EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data
Abstract: Human behavior is among the most scalable sources of data for learning physical intelligence, yet how to effectively leverage it for dexterous manipulation remains unclear. While prior work demonstrates human to robot transfer in constrained settings, it is unclear whether large scale human data can support fine grained, high degree of freedom dexterous manipulation. We present EgoScale, a human to dexterous manipulation transfer framework built on large scale egocentric human data. We train a Vision Language Action (VLA) model on over 20,854 hours of action labeled egocentric human video, more than 20 times larger than prior efforts, and uncover a log linear scaling law between human data scale and validation loss. This validation loss strongly correlates with downstream real robot performance, establishing large scale human data as a predictable supervision source. Beyond scale, we introduce a simple two stage transfer recipe: large scale human pretraining followed by lightweight aligned human robot mid training. This enables strong long horizon dexterous manipulation and one shot task adaptation with minimal robot supervision. Our final policy improves average success rate by 54% over a no pretraining baseline using a 22 DoF dexterous robotic hand, and transfers effectively to robots with lower DoF hands, indicating that large scale human motion provides a reusable, embodiment agnostic motor prior.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data”
Overview
This paper is about teaching robots to use their hands in skillful ways—like humans do—by learning from huge amounts of first-person human videos. The authors show that if you train an AI model on lots of human “how-to” videos (filmed from the person’s own viewpoint), the robot can learn better, faster, and more general hand skills. They also introduce a simple two-step recipe to bridge the gap between human data and robot execution.
Key Questions the Paper Tries to Answer
Here are the main questions the researchers wanted to explore:
- Can robots learn fine finger skills from large-scale human first-person videos?
- Does more human data keep making the robot better in a predictable way?
- How much “alignment” (small, carefully matched human-and-robot examples) do we need to make human knowledge usable by the robot?
- Can a robot learn a new task from just one robot demo after learning from humans?
- Do the learned hand skills transfer to different kinds of robot hands?
How They Did It (Methods and Approach)
Think of this like learning a sport:
- First, you watch lots of games (human videos) to understand how players move.
- Then, you get a short practice session on your own field with your own equipment (robot alignment).
- Finally, you practice the specific plays (task fine-tuning).
The paper follows that pattern:
- Big human video pretraining:
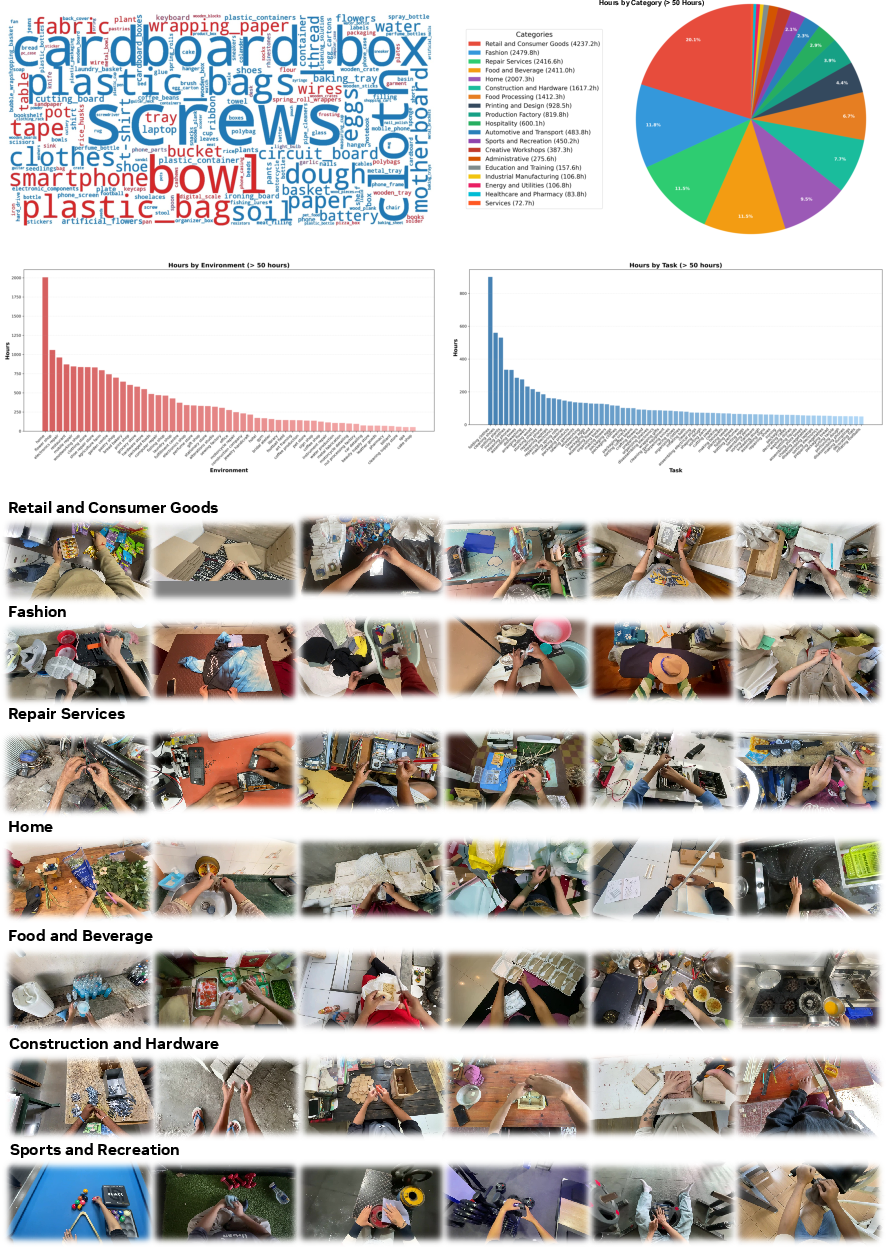
- They trained a Vision–Language–Action (VLA) model on 20,854 hours of first-person human videos. “Vision–Language–Action” means the AI looks at images, reads short instructions, and predicts what movements to make next.
- The videos include hand and wrist motion estimates from off-the-shelf tracking tools. The model learns two things:
- Wrist motion (like where and how your hand moves in space).
- Finger articulation (how each finger bends), retargeted to a 22-degree-of-freedom robot hand. “22-DoF” means the robot hand has many joints that can move independently, like a human hand.
- Mid-training for human–robot alignment:
- After pretraining, they add a small set of carefully matched data where humans and robots do similar tabletop tasks from similar camera views.
- This aligns what the model learned from humans with the robot’s sensors and controls, like switching from watching soccer to playing on your team’s field with your coach’s rules.
- Post-training on specific tasks:
- Finally, they fine-tune the policy (the robot’s decision-maker) on a small set of robot demos for the target tasks, such as folding shirts, sorting cards, unscrewing bottle caps, using tongs, and transferring liquid with a syringe.
Simple analogies for technical terms:
- Egocentric video: first-person view, like a GoPro on someone’s head.
- Retargeting: mapping human finger motions to robot finger joints, like translating piano fingering from one keyboard to another.
- Validation loss: a number that says how wrong the model is on a test set. Lower is better.
- Scaling law: a rule that describes how performance improves as you add more data. Here, more human data steadily lowers error.
Main Findings and Why They Matter
The authors discovered several important results:
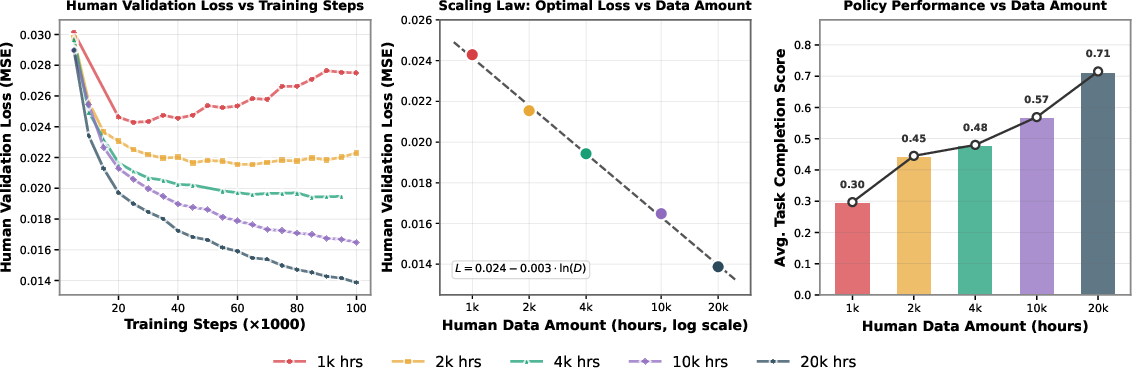
- Scaling law with human data:
- As they added more human video hours, the model’s error (validation loss) dropped in a clean, predictable way. In simple math, the best validation loss followed a log-linear law:
- , where is the number of hours of human data.
- This validation loss strongly matched real robot performance: lower loss meant better success on real tasks.
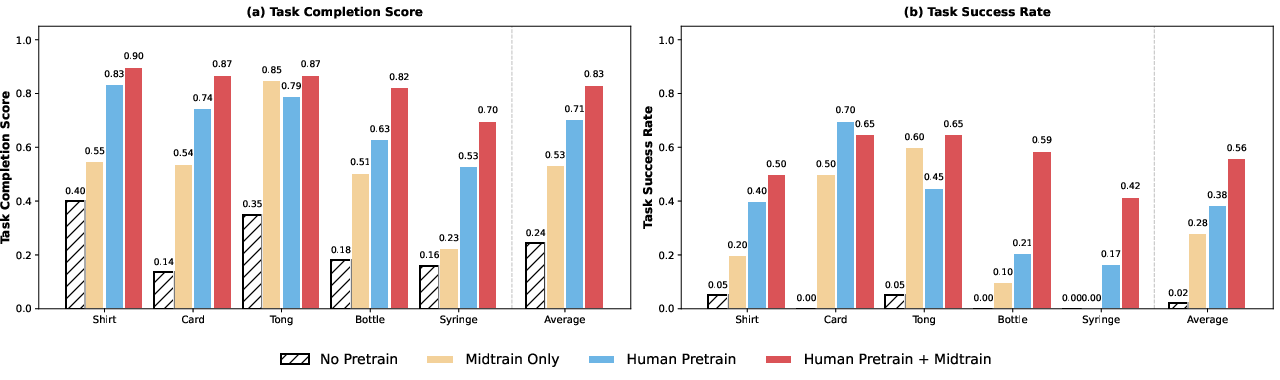
- Big gains from human pretraining:
- Training with the 20k+ hours of human videos improved average robot task completion by over 55% versus training from scratch.
- Combining human pretraining with a small amount of aligned mid-training gave the best results.
- One-shot learning:
- After pretraining + mid-training, the robot could learn some new complex tasks from just one robot demonstration.
- Example: shirt folding reached up to 88% success with only one robot demo per task plus aligned human examples.
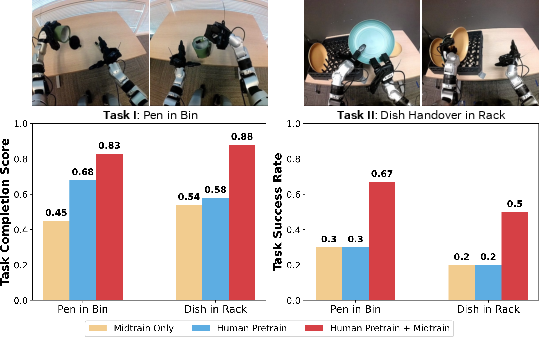
- Works across different robot hands:
- Even though the model learned in a 22-DoF (highly dexterous) hand space, it transferred well to a robot with a simpler tri-finger hand, boosting success by more than 30% absolute compared to no human pretraining.
- This suggests the model learned general movement “motors” (like reusable hand skills) that adapt to different robots.
- The right hand representation matters:
- Using detailed finger joint actions during human pretraining led to the most consistent success, especially for tasks needing precise finger control (like separating a single card or using tongs).
- Using only wrist motion or fingertip positions was less reliable for contact-heavy, precision tasks.
Implications and Impact
This work shows a practical path to teaching robots skillful hand use:
- Human first-person videos are a powerful, scalable training source for robot dexterity.
- A simple two-step recipe—large human pretraining plus a small aligned mid-training—turns that human knowledge into robot actions.
- Robots can learn new tasks quickly (even from one demo), reducing the need for long, expensive robot data collection.
- The learned skills can transfer across different robot hardware, hinting at “general” hand know-how.
In the future, scaling both the model and human data further could unlock even better planning, longer tasks, and stronger generalization. As robot hands become more human-like, the gap will shrink even more, making zero-shot or one-shot transfer increasingly possible.
A Few Terms, Simply Explained
Here are a few tricky words from the paper, explained in everyday language:
- Egocentric: first-person view (camera on your head or chest).
- DoF (Degrees of Freedom): how many independent ways a hand or arm can move (more DoF = more dexterous).
- VLA (Vision–Language–Action): an AI that sees images, reads or uses instructions, and outputs movement commands.
- Validation loss: a score of how often and how badly the model’s predictions are wrong on a test set.
- One-shot learning: learning a new task from just one example.
- Retargeting: converting human hand motions to robot joint angles.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored, to guide future research.
- Scaling frontier and compute–data trade-offs: The observed log-linear scaling (validation loss vs. ln(data hours)) is shown only up to 20k hours and a single model size/training budget. It remains unknown whether the trend persists (or saturates) at larger data/model scales, and what the compute-optimal frontier is when jointly scaling model capacity, data, and training steps.
- Diversity vs. volume disentanglement: The work scales total hours but does not isolate the contributions of scene/object/task diversity from raw data volume. Controlled experiments holding hours fixed while varying diversity (and vice versa) are needed to quantify what most drives gains.
- Noise robustness and label quality: Stage I supervision relies on noisy SLAM and hand-pose estimates from in-the-wild videos. There is no quantification of noise levels, sensitivity analysis to tracker errors, or robust training methods (e.g., denoising, confidence-weighted targets, temporal consistency priors). How much cleaner data (e.g., EgoDex-quality) is needed to offset large amounts of noisy data?
- Language grounding in human pretraining: The paper does not specify how language instructions are obtained/aligned for large-scale human videos, nor the contribution of language to the learned representation. Ablations on language-free vs. language-augmented pretraining and methods to auto-generate/align language labels remain open.
- Action-space generality: Human actions are retargeted into a 22-DoF Sharpa hand space, then adapted to other embodiments via adapters. It is unclear how sensitive performance is to the choice of canonical hand, to retargeting errors, or how well this approach extends to underactuated, soft, or very low-DoF grippers without hand analogues.
- Retargeting fidelity and failure modes: The optimization-based retargeter can introduce physically implausible joint solutions, especially under fingertip pose noise. A systematic analysis of retargeting errors, their impact on policy learning/execution, and alternatives (e.g., contact/force-aware retargeters, diffusion-based hand pose priors) is missing.
- Sensing modality limitations: The approach uses RGB vision (with egocentric and wrist views) but no depth, tactile, or force/torque sensing. The benefits and integration pathways for tactile and force feedback—particularly for contact-rich, precise manipulation—are unexplored.
- Camera/view alignment dependence: Mid-training presumes tightly aligned human–robot viewpoints and intrinsics (including matched wrist cameras for humans), which may not hold in practice. How robust is transfer when viewpoints differ, cameras are missing, or extrinsics drift?
- One-shot transfer caveat: The “one-shot” robot adaptation still uses 100 aligned human demonstrations per task. The minimal amount and composition of human data needed for successful one/few-shot robot transfer is not characterized. Pure robot-only one-shot/few-shot capability remains untested.
- Robot data efficiency in post-training: Most tasks use 100 robot demonstrations (except one with 20), which is still substantial. The trade-off curve between downstream robot supervision and performance—especially under strong pretraining/mid-training—needs quantification.
- Cross-embodiment breadth: Cross-embodiment results are limited to two platforms (R1 Pro with 22-DoF hands, Unitree G1 with a tri-finger hand). Generality to a wider range of hands (Allegro, Shadow, soft hands) and mobile manipulators with very different kinematics is untested.
- Unpaired alignment without mocap: Mid-training uses mocap/gloves and carefully matched setups. Methods for learning human–robot alignment from unpaired or weakly paired data (e.g., adversarial domain alignment, cycle consistency, diffusion alignment) could reduce instrumentation dependence but remain unexplored.
- Long-horizon memory and hierarchical control: The flow-based policy predicts action chunks but lacks explicit mechanisms for long-horizon memory, subgoal discovery, or hierarchical skill composition. It is unclear how performance scales on much longer, multi-stage tasks without external planners.
- Stability and force control in contact: The system controls joint angles and end-effector poses but lacks explicit force, compliance, or impedance control. Failures in cap removal and maintaining grasps hint at limitations in contact stability; evaluation under varying friction and compliance is missing.
- Robustness and recovery: There is no analysis of robustness to perturbations (object slips, pushes, occlusions), recovery behaviors, or safe failure handling. Benchmarks with stochastic disturbances could reveal resilience gaps.
- Generalization beyond tabletop: Training and evaluation focus on tabletop manipulation. Transfer to in-hand reorientation, articulated object manipulation (doors, drawers), assembly, or dynamic human–robot interaction scenarios is not evaluated.
- Initialization and evaluation bias: The image-overlay initialization reduces scene variability and may inflate performance. Testing under randomized initial conditions and reporting sensitivity would strengthen claims.
- Statistical rigor and reproducibility: Results report averages over limited trials (often 10) without confidence intervals or significance testing. Standardized, larger-scale evaluations, public checkpoints, and reproducible pipelines (including data access) would clarify effect sizes.
- Flow matching at inference: Although the model is probabilistic, inference averages samples for evaluation. The role of sampling vs. deterministic decoding, uncertainty-aware control, and risk-sensitive execution is not studied.
- Human proprioception placeholder: Replacing human proprioception with a learned token may limit the fidelity of human action modeling. Alternatives (e.g., inferred body pose, coarse arm kinematics) and their impact on transfer remain open.
- Multi-view mismatch in Stage I: Stage I uses head-mounted egocentric videos, while robot execution relies heavily on wrist cameras. Quantifying the penalty from this view mismatch and the benefits of multi-view human data in pretraining is an open question.
- Data curation and leakage: The paper states that certain evaluation tasks are not in mid-training, yet Stage II includes 344 tasks with overlapping primitives. More transparent task splits, deduplication checks, and leakage analyses would increase confidence in generalization claims.
- Active data selection: No strategy is explored for prioritizing human videos/tasks that maximally benefit downstream embodiments. Active selection, curriculum learning, or diversity-aware sampling could further improve data efficiency.
- Self-supervised and multi-task objectives: Pretraining is dominated by action prediction. The gains from incorporating contrastive objectives, masked modeling, video-language alignment, contact prediction, or multi-task learning are unknown.
- Integration with RL or online adaptation: The framework is purely imitation-based. Whether human-pretrained policies provide a stronger initialization for RL fine-tuning with sparse rewards, or support safe online improvement, remains unexplored.
- Tool-use generalization: Tool use is demonstrated with tongs; broader tool families (screwdrivers, spatulas, scissors) and compositionally novel tool–task combinations are not tested. How well the motor prior extrapolates to unseen tools is open.
- Real-time constraints and deployment: Training/inference compute, latency, and on-board vs. off-board execution trade-offs are not reported. Performance under resource-constrained deployment (edge devices) is unknown.
- Safety and ethics: Large-scale human video raises privacy considerations; robot execution raises safety concerns. Protocols for safe exploration, contact limit enforcement, and ethical data use are not addressed.
Practical Applications
Overview
EgoScale demonstrates that large-scale egocentric human video can be turned into a reusable “dexterity prior” for robots via a two-stage recipe: (1) pretraining a Vision–Language–Action policy on 20k+ hours of human wrist and retargeted hand-joint actions, and (2) a small, aligned human–robot mid-training phase to anchor the representation to specific robot sensing/control. It yields strong long-horizon dexterous manipulation, one-shot task adaptation, and cross-embodiment transfer (including low-DoF hands), underpinned by a log-linear scaling law that predicts downstream performance. Below are concrete applications derived from these findings.
Immediate Applications
The following use cases can be deployed now in controlled environments with available hardware and modest aligned data collection. Each item notes sectors, specific use cases, tools/workflows that might emerge, and key dependencies.
- Sector(s): Manufacturing, Warehousing, Electronics
- Use case: Rapidly teach dexterous assembly/kitting subtasks—e.g., cap screwing/unscrewing, single-sheet/card separation, small-part insertion, cable routing, container opening—via one/few robot demos augmented by aligned human play.
- Tools/products/workflows: “Dexterous Motor Prior” model checkpoint; ROS2-compatible adapters for different hands; an aligned-play data collection kit (head/wrist cameras, Vive trackers, Manus gloves) to gather ~tens of minutes to a few hours of human and ~minutes of robot play per cell; one-shot teaching UI for operators.
- Assumptions/dependencies: Controlled stations with matched camera viewpoints; reliable high- or mid-DoF end-effectors (dexterous hands or tri-finger); basic safety interlocks; limited task variability; small mid-training dataset per cell.
- Sector(s): Lab Automation (Biotech/Pharma/Academia)
- Use case: Tool-use sequences such as syringe liquid transfer, vial cap removal, pipette-like motions, tube handling; quickly adapting to new protocols with one-shot robot demos and aligned human demonstrations on bench setups.
- Tools/products/workflows: Bench-top dual-arm system with wrist cameras; protocol-specific aligned human play library; model adapters for lab grippers/dexterous hands; standardized rubrics for step-wise scoring and validation.
- Assumptions/dependencies: Sterility/cleanroom compliance; consistent lighting and fixtures; safety constraints for liquid handling; small robot dataset for each protocol variant.
- Sector(s): Retail Fulfillment, e-Commerce
- Use case: Picking thin/fragile items from stacks, de-nesting containers, sorting and binning, simple tool-mediated handling (e.g., tongs for delicate produce or thin pouches).
- Tools/products/workflows: Camera-configured stations; pretraining-derived prior; one-shot adaptation workflow per SKU/task; monitoring dashboards tracking prediction loss as a leading KPI for performance.
- Assumptions/dependencies: Moderate item variability; robust gripping surfaces and compliance; environmental stability; limited tool set.
- Sector(s): Assistive/Home Robotics, Healthcare (Non-clinical)
- Use case: Household help with deformable and small-object tasks—folding/rolling laundry, opening bottles/containers, organizing items, basic kitchen prep with simple tools—adapted via a few user demonstrations.
- Tools/products/workflows: Consumer-friendly “teach-by-demonstration” app using a head camera or AR/VR headset; embodiment adapters for affordable hands; incremental post-training per home.
- Assumptions/dependencies: Safety/certification; reliable perception in clutter; comfort-level dexterity with low-DoF hands; caregiver/user oversight during deployment.
- Sector(s): Humanoid/Field Robotics (R&D, Pilots)
- Use case: Cross-embodiment transfer to humanoids or mobile manipulators for tasks like opening/placing items, human-like handovers; smoother motions and faster adaptation to new embodiments with minimal data.
- Tools/products/workflows: Embodiment adapters for proprioception and hand-action decoding; integration with locomotion/balance controllers (e.g., Homie); small mid-training datasets per robot.
- Assumptions/dependencies: Stable lower-body control; calibration of multi-camera rigs; small aligned play for each embodiment.
- Sector(s): Software/Robotics Platforms
- Use case: “Dexterity Foundation Model” API that outputs relative end-effector motions and hand-joint targets from images + language; SDK for embodiment adapters; plug-ins for Octo/RT-series/GR00T-style stacks.
- Tools/products/workflows: Cloud/on-prem inference endpoints; MLOps pipeline to collect aligned play, fine-tune, and validate using human action-prediction loss; ROS2 integration.
- Assumptions/dependencies: Camera calibration; low-latency inference if closed loop; security for customer data.
- Sector(s): Academia, Corporate R&D
- Use case: Data-driven benchmarking and research—using the discovered log-linear scaling law to plan dataset expansion; ablations on wrist-only vs fingertip vs joint-space supervision; cross-embodiment studies.
- Tools/products/workflows: Public benchmarks/rubrics from the paper; SLAM + hand-pose preprocessing pipelines; mid-training protocols; evaluation suites for dexterous tasks.
- Assumptions/dependencies: Access to egocentric datasets; adequate compute; permissions/licensing for human video; reproducibility practices.
- Sector(s): QA/Validation, MLOps for Robotics
- Use case: Use human action-prediction validation loss as a leading indicator to forecast downstream robot performance; automate gating for releases and data collection.
- Tools/products/workflows: Validation sets with held-out human videos; dashboards tracking loss vs. success rates; data acquisition triggers when loss plateaus.
- Assumptions/dependencies: High-quality validation data reflecting deployment tasks; stable preprocessing.
- Sector(s): Data Services
- Use case: Turnkey egocentric capture services to bootstrap aligned play—install matched head/wrist cameras in customer environments and deliver ready-to-train datasets.
- Tools/products/workflows: Sensor kits; standardized consent/privacy workflows; packaged data pipelines (SLAM, hand pose, retargeting).
- Assumptions/dependencies: Privacy compliance; site cooperation; data governance.
Long-Term Applications
These use cases require additional research, scaling, hardware maturation, standardization, or regulation before wide deployment.
- Sector(s): General-Purpose Home Robotics
- Use case: Broad household dexterity—laundry folding across garments, dish loading, cooking prep, tool use—taught by owners via a few demonstrations.
- Tools/products/workflows: Affordable, reliable high-DoF or capable low-DoF hands with tactile sensing; robust one-shot teaching UI; continual learning from household demonstrations.
- Assumptions/dependencies: Durable hardware, richer tactile/force control, robust perception in high-variance homes, strong safety standards, continued data/model scaling.
- Sector(s): Surgical/Interventional Robotics
- Use case: Transfer of fine motor skills from surgeon egocentric streams to robot for delicate, contact-rich procedures; rapid adaptation to new instruments or steps.
- Tools/products/workflows: High-precision retargeting from human hand/keypoints to surgical manipulators; haptics integration; validated one-shot adaptation for sub-steps.
- Assumptions/dependencies: Stringent regulatory approval; submillimeter accuracy; force/torque control; extensive safety/validation datasets; privacy for OR video.
- Sector(s): Advanced Manufacturing/Electronics
- Use case: Fine insertion, connector mating, wire harnessing, watch/phone assembly; scaling dexterous automation across product variants via human data from production floors.
- Tools/products/workflows: Tight-tolerance dexterity priors; fast mid-training workflows per SKU; integration with MES/quality systems.
- Assumptions/dependencies: Cycle-time and yield requirements; robust end-effectors; comprehensive data for edge cases; ESD/cleanroom constraints.
- Sector(s): Agriculture/Food Processing
- Use case: Delicate produce handling, trimming, sorting with tool use; skill transfer from expert workers’ egocentric data.
- Tools/products/workflows: Ruggedized sensors; adaptable end-effectors; seasonal datasets and one-shot adaptation across crops and tools.
- Assumptions/dependencies: Outdoor variability (lighting, weather), bio-safety, object variability; domain-specific mid-training.
- Sector(s): Disaster Response, Remote Operations
- Use case: Rapid tool-use adaptation in unstructured scenes; learn from responders’ headcams for remote dexterous interventions.
- Tools/products/workflows: Teleop fallback with shared autonomy; offline pretraining on historical egocentric footage; fast on-site mid-training.
- Assumptions/dependencies: Reliable comms; rugged hardware; safety in hazardous conditions.
- Sector(s): Workforce Training & Human–Robot Collaboration
- Use case: Workers demonstrate complex manual tasks via egocentric capture; robots learn as assistive co-workers or to automate sub-steps.
- Tools/products/workflows: Consent-aware data capture; task libraries per workstation; on-the-fly one-shot adaptation during shifts.
- Assumptions/dependencies: Labor agreements; IP/data ownership and privacy policies; change management and safety standards.
- Sector(s): Policy & Standards
- Use case: Frameworks for egocentric data privacy, anonymization, storage, and consent; safety/benchmarking standards for dexterous robots and one-shot adaptation; liability guidelines for human-derived motor priors.
- Tools/products/workflows: Industry consortia for “aligned play” protocols; standardized evaluation tasks and rubrics; certification processes.
- Assumptions/dependencies: Multi-stakeholder coordination; evolving data protection laws; harmonization across regions.
- Sector(s): Cloud/Edge AI Services
- Use case: “Dexterity Foundation Model as a Service” for enterprises—fine-tune to client hardware and tasks with a few demos; marketplace of embodiment adapters and mid-training packs.
- Tools/products/workflows: Secure, compliance-ready training/inference; on-prem options; automated calibration and QA.
- Assumptions/dependencies: Customer data governance; latency/availability; ecosystem of compatible hands/cameras.
- Sector(s): Core Robotics R&D
- Use case: Self-supervised pretraining on unlabeled egocentric video at larger scales; integration of tactile sensing and force control; planning for longer-horizon, compositional tasks.
- Tools/products/workflows: Multimodal VLA (vision–language–action–tactile); improved retargeting across embodiments; curriculum learning with weak labels.
- Assumptions/dependencies: Larger models/compute; better tactile hardware; algorithmic advances for long-horizon credit assignment.
- Sector(s): Data Ecosystems
- Use case: Cross-industry “Aligned Play” data-sharing consortia to reduce redundant robot data collection by pooling small robot datasets paired with broad human pretraining.
- Tools/products/workflows: Federated or privacy-preserving aggregation; shared benchmarks; adapter libraries for common embodiments.
- Assumptions/dependencies: IP/licensing models; privacy-preserving pipelines; incentives for participation.
Notes on Cross-Cutting Assumptions and Dependencies
- Data: Scalable access to diverse, consented egocentric video; action labeling pipelines (SLAM + hand pose) with acceptable noise; small, embodiment-aligned “play” datasets per deployment.
- Hardware: Availability of capable hands (22-DoF preferred; tri-finger workable), matched camera rigs (head + wrist), and reliable calibration.
- Compute: Access to high-performance training/inference (cloud/on-prem); efficient post-training workflows.
- Safety & Compliance: Human–robot safety standards, especially for contact-rich, tool-use tasks; strong privacy and data governance for human video.
- Generalization: Performance degrades with distribution shift; one/few-shot adaptation and aligned mid-training remain necessary for new embodiments/environments.
- Retargeting Quality: Joint-space retargeting outperforms fingertip-only or wrist-only supervision in this work; success depends on accurate kinematics, joint limits, and contact stability modeling.
Glossary
- Camera frame: The coordinate system attached to the camera, used to express poses relative to the camera viewpoint. Example: "Let denote the world frame and the camera frame at time ."
- Camera intrinsics: The internal calibration parameters of a camera (e.g., focal length, principal point) that define how 3D points project onto the image. Example: "with matched viewpoints and calibrated intrinsics"
- Coefficient of determination (R2): A statistical measure indicating how well a model fits the data, with 1.0 being a perfect fit. Example: "The fitted curve achieves an of 0.9983"
- Co-training: A training approach that jointly leverages data from two related domains or modalities to align representations. Example: "we introduce a small amount of aligned human-robot mid-training data through co-training."
- Degrees of freedom (DoF): The number of independent parameters that define a system’s configuration, often used for robot joints or hands. Example: "We equip the robot with Sharpa Wave hands with 22 degrees of freedom and joint-space control"
- Dexterous manipulation: Fine-grained, multi-fingered object interaction requiring precise control and coordination. Example: "Human behavior is among the most scalable sources of data for learning physical intelligence, yet how to effectively leverage it for dexterous manipulation remains unclear."
- DiT (Diffusion Transformer): A transformer architecture used for diffusion-style generative modeling, here applied as an action generator. Example: "A flow-based VLA policy with a VLM backbone and DiT action expert."
- Egocentric: First-person perspective captured from the actor’s viewpoint (e.g., head-mounted camera). Example: "We pretrain on 20,854 hours of egocentric human manipulation data"
- Embodiment: The physical form and capabilities of an agent (human or robot), including its kinematics and sensors. Example: "transfer from human data to robots is possible by aligning observations or actions across embodiments"
- Embodiment-agnostic: Not tied to a specific physical body; transferable across different robots or humans. Example: "indicating that large-scale human motion provides a reusable, embodiment-agnostic motor prior."
- Embodiment gap: The mismatch between human and robot bodies (e.g., kinematics, sensing) that complicates transfer. Example: "as robotic hardware becomes more human-like in kinematics and dexterity, the embodiment gap will naturally shrink"
- End-effector: The tool or hand at the tip of a robot arm that interacts with the environment; actions can be defined in its pose space. Example: "controlling both 7-DoF arms in relative end-effector space where actions specify incremental position and orientation changes"
- Few-shot generalization: The ability of a model to adapt to new tasks with only a few examples. Example: "demonstrating strong few-shot generalization."
- Flow-based model: A generative model class that learns invertible mappings or continuous flows for predicting outputs. Example: "A flow-based VLA policy is first pretrained on 20,854 hours of egocentric human videos"
- Flow-matching: A training objective for learning continuous-time generative flows that match data distributions. Example: "The model then predicts a chunk of future actions using a flow-matching objective."
- Force closure: A grasping condition ensuring an object is immobilized by contact forces and torques. Example: "grasping methods that model force closure, contact stability, and hand kinematics"
- Grasp affordances: Learned or modeled cues indicating feasible and effective grasps on objects. Example: "structured representations such as grasp affordances, contact maps, and hand–object interaction fields"
- Hand–object interaction fields: Representations capturing how hands contact and manipulate object surfaces over space. Example: "structured representations such as grasp affordances, contact maps, and hand–object interaction fields"
- Joint limits: Physical constraints on how far each joint can move. Example: "using an optimization-based procedure that enforces joint limits and kinematic constraints."
- Joint-space control: Commanding a robot by specifying target joint angles rather than end-effector poses. Example: "joint-space control, where actions directly specify target joint angles"
- Kinematic constraints: Restrictions imposed by the mechanical structure and motion relationships of a robot or hand. Example: "using an optimization-based procedure that enforces joint limits and kinematic constraints."
- Kinematics: The study and modeling of motion without considering forces, central to robot arm and hand movement. Example: "human and robot embodiments differ substantially in kinematics and control interfaces."
- Log-linear scaling law: A relationship where performance (or loss) scales linearly with the logarithm of data size. Example: "uncover a log-linear scaling law between human data scale and validation loss."
- Mid-training: An intermediate alignment stage that fine-tunes a pretrained model using a small, targeted dataset to bridge domains. Example: "a small amount of aligned human–robot mid-training"
- Motion capture: Systems that record precise 3D motion (e.g., of wrists and fingers) for supervision or teleoperation. Example: "Human hand motion is captured using the same motion-capture stack as in robot teleoperation"
- One-shot transfer: Adapting to a new task from a single demonstration. Example: "Aligned mid-training enables emergent one-shot transfer."
- Power law: A functional relationship where one quantity varies as a power of another; used to describe scaling behavior. Example: "policy generalization follows an approximate power law with environment and object diversity"
- Proprioceptive state: Internal robot sensing of its own configuration (e.g., joint angles, velocities). Example: "For robot data, the model conditions on the robot proprioceptive state "
- Retargeting (hand motion): Mapping human hand motion to a robot’s joint space while respecting constraints. Example: "we retarget the 21 human hand keypoints into a dexterous robot hand joint space"
- Rigid transform: A rotation and translation that preserves distances, used to represent 3D pose. Example: "each represented as a rigid transform "
- Scaling law: Empirical rule describing how performance or loss changes predictably with data, model, or compute scale. Example: "we uncover a clear scaling law: human wrist and hand action prediction validation loss follows a log-linear relationship with data volume."
- SE(3): The Lie group of 3D rigid-body transformations (rotations and translations). Example: "The estimated camera pose is represented as ."
- Simultaneous Localization and Mapping (SLAM): Techniques for estimating camera/agent pose while building a map from sensor data. Example: "We apply off-the-shelf SLAM and hand-pose estimation pipelines to recover camera motion and human hand trajectories."
- Teleoperation: Controlling a robot remotely by a human operator, often via motion tracking or VR interfaces. Example: "a smaller dataset with both human and teleoperated robot data."
- Vision–Language–Action (VLA): Models that jointly process visual input, language instructions, and output actions for control. Example: "We train a Vision–Language–Action (VLA) model on over 20,854 hours of action-labeled egocentric human video"
- Vision–LLM (VLM): A model that integrates visual and textual inputs to produce joint embeddings or predictions. Example: "A flow-based VLA policy with a VLM backbone and DiT action expert."
- Workspace: The region of space a robot can reach with its end-effector given its kinematics. Example: "which features a shorter arm with a reduced reachable workspace"
- World frame: A global, fixed coordinate system used as a common reference for all poses. Example: "Let denote the world frame and the camera frame at time ."
Collections
Sign up for free to add this paper to one or more collections.