Operationalising the Superficial Alignment Hypothesis via Task Complexity
Abstract: The superficial alignment hypothesis (SAH) posits that LLMs learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge. The SAH, however, lacks a precise definition, which has led to (i) different and seemingly orthogonal arguments supporting it, and (ii) important critiques to it. We propose a new metric called task complexity: the length of the shortest program that achieves a target performance on a task. In this framework, the SAH simply claims that pre-trained models drastically reduce the complexity of achieving high performance on many tasks. Our definition unifies prior arguments supporting the SAH, interpreting them as different strategies to find such short programs. Experimentally, we estimate the task complexity of mathematical reasoning, machine translation, and instruction following; we then show that these complexities can be remarkably low when conditioned on a pre-trained model. Further, we find that pre-training enables access to strong performances on our tasks, but it can require programs of gigabytes of length to access them. Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude. Overall, our results highlight that task adaptation often requires surprisingly little information -- often just a few kilobytes.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question with a big idea behind it: Do LLMs already know how to do most tasks after pre-training, and does later “fine-tuning” mostly just help us access what they already know? The authors give this idea a precise, testable meaning using a concept they call task complexity—basically, “How short can the instructions be to make a model do well on a task?” Then they measure this across real tasks and real models.
What questions did the paper ask?
- Can we define the “superficial alignment hypothesis” (SAH) in a clear, quantitative way?
- For a given task and a pre-trained model, how much extra information do we need to reach a good score?
- Do different ways of adapting a model (prompts, small adapters, small datasets) give us short “instruction programs” that achieve high performance?
- How do pre-training and post-training change how easy it is to reach good performance?
How did they study it?
The key idea: task complexity as “shortest instructions”
Think of adapting a model like giving a robot instructions to do a job. The robot already has a lot of skills (from pre-training), but you still need to tell it what to do for your specific task. The shorter the instructions you need to get a good result, the lower the task’s complexity with respect to that robot.
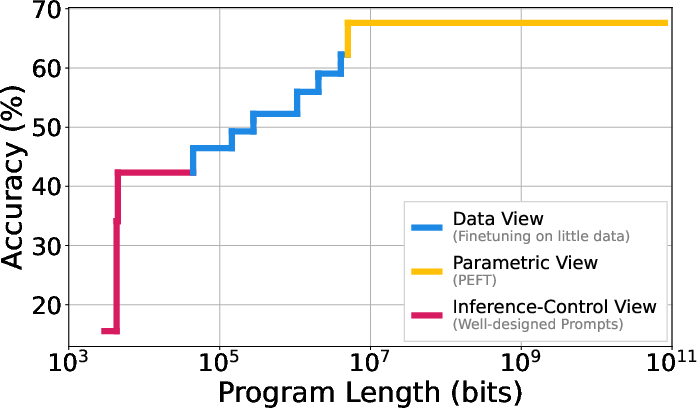
- Task complexity: the length of the shortest “program” (set of instructions, data, or small parameter updates) that gets at least a target score on the task.
- Conditional task complexity: same thing, but assuming you already have a particular pre-trained model to use. This asks, “Given this model’s knowledge, how short can the extra instructions be?”
They measure “length” as size in bits (like file size), so everything is comparable: a prompt, a small dataset, or tiny adapter weights are all just “bits of extra information” added on top of the pre-trained model.
To compare fairly, they also compress these extras (like zipping a file), often using the model itself to help compress them. That way, they really do count only the extra information needed.
Three ways to write short instructions
To find short, high-performing instructions, they try three practical strategies people already use:
- Inference-time control (no training):
- Carefully designed prompts or a few in-context examples (like a cheat sheet) that guide the model at runtime.
- Data-based methods:
- Fine-tune the model on a very small, compressed subset of training examples.
- Parametric methods:
- Add or update a very small number of parameters (like LoRA adapters) rather than changing the whole model.
Each strategy produces a “program” (instructions) with a measurable size and a resulting performance. Plotting the best trade-offs gives a curve showing the shortest instructions that can reach each performance level.
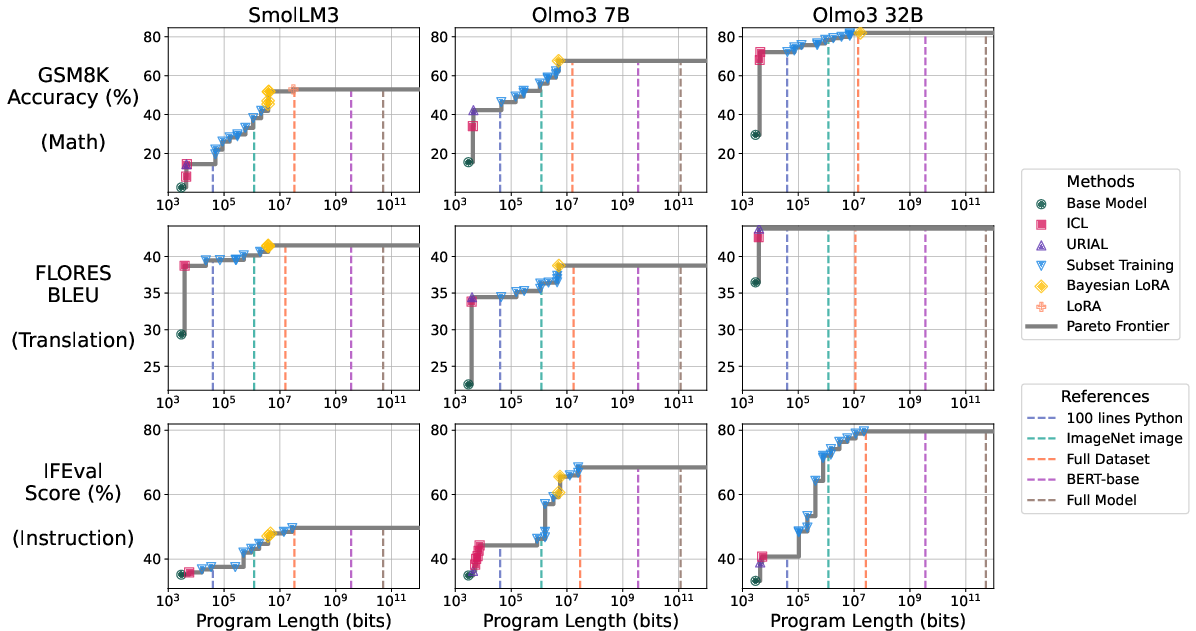
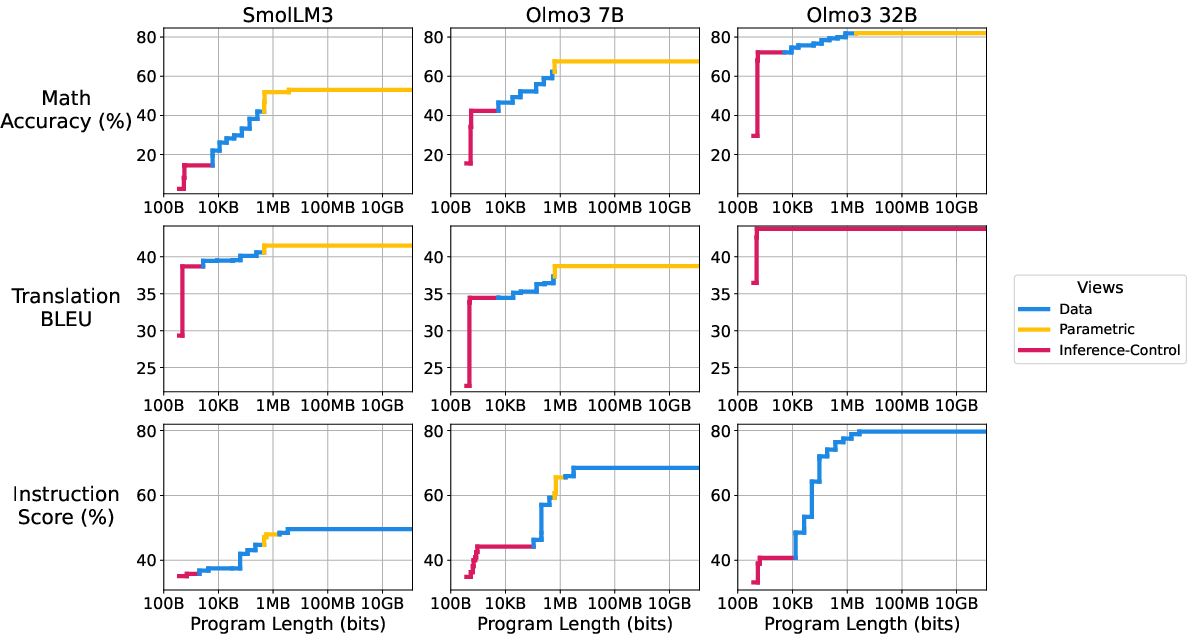
What they tested on
- Models: SmolLM3 3B and OLMo3 7B and 32B (open models).
- Tasks:
- Math word problems (GSM8K)
- English→French translation (FLORES-200)
- Instruction following (IFEval)
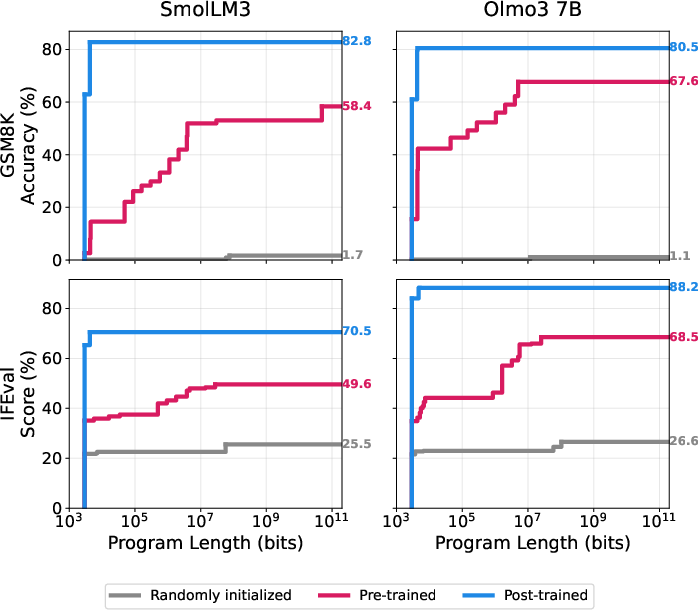
They also compare three checkpoints for some models: random (no training), pre-trained, and post-trained (instruction-tuned and safety-tuned), to see how training changes the “instruction length” needed.
What did they find, and why does it matter?
Here are the main takeaways, each with a brief explanation of why it’s important.
- Small programs can unlock strong performance.
- With a pre-trained model, surprisingly tiny “instruction programs” can reach high scores. For example, in some cases, programs around 150 KB (about the size of a single smartphone photo) are enough to get strong results.
- Why it matters: This supports the SAH—most of what’s needed is already inside the pre-trained model; we often just need a small “key” to access it.
- Different adaptation methods shine in different size ranges.
- Very small sizes: prompts and in-context learning give modest gains with almost no extra bits.
- Medium sizes: fine-tuning on a small subset of data gives better performance without huge sizes.
- Larger sizes (but still small compared to the full model): tiny parameter updates (like LoRA) can push performance higher.
- Why it matters: The three “views” of superficiality—prompts, small data, and small adapters—are not competing theories; they’re different tools for finding short instructions at different budget levels.
- Pre-training vs. post-training: accessibility vs. simplicity.
- Pre-training makes strong performance possible, but you may still need longer instructions to reach top scores.
- Post-training “collapses” the instruction size needed—after post-training, short prompts or small programs often suffice to get similar or better performance.
- Why it matters: This gives a concrete meaning to “post-training surfaces knowledge”: it makes good performance easy to access with very little extra information.
- Responses to common critiques:
- “If models already know the task, shouldn’t performance saturate with very little fine-tuning?” Not necessarily. Reaching “good” performance may need only a tiny program; squeezing out the last few percentage points can require much more information. So the SAH should be about reaching strong, not necessarily perfect, performance.
- “Fine-tuning changes are tiny—sometimes 1 bit per parameter!” Even that can be huge overall compared to a small dataset or prompt. When measured as program size, those “tiny per-parameter” updates can be much larger than other short-instruction options, and not on the best trade-off curve.
What’s the potential impact?
- Practical guidance: If you want the best result per bit of extra information, use prompts when your “bit budget” is tiny, small datasets when you can afford a bit more, and small adapters when you can afford more still. This helps engineers pick the right adaptation method for their constraints.
- Clear definition: The paper turns a fuzzy debate (“Do models already know it?”) into a measurable question: “How many extra bits do we need to reach this score?”
- Understanding training: Pre-training builds broad abilities; post-training makes those abilities easy to reach. This helps explain why post-trained models feel more “helpful” without being much bigger.
Limitations and what’s next
- Finding the absolute shortest instructions is impossible in general (a math fact), so they estimate upper bounds by trying practical methods. There might be even shorter programs no one has discovered yet.
- They focus on three NLP tasks and a few models; future work could test more tasks (including safety-sensitive ones) and more models.
- Measuring the “total” information the model learned (not just the extra bits needed) is harder; the paper focuses on the extra bits because that’s what matters for adaptation.
Bottom line
This paper gives a clean, real-world way to test the superficial alignment hypothesis: measure how many extra bits you need to reach a target score when you already have a pre-trained model. Across math, translation, and instruction following, the answer is often “surprisingly few”—sometimes just a prompt or a tiny adapter—especially after post-training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that, if addressed, could strengthen and extend the paper’s framework and empirical findings.
- Sensitivity to the choice of Universal Turing Machine (UTM): results depend on treating the Python interpreter and libraries as “free” while counting only model weights, tokenizers, and data. How robust are the Pareto curves under alternative UTMs or accounting conventions (e.g., counting library code, decoding algorithms, or sampler implementations)?
- Tokenizer and asset boundary choices: tokenizers are counted but other critical assets (e.g., system prompts, decoding heuristics) are not. How do these boundary decisions affect cross-model comparability and program-length estimates?
- Constant-overhead effects: the “constant” code overhead is assumed negligible, yet may dominate at very small program lengths. What is the exact overhead per method, and how does it affect short-program regimes?
- Determinism and exact recoverability: the subset-training scheme assumes bit-exact decompression and replay of training using the model as a compressor. What is the impact of floating‑point nondeterminism, library versions, and hardware variability on reproducibility and measured lengths?
- Potential circularity in compression: compressing each batch with the same model that is then updated on that batch can create coder–decoder mismatch and bias length estimates. How do offline compressors, alternative coding schedules, or fixed compressors change results?
- Compressor dependence: arithmetic coding with the model defines the codelengths; the sensitivity to compressor choice (e.g., generic compressors, ensemble model-based coders) is not measured. How much do different compressors shift the Pareto front?
- Weight-bit accounting: adapter weight sizes are counted via rank/quantization choices, but not entropy-coded. Can structure-aware priors and entropy coding of adapters/deltas substantially reduce bits-per-parameter and improve Pareto optimality?
- Limited adaptation classes: only three adaptation families are evaluated (subset training, LoRA/Bayesian-LoRA, ICL/URIAL). How do other strategies (e.g., RLHF/DPO, reward-model-based post-training, prefix-tuning/BitFit, scaffolding/agents, retrieval augmentation, tool-use, delta compression, search policies) alter the length–performance frontier?
- Hybrid strategies under a bit budget: combinations (e.g., short prompts + tiny adapters + few data batches) could dominate individual methods. What joint optimization procedures best explore the hybrid Pareto region?
- Compute/time vs bits trade-offs: the metric optimizes for bits only, ignoring compute, memory, and latency. How does the Pareto surface change under joint constraints (bits, compute, wall-clock), and do “shortest” programs remain practical?
- Subset selection under bit budgets: Subset Training does not optimize which examples to include given a bit budget. Can principled selection (e.g., submodular or information-theoretic selection under compression constraints) improve the frontier?
- Inference-control breadth: only ICL and URIAL are tested. How do chain-of-thought, self-consistency, tree-of-thought, constrained decoding, and logit-bias strategies (and the bits required to specify them) affect results?
- Evaluation metric choices and task coverage: translation is assessed only on En→Fr with BLEU; other directions and metrics (e.g., COMET/BLEURT) may change conclusions. More tasks (code generation, long-context reasoning, safety tasks, multimodal tasks) are needed to test generality.
- Scaling characterization: three model sizes (3B/7B/32B) are tested, but no systematic scaling law is derived for conditional task complexity vs model size. How does C(T_δ|M) scale across orders of magnitude in parameters and data?
- Lower bounds and tightness: all curves are upper bounds; no lower bounds on C(T_δ|M) are provided, nor diagnostics of tightness. Can adversarial constructions, rate–distortion arguments, or oracle baselines establish nontrivial lower bounds?
- Unconditional task complexity and information: C(T_δ) is not estimated, leaving I(T_δ;M) unmeasured. Can non-LLM baselines (e.g., symbolic solvers, classic MT systems) provide actionable lower/upper bounds on C(T_δ) for representative tasks?
- Post-training confounds: post-training includes target-task data (GSM8K, IFEval), confounding the claim that post-training collapses complexity. Clean experiments excluding target tasks from post-training are needed to attribute effects causally.
- Robustness to evaluation protocol: performance depends on prompt templates, sampling, decoding, and n‑samples. Variance estimates and ablations are needed to quantify uncertainty and protocol sensitivity in Pareto points.
- External resources and tools: the framework does not examine how retrieval, tools, or external KBs (and the bits to specify/access them) affect conditional complexity. What accounting conventions should govern such resources?
- Multi-task adaptability: can one small program enable strong performance on multiple tasks simultaneously? What are the trade-offs between per-task δ and total bit budget?
- Theoretical links: the connection to rate–distortion and mutual information is qualitative. Can formal bounds relate C(T_δ|M) to model capacity, pretraining cross-entropy on task distributions, or properties of the pretraining corpus?
- Portability across model families: results are limited to SmolLM3 and OLMo3. Do similar conditional complexity patterns hold for different architectures (e.g., MoE, non-transformer LMs) and tokenizer designs?
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s methods and findings, with sectors, potential tools/workflows, and feasibility notes.
- Complexity-aware adaptation planner (software, MLOps)
- What: Automatic selection among inference-control (ICL/URIAL), data-based subset training, or parametric adapters (LoRA/Bayesian-LoRA) to hit a target performance with the smallest “program-length” (bit) budget.
- Tools/workflows:
- A “Task Complexity Estimator” library that runs small sweeps and builds a Pareto curve of length vs. performance for a chosen task/model.
- Integration into Hugging Face/Lightning pipelines to recommend prompt-only vs. LoRA vs. subset SFT.
- Assumptions/dependencies: Requires a standardized “UTM” (Python env) and scoring function; measured program length depends on compression choices and what’s counted as library code.
- Capability packs: shipping tiny updates instead of full models (software, edge, telecom)
- What: Distribute kilobyte–megabyte “programs” (prompts, micro-adapters, or compressed finetune deltas) that adapt a fixed base model for new skills/features.
- Tools/workflows:
- A package manager that versions “capability packs,” reports their bit-size, and validates performance on a small test set.
- CDN optimization for kilobyte-scale updates.
- Assumptions/dependencies: Base model must be stable and compatible; licensing for adapters/prompts; secure loading of third-party adapters.
- On-device specialization with minimal connectivity (mobile, IoT, embedded)
- What: Deploy a quantized base LLM once and update devices via small “programs” to enable offline translation, math help, or instruction-following improvements.
- Tools/workflows:
- Device-side loader for URIAL/ICL prompts and LoRA adapters.
- Bit-budget gates to ensure updates fit bandwidth/flash constraints.
- Assumptions/dependencies: Device RAM/flash must accommodate the base model; reliable quantization/runtime, and power constraints.
- Personalization via tiny per-user adapters/prompts (consumer apps, enterprise SaaS)
- What: Maintain per-user kilobyte-scale “profiles” (adapters or prompts) to tune tone, domain conventions, or workflows without retraining the base model.
- Tools/workflows:
- Multi-adapter routing and caching.
- Privacy-preserving local training for small updates.
- Assumptions/dependencies: Adapter stacking/merging support; policy for sensitive data; drift monitoring.
- Cost-aware procurement and vendor evaluation (finance, enterprise IT)
- What: Require “conditional task complexity” disclosures in model cards to compare models by the program length needed to reach target accuracy on relevant tasks.
- Tools/workflows:
- Benchmark kit that generates length–performance curves on internal datasets.
- RFP criteria that score adaptability and update shipping costs.
- Assumptions/dependencies: Comparable tasks/metrics across vendors; reproducible measurement protocol.
- Safety/governance triage for model releases (policy, trust & safety)
- What: Estimate how many bits are needed to elicit unsafe capabilities; if small, gate weight release or require additional mitigations.
- Tools/workflows:
- A “Risk by Conditional Complexity” dashboard that runs standardized unsafe tasks (e.g., dual-use protocols) and reports bit-budgets required.
- Assumptions/dependencies: Well-defined unsafe task specs and scoring; strong provenance/contamination checks.
- Post-training optimization metric (ML training, RLHF/SFT teams)
- What: Treat “collapse of conditional task complexity” as a first-class success metric of post-training; prefer recipes that preserve capability while minimizing bit-budget required to access it.
- Tools/workflows:
- Small, periodic complexity-probe jobs during RLHF/SFT to track shifts in the Pareto curve.
- Assumptions/dependencies: Comparable checkpoints; test sets not leaked into post-training.
- Complexity-aware prompt engineering (developer tooling, education)
- What: Assistants that propose “bit-budgeted prompts” (URIAL + exemplars) vs. “micro-adapters” when prompts alone are insufficient for target performance.
- Tools/workflows:
- Prompt/tooling IDE plugins that estimate compressed prompt size and expected gain.
- Assumptions/dependencies: Reliable compression and performance prediction; task scoring availability.
- Distribution marketplaces for micro-adapters/prompts (open source ecosystems)
- What: Curate and share tiny, signed adapters/prompts with declared bit-size and verified performance.
- Tools/workflows:
- Registry with reproducibility harness; automatic signature checks.
- Assumptions/dependencies: IP/licensing clarity for adapters/prompts; base model compatibility.
- Curriculum and budget planning for training (academia, industry labs)
- What: Use length–performance curves across checkpoints to decide where to invest: more pretraining vs. more post-training to reduce complexity of access.
- Tools/workflows:
- Training dashboards that overlay complexity curves over compute spend and data mixtures.
- Assumptions/dependencies: Access to intermediate checkpoints; consistent evaluation setup.
Long-Term Applications
These applications require further research, scaling, or standardization before routine deployment.
- Standardized “Task Complexity” reporting and certification (policy, standards)
- What: Industry-wide protocols for measuring/program-length reporting by task, with certified UTMs, compression settings, and task definitions.
- Tools/workflows:
- NIST/ISO-style benchmarks; third-party auditors.
- Assumptions/dependencies: Consensus on counting rules; legally robust reporting.
- Architecture and training co-design for adaptability (model R&D)
- What: Pretrain models that explicitly minimize the bit-length needed to adapt to common task families (modularity, adapter-ready designs).
- Tools/workflows:
- New objectives/regularizers that reduce conditional task complexity for target task sets.
- Assumptions/dependencies: Reliable surrogates for uncomputable complexity; no regressions in raw capability.
- Safety-by-design: increase conditional complexity of unsafe tasks (AI safety)
- What: Train models so that eliciting dangerous capabilities requires long programs (hard to unlock with prompts or tiny adapters), while keeping benign tasks easy to access.
- Tools/workflows:
- Adversarial “short-program” red-teaming; defenses that penalize short-program elicitation for unsafe tasks.
- Assumptions/dependencies: Robust unsafe task taxonomies; avoiding collateral damage to helpful capabilities.
- Compute and adaptation governance via “bit-budget” caps (policy, platform governance)
- What: Oversight that limits the size of adaptation payloads allowed on shared platforms, or requires review for programs below a danger threshold.
- Tools/workflows:
- Platform-level bit-budget enforcement, signed update manifests, and provenance.
- Assumptions/dependencies: Accurate measurement; prevention of obfuscation/circumvention.
- Automated program synthesis for minimal adapters/prompts (AutoML, program synthesis)
- What: Systems that search the program space to approach minimal-length, high-performance adapters/prompts under a given model and task.
- Tools/workflows:
- Hybrid search combining gradient-based finetuning, discrete prompt search, and compression-aware objectives.
- Assumptions/dependencies: Compute-intensive; risk of overfitting or leakage if not careful.
- Lower-bound theory and practical certificates (theory, evaluation science)
- What: Methods that provide usable lower bounds (or hardness surrogates) on program length for a target performance, closing the gap with current upper bounds.
- Tools/workflows:
- Reductions to coding theory/rate–distortion variants; statistical hardness diagnostics.
- Assumptions/dependencies: Task formalization quality; tractable relaxations.
- Compression-driven training objectives (training science)
- What: Incorporate rate–distortion style objectives that directly optimize the trade-off between pretraining/post-training and downstream adaptation bit-budgets.
- Tools/workflows:
- Multi-task training with per-task conditional complexity penalties.
- Assumptions/dependencies: Stable optimization; reliable multi-task scoring.
- IP, licensing, and marketplaces for “capability packs” (legal, platforms)
- What: New licensing models and DRM/signing for micro-adapters/prompts sold as IP with performance/bit-size guarantees.
- Tools/workflows:
- Smart contracts that meter bits and validate scores on escrow datasets.
- Assumptions/dependencies: Enforceability; reproducibility without leaking sensitive evals.
- Cross-domain extensions beyond NLP (healthcare, robotics, energy, finance)
- What: Bring conditional task complexity tooling to:
- Healthcare: minimal adapters for clinical note structuring with strict privacy budgets.
- Robotics: small controllers/policies layered over a general visuomotor base model.
- Energy/finance forecasting: small domain adapters for local regimes on top of general models.
- Tools/workflows:
- Domain-specific scoring functions; safety reviews; on-prem deployment.
- Assumptions/dependencies: Regulatory constraints; domain data availability; safety-critical validation.
- Massive-scale personalization infrastructure (consumer platforms)
- What: Hosting and routing for millions of user-specific kilobyte programs with caching, merging, and lifecycle management.
- Tools/workflows:
- Adapter composition at inference; storage-tiering for hot/cold user profiles.
- Assumptions/dependencies: Efficient serving; conflict resolution across adapters.
General Assumptions and Dependencies (affecting feasibility across applications)
- Measurement choices matter: Program lengths are upper bounds and depend on the chosen UTM (Python environment), compression scheme, and what is counted as “library code.”
- Task formalization: Clear scoring functions and representative datasets are required; contamination must be strictly controlled.
- Model compatibility: Capability packs/adapters are model-specific; versioning and licensing must be respected.
- Compute budgets: Finding good points on the Pareto curve may require small sweeps; program-synthesis variants could be compute-heavy.
- Security and integrity: Adapters/prompts must be signed and sandboxed; marketplaces need provenance and abuse prevention.
- Ethical and legal constraints: Safety evaluations, IP for adapters/prompts, and compliance (especially in healthcare/finance) are necessary.
Glossary
- Adapter weights: Trainable parameters of small adapter modules added to a model for efficient fine-tuning. "These adapter weights $\adapterweights$ are then trained using the data in $\dataset$, and written into a program $\program$."
- Algorithmic information theory: A field that studies information content and complexity via algorithmic descriptions. "We introduce definitions based in algorithmic information theory \cite{li2008introduction}"
- Algorithmic rate-distortion theory: A theory extending rate-distortion to algorithmic complexity, allowing approximate outputs at controlled distortion. "Algorithmic rate-distortion theory \cite{vereshchagin2010rate} addresses the second limitation above by allowing approximate outputs, defining complexity as the length of the shortest program which produces an output within a given distortion level of a target value."
- Arithmetic coding: An entropy coding method that compresses data using a probabilistic model. "it uses the model $\model$ to compress this batch via arithmetic coding \cite{deletanglanguage} and writes this compressed data $\compresseddata$ into program $\program$."
- Bayesian-LoRA: A variant of LoRA that optimizes adapter ranks and parameter precision to reduce the number of bits. "The second, #1{Bayesian-LoRA} \cite{meo2024bayesian}, is similar, but directly optimises the ranks (number of parameters) and quantisation levels (precision of each parameter) in each LoRA layer, allowing a model to be adapted with fewer bits."
- BLEU: A metric for machine translation quality based on n-gram overlap between hypothesis and reference. "We evaluate performance using accuracy, BLEU, and verified success rate, respectively."
- Conditional task complexity: The minimal program length required to reach a target performance on a task given access to a model’s weights. "This motivates our definition of conditional task complexity: the length of the minimum program $\program$ which, given access to a model's weights $\model$ (represented as a bit-string\footnote{We additionally consider the tokenizer for a LLM to be part of the bit-string $\model$.}), achieves a certain performance at task $\task$."
- Data view: The perspective that adaptation is superficial because only a small amount of data is needed to adapt a pre-trained model. "Adaptation is superficial because we can finetune an LLM on few data points to adapt it to a new task."
- Delta compression: Compressing the difference (delta) between pre-trained and fine-tuned model weights. "There is a growing interest in compressing the weight difference between pre-trained and fine-tuned model, which is sometimes termed delta compression \cite{ping2024delta, huang2025dynamic, yadav2023compeft}."
- Fine-tuning: Updating a pre-trained model’s parameters on task-specific data to adapt it to a downstream task. "There is ample evidence showing that fine-tuning a pre-trained LLM requires a surprisingly small amount of trainable parameters \cite{li2021prefix, hu2022lora, liu2022few, zaken2022bitfit, liu2022p, dettmers2023qlora, yadav2023compeft, hanparameter, li2024superficial, ping2024delta, liu2024bitdelta, huang2025dynamic, morris2026learningreason13parameters}."
- FLORES-200: A multilingual benchmark dataset used to evaluate machine translation quality across many languages. "English to French machine translation \citep[FLORES-200;] []{costa2022no}"
- GSM8K: A benchmark dataset of grade school math word problems used to evaluate mathematical reasoning. "Mathematical reasoning \citep[GSM8K;] []{cobbe2021training}"
- IFEval: A benchmark for instruction-following where performance is measured by verified success on specified constraints. "instruction following \citep[IFEval;] []{zhou2023instruction}."
- In-Context Learning (ICL): Adapting model behavior at inference time by including examples in the prompt rather than updating weights. "First, #1{In-Context Learning} \citep[ICL;] []{brown2020language}, where the prompt $\prompt$ contains examples from $\dataset'$."
- Injectivity (of transformers): The property that distinct inputs map to distinct outputs; used to argue representations preserve input information. "Note that, due to the injectivity of transformers with real-valued hidden representations outputs \citep{sutter2025nonlinear,nikolaou2026language}, an LLM's representation always preserve all the information encoded in its inputs \citep{pimentel2020information}."
- Kleene star operator: The operator denoting zero or more repetitions in formal language theory. "where denotes the Kleene star operator."
- Kolmogorov complexity: The length of the shortest program that outputs a given string, measuring its information content. "Kolmogorov complexity \cite{kolmogorov1965three} measures the information content of a finite string $\outputvalue$ as the length of the shortest program\footnote{Note that, in this definition, the program takes no input value.} that outputs $\outputvalue$:"
- LLM: A neural LLM trained on large corpora that exhibits broad language understanding and generation capabilities. "The superficial alignment hypothesis (SAH) states that a LLM’s “knowledge and capabilities are learned almost entirely during pre-training, while alignment teaches it which subdistribution of formats should be used when interacting with users” \cite{zhou2023lima}."
- LoRA: Low-Rank Adaptation; a fine-tuning method that adds low-rank trainable adapters to reduce the number of updated parameters. "The first, #1{LoRA} \cite{hu2022lora}, uses a number of low-rank adapter layers when fine-tuning a model."
- Minimum description length (MDL) principle: A model selection principle favoring the shortest total description of data and model. "Task complexity is also related to the minimum description length (MDL) principle \cite{grunwald2007minimum} and, more specifically, to prior probing methods inspired by it \cite{voita2020information, pimentel-etal-2020-pareto, pimentel2021bayesian}."
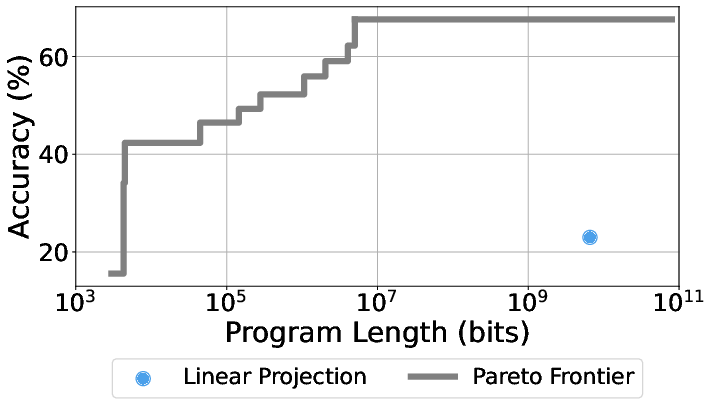
- Pareto curve: The frontier showing trade-offs between two objectives (here, program length and performance) where improving one worsens the other. "Pareto curve of program length vs.\ performance for Olmo3-7B on GSM8K."
- Pareto-optimal curve: The set of non-dominated points where no other point is better in both objectives simultaneously. "Based on these points, we construct a Pareto optimal curve by selecting all the $(\targetkolmogorov, \targetacc)$ pairs which are not dominated by any other, i.e., pairs for which no other pair performs at least as well in terms of both length and accuracy."
- Post-training: A stage after pre-training that refines model behavior (often alignment) and can reduce the complexity of accessing capabilities. "Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude."
- Pre-training: The initial training phase on large unlabeled corpora where models learn broad capabilities and knowledge. "The superficial alignment hypothesis (SAH) posits that LLMs learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge."
- Probing (methods): Techniques that train auxiliary models to measure how accessible specific information is in learned representations. "Task complexity is also related to the minimum description length (MDL) principle \cite{grunwald2007minimum} and, more specifically, to prior probing methods inspired by it \cite{voita2020information, pimentel-etal-2020-pareto, pimentel2021bayesian}."
- Quantisation levels: The chosen precision (number of bits) used to represent numerical parameters. "directly optimises the ranks (number of parameters) and quantisation levels (precision of each parameter) in each LoRA layer"
- Subset Training: A procedure that adapts a model using a compressed subset of training data encoded inside the adaptation program. "We term this procedure as #1{Subset Training}."
- Superficial alignment hypothesis (SAH): The claim that most knowledge is learned during pre-training and later surfaced by adaptation. "The superficial alignment hypothesis (SAH) posits that LLMs learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge."
- Task complexity: The length of the shortest program required to achieve a specified performance on a task. "We propose a new metric called #1{task complexity}: the length of the shortest program that achieves a target performance on a task."
- Tokenizer: The component that converts text into token IDs; considered part of the model bit-string in this framework. "We additionally consider the tokenizer for a LLM to be part of the bit-string $\model$."
- Universal Turing Machine: An abstract computational model capable of simulating any other Turing machine. "Now, let $\machine$ be a Universal Turing Machine."
- URIAL: A prompting method that adds task explanations (and examples) to improve instruction following at inference time. "Second, #1{URIAL} \cite{lin2023unlocking}, where an explanation of the task $\task$ is added to prompt $\prompt$ in addition to the examples in $\dataset'$."
- Verified success rate: An automatic metric that verifies whether generated outputs satisfy specified instruction constraints. "We evaluate performance using accuracy, BLEU, and verified success rate, respectively."
Collections
Sign up for free to add this paper to one or more collections.