Fast KV Compaction via Attention Matching
Abstract: Scaling LLMs to long contexts is often bottlenecked by the size of the key-value (KV) cache. In deployed settings, long contexts are typically managed through compaction in token space via summarization. However, summarization can be highly lossy, substantially harming downstream performance. Recent work on Cartridges has shown that it is possible to train highly compact KV caches in latent space that closely match full-context performance, but at the cost of slow and expensive end-to-end optimization. This work describes an approach for fast context compaction in latent space through Attention Matching, which constructs compact keys and values to reproduce attention outputs and preserve attention mass at a per-KV-head level. We show that this formulation naturally decomposes into simple subproblems, some of which admit efficient closed-form solutions. Within this framework, we develop a family of methods that significantly push the Pareto frontier of compaction time versus quality, achieving up to 50x compaction in seconds on some datasets with little quality loss.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a practical problem in LLMs (like ChatGPT): how to remember long conversations or documents without running out of memory. The specific memory part they focus on is called the “KV cache,” which stores what the model has already seen so it can pay attention to the right parts later. The authors propose a fast way to shrink (“compact”) this KV cache so it takes much less space while keeping the model’s performance almost the same.
What questions are the authors trying to answer?
- Can we reduce the KV cache by 20–100 times and still have the model behave almost the same?
- Can we do this quickly (in seconds or minutes), rather than slowly (hours of training)?
- How can we make sure the compacted memory still works when new text is added later?
- Are there smart ways to choose what to keep so that the compacted memory works well across different models and tasks?
How does their method work? (Explained simply)
Think of the KV cache like a giant notebook filled with “keys” (labels telling you where to look) and “values” (the actual information). When the model “attends,” it’s like flipping through the notebook to find the most useful pages.
The authors’ method, called Attention Matching, is like making a shorter notebook that still leads the model to the same answers. Here’s the idea:
- Attention output: What the model gets after looking up the right pages.
- Attention mass: How strongly the model focuses on a block of pages compared to other blocks.
If we match both the attention output and the attention mass, the shorter notebook behaves almost like the original one.
To do this, they follow a few steps:
- Collect “reference queries”: These are examples of the model’s “questions” it asks internally while reading or reasoning. They get these by:
- Prefilling the context (having the model read it).
- “Self-study”: prompting the model to ask and answer questions about the context to broaden what queries it might use.
- Choose which “keys” to keep:
- Fast option: Keep the keys that the model tends to look at the most.
- Higher-quality option: Use a greedy algorithm (called OMP) that picks keys to best match how much attention the original notebook would get.
- Add tiny “bias weights” to the kept keys:
- These are small numbers that tell each kept key how many original keys it stands in for, so the compacted notebook gets the right total amount of attention.
- Rebuild the “values”:
- Using simple linear algebra (least squares), they set the values so the compacted notebook produces attention outputs that match the original.
- Nonuniform compaction:
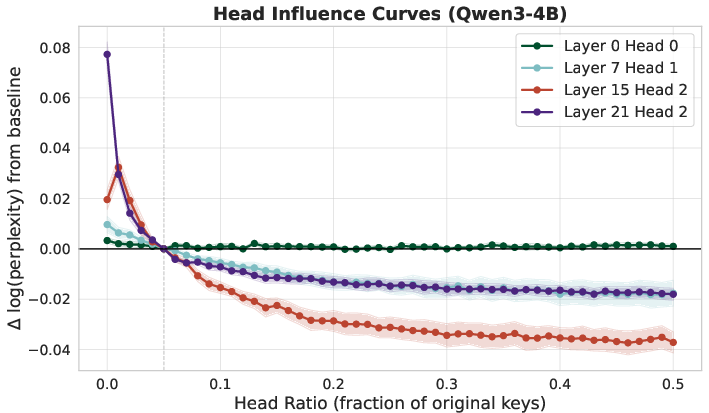
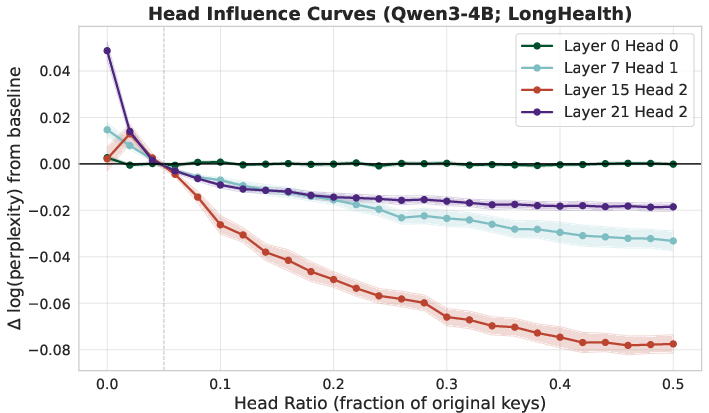
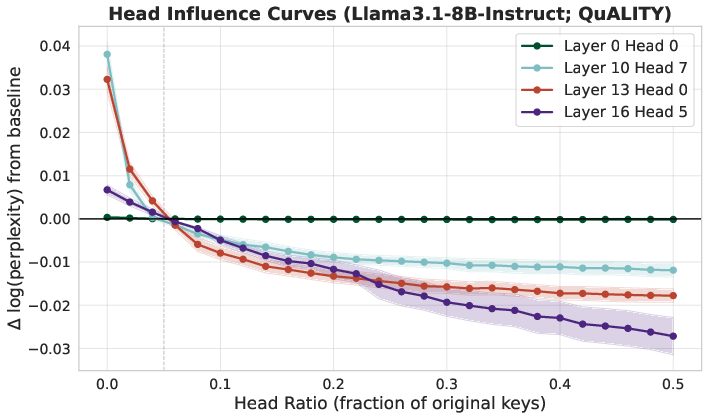
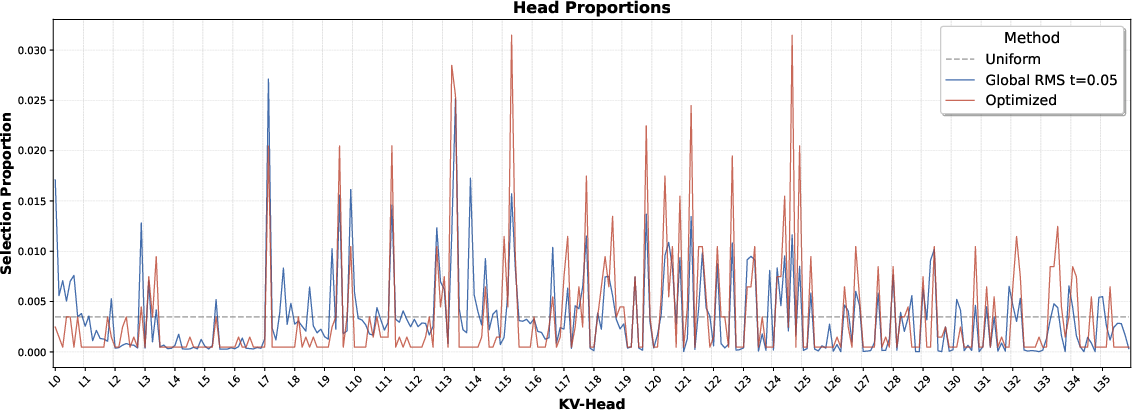
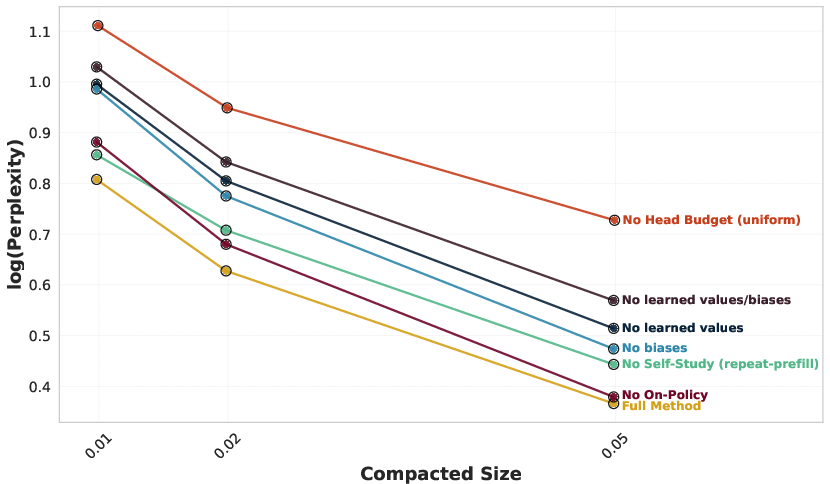
- Not all “attention heads” (sub-parts of attention) are equally important. Some need more memory. They measure which heads are most sensitive and give them bigger budgets. This schedule can be reused across contexts.
- Chunking for very long texts:
- They compact the KV cache in chunks (pieces) and then stitch them together so the whole thing still works.
Important detail: The compacted cache keeps the “logical length” of the original. That means new tokens added later get the same positions they would have gotten before, so future attention still works correctly.
What did they find, and why is it important?
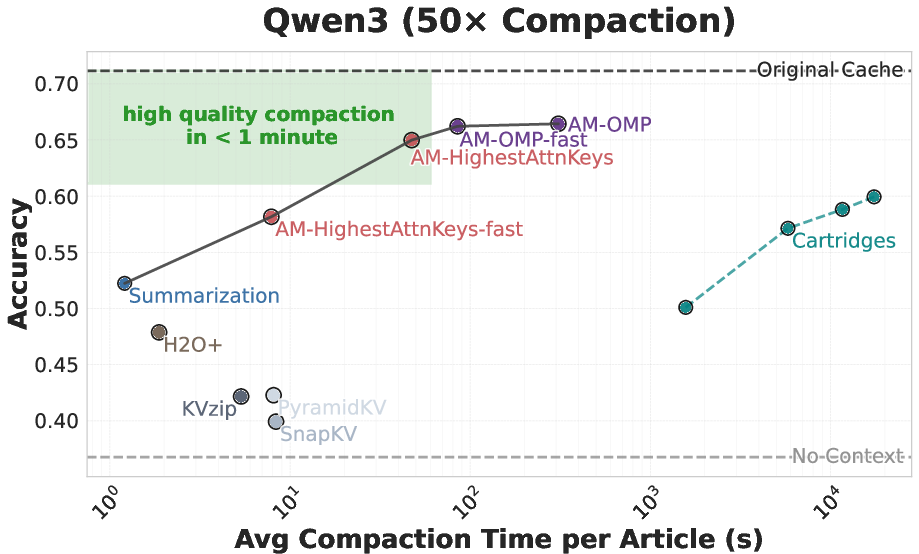
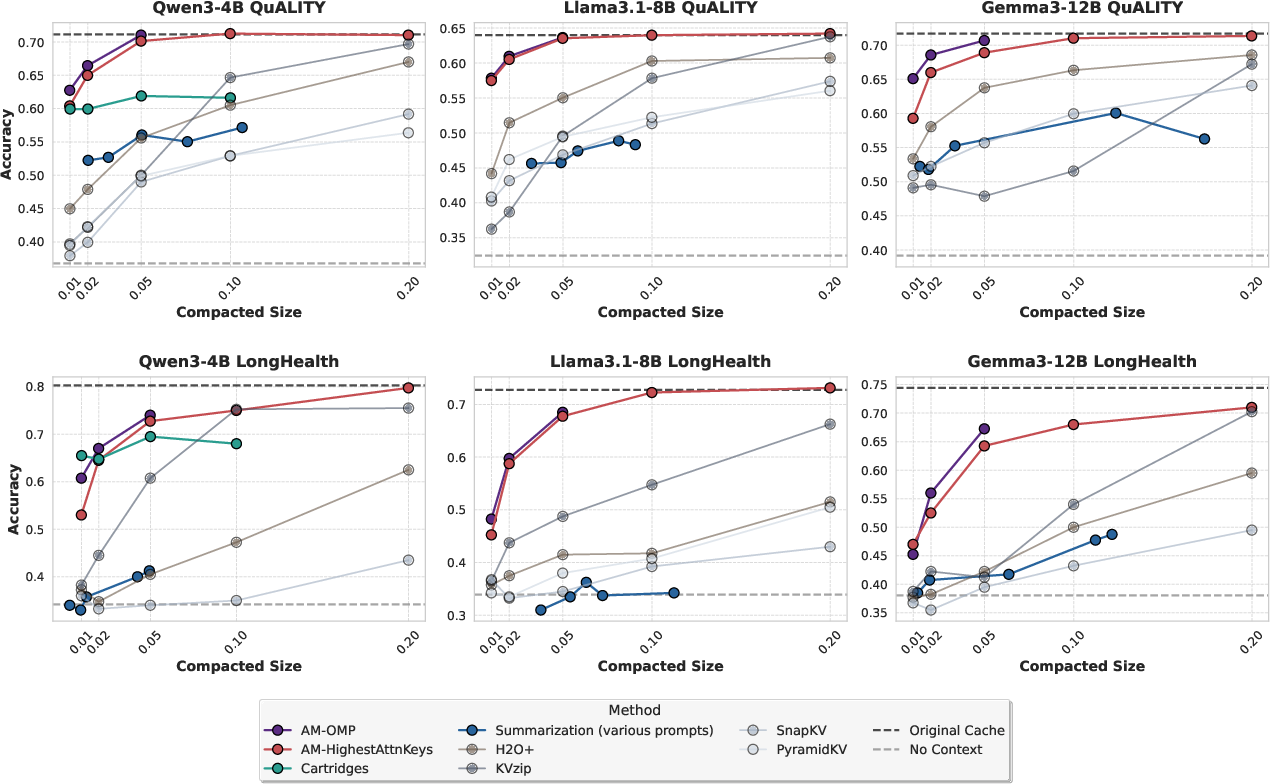
- Big memory savings fast: Their methods achieve up to 50× compaction in seconds to minutes, with little loss in performance on tasks like long-document question answering.
- Better than common shortcuts: Summarization (turning text into shorter text) often loses important info. Simple token-dropping methods also degrade quickly at high compression. Attention Matching keeps quality much better.
- Competitive with slow training methods: A previous approach called “Cartridges” can also reach high compaction, but it’s slow because it trains a special cache for each context. Attention Matching reaches similar accuracy while being about 100× faster.
- Works across models and tasks:
- On datasets like QuALITY (long story comprehension) and LongHealth (medical records QA), their method consistently outperforms baselines.
- It also works with “sliding-window” models (which mostly focus locally and only have a few global layers), by compacting the global parts.
- Plays nicely with summarization:
- If you do need summarization, you can compact the summary further with Attention Matching, getting extreme reductions (about 200× total) while keeping similar accuracy to summarization-only.
Why it matters: This makes it more practical to run LLMs on long conversations, big codebases, medical records, or multi-session tasks without huge memory costs or big drops in quality.
What does this mean for the future?
- Longer, smarter systems: With fast, high-quality compaction, models can remember more across long sessions—important for coding agents, research assistants, and multi-step reasoning.
- Better infrastructure: This approach could be built into inference engines so they auto-compact memory when it gets too large.
- Beyond subsets: Future work might learn brand-new compact keys rather than selecting from the original ones, which could help at extreme compaction (like 100× and beyond).
- Online compaction: Compacting mid-conversation could help agents run indefinitely under fixed memory limits, offering a better alternative to dropping history or over-summarizing.
In short: The paper introduces a fast, practical way to shrink the memory footprint of LLMs by matching how attention behaves, not just compressing text. It gets strong results quickly, helping models handle long contexts much more effectively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains unresolved, missing, or uncertain in the paper, phrased to guide concrete follow‑up work:
- Lack of theoretical guarantees: no formal bounds relate matching attention outputs/mass on sampled reference queries to downstream approximation error for unseen queries or future concatenations; conditions under which this matching suffices remain unproven.
- Reference-query coverage and selection: the method’s quality hinges on how well
Q_refcovers future queries; there is no principled procedure (e.g., active selection, coverage metrics, or stopping criteria) to determine how many and which queries are needed for a target error. - Generalization across tasks and domains: query generation is tailored to repeat‑prefill and limited self‑study prompts; robustness to different tasks (e.g., long-form generation, code agents, reasoning with tool use, multilingual) is untested.
- Sequential, per-layer compaction effects: “on‑policy” queries mitigate query shift, but there is no analysis of error propagation across layers or an optimal compaction order; joint multi-layer optimization is unexplored.
- Subset restriction for compact keys:
C_kis constrained to a subset of original keys; the quality gap vs. optimizing continuous compact keys (or learned dictionaries/bases) remains unquantified, especially at ultra‑high compaction. - Value fitting without regularization:
C_vis obtained via ordinary least squares; numerical conditioning of(X^T X)^{-1}, sensitivity to outliers, and overfitting risk are not analyzed; alternatives (ridge, constraints, multi-objective fits) are not evaluated. - Attention-bias mechanism: per-key scalar biases β are critical but lack systematic study of:
- numerical stability (e.g., overflow/underflow under extreme compaction),
- impact on calibration and confidence,
- interactions with positional schemes (RoPE scaling, ALiBi) and attention sinks,
- support across production kernels/backends beyond PyTorch SDPA/FlexAttention.
- Mass-matching approximation quality: the conditions and sample complexity under which NNLS weights can approximate the original mass within ε (as a function of
t,n, and key/query distributions) are unknown. - Nonuniform head budgets: the precomputed schedule assumes separability and stable head importance; cross-head interactions, context-adaptive allocations, and re-optimization at inference (vs. static budgets) remain open.
- Scalability of OMP: greedy selection with NNLS refits scales with both
tand number of keys; complexity and memory overheads for 100k–1M token contexts and many heads are not characterized; approximate/parallelizable variants need study. - Chunked compaction trade-offs: KV-based chunking requires full-context prefill (costly for very long inputs), while text-based chunking ignores cross-chunk interactions; practical streaming-friendly chunking without full prefill is not developed.
- Evaluation breadth: experiments cover three models (up to 12B) and two datasets (MCQ QA); missing are:
- larger (70B+) and MoE models,
- multimodal models,
- long-form free-form generation metrics (coherence, factuality),
- tool/agentic settings (function-calling, retrieval),
- latency/throughput during subsequent decoding.
- Integration with inference systems: end-to-end throughput gains with PagedAttention, prefix caching, speculative decoding, batching, and KV packing are not benchmarked; system-level bottlenecks and engine compatibility remain unclear.
- Quantization and memory formats: the approach is evaluated in FP32/BF16 only; interactions with KV quantization and mixed precision used in production are unexplored.
- Robustness and worst-case behavior: no stress tests for adversarial contexts or rare-query regimes; failure modes where selected keys miss rare but critical information are not characterized.
- Sliding-window and hybrid architectures: only global layers are compacted in Gemma-3; how to co-design compaction with dynamic/local windows, or extend to state-space/recurrent architectures, is open.
- Repeated/online compaction: preliminary results suggest feasibility, but there is no systematic study of compaction frequency, cumulative error over long horizons, or policies for when and what to compact during ongoing interactions.
- Hyperparameter sensitivity: guidance is lacking for choosing
t(budget per head),n(number of queries per head), OMP parameters (batch size, refit interval), and chunk size; ablations quantify importance but do not provide robust defaults or auto-tuning. - Cross-head and cross-layer coupling: assuming independent per-head mass/output matching may ignore dependencies mediated by the residual stream; methods that co-optimize heads/layers jointly are uninvestigated.
- Safety and calibration: the impact of attention-mass reweighting on model calibration, harmful content risks, or distributional shifts is not evaluated.
- RoPE and position handling: logical-length preservation is asserted, but edge cases (e.g., RoPE scaling, interpolation/extrapolation, dynamic position encodings) under compaction and chunk merging lack formal or empirical analysis.
- Determinism and reproducibility: stochastic self-study and OMP selection might induce variance; sensitivity to seeds and reproducibility across runs and hardware is not reported.
- Storage and serialization: the overheads of storing compact caches (per-head β, varlen packing metadata) and their lifecycle management (e.g., reuse across sessions) are not quantified.
- Theoretical decomposition: while attention mixing decomposition is used, no formal equivalence is shown between matching local outputs + mass and preserving concatenated attention beyond sampled queries; tighter theory would clarify sufficiency/necessity.
- Data privacy and leakage: since compacted latent caches preserve behavior, risks of reconstructing sensitive content from
C_k,C_v, and β are unaddressed; privacy-preserving compaction is an open avenue. - Automated budget schedulers: learning per-model schedules once is suggested, but how to automate schedule discovery reliably, transfer to model variants, or adapt online to context constraints (memory/latency) remains open.
Practical Applications
Practical Applications of “Fast KV Compaction via Attention Matching”
Below are actionable, real-world applications that follow from the paper’s findings and methods—focusing on fast, latent-space KV cache compaction via Attention Matching (AM), per-head nonuniform budgets, chunked compaction, and closed-form fitting of biases and values. Each item includes sector alignment and key dependencies that influence feasibility.
Immediate Applications
The following can be deployed now with standard engineering effort and without model retraining.
- LLM inference memory/cost reduction in production
- Sector: software/cloud/AI infrastructure
- What: Integrate AM as a primitive in inference engines (e.g., vLLM, TensorRT-LLM, TGI) to reduce KV cache size by 20–50× with minimal quality loss; trigger compaction after prefill or when cache exceeds a threshold.
- Tools/products: “AM-KV” plugin, “KV budget scheduler” using precomputed per-head budgets, varlen KV packer for nonuniform per-head ratios.
- Workflow: prefill → sample reference queries (repeat-prefill/self-study) → select keys (highest-attention or OMP-fast) → fit biases (NNLS) → fit values (LS) → replace KV cache with compacted version → continue decoding.
- Dependencies/assumptions: attention implementations must support per-token scalar bias (e.g., PyTorch SDPA, FlexAttention); access to KV states and the ability to run prefill; variable-length per-head packing to realize compute/memory savings; quality hinges on reference-query coverage.
- Long-horizon chat, CRM, and call center assistants with low drift
- Sector: customer support/enterprise SaaS
- What: Maintain multi-session histories without aggressive summarization by compacting older dialogue turns in latent space, preserving attention behavior over salient details.
- Tools/products: “Session compactor” that runs on idle or on a schedule; dashboards to tune compaction ratios per tenant.
- Dependencies/assumptions: repeat-prefill or light self-study for query extraction; per-head nonuniform budgets improve stability; ensure chat template tokens are exempt or handled carefully.
- Coding assistants and agentic development tools
- Sector: software engineering/dev tools
- What: Online compaction during long coding sessions to keep execution traces, logs, and edits accessible within fixed VRAM/RAM budgets; reduces reliance on lossy summaries.
- Tools/products: IDE plugin (VS Code/JetBrains) that invokes AM when memory thresholds are exceeded; “agent memory manager” that compacts mid-trajectory.
- Dependencies/assumptions: on-policy query extraction improves later-layer alignment; compaction time (seconds–minutes) is acceptable between tool calls or pauses.
- Clinical document QA and patient-record assistants
- Sector: healthcare
- What: Apply AM to EHR-scale contexts (validated on LongHealth) to enable long-document question answering without retraining; compacted caches improve latency/memory use.
- Tools/products: “EHR QA service with AM” deployed on secure infra; optional hybrid “Summarize + AM” for extreme compaction.
- Dependencies/assumptions: HIPAA compliance (process within secure boundaries); reference queries should capture clinical styles of access; extreme compaction (>50×) may degrade more on dense medical records.
- Legal, finance, and compliance document analysis
- Sector: legal/finance/compliance
- What: Compact long filings, contracts, and research reports as reusable latent caches for repeated querying across teams.
- Tools/products: “Compact cache library” per document; cached AM artifacts stored alongside document metadata for fast QA.
- Dependencies/assumptions: initial prefill + compaction costs amortized across many queries; document updates require re-compaction; quality depends on coverage of reference queries.
- Education and tutoring systems with persistent memory
- Sector: education
- What: Keep per-learner history (progress, misconceptions, goals) and course materials available across sessions without summarization loss.
- Tools/products: “Tutor memory compactor” that refreshes student history at session start; nonuniform head allocation per model.
- Dependencies/assumptions: sampling of representative queries during prefill/self-study; guardrails for sensitive content storage as latent caches.
- On-device and edge assistants
- Sector: mobile/IoT/embedded
- What: Use AM to fit longer effective contexts into limited RAM/VRAM on phones/edge devices; combine with sliding-window models by compacting only global-attention layers (as shown with Gemma-3).
- Tools/products: MLC-LLM or mobile inference runtimes with AM hooks; periodic background compaction when device is idle/charging.
- Dependencies/assumptions: attention-bias support in edge kernels; power budget for short compaction steps; reference-query generation minimized (repeat-prefill preferred).
- Summarization pipelines with retained fidelity
- Sector: knowledge management/RAG/enterprise search
- What: Apply AM on top of textual summaries to reduce memory further while maintaining summary-level quality (paper shows ~200× total compaction with similar accuracy to summary alone).
- Tools/products: “Summarize+AM” pipeline stage in RAG; store compact latent memory accompanying summaries.
- Dependencies/assumptions: acceptable to cap information to what summaries contain; AM preserves summary behavior, not omitted details.
- Cloud cost and sustainability optimization
- Sector: cloud operations/FinOps
- What: Reduce GPU memory pressure and increase batch concurrency by compacting KV caches; translate to lower cost per token and reduced energy use.
- Tools/products: autoscalers that trigger compaction at load spikes; cost/latency predictors aware of compaction trade-offs.
- Dependencies/assumptions: reference-query generation overhead amortized; nonuniform per-head schedules precomputed once per model; observability to track quality/latency impact.
- Research utilities for model analysis
- Sector: academia/AI research
- What: Use AM’s head-sensitivity profiling and on-policy query collection to study memory usage, head roles, and long-context behavior across models.
- Tools/products: “Head budget profiler” that precomputes reusable per-head allocations; ablation workbenches comparing OMP vs attention-score selection.
- Dependencies/assumptions: approximate separability of head sensitivities holds well; portability across datasets is strong but should be validated per model.
Long-Term Applications
These require further research, engineering, or ecosystem support to scale broadly.
- Online, continual compaction for long-horizon agents
- Sector: software agents/automation/robotics
- What: A robust “memory manager” that compacts mid-trajectory with policies conditioned on task phase, available budget, and observed degradation—enabling arbitrarily long operation at fixed cost.
- Tools/products: agents that dynamically swap compaction ratios across heads/layers; adaptive reference-query sampling on-device.
- Dependencies/assumptions: real-time constraints; better algorithms for faster key selection and query sampling; strong guarantees on compounding error.
- Compaction-aware model training and architectures
- Sector: AI model development
- What: Train models with objectives or structures that make attention-matching compaction more faithful (e.g., keys optimized for aggregatability, explicit global slots, or compaction-aware bias terms).
- Tools/products: “Compaction-ready” transformer variants; pretraining with mass/attention-output matching proxies; combined sliding-window + compact-global designs.
- Dependencies/assumptions: changes to training pipelines; evaluation of generalization under extreme compaction (>100×).
- Memory tiers combining AM with gradient-optimized Cartridges
- Sector: AI infrastructure
- What: Tiered memory where AM handles fast, frequent compactions and Cartridges (or similar) are invoked for ultra-high-compaction archives or premium sessions.
- Tools/products: “Memory tier orchestrator” that chooses AM vs. Cartridges based on latency/quality targets.
- Dependencies/assumptions: scheduling logic to trade time vs. quality; standardized cache interchange formats.
- Privacy-optimized latent session storage
- Sector: compliance/security
- What: Store compacted latent KV caches instead of raw text for session handoff/resumption to reduce exposure to PII and sensitive content while retaining utility.
- Tools/products: “Latent session vaults” with access controls and deletion policies; risk assessments for inversion attacks.
- Dependencies/assumptions: empirical evidence that latent caches reduce privacy risk; mechanisms to refresh caches as contexts evolve.
- Knowledge-base precompaction for enterprise corpora
- Sector: enterprise search/KM
- What: Precompute AM caches per document/chunk as shared latent “memory objects” reusable across users and tasks for faster query-time inference.
- Tools/products: “Compact KV library” attached to document indices; cache routing based on task metadata.
- Dependencies/assumptions: robustness to query distribution shift across workloads; versioning and invalidation strategies for content updates.
- Multi-tenant GPU scheduling and hardware co-design
- Sector: cloud/hardware
- What: Scheduler policies that exploit compaction to pack more concurrent requests; potential co-design for fast NNLS/LSQ kernels or in-network compaction services.
- Tools/products: compaction-aware batching; dedicated accelerators for mass/LS solves.
- Dependencies/assumptions: kernel-level support for attention bias and varlen per-head packing is widespread; measurable ROI for specialized kernels.
- Robotics and embedded autonomy with language-planning loops
- Sector: robotics/industrial automation
- What: Maintain long-range task context and plans on-board using compacted caches, minimizing compute while preserving key dependencies for LLM-based planners.
- Tools/products: embedded AM modules in Jetson-class systems; safety-certified memory management policies.
- Dependencies/assumptions: strict real-time guarantees; robust online compaction; kernels supporting attention bias on embedded platforms.
- Standards and benchmarking for compaction primitives
- Sector: standards/consortia/policy
- What: Define APIs and test suites for per-token attention bias, varlen per-head caches, and compaction quality metrics (attention mass/output preservation).
- Tools/products: open benchmarks across domains (healthcare, legal, education) at 20–200× compaction; reference implementations across frameworks.
- Dependencies/assumptions: community and vendor alignment (PyTorch/JAX/TVM, inference engines, cloud providers); governance for model-agnostic comparability.
- Energy-efficiency policy and reporting
- Sector: sustainability/policy
- What: Encourage adoption of compaction techniques in AI services through energy reporting frameworks and incentives, recognizing reduced VRAM footprints and improved throughput.
- Tools/products: best-practice guides; emissions calculators incorporating compaction gains.
- Dependencies/assumptions: standardized measurement protocols; verifiable baselines and disclosures from providers.
Notes on feasibility and general assumptions across applications:
- Quality depends on the representativeness of reference queries (repeat-prefill and lightweight self-study work well in most cases; on-policy queries further help for later layers).
- Nonuniform head budgets require either precomputation per model or runtime heuristics; varlen per-head packing is needed to avoid padding overheads.
- Extreme compaction (>100×) may benefit from optimization-heavy methods (e.g., Cartridges); AM excels in speed and performs best up to ~50× in many settings.
- Attention biases add negligible runtime/memory and are supported in common kernels; broad framework support is still a practical dependency.
- Chunked compaction is recommended for very long contexts; KV-based chunking more faithfully preserves behavior than text-only chunking.
Glossary
- ALiBi: A positional encoding technique that adds linear biases to attention scores to enable length extrapolation. "The notion of adding a per-token scalar attention bias was suggested in T5~\cite{raffel2020t5} and ALiBi~\citep{press2022train} as a form of positional encoding."
- Attention biases: Per-token scalar terms added to attention logits to adjust a compacted block’s contribution (e.g., mass) without changing key vectors. "We therefore introduce a per-token scalar bias , which multiplicatively reweights the contribution of each retained key to the mass."
- Attention Matching: An objective that constructs compact keys and values to reproduce a block’s attention outputs and attention mass over reference queries. "Attention Matching, which constructs compact keys and values to reproduce attention outputs and preserve attention mass at a per-KV-head level."
- Attention mass: The total unnormalized attention weight a block receives from a query, used to preserve a block’s contribution under concatenation. "match (i) the compacted block's local attention output and (ii) its attention mass."
- Attention outputs: The locally normalized attention-weighted sum of values produced by a key–value block for a given query. "constructs compact keys and values to reproduce attention outputs and preserve attention mass"
- Autoregressive LMs: LLMs that generate tokens sequentially, conditioning each step on all previous tokens. "For autoregressive LMs based on the Transformer architecture, the memory bottleneck is specific: the key–value (KV) cache."
- Cartridges: A method that trains compact latent KV caches (via prefix-tuning on self-study data) to match full-context behavior. "Cartridges uses prefix-tuning~\citep{li2021prefix} on synthetic ``self-study'' data to train a compact KV cache for a given context."
- Cascade Inference: An inference technique that exploits block-wise decomposition of attention for shared-prefix batch decoding. "Efficient attention implementations such as FlashAttention~\citep{dao2022fa} and Cascade Inference~\citep{ye2024cascade,juravsky2024hydragen} exploit the same decomposition."
- Chunked compaction: Performing compaction independently on contiguous chunks of a long input, then concatenating the compacted caches. "Chunked Compaction"
- Compaction ratio: The factor by which the KV cache is reduced relative to its original size. "using a single H100 GPU at a fixed 50 compaction ratio."
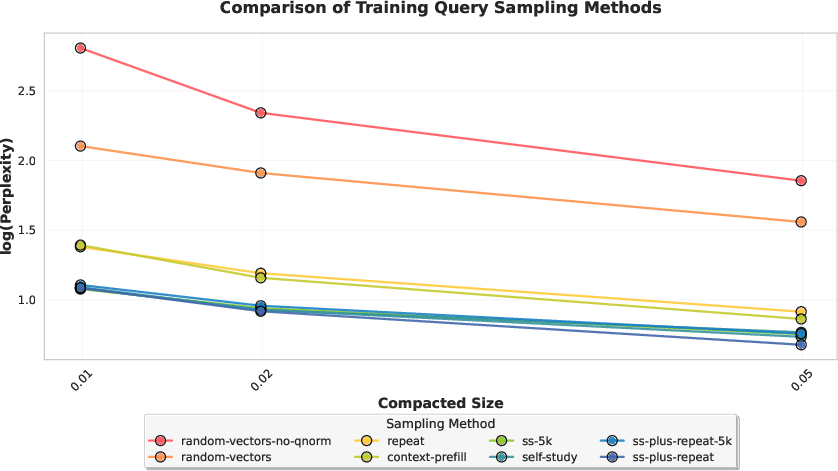
- Context-prefill: Extracting queries by running a prefill on the original context only, without repetition, as a faster but slightly worse proxy. "the simpler variant of running a prefill on alone, which we call context-prefill (and used by H2O~\citep{zhang2023h2o}), was cheaper ... but performed slightly worse than repeat-prefill."
- DuoAttention: An approach that partitions attention heads into retrieval vs. streaming heads to manage KV capacity. "DuoAttention~\citep{xiao2025duoattention} proposes that attention heads be split into a small set of retrieval heads that use a full-length KV cache, and streaming heads that can run with a constant-length cache"
- FlashAttention: An IO-aware attention kernel that computes exact attention with high speed and low memory use. "Efficient attention implementations such as FlashAttention~\citep{dao2022fa} ... exploit the same decomposition."
- GQA: Grouped Query Attention; an attention variant where multiple queries share keys/values, yielding multiple query vectors per token per head. "under GQA, each token yields multiple query vectors per KV-head"
- Global-attention layers: Layers with full-sequence attention (as opposed to sliding-window), often targeted for compaction in hybrid models. "we compact only the global-attention layers, leaving the sliding-window layers unchanged."
- Greedy exchange algorithm: A discrete resource-allocation procedure that iteratively swaps KV budget between heads to minimize loss. "we solve a discrete resource allocation problem using a standard greedy exchange algorithm (Algorithm~\ref{alg:head_budget_swaps})."
- H2O: Heavy-Hitter Oracle; a token-eviction baseline that retains tokens with high attention. "context-prefill (and used by H2O~\citep{zhang2023h2o})"
- KV-based chunking: A chunking variant that compacts slices of the model’s actual KV states from a full prefill, then merges them. "In KV-based chunking, we prefill the full context, slice out the KV states corresponding to each chunk, compact them independently, and merge the compacted chunks."
- KV cache: The per-token memory of keys and values stored during transformer attention, often the main memory bottleneck. "the key–value (KV) cache."
- KVzip: A query-agnostic KV compression baseline that reconstructs context to guide token selection. "KVzip sometimes matches Attention Matching performance, which we attribute to its non-uniform budget"
- Least squares: A linear regression approach used to fit compacted values to match attention outputs over reference queries. "With and fixed, we can solve for with ordinary least squares."
- Lexico: A compression method that learns per-layer dictionaries and uses sparse coding (OMP) to reconstruct KV vectors. "Lexico~\citep{kim2025lexico}, which compresses keys and values by learning a universal dictionary per layer and uses orthogonal matching pursuit (OMP) at inference time"
- Nonnegative least squares (NNLS): A constrained regression used to fit mass weights (biases) with nonnegative coefficients. "We solve for this via nonnegative least squares (NNLS; see Appendix~\ref{app:nnls} for implementation details)"
- Nonuniform compaction: Assigning different KV budgets to different heads/layers rather than using a fixed ratio everywhere. "we say that uniform compaction uses the same ratio for every KV-head at every layer, whereas nonuniform compaction assigns a potentially different ratio to each head and layer."
- On-policy queries: Reference queries extracted after earlier layers have been compacted, reducing distribution mismatch. "optimize compaction at layer using these on-policy queries."
- Orthogonal matching pursuit (OMP): A greedy sparse selection algorithm used to choose keys and fit biases to match attention mass. "orthogonal matching pursuit \citep[OMP;] []{tropp2007signal}, which greedily builds and to best satisfy Eq.~\ref{eq:mass-match}."
- Pareto frontier: The tradeoff curve of compaction speed vs. quality where improving one dimension would worsen the other. "Our attention-matching (AM) methods trace a speed--quality tradeoff and form the Pareto frontier"
- Prefix-tuning: A technique that optimizes continuous prefix vectors to steer generation without full model finetuning. "Cartridges uses prefix-tuning~\citep{li2021prefix} on synthetic ``self-study'' data"
- Repeat-prefill: Extracting queries by instructing the model to repeat the context and capturing the queries used to reconstruct it. "Following KVzip~\citep{kim2025kvzip}, we construct a sequence ... run a prefill pass on this sequence ... We found that ... performed slightly worse than repeat-prefill."
- Residual stream: The running hidden state in transformer layers; compaction changes it and thus later-layer queries. "compacting early layers changes the residual stream seen by later layers"
- Rotary embeddings (RoPE): A positional encoding that rotates key/query vectors by position-dependent phases. "Rotary embeddings are assumed to have already been applied to cached keys."
- Sliding-window attention: Attention restricted to a local window, used in hybrid models with a few global layers. "hybrid architectures with sliding-window attention~\citep{child2019sparsetransformers, beltagy2020longformer}"
- SnapKV: A token-selection baseline that predicts important tokens before generation using attention signals. "SnapKV~\citep{li2024snapkv}"
- Token eviction: Reducing KV size by dropping less-important tokens according to attention or heuristic scores. "Existing approaches to KV cache reduction, such as token eviction \citep{zhang2023h2o, li2024snapkv, kim2025kvzip}"
- Token merging: Reducing KV size by combining multiple tokens’ states into fewer representatives. "token merging \citep{wang2024modeltells, zhang2024cam}"
- Varlen representation: A packed, variable-length storage/layout for per-head KV segments that avoids padding overhead. "packing per-head KV segments into a flat, variable-length (varlen) representation."
- Wall-clock time: Actual elapsed time to perform compaction, used to assess efficiency. "plotted against the average wall-clock time required to compact a context (seconds, log-scale)"
Collections
Sign up for free to add this paper to one or more collections.