CrispEdit: Low-Curvature Projections for Scalable Non-Destructive LLM Editing
Abstract: A central challenge in LLM editing is capability preservation: methods that successfully change targeted behavior can quietly game the editing proxy and corrupt general capabilities, producing degenerate behaviors reminiscent of proxy/reward hacking. We present CrispEdit, a scalable and principled second-order editing algorithm that treats capability preservation as an explicit constraint, unifying and generalizing several existing editing approaches. CrispEdit formulates editing as constrained optimization and enforces the constraint by projecting edit updates onto the low-curvature subspace of the capability-loss landscape. At the crux of CrispEdit is expressing capability constraint via Bregman divergence, whose quadratic form yields the Gauss-Newton Hessian exactly and even when the base model is not trained to convergence. We make this second-order procedure efficient at the LLM scale using Kronecker-factored approximate curvature (K-FAC) and a novel matrix-free projector that exploits Kronecker structure to avoid constructing massive projection matrices. Across standard model-editing benchmarks, CrispEdit achieves high edit success while keeping capability degradation below 1% on average across datasets, significantly improving over prior editors.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about “editing” LLMs in a way that fixes or updates specific facts or behaviors without breaking everything else the model already does well. The authors introduce a method called CrispEdit (sometimes labeled “black” in their figures) that makes small, carefully chosen changes to a model so it learns the new thing while keeping its general skills—like reasoning, following instructions, and being truthful—nearly unchanged.
What questions are the authors trying to answer?
Here are the main questions the paper tackles:
- How can we change a model’s behavior in a targeted way (for example, correct a fact) without damaging its overall abilities?
- Can we enforce “don’t break the model’s skills” as a strict, built-in rule instead of hoping it happens?
- How do we make this work at the scale of big LLMs, fast enough to handle lots of edits?
How does their method work?
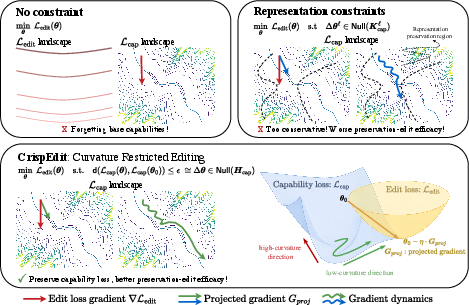
Think of a model’s behavior like walking around a giant landscape of hills and valleys, where “height” means how badly the model performs (loss). Good performance sits in low, flat valleys. If you move in a steep direction, performance gets worse fast; if you move along the flat valley floor, performance doesn’t change much.
CrispEdit tries to make edits by moving the model’s parameters along the “flat” directions—the gentle directions that don’t hurt its general abilities.
Big idea: Move only in gentle directions (low curvature)
- “Curvature” tells you how quickly things get worse if you move in a certain direction. High curvature = steep hill; low curvature = flat valley.
- CrispEdit finds the low-curvature directions tied to the model’s general skills (its “capabilities”) and projects its edit updates into those directions. In plain terms: it only lets the update push the model where it won’t damage its broad abilities.
Measuring “gentle” without needing a perfectly trained base model
- Many math tools for curvature assume the original model is trained to perfection, which isn’t true in practice.
- To avoid this, the authors measure the change to capabilities using something called Bregman divergence. Don’t worry about the name—what matters is that it gives a dependable way to describe how much the model’s behavior changes even if the starting model isn’t perfect.
- With this choice, the method uses a reliable “curvature” matrix called the Gauss–Newton (GN) matrix (a practical stand-in for true curvature), which works well for large neural networks.
Making it fast and scalable (so it works for big LLMs)
- Problem: These curvature matrices are huge—far too big to store or multiply directly for billion-parameter models.
- Solution 1: Use K-FAC (Kronecker-Factored Approximate Curvature). This breaks the giant curvature matrix into many small pieces that are much easier to handle.
- Solution 2: A “matrix-free projector.” Instead of building a massive projector matrix, they: 1) rotate the update into a compact “eigen” space, 2) mask out the “steep” parts, 3) rotate back. This achieves the same effect with a fraction of the memory and compute.
Batch and sequential editing
- Batch editing: apply many edits at once. CrispEdit precomputes the curvature info once and reuses it, making lots of edits fast.
- Sequential editing: apply edits one after another over time. CrispEdit updates its small K-FAC statistics after each round, so it can keep both old capabilities and previous edits while adding new ones—without storing all past data.
How this compares to other approaches
- Some methods change many parameters aggressively and often hurt general skills (“capability degradation”).
- Other methods are overly cautious and restrict edits too much (for example, only changing certain internal “representations”), which can block successful fixes.
- The authors show that those cautious methods are actually solving a stricter, smaller version of the problem than CrispEdit, which is why they often struggle to balance “fix the thing” vs. “don’t break the rest.”
What did they find?
The authors run two kinds of tests: small controlled tests and large LLM tests.
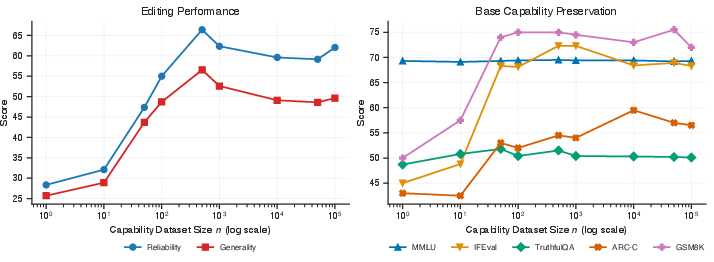
- Small test (images): They pretrain a small image model on MNIST (handwritten digits), then try to fine-tune it on Fashion-MNIST (clothing images) while keeping the digit skills. Projecting updates into low-curvature directions preserves the original digit performance much better than other heuristics. Their fast approximations (K-FAC) closely match the ideal curvature-based behavior.
- Large-scale LLM tests:
- Datasets: ZsRE, CounterFact, and WikiBigEdit—standard model editing benchmarks.
- Evaluation: WILD (a more realistic test that uses natural generation and an LLM judge) to check:
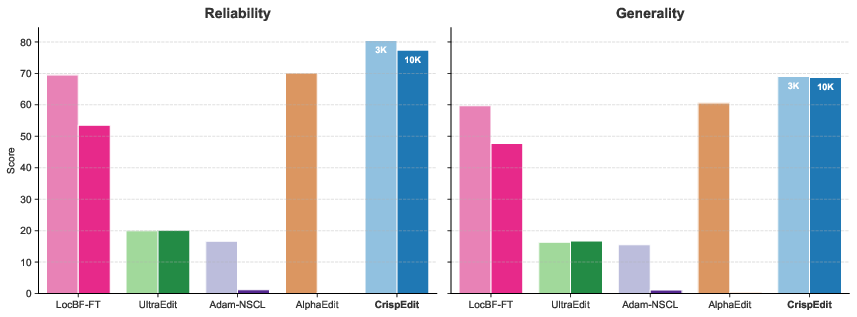
- Reliability: Does the edit fix the intended behavior?
- Generalization: Does the fix work across different but related prompts?
- Capability preservation: Do general skills (like MMLU, GSM8K, ARC-C, TruthfulQA, IFEval) stay intact?
- Results: CrispEdit consistently achieves high edit success and keeps capability loss very low (on average below ~1% across datasets), outperforming many prior editors that either break the model’s skills or don’t generalize well.
- Speed: With curvature info cached, they report applying 3,000 edits in about six minutes on a single NVIDIA A40 GPU—fast enough to be practical.
Why this matters: These results show a better balance—edits that work in realistic settings without silently harming the model’s overall strengths.
Why does this matter?
As facts change, rules evolve, and safety concerns arise, we need to update models quickly without retraining them from scratch. CrispEdit:
- makes targeted updates that “do no harm” to general abilities,
- scales to modern, huge LLMs,
- supports both one-time and ongoing edits,
- and reduces the risk of “reward hacking” or “proxy hacking,” where the model seems to pass tests but actually loses broader competence.
In short, this research provides a practical, principled way to keep AI systems accurate and safe as the world changes—helping them learn new facts or behaviors while staying reliable at everything else they already do well.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that the paper does not resolve, intended to guide future research:
- Theoretical guarantees on constraint satisfaction
- No formal bounds on capability-loss increase when using projected updates (with Bregman/GNH and K-FAC approximations), nor conditions under which the ε-constraint in the original problem is actually enforced.
- Absence of convergence guarantees for the projected gradient procedure (especially with approximate, layerwise, block-diagonal curvature and nonstationary objectives).
- Validity and scope of the Bregman/Gauss–Newton formulation
- The claim that the Bregman quadratic “yields the Gauss–Newton Hessian exactly” is not characterized for general losses and architectures (beyond softmax cross-entropy); implications for RLHF, DPO, sequence-level, or non-likelihood objectives are unstudied.
- Lack of analysis on how far from θ0 the local quadratic/Bregman approximation remains accurate during editing (i.e., trust-region radii or drift thresholds for LLM-scale updates).
- Approximation error of K-FAC and its impact
- No quantitative assessment of how K-FAC approximation error (block-diagonality, factorization noise, finite-sample estimates) translates into capability degradation or edit failure.
- No sensitivity analysis to K-FAC hyperparameters (e.g., damping, moving averages) and to the size/composition of the capability dataset used to estimate factors.
- Construction and representativeness of the capability dataset D_cap
- The paper primarily uses Wikipedia samples to estimate capability curvature while evaluating preservation on diverse tasks (reasoning, instruction following, truthfulness); the mismatch and its effects are not assessed.
- No guidance on D_cap size, domain coverage, or sampling strategy to preserve targeted capability portfolios; no ablations on how D_cap composition alters the preservation–edit trade-off.
- How to maintain privacy/compliance when D_cap must reflect sensitive capabilities (e.g., enterprise instruction patterns) is left open.
- Hyperparameter selection and adaptivity
- No principled method to set ε or the energy threshold γ; no budgeted tuning procedure that balances edit efficacy against capability preservation without expensive grid searches.
- Lack of adaptive γ or per-layer masking schemes that respond to per-edit curvature alignment or evolving curvature during training.
- Robustness to parameter drift and projector staleness
- Unlike the small-scale experiment (where the projector is periodically recomputed), LLM-scale experiments do not analyze how often curvature caches must be refreshed to keep projections valid under drift.
- No criteria or diagnostics for when cached curvature becomes stale and starts violating the preservation constraint.
- Layer coverage and edit locality
- Experiments focus on a handful of MLP down-projection layers; it is unclear how results translate to attention layers, embeddings, layer norms, or broader parameter subsets.
- No study of which layers benefit most from low-curvature projections for different edit types (factual inserts, behavior removal, stylistic changes).
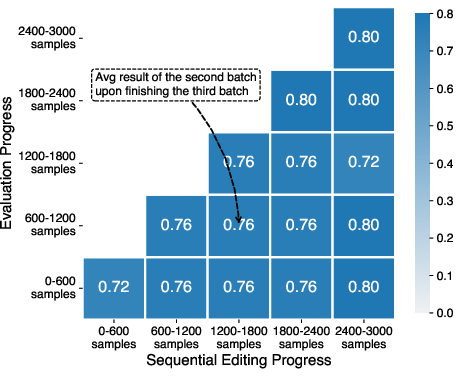
- Sequential editing at scale
- The proposed online projector update algorithm is not empirically stress-tested with long edit sequences, large K, or diverse/edit-conflicting batches.
- Open questions remain about catastrophic forgetting of prior edits, order effects, conflict resolution among edits, and compounding approximation errors across rounds.
- Generalization and out-of-domain behavior
- Generalization is evaluated on paraphrases and limited contexts; resilience across longer contexts, tool use, retrieval-augmented settings, multi-hop reasoning, and distribution shifts is not assessed.
- No evaluation in multilingual or multi-domain scenarios to see whether projections inadvertently bias toward high-density domains in D_cap.
- Safety and removal edits
- Editing for removal/mitigation of unsafe behaviors (as opposed to insertion) is not systematically evaluated; how low-curvature projections interact with alignment layers (e.g., RLHF adapters) is unknown.
- Potential attack surface: can malicious edits exploit low-curvature directions to subtly degrade capabilities that are poorly represented in D_cap?
- Calibration, consistency, and reliability metrics
- Effects on calibration, factual consistency, toxicity, and hallucination beyond TruthfulQA are not measured; tail-risk of rare but severe degradations is unquantified.
- Runtime, memory, and scalability limits
- Cache construction cost (time/compute to build K-FAC factors and eigensystems) is not isolated from edit-time speedups; amortization curves over many edits are not reported.
- Scalability to much larger models (70B+, MoE) and multi-modal models (VLMs) is not demonstrated; memory pressure of storing per-layer eigenbases and masks at that scale is unquantified.
- Constraint tightness vs. edit success trade-off
- Failure modes when the capability curvature is close to full-rank (i.e., few “safe” directions) are not discussed; fallback strategies (e.g., trust-region line searches, local reweighting, or mixed penalties) are undeveloped.
- No analysis of per-edit curvature alignment: how often does the edit gradient lie mostly in high-curvature space, and what strategies improve feasibility in those cases?
- Comparisons and ablations
- Missing ablations on: number of edited layers, per-layer γ thresholds, projector re-estimation frequency, D_cap size, and different capability corpora.
- No comparison against alternative second-order editors that use low-rank Hessian sketches or subspace tracking beyond K-FAC/EK-FAC.
- Formal relation to representation-level constraints
- Proposition 1 shows Null(K_cap) ⊂ Null(G_cap) in a specific setting; conditions for tightness, extensions to attention layers/transformers, and implications for combined representation+curvature constraints remain open.
- Optimization details and optimizer interactions
- The interaction between projection and adaptive optimizers (e.g., Adam’s momentum and second-moment estimates) is not explored; projected-Adam vs projected-SGD may behave differently.
- No study of step-size schedules or trust-region methods that explicitly control capability-loss increments per step.
- Edit types and task diversity
- Edits are evaluated primarily on factual datasets (ZsRE, CounterFact, WikiBigEdit); effectiveness on reasoning edits, tool-use behaviors, style/persona edits, and programmatic constraints (e.g., structured outputs) is not reported.
- Distributional and fairness considerations
- It is unknown whether curvature-based projections systematically under-preserve low-resource domains or minority-language capabilities if D_cap under-represents them.
- Reparameterization and invariance
- Projections in parameter space may not be invariant to reparameterizations; whether a natural-gradient-inspired projector (metric-aware) would yield better invariance is an open question.
- Compatibility with PEFT and deployment constraints
- How to integrate black with parameter-efficient methods (e.g., LoRA adapters) or quantized/low-precision models used in deployment is not addressed.
- Worst-case guarantees and certification
- No worst-case or certified bounds on capability degradation under bounded edit norms or after many sequential edits; lack of certification hinders high-stakes deployment.
- Conflict detection and governance
- No mechanism is provided for detecting and resolving conflicting edits (either within a batch or across time) or for attributing which edits caused which capability changes.
- Extensions beyond text
- The approach is shown on a small vision model for tractability and on LLMs for language; extensions to multi-modal and code-generation models (with different losses/objectives) are open.
Practical Applications
Immediate Applications
The following items translate the paper’s findings into concrete, deployable use cases across industry, academia, policy, and daily life. Each item includes sectors, potential tools/workflows, and key dependencies that affect feasibility.
- Enterprise knowledge patching for production LLMs
- Sectors: software, e-commerce, customer support
- What to deploy: rapidly insert updated product details, shipment policies, pricing, and FAQs via constrained edits that preserve reasoning, instruction-following, and fluency
- Tools/workflows: precompute K-FAC curvature caches on a representative capability dataset (e.g., internal wiki, support logs), batch edits using CrispEdit’s matrix-free projector, WILD-style autoregressive eval as a gating step, patch rollouts with rollback if capability metrics drop
- Dependencies: access to finetunable model weights; a domain-representative capability set; GPU resources to compute caches once; compatible loss (e.g., cross-entropy) and differentiable forward path; selection of suitable gamma/epsilon thresholds
- Safety hotfixes to remove unsafe behaviors without collateral damage
- Sectors: trust & safety, social platforms, consumer apps
- What to deploy: targeted edits that suppress unsafe outputs (e.g., disallowed instructions), while preserving broader skills and avoiding proxy/reward hacking side effects
- Tools/workflows: safety-focused capability dataset for curvature estimation, edit-specific prompts, matrix-free low-curvature projection for updates, LLM-as-a-judge with WILD for efficacy and generalization checks
- Dependencies: curated safety datasets; access to editable layers; careful thresholding to avoid over-constraining useful behavior; human-in-the-loop review for sensitive domains
- Regulatory and policy compliance updates
- Sectors: finance, healthcare, energy, education
- What to deploy: insert or correct guidance reflecting newly issued regulations, practice guidelines, or compliance rules without retraining from scratch
- Tools/workflows: compliance-curated capability datasets (e.g., regulations, clinical guidelines), edit queues with audit logs, edit “budgets” defined by epsilon (capability loss tolerance) and gamma (curvature energy threshold), periodic re-evaluation on diverse capability benchmarks
- Dependencies: domain-specific capability data; governance procedures (tracking edits, approvals); model access under compliance constraints; regulator-ready documentation of capability preservation
- Stable personalization and brand voice tuning
- Sectors: marketing, media, enterprise communications
- What to deploy: adjust tone, style, and brand-specific phrasing while maintaining base factual and reasoning capabilities
- Tools/workflows: sequential edits per client or campaign using online K-FAC factor updates; multi-tenant curvature caches; WILD-based testing in paraphrased contexts
- Dependencies: persistent storage for curvature stats; per-client capability slices to avoid cross-tenant interference; privacy controls for personalization data
- Code assistant patching for API and library changes
- Sectors: software engineering, DevOps
- What to deploy: update suggestions, examples, and completions to reflect deprecations or new APIs while keeping chain-of-thought and debugging competency intact
- Tools/workflows: capability sets built from codebases and doc corpora; batch edits with matrix-free projection; unit/integration tests as a capability proxy; continuous monitoring of reasoning benchmarks
- Dependencies: access to weights and target layers; domain-representative code datasets; alignment of loss and evaluation regimes; CI/CD integration
- Localization and multilingual fact updates
- Sectors: global product operations, education
- What to deploy: update region-specific facts and terminology across languages with minimal impact on general multilingual skills
- Tools/workflows: per-language curvature caches; batched edits per locale; multilingual WILD evaluation; automated canary checks before full rollout
- Dependencies: adequate multilingual capability datasets; language-specific tuning of thresholds; storage/computational overhead per locale
- LLMOps “edit pipeline” and patch management
- Sectors: platform teams, model operations
- What to deploy: standardized workflows for curvature cache precomputation, batched/sequential edits, matrix-free projection, and WILD-based gating
- Tools/workflows: a “curvature statistics service” (cache-once, reuse-many-edits), edit queues, rollback mechanisms, dashboarding of capability degradation (<1% targets), integration with EasyEdit/WILD
- Dependencies: engineering investment in ops tooling; monitoring and alerting; GPU scheduling; clear SLOs for capability preservation
- Academic experimentation and benchmarking of editing vs capability trade-offs
- Sectors: academia, research labs
- What to deploy: reproducible evaluation of second-order constraints, Bregman/Gauss-Newton formulations, and K-FAC approximations on open benchmarks
- Tools/workflows: public datasets (ZsRE, CounterFact, WikiBigEdit), WILD protocol for realistic evaluation, ablations of gamma thresholds and edited layers
- Dependencies: model access and compute; careful selection of capability proxies to avoid overfitting to the cache corpus; transparent reporting
- Personal assistant updates for daily life without forgetting
- Sectors: consumer apps, productivity
- What to deploy: inject user-specific facts (new address, preferences, devices) while preserving general conversational and planning abilities
- Tools/workflows: small personal capability set (emails, calendars) to compute curvature caches; on-device or privacy-preserving server-side editing; WILD-style checks for paraphrased contexts
- Dependencies: privacy and consent; storage of caches; potentially limited compute on-device; safeguards against unintended personalization drift
Long-Term Applications
These applications build on the paper’s innovations but depend on further research, scaling, vendor support, or standardization.
- Model patch governance and certification
- Sectors: policy, finance, healthcare, critical infrastructure
- Vision: standardized “non-destructive edit” protocols with audit trails, edit budgets, and capability degradation thresholds; third-party certification bodies validating preservation claims
- Tools/workflows: audit logs for epsilon/gamma values, diffs of curvature stats pre/post edit, WILD or similar autoregressive evaluation as conformance tests
- Dependencies: regulatory consensus; shared benchmarks and metrics; secure artifact signing and traceability
- Continuous learning via safe sequential editing
- Sectors: all industries with frequent updates
- Vision: streaming edit pipelines that maintain both base capabilities and previously applied edits, avoiding catastrophic forgetting using online K-FAC factor aggregation
- Tools/workflows: long-lived curvature caches updated incrementally; edit prioritization; automated detection of capability drift; hybrid retrieval+editing systems
- Dependencies: robust algorithms for drift detection; scalable storage; orchestration for high edit volumes; domain-specific capability sets that evolve over time
- Closed-model adaptation through provider APIs
- Sectors: SaaS LLM providers, enterprise consumers
- Vision: vendor-exposed “edit endpoints” that implement curvature-restricted updates under-the-hood; optional coupling with LoRA modules
- Tools/workflows: managed curvature cache computation by providers; customer-specified edit datasets; contract-level SLAs for capability preservation
- Dependencies: provider cooperation; secure, auditable APIs; alignment on acceptable capability proxies and evaluation protocols
- Safety “unlearning” with minimal collateral damage
- Sectors: trust & safety, public sector
- Vision: systematic removal of harmful behaviors/content while preserving beneficial capabilities, with formal edit budgets and fail-safes
- Tools/workflows: negative edit datasets; multi-layer curvature constraints; real-time safety evaluation; emergency rollback
- Dependencies: reliable detection of harmful patterns; careful choice of capability datasets to avoid over-pruning; oversight boards
- Clinical decision support with certified edit pipelines
- Sectors: healthcare
- Vision: safe incorporation of updated clinical guidelines and drug information via constrained edits, paired with rigorous validation and post-market monitoring
- Tools/workflows: clinical capability datasets; human validation; audit-ready documentation; integration with EHR systems
- Dependencies: regulatory approvals; high-quality medical corpora; strict governance; liability frameworks
- Robotics and edge deployments with lightweight curvature projection
- Sectors: robotics, IoT, energy operations
- Vision: on-device curvature-aware editing for instruction changes and environment-specific facts under tight memory/compute budgets
- Tools/workflows: compressed K-FAC factors; hardware acceleration for Kronecker-based projections; periodic sync with central cache servers
- Dependencies: efficient approximations beyond current K-FAC; hardware support; robust fallbacks when caches are stale
- Cross-model curvature maps and transfer
- Sectors: foundation model development
- Vision: sharing or transferring capability-preserving curvature statistics across model family variants to amortize costs and enable faster edits
- Tools/workflows: canonicalization of layer mappings; factor alignment across architectures; tooling to estimate transfer fidelity
- Dependencies: architectural compatibility; empirical validation of transfer; version management
- Patch registry and marketplaces
- Sectors: platform ecosystems, enterprise IT
- Vision: distribution and reuse of certified edit patches (e.g., “API vX→vY,” “regulation update Q3”), with provenance and signatures
- Tools/workflows: package formats for curvature-aware patches; dependency resolution; capability impact metadata
- Dependencies: standards for patch formats; IP and licensing models; secure distribution channels
- Integrated model risk frameworks with capability-preserving edits
- Sectors: finance, insurance
- Vision: incorporate edit budgets and preservation metrics into model risk management (MRM), stress-testing edits under scenario analyses
- Tools/workflows: dashboards tracking epsilon vs. capability metrics (MMLU, GSM8K, ARC-C, IFEval, TruthfulQA), audit-friendly reports
- Dependencies: alignment with existing MRM standards; cross-functional buy-in; ongoing validation datasets
Common assumptions and dependencies across applications
- Model access: CrispEdit requires access to model weights (or selected layers). For fully closed models, provider support would be needed.
- Capability dataset quality: Preservation depends on how representative the chosen capability dataset is; domain-specific caches are recommended.
- Compute/storage: One-time computation of K-FAC factors and eigendecompositions requires GPU resources and memory; thereafter, edits are fast (e.g., thousands of edits in minutes using cached curvature).
- Loss and differentiability: The approach assumes a differentiable loss and output pathway; typical for modern LLMs (e.g., softmax + cross-entropy).
- Threshold tuning: Choosing gamma (curvature energy) and epsilon (capability tolerance) affects the edit–preservation trade-off and may require validation sweeps.
- Evaluation realism: Autoregressive, context-sensitive evaluation (e.g., WILD + LLM-as-a-judge) is important; teacher-forced metrics can overestimate success.
- Security and privacy: Curvature caches derived from capability datasets must be governed (privacy, PII), especially in regulated settings.
Glossary
- Activation covariance: The covariance of layer activations over a dataset, used to define conservative update directions. "Projecting onto the nullspace of activation covariance is overly conservative; it preserves representations but restricts the update too heavily to successfully optimize the edit loss."
- Adam-NSCL: A model-editing method that constrains updates by projecting gradients into the feature covariance nullspace. "Adam-NSCL performs PGD in the feature covariance nullspace;"
- AlphaEdit: A locate-then-edit approach that enforces representation-level constraints (knowledge vectors), resulting in a more restrictive update subspace. "popular editors such as AlphaEdit~\citep{fang2025alphaedit} and Adam-NSCL~\citep{wang2021training} solve an approximate special case of our framework"
- Anisotropic Hessian: A curvature property where the loss landscape is sharper in few directions and flatter in many others. "which is observed to be highly anisotropic: sharp in a small number of directions and flat in others"
- ARC-Challenge: A scientific question-answering benchmark used to assess base capabilities. "ARC-Challenge~\citep{clark2018think}"
- Autoregressive decoding: Generating model outputs token-by-token conditioned on previous tokens; realistic evaluation mode for edited LLMs. "editing performance under autoregressive decoding"
- Bregman divergence: A divergence induced by a convex function that is first-order flat at a reference point, enabling Gauss-Newton curvature without stationarity. "At the crux of black is expressing capability constraint via Bregman divergence"
- Capability-loss landscape: The geometry of the capability objective over parameters, whose curvature guides safe edit directions. "projecting edit updates onto the low-curvature subspace of the capability-loss landscape."
- Catastrophic forgetting: Loss of previously acquired knowledge or edits during sequential learning. "inherits its core failure mode catastrophic forgetting."
- Constrained optimization: Optimizing an objective subject to explicit constraints (here, preserving capabilities). "black formulates editing as constrained optimization"
- Continual learning: Sequential or lifelong learning setting where models are updated over time while trying to retain prior knowledge. "This setting is closely connected to continual (or lifelong) learning"
- Ellipsoidal constraint: A quadratic constraint defining an ellipsoid in parameter space that limits curvature-sensitive directions. "the ellipsoidal constraint in \eqref{eq:hessian_constrained_problem} offers many parameter directions around of low-curvature"
- Eigenvalue-corrected K-FAC (EK-FAC): A refinement of K-FAC that adjusts eigenvalues for improved curvature approximation. "eigenvalue-corrected K-FAC (EK-FAC)"
- Eigendecomposition: Decomposition of a matrix into its eigenvalues and eigenvectors, used to form curvature-aware projectors. "denote the respective eigendecompositions of and ."
- Fisher information matrix: The expected curvature of the log-likelihood; equivalent to GNH in common settings. "While K-FAC approximates the Fisher information matrix, for many models, such as the transformers with softmax output and cross-entropy loss, it is equivalent to the GNH"
- Gauss-Newton Hessian (GNH): A curvature matrix JT H_y J that captures output-space curvature mapped through the Jacobian. "the Gauss-Newton Hessian (GNH, also referred to as the Generalized Gauss-Newton)"
- GeLU: A smooth activation function used in modern neural architectures. "such as GeLU/SwiGLU."
- Generalized Gauss-Newton: Another name for the Gauss-Newton Hessian used in second-order optimization. "also referred to as the Generalized Gauss-Newton"
- GSM8k: A math word problem benchmark used to assess reasoning capabilities. "GSM8k~\citep{cobbe2021training}"
- Hadamard product: Element-wise multiplication of matrices. "where denotes the Hadamard (entry-wise) matrix product"
- Hessian: The second derivative matrix of a loss with respect to parameters, capturing curvature. "the Hessian of the capability loss function evaluated at "
- Jacobian: The matrix of first derivatives of model outputs with respect to parameters. "Here, $\bm{J} = \nabla_{\bm{\theta} f_{\bm{\theta}(x)$ is the network's parameter-output Jacobian"
- Kronecker eigenbasis: The basis formed by eigenvectors of Kronecker-factor matrices used to rotate gradients for projection. "rotate gradients into a factored eigenbasis, mask high-curvature components, and rotate back."
- Kronecker-factored approximate curvature (K-FAC): A scalable curvature approximation that factorizes per-layer GNH into Kronecker products of activation and gradient covariances. "Kronecker-factored approximate curvature (K-FAC)"
- Kronecker product: A matrix operation combining two matrices into a larger block-structured matrix; its eigen-structure enables matrix-free projection. "the eigenvalues/eigenvectors of a Kronecker product "
- LocBF-FT: A fine-tuning baseline that edits a single, tuned layer to localize change. "LocBF-FT~\citep{yang2025finetuning} constrains fine-tuning to a single, hyperparameter-tuned layer."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that adds trainable low-rank matrices. "FT and LoRA~\citep{hu2022lora, zhang2023adaptive} performs standard and low-rank fine-tuning, respectively;"
- Matrix-free projector: A projection method that avoids explicitly forming large projection matrices, operating via eigen-rotations and masking. "a novel matrix-free projector that exploits Kronecker structure to avoid constructing massive projection matrices."
- MEMIT: A mass-editing approach that locates and modifies internal knowledge in LLMs. "MEMIT~\citep{meng2023massediting} and AlphaEdit~\citep{fang2025alphaedit} follow the locate-then-edit paradigm;"
- MEND: A hypernetwork-based editor that predicts parameter updates to enact edits quickly. "MEND~\citep{mitchell2022fast} uses a hypernetwork to predict parameter changes"
- MMLU: A comprehensive multi-task language understanding benchmark to measure broad capabilities. "MMLU~\citep{hendrycks2020measuring}"
- Nullspace: The set of directions annihilated by a matrix; used to identify low-curvature update directions. "the -approximate nullspace"
- Pseudo-gradients: Gradients with respect to preactivations used in curvature approximation for K-FAC. "Let denote the pseudo-gradients of preactivations."
- Projected gradient descent (PGD): Gradient descent that projects updates onto a feasible set defined by constraints. "applying projected gradient descent (PGD) to fine-tune a one hidden-layer MLP"
- Reward/proxy hacking: Exploiting a proxy objective to achieve apparent success while degrading true performance. "reminiscent of {proxy/reward hacking}."
- Streaming averages: Online updating of summary statistics by averaging over sequential batches. "via streaming averages."
- SVD: Singular value decomposition used to compute eigenbases for projection. "(computed via SVD)."
- SwiGLU: A smooth gated activation function used in transformer models. "such as GeLU/SwiGLU."
- Teacher-forced evaluation: Evaluation where models are fed the ground-truth prefix and target length, inflating performance. "unrealistic teacher-forced evaluation that scaffolds the ground-truth prefix and target length"
- Trust-region methods: Second-order optimization techniques that restrict updates within a region where approximations are reliable. "via projected gradient or trust-region methods"
- TruthfulQA: A benchmark evaluating the truthfulness of model answers. "TruthfulQA~\citep{lin2022truthfulqa}"
- UltraEdit: An editing method leveraging sensitivity analysis with online statistics to guide updates. "UltraEdit~\citep{gu2025ultraedit} leverages sensitivity analysis with online statistics"
- WikiBigEdit: A large-scale dataset for evaluating model edits on factual knowledge. "WikiBigEdit~#1{thede25awikibigedit}"
- WILD evaluation protocol: An evaluation combining context-guided autoregressive decoding and LLM-as-a-judge scoring. "we follow the WILD evaluation protocol~\citep{yang-etal-2025-mirage} that combines context-guided autoregressive decoding of LLM responses with LLM-as-a-judge evaluation."
- ZsRE: A dataset of factual rewrites used to test editing reliability and generalization. "ZsRE~#1{levy-etal-2017-zero}"
Collections
Sign up for free to add this paper to one or more collections.