Improving Interactive In-Context Learning from Natural Language Feedback
Abstract: Adapting one's thought process based on corrective feedback is an essential ability in human learning, particularly in collaborative settings. In contrast, the current LLM training paradigm relies heavily on modeling vast, static corpora. While effective for knowledge acquisition, it overlooks the interactive feedback loops essential for models to adapt dynamically to their context. In this work, we propose a framework that treats this interactive in-context learning ability not as an emergent property, but as a distinct, trainable skill. We introduce a scalable method that transforms single-turn verifiable tasks into multi-turn didactic interactions driven by information asymmetry. We first show that current flagship models struggle to integrate corrective feedback on hard reasoning tasks. We then demonstrate that models trained with our approach dramatically improve the ability to interactively learn from language feedback. More specifically, the multi-turn performance of a smaller model nearly reaches that of a model an order of magnitude larger. We also observe robust out-of-distribution generalization: interactive training on math problems transfers to diverse domains like coding, puzzles and maze navigation. Our qualitative analysis suggests that this improvement is due to an enhanced in-context plasticity. Finally, we show that this paradigm offers a unified path to self-improvement. By training the model to predict the teacher's critiques, effectively modeling the feedback environment, we convert this external signal into an internal capability, allowing the model to self-correct even without a teacher.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Improving Interactive In-Context Learning from Natural Language Feedback”
1) What is this paper about?
This paper is about teaching AI chatbots to learn better during a conversation—kind of like a student who listens to a teacher’s hints and fixes mistakes step by step. Instead of only studying huge, fixed datasets, the AI is trained to pay attention to feedback in natural language and use it to improve its answers over multiple turns.
2) What questions are the researchers asking?
The researchers mainly ask:
- Can today’s AI models actually use feedback from a person (or another model) to improve their answers over several back-and-forth turns?
- If not, can we train them to do this better by practicing in teacher–student-style conversations?
- Can a smaller model trained this way catch up to a much larger model?
- If the model learns this skill on math problems, will it also help in other areas like coding, puzzles, or games?
- Can the model eventually learn to “teach itself” by predicting the kinds of feedback a teacher would give?
3) How did they do it? (Methods in everyday language)
The core idea is to turn regular, single-step problems into multi-turn “teaching” conversations:
- Teacher–student setup:
- The “student” model tries to solve a problem (like a math question or a coding task).
- The “teacher” has extra information—like an answer key or unit test results—but does not reveal the final answer. Instead, the teacher gives helpful hints about what went wrong.
- The student tries again, using the new hint. This can repeat for several turns.
- Information asymmetry:
- This just means the teacher sees more than the student (for example, the correct answer or test outputs). That extra info helps the teacher give useful, targeted feedback without spoiling the answer.
- Verifiable tasks:
- They use problems where it’s easy to check if the final answer is right—like math problems with known solutions or code that must pass tests. That way, there’s an automatic checker that says “correct” or “incorrect.”
- Reinforcement Learning (RL) with language feedback:
- Think of RL like a game with points: the model gets a reward when it ends with the correct answer.
- If the student solves the problem, it gets a point; if not, it gets nothing. This simple score teaches the model which behaviors work.
- Over many practice conversations, the student learns to use the teacher’s hints more effectively.
- In-context learning and plasticity:
- “In-context learning” means adjusting your answers within the same conversation, without changing the model’s permanent settings.
- “Plasticity” here means being flexible: the model should update its thinking when it hears a good critique, instead of repeating the same mistake.
- Self-improvement:
- The team also trains the model to predict what the teacher would say. Later, at test time, the model can play both roles—student and teacher—giving itself critiques and fixing its own answers even when no teacher is available.
4) What did they find, and why is it important?
Here are the main results:
- Many top AI models struggle to use feedback across turns on hard problems. Even with hints, they often keep making the same mistake.
- Training with multi-turn “didactic” (teaching) interactions worked much better than standard training:
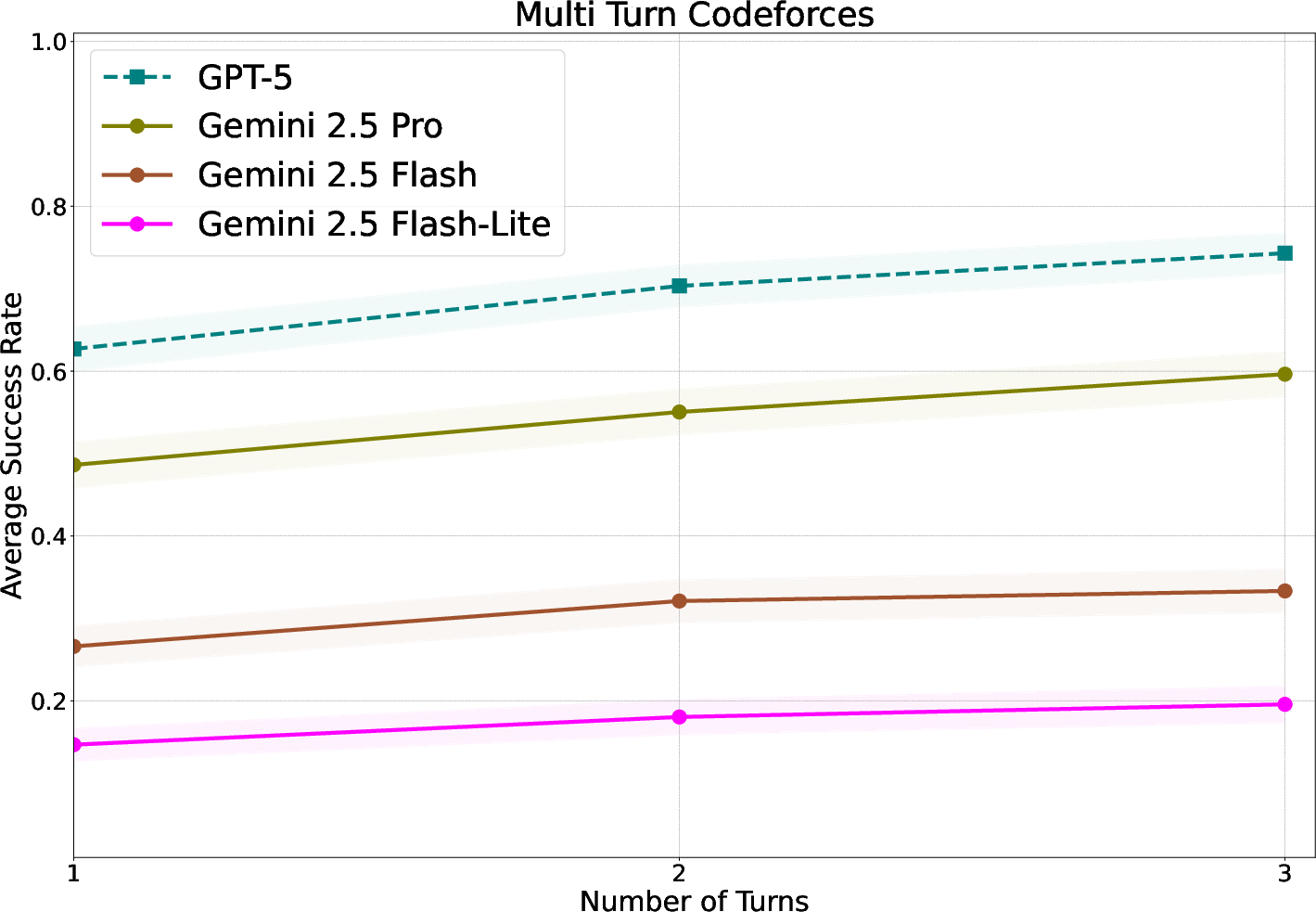
- A smaller model (Gemini 2.5 Flash), after this training, nearly matched the performance of a much larger model (Gemini 2.5 Pro) on a tough math benchmark.
- Compared to two common baselines—supervised fine-tuning (learning from solutions) and single-turn RL—this multi-turn method improved more with each extra turn of feedback.
- The skill transfers to new areas:
- A model trained only on math feedback got better at coding tasks, logic puzzles, and even games like Wordle and Poker. That means it learned a general skill: how to learn from feedback in a conversation.
- Increased in-context plasticity:
- The trained model was more willing to change its answer when given a good hint, instead of sticking to the same wrong solution.
- Self-correction without a teacher:
- When trained to predict teacher feedback, the model could later critique and correct itself. In some cases, this self-improvement was even stronger than when it interacted with an external teacher at test time.
Why this matters:
- It shows a practical way to make AI models more teachable and responsive during real conversations—so users can guide them without fancy prompts or extra training.
- It’s data-efficient: You can convert many existing problems into teaching conversations and get big gains.
5) What’s the big picture? (Implications and impact)
- More helpful AI assistants: Models that quickly learn from your hints can save time and reduce frustration. You can correct them, and they actually adapt in the same chat.
- Scalable training: Turning ordinary problems into multi-turn teaching sessions can powerfully improve “learning-to-learn” behavior, even for smaller models.
- General skills: Learning to use feedback isn’t just for math—it carries over to coding, puzzles, and interactive tasks.
- Toward self-improving AI: By modeling the teacher’s critiques, a single model can learn to critique itself and improve without outside help.
- Open questions and safety:
- The authors note future work should explore teacher-designed curricula (choosing the right problems at the right time).
- They also flag safety concerns: if a model becomes too eager to please, it could become sycophantic (agreeing too easily), or misuse could occur. Careful design and evaluation are needed.
In short, this paper shows how to train AI to be a better “student” in conversations—listening to feedback, adjusting its answers, and even teaching itself—so it becomes more useful, flexible, and reliable across many tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address to strengthen, generalize, and safely deploy the proposed interactive in-context learning framework.
- Extension beyond verifiable tasks: How to adapt the method when no automatic verifier exists (e.g., subjective or open-ended tasks), including reward design and evaluation without ground-truth labels.
- Robustness to noisy or incorrect feedback: Sensitivity analyses and defenses when teacher feedback is ambiguous, partially correct, adversarial, or inconsistent (reflecting real human inputs).
- Feedback style sensitivity: Which feedback formats (hints vs. critiques vs. rationales), lengths, and granularities most effectively drive adaptation and across which domains.
- Prompting policies for teachers: Domain-agnostic, automated prompt strategies that reliably prevent answer leakage while preserving effectiveness, and their transferability across models/datasets.
- Leakage detection reliability: False-negative rates of the leakage-detector (string match + LLM judge), cross-model robustness, and information-theoretic bounds on unintentional leakage via subtle cues.
- RL algorithm specification and stability: Clear disclosure and comparison of optimization methods (e.g., PPO vs. DPO vs. RLAIF), stability under sparse rewards, and sensitivity to hyperparameters.
- Credit assignment across turns/tokens: Impact of per-turn reward shaping, intermediate improvement signals (e.g., partial unit-test passes), and variance-reduction techniques on learning efficiency.
- Compute and latency overheads: Quantify extra tokens, wall-clock latency, and energy per solved instance; measure cost-effectiveness vs. single-turn RL and SFT at comparable accuracy.
- In-context plasticity measurement: Develop quantitative metrics for “plasticity,” validate them across tasks, and link metric changes to accuracy gains over turns.
- Catastrophic forgetting/regressions: Systematic evaluation of single-turn and non-reasoning capabilities post-training to detect regressions from multi-turn optimization.
- Scaling laws: How gains vary with model size, training data volume, number of turns, and feedback quality; extrapolation to frontier-scale models.
- Generalization limits and failure modes: Diagnose tasks where gains are minimal or negative (e.g., Circuit Decoding), identifying domain characteristics that hinder transfer.
- Human-in-the-loop validation: Test with real users providing diverse, terse, or noisy feedback; measure teachability improvements and user effort required to correct errors.
- Safety and sycophancy: Quantify susceptibility to flattery, manipulation, and harmful instruction-following after increasing “adaptability”; develop calibration mechanisms.
- Curriculum and problem selection: Explore adaptive curricula (teacher-driven or error-aware sampling) to target weaknesses and accelerate learning.
- Mixed-motive social learning: Extend beyond cooperative teaching to debate, negotiation, and adversarial critiques; evaluate benefits, risks, and alignment challenges.
- Consolidation into long-term knowledge: Mechanisms to convert improved in-context behavior into durable weight-level capabilities without overfitting or drift.
- Self-improvement dynamics: Analyze stability of self-critique loops (mode collapse, confirmation bias), define stopping criteria, and prevent degenerative trajectories.
- Self-critique fidelity: Methods to estimate and improve the quality of self-generated feedback when no privileged information is available (e.g., uncertainty-aware critiques).
- Tool-use and embodied settings: Evaluate with tool-augmented agents (browsers, code execution, APIs) and in environments with external state transitions (beyond text-only).
- Multimodal and multilingual generalization: Test with visual/audio inputs and non-English feedback; study cross-lingual transfer of interactive learning skills.
- Teacher identity and parameter sharing: Effects of using distinct vs. shared teacher models, and whether updating the teacher (vs. freezing) improves outcomes or destabilizes training.
- Dependence on privileged information: Strategies for settings lacking ground-truth labels or unit tests (e.g., weak supervision, consensus signals, or post-hoc audits).
- Reward design alternatives: Impact of dense rewards (e.g., incremental unit-test pass counts), rank-based signals, and uncertainty-weighted rewards on sample efficiency and stability.
- Reproducibility and transparency: Public release of prompts, teacher templates, datasets, and hyperparameters to enable independent replication and fair comparison.
- Information leakage via critiques: Measure whether training on teacher critiques indirectly encodes labels/solutions and leads to shortcut learning; mitigation techniques.
- Interaction design and meta-instructions: Robustness to terse directives (e.g., “be concise”), meta-instructions, and shifting user intents; detection and adaptation policies.
- Token budget governance: How to enforce concision in revisions; trade-offs between brevity and accuracy; adaptive token allocation across turns.
- Rejecting low-quality feedback: Criteria and calibration for when to resist or defer on incorrect feedback while maintaining openness to correction.
- Bias and fairness: Assess whether feedback (human or model-generated) propagates or amplifies social biases into the autodidact; mitigation and auditing procedures.
- Turn-budget optimization: Methods to adaptively set or learn the maximum number of turns per task based on uncertainty, difficulty, or marginal gains.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s findings and methods (multi-turn didactic interactions via information asymmetry, RL with Language Feedback—RL2F, and self-critique for autodidactic correction). Each item notes target sector(s), possible tools/products/workflows, and key assumptions/dependencies.
- Test-anchored code repair and review assistants
- Sectors: Software, DevTools, QA
- Tools/products/workflows: “Fix-with-Feedback” coding copilot that runs unit tests (privileged signal), returns targeted hints without revealing the answer, and iterates until tests pass; CI/CD bot that takes failing jobs, provides language feedback to the model, and proposes patches; IDE plugin that uses compiler/linter errors as privileged signals to guide multi-turn repair.
- Assumptions/dependencies: Reliable automatic verifiers (unit tests, linters); careful prompt constraints and leakage checks so “teacher” doesn’t reveal solutions; multi-turn API support; access to project test suites.
- Adaptive customer support and service chatbots that learn mid-conversation
- Sectors: Customer Support, Commerce, Telecom, Public Services
- Tools/products/workflows: “Teach-Mode” where user corrections (privileged facts: account status, policy rules) trigger targeted feedback to the model for immediate course correction; workflows that re-run business-rule checkers after each turn to generate guided hints.
- Assumptions/dependencies: Verifiable back-end rule engines; logging and oversight to avoid sycophancy; data privacy and consent for using user feedback.
- Math and STEM tutoring with progressive hinting (no answer leak)
- Sectors: Education, EdTech
- Tools/products/workflows: Problem-set platforms that auto-generate didactic dialogues from answer keys/solutions; “Hint-first” tutors that correct reasoning step-by-step and measure student/model improvement over turns; dashboards measuring in-context plasticity for student modeling.
- Assumptions/dependencies: High-quality solution keys; robust leakage detectors; alignment to discourage revealing final answers.
- “Self-correct” inference mode for existing LLM deployments
- Sectors: Cross-cutting (software, education, enterprise productivity)
- Tools/products/workflows: Autodidactic/self-critique toggles that generate internal critiques and revisions before responding; guardrails to stop degenerate self-feedback loops; confidence gating to escalate to humans when self-correction stalls.
- Assumptions/dependencies: Budget for extra tokens/latency; well-tuned self-critique prompts; monitoring to detect repetition or mode collapse.
- Cheaper small-model swaps for task-specific assistants
- Sectors: Software, Education, Finance, Enterprise IT
- Tools/products/workflows: RL2F post-training of smaller “thinking” or “non-thinking” models to approach larger-model performance on verifiable domains (e.g., math, code) and multi-turn agentic tasks; model selection pipeline that compares single-turn vs multi-turn gains.
- Assumptions/dependencies: Access to verifiable tasks; compute for RL fine-tuning; evaluation harness for multi-turn performance and leakage.
- Compliance and policy assistants that incorporate rule-based feedback
- Sectors: Finance, Legal, Compliance, Insurance
- Tools/products/workflows: Assistants that treat rulebooks/checkers as privileged feedback sources (e.g., pre-trade compliance rules, regulator guidance), iteratively refining outputs until checks pass; audit logs of teacher hints vs model revisions.
- Assumptions/dependencies: Trustworthy rule engines; traceable logs; strong privacy and access control; domain adaptation to legal language.
- Medical administrative coding and documentation support (non-diagnostic)
- Sectors: Healthcare administration, Revenue Cycle
- Tools/products/workflows: ICD/CPT coding assistants that use coding validators as privileged feedback; multi-turn hint loops to fix mismatches; documentation bots that integrate structured EHR checks (e.g., template completeness).
- Assumptions/dependencies: Strict exclusion of diagnostic advice; certified coding validators; HIPAA/PHI safeguards; human-in-the-loop sign-off.
- Multi-turn agent frameworks with tool-driven “teacher” feedback
- Sectors: Software (agents), Data/Analytics, Ops
- Tools/products/workflows: Agents that translate tool outputs (SQL errors, plan diffs, solver failures, cost models) into teacher hints; “Feedback Orchestrator” SDK that standardizes building teacher-student loops from any verifiable tool result.
- Assumptions/dependencies: Clear mapping from tool output to actionable hints; error taxonomies; throttling to control iteration cost.
- Data synthesis pipelines: convert single-turn datasets into didactic dialogues
- Sectors: AI/ML, Data-centric AI, Academia
- Tools/products/workflows: “Dialogue Generator” that turns Q/A + verifier into multi-turn teacher-student interactions at scale; leakage detection module (string + LLM judge) integrated into curation; metrics dashboards for in-context plasticity.
- Assumptions/dependencies: Large supply of verifiable tasks; consistent verifier quality; governance for synthetic data provenance.
- Safety, evaluation, and red-teaming workflows focused on in-context plasticity
- Sectors: AI Safety, Platform Trust & Safety
- Tools/products/workflows: Evaluations that probe whether the model updates vs repeats errors; targeted red-team feedback to test sycophancy and leakage; gates that only deploy models scoring above an “interactive adaptation” threshold.
- Assumptions/dependencies: Defined plasticity metrics; adversarial feedback suites; continuous monitoring for regressions.
Long-Term Applications
These applications build on the paper’s self-improvement pathway, cross-domain transfer, and social learning framing, but require further research, validation, or scaled engineering.
- Safe continual learning: consolidate transient interactive gains into lasting capabilities
- Sectors: AI/ML Infrastructure, Enterprise IT
- Tools/products/workflows: “Interaction-to-Weights” pipelines that distill successful multi-turn adaptations into model updates; replay buffers of teacher-student traces; safety layers preventing catastrophic forgetting or preference drift.
- Assumptions/dependencies: Methods to avoid data poisoning, sycophancy, and bias accumulation; governance for online learning; scalable compute/storage.
- Curriculum-generating teachers that select problems based on mistakes
- Sectors: Education, Corporate Training, AI/ML Training
- Tools/products/workflows: Adaptive curricula where the teacher selects or synthesizes next tasks to target observed error modes; progress models tied to in-context plasticity.
- Assumptions/dependencies: Robust difficulty estimation; content licensing/quality control; fairness audits to avoid disparate outcomes.
- Mixed-motive multi-agent training (debate, negotiation, markets)
- Sectors: Governance, Law, Strategy, Economics
- Tools/products/workflows: Debate/negotiation agents trained with privileged feedback and reward shaping to generalize beyond cooperative settings; evaluators that measure persuasion accuracy vs sycophancy.
- Assumptions/dependencies: New verifiers for “soft” tasks; safety frameworks for adversarial dynamics; ethical guardrails.
- Clinical decision support that adapts to clinician feedback and outcomes
- Sectors: Healthcare (clinical), Life Sciences
- Tools/products/workflows: Decision-support agents that treat outcomes, guidelines, and trial evidence as privileged signals; multi-turn refinement with clinician critiques; post-deployment learning under real-world constraints.
- Assumptions/dependencies: Regulatory approval, rigorous clinical validation, post-market surveillance; robust non-leakage of answers; alignment with standard-of-care.
- Embodied and robotic systems taught via language corrections
- Sectors: Robotics, Manufacturing, Logistics
- Tools/products/workflows: Robots that accept multi-turn verbal corrections; teacher feeds privileged sensor/ground-truth via simulators for safe training; transfer learning from simulation to real.
- Assumptions/dependencies: High-fidelity simulators and verifiers; sim-to-real transfer; safety interlocks.
- Enterprise copilots that continuously self-improve from operational feedback
- Sectors: Enterprise SaaS, IT Ops, SecOps
- Tools/products/workflows: Agents that convert monitoring alerts, SLO breaches, and playbook results into privileged feedback; auto-remediation proposals refined with guardrailed self-critique before human approval.
- Assumptions/dependencies: Verifiable KPIs; incident simulators for safe training; strong access controls and audit.
- Scientific discovery agents that learn from experimental outcomes
- Sectors: R&D, Pharma, Materials
- Tools/products/workflows: Hypothesis-generation agents where lab results/bench simulations serve as privileged signals; multi-turn critique of hypotheses and protocol design; data-centric loops to reduce failed experiments.
- Assumptions/dependencies: Reliable lab automation/verifiers; causal inference safeguards; IP and data governance.
- Standardization of “interactive adaptability” in procurement and regulation
- Sectors: Policy, Public Sector, Standards Bodies
- Tools/products/workflows: Benchmarks and certification that require multi-turn feedback integration and leakage controls; policy guidance for public-service chatbots to learn from citizen feedback without storing PII or leaking answers.
- Assumptions/dependencies: Cross-agency agreement on metrics; privacy-preserving telemetry; vendor-neutral evaluation suites.
- Edge/embedded assistants using RL2F-tuned small models
- Sectors: Mobile, Automotive, IoT
- Tools/products/workflows: On-device copilots that self-correct and learn from local verifiable checks (e.g., device diagnostics); periodic federated consolidation of improvements.
- Assumptions/dependencies: Efficient RL2F training for small models; federated privacy; energy and latency constraints.
- Bias, fairness, and sycophancy–aware interactive training regimes
- Sectors: AI Ethics, HR Tech, EdTech, Financial Services
- Tools/products/workflows: Feedback-aware debiasing where teachers carry counterfactual privileged signals; multi-turn audits that stress-test model’s willingness to contradict user when facts disagree.
- Assumptions/dependencies: Diverse verifiers and datasets; fairness metrics adapted to multi-turn settings; governance and redress mechanisms.
Cross-cutting dependencies and assumptions
- Verifiable signals are central: availability of ground-truth solutions, rule engines, unit tests, sensors, or outcomes that can be transformed into actionable teacher hints without revealing answers.
- Leakage control: reliable automatic detectors (string + LLM-judge) and prompt discipline so the teacher doesn’t disclose solutions; ongoing audits for rare leaks.
- Compute and orchestration: RL fine-tuning budget, multi-turn inference costs, and tool orchestration for teacher-student loops.
- Safety and alignment: guardrails against sycophancy, biased self-feedback loops, and privacy violations; human-in-the-loop for high-stakes domains.
- Evaluation: new, standardized metrics for in-context plasticity and multi-turn generalization to ensure genuine learning from feedback rather than memorization.
Glossary
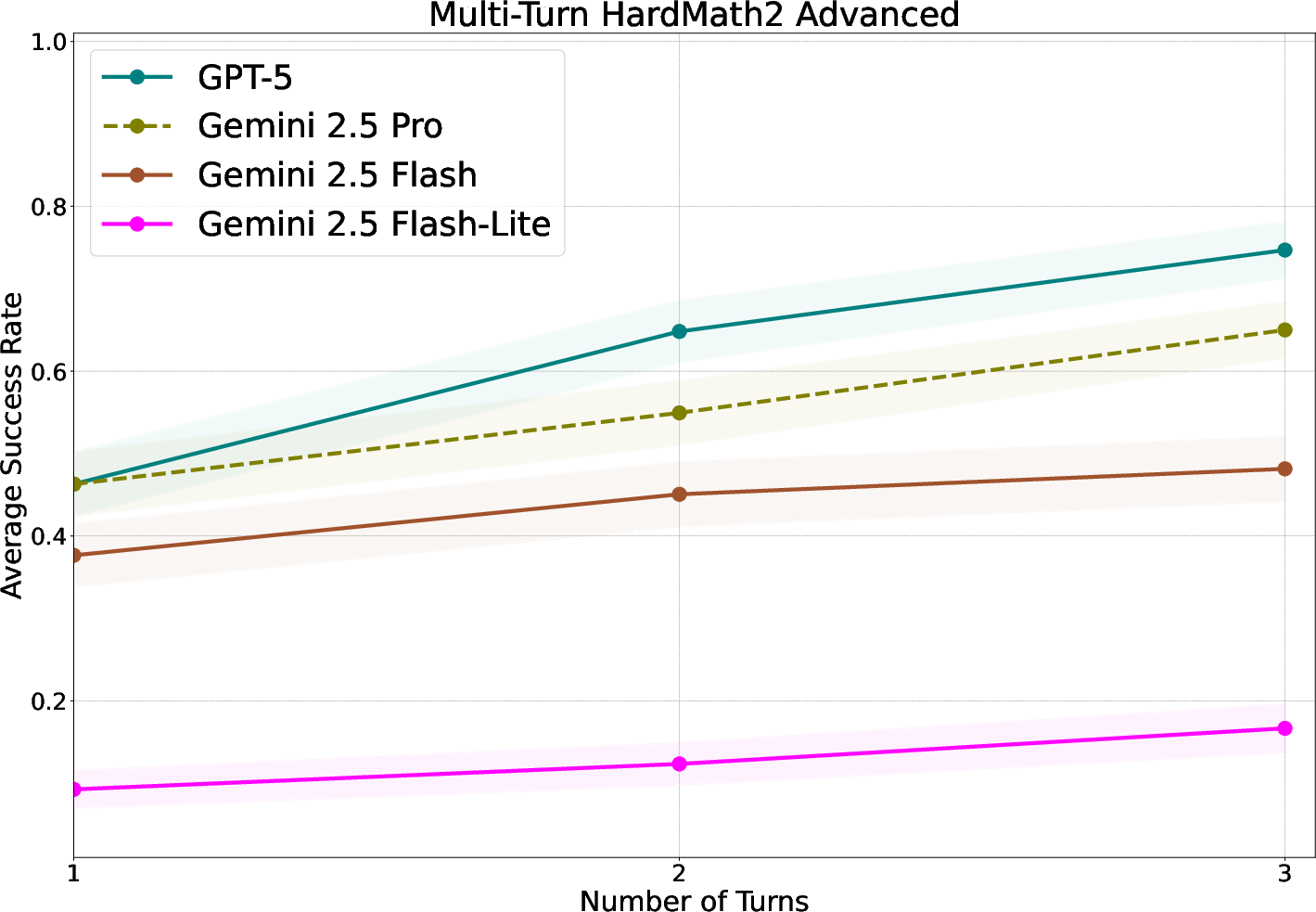
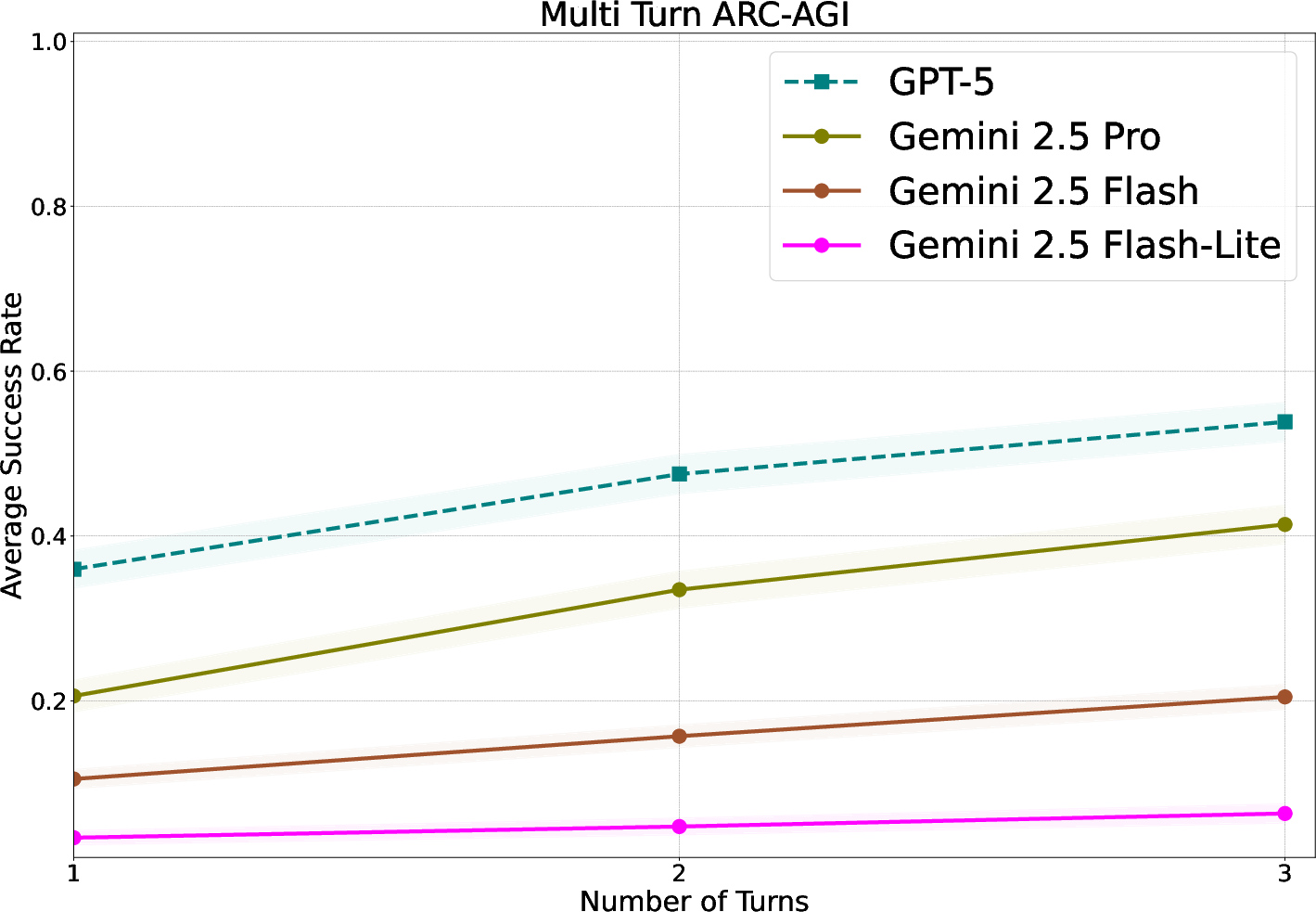
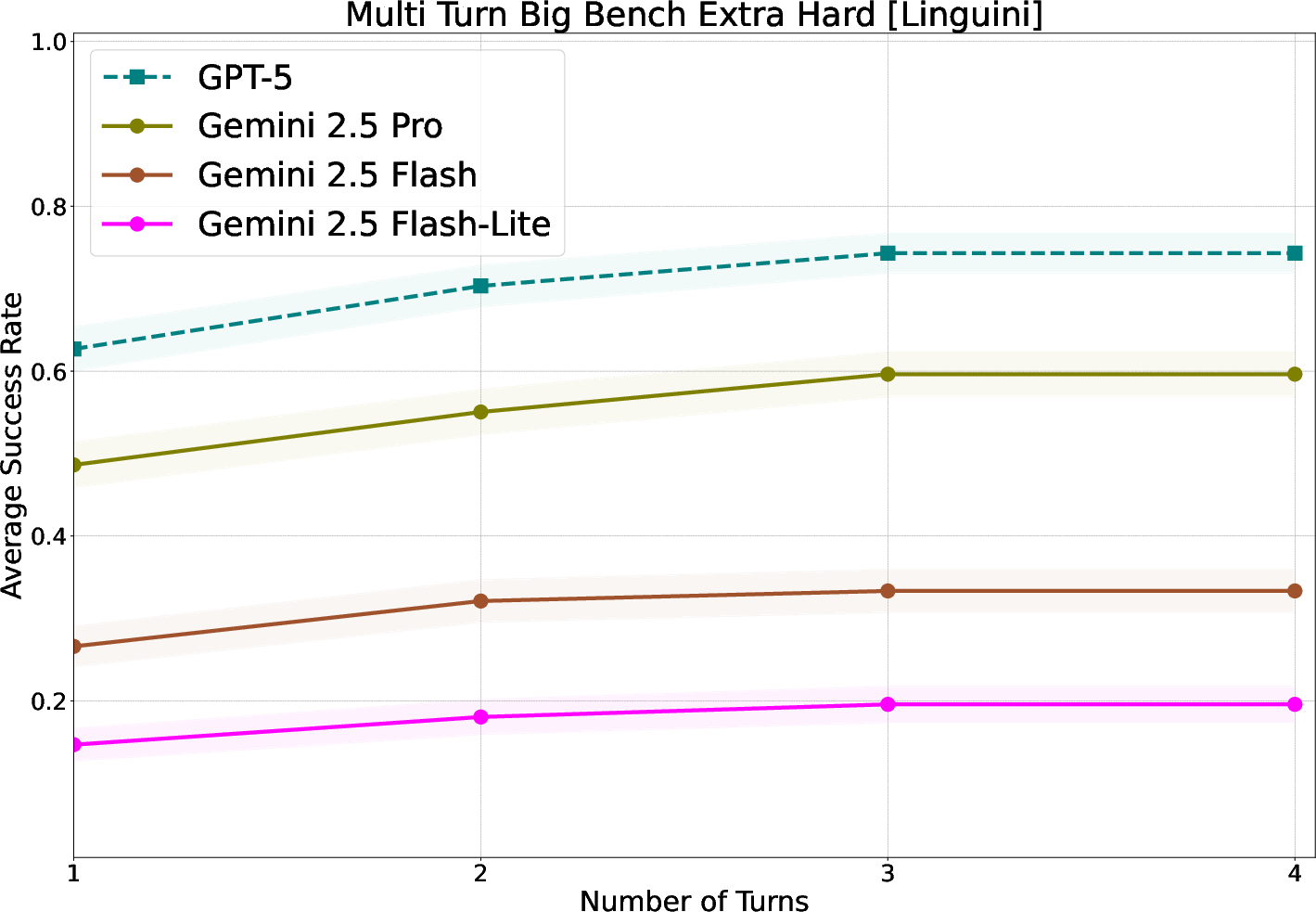
- ARC-AGI: A benchmark for measuring abstract reasoning capabilities in AI models. "We experiment across four different hard reasoning tasks: HardMath2 \citep{roggeveen2025hardmath2}, ARC-AGI \citep{chollet2024arc}, Codeforces \citep{codeforces} and BIG-Bench Extra Hard \citep{kazemi-etal-2025-big}."
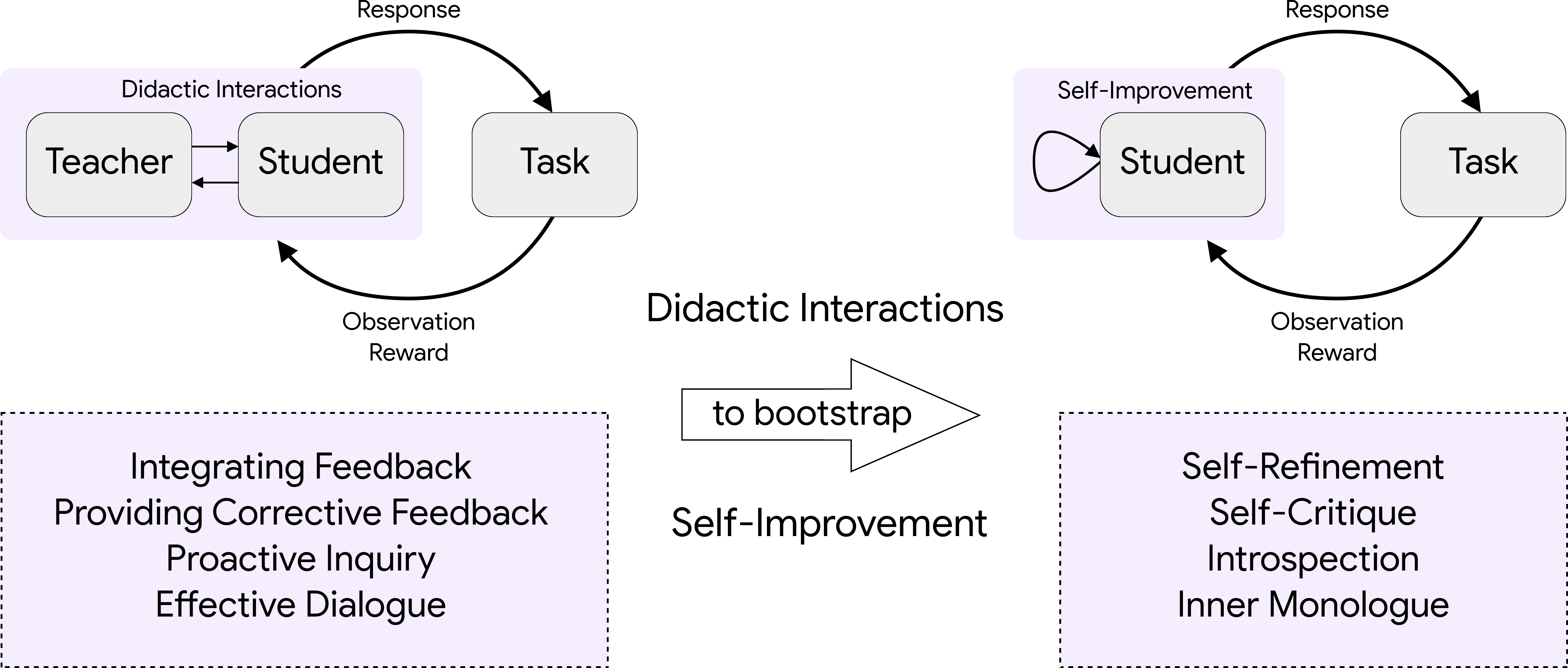
- Autodidact: An agent that self-improves by generating its own critiques and refinements without external teachers. "adopting a world-modeling approach within didactic interactions leads the student model to become an autodidact."
- BIG-Bench Extra Hard: A collection of especially difficult tasks designed to stress-test LLMs. "We experiment across four different hard reasoning tasks: HardMath2 \citep{roggeveen2025hardmath2}, ARC-AGI \citep{chollet2024arc}, Codeforces \citep{codeforces} and BIG-Bench Extra Hard \citep{kazemi-etal-2025-big}."
- Bi-level optimization: A meta-learning formulation with nested optimization problems (inner and outer loops). "recent works \citet{pmlr-v80-franceschi18a,Grefenstette2019Generalized} through the lens of bi-level optimization"
- Black box meta-learning: Meta-learning that treats the learner as an opaque function trained end-to-end, exemplified by RL2. "This approach is similar to black box meta-learning (e.g., RL) \citep{wang2017learningreinforcementlearn,duan2016rl2fastreinforcementlearning}"
- Boundless Socratic learning: A paradigm where agents learn through open-ended dialogue resembling the Socratic method. "Overall, our teacher-student setup is a particular instantiation of the concepts of language games and boundless socratic learning \citep{schaul2024boundlesssocraticlearninglanguage}."
- Codeforces: A competitive programming platform used as a verifiable coding benchmark for LLMs. "We experiment across four different hard reasoning tasks: HardMath2 \citep{roggeveen2025hardmath2}, ARC-AGI \citep{chollet2024arc}, Codeforces \citep{codeforces} and BIG-Bench Extra Hard \citep{kazemi-etal-2025-big}."
- Cooperative self-play: A training setup where identical agents with different roles (e.g., teacher and student) improve via interaction. "This cooperative self-play dynamic, optimized via RL, will be shown to yield significant performance improvements after fine-tuning."
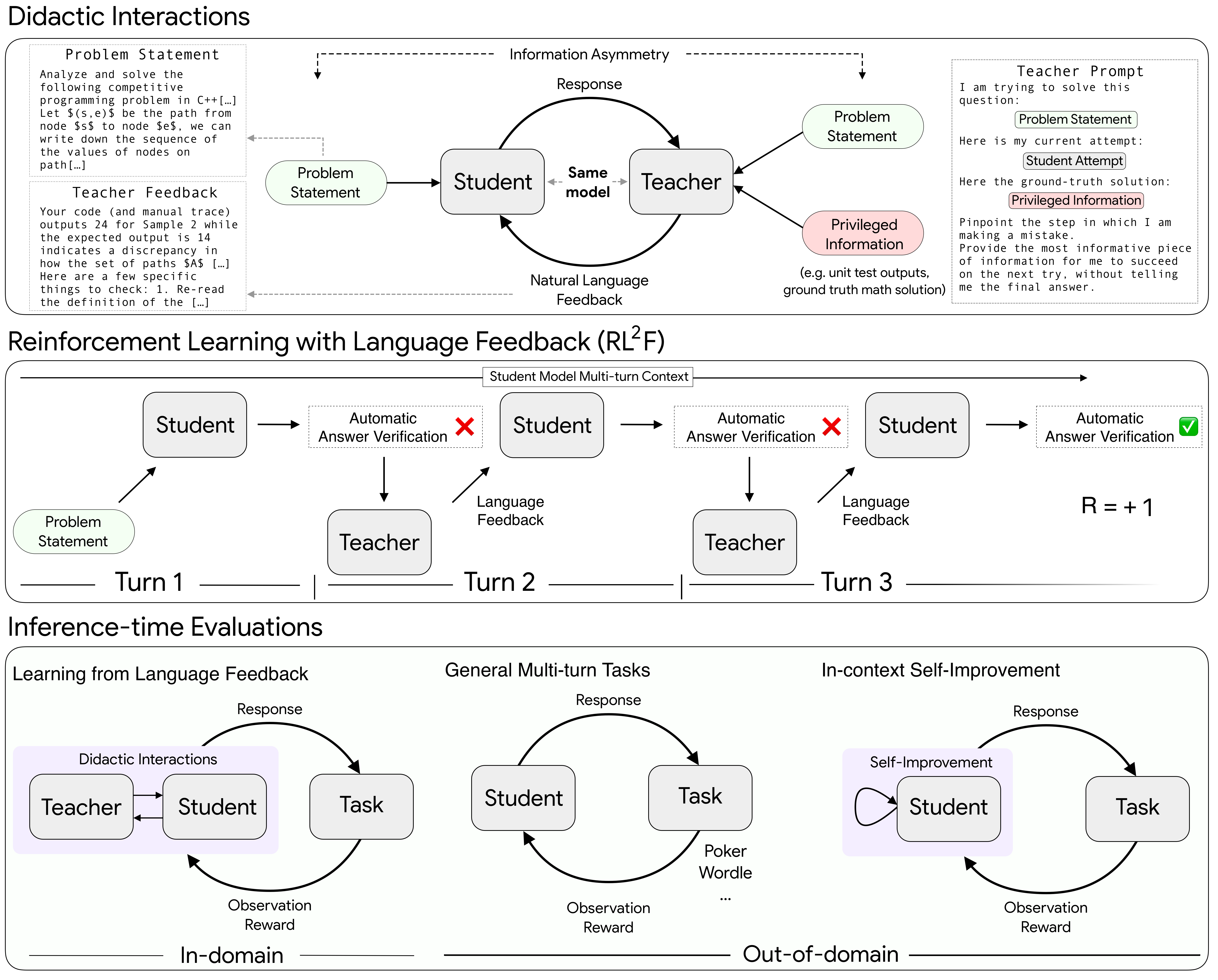
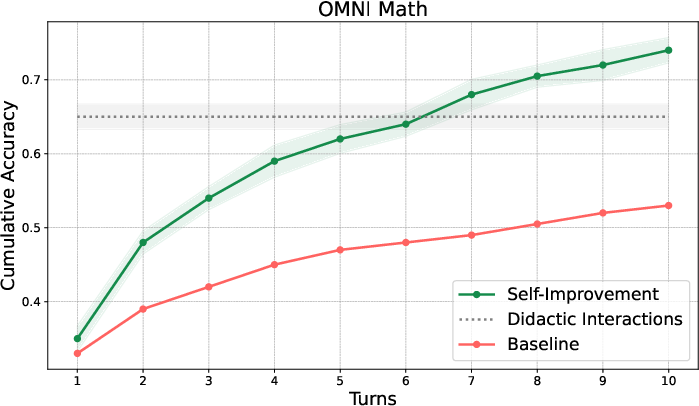
- Cumulative accuracy: A metric counting the proportion of tasks solved correctly within a given number of interaction turns. "we report the cumulative accuracy which is defined as the percentage of problems that were correctly solved for a certain number of turns"
- Didactic interactions: Structured teacher-student dialogues where feedback guides iterative problem-solving. "We introduce a scalable method that transforms single-turn verifiable tasks into multi-turn didactic interactions driven by information asymmetry."
- Distillation: Transferring knowledge from a teacher model to a student model, often using softer targets. "Unlike common student-teacher frameworks such as distillation \citep{hinton2015distilling,agarwal2023onpolicy}"
- HardMath2: A challenging math benchmark used to assess multi-turn reasoning and feedback integration. "Gemini 2.5 Flash nearly reaches the performance of Gemini 2.5 Pro on the challenging HardMath2 dataset."
- In-context learning: Adjusting behavior within a single interaction by conditioning on conversation history and feedback. "we propose a framework to address this problem by treating interactive in-context learning from natural language feedback as a distinct, trainable capability."
- In-context plasticity: The capacity of a model to change its outputs across turns in response to new feedback within the same context. "Our qualitative analysis suggests that this improvement is due to an enhanced in-context plasticity."
- Information asymmetry: A setup where the teacher has access to privileged information (e.g., solutions) not revealed to the student. "We introduce a scalable method that transforms single-turn verifiable tasks into multi-turn didactic interactions driven by information asymmetry."
- Language games: Interactive dialogues used as learning environments where agents communicate to solve tasks. "Overall, our teacher-student setup is a particular instantiation of the concepts of language games and boundless socratic learning \citep{schaul2024boundlesssocraticlearninglanguage}."
- Linguini: A linguistic logic benchmark from BIG-Bench Extra Hard used to test multi-turn reasoning. "and Linguini (from BIG-Bench Extra Hard) for linguistic logic."
- LiveCodeBench: A benchmark with executable unit tests for evaluating code generation and iterative correction. "We train the Gemma 3 12b model on Omni MATH and evaluate on LiveCodeBench \citep{Jain2025LiveCodeBench}."
- Natural Language Reinforcement Learning (NLRL): A framework re-expressing RL components (policies, values) directly in natural language. "introduce Natural Language Reinforcement Learning (NLRL), a framework that redefines core reinforcement learning concepts"
- Omni MATH: A large math dataset used for training and evaluation of multi-turn teacher-student interactions. "fine-tune a non-thinking model, Gemma 3 12b, on the training split of Omni MATH \citep{Gao2025Omni}."
- Out-of-distribution generalization: Transfer of learned capabilities to tasks and domains not seen during training. "We also observe robust out-of-distribution generalization: interactive training on math problems transfers to diverse domains like coding, puzzles and maze navigation."
- Partially observable Markov decision process (POMDP): A formal model for decision-making with hidden state and observable histories. "Learning from language feedback can be modeled as a partially observable Markov decision process (POMDP) ."
- Privileged information: Ground-truth solutions or test outputs available only to the teacher to guide feedback. "The teacher leverages privileged information (such as ground truth labels) to generate corrective feedback."
- Reinforcement Learning with Language Feedback (RL2F): An RL method that jointly leverages verifiable rewards and language feedback signals. "We name our method Reinforcement Learning with Language Feedback (RLF) to indicate the use of these two learning signals and to highlight the connection with RL."
- RL from machine feedback (RLMF): Optimizing with signals produced by automated systems rather than human labels. "also known as RL from verifiable rewards (RLVR) or RL from machine feedback (RLMF)."
- RL from verifiable rewards (RLVR): RL where reward comes from automatic correctness checks (e.g., unit tests). "also known as RL from verifiable rewards (RLVR) or RL from machine feedback (RLMF)."
- RL2: A meta-RL approach where an agent learns an RL algorithm in its recurrent dynamics across episodes. "This approach is similar to black box meta-learning (e.g., RL) \citep{wang2017learningreinforcementlearn,duan2016rl2fastreinforcementlearning}"
- Supervised Fine-Tuning (SFT): Post-training by minimizing loss on labeled pairs (e.g., problem–solution). "a standard supervised fine-tuning (SFT) baseline"
- Thinking tokens: Internal generation tokens dedicated to reasoning traces in “thinking” models. "eventually ceasing to utilize thinking tokens entirely."
- Transition function: The function describing state evolution given actions, here induced by teacher/student policies. "In our implementation, the teacher and the student policies define the transition function ."
- Verifiable domains: Task categories with objective checks for correctness (e.g., math proofs, unit-tested code). "We use verifiable domains like math and code, where objective performance measures exist."
- World modeling objective: An auxiliary training goal to predict environment (or teacher) feedback dynamics. "an auxiliary world modeling objective."
Collections
Sign up for free to add this paper to one or more collections.