Adam Improves Muon: Adaptive Moment Estimation with Orthogonalized Momentum
Abstract: Efficient stochastic optimization typically integrates an update direction that performs well in the deterministic regime with a mechanism adapting to stochastic perturbations. While Adam uses adaptive moment estimates to promote stability, Muon utilizes the weight layers' matrix structure via orthogonalized momentum, showing superior performance in LLM training. We propose a new optimizer and a diagonal extension, NAMO and NAMO-D, providing the first principled integration of orthogonalized momentum with norm-based Adam-type noise adaptation. NAMO scales orthogonalized momentum using a single adaptive stepsize, preserving orthogonality while improving upon Muon at negligible additional cost. NAMO-D instead right-multiplies orthogonalized momentum by a diagonal matrix with clamped entries. This design enables neuron-wise noise adaptation and aligns with the common near block-diagonal Hessian structure. Under standard assumptions, we establish optimal convergence rates for both algorithms in the deterministic setting and show that, in the stochastic setting, their convergence guarantees adapt to the noise level of stochastic gradients. Experiments on pretraining GPT-2 models demonstrate improved performance of both NAMO and NAMO-D compared to the AdamW and Muon baselines, with NAMO-D achieving further gains over NAMO via an additional clamping hyperparameter that balances the competing goals of maintaining a well-conditioned update direction and leveraging fine-grained noise adaptation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Adam Improves Muon: Adaptive Moment Estimation with Orthogonalized Momentum”
Overview: What is this paper about?
Training big AI models (like GPT-2) means solving a giant “find the best settings” puzzle using noisy clues. This paper introduces two new ways to update a model’s weights during training so that learning is both:
- well‑directed (good “which way to step”), and
- stable under noise (good “how big a step to take”).
The two methods are called:
- NAMO: combines Muon’s “clean direction” with Adam’s “smart speed control”
- NAMO‑D (the diagonal version): like NAMO, but adjusts speed per neuron for even finer control
The main questions the paper asks
- Can we combine the best parts of two popular optimizers—Adam (great at handling noise) and Muon (great at picking a stable direction)—into one method that works better for LLMs?
- Can we do this with solid math guarantees and without making training much slower or more complicated?
- Will this actually help when training real models like GPT‑2?
How the methods work (in everyday terms)
Think of training as hiking to the bottom of a valley:
- “Direction” is where you point your step (downhill).
- “Step size” is how far you move each time.
Two ideas the paper builds on:
- Adam = automatic speed control. When the ground is noisy or uncertain, it slows the step; when things look clearer, it speeds up. It does this by tracking averages of recent gradients (signals) and how noisy they are (variance).
- Muon = clean direction for matrices. Neural network weights are often matrices, not just long vectors. Muon uses a trick called orthogonalization (think: keeping only the pure “rotation/reflection” part of the update, no stretching) so steps are well‑shaped and stable.
What this paper adds:
- NAMO: Keep Muon’s clean direction but multiply it by a single adaptive scale (a “smart speed” number) computed in an Adam‑like way from how strong and how noisy recent gradients are. That way:
- Direction stays clean and stable (thanks to Muon).
- Step size adapts to noise (thanks to Adam‑style scaling).
- It’s cheap to run: only a tiny bit more work than Muon.
- NAMO‑D (diagonal version): Same idea, but instead of one speed for the whole matrix, it gives each neuron (each column) its own speed. That’s like giving each hiker in a group their own pace based on their terrain. To keep things safe and not wobbly, the per‑neuron speeds are “clamped” around the average using a parameter so no one goes too fast or too slow.
Key terms made simple:
- Orthogonalization: transforms a matrix so it only rotates/reflects—no stretching. This keeps updates well‑conditioned and prevents weird distortions.
- Adaptive moments (Adam): running averages that estimate “typical size” of the gradient and how noisy it is; used to scale step sizes up or down.
- Clamping (in NAMO‑D): gently pulling very large or very small per‑neuron speeds back toward the average, controlled by .
What did the researchers do to test these ideas?
- Theory (math guarantees):
- With perfect (noise‑free) gradients: both NAMO and NAMO‑D converge at the best-known rate for this kind of problem (roughly like 1/√T after T steps).
- With noisy gradients: both methods slow down the step size in a noise‑aware way and achieve the best-known kind of rate for noisy problems (roughly like 1/T{1/4}), especially when the batch size is big enough.
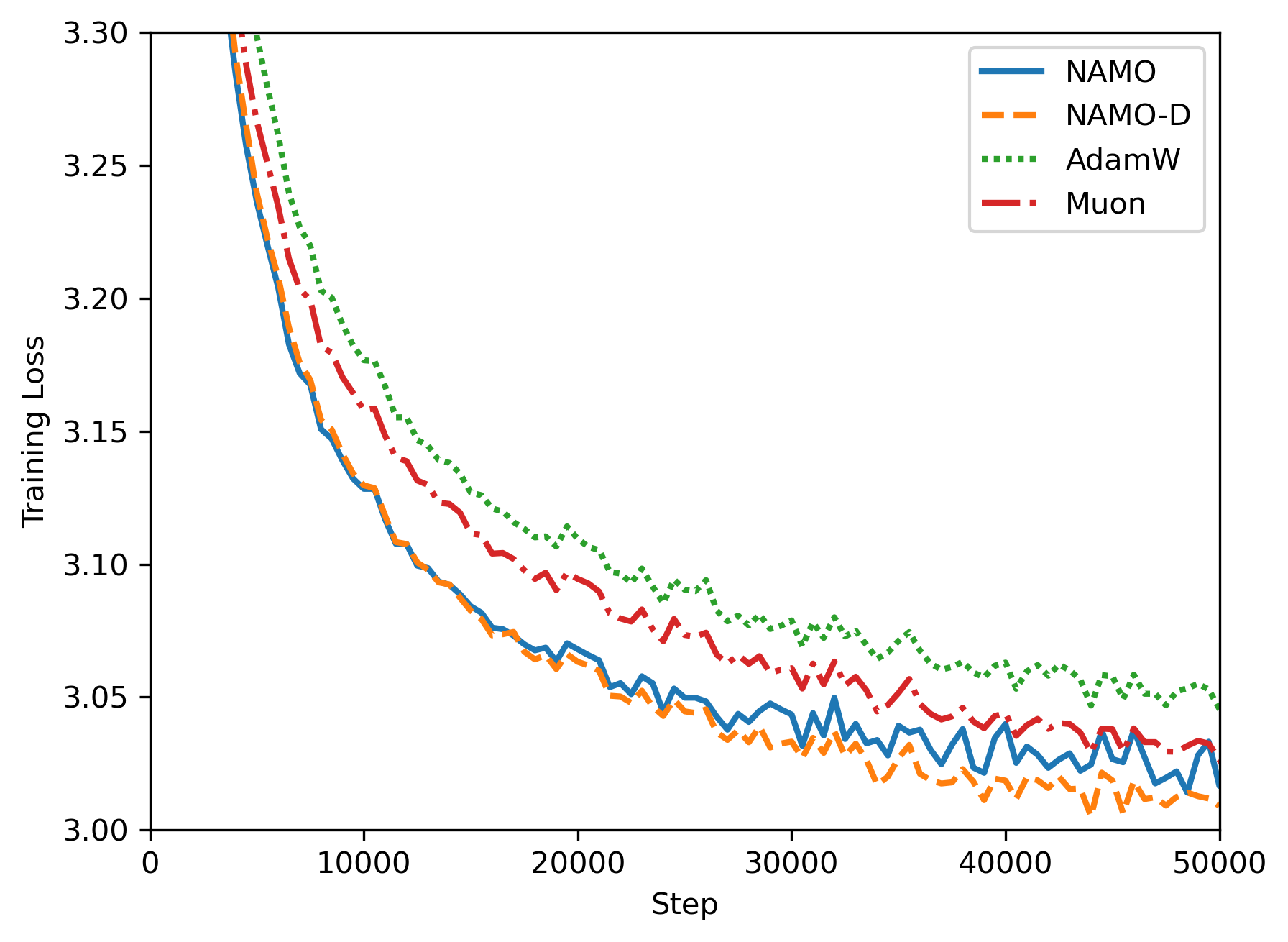
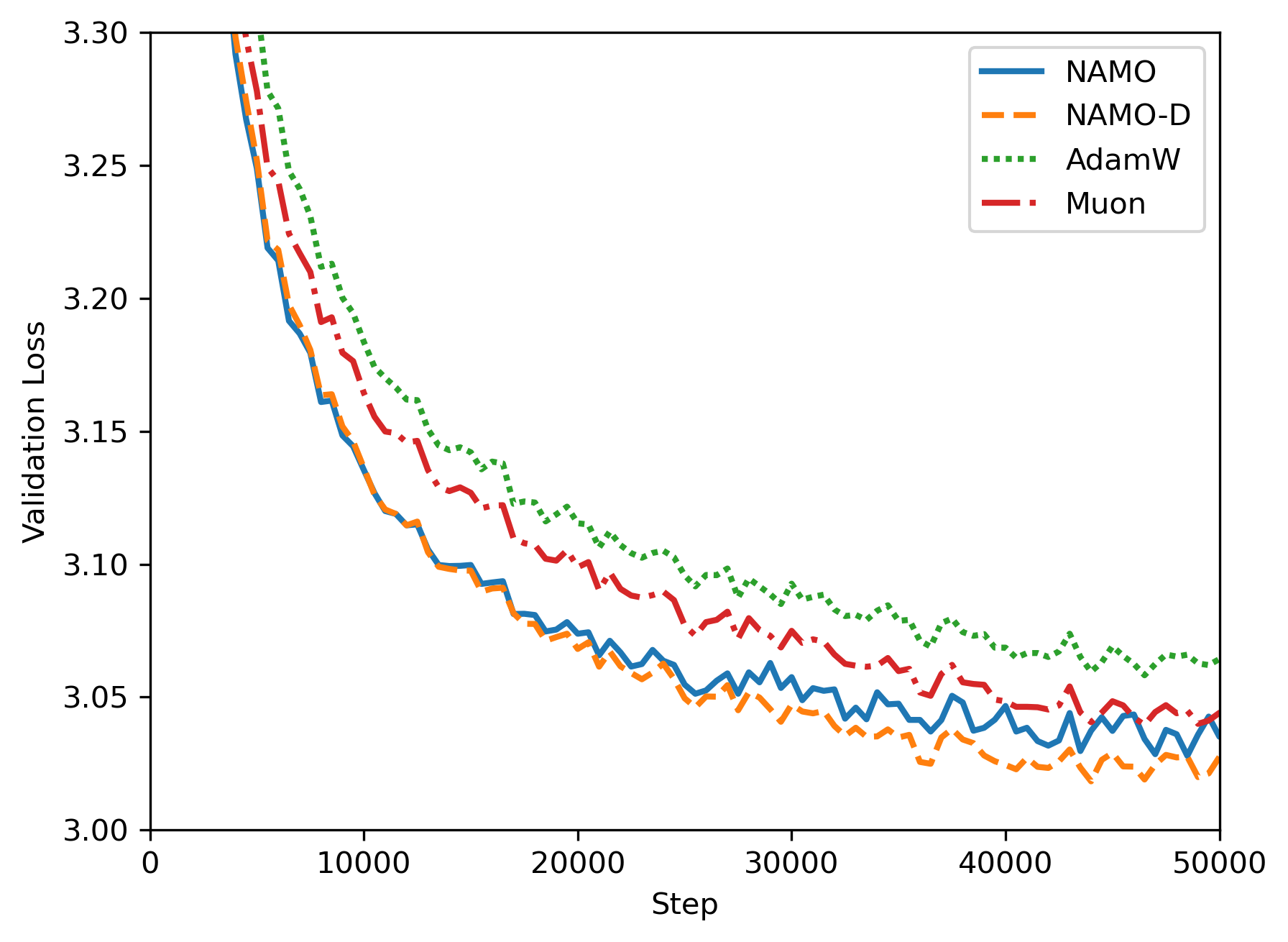
- Experiments (real training):
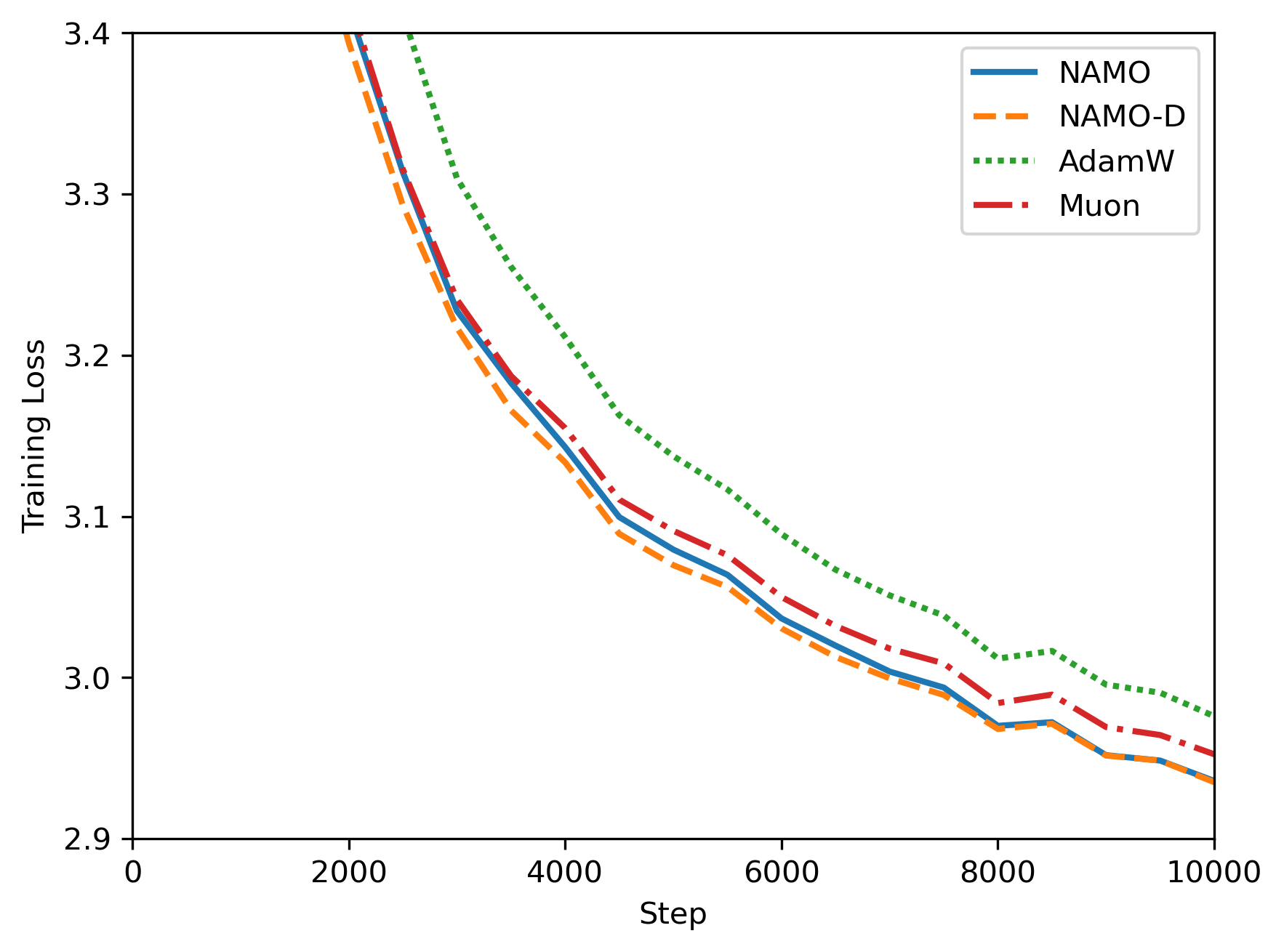
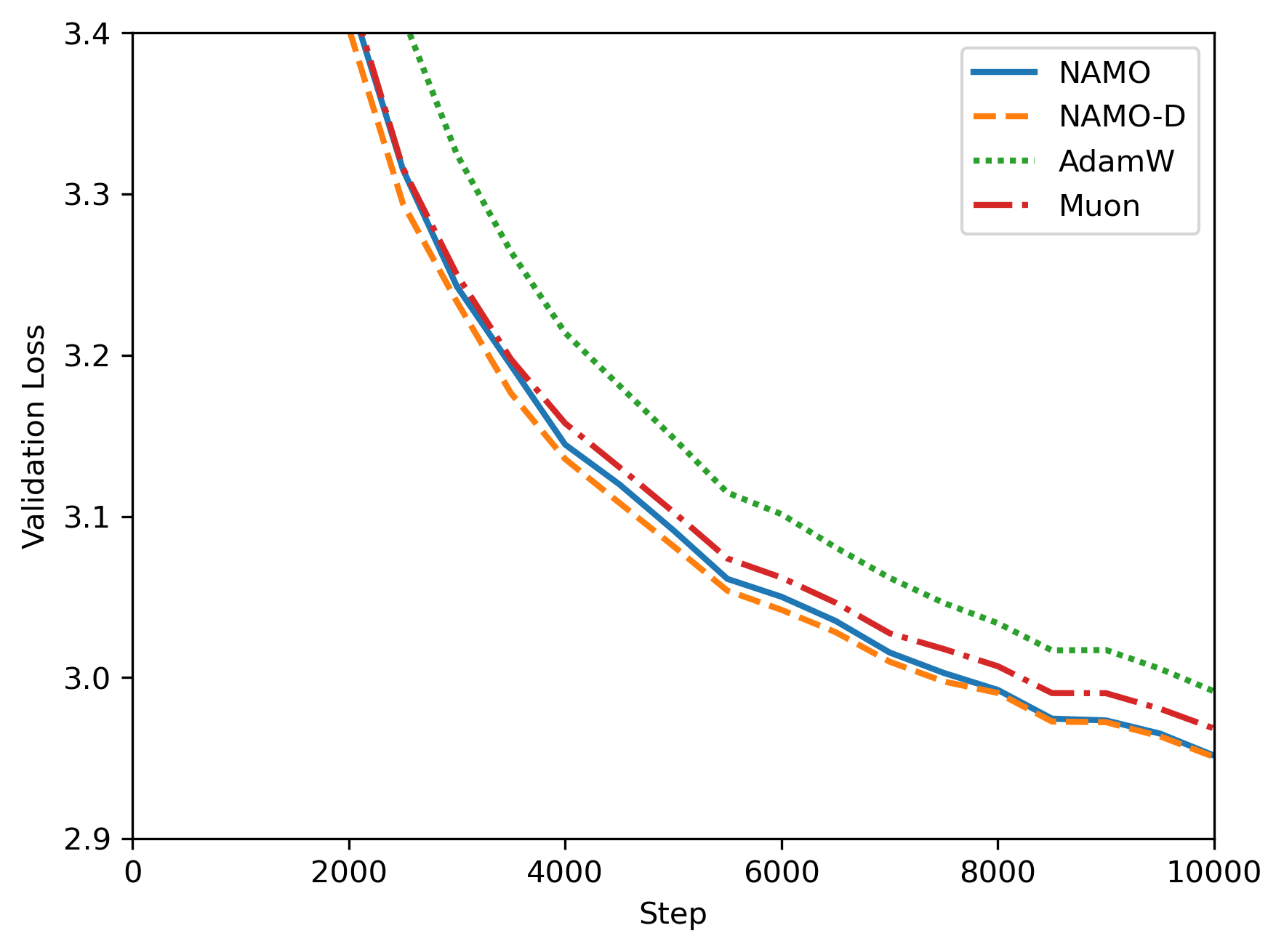
- They trained GPT‑2 models (124M and 355M parameters) on OpenWebText.
- They compared NAMO and NAMO‑D to AdamW and Muon.
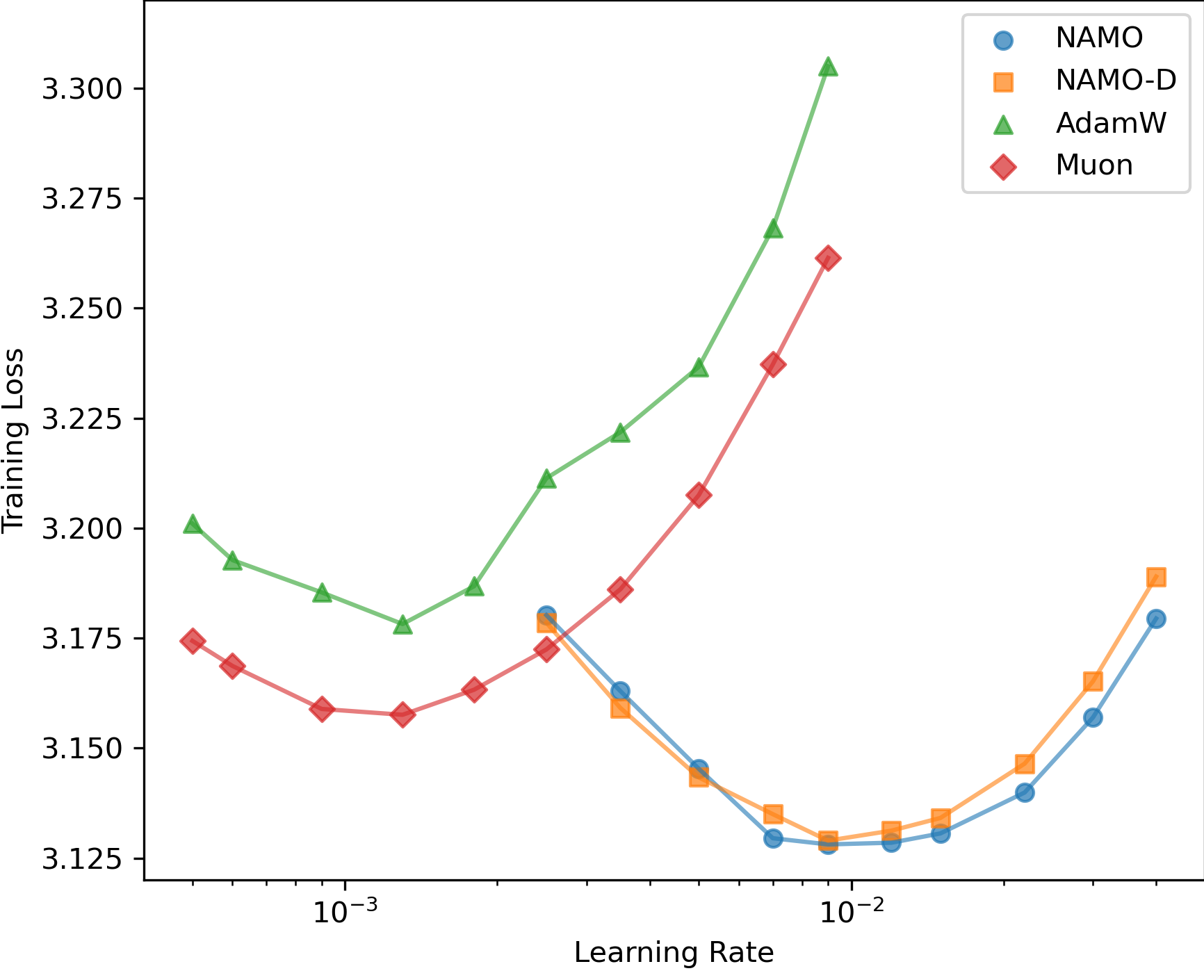
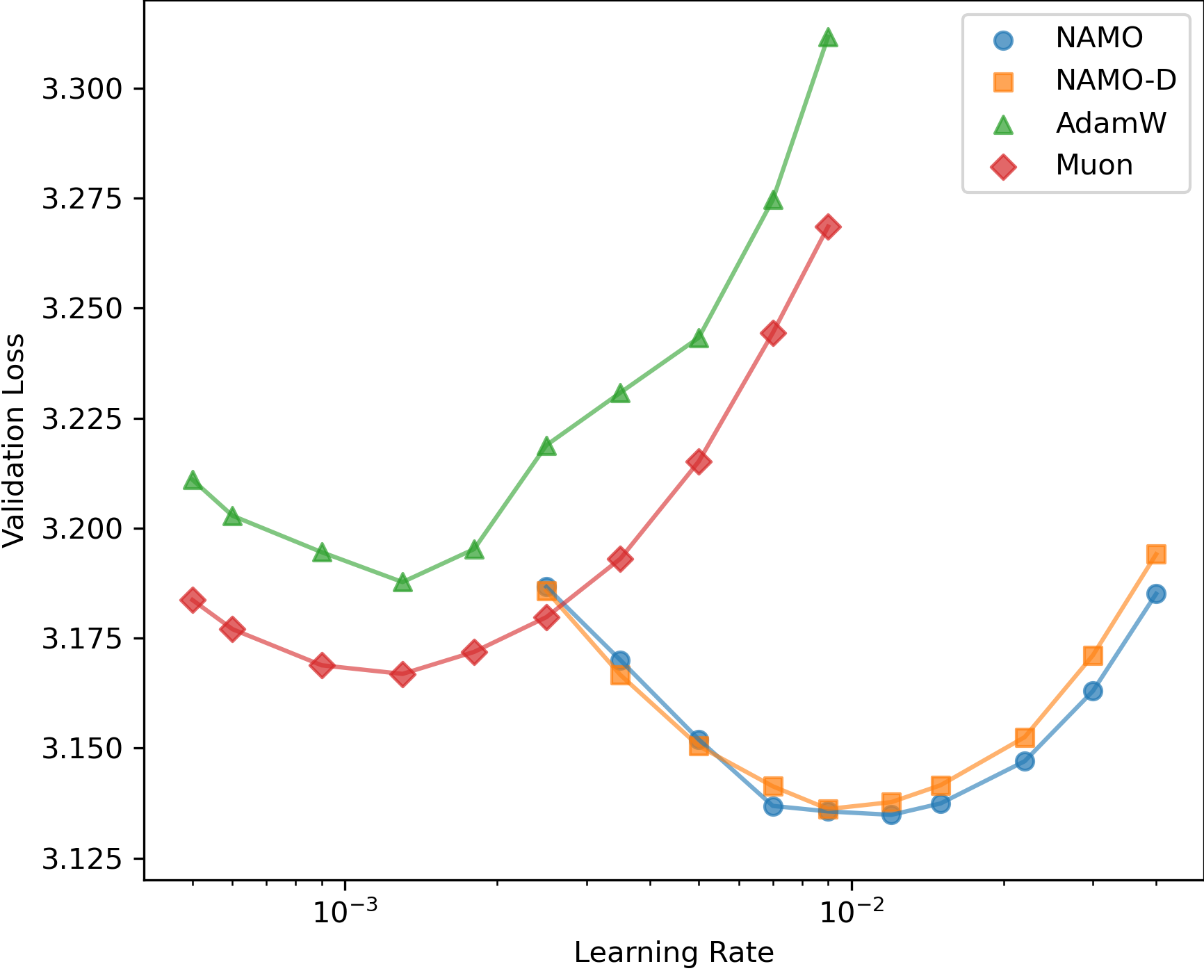
- They measured training loss and validation loss, and also tested how sensitive results are to the learning rate.
Main results and why they matter
- Both NAMO and NAMO‑D beat AdamW and Muon in GPT‑2 pretraining:
- Lower training and validation losses.
- More robust across different learning rates (less finicky to tune).
- NAMO‑D often does even better than NAMO:
- Because it adapts speed per neuron, it can handle noise more precisely.
- The clamp parameter lets you balance two goals: keep steps well‑shaped and still adapt finely to noise.
- Theoretical guarantees match the best possible rates for this kind of optimization:
- In plain terms: they’re not just hacks that work in practice—they’re also provably good.
Why this is important:
- Training big models is expensive and sensitive to settings. Methods that are both stable and strong can save time, compute, and frustration.
- Bringing matrix awareness (from Muon) together with noise awareness (from Adam) is a practical and elegant step forward.
What this could mean going forward
- Faster, more stable training for LLMs.
- Less hyperparameter tuning and fewer training crashes.
- A general recipe: use the structure of neural network weights (matrices) to pick good directions, and use adaptive moment estimates to choose safe, noise‑aware step sizes.
- Future work could apply NAMO/NAMO‑D to even larger models, refine the clamping strategy, or design tuning‑light versions.
In short: NAMO and NAMO‑D are like giving your training process a better compass (clean direction) and smarter cruise control (noise‑aware speed). Together, they help you reach better performance more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues and concrete next steps suggested by the paper’s current scope, assumptions, and experimental design.
- Theoretical guarantees assume exact orthogonalization; no analysis quantifies how approximate orthogonalization (e.g., finite Newton–Schulz iterations) affects convergence rates, stability, or noise amplification.
- The paper scales decoupled weight decay by the adaptive factor (α or D), diverging from AdamW practice; there is no theoretical justification or empirical ablation for whether scaling weight decay is beneficial or harmful.
- “Negligible additional cost” is asserted without a FLOP/memory analysis; wall‑clock training time, throughput, and memory overhead (especially for column‑wise second moment tracking in wide layers) are not measured or reported.
- Sensitivity to optimizer hyperparameters (μ1, μ2, ε schedule, and clamping c) is not systematically studied; no principled defaults, tuning heuristics, or adaptive schemes (e.g., dynamic c) are proposed.
- Convergence analysis relies on bounded‑variance, unbiased stochastic gradients; heavy‑tailed noise, affine/heteroscedastic variance, or biased gradients (common in practice) are not addressed.
- Smoothness assumption (Lipschitz gradient under nuclear/spectral norm equivalence) may not hold for deep networks; there is no analysis for non‑smooth or weakly smooth settings (e.g., Hölder continuity).
- Orthogonalization is known to be an unbounded operation; the paper does not provide perturbation bounds showing NAMO/NAMO‑D’s scaling attenuates noise amplification in Orth(M) under realistic noise models.
- The diagonal extension uses right‑multiplication (column‑wise scaling) only; the design trade‑offs versus left‑multiplication (row‑wise scaling) or two‑sided diagonal scaling (both rows and columns) are not explored.
- NAMO‑D loses strict orthogonality; there is no quantitative bound on the condition number of O_t D_t and how c controls the deviation from spectral steepest descent and impacts convergence speed.
- “Neuron‑wise” column interpretation is assumed; applicability and correctness across diverse layer types (attention projections, embeddings, convolutions, weight sharing) are neither justified nor evaluated.
- Experimental scope is limited to GPT‑2 124M and 355M on OpenWebText with short training horizons; larger LLMs, other modalities (vision, speech), and downstream tasks (e.g., perplexity on held‑out corpora, zero‑shot benchmarks) are not tested.
- Baselines omit recent adaptive Muon variants (AdaMuon, NorMuon, PRISM, DeVA, AdaGO, Adam‑mini); comparative ablations disentangling “orthogonalization” vs “structured adaptation” effects are missing.
- Interaction with common training practices (gradient clipping, mixed precision/FP8, optimizer state quantization, norm clipping) is unexplored; robustness under these regimes should be evaluated.
- Batch‑size dependence in theory (b = Ω(σ²√T)) is potentially impractical; empirical estimates of σ and the feasibility of meeting this scaling in large‑model training are not discussed.
- Block‑structured adaptation beyond columns (e.g., submatrix or layerwise scaling tailored to block‑diagonal Hessians) is not examined; connections to Adam‑mini and structured preconditioning remain open.
- Scaling uses momentum norms; the trade‑offs versus using gradient norms (G_t) for adaptation are not analyzed theoretically or empirically (e.g., responsiveness vs. stability).
- Effects of extreme aspect ratios in rectangular weight matrices on orthogonalization quality and scaling (e.g., narrow or very wide layers) are not analyzed.
- Reproducibility risks: the diagonal extension is inconsistently named/omitted in places, macros are broken, and some formulas are malformed; implementation details (e.g., Newton–Schulz iteration count and stopping criteria) are not specified.
- Stability under extreme noise or adversarial perturbations is not characterized; safeguards beyond clamping (e.g., trust‑region bounds, spectral norm caps, adaptive clipping) remain to be investigated.
- Learning‑rate transfer across model sizes is claimed broadly for orthogonalization in related work but not validated for NAMO/NAMO‑D; scaling laws and tuning‑transfer rules are needed.
- The deviation from spectral steepest descent caused by D_t is not quantified; a bound on performance loss vs. the gains from fine‑grained noise adaptation would guide c selection.
- Alternative clamping strategies (median anchors, percentile caps, layerwise normalization, adaptive c schedules) are not explored; their impact on conditioning and adaptation remains unknown.
- Mixing optimizers (matrix parameters with NAMO/NAMO‑D, others with AdamW) may create interactions (e.g., mismatched decay/scaling) that affect training dynamics; this hybrid design is not analyzed.
- Training‑time metrics (e.g., steps/sec, GPU utilization) and memory footprint comparisons are not reported; claims of negligible cost need empirical validation at scale.
- Initialization schemes, normalization layers (LayerNorm), and their interaction with orthogonalized updates and adaptive scaling are not studied; potential synergies or conflicts remain open.
Practical Applications
Practical Applications of NAMO and its Diagonal Extension (Orthogonalized Momentum with Adam-type Noise Adaptation)
Below are actionable applications derived from the paper’s methods and findings. Each item includes sectors, suggested tools/workflows/products, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now with available tooling (the authors provide code at https://github.com/minxin-zhg/namo) and require only routine integration into current training pipelines.
- LLM pretraining and fine-tuning optimizer upgrade (software/AI, cloud, MLOps)
- What to do: Replace AdamW/Muon on matrix-structured weights with NAMO (global scalar scaling) or its diagonal variant (neuron-wise scaling with clamping), keep AdamW for vector/scalar parameters.
- Benefits: Lower training/validation loss and wider learning-rate tolerance versus AdamW and Muon (as shown on GPT‑2 124M/355M), improved stability under noisy gradients, often fewer failed runs.
- Tools/workflows/products:
- PyTorch/JAX/TensorFlow optimizer plugin; Hugging Face Trainer integration; FSDP/DeepSpeed compatibility.
- Hyperparameter starting points from the paper: μ1=0.95, μ2=0.99, clamping c∈[0.1, 0.9]; larger base LRs than AdamW (e.g., 7e-3–1.2e-2 for NAMO in GPT‑2 setups), standard decoupled weight decay.
- Assumptions/dependencies: Matrix-structured parameters are required to benefit from orthogonalization; approximate orthogonalization (Newton–Schulz) must be stable; empirical gains demonstrated on GPT‑2 sizes—verify on your model/data.
- Training stability and tuning robustness for model scaling (software/AI, cloud)
- What to do: Use NAMO-D’s clamped neuron-wise scaling to reduce sensitivity to learning rate and batch size when transferring hyperparameters across model sizes.
- Benefits: Less hyperparameter sweeping, smoother scaling, fewer training collapses.
- Tools/workflows/products: Automated LR+c sweeps in MLOps; dashboard tracking of αt or diag(Dt) statistics to detect instability.
- Assumptions/dependencies: Clamping parameter c needs a brief sweep; performance hinges on stable approximate orthogonalization.
- Faster time-to-accuracy and compute/energy efficiency (cloud, energy, sustainability)
- What to do: Adopt NAMO/NAMO-D in existing training pipelines to reduce iterations to target loss or avoid restart costs.
- Benefits: Lower compute hours on clusters and carbon footprint; improved reliability reduces waste.
- Tools/workflows/products: Cloud training profiles that expose “optimizer=namod” toggle; energy dashboards attributing improvements to optimizer.
- Assumptions/dependencies: Gains are model- and data-dependent; energy/carbon benefits realized only if training steps truly decrease or throughput increases.
- Mixed-precision and large-batch training made more robust (software/AI, hardware)
- What to do: Combine NAMO/NAMO-D with BF16/FP16 training and gradient accumulation.
- Benefits: Orthogonalized direction with adaptive scaling keeps updates well-conditioned, reducing overflow/underflow risks and easing loss-scaling dynamics.
- Tools/workflows/products: AMP/Apex or PyTorch autocast integration; Fused kernels where available for the orthogonalization step.
- Assumptions/dependencies: Mixed-precision numerics amplify instability if clamping is too loose; verify with loss-scaling logs.
- Improved training for non-LLM matrix-heavy models (software/AI)
- What to do: Apply NAMO/NAMO-D to ViTs, diffusion U-Nets, large MLP blocks in recommenders, or other architectures with sizable dense weight matrices.
- Benefits: Potentially better convergence and robustness under heavy-tailed or noisy gradients.
- Tools/workflows/products: Optimizer registry entries in vision and generative modeling codebases; unit tests for layer coverage (matrix-only).
- Assumptions/dependencies: Convolutions and embeddings may be less directly compatible unless represented in matrix form; validate per-model impact.
- RL policy and value network training (robotics, gaming, operations research)
- What to do: Use NAMO/NAMO-D for large actor–critic networks or behavior cloning with matrix layers.
- Benefits: More stable policy updates under noisy, high-variance gradients; better step-size control via αt/diag(Dt).
- Tools/workflows/products: Integration in RL libraries (e.g., CleanRL, RLlib) with optional clamping sweeps.
- Assumptions/dependencies: Unbiased-gradient assumption in the theory does not strictly hold in RL; benefits are empirical and setup-dependent.
- Domain-specific foundation models (healthcare, finance, legal, scientific ML)
- What to do: Pretrain/fine-tune domain LLMs using NAMO-D to better manage gradient noise in scarce or skewed datasets.
- Benefits: Improved stability/generalization on specialty corpora; fewer catastrophic diverging runs.
- Tools/workflows/products: MLOps templates for domain LLMs with NAMO-D as default; automated c schedule tied to observed gradient variance.
- Assumptions/dependencies: Regulatory or privacy constraints are unaffected by optimizer choice; validate domain generalization empirically.
- Education and reproducible research baselines (academia, daily life for learners)
- What to do: Include NAMO and NAMO-D in optimization curricula, benchmark assignments, and open-source baselines.
- Benefits: Demonstrates modern optimizer trade-offs (directional orthogonalization vs. noise adaptation); supports replicable results with code.
- Tools/workflows/products: Teaching modules, notebooks comparing AdamW, Muon, NAMO, NAMO-D on public datasets.
- Assumptions/dependencies: Students need GPUs to observe performance differences on realistic models.
Long-Term Applications
These require further research, scaling work, or engineering beyond current open-source availability.
- Optimizer kernels and compiler support for orthogonalization (software/hardware)
- What to build: Fused, hardware-accelerated implementations of Newton–Schulz/polar orthogonalization in cuDNN/XLA/MLIR; graph-level optimizer fusion.
- Benefits: Lower per-step overhead, enabling use at very large scale and on diverse hardware.
- Dependencies: Vendor support; numerical stability guarantees; integration with distributed training runtimes.
- Petascale/trillion-parameter adoption (cloud, hyperscale AI)
- What to build: Distributed orthogonalization compatible with tensor/pipeline parallelism; numerically stable, communication-efficient synchronization of O_t and D_t.
- Benefits: Extends robustness and tuning-light properties to frontier LLMs.
- Dependencies: Collective communication strategies; tolerance to partial orthogonalization or layer-wise approximations.
- Adaptive clamping and noise-aware schedules (AutoML, MLOps)
- What to build: Automated controllers that tune c, μ1, μ2 online using gradient-noise metrics and validation feedback; per-layer clamping policies.
- Benefits: Reduces human tuning; adapts to non-stationary training regimes and curriculum changes.
- Dependencies: Reliable noise estimators; safeguards to prevent instability from aggressive adaptation.
- Structured extensions beyond dense matrices (software/AI)
- What to build: Variants for convolutional/tensor operators, block-diagonal or Kronecker-aware scaling, and attention-specific parameterizations.
- Benefits: Brings the method’s gains to a broader set of architectures (CNNs, low-rank adapters, factorized layers).
- Dependencies: Theory and numerics for orthogonalization in non-matrix or structured-operator spaces.
- Combination with second-order/curvature-aware methods (software/AI)
- What to build: NAMO/NAMO-D coupling with lightweight curvature approximations (e.g., diagonal/low-rank K-FAC-like statistics) while preserving orthogonality and adaptivity.
- Benefits: Potentially faster convergence with manageable overhead; better conditioning on ill-posed problems.
- Dependencies: Memory/compute budgets; stability of multi-preconditioner interactions.
- Quantization- and sparsity-aware training (software/AI, hardware)
- What to build: NAMO variants that preserve update quality under 8‑bit/4‑bit optimizers and sparsity constraints; quantization-aware orthogonalization.
- Benefits: Efficient training and fine-tuning for edge deployment; better stability in low-bit regimes.
- Dependencies: Quantization-friendly matrix functions; calibration pipelines.
- Standardization and policy guidance for efficient training (policy, sustainability)
- What to do: Incorporate optimizer choice into reporting standards for compute efficiency and carbon accounting; encourage best practices for stable training at scale.
- Benefits: More transparent, efficient AI development; supports sustainability targets.
- Dependencies: Community consensus and adoption by conferences, benchmarks, and regulators.
- Monitoring and governance for safety-critical training (policy, governance, regulated sectors)
- What to build: Dashboards and guardrails that track αt, diag(Dt), and conditioning metrics to detect training anomalies; audit trails linking stability to optimizer behavior.
- Benefits: Enhanced reliability and accountability in high-stakes applications.
- Dependencies: Organizational processes for monitoring; risk frameworks that recognize optimizer impacts.
- Theory for heavy-tailed and biased-gradient regimes (academia)
- What to research: Convergence and generalization under heavy-tailed noise, biased or correlated gradients (e.g., RL, curriculum learning), and non-Lipschitz landscapes.
- Benefits: Broader applicability and principled guidance for complex training settings.
- Dependencies: New analytical tools; empirical validation across tasks.
Cross-Cutting Assumptions and Dependencies
- Matrix-structured parameters: The core benefit relies on per-layer matrix updates (common in transformer MLP/attention projections). Non-matrix parameters should continue to use AdamW (hybrid mode).
- Orthogonalization approximation: Practical use relies on iterative approximations (e.g., Newton–Schulz). Accuracy/efficiency trade-offs and numerical stability are critical.
- Noise model and batch size: Theoretical rates assume unbiased gradients with bounded variance and show optimal scaling when batch size b is sufficiently large. Small-batch or biased settings may not meet assumptions.
- Hyperparameter sensitivity: NAMO-D’s clamping parameter c trades off strict conditioning vs. fine-grained adaptation. A small sweep is typically required per model/scale.
- Compute overhead: While memory overhead is negligible, there is per-step compute for orthogonalization and column-norm statistics. Fused kernels or vendor support can mitigate costs.
- Generalization: Empirical improvements demonstrated on GPT‑2 (124M/355M) and OpenWebText; verify on your data/task. Effects may differ for CNN-heavy models or RL.
These applications provide a roadmap for using NAMO/NAMO‑D now in production and research settings, and for advancing the ecosystem (kernels, workflows, theory) needed to realize their full potential at the largest scales.
Glossary
- Adaptive moment estimation: A family of techniques that maintain and use running estimates of gradient moments (e.g., means and variances) to adapt step sizes during optimization. Example: "with adaptive moment estimation to account for gradient noise."
- AdamW: An Adam variant that decouples weight decay from the gradient-based update to improve generalization and tuning. Example: "compared to the AdamW and Muon baselines"
- Bias corrections: Adjustments applied to biased moving averages of moments to debias them at finite time steps. Example: "With the standard bias corrections and "
- Clamping hyperparameter: A parameter controlling the range within which adaptive scaling values are constrained to ensure well-conditioned updates. Example: "through an additional clamping hyperparameter "
- Column-wise adaptive stepsize: A scheme assigning separate adaptive step sizes to each column (e.g., neuron) of a weight matrix. Example: "employs a column-wise adaptive stepsize for the orthogonalized momentum."
- Decoupled weight decay: Applying weight decay as a separate step from the gradient update, rather than via L2-regularization in the loss. Example: "The Muon optimizer applies decoupled weight decay as AdamW:"
- Effective stepsize: The actual per-update scaling that results from combining a base learning rate with adaptive normalization or scaling factors. Example: "adapting the effective stepsize to the noise level."
- Euclidean norm: The standard vector 2-norm measuring length in Euclidean space. Example: "where denotes the Euclidean norm."
- First-moment estimate: An exponential moving average of gradients approximating their mean. Example: "a biased first-moment estimate of the stochastic gradient:"
- Frobenius norm: A matrix norm equal to the square root of the sum of squares of all entries (equivalently, the l2 norm of the vectorized matrix). Example: "the nearest orthogonal matrix to in the Frobenius norm"
- Heavy-tailed data: Data whose distributions have tails heavier than exponential (e.g., power-law), affecting optimization stability and robustness. Example: "learn more effectively from heavy-tailed data"
- Hessian (near block-diagonal): The second-derivative matrix that, in many neural networks, is approximately block-diagonal, motivating structured adaptivity. Example: "near block-diagonal Hessian structure"
- Kronecker preconditioners: Structured preconditioners based on Kronecker products used to approximate curvature efficiently. Example: "maintaining Kronecker preconditioners and periodic eigendecompositions."
- Lipschitz continuous: A function (or gradient) whose rate of change is bounded linearly by the change in input, ensuring smoothness. Example: "The gradient of is Lipschitz continuous"
- Minibatch: A subset of training data used to compute a stochastic gradient estimate at each iteration. Example: "Sample a minibatch of size and compute stochastic gradient "
- Newton–Schulz iterations: An iterative method to approximate matrix inverses or polar factors efficiently. Example: "we use Newton--Schulz iterations to obtain an approximate orthogonalization"
- Norm duality: The relationship between a norm and its dual norm, often used to derive optimality or scaling characterizations. Example: "through a norm-duality characterization"
- Nuclear norm: The sum of singular values of a matrix (the l1 norm of singular values), dual to the spectral norm. Example: "where and denote the nuclear norm and the spectral norm respectively."
- Orthogonal factor: The unitary (orthogonal) component in the polar decomposition of a matrix. Example: "is also called the orthogonal factor in the polar decomposition"
- Orthogonalization: Mapping a matrix to the nearest orthogonal matrix (e.g., via polar decomposition), often to normalize update directions. Example: "matrix orthogonalization is an unbounded operation"
- Orthogonalized descent inequality: A descent guarantee tailored to updates using orthogonalized directions. Example: "using the orthogonalized descent inequality from \citep[Lemma~B.1]{zhang2025adagrad}"
- Orthogonalized momentum: Momentum vectors or matrices mapped to an orthogonal direction before applying updates. Example: "via orthogonalized momentum"
- Polar decomposition: A factorization of a matrix into the product of an orthogonal (or unitary) factor and a positive semidefinite factor. Example: "is also called the orthogonal factor in the polar decomposition"
- Preconditioner: A transformation applied to gradients to improve conditioning and convergence (e.g., adaptivity based on moments). Example: "a moment-based adaptive preconditioner"
- Signal-to-noise ratio (SNR): A measure comparing the magnitude of the signal (e.g., mean gradient) to the noise (e.g., variance), used to modulate step sizes. Example: "is often interpreted as a {signal-to-noise ratio} (SNR)."
- Singular value decomposition (SVD): A matrix factorization into orthogonal matrices and singular values, used here to define orthogonalization. Example: "reduced singular value decomposition (SVD)"
- Spectral norm: The largest singular value of a matrix (operator norm), dual to the nuclear norm. Example: "steepest descent direction under the spectral norm"
- Steepest descent: A method that moves in the direction of greatest immediate decrease under a chosen norm. Example: "the steepest descent direction under the spectral norm"
- Variance adaptation: Adjusting update magnitudes based on estimated gradient noise or variance to stabilize training. Example: "integration of Adam-type variance adaptation with an orthogonalized update direction."
Collections
Sign up for free to add this paper to one or more collections.