Delving into Muon and Beyond: Deep Analysis and Extensions
Abstract: The Muon optimizer has recently attracted considerable attention for its strong empirical performance and use of orthogonalized updates on matrix-shaped parameters, yet its underlying mechanisms and relationship to adaptive optimizers such as Adam remain insufficiently understood. In this work, we aim to address these questions through a unified spectral perspective. Specifically, we view Muon as the p = 0 endpoint of a family of spectral transformations of the form U \boldsymbolΣ{p} V' , and consider additional variants with p = 1/2 , p = 1/4 , and p = 1 . These transformations are applied to both first-moment updates, as in momentum SGD, and to root-mean-square (RMS) normalized gradient updates as in Adam. To enable efficient computation, we develop a coupled Newton iteration that avoids explicit singular value decomposition. Across controlled experiments, we find that RMS-normalized updates yield more stable optimization than first-moment updates. Moreover, while spectral compression provides strong stabilization benefits under first-moment updates, the Muon update (p = 0) does not consistently outperform Adam. These results suggest that Muon is best understood as an effective form of spectral normalization, but not a universally superior optimization method. Our source code will be released at https://github.com/Ocram7/BeyondMuon.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Delving into Muon and Beyond: Deep Analysis and Extensions”
Overview
This paper looks at two ways to train big neural networks faster and more reliably: the well-known Adam optimizer and a newer method called Muon. The authors try to understand how Muon really works, how it compares to Adam, and whether changing Muon’s main idea can make training better. They do this by studying the “shape” of gradient updates using a common lens (called a spectral perspective) and running careful, controlled experiments.
What questions did the paper ask?
The paper asks a few straightforward questions:
- What is Muon doing under the hood, and how does it relate to Adam?
- If we take Muon’s core idea (reshaping the update directions) and make it stronger or weaker, what happens?
- Is Muon actually better than Adam, or is it useful only in specific situations?
- Can we compute Muon-like updates efficiently on large models?
How did they study it?
To keep things clear, here are the main ideas they used:
- Adam vs. Muon (basic idea in everyday language):
- Adam: Think of Adam as a smart “cruise control” for training. It looks at how big the gradients are on each parameter and automatically turns the speed up or down to keep training steady. It uses two running averages: the first moment (an average of recent gradients) and the second moment (an average of squared gradients that measures typical size/variability). This second-moment “RMS-normalization” keeps updates from exploding.
- Muon: Instead of adjusting each number separately, Muon looks at whole matrices of gradients and treats them like combinations of directions with different strengths (this comes from something like a “direction-strength” breakdown called SVD). Muon’s core move is to flatten the strengths so all directions have the same size. Think of it like an audio compressor that turns down loud parts and turns up quiet parts so everything is more even.
- A family of “spectral” transformations:
- The authors build a family of updates that smoothly moves from “do nothing” to “flatten everything,” controlled by a knob called p:
- p = 1: keep the original update (like standard Adam or momentum SGD).
- p = 1/2 or p = 1/4: partially compress the strong directions and lift the weak ones.
- p = 0: fully flatten everything (this is Muon’s signature move).
- This lets them test whether “a little flattening” is better than “flatten everything.”
- Two places to apply these transformations:
- Momentum-only updates (first moment): like using the average of recent gradients without scale control.
- RMS-normalized updates (second moment, Adam-style): like using Adam’s “cruise control,” which already keeps sizes bounded and stable.
- Efficient computation trick:
- Doing these matrix operations directly can be slow. The authors use a method called coupled Newton–Schulz iteration, which is a fast, repeated “guess-and-improve” technique that avoids the heavy-duty SVD step. In simple terms: it’s a way to estimate certain matrix “square roots” using only multiplications, making the method practical on big models.
- Controlled experiments:
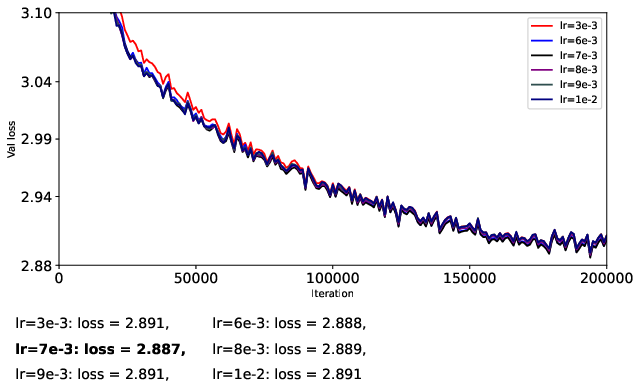
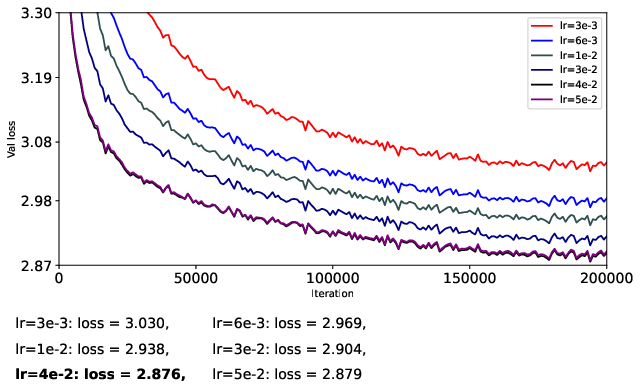
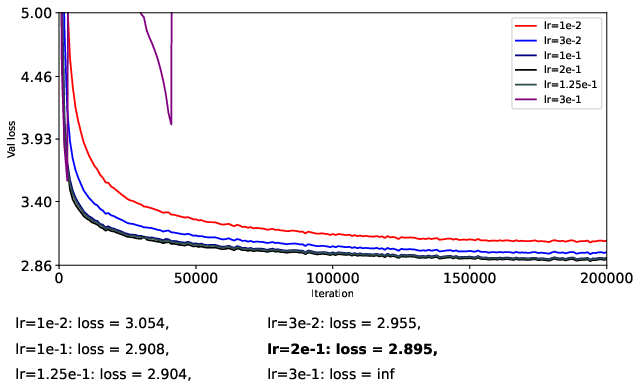
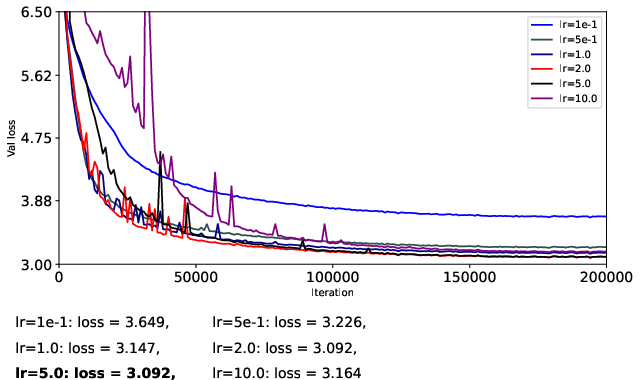
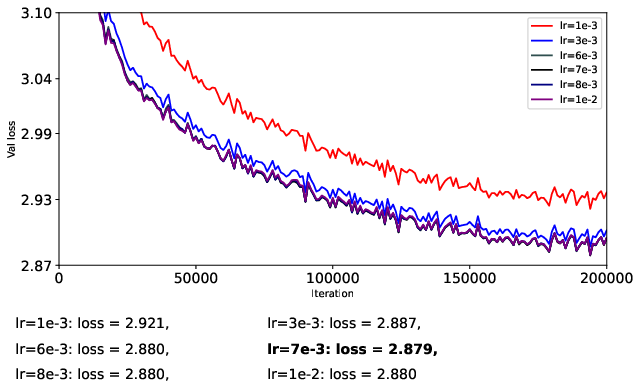
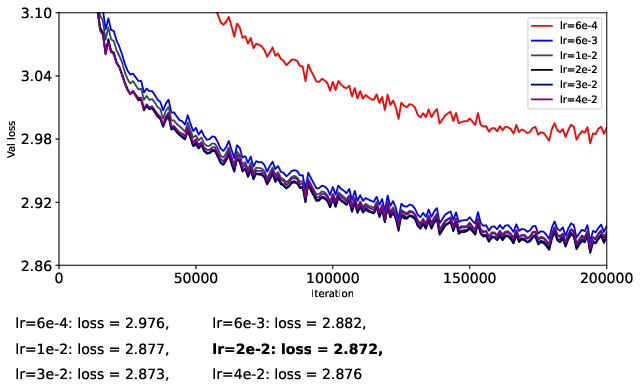
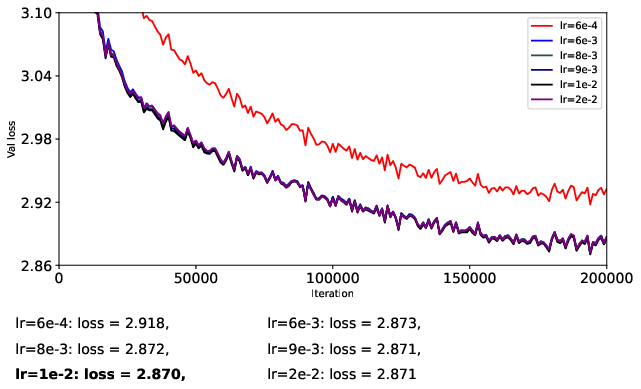
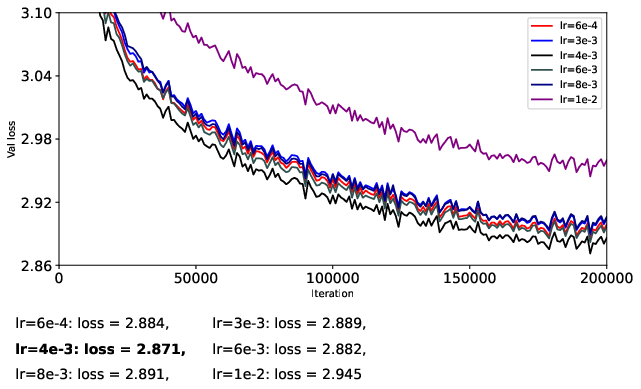
- They train a 124M-parameter GPT-2-like model (nanoGPT) on OpenWebText for 200k steps.
- To be fair, they carefully separate learning rates for matrix parameters and vector parameters, turn off weight decay, and avoid extra tricks (like QK-Norm or QK-Clip) so they can isolate what the optimizer itself is doing.
- They try different learning rates in a coarse-to-fine search to find stable and strong settings for each optimizer.
What did they find, and why is it important?
Here are the main results the authors saw:
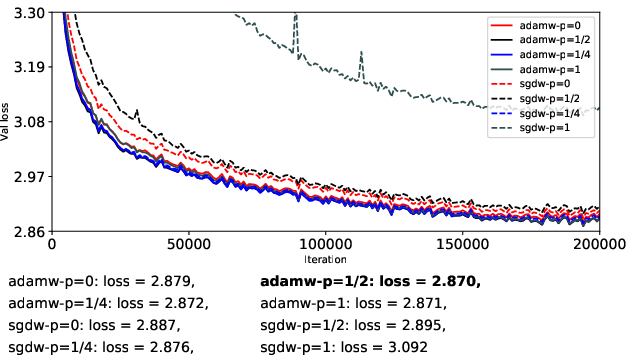
- Adam-style (RMS-normalized) updates are more stable than momentum-only updates.
- When you already have Adam’s “cruise control,” training tends to be smoother and more predictable.
- Muon (full flattening, p = 0) helps stabilize momentum-only updates but doesn’t beat Adam overall.
- If you don’t normalize the size of updates (just use momentum), Muon’s flattening step can stop training from blowing up. However, when you compare Muon to Adam (which already normalizes), Muon doesn’t consistently win.
- Partial flattening (p = 1/2 or 1/4) can sometimes be better than full flattening, especially with momentum-only updates.
- Making strong directions “less strong” helps stability, but flattening them all the way can also suppress helpful signals and boost noise. A gentler touch (like p = 1/4 or p = 1/2) can strike a better balance.
- Spectral transforms on Adam-style updates give modest gains at best.
- Since Adam already keeps scales under control, extra “flattening” rarely helps and full flattening (p = 0) can even hurt by amplifying noisy directions.
Why this matters:
- It clarifies what Muon is best at: stabilizing updates when you don’t already have Adam’s normalization.
- It shows that Muon isn’t a magic replacement for Adam. Instead, it’s a useful form of “spectral normalization” for certain cases.
- It suggests that second-moment (Adam-like) methods remain strong, and that “how much to flatten” is a tuning knob, not a one-size-fits-all fix.
What could this change or influence?
- Practical training choices: If you’re using momentum-only methods and struggle with stability, adding Muon-like spectral compression (especially partial compression) can help. But if you’re already using Adam-style updates, Muon’s full flattening may not be worth it.
- Design of future optimizers: The paper’s unified view (the p family) provides a clear framework for building and testing new optimizers that adjust how aggressively they flatten gradients. It also offers fast computation tricks to make these ideas practical.
- Honest expectations: Muon is best understood as a powerful stabilizer for certain inputs, not a guaranteed upgrade over Adam.
Simple takeaway
- Muon flattens the “direction strengths” of gradient updates to stabilize training, which helps a lot if you’re not already controlling update sizes.
- Adam already controls sizes, so Muon’s full flattening doesn’t usually beat it and can sometimes make things worse by boosting noisy directions.
- Gentle flattening (p = 1/2 or p = 1/4) can be a sweet spot, especially without Adam-style normalization.
- In short: think of Muon as a good spectral normalization tool, not a universal replacement for Adam.
A note on limitations and future directions
- The experiments turned off weight decay and avoided extra stabilization tricks to keep comparisons clean. Real-world training often uses those, so future work should test how spectral methods interact with them.
- The fast matrix method (coupled Newton–Schulz) still has overhead; improving efficiency would help scale these ideas further.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what the paper leaves unresolved, focusing on concrete, actionable gaps for future research.
- External validity across scales and architectures:
- Generalization beyond a single 124M-parameter GPT-2 on OpenWebText is untested (e.g., larger LLMs, ViTs/CNNs, speech models, RL, MT).
- No evidence on downstream task performance (e.g., zero-shot, finetuning, transfer) beyond training/validation loss.
- Weight decay and regularization:
- Interaction between spectral updates and decoupled weight decay (AdamW-style) is not evaluated; best practices for matrix-wise vs elementwise decay remain unknown.
- Interplay with widespread LLM stabilizers (e.g., QK-Norm, QK-Clip, gradient clipping) is deliberately excluded, leaving their combined effects uncharacterized.
- Whether spectral compression acts as implicit regularization (and its effect on generalization gap) is not measured.
- Runtime, memory, and scalability:
- No wall-clock, FLOPs, memory footprint, or throughput measurements comparing spectral variants to Adam across model sizes.
- Scalability and communication costs under data/tensor/pipeline parallelism are unquantified (e.g., extra matmul kernels inside the optimizer).
- Practical feasibility on very large layers and tall/skinny vs wide/short matrices is not established.
- Numerical stability and precision:
- Robustness of the coupled Newton–Schulz iteration in mixed precision (bf16/fp16/fp8), under gradient spikes or extreme conditioning, is untested.
- Convergence safeguards (e.g., adaptive scaling α, iteration caps, fallbacks) and their impact on numerical stability are not characterized.
- Rank deficiency and singular-value pathologies:
- Behavior of the polar factor in rank-deficient or near-singular updates (partial isometry corner cases) is not analyzed; effects on step quality remain unclear.
- Handling of exact zeros or extremely small singular values (and their numerical consequences) is unspecified.
- Design and scheduling of spectral compression:
- Only fixed exponents p ∈ {1, 1/2, 1/4, 0} are tested; no adaptive p selection (per-layer, per-step) or time-varying schedules are explored.
- Criteria to choose p based on online conditioning, signal-to-noise, or training phase are missing.
- Periodic or stochastic application of spectral transforms (vs every step) to reduce overhead and preserve beneficial anisotropy is unexplored.
- Algorithmic ablations and controls:
- Number of Newton–Schulz iterations K, choice of scaling α, and their accuracy–speed trade-offs are not ablated.
- Sensitivity to Adam hyperparameters (β1, β2, ε), learning-rate schedules (cosine/linear, warmup length), and batch size is not investigated.
- Multi-seed variability, confidence intervals, and statistical significance are not reported; “representative runs” may mask variance.
- Comparative baselines:
- No head-to-head comparison with strong matrix/curvature-aware baselines (e.g., Shampoo, K-FAC), or widely used optimizers (Adafactor, LAMB, Lion, Sophia).
- Absence of AdamW with tuned weight decay as a baseline weakens conclusions about superiority or parity in realistic settings.
- Measurement of spectral effects:
- The hypothesized “noise magnification” in small singular directions is not quantitatively validated (e.g., SNR per singular mode, effective rank dynamics).
- No tracking of update singular spectra or condition numbers during training to correlate anisotropy control with stability/performance outcomes.
- Alignment of update directions with raw gradients (cosine similarity, step efficiency) is not measured.
- Scope of parameter coverage:
- Only “matrix-shaped” parameters receive spectral updates; whether embeddings, LayerNorm scales/biases, and other vector-like or block-structured parameters could benefit from tailored spectral schemes is left open.
- Treatment of non-square matrices when n > m (the paper assumes m ≥ n) and layer-shape-specific strategies (e.g., using O OT vs OT O) are not detailed.
- Tensor and convolutional parameters:
- Extensions of spectral transforms to higher-order tensors (e.g., convolutional kernels) or structured factorizations (e.g., Kronecker, blockwise) are not explored.
- Theory and guarantees:
- No convergence analysis, regret bounds, or stability guarantees for Ψp under stochastic nonconvex settings.
- Lack of formal preconditioning interpretation for rectangular matrices (i.e., when and how Ψp equates to a principled preconditioner).
- No theory linking p, curvature, and gradient noise to optimal risk or convergence rates.
- Practical training questions:
- Interaction with gradient clipping (ubiquitous in LLMs) is untested; whether spectral flattening reduces/increases clipping events is unknown.
- Stage-dependent strategies (e.g., stronger compression early, milder later) and their impact on final perplexity or overfitting are unexplored.
- Generalization to finetuning regimes (instruction tuning, RLHF, low-resource) and catastrophic forgetting behavior are untested.
- Implementation and reproducibility:
- Exact reproducibility details (seeds, full configs, logs) and completeness of the forthcoming code release are unspecified.
- Guidance for practitioners on when the extra optimizer cost is justified by gains (decision rules, heuristics) is not provided.
- Methodological extensions:
- Alternative spectral nonlinearities (e.g., soft-thresholding, spectral clipping, learned shrinkage) beyond power-law σp are not examined.
- Combining spectral compression with curvature-aware preconditioners (e.g., Ψp atop Adam/Shampoo) is untested.
Practical Applications
Overview
Based on the paper’s unified spectral framework for matrix-shaped updates, its efficient coupled Newton–Schulz (NS) computation for fractional spectral transforms, and controlled empirical findings comparing Muon-style orthogonalization to Adam-like RMS normalization, the following applications emerge across industry, academia, policy, and daily practice.
Immediate Applications
- 1) Drop-in spectral variants of Adam for matrix-shaped parameters (software/AI)
- What: Use partial spectral compression on RMS-normalized updates (e.g., “AdamS” with p=1/2 or “AdamQ” with p=1/4) as a drop-in optimizer for matrix parameters while keeping standard Adam for vectors.
- Tools/workflows:
- PyTorch/TF optimizer wrappers that apply Ψp only to matrix-shaped weights.
- Configurable p∈{1, 1/2, 1/4, 0}, tuned separately from vector learning rates.
- Automated layer tagging (e.g., linear/attention projections).
- Assumptions/dependencies:
- Benefits are modest when second-moment normalization is already used; p=1/2 often a safe default.
- Additional matrix multiplications add overhead; suitable for GPU/TPU.
- Numerical scaling for NS iterations required for stability.
- 2) Stabilize momentum-based training with Muon-like orthogonalization (software/robotics/embedded)
- What: For pipelines still relying on first-moment momentum (mSGD) or constrained environments, apply Muon (p=0) or mild compression (p=1/4, 1/2) to improve robustness to ill-conditioning.
- Tools/workflows:
- mSGDZ (Muon) updates on matrix parameters; keep vectors on Adam or mSGD.
- Fallback workflow: increase compression (lower p) only for unstable layers.
- Assumptions/dependencies:
- May underperform Adam in final metrics; best suited where RMS normalization is not feasible.
- Matrix sizes should permit efficient batched matmuls.
- 3) Efficient spectral primitives via coupled Newton–Schulz (software/hardware acceleration)
- What: Package the coupled NS iteration to compute X±1/2, polar factors, and quarter powers using only matrix multiplications (no SVD).
- Tools/products:
- Library kernels (CUDA/ROCm/XLA) for batched small-matrix NS updates.
- Reusable module for optimizers, polar decomposition, and spectral normalization.
- Assumptions/dependencies:
- Convergence depends on input scaling; implement normalization and iteration caps.
- Memory/compute overhead scales with number of matrix parameters and NS iterations.
- 4) Layer-selective spectral compression for “problem” matrices (LLMs/CV/ASR)
- What: Apply p<1 only to specific unstable modules (e.g., attention projections, deep MLP layers), leaving others on standard Adam.
- Tools/workflows:
- Per-layer p scheduling and per-group learning rates.
- Heuristics: lower p if condition proxies spike or training diverges.
- Assumptions/dependencies:
- Requires instrumentation to identify unstable layers.
- Gains depend on model- and task-specific spectra.
- 5) Spectral anisotropy diagnostics for training health (industry/academia)
- What: Monitor condition-number proxies κ(O_t) of update matrices to detect ill-conditioning and trigger mitigations (lower p, reduce LR).
- Tools/workflows:
- Logging hooks for κ estimates via O_tT O_t (power iterations or low-rank approximations).
- Integration with experiment trackers (W&B/MLflow).
- Assumptions/dependencies:
- Estimating κ efficiently requires approximations; tradeoff between accuracy and overhead.
- Most valuable for matrix-heavy architectures (Transformers).
- 6) Reproducible optimizer benchmarking protocol (academia/standards/policy)
- What: Adopt the paper’s controlled comparison setup—decoupled matrix/vector LRs, disabled weight decay, and removal of auxiliary tricks—to isolate optimizer effects.
- Tools/workflows:
- Shared harness with fixed β1/β2, batch size, warmup, and tuning grids.
- Reporting templates including matrix/vector LR separation and spectral settings.
- Assumptions/dependencies:
- Protocol may differ from production recipes (e.g., weight decay off); use both “controlled” and “production” evaluations for completeness.
- 7) Teaching modules for spectral optimization (education)
- What: Use the unified Ψp framework and coupled NS iteration to teach matrix functions, polar decomposition, and optimizer design.
- Tools/workflows:
- Jupyter notebooks demonstrating p∈{1, 1/2, 1/4, 0}, κ evolution, and NS convergence.
- Assumptions/dependencies:
- Requires GPU/CPU with BLAS for smooth classroom demos.
Long-Term Applications
- 1) Adaptive spectral exponent scheduling (software/AI research)
- What: Learn or schedule p online per layer based on κ(O_t) or other signals, balancing stabilization vs. preserving informative anisotropy.
- Tools/products:
- “Adaptive Spectral Adam” that tunes p∈[0,1] via rules or learned controllers.
- Assumptions/dependencies:
- Requires robust κ estimation and stability analysis; added compute.
- Interaction with momentum/second-moment dynamics needs theoretical support.
- 2) Production-ready spectral optimizers integrated with weight decay and popular LLM tricks (industry)
- What: Combine spectral compression with decoupled weight decay (AdamW), QK-Norm/Clip, and large-scale training recipes to improve stability at scale.
- Tools/products:
- Next-gen optimizer suite exposing p, decay, and norm/clip knobs with safe defaults.
- Assumptions/dependencies:
- Paper’s findings exclude weight decay and auxiliary tricks; empirical re-validation required.
- Large-scale ablations on multi-billion parameter models and multi-node training.
- 3) High-performance, distributed NS kernels (systems/hardware)
- What: Mixed-precision, fused, and distributed coupled-NS implementations (e.g., FP8/FP16 with error compensation) for batched small matrices across devices.
- Tools/products:
- Custom kernels in cuBLASLt/TVM/Triton; XLA SPMD partitioning strategies.
- Assumptions/dependencies:
- Numerical error control is critical; hardware-specific tuning needed.
- Benefits must outweigh kernel engineering costs.
- 4) Energy and cost reductions via broader stable LR ranges (operations/energy)
- What: Use partial spectral compression to widen stable learning-rate regions, reducing hyperparameter sweeps and failed runs.
- Tools/workflows:
- AutoML systems that toggle p as a stabilization knob during search.
- Assumptions/dependencies:
- Gains likely task- and model-dependent; may be modest with RMS-normalized optimizers.
- Must be validated with end-to-end cost metrics.
- 5) Sector-specific robust training recipes (healthcare, finance, safety-critical AI)
- What: For models where training failures are costly, use conservative spectral settings (e.g., p=1/2 on selected layers) to reduce instability without large performance trade-offs.
- Tools/workflows:
- Compliance-ready training templates that prioritize stability and auditability.
- Assumptions/dependencies:
- Domain generalization requires validation; modest compute overhead acceptable.
- Regulatory environments may demand extensive documentation of optimizer choices.
- 6) Applications beyond deep nets: spectral updates in control/RL and calibration (robotics)
- What: Apply spectral compression/orthogonalization to matrix-valued updates in policy optimization, system identification, or calibration to mitigate ill-conditioning.
- Tools/workflows:
- Optimizer modules wrapping policy-gradient or Jacobian-based updates with Ψp.
- Assumptions/dependencies:
- Structure of update matrices must align with spectral assumptions; empirical benefits uncertain.
- Real-time constraints may limit NS iteration counts.
- 7) Extensions to tensor-valued parameters (research)
- What: Generalize Ψp to tensors via multi-mode SVD, Kronecker, or low-rank factorizations for convolutional kernels and attention tensors.
- Tools/products:
- Approximate multi-mode spectral transforms with efficient factorizations.
- Assumptions/dependencies:
- Algorithmic complexity and memory can be high; theory and scalable approximations needed.
- 8) Standardized reporting for optimizer studies (policy/standards)
- What: Encourage venues and repositories to require reporting of matrix vs. vector LRs, weight decay coupling, and use of auxiliary techniques to improve comparability.
- Tools/workflows:
- Checklists and metadata schemas for optimizer configurations.
- Assumptions/dependencies:
- Community and venue buy-in; backward compatibility with existing benchmarks.
Notes on Feasibility and Generalization
- The paper’s empirical conclusions are drawn from controlled GPT-2 (124M) experiments on nanoGPT with weight decay disabled and without auxiliary tricks (e.g., QK-Norm/Clip). Results may differ in production-scale settings.
- Coupled NS iteration is practical for matrix-shaped parameters but introduces nontrivial matmul overhead; benefits depend on matrix size distributions and available accelerator throughput.
- Code availability (BeyondMuon repository) is a dependency for replication and rapid prototyping.
Glossary
- Anisotropic scaling: Direction-dependent magnitude differences in a matrix’s spectrum that can cause imbalanced updates; reducing it improves stability. "As a result, Muon removes anisotropic scaling in the spectrum of , yielding directionally balanced but magnitude-agnostic updates."
- Coupled Newton–Schulz iteration: A two-sequence iterative method that simultaneously computes a matrix square root and its inverse using only matrix multiplications. "Coupled Newton-Schulz iteration~\cite{higham_higham2008functions} provides an efficient and numerically stable procedure for simultaneously computing the matrix square root and its inverse ."
- Fisher information matrix: A matrix capturing curvature (information) of the parameterized model’s likelihood, often used for second-order preconditioning. "K-FAC~\cite{kfac_martens2015optimizing} introduced a Kronecker-factored approximation of the Fisher information matrix, enabling efficient layer-wise preconditioning,"
- Frobenius norm: The square root of the sum of squared matrix entries; commonly used for normalization and scaling in matrix algorithms. "In practice, a normalization step based on the Frobenius norm of is applied at initialization to ensure numerical stability,"
- K-FAC: Kronecker-Factored Approximate Curvature; an optimizer that approximates curvature via Kronecker factorizations of the Fisher information matrix. "K-FAC~\cite{kfac_martens2015optimizing} introduced a Kronecker-factored approximation of the Fisher information matrix, enabling efficient layer-wise preconditioning,"
- Kronecker factorizations: Decompositions using Kronecker products along matrix dimensions to structure curvature approximations. "Shampoo~\cite{shampoo_gupta2018shampoo} extended this idea by applying Kronecker factorizations along multiple matrix dimensions, leading to improved stability."
- Manifold-aware optimization: Optimization that respects the geometric constraints of parameter manifolds (e.g., orthogonal groups). "and geometric interpretations that view it as implicit manifold-aware optimization~\cite{bernstein_bernstein2025manifolds, sam_buchanan2025mmuonadmm}."
- Momentum SGD: Stochastic gradient descent augmented with momentum to accumulate first-moment information across iterations. "Adam-style optimizers that incorporate second-moment statistics generally outperform momentum SGD-based optimizers that only leverage first-moment information."
- Newton–Schulz iteration: An iterative scheme to compute matrix inverse roots using only matrix multiplications; often used to avoid explicit SVD. "However, we can approximate the inverse square root using Newton--Schulz iteration, which relies only on matrix multiplications."
- Orthogonalization: Transforming a matrix update to have orthonormal singular directions (unit magnitude across directions). "Computing the polar factor is typically referred to as matrix orthogonalization."
- Polar factor: The orthogonal component in the polar decomposition of a matrix, given by for the SVD . "Muon defines the update direction as the polar factor"
- Preconditioning: Re-scaling or transforming gradients/updates to account for curvature, improving optimization stability and convergence. "From a preconditioning perspective, Adam applies a diagonal matrix to the momentum , normalizing each coordinate by an estimate of its second-moment"
- RMS-normalized update: An update normalized by the root-mean-square of past gradients (second-moment), as in Adam. "we refer to as the RMS-normalized update, since tracks an exponential moving average of squared gradients."
- Singular value decomposition (SVD): Factorization of a matrix into singular vectors and singular values; central to spectral methods. "Computing the polar factor
via an explicit SVD is prohibitively expensive for large models."
- Singular vectors: The orthonormal bases (left/right) from SVD that define principal directions of a matrix’s action. "which discards the singular values and retains only the left and right singular vectors."
- Spectral anisotropy: Uneven distribution of singular values across directions, leading to ill-conditioning in updates. "Therefore, decreasing reduces spectral anisotropy:"
- Spectral compression: Dampening large singular values relative to small ones to reduce anisotropy and stabilize updates. "while spectral compression provides strong stabilization benefits under first-moment updates, the Muon update () does not consistently outperform Adam."
- Spectral condition number: The ratio of the largest to smallest singular values; measures ill-conditioning of a matrix. "To quantify anisotropy, we use the spectral condition number"
- Spectral flattening: Mapping all nonzero singular values to a constant (often 1), equalizing directional magnitudes. "This viewpoint clarifies how the exponent continuously interpolates between the original spectrum () and complete spectral flattening ()."
- Spectral normalization: Rescaling updates in the spectral domain (via singular values) to control magnitudes across directions. "These results suggest that Muon is best understood as an effective form of spectral normalization, but not a universally superior optimization method."
- Spectral transformation: A mapping of a matrix’s SVD components via a function of singular values (e.g., ) to shape update behavior. "we view Muon as the endpoint of a family of spectral transformations of the form "
Collections
Sign up for free to add this paper to one or more collections.