Large-scale online deanonymization with LLMs
Abstract: We show that LLMs can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at high precision, given pseudonymous online profiles and conversations alone, matching what would take hours for a dedicated human investigator. We then design attacks for the closed-world setting. Given two databases of pseudonymous individuals, each containing unstructured text written by or about that individual, we implement a scalable attack pipeline that uses LLMs to: (1) extract identity-relevant features, (2) search for candidate matches via semantic embeddings, and (3) reason over top candidates to verify matches and reduce false positives. Compared to prior deanonymization work (e.g., on the Netflix prize) that required structured data or manual feature engineering, our approach works directly on raw user content across arbitrary platforms. We construct three datasets with known ground-truth data to evaluate our attacks. The first links Hacker News to LinkedIn profiles, using cross-platform references that appear in the profiles. Our second dataset matches users across Reddit movie discussion communities; and the third splits a single user's Reddit history in time to create two pseudonymous profiles to be matched. In each setting, LLM-based methods substantially outperform classical baselines, achieving up to 68% recall at 90% precision compared to near 0% for the best non-LLM method. Our results show that the practical obscurity protecting pseudonymous users online no longer holds and that threat models for online privacy need to be reconsidered.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows that modern AI LLMs (the kinds that can read and write like people) can figure out who is behind an online username much more easily than before. This is called deanonymization: taking a “pseudonymous” account (an account using a handle, not a real name) and matching it to the real person. The authors find that these AIs can do this at large scale, quickly, and with high accuracy—often matching what a skilled human investigator could do, but in minutes instead of hours.
What questions the researchers asked
- Can LLMs identify real people from the texts they write online, even when accounts don’t show obvious personal info?
- Can LLMs outperform older deanonymization methods that relied on very neatly organized data (like numerical ratings) and lots of manual work?
- How well does this work across different situations, like matching a pseudonymous account to a real identity, or linking two separate anonymous accounts that belong to the same person?
- How precise can these attacks be (few wrong matches) and how often do they succeed (many correct matches)?
How they did it (with everyday analogies)
Think of online posts like a trail of breadcrumbs: your writing style, the topics you talk about, the movies you like, where you studied or worked, hobbies, and other hints. Each breadcrumb alone isn’t enough to identify you. But when many breadcrumbs are put together, they can point strongly to one person.
The researchers built a step-by-step system that uses LLMs to act a bit like a very fast, careful detective:
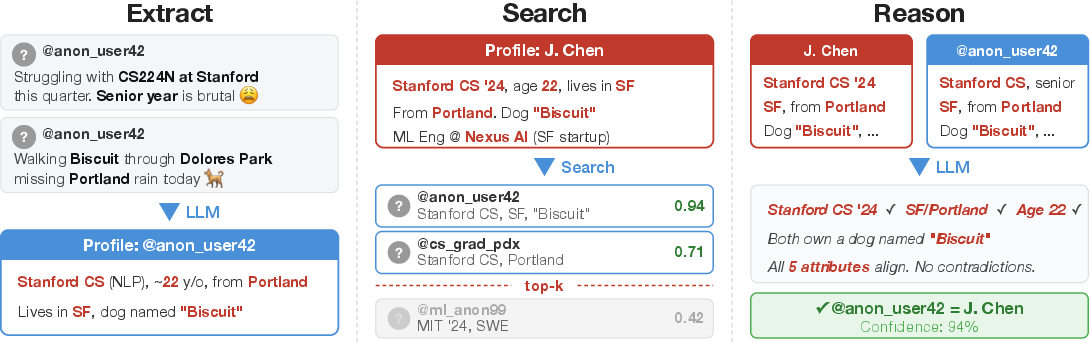
- Extract: Like taking notes from a messy conversation, the AI reads posts and pulls out important “identity clues” (interests, jobs, locations mentioned, writing style, unique phrases).
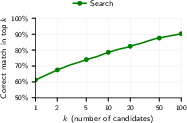
- Search: It turns those clues into “searchable fingerprints” and looks through huge piles of other profiles to find likely matches.
- Reason: From the best few candidates, the AI thinks through the evidence—comparing details and ruling out lookalikes—to pick the most likely match.
- Calibrate: It also gives a confidence score, so you can set strict rules like “only accept matches when we’re 99% sure,” which reduces false positives.
They tested two kinds of settings:
- Open-web “agent” searches: An LLM with web access searches the internet to find real identities from pseudonymous profiles or interview transcripts.
- Closed-world matching: The AI gets two databases of profiles (like two different platforms or two time periods) and must link which pairs belong to the same person. Here they used ground-truth datasets to measure accuracy fairly.
To judge results in plain terms, they use:
- Precision: Of the matches the AI claims, how many are actually right? Example: 90% precision means 9 out of 10 claimed matches are correct.
- Recall: Of all the people who could be matched, how many did the AI successfully find? Example: 50% recall means it found half of them.
What they tested on
To measure real performance while protecting privacy, they created evaluation setups with known, verifiable answers:
- Hacker News → LinkedIn: Users who had publicly linked their profiles were “masked” by removing direct identifiers (like URLs) and then the AI tried to rediscover the link.
- Reddit movie communities: They split each user’s movie discussions across different subreddits and asked the AI to match the halves.
- Reddit time splits: They split a single user’s posts by time (before vs. after a one-year gap) and tested if the AI could link the two halves.
- Anthropic Interviewer transcripts: The AI tried to identify scientists from redacted interview transcripts using careful web search. This shows real-world risk, but they report results cautiously and ethically.
Main findings and why they matter
- LLMs make deanonymization practical at scale. The AI matched users much better than older “classical” methods that needed tidy, numerical data and lots of human effort.
- Strong results with high precision:
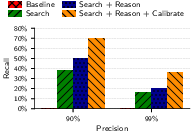
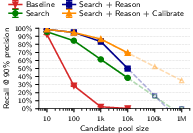
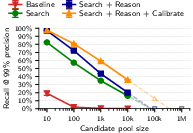
- Hacker News to LinkedIn: Up to about 68% of users correctly matched at 90% precision, and about 45% recall at 99% precision. That means when the system is extremely cautious (99% sure), it still finds almost half of all possible matches.
- Reddit movie discussions: The AI still beats classical methods even in a tougher setting; recall improves as users share more overlapping movie talk.
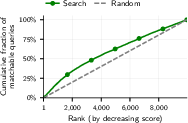
- Agentic web search: With full internet access, the AI can re-identify a notable share of pseudonymous accounts and even some interview participants, in minutes, with high precision.
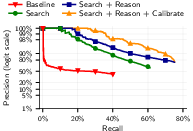
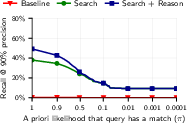
- Reasoning helps a lot: Simply “searching by similarity” isn’t enough. The extra reasoning step—where the AI carefully compares top candidates—significantly improves accuracy, especially when you demand very few mistakes.
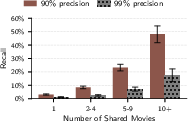
- More shared detail = easier to identify: When users post more distinctive content or share more overlapping topics (like the same set of movies), matching becomes far easier.
- “Practical obscurity” is fading: People used to be protected because deanonymization was too time-consuming to do at scale. LLMs reduce that cost dramatically.
What this means for the future
- Privacy assumptions need updating: Many people assume that using a handle or avoiding direct personal info keeps them safe. This research shows that patterns in what you say—interests, style, life details—can be enough for powerful AIs to connect the dots.
- Platform policies and norms may need to change: Communities and companies might need new rules or tools to protect users, because the same rich text content that makes online spaces valuable can also enable deanonymization.
- Evaluating and defending privacy will be harder: Past advice for structured datasets was often “don’t release them.” For unstructured text (posts, comments), that’s trickier because text is the main content itself. New protections, product designs, and possibly legal standards may be necessary.
- Ethical research is crucial: The authors built careful, verifiable tests without targeting truly anonymous people, aiming to warn about risks, not to enable misuse.
In short: Modern AIs can connect online dots far better than before. Even if you never share your real name, the way you write and what you talk about can reveal who you are. That’s a big deal for online privacy, and it calls for new thinking about how we share and protect information on the internet.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow‑up research.
Evaluation scope and generalizability
- Lack of evaluation on truly pseudonymous users without self-identifying links; current datasets (synthetic anonymization and split-profiles) likely overestimate recall and do not reflect the hardest cases.
- Limited platform coverage (HN→LinkedIn, Reddit movies, Reddit temporal splits); unclear transfer to other ecosystems (e.g., X/Twitter, Mastodon, StackOverflow, Discord, niche forums, review sites).
- No multilingual assessment; generalization to non-English, code-switching, transliterated names, and low-resource languages is untested.
- Unclear robustness over longer temporal gaps and life changes; only a one-year Reddit split is examined—what happens over multi-year horizons or career changes?
- Cross-domain transferability is unmeasured (e.g., matching technical forums to lifestyle blogs, or professional to hobbyist communities).
Threat model realism and open-world settings
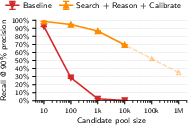
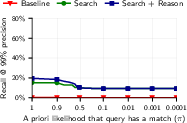
- Open-world performance where most queries have no match is insufficiently characterized beyond brief ablation; precision/recall for extremely low base rates (e.g., <1% match probability) remains unknown.
- No per-query risk scoring or calibrated abstention policies for mixed pools (matchable and non-matchable queries), which is essential for safe deployment and realistic threat models.
- Impact of dynamic candidate pools (users joining/leaving, content evolving) and streaming/online matching is unexplored.
Methodology and calibration
- Reliance on LLM self-reported confidence for calibration lacks robust validation (e.g., Brier scores, ECE, isotonic/Platt scaling on held-out data); calibration stability under distribution shift is unknown.
- Confidence based on top-2 embedding gap is weak at high precision; alternative uncertainty metrics (e.g., mutual rank, reciprocal rank fusion, Bayesian margins, ensemble variance) weren’t explored.
- Sensitivity to hyperparameters (e.g., top-k=15/100, embedding normalization, index type, chunking strategies) is not systematically analyzed.
- Error propagation from the Extract stage (LLM hallucinations, missed cues) is not quantified; no measurement of extraction accuracy or inter-annotator agreement vs. human labels.
- Tournament/sorting-based calibration is only briefly attempted in one setting; broader comparisons (pairwise vs. listwise ranking, Bradley–Terry/Plackett–Luce aggregation, Condorcet methods) are missing.
Baselines and attribution of gains
- Missing comparisons to strong stylometry and authorship attribution baselines (e.g., character n-grams, Writeprints, open-set stylometry, modern transformer stylometric models) beyond the Netflix-style baseline.
- No ablations to attribute gains to content (interests), style (syntax/lexicon), demographics, or incidental disclosures; relative contribution of each signal is unknown.
- Limited analysis of embedding model choice (Gemini vs. OpenAI vs. Cohere vs. open-source) and vectorization strategies; robustness and performance sensitivity remain unquantified.
- Role of web search retrieval vs. LLM reasoning in the agentic setting is not disentangled; the contribution of search engine embeddings/ranking remains opaque.
Robustness and adversarial conditions
- No evaluation against realistic evasion tactics: style obfuscation, deliberate misinformation, paraphrasing, machine translation, code-switching, or automated “style-masking” tools.
- Unknown resilience to data poisoning or adversarial distractors in candidate pools; how easily can an attacker be misled by decoy accounts?
- No tests of robustness to sparse activity (few posts), short accounts, or heavily moderated/ephemeral content (e.g., deleted/edited posts).
- Vulnerability to model memorization (privacy leakage): if LLMs memorize individuals, matching success may be confounded; training-data contamination controls are absent.
Scalability and cost
- End-to-end cost curves for the ESRC pipeline at Internet scale (millions to hundreds of millions of candidates) are extrapolated but not empirically validated; compute, memory, and latency constraints are not quantified.
- Cost-performance tradeoffs for different test-time compute (reasoning effort), shortlist sizes, and multi-stage cascades are not systematically explored.
- Operational considerations (index maintenance, periodic re-embedding, caching, deduplication, and incremental updates) are not addressed.
Ethics, safety, and legality
- Ground-truth verification for Anthropic Interviewer deanonymization is uncertain and partly manual; a formal adjudication protocol, inter-rater reliability, and error auditing are missing.
- No quantitative harm analysis for false positives at population scale (e.g., expected misidentifications per million queries) under realistic deployment scenarios.
- Legal and policy constraints (platform ToS, scraping restrictions, GDPR/CCPA implications) and how they shape feasible adversary models are not analyzed.
- Dual-use safeguards and reproducibility tension: prompts, tools, and agents are not released; guidance for secure replication (e.g., controlled sandboxes, red-team protocols) is absent.
Fairness and differential risk
- No assessment of whether deanonymization success varies by demographics, profession, geography, or community; potential disparate impacts are unmeasured.
- Lack of analysis on how content domains (e.g., health, politics, sensitive topics) affect identifiability and risk.
Defenses and mitigations
- No empirical evaluation of countermeasures: writing-style obfuscation, rate-limiting, post redaction, privacy-preserving UI nudges, platform-side perturbations/noise, or content throttling.
- Detection strategies (e.g., platform monitors for cross-account linking behavior, bot/agent detection, watermarking of writing style) are not explored.
- Policy-level mitigations (e.g., default privacy guardrails, warnings about identifiable disclosures, “privacy budgets” for posting) remain conceptual without measurement of efficacy.
Experimental design and measurement
- Metrics beyond precision/recall at high thresholds (e.g., AUCPR, calibration error, per-query uncertainty, FPR per N predictions) are limited; real-world decision thresholds aren’t grounded in risk tolerance.
- Limited error analysis: root causes for false positives/negatives (e.g., ambiguous interests vs. style collisions) are not categorized to inform targeted fixes or defenses.
- Selection bias in ground-truth datasets (users willing to link profiles, active users) is acknowledged but not corrected with reweighting or robustness checks.
Integration and system questions
- Criteria for when to use agentic web search vs. closed-world ESRC are not formalized; no decision framework based on data availability, candidate pool size, or cost.
- Human-in-the-loop strategies (lightweight verification to boost precision at low cost) are not studied.
- Graph signals (social ties, co-participation networks) and multimodal cues (images, code, audio) are not incorporated or benchmarked.
These gaps point to concrete next steps: build harder, multilingual benchmarks with verified ground truth; design robust calibration and uncertainty estimation; compare against modern stylometry; stress-test under adversarial obfuscation; quantify fairness impacts; and experimentally assess practical defenses and platform mitigations.
Glossary
- Ablations: Controlled experiments that remove or vary components to measure their contribution to performance. "Ablations confirm that each pipeline stage contributes: in particular, the Reason step improves recall at 99\% precision from 4.4\% (Search only) to 45.1\%."
- Calibrate: Adjusting decision thresholds or confidence measures to control the precision–recall trade-off of an attack. "Calibrate: we prompt LLMs to provide confidences in identified matches (either absolute or relative to other matches), which lets us calibrate the attack to a desired false positive rate."
- Closed-world setting: An evaluation scenario where it is assumed that every query has a corresponding match within a fixed candidate set. "We then design attacks for the closed-world setting."
- Confidence score: A numeric measure of how certain a model is in its prediction, used to decide whether to output a match or abstain. "We use the verification-stage confidence as the calibration score for precision-recall curves."
- Cosine similarity: A distance metric that measures the cosine of the angle between two vectors, commonly used in embedding spaces. "using Gemini embeddings~\citep{lee2025gemini} and FAISS~\citep{douze2025faiss} with cosine similarity."
- Distractors: Additional non-matching candidates added to increase task difficulty and evaluate robustness. "we add 5{,}000 candidate distractors: candidate profiles of users who appear only in the candidate pool, with no corresponding query."
- Doxxing: The act of publicly revealing the real-world identity behind an online pseudonym. "These settings capture distinct threat models (e.g., doxxing of an online account, a stalker targeting a victim, or an adversary consolidating a user's activity across contexts)"
- FAISS: A library for efficient similarity search and clustering of dense vectors. "using Gemini embeddings~\citep{lee2025gemini} and FAISS~\citep{douze2025faiss} with cosine similarity."
- False positive rate: The proportion of non-matching cases incorrectly identified as matches. "which lets us calibrate the attack to a desired false positive rate."
- Frontier LLMs: The most capable, state-of-the-art LLMs. "we begin our study by directly evaluating whether frontier LLMs can autonomously perform end-to-end deanonymization"
- Function calling: A structured interface for LLMs to return outputs in predefined schemas (e.g., confidences), facilitating reliable extraction. "The model outputs confidence via function calling, and we threshold it to trade off precision and recall"
- Ground truth: Verified factual labels used to evaluate model accuracy in matching tasks. "We construct three datasets with known ground-truth data to evaluate our attacks."
- Heuristic pre-filter: A rule-based filtering step that removes obviously irrelevant or low-quality data before model processing. "a heuristic pre-filter removes empty and deleted comments, very short responses, and pure URLs."
- Held-out test set: A dataset reserved for final evaluation that is not used during training or tuning to avoid overfitting. "a held-out test set for our final evaluation."
- Jaccard similarity: A set-based similarity metric defined as the size of the intersection divided by the size of the union. "rarity-weighted Jaccard similarity (see \cref{app:narayanan_baseline} for details)."
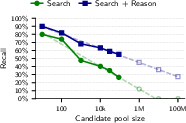
- Log-linear extrapolation: Projecting performance trends by fitting a linear relationship in log space and extending it to larger scales. "Dashed lines show log-linear extrapolation to larger pools."
- LLM embeddings: Dense vector representations of text produced by LLM embedding models, used for semantic search. "we do this by performing a nearest-neighbor search over LLM embeddings of the extracted summaries."
- LLM reasoning: Using an LLM’s chain-of-thought or analytical capabilities to compare candidates and verify matches beyond simple similarity. "LLM reasoning further improves matching."
- Micro-data: Fine-grained, individual-level data points that can be used to uniquely identify a person. "Micro-data is information at the level of an individual, such as
gave Twilight a 5-star rating'',lives in Texas'', or ``never capitalizes sentences''." - Nearest-neighbor search: Retrieving the most similar items to a query in an embedding space based on a chosen distance metric. "we do this by performing a nearest-neighbor search over LLM embeddings of the extracted summaries."
- Netflix Prize attack: A classical deanonymization technique that links anonymized data to public profiles using overlapping attributes like ratings. "\citet{narayanan2008deanonymization} (hereafter termed the ``Netflix Prize attack'') demonstrate this by matching anonymized Netflix Prize ratings to public IMDb profiles based on movie rating micro-data."
- Pairwise LLM comparisons: A calibration method where an LLM judges relative match likelihood by comparing candidate pairs. "or ratings computed by sorting matches via pairwise LLM comparisons."
- Precision–recall curve: A plot showing how precision and recall change as the decision threshold varies, used to evaluate detection systems. "We use these confidence scores to trace precision-recall curves."
- Practical obscurity: The privacy protection afforded by the effort or cost required to identify someone, rather than by technical anonymity. "Our results show that the practical obscurity protecting pseudonymous users online no longer holds"
- Rarity-weighted Jaccard similarity: A variant of Jaccard that downweights common items and emphasizes rare, distinctive attributes. "rarity-weighted Jaccard similarity (see \cref{app:narayanan_baseline} for details)."
- Semantic embeddings: Vector representations designed to capture the meaning of text for tasks like semantic search or matching. "search for candidate matches via semantic embeddings,"
- Semantic splits: Dataset construction by dividing profiles based on semantic criteria (e.g., community or topic) to create matched pairs. "Semantic splits for arbitrary profiles."
- Selection bias: Systematic bias introduced when the sampled data is not representative of the broader population. "This mitigates selection bias concerns but comes with other limitations discussed later."
- Spatiotemporal points: Data points that contain both spatial (location) and temporal (time) components. "four spatiotemporal points are enough to uniquely identify 95\% of individuals in mobile phone datasets."
- Test-time compute: Additional computation used during inference (not training) to improve performance, such as running higher-effort reasoning. "Increased reasoning effort (test-time compute) substantially improves deanonymization success."
- Threat model: A formal description of an attacker’s goals, capabilities, and constraints used to frame security/privacy analyses. "We first define our threat model and the ESRC deanonymization framework in \cref{ssec:method_threatmodel} and \cref{ssec:method_framework}, respectively."
- Top-2 similarity gap: The difference between the highest and second-highest similarity scores, used as a confidence indicator. "we use the gap between the top-2 candidates' similarities---a large gap indicates the top candidate stands out clearly, making it more likely correct."
- Top-K: Selecting the K highest-ranked candidates for further processing or verification. "First, we select from the top-K candidates using only reviews with matching movie titles between query and candidates."
- Transformer-derived text embeddings: Text embeddings produced by transformer models, capturing nuanced semantics for retrieval and matching. "we use transformer-derived text embeddings, while \citet{narayanan2008deanonymization} relied on hand-crafted numerical features."
- True Positive Rate (TPR): The fraction of actual positives correctly identified; equivalent to recall. "We hence define recall (or True Positive Rate (TPR)) as the fraction of matchable users..."
- Wilson confidence intervals: A method for estimating confidence intervals for proportions that performs well with finite samples. "95\% Wilson confidence intervals shown."
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s ESRC pipeline (Extract → Search → Reason → Calibrate), leveraging LLM-based feature extraction, embedding search, and calibrated verification. Each item notes sectors, potential tools/workflows, and key dependencies.
- Platform privacy risk auditor for user-generated content
- Sectors: software platforms, social media, forums, communities
- What: Continuously audit posts, bios, and histories to compute an “anonymity leak score,” flag likely re-identification risks, and suggest targeted redactions or profile design changes.
- Tools/Workflows: ESRC pipeline; FAISS-based nearest-neighbor over profile embeddings; LLM verification and confidence calibration to control false positives; dashboard with precision–recall controls.
- Assumptions/Dependencies: API/content access; cost budgets for LLM inference; governance to avoid misuse; precision calibrated to very low FPR to prevent wrongful flags.
- Pre-release red teaming for unstructured text datasets
- Sectors: academia, industry (ML/data science), government data portals
- What: Before releasing transcripts, support logs, forums, and qualitative study data, run scalable re-identification tests to quantify recall at 98–99% precision and gate release/redaction decisions.
- Tools/Workflows: ESRC with synthetic anonymization and split-dataset evaluation (as introduced in the paper); report of “re-ID risk by feature” and ablation-based mitigations.
- Assumptions/Dependencies: IRB/ethics approvals; secure compute for sensitive data; policy for acceptable risk thresholds (e.g., “no release if recall > X% at 99% precision”).
- End-user “privacy copilot” for posts and profiles
- Sectors: daily life, productivity/browsers, education
- What: A writing assistant that highlights identity-bearing micro-data (e.g., job history, locations, unique hobbies), suggests safer paraphrases, and offers “style smoothing” to reduce stylometric fingerprints.
- Tools/Workflows: On-write ESRC-Extract with lightweight local models; optional cloud-based “Reason + Calibrate” to estimate re-ID likelihood pre-posting.
- Assumptions/Dependencies: Latency/UX constraints; user consent; robust prompts to avoid over-redaction; multilingual support for broader adoption.
- Trust & Safety account-linking for abuse mitigation
- Sectors: platforms, marketplaces, gaming, media communities
- What: Link ban-evasion alts, sockpuppets, coordinated inauthentic behavior, and cross-community brigading using calibrated LLM reasoning over top-k candidates.
- Tools/Workflows: Embedding retrieval over millions of accounts; LLM-based shortlist selection and verification; thresholding at 99% precision to minimize wrongful linkage; human-in-the-loop review.
- Assumptions/Dependencies: Strong internal policy and audit trails; appeal mechanisms; dataset bias awareness; clear separation of detection vs. enforcement.
- Corporate leak forensics and insider risk investigations
- Sectors: enterprise security, legal/compliance
- What: Attribute pseudonymous leaks or anonymous posts to known employees by matching stable micro-data (topics, writing style, career hints) across corporate and public corpora.
- Tools/Workflows: ESRC with restricted access to internal comms; calibrated confidence thresholds; legal chain-of-custody workflows.
- Assumptions/Dependencies: Lawful basis and employee privacy constraints; false-positive risk management; robust logging and explainability for evidentiary use.
- Fraud/sockpuppet detection in reviews and marketplaces
- Sectors: e-commerce, app stores, travel/review sites, finance (fintech support channels)
- What: Detect clusters of accounts with high-likelihood identity overlap (e.g., sellers boosting reputations or reviewers astroturfing).
- Tools/Workflows: ESRC Search → Reason for cluster formation; graph analytics overlay; risk scoring with abstentions at strict precision.
- Assumptions/Dependencies: Content access; platform policy alignment; scalable indexing; fairness checks against community drift.
- Clinical text de-identification QA
- Sectors: healthcare, health IT, clinical research
- What: Independently verify that de-identified clinical notes cannot be re-linked to individuals, even via unstructured micro-data and stylometry.
- Tools/Workflows: ESRC red team on sampled notes; measure recall at high precision; highlight residual signals (e.g., rare events, timelines).
- Assumptions/Dependencies: HIPAA/PHI governance, BAA and secure enclaves; minimal data movement; strict abstention when uncertain.
- Legal e-discovery identity consolidation
- Sectors: legal services, compliance
- What: Consolidate aliases/pseudonyms across large discovery sets (forums, emails, chats), reducing reviewer burden and improving timeline reconstruction.
- Tools/Workflows: ESRC pipeline with “candidate-link packs” for reviewers; confidence bins for triage; audit-ready reports.
- Assumptions/Dependencies: Jurisdictional limits; explainability requirements; privilege considerations; calibrated thresholds to avoid prejudice.
- Identity resolution for CRM/marketing with explicit consent
- Sectors: enterprise CRM, ad-tech (consent-based), customer support
- What: Link cross-channel profiles (support forums ↔ product communities ↔ known accounts) to improve support continuity and personalization under consented programs.
- Tools/Workflows: ESRC applied to first-party data; consent registry; per-link provenance and revocation.
- Assumptions/Dependencies: Regulatory compliance (GDPR/CCPA/CPRA); consent management; clear opt-outs; restricted scopes to avoid dark patterns.
- Research toolkit for anonymity measurement
- Sectors: academia, civil society/NGOs
- What: Use the paper’s evaluation datasets and methodology to benchmark anonymization strategies, community policies, and the effect of content volume on re-ID risk.
- Tools/Workflows: Open benchmarks following synthetic anonymization and temporal/community splits; shared precision–recall reporting templates.
- Assumptions/Dependencies: IRB oversight; reproducible LLM configurations; documented biases in ground truth construction.
- Pre-publication checks for qualitative research and journalism
- Sectors: universities, newsrooms, think tanks
- What: Screen interview transcripts and field notes for re-ID risk and recommend targeted edits (paraphrasing, timeline coarsening, rare-detail removal).
- Tools/Workflows: ESRC with “rare detail” detectors and confidence-calibrated alerts; editor-in-the-loop redaction workflow.
- Assumptions/Dependencies: Editorial standards; subject consent; balance between narrative fidelity and privacy.
- Government data release risk checks (FOIA/open data)
- Sectors: public sector, open-data offices
- What: Assess whether releasing textual records (comments, case notes) could enable deanonymization at scale; gate releases or apply structured redactions.
- Tools/Workflows: ESRC runbooks; standardized “Anonymity Risk Score” reports; procurement-friendly playbooks.
- Assumptions/Dependencies: Statutory mandates; transparency–privacy tradeoffs; inter-agency alignment.
Long-Term Applications
These require further research, scaling, policy development, or technical advances (e.g., multimodal, cross-lingual robustness, on-device deployment, or new standards).
- Internet-scale, multimodal identity linkage
- Sectors: OSINT, law enforcement, national security, large platforms
- What: Extend ESRC to text+image+audio+code; link identities across social, video, and chat platforms at web scale with strict abstention.
- Dependencies: Legal frameworks and oversight; cross-platform data access; compute budgets; strong auditability; safeguards against misuse.
- Standardized “Anonymity Risk Score” and certification
- Sectors: regulators, standards bodies (NIST/ISO), industry consortia
- What: Codify testing protocols (precision targets, splits, adversarial evaluations) and certify datasets/products before public release.
- Dependencies: Stakeholder consensus; public benchmarks; periodic re-certification as model capabilities advance.
- Differential privacy and text-specific anonymization breakthroughs
- Sectors: privacy tech, ML research
- What: Develop DP mechanisms and robust text transformations (style smoothing, topic obfuscation, timeline coarsening) that provably reduce re-ID risk under ESRC-like adversaries.
- Dependencies: New theory for unstructured micro-data; utility–privacy trade-off quantification; domain-specific evaluators.
- On-device privacy advisors and secure enclaves
- Sectors: mobile OS, productivity suites, browsers
- What: Private, low-latency advisors that never send raw text off-device, offering live leak detection and rewriting.
- Dependencies: Efficient LLMs; hardware acceleration; privacy-preserving telemetry; UX that encourages adoption.
- Cross-lingual and low-resource deanonymization
- Sectors: global platforms, international NGOs, research
- What: Robust identity linkage across languages and code-switching; culturally aware feature extraction.
- Dependencies: High-quality multilingual models; localized benchmarks; bias detection and mitigation.
- Platform-level “privacy budget” UX and governance
- Sectors: social media, forums, education tech
- What: Give users a running privacy budget (akin to k-anonymity) that updates as they post, with proactive warnings when risk spikes.
- Dependencies: Reliable, real-time calibration; comprehensible risk explanations; minimal false alarms to avoid habituation.
- Privacy-aware logging and MLops pipelines
- Sectors: software/ML engineering
- What: CI/CD gates that run ESRC checks on internal logs, prompts, and traces before retention or sharing; automated redactions at ingest.
- Dependencies: Integration with data catalogs; lineage tracking; role-based access; organizational incentives.
- Updated legal safe harbors for unstructured text
- Sectors: policy and law (HIPAA, FERPA, GDPR, CCPA/CPRA, FOIA)
- What: Move beyond enumerated identifiers to risk-based standards acknowledging LLM-enabled re-ID from micro-data and stylometry.
- Dependencies: Legislative processes; enforcement guidance; impact assessments on transparency and research.
- Responsible identity graphs for compliance/KYC
- Sectors: finance, fintech, cybersecurity
- What: Calibrated, explainable identity linkage to improve KYC/AML while minimizing wrongful associations; human adjudication for edge cases.
- Dependencies: Regulatory acceptance; model governance; explainability tooling and appeals processes.
- Community-level defenses and content design patterns
- Sectors: community management, product design
- What: Design defaults that reduce leakage (e.g., delayed timestamps, coarser location granularity, style-normalized templates).
- Dependencies: Usability studies; measurement of utility loss; community acceptance.
- Editorial automation for anonymized storytelling
- Sectors: media, documentary, social impact orgs
- What: Tools that “blend” unique details across multiple contributors to preserve narrative while lowering re-ID probability.
- Dependencies: Ethical guidelines; audience transparency; empirical fidelity checks.
Cross-cutting assumptions and constraints
- Data access and legality: Many applications presume lawful access to content (APIs, consent, workplace policies) and jurisdiction-specific compliance.
- Calibration matters: The paper shows LLM Reason + Calibrate drastically reduces false positives compared to embeddings alone; production uses should target ≥98–99% precision with clear abstention.
- Coverage vs. overlap: Success often depends on overlapping micro-data (shared topics, timelines). Sparse or highly sanitized content may reduce recall.
- Scale and cost: Web-scale deployments require efficient indexing (e.g., FAISS) and selective LLM use (shortlists, staged reasoning) to control cost (the paper’s agentic runs cost ~$1–$4 per profile).
- Bias and fairness: Ground-truth construction and community characteristics can bias recall. Human review, appeals, and transparency are essential, especially for enforcement or high-stakes decisions.
- Model and data drift: Changes in platform norms or LLM behavior affect calibration; periodic revalidation is required.
Collections
Sign up for free to add this paper to one or more collections.