrains
- Description: Move beyond “same-scene” deployment toward robust closed-loop perception–planning–control that adapts contacts on unknown obstacles at runtime.
- Sectors: robotics (mobile manipulation, legged mobility), public safety.
- Potential tools/workflows: Onboard 3D recon + contact prediction; uncertainty-aware planning; robust domain randomization for friction/compliance; self-replay of new traversals.
- Assumptions/dependencies: Reliable online 3D scene estimation on embedded hardware; robust contact inference; safety fallbacks; advanced policy generalization.
- Disaster response and inspection from “learning what humans do” in the wild
- Description: Train robots to traverse rubble, ladders, steep terrain by learning from news/bodycam videos, then adapt to site-specific digital twins for deployment.
- Sectors: public safety, energy (plants/refineries), infrastructure inspection.
- Potential tools/workflows: Data engine ingesting public videos; hazard-aware TSDF penalties; safety envelopes and tethered trials; remote operator oversight.
- Assumptions/dependencies: Legal/ethical use of public media; severe domain shifts (dust, debris, deformables); stringent safety certification.
- Home assistance robots learning from casual household videos
- Description: Residents record “how to get around our home,” enabling a robot to learn stairs/thresholds/obstacle traversals aligned to that specific house.
- Sectors: consumer humanoids, smart home, eldercare.
- Potential tools/workflows: Phone app (“MeshMimic Studio”) to capture, reconstruct, and train cloud-side; nightly updates; safety gating before activation.
- Assumptions/dependencies: Privacy/consent management; dynamic environments (pets, moved furniture); strong runtime perception to handle change.
- Construction and facility navigation integrated with BIM/digital twins
- Description: Use BIM data refined by short site videos to teach robots scaffolding, catwalks, temporary ramps, and evolving layouts.
- Sectors: construction tech, industrial robotics, AEC.
- Potential tools/workflows: BIM-to-TSDF converters; continuous re-scan and retrain; schedule-aware skill updates as sites evolve.
- Assumptions/dependencies: Frequent changes and deformables; strict safety requirements; multi-sensor fusion for reliability.
- Rehabilitation and exoskeleton assistance from therapist demonstrations
- Description: Learn contact-rich gait and stair strategies from therapist videos, retargeted to exoskeletons or assistive humanoids.
- Sectors: healthcare, medical devices.
- Potential tools/workflows: Clinic capture kits; clinician-in-the-loop verification; patient-specific retargeting with safety bounds.
- Assumptions/dependencies: Regulatory approvals; clinical validation; precise force/torque control and fall protection.
- Cross-morphology skill libraries for manufacturers
- Description: Retarget the same human–terrain skills to diverse robot morphologies (different link lengths/DoFs) with contact invariance.
- Sectors: robotics manufacturing, platform ecosystems.
- Potential tools/workflows: “MeshRetarget SDK Pro” with constraint authoring and validation; marketplace of skill packs; automated tuning per morphology.
- Assumptions/dependencies: Hardware constraints (torque, ROM); friction/compliance mismatch; automated calibration procedures.
- Crowdsourced video-to-skill data engine and foundation policies
- Description: Large-scale ingestion of diverse terrains and motions to train general terrain-aware locomotion/manipulation policies.
- Sectors: AI platforms, robotics, software.
- Potential tools/workflows: Data quality scoring (MPJPE, TSDF metrics, sim2sim pass rates); deduplication; continual learning pipelines.
- Assumptions/dependencies: Data licensing, consent, and provenance; scalable compute; robust outlier handling.
- Standards, safety, and policy for video-based robot training and deployment
- Description: Define certification procedures that include sim2sim gating, contact violation thresholds, and success-rate minimums before field use.
- Sectors: policy/regulation, insurance, certification bodies.
- Potential tools/workflows: Compliance test suites (penetration/hover tolerances, failure case taxonomies); audit logs linking training data to deployed behaviors.
- Assumptions/dependencies: Cross-industry agreement on metrics and thresholds; privacy frameworks for in-the-wild video datasets.
- Productized cloud service for “video → skill → deployment”
- Description: End-to-end SaaS that turns uploaded videos into deployable robot skills, with APIs for simulation, safety checks, and over-the-air rollout.
- Sectors: software, robotics-as-a-service (RaaS).
- Potential tools/workflows: Fleet management integration; continuous monitoring of SR and safety; automatic rollback on degradation.
- Assumptions/dependencies: Customer data governance and security; robust versioning and reproducibility; heterogeneous robot support.
- Multi-contact loco-manipulation (beyond stepping) from video
- Description: Extend from hand-support vaults to environment-assisted manipulation (pulling/pushing, using railings/doors) with rich contact semantics.
- Sectors: service robotics, logistics, assistive robotics.
- Potential tools/workflows: Interaction mesh expansion to object affordances; grasp/contact classifiers coupled to TSDF geometry; hybrid task/motion RL.
- Assumptions/dependencies: Reliable object segmentation and dynamics; force-aware control; safety around humans and movable objects.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit, point-based 3D scene representation enabling high-quality, real-time rendering and reconstruction. "More recently, 3D Gaussian Splatting (3DGS) \cite{kerbl20233d} has emerged as a state-of-the-art representation, offering explicit, primitive-based modeling with real-time rendering capabilities."
- Asymmetric PPO: A reinforcement learning setup where the actor and critic receive different observations (e.g., actor: proprioceptive; critic: privileged), improving sample efficiency and stability. "We train the policy in IsaacLab~\cite{mittal2025isaac} using asymmetric PPO, where the actor operates on proprioceptive and reference features while the critic has access to privileged scene."
- Chamfer Distance: A metric measuring the average nearest-neighbor distance between two point sets, commonly used to compare reconstructed and ground-truth geometry. "For scene geometry, we report the Chamfer Distance (in meters) between the aligned predicted point cloud and the LiDAR point cloud, restricted to the RGB camera's field of view."
- Contact-invariant retargeting: A retargeting approach that preserves contact patterns when transferring motion from a source to a target morphology. "We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent."
- Degrees of Freedom (DoFs): Independent parameters defining the configuration of a kinematic system, such as a humanoid robot’s joints. "Developing controllers that can manage their high-dimensional degrees of freedom (DoFs) while executing human-like movements remains a profound challenge."
- Exteroceptive observations: Sensor-derived information about the external environment (e.g., terrain geometry) used by a control or learning system. "By converting these segmented instances into high-resolution collision meshes, we provide the necessary physical constraints and exteroceptive observations for downstream reinforcement learning."
- HQ-SAM (Segment Anything in High Quality): A high-quality variant of the Segment Anything model for robust, fine-grained segmentation. "The emergence of 3D-aware foundation models, such as SAM3D \cite{SAM3D} and Segment Anything in High Quality (HQ-SAM) \cite{ke2023segment}, has enabled robust instance-level segmentation within 3D space."
- Huber-style robust penalty: A loss function that behaves quadratically near zero and linearly for large residuals, stabilizing optimization under outliers. "Finally, we apply a Huber-style robust penalty to stabilize gradients:"
- Instant-NGP: A fast NeRF variant leveraging multi-resolution hash grids for accelerated neural rendering. "The field was further revolutionized by Neural Radiance Fields (NeRF) \cite{mildenhall2021nerf} and its accelerated variants like Instant-NGP \cite{muller2022instant}, which introduced differentiable volumetric representations."
- Interaction mesh: A graph/mesh constructed from agent and environment keypoints used to preserve spatial relations during retargeting. "Following OminiRetarget~\cite{omniretarget}, we preserve the spatial relationships among robot parts, manipulated objects, and terrain by minimizing the Laplacian deformation energy of an interaction mesh built from corresponding human/robot anatomical keypoints together with sampled object and terrain points."
- IsaacLab: A simulation and learning framework for robotics used to train control policies. "We train the policy in IsaacLab~\cite{mittal2025isaac} using asymmetric PPO"
- Kinematic Consistency Optimization: An optimization procedure enforcing physically plausible motion by penalizing violations like penetration and contact inconsistency. "To handle the inherent noise in visual reconstruction, we introduce a Kinematic Consistency Optimization algorithm to ensure physically plausible reference motions."
- Laplacian deformation energy: An energy term that preserves local geometric relationships during deformation/retargeting by penalizing deviations in Laplacian coordinates. "Following OminiRetarget~\cite{omniretarget}, we preserve the spatial relationships among robot parts, manipulated objects, and terrain by minimizing the Laplacian deformation energy of an interaction mesh"
- Multi-View Stereo (MVS): A method that reconstructs dense 3D geometry from multiple calibrated images. "Early milestones in Structure-from-Motion (SfM) and Multi-View Stereo (MVS), exemplified by frameworks like COLMAP \cite{fisher2021colmap} and \cite{schonberger2016structure}, laid the foundation for spatial mapping but often struggled with textureless surfaces and dynamic occlusions common in real-world robotic environments."
- Neural Radiance Fields (NeRF): A neural volumetric rendering approach that models view-dependent appearance and density for 3D scenes. "The field was further revolutionized by Neural Radiance Fields (NeRF) \cite{mildenhall2021nerf} and its accelerated variants like Instant-NGP \cite{muller2022instant}, which introduced differentiable volumetric representations."
- Proprioceptive observations: Internal sensor readings of the robot (e.g., joint positions/velocities, IMU) used by control policies. "We train the policy in IsaacLab~\cite{mittal2025isaac} using asymmetric PPO, where the actor operates on proprioceptive and reference features while the critic has access to privileged scene."
- SAM2: A video-capable extension of Segment Anything enabling tracking/association across frames. "For the human, we detect the target person using ViTDet~\cite{ViTDet} and associate the identity across frames via SAM2~\cite{SAM2}."
- SAM3D: A 3D-aware Segment Anything model used to reconstruct human geometry and motion from images. "Given the tracked person instances, we reconstruct per-frame human body geometry and motion using SAM3D~\cite{SAM3D}."
- SMPL-X: A parametric human body model with expressive face and hand articulation used for consistent 3D pose/shape representation. "Specifically, we follow the official SAM3D-Body pipeline: we convert the intermediate MHR representation to SMPL-X~\cite{SMPL-X}, yielding per-frame local pose parameters"
- SQP-style optimizer (Sequential Quadratic Programming): An iterative constrained optimization method solving a sequence of quadratic subproblems. "We solve for the robot configuration per frame with an SQP-style optimizer, under hard constraints for collision avoidance, joint/velocity limits, and stance-foot anchoring to prevent foot skating."
- Structure-from-Motion (SfM): A technique to estimate camera poses and sparse 3D structure from multiple images. "Early milestones in Structure-from-Motion (SfM) and Multi-View Stereo (MVS), exemplified by frameworks like COLMAP \cite{fisher2021colmap} and \cite{schonberger2016structure}, laid the foundation for spatial mapping but often struggled with textureless surfaces and dynamic occlusions common in real-world robotic environments."
- Trilinear sampling: An interpolation method in 3D grids used to sample values (e.g., SDF) at arbitrary points. "We then query the TSDF at all world-space human vertices using trilinear sampling."
- TSDF (Truncated Signed Distance Function): A voxel grid storing truncated signed distances to surfaces, widely used for collision and penetration checks. "To discourage the human mesh from intersecting scene geometry, we construct a TSDF volume~\cite{volumetric, kinectfusion} from the background point cloud and oriented normals."
- WA-MPJPE (World-frame Aligned MPJPE): A pose error metric aligning an entire sequence segment to ground truth to evaluate local accuracy. "For human trajectories, we report World-frame Mean Per Joint Position Error (W-MPJPE) and World-frame Aligned MPJPE (WA-MPJPE)."
- WBC (Whole-Body Control): A control paradigm coordinating all robot limbs/joints to achieve complex tasks with stability and contact handling. "By training with terrain-optimized reference trajectories, the whole-body controller (WBC) internalizes the interaction priors necessary for complex environments."
- W-MPJPE (World-frame Mean Per Joint Position Error): A global pose error metric aligning only initial frames, emphasizing long-horizon consistency. "For human trajectories, we report World-frame Mean Per Joint Position Error (W-MPJPE) and World-frame Aligned MPJPE (WA-MPJPE)."
Collections
Sign up for free to add this paper to one or more collections.