PRISM: Structured Optimization via Anisotropic Spectral Shaping
Abstract: We propose PRISM, an optimizer that enhances first-order spectral descent methods like Muon with partial second-order information. It constructs an efficient, low-rank quasi-second-order preconditioner via innovation-augmented polar decomposition. This mechanism enables PRISM to perform anisotropic spectral shaping, which adaptively suppresses updates in high-variance subspaces while preserving update strength in signal-dominated directions. Crucially, this is achieved with minimal computational overhead and zero additional memory compared to first-order baselines. PRISM demonstrates a practical strategy for integrating curvature-adaptive properties into the spectral optimization paradigm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces PRISM, a new way to train neural networks faster and more safely. PRISM is an “optimizer,” which means it’s a set of rules that decides how to change a model’s weights so it gets better at its task. PRISM builds on a recent method called Muon and adds a smart twist: it learns to step boldly in directions that look trustworthy and gently in directions that look noisy or risky. It does this while using almost no extra memory and very little extra compute.
Goals and questions the paper asks
- Can we make Muon smarter by letting it “see” which directions of change are noisy and which are reliable, without paying big costs in memory or computation?
- Is there a simple signal we can use, right now at each step, to estimate how uncertain the gradient is (the gradient is the direction that reduces the model’s error)?
- If we add that signal, do we actually train models faster and keep them more stable, especially with bigger learning rates?
How PRISM works (in everyday language)
Think of training a model like hiking down a mountain in heavy fog to reach the lowest point (the best solution). The “gradient” is the direction downhill at each step. “Momentum” is like remembering the recent path you’ve taken so you don’t zig-zag too much.
- Muon’s idea: Treat weight matrices as true matrices (not just long lists of numbers) and “straighten out” the directions so you don’t favor one direction just because it’s bigger. This is called a spectral method; it’s like making all directions equally easy to step along.
- What’s missing in Muon: It treats all directions equally after whitening, but some directions are actually shaky and noisy. If you step too hard in those noisy directions, you can stumble.
- PRISM’s new signal: PRISM measures “innovation,” which is the surprise at each step:
- innovation = (today’s gradient) − (your momentum’s prediction)
- If innovation is large in a direction, that means today’s signal disagrees with your recent history—likely noisy.
- If innovation is small, that direction is more consistent—likely reliable.
- What PRISM does with that: It builds a tiny extra piece of information from the innovation and adds it to Muon’s usual calculation. Then it uses a fast procedure (called Newton–Schulz, a way to compute a “polar decomposition” that finds the rotation-orientation part of a matrix) to produce an update that:
- keeps strong steps in directions with consistent signal
- softens steps in directions with high uncertainty
This behavior is called “anisotropic spectral shaping.” Think of it like having a separate volume knob for each direction: loud where the music is clear, quiet where there’s static. In contrast, Muon’s “isotropic whitening” sets all directions to the same volume.
Key points in simple terms:
- No extra memory: PRISM doesn’t store big, heavy matrices. It computes the innovation on the fly and reuses Muon’s machinery.
- Tiny compute overhead: It does roughly the same kind of math as Muon, with only a small constant increase that modern hardware handles well.
What the experiments found and why it matters
The authors trained a 22M-parameter Transformer LLM on a large text dataset and compared:
- AdamW (a popular optimizer),
- Muon,
- PRISM (their method).
Main results:
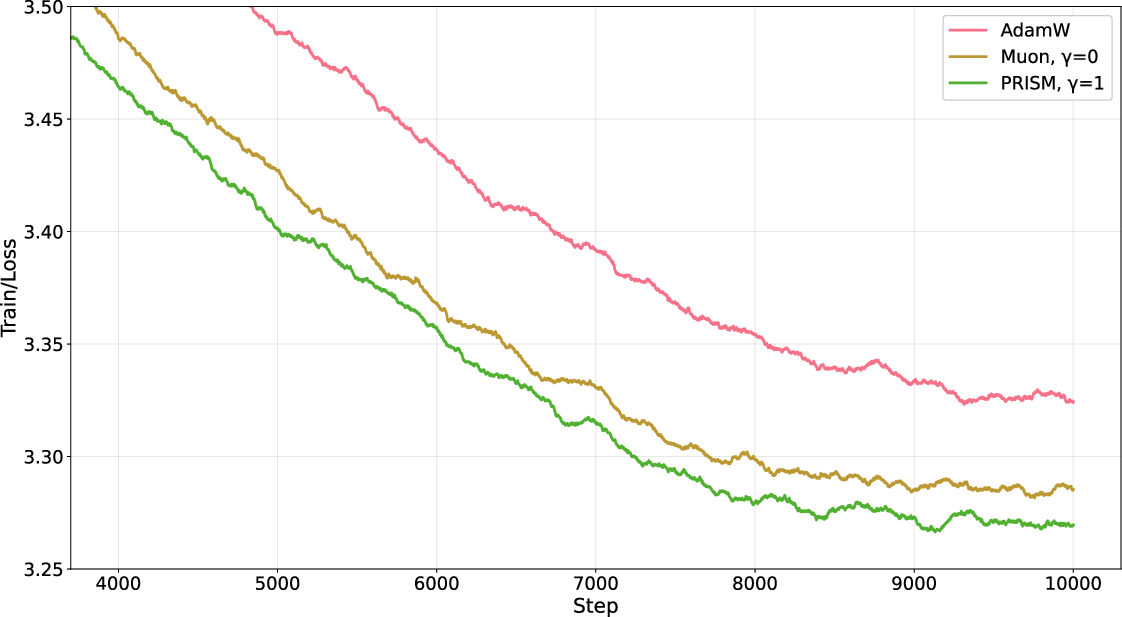
- Both Muon and PRISM beat AdamW on training speed and stability.
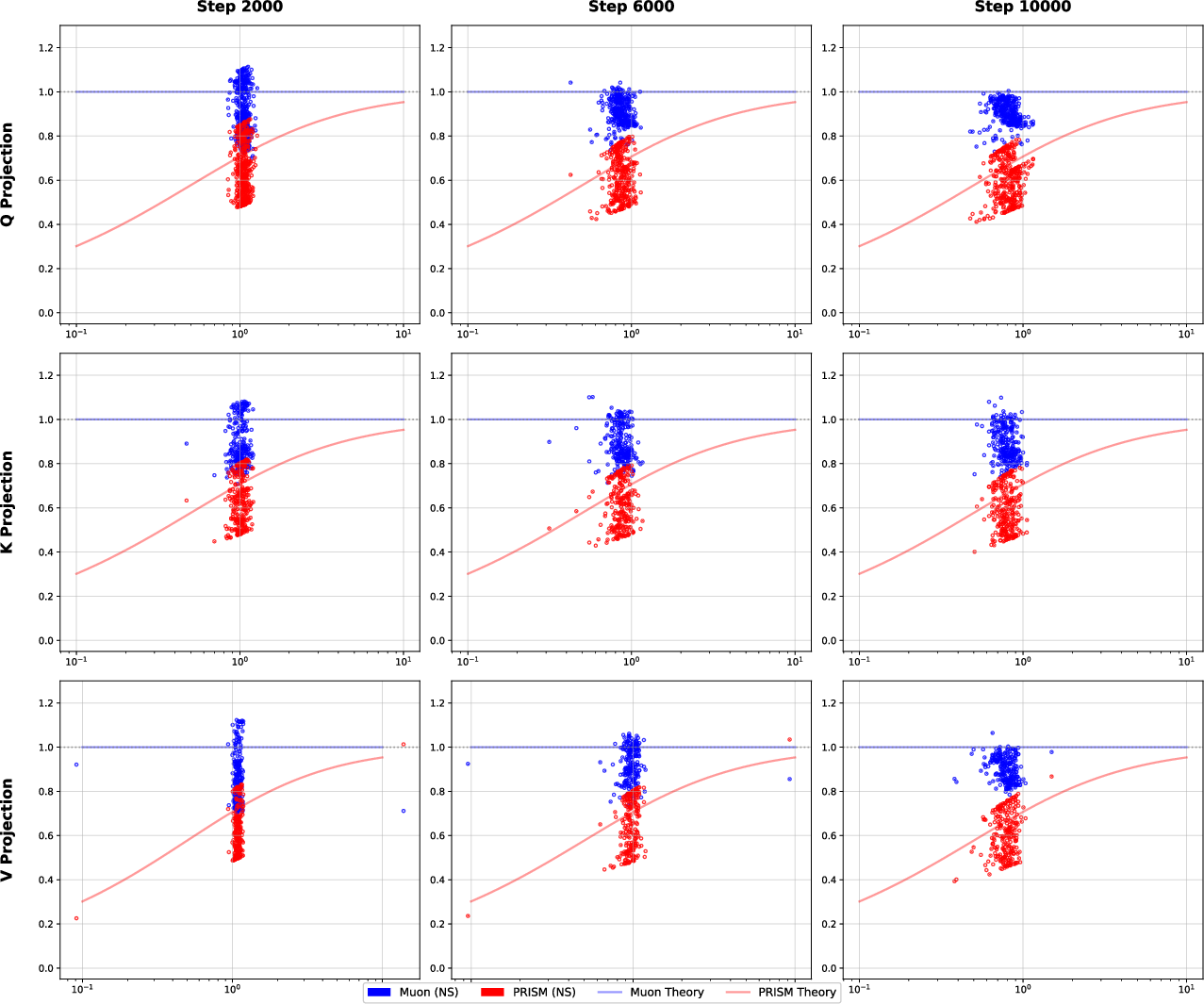
- PRISM consistently did a bit better than Muon (for example, after 10,000 steps, PRISM’s loss was about 3.269 vs. Muon’s 3.285—lower is better).
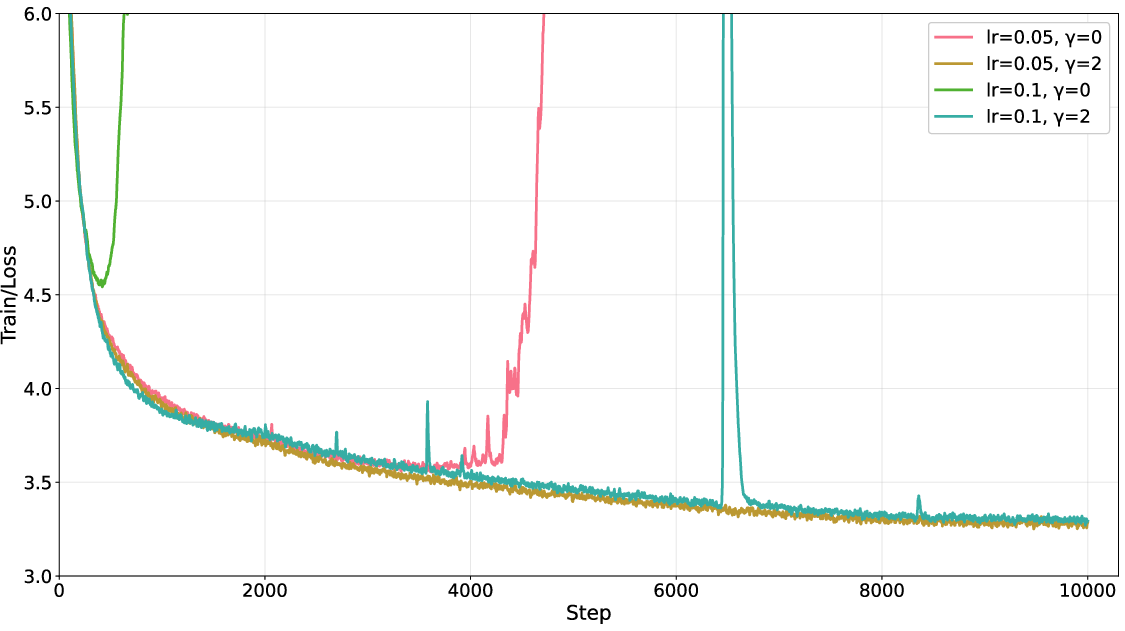
- PRISM was stable even with much higher learning rates where Muon failed (Muon “diverged” at learning rates like 0.05 or 0.1, while PRISM kept going).
- The damping strength (a setting called γ) worked well across a wide range, so PRISM didn’t need delicate tuning.
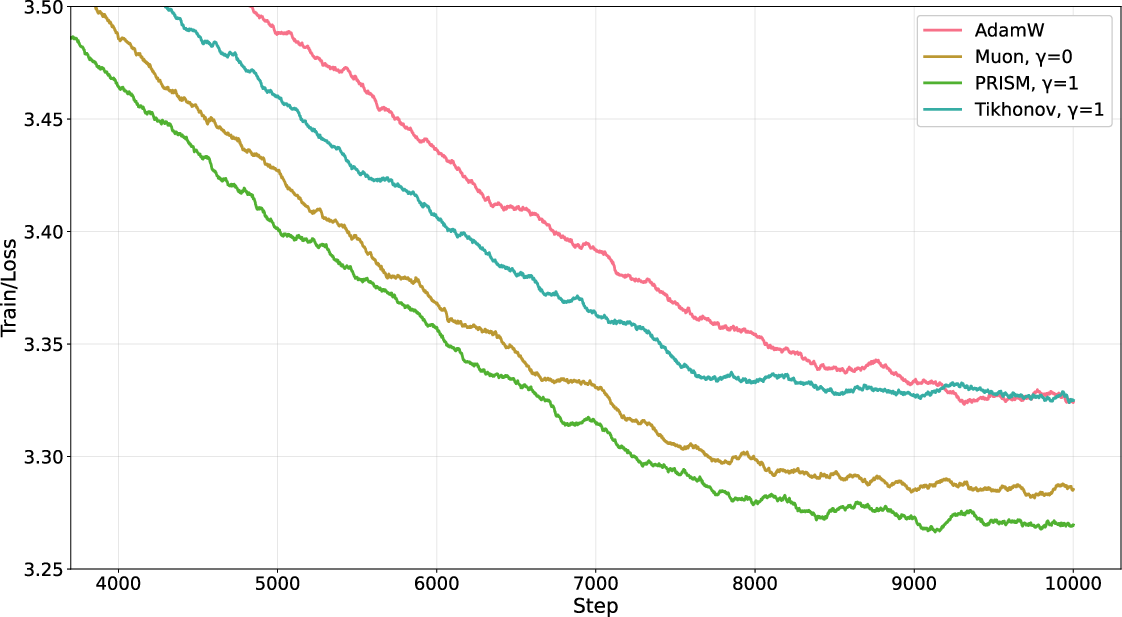
- A “simple fix” (uniform damping called Tikhonov damping) didn’t help Muon; it actually made it worse. This shows PRISM’s advantage comes from smart, direction-by-direction shaping, not just from generic damping.
Why this matters:
- Faster convergence means you reach good performance earlier.
- Better stability means fewer crashes when you push for speed.
- You get these gains without paying extra memory and with very small extra compute.
What this could mean going forward
PRISM shows a practical way to combine two worlds:
- First-order methods (fast, light, easy to scale) and
- Second-order ideas (pay attention to curvature and uncertainty).
By using the “innovation” at each step, PRISM can tell which directions are trustworthy and which are noisy. That means:
- Training large models could be faster and more robust, saving time and compute.
- We can safely try larger learning rates to speed things up.
- Future versions could add even richer (but still efficient) ways to estimate uncertainty, possibly improving speed and stability even more.
In short, PRISM is like putting a smart, automatic shock absorber into your optimizer: it keeps you moving fast on smooth roads and slows you down just enough on bumpy ones—so you reach your destination quicker and more safely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future research.
- Theoretical justification that the innovation term provides an unbiased or consistent proxy for under realistic training dynamics; quantify the bias/error as a function of the EMA momentum , non-stationarity of gradients, batch size, and stochastic noise models.
- Clarify the “low-rank” claim: under what conditions is effectively low-rank in practice (per layer and batch), and how does its empirical rank relate to model width/depth, batch size, and data distribution?
- Convergence and stability guarantees are absent: derive conditions (e.g., Lipschitz/PL assumptions, bounds on , step-size , and ) under which PRISM converges in convex and non-convex settings, and provide formal stability regions compared to Muon and adaptive methods.
- Newton–Schulz (NS) iteration details are under-specified: specify iteration counts, scaling/normalization required for NS convergence on inverse square roots of Gram matrices, error bounds per iteration, and numerically stable parameter choices (the constants a, b, c) for rectangular polar decomposition.
- Mixed-precision and numerical robustness: evaluate PRISM’s numerical stability with FP16/BF16, accumulation precision, and the impact of large/small singular values on NS convergence and the anisotropic gain.
- Memory and compute profiling: substantiate the “zero additional memory” claim with empirical GPU/TPU memory traces (including transient buffers for concatenated augmented matrices) and wall-clock throughput; quantify the overhead versus Muon and structured baselines across model sizes.
- Scope of empirical validation is narrow: extend evaluations beyond a 22M-parameter Transformer to larger LLMs (hundreds of millions to billions of parameters), CNNs/ViTs, speech, and multimodal models to test generality and scalability.
- Task breadth and generalization: include downstream evaluations (perplexity on held-out corpora, GLUE/SuperGLUE, generation quality), longer training horizons, and transfer/finetuning scenarios to assess generalization and robustness rather than only training loss.
- Statistical rigor: report multi-seed runs, confidence intervals, and statistical significance of improvements (e.g., the reported 0.016 loss gap at 10k steps); conduct sensitivity analyses across batch sizes and data orders.
- Interaction effects: ablate and analyze interactions with gradient clipping, weight decay, layer normalization, Nesterov momentum, and learning-rate schedules to isolate PRISM’s contribution and identify best practices.
- Hyperparameter policy for : develop principled or adaptive rules (per-layer, per-step, or per-direction) to set based on measured SNR, gradient variance, or curvature proxies; explore scheduling or learning .
- Dual-sided vs single-sided shaping: empirically and theoretically compare left-, right-, and dual-sided preconditioning; provide criteria for choosing augmentation dimension per layer, and quantify trade-offs in performance and cost.
- Relation to Fisher information and second-order methods: formalize the approximation quality of PRISM’s preconditioner relative to the Fisher matrix or K-FAC/Shampoo, and characterize regimes where anisotropic spectral shaping is provably beneficial.
- Benchmark against structured baselines: include strong baselines like Shampoo, K-FAC, SOAP, and Kronecker-factored spectral methods under matched compute/memory budgets; provide fair comparisons and Pareto frontiers of speed, memory, and accuracy.
- Robustness under extreme noise regimes: test PRISM under small-batch training, high-augmentation/noisy settings, curriculum changes, and non-stationary data streams (e.g., RLHF/RL) to validate the claimed SNR-aware damping.
- Layer-wise heterogeneity: investigate whether different layers (embeddings, attention, MLP, output) benefit from distinct , augmentation strategies, or preconditioning sides; assess applying PRISM to “unstructured” parameters instead of defaulting to AdamW.
- Tensors and convolutions: extend the method to tensor parameters (e.g., convolutional kernels) with appropriate spectral/tensorial norms; evaluate whether anisotropic shaping on higher-order structures improves optimization.
- Analytical characterization of the spectral gain: provide rigorous bounds on as a function of gradient statistics, and derive conditions under which PRISM avoids over-damping signal-dominated directions or under-damping noisy directions.
- Distinguishing noise from drift: analyze cases where captures distribution shift or non-stationary drift rather than pure stochasticity; propose modifications (e.g., lag-compensated innovations or second-moment accumulators) to avoid suppressing true signal.
- Practical guidance for NS implementation: detail whether PRISM uses Gram-based inverse square roots or direct polar via NS, outline numerically stable scaling (e.g., Higham-style balancing), and publish reference implementations.
- Throughput vs accuracy trade-offs: quantify how the approximately 2× increase in matrix multiplications affects training speed at scale, and whether reduced learning rate/iteration counts offset added per-step cost.
- Safety under aggressive learning rates: formalize the observed “self-recovery” in terms of adaptive damping and provide predictive diagnostics (e.g., innovation magnitude thresholds) to prevent divergence proactively.
- Energy and hardware considerations: profile PRISM on diverse hardware (A100/H100/TPUv5) and compilers (XLA, Triton), and optimize kernels for concatenation and polar decomposition to minimize energy usage and latency.
- Data/model scaling laws: study how PRISM’s benefits scale with tokens, parameters, context length, and depth, and whether anisotropic shaping changes scaling exponents relative to Muon/AdamW.
- Open-source reproducibility: release code, configs, and logs to enable independent verification of the figures/tables, including specific NS parameters, optimizer mixes, and hyperparameters.
Practical Applications
Immediate Applications
The following applications can be deployed now based on PRISM’s anisotropic spectral shaping, innovation-augmented polar decomposition, and low-overhead implementation.
- Drop-in optimizer for deep learning training pipelines (software, AI/ML)
- Use case: Replace Muon or AdamW for structured parameters in PyTorch/JAX/TF training loops to accelerate convergence and widen the safe operating region without increasing memory footprint; keep AdamW for unstructured params (embeddings, LayerNorm, biases) as in the paper’s recipe.
- Tools/workflows: Implement PRISM as an Optimizer class; right-sided preconditioning for tall matrices; gamma in [0.5, 2.0] as a robust default; Newton–Schulz (NS) iteration for polar decomposition; cosine schedule with warmup; gradient clipping around 10.0.
- Assumptions/dependencies: GPU/TPU matrix multiplication efficiency; availability of stable NS kernels; best performance on matrix-shaped weights; results validated on a 22M-parameter LM pretraining task—larger-scale generalization should be re-benchmarked.
- Faster fine-tuning and continual learning of foundation models (software, education, media)
- Use case: Reduce wall-clock time and instability during domain adaptation or task-specific fine-tuning by leveraging PRISM’s SNR-aware damping to handle noisy gradients.
- Tools/workflows: Adopt higher learning rates or shorter warmups; monitor training loss spikes; use PRISM for linear/attention/MLP layers while keeping AdamW for small/unstructured layers.
- Assumptions/dependencies: Benefits depend on gradient noise characteristics; tuning gamma and LR may be required per task/dataset.
- More aggressive learning-rate schedules with widened “safe operating region” (software, MLOps)
- Use case: Shorten experimentation cycles by safely pushing LR above typical baselines; useful for rapid prototyping and hyperparameter sweeps.
- Tools/workflows: Start with LR 2–5× higher than AdamW baselines and verify stability; keep gradient clipping; log loss spikes and recovery.
- Assumptions/dependencies: Stability depends on the dataset’s curvature/variance; the 2× matmul overhead in NS may be offset by fewer steps needed.
- Stabilizing noisy optimization regimes (robotics, reinforcement learning, finance)
- Use case: Improve stability in policy gradients, online learning, and stochastic environments by damping updates in high-variance subspaces while preserving signal directions.
- Tools/workflows: Integrate PRISM into PPO/Actor–Critic for policy networks; use gamma as a “noise sensitivity” knob; track episodic reward variance versus training stability.
- Assumptions/dependencies: Innovation term D_t must reflect meaningful deviations; RL-specific noise may require gamma and LR tuning.
- Training under mixed precision and distributed settings (HPC, cloud AI)
- Use case: Reduce FP16/BF16 instability during large-batch distributed training by leveraging PRISM’s anisotropic damping.
- Tools/workflows: Combine PRISM with ZeRO/DeepSpeed/Megatron-LM; ensure numerically stable NS iteration in mixed precision; enable loss scaling as needed.
- Assumptions/dependencies: Numerical robustness of NS at lower precision; communication overhead unaffected; verify with benchmark suites.
- SNR-aware training diagnostics and monitoring (academia, MLOps)
- Use case: Instrument PRISM-derived spectral gain (ρ_k) as a real-time health metric to detect unstable directions and guide LR/gamma adjustments.
- Tools/workflows: Log approximate ρ_k per layer via small sampled eigenspaces; build dashboards for “directional confidence” during training.
- Assumptions/dependencies: Approximate eigendecompositions or projections add small overhead; sampling strategies needed for large layers.
- Energy and cost optimization in AI training (energy, sustainability, enterprise IT)
- Use case: Reduce total compute via faster convergence or higher LR schedules without divergence; translate into lower energy usage and cost per experiment.
- Tools/workflows: Track tokens-to-target-loss and wall-clock energy (Joules) per run; integrate PRISM into standard training recipes for enterprise models.
- Assumptions/dependencies: Net savings depend on throughput versus steps; measure on target hardware; gains vary by task and scale.
- Edge and on-device training for personalization (consumer apps, IoT)
- Use case: Enable limited-memory on-device continual learning of small models by adopting a memory-neutral optimizer with improved stability.
- Tools/workflows: Use PRISM for matmul-heavy layers in tiny transformers/CNNs; microbatching; conservative gamma; fallback to AdamW for small parameters.
- Assumptions/dependencies: Sufficient local compute for NS iterations; benefit depends on task noise and model structure.
- Open-source optimizer package and benchmark suite (software, academia)
- Use case: Package PRISM into widely used libraries for broad testing and adoption; include reproducible scripts for LM/CV benchmarks and ablation of gamma, LR, and clipping.
- Tools/workflows: PyTorch/JAX/TF implementations; integration with DeepSpeed, Megatron-LM; CI tests, reproducible configs, logging and visualization of spectral metrics.
- Assumptions/dependencies: Licensing, maintenance, and community support; performance validation beyond the reported LM setting.
Long-Term Applications
These applications require further research, engineering, scaling, or validation to reach production readiness.
- Dual-sided or adaptive-sided PRISM preconditioning (software, LLM training)
- Use case: Capture both row and column curvature for heavier anisotropic shaping than single-sided PRISM; potentially close gaps to Kronecker-factored methods at lower cost.
- Tools/workflows: Dynamic selection of preconditioning side per layer; hybrid recipes for attention vs MLP projections.
- Assumptions/dependencies: Higher compute and possible additional states; algorithmic and empirical validation needed.
- Streaming low-rank covariance via matrix sketching (academia, software)
- Use case: Maintain a small, evolving sketch of gradient covariance to enhance the innovation proxy beyond rank-1; improve robustness on highly stochastic tasks.
- Tools/workflows: Randomized sketching for D_t accumulators; periodic refresh and forgetting factors; compatibility with NS-based polar decomposition.
- Assumptions/dependencies: Extra memory and compute; careful design to avoid numerical instability and overfitting to recent noise.
- Hardware and compiler support for fused PRISM kernels (semiconductors, compilers)
- Use case: Accelerate NS iteration and augmentation steps via fused CUDA/ROCm kernels and XLA/Triton codegen; reduce the ~2× matmul overhead.
- Tools/workflows: Vendor-optimized primitives; autotuning; kernel fusion with mixed-precision safety.
- Assumptions/dependencies: Requires ecosystem and vendor adoption; engineering investment; portability across accelerators.
- Auto-optimizers and meta-scheduling using SNR-aware signals (AutoML, MLOps)
- Use case: Automatically tune gamma, LR, and clipping from observed spectral gains (ρ_k) and innovation statistics; adapt schedules to phase of training.
- Tools/workflows: Controllers that read ρ_k distributions; policy learning for optimizer hyperparameters.
- Assumptions/dependencies: Reliable diagnostics; generalization across datasets/model families; safeguards against oscillatory policies.
- Federated and privacy-preserving training with variance-aware damping (healthcare, finance)
- Use case: Mitigate client heterogeneity and DP-induced gradient noise by targeted anisotropic damping; reduce divergence and clipping side-effects.
- Tools/workflows: PRISM in federated optimizers with secure aggregation; gamma scheduling per client or cluster.
- Assumptions/dependencies: Interplay with DP noise, communication constraints, and non-IID data; extensive validation required.
- Robust continual learning under distribution shift (industry, robotics)
- Use case: Maintain stability when data distributions evolve over time by dynamically suppressing high-variance directions; reduce catastrophic forgetting.
- Tools/workflows: PRISM with adaptive gamma; memory replay and regularization techniques.
- Assumptions/dependencies: Needs long-horizon studies; interactions with other continual learning strategies.
- Safety-critical model training and certification pathways (autonomous systems, medical devices)
- Use case: Use PRISM’s expanded safe operating region to reduce divergence risks; pair with formal verification of optimizer behavior.
- Tools/workflows: Safety cases that include optimizer stability evidence; spectral diagnostics as audit artifacts.
- Assumptions/dependencies: Regulatory acceptance; formal guarantees; cross-domain replication.
- Policy and standards for energy-efficient AI training (public policy, sustainability)
- Use case: Encourage reporting of optimizer efficiency metrics and adoption of variance-aware methods; inform procurement and funding priorities.
- Tools/workflows: Standardized benchmarks tracking energy per unit improvement; guidance on optimizer selection.
- Assumptions/dependencies: Independent replication; consensus across academia/industry; evolving best practices.
- Hybrid PRISM–Shampoo/Preconditioner designs (software, optimization research)
- Use case: Combine PRISM’s spectral shaping with Kronecker-factored or diagonal accumulators to better approximate curvature at modest cost.
- Tools/workflows: Layer-wise hybrids; selective application based on dimension and structure.
- Assumptions/dependencies: Complexity and memory growth; careful numerical treatment of inverse roots.
- Extensions to convolutional and tensor operators (software, CV)
- Use case: Generalize PRISM beyond simple matrix layers to structured tensors (e.g., conv kernels) while preserving anisotropic shaping.
- Tools/workflows: Reshape strategies; left/right augmentation choices tailored to tensor modes.
- Assumptions/dependencies: Algorithmic design for tensor-specific geometries; performance validation on CV, speech, and multimodal tasks.
Glossary
- ADAspectral: A spectral optimization variant combining spectral updates with adaptive scaling. "the concurrent RMSspectral and ADAspectral \cite{carlson2015preconditioned} methods straightforwardly combined the spectral update with element-wise scaling"
- Adaptive optimization: A class of methods that use gradient statistics to adjust per-parameter step sizes. "A dominant family is adaptive optimization, such as AdaGrad \cite{duchi2011adaptive}, RMSprop \cite{tieleman2012rmsprop} and Adam \cite{kingma2014adam}."
- Anisotropic spectral shaping: Direction-dependent modulation of update magnitudes in the spectral domain based on local signal versus noise. "This design transforms the update mechanism from isotropic spectral whitening to anisotropic spectral shaping."
- Cosine annealing learning rate schedule: A learning rate schedule that decays the rate following a cosine curve, often with warmup. "All experiments use a global batch size of 128 and a cosine annealing learning rate schedule with a 2000-step linear warmup."
- Fisher Information Matrix: A second-order matrix capturing curvature via expected gradient outer products, often used for preconditioning. "An ideal preconditioner, such as the Fisher Information Matrix, is based on the second moment, "
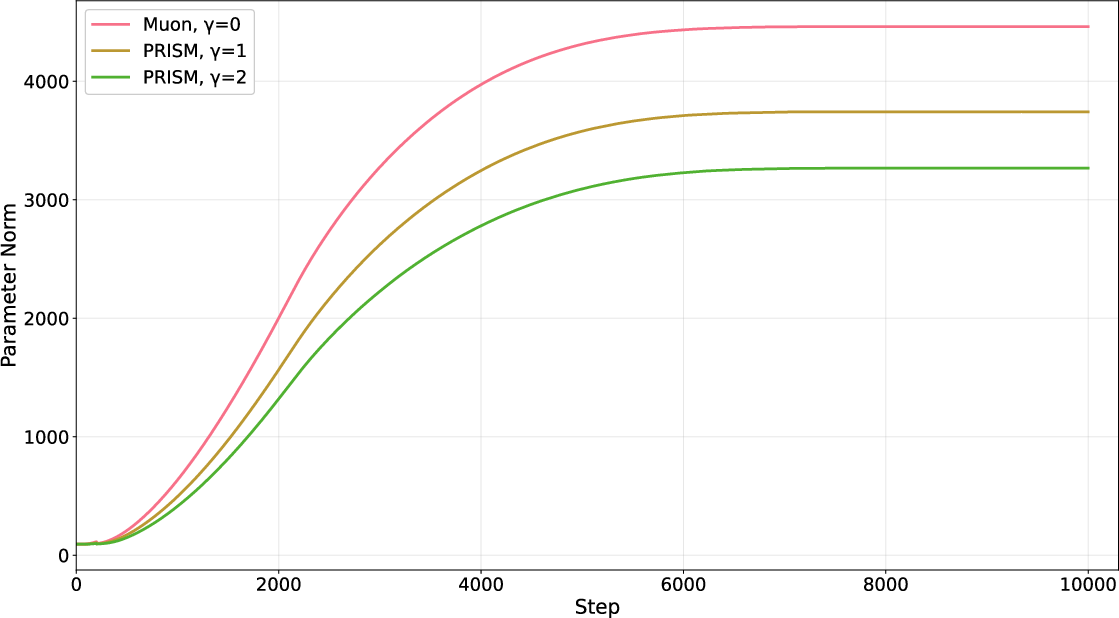
- Frobenius norm: The square-root of the sum of squared matrix entries, measuring matrix magnitude. "Figure \ref{fig:traning_norm} plots the Frobenius norm of the parameter matrix along training."
- Gram matrix: A symmetric matrix formed by inner products (e.g., MT M) summarizing correlations. "Since the innovation-augmented Gram matrix $G_{\text{aug} = \tilde{M}_t^\top \tilde{M}_t = M_t^\top M_t + \gamma^2 D_t^\top D_t$ is a real, symmetric, and positive-definite matrix"
- Innovation-Augmented Momentum: A momentum formulation extended with an innovation term to approximate covariance information. "Innovation-Augmented Momentum. At each step , we define the instantaneous innovation term "
- innovation-augmented polar decomposition: A polar decomposition applied to a momentum matrix augmented with an innovation component to inject covariance structure. "our core contribution is a mechanism we term innovation-augmented polar decomposition"
- Kronecker-factored structures: Preconditioner structures that factor curvature into Kronecker products over parameter dimensions. "Methods like Shampoo \cite{gupta2018shampoo} and SOAP \cite{vyas2024soap} extend the adaptive philosophy from diagonal to more expressive Kronecker-factored structures."
- Kronecker products: A matrix operation producing block-structured matrices, used to build structured preconditioners. "approximates the full-matrix AdaGrad using Kronecker products of rows and columns statistics."
- Left-Sided Preconditioning: Preconditioning that operates on row-space correlations by left-multiplying with a matrix function of M MT. "Left-Sided Preconditioning: To target correlations between the rows, we concatenate along the column dimension"
- Newton-Schulz iterations: An iterative method to compute matrix inverse square roots or polar factors via recursive multiplications. "Muon employs Newton-Schulz iterations to approximate the polar decomposition"
- Nesterov acceleration: A momentum variant that looks ahead to improve convergence speed over standard momentum. "we use a momentum coefficient of with Nesterov acceleration"
- Orthogonal polar factor: The orthogonal matrix U in the polar decomposition of a matrix, representing a “direction-only” component. "The Muon update is driven by the orthogonal polar factor of the momentum matrix ."
- Polar decomposition: A matrix factorization into an orthogonal factor and a positive-semidefinite factor. "Muon employs Newton-Schulz iterations to approximate the polar decomposition"
- Preconditioner: A transformation applied to gradients or updates to improve conditioning and convergence. "the Muon update direction is formed by the preconditioner derived from the momentum ."
- Quasi-second-order method: An optimizer that partially incorporates second-order (curvature) information without full Hessian costs. "This elevates the spectral descent paradigm to a quasi-second-order method that is aware of gradient uncertainty"
- Rayleigh quotient: A scalar quantity vT A v used to measure energy of A along direction v; key in eigen-analysis. "Applying the Rayleigh quotient yields a critical decomposition:"
- Right-Sided Preconditioning: Preconditioning that operates on column-space correlations by right-multiplying with a matrix function of MT M. "Right-Sided Preconditioning: This configuration, which targets correlations between the columns, is achieved by concatenating the innovation along the row dimension"
- Safe Operating Region: The range of hyperparameters (e.g., learning rates) within which training remains stable. "PRISM significantly expands the optimizer's Safe Operating Region"
- Signal-to-Noise Ratio (SNR): The ratio of signal magnitude to noise magnitude in a direction, guiding adaptive damping. "It can be expressed directly in terms of the Signal-to-Noise Ratio (SNR) for the -th principal direction"
- Spectral descent: Optimization that chooses descent directions considering the operator (matrix) nature via spectral norms. "the other refines the update direction using principles of spectral descent"
- Spectral gain: A direction-specific scaling factor determining how much an update is attenuated or passed in the spectral domain. "The update magnitude in this direction is modulated by a spectral gain, :"
- Spectral norm: The largest singular value of a matrix; a norm capturing operator magnitude. "seeks the steepest descent direction under a spectral norm"
- Spectral theorem: A result ensuring that real symmetric matrices admit an orthonormal eigen-decomposition. "the spectral theorem guarantees its eigendecomposition"
- Spectral whitening: Normalizing spectra to equalize singular values, making updates isotropic across singular directions. "Here, PRISM mimics spectral whitening optimizers like Muon"
- Steepest descent direction: The direction that maximizes loss decrease under a given norm constraint. "the steepest descent direction under a spectral norm constraint is superior to that under the Euclidean () norm."
- Tikhonov damping: A regularization technique adding a multiple of the identity to stabilize inverses or root operations. "The Tikhonov damping introduces a uniform damping term, , to the momentum Gram matrix"
Collections
Sign up for free to add this paper to one or more collections.