- The paper proposes a Social Meta-Learning framework that fine-tunes LLMs through multi-turn, dialogue-based reinforcement learning with integrated language feedback.
- It demonstrates that online multi-turn RL outperforms single-turn RL and supervised fine-tuning, ensuring robust cross-domain generalization.
- The study reveals that Q-priming boosts clarification-seeking behavior and reduces premature answers, leading to adaptive and interactive dialogue strategies.
Motivation and Context
LLMs deployed for conversational tasks exhibit limited adaptive capabilities when interacting with users, primarily due to their passive stance in soliciting and integrating corrective feedback. This leads to static, unidirectional dialogues, and a reliance on prompt engineering rather than dynamic conversational learning. Drawing from social meta-learning (SML) paradigms observed in human developmental learning, the authors formulate SML as a fine-tuning methodology for LLMs, whereby static task instances are converted into pedagogical multi-turn dialogues with a privileged-information teacher. The core objective is to enhance the model’s ability to proactively seek clarifications, absorb feedback, and adapt to ambiguity in a manner that generalizes across domains.
The SML framework is formalized as a POMDP. Student models (parameterized as θS) interact in pedagogical dialogues with teacher models endowed with privileged information (ground truth, verifier outputs, etc.), thereby imposing an information asymmetry. The student action space is constrained to natural language utterances, and rewards are sparse at the conversation level (success/failure per trajectory). SML fine-tuning comprises two main variants: (1) offline RL (supervised fine-tuning on filtered successful rollouts) and (2) online RL (GRPO algorithm with group-normalized reward across conversational trajectories).
Additionally, Q-priming is introduced as a preliminary SFT stage to explicitly bootstrap question-asking behaviour. Informative queries are synthetically injected based on teacher knowledge, decaying over conversational turns to promote early exploratory interaction.
Empirical Evaluation
The central empirical result establishes the superiority of online multi-turn RL over both single-turn RL and SFT baselines in the context of math reasoning (Omni-MATH benchmark). SML-trained models exhibit a pronounced ability to generalize to longer test-time conversational interactions (training at N=4 turns enables effective adaptation up to N=10 turns), with the performance gap widening as interaction depth increases.
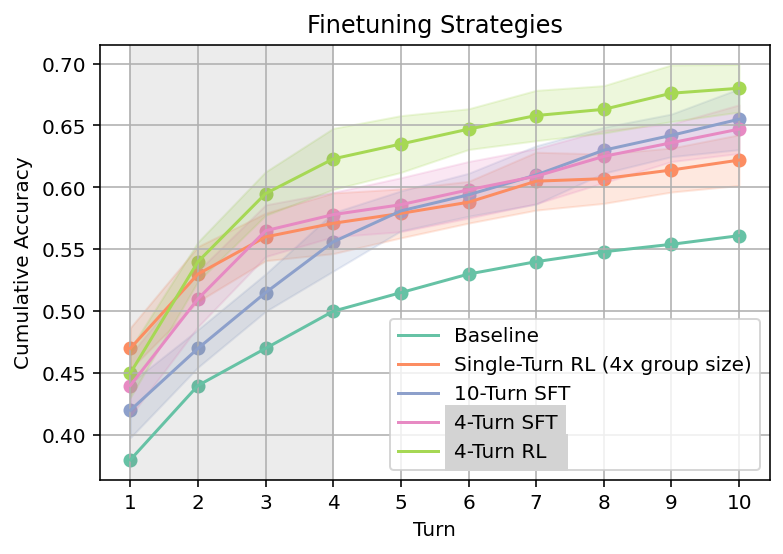
Figure 1: Multi-turn RL significantly outperforms single-turn RL and SFT on Omni-MATH across extended conversational turns.
The use of a stronger teacher at inference time yields more informative feedback to the student, but contrary to intuition, the strength of the teacher during SML training is not critical for downstream student performance, indicating that peer-level teacher models suffice for effective SML training.
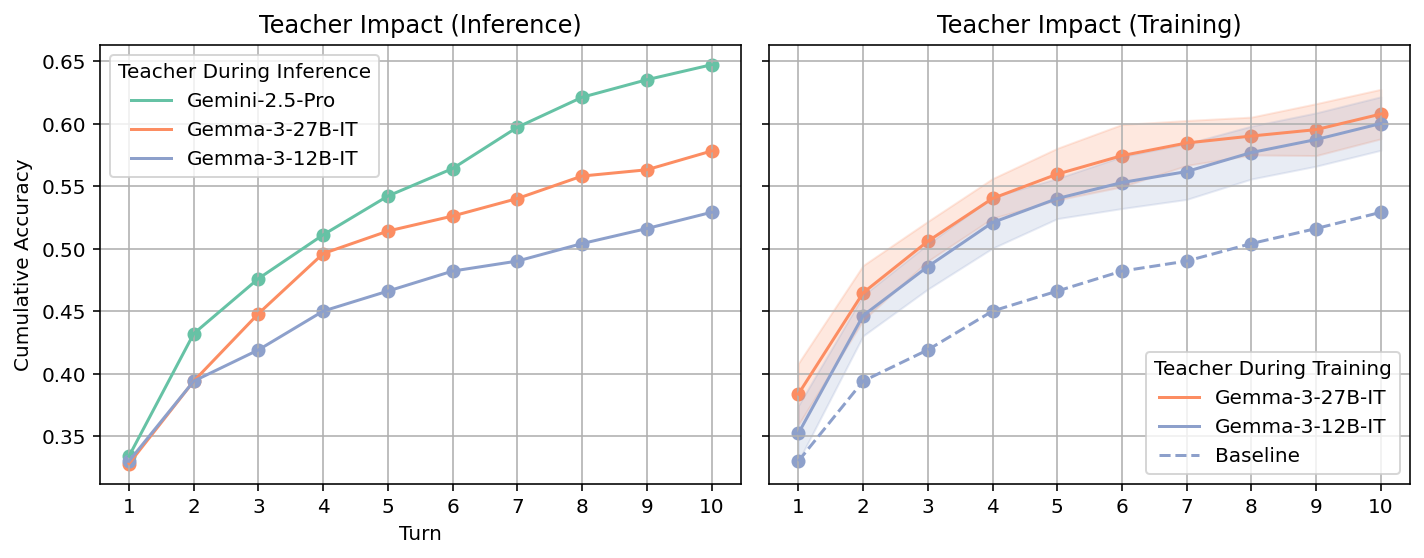
Figure 2: Stronger teacher models at test time provide more effective feedback, but teacher strength during SML training is not essential.
Analysis of token-level loss trajectories demonstrates a marked reduction in loss for SML-trained models following successive teacher turns, confirming an internalization of feedback integration strategies.
Domain Generalization of SML
The ability to learn from language feedback generalizes robustly across both math (Omni-MATH) and code (LiveCodeBench, OpenCodeInstruct) domains. Models SML-trained in math transfer improved learning-from-feedback capabilities to coding tasks, and vice versa.
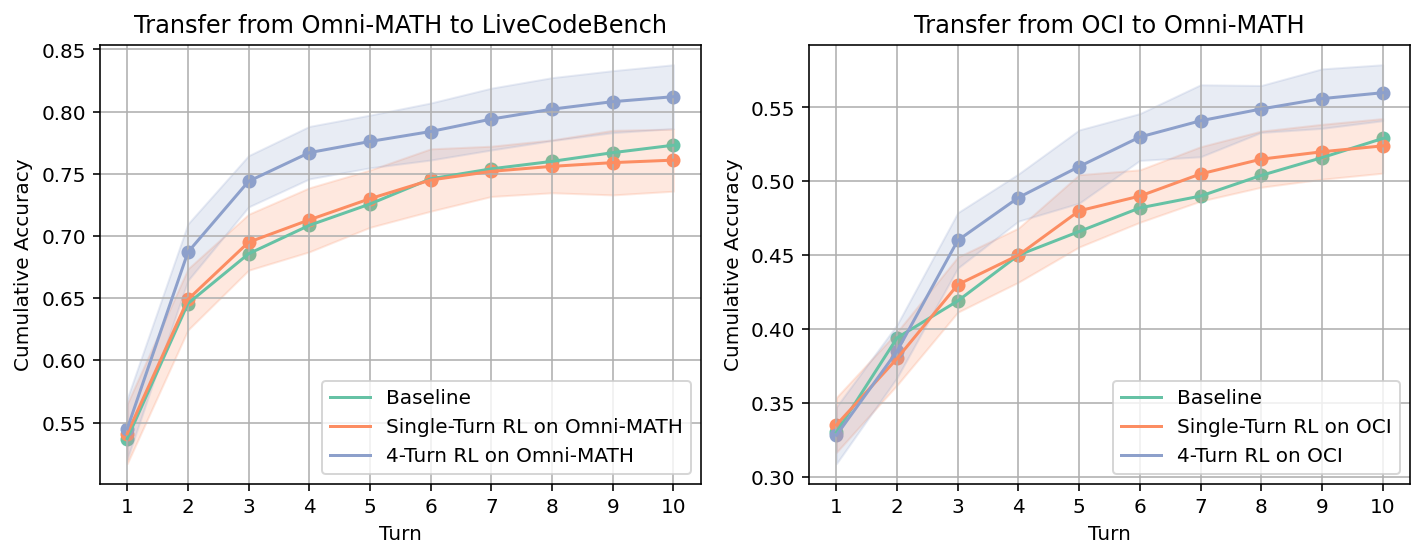
Figure 3: SML-trained models transfer the ability to learn from feedback between math and code domains, outperforming baselines in multi-turn settings.
This indicates that dialogic meta-learning via SML induces cross-domain reusable strategies for feedback assimilation, extending beyond the task-specific memorization observed in traditional SFT approaches.
Behavioural Adaptation and Handling Ambiguity
SML, particularly when augmented via Q-priming, enhances the model’s capacity to handle underspecified or incrementally revealed information. On the Lost-in-Conversation benchmark, SML-trained models make significantly fewer premature answer attempts and demonstrate substantial increases in clarification-seeking turns.
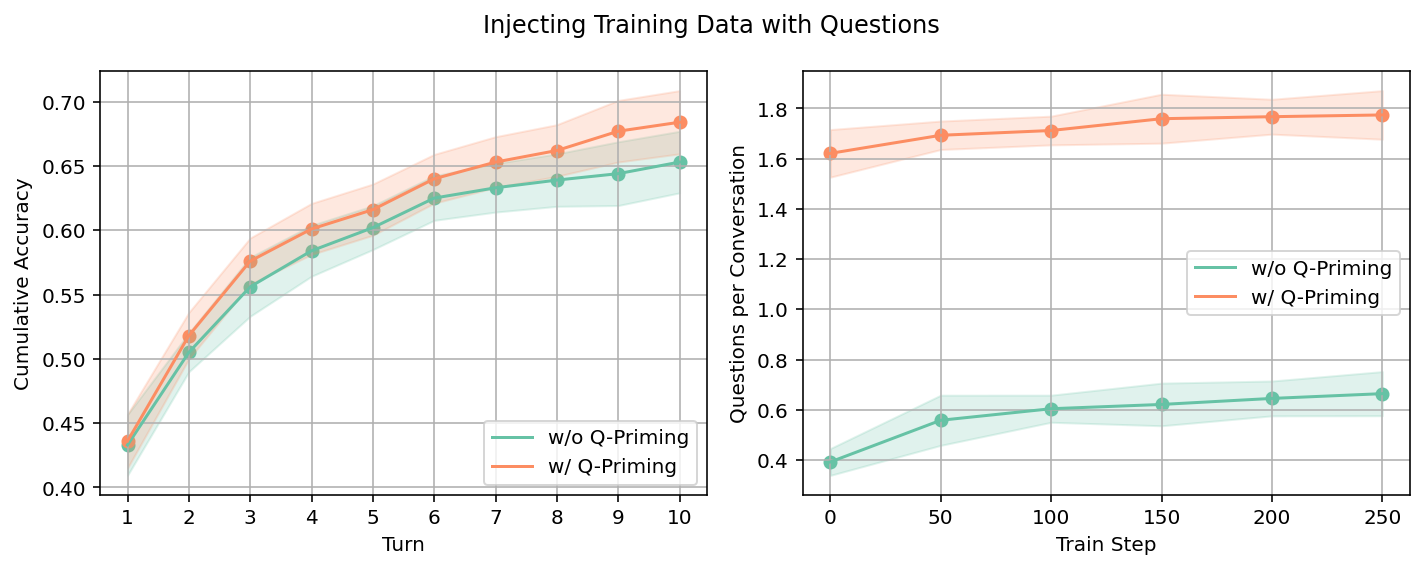
Figure 4: Q-priming increases both question-asking and multi-turn performance for SML-trained models on Omni-MATH.
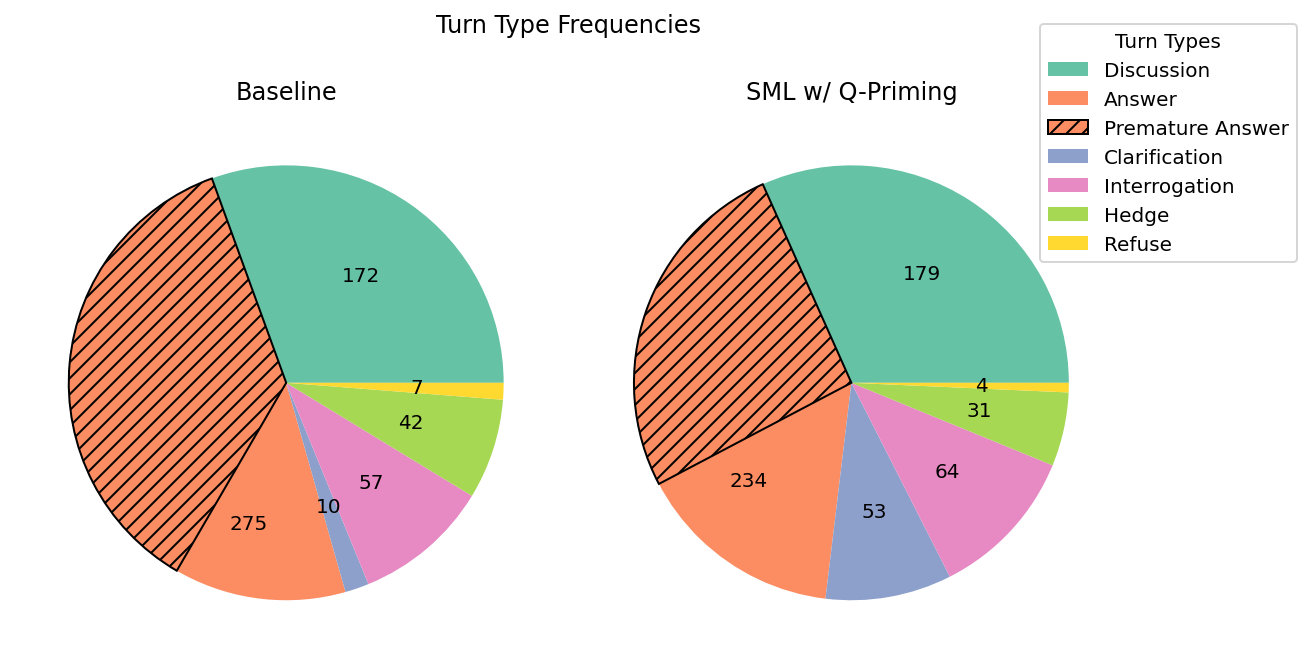
Figure 5: SML with Q-priming yields a five-fold increase in clarification-seeking behaviour and a marked reduction in presumptive answer attempts.
This behavioural reconfiguration represents a strong departure from passive response strategies inherently present in LLMs, aligning more closely with collaborative and human-compatible interaction norms.
Practical and Theoretical Implications
The SML paradigm reframes static input-output tasks as interactive, in-context learning opportunities, facilitating the development of dialogically adaptive LLMs. The robust domain generalization and behavioural flexibility observed suggest that SML finetuning is an effective pathway to scalable, collaborative assistants, reducing reliance on prompt engineering and enabling adaptation to evolving user information over prolonged interactions. The empirical results contradict claims that RL-based post-training does not generalize to multi-turn settings, establishing that online RL within SML is preferable to SFT for dynamic dialogue adaptation.
From the theoretical perspective, casting pedagogical dialogue as a POMDP aligns LLM behaviour with agentic models in RL, opening avenues for further exploration in dynamic, evolving task goals and subjective reward structures. The use of sparse, conversation-level rewards is amenable to extension to denser reward regimes or subjective evaluation metrics.
Future Directions
Areas for extension include adaptation of SML to non-verifiable, open-ended tasks that lack strict correctness signals, integration of turn-level reward judgements to improve sample efficiency, and introduction of non-static task objectives reflecting dynamic user intent. Additionally, applying SML to agentic frameworks involving multiple LLM participants (multi-agent systems) could further bootstrap cooperative and competitive conversational skills.
Conclusion
The paper establishes SML as a scalable fine-tuning methodology for enhancing LLM responsiveness to language feedback, generating models capable of handling ambiguity, seeking clarifications, and generalizing across domains. Online RL outperforms SFT in these settings, and Q-priming successfully instills exploratory question-asking strategies. The theoretical underpinnings, empirical evidence, and behavioural analyses position SML as a pivotal approach for advancing the adaptive conversational abilities of large-scale generative models (2602.16488).