Unified Latents (UL): How to train your latents
Abstract: We present Unified Latents (UL), a framework for learning latent representations that are jointly regularized by a diffusion prior and decoded by a diffusion model. By linking the encoder's output noise to the prior's minimum noise level, we obtain a simple training objective that provides a tight upper bound on the latent bitrate. On ImageNet-512, our approach achieves competitive FID of 1.4, with high reconstruction quality (PSNR) while requiring fewer training FLOPs than models trained on Stable Diffusion latents. On Kinetics-600, we set a new state-of-the-art FVD of 1.3.
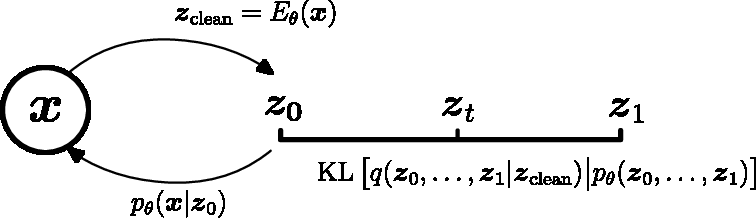















: How to train your latents")
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Unified Latents (UL), a new way to “compress” images and videos into a smart summary (called a latent) that a computer can easily work with to generate new, high-quality images and videos. UL focuses on learning these summaries so they:
- carry just the right amount of information, and
- are especially easy for powerful image/video generators, called diffusion models, to use.
The big idea is to train the compressor and the generator together, using the same kind of model (diffusion) on both sides. This makes training simpler, more stable, and more efficient.
What questions are the researchers trying to answer?
In simple terms:
- How should we compress images and videos so that a diffusion model can generate the best-looking results?
- How can we control how much detail the compressed summary holds, without guessing lots of tricky settings?
- Can we get better quality with less training compute than previous methods?
How does their method work?
First, some quick meanings in everyday language:
- Latent: Think of a latent as a short, clever summary of an image or video—like a blueprint that keeps the important parts without every tiny detail.
- Diffusion model: Imagine starting with a blurry, noisy picture and teaching a model how to gradually remove the noise to recover a clean image. That’s diffusion. It’s great at generating realistic images and videos.
- Noise level: How “foggy” or “noisy” the data is. Training is spread across different fog levels, from very foggy to almost clear.
- Bitrate: How much information the latent carries. Higher bitrate = more detail, but harder for the generator to learn; lower bitrate = simpler to learn, but might miss fine details.
What UL does:
- A shared language for both sides: UL uses diffusion models both to regularize the latent (the “prior”) and to turn it back into an image/video (the “decoder”). Because both sides use diffusion, they work together smoothly.
- Fixed tiny noise in the latent: The encoder makes a clean latent, then UL adds a small, fixed amount of noise to it. This aligns perfectly with the prior diffusion model’s “minimum noise level.” This trick simplifies the math and gives a clear, reliable limit on how many bits the latent can carry.
- Simple, controllable training: The decoder uses a gentle weighting that emphasizes important, visible structure over imperceptible tiny details. Two simple knobs control the trade-off:
- Loss factor: nudges how much detail goes into the latent versus the decoder.
- Sigmoid bias: shifts which noise levels matter more during training (like focusing more on big shapes vs. tiny textures).
- Two stages for best results:
- Stage 1: Train encoder + diffusion prior + diffusion decoder together so the latent is compact and the decoder can reconstruct well.
- Stage 2: Freeze the encoder and train a bigger “base” diffusion model on the latents with a friendly weighting. This improves final sample quality a lot.
Analogy:
- The encoder writes a blueprint (latent).
- A safety inspector (the prior) checks that the blueprint follows simple, predictable rules.
- A builder (the decoder) uses the blueprint to rebuild the full image or video.
- By adding a fixed amount of “fog” to the blueprint and matching the inspector’s rules to that fog level, everyone “speaks the same language.” This keeps the blueprint compact but useful.
What did they find, and why does it matter?
Main results:
- Images: On ImageNet at 512×512 resolution, UL achieves excellent FID around 1.4, while using fewer training FLOPs than models trained on standard Stable Diffusion latents. FID is a score for how realistic generated images look; lower is better.
- Videos: On the Kinetics-600 video dataset, UL sets a new state of the art with FVD around 1.3. FVD is like FID, but for videos.
- Efficiency: For the same amount of training compute, UL beats other methods on the quality-vs-cost curve. That means better results for less training time.
- Control: By tuning just two simple settings (loss factor and bias), you can choose how much detail to store in the latent. That lets you balance “sharp reconstructions of a particular image” versus “easier, better generation overall.”
- Robustness: UL works well across different latent sizes and shapes, and across images and videos. It’s not overly sensitive to specific design choices.
Why it matters:
- Training large image and video models is expensive. UL helps get better results with less compute.
- UL makes the trade-off between compression and generation clear and controllable, which is valuable when scaling to bigger models and datasets.
What does this mean for the future?
- Better foundations: UL shows that if you design the compressed representation specifically for diffusion models, you can train faster and generate higher-quality images and videos.
- Easy scaling: The simple controls (loss factor and bias) make it practical to choose the right latent bitrate for different model sizes and budgets.
- Broader use: Although this paper focuses on images and videos, the same idea—learning compact, diffusion-friendly latents—could extend to other data types.
- Practical note: Diffusion decoders are slower to sample than GAN decoders, so deploying UL at scale benefits from extra steps like distillation to speed things up.
In short, Unified Latents give a cleaner, more efficient way to learn the summaries that diffusion models use, leading to better-looking results with less training cost and with simple dials to tune detail versus learnability.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future work.
- Lack of a principled procedure to choose the decoder’s loss factor (c_lf) and sigmoid bias (b): hyperparameters control latent bitrate and the reconstruction–modeling split, but only empirical sweeps are provided; no algorithmic tuning rule or adaptive schedule tied to base-model capacity, dataset, or compute budget is given.
- Fixed encoder precision choice is ad hoc: the final log-SNR λ(0)=5 is selected without an analysis of how to set or adapt it across tasks, datasets, or model sizes; the impact of λ(0) on the tightness of the bitrate bound and on training stability is not characterized.
- Tightness and calibration of the “upper bound on latent bitrate” are not evaluated empirically: no experiments compare the bound to measured mutual information or compression-rate proxies, nor is the effect of retraining the prior as a weighted base model on this bound analyzed.
- Single-stage training viability is unresolved: the paper states that a two-stage approach outperforms joint training but defers details to an appendix; a clear recipe and head-to-head comparison (quality, stability, compute) for single-stage vs. two-stage pipelines is missing.
- Decoder posterior collapse avoidance lacks guarantees: increasing c_lf mitigates collapse empirically, but conditions under which collapse reappears (e.g., larger decoders, different schedules) and formal criteria to detect/prevent it are not established.
- Generalization across domains is underexplored: AE trained on ImageNet vs. internal TTI datasets shows mixed rFID behavior; systematic cross-domain transfer studies (e.g., web-scale → ImageNet/ImageNet-V2/ImageNet-Real; TTI → COCO) are not presented.
- Scaling laws are not provided: while the discussion calls for scaling laws to choose optimal latent bitrate for a given base model and compute, no empirical or theoretical scaling relation (e.g., bitrate vs. model FLOPs vs. FID/FVD) is reported.
- Compute accounting is incomplete/inconsistent: training-cost plots explicitly exclude autoencoder training cost; it is unclear whether convolution FLOPs are counted (text mentions linear and attention FLOPs); end-to-end training and inference cost (base + decoder) is not compared against baselines on equal sampling steps.
- Sampling speed–quality trade-offs are missing: no speed-quality curves (steps vs. FID/FVD) for base and diffusion decoder are shown, and comparisons to GAN decoders or distilled decoders on equivalent runtime budgets are absent.
- Diffusion decoder cost remains high and undistilled: the paper acknowledges the decoder is ~10× costlier than GAN decoders; no attempt is reported to distill the diffusion decoder (or the combined base+decoder) and measure retained quality.
- Text-to-image evaluation is limited and non-standard: results are on internal datasets with FID and CLIP scores only, without public benchmarks (e.g., COCO, PartiPrompts, DrawBench), human evaluation, guided vs. unguided comparisons, or alignment metrics beyond CLIP.
- Decoder conditioning for TTI is speculative: the claim that text conditioning in the decoder might improve alignment is not tested; ablations on conditioning pathways, cross-attention placement, or shared vs. separate text encoders are absent.
- Video scaling limits are untested: experiments use 16×128×128 clips with 5-frame conditioning; behavior at higher spatial resolutions, longer temporal horizons, and different conditioning regimes (e.g., unconditioned, text-conditioned, longer contexts) is not evaluated.
- Robustness and OOD behavior are not studied: sensitivity to corruption, adversarial perturbations, or domain shifts (e.g., ImageNet-C, ImageNet-A) for both reconstruction and generation is not assessed.
- Evaluation metric limitations are acknowledged but not addressed: rFID uses same-sample references, and FID’s high-frequency sensitivity is noted; alternative perceptual metrics (LPIPS, DISTS), human studies, or task-based evaluations are not provided.
- Theoretical justification for latent-channel insensitivity is missing: empirical results show gFID is flat across large changes in latent channels and spatial size (within ranges), but there is no analysis explaining why, or guidelines for selecting latent shape under fixed compute.
- Architectural sensitivity is only partially ablated: patching harms the base model, but systematic studies of patch size, convolutional stacks, UNet vs. ViT, UVit depth/width, and decoder/base regularization (beyond dropout) are lacking.
- Learned-variance encoders are unstable but unexplained: the paper reports instability with learned encoder variance; it remains open whether alternative parameterizations (e.g., variance floors, log-variance clipping, normalizing flows, VAEs with hierarchical posteriors) can stabilize training and improve performance.
- Prior/base weighting mismatch impacts theory: the prior is trained with unweighted ELBO to preserve the bitrate bound, but the base model is retrained with a sigmoid weighting; the theoretical implications for the bound and the encoded information allocation are not analyzed.
- Information allocation between latent and decoder is heuristic: there is no framework quantifying how much signal should reside in the latent vs. be modeled by the decoder for a given base capacity and dataset; dynamic or learned allocation mechanisms are not explored.
- Multi-modal extensions are not demonstrated: while the method is claimed to be broadly applicable (e.g., discrete decoders for text), no experiments on discrete data (text, tokens), audio, or cross-modal latents are provided.
- Fairness and comparability of baselines need strengthening: some comparisons rely on internal implementations (e.g., SD-latent baselines with architectural changes), and public baselines’ FLOPs are normalized with assumptions (e.g., token count corrections); standardized protocols or re-runs on public code are not included.
- Training dynamics of two simultaneous diffusion models are opaque: optimization difficulties are mentioned, and an L2-regularized decoder alternative is briefly tested; more systematic studies on optimizer choice, learning-rate schedules, update frequency, and alternating vs. joint updates are not provided.
- Choice of diffusion schedules is fixed: the method uses variance-preserving schedules; effects of alternative schedules (VP vs. VE, logSNR ranges, noise distributions) on bitrate bounds, stability, and sample quality are not analyzed.
- Long-term memorization and privacy are not addressed: given higher-fidelity reconstructions (higher PSNR) can encode more instance-specific details, risks of memorization or leakage (and mitigation via the bitrate control) are not evaluated.
- Compression perspective is unexplored: although a bitrate bound is claimed, comparisons to learned compression baselines (rate–distortion curves, bpp vs. PSNR/MS-SSIM) and whether UL latents serve as practical codecs are not investigated.
- End-to-end invertibility and determinism are not guaranteed: the diffusion decoder models a distribution; the trade-off between exact reconstructions (high PSNR) and generative diversity is not formalized, and knob(s) to control this at inference (e.g., temperature, guidance) are not studied.
- Sensitivity to dataset curation and high-frequency statistics is unresolved: rFID differences when training AEs on different data suggest sensitivity to subtle statistics; there is no analysis of which frequency bands or features are emphasized by the decoder weighting and how that impacts downstream generation.
- Public reproducibility is limited: key TTI datasets are internal; hyperparameter tables, training durations, and code for FLOP counting and metric computation (e.g., rFID protocol) are not provided, hindering independent verification.
Practical Applications
Practical Applications of Unified Latents (UL)
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Each item includes sectors, potential tools/products/workflows, and feasibility notes.
Immediate Applications
- UL-powered pretraining efficiency upgrades for image/video generation
- Sectors: software, media/entertainment, gaming, academia
- What to deploy: Replace Stable Diffusion (SD) latents with UL encoders + diffusion prior + diffusion decoder; adopt the two-stage training (prior+decoder, then base) with fixed encoder noise and unweighted prior ELBO; use FID/FVD vs FLOPs tracking
- Why: Better quality per training FLOP (e.g., competitive ImageNet-512 FID; SOTA Kinetics-600 FVD) and interpretable control of latent bitrate
- Dependencies/Assumptions: Access to GPU/TPU clusters; integration into existing training pipelines; diffusion decoders are more expensive to sample than GAN decoders; stage-2 base training recommended
- Budget-aware latent bitrate tuning for model training
- Sectors: MLOps, academia, AI research labs
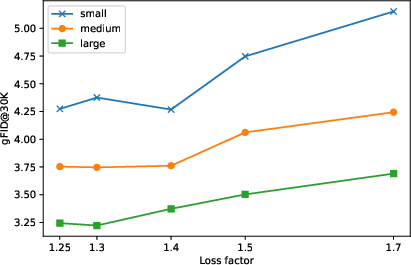
- What to deploy: Hyperparameter sweeps over decoder sigmoid bias and loss factor (c_lf) to target optimal bits-per-pixel/bpd for a given base model size; monitor gFID/rFID/PSNR and bpd to select operating points
- Why: Smaller base models benefit from lower bitrate latents; larger models tolerate higher bitrate while preserving generation quality
- Dependencies/Assumptions: Reliable metric logging (FID/FVD/PSNR/bpd); careful dataset alignment; automated sweep tooling
- Synthetic data generation at state-of-the-art video/image quality for augmentation
- Sectors: robotics, autonomous driving, AR/VR, security/surveillance, sports analytics
- What to deploy: Use UL-trained base models to produce synthetic sequences/images for data augmentation and benchmarking; leverage conditional setups (e.g., frames-in, frames-out for video)
- Why: Improved FVD/FID at lower training cost helps expand datasets affordably while preserving realistic high-frequency details where desired
- Dependencies/Assumptions: Domain gap must be managed (potential fine-tuning); label integration; guidance for text/video conditioning where applicable
- Generative dataset compression and archival using controllable UL latents
- Sectors: cloud storage, ML data management, media libraries
- What to deploy: Encode large datasets into UL latents with a target bitrate; store latents and reconstruct on demand via diffusion decoder; track bpd upper bounds as auditability for information content
- Why: Reduces storage while maintaining reconstruction quality (PSNR/rFID), with principled bitrate control via c_lf and loss weighting
- Dependencies/Assumptions: Decoder sampling cost is high; reconstructions must meet regulatory/quality requirements; performance sensitive to training dataset mismatches
- Production text-to-image pipelines with improved quality-per-budget
- Sectors: marketing/creative studios, product design, e-commerce
- What to deploy: Train UL autoencoders on in-domain text-to-image corpora; deploy base models sized to budget; tune loss factor for perceptual quality vs text alignment; use guidance at inference
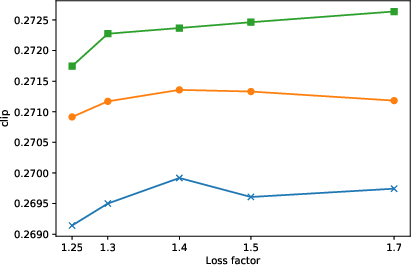
- Why: UL samples show better gFID than pixel diffusion and SD latents, with slightly better CLIP alignment; smaller models benefit most
- Dependencies/Assumptions: Dataset curation and prompt guidance; possible decoder-side text conditioning for alignment; legal/licensing compliance
- Standardized reporting of training cost and latent bitrate in model releases
- Sectors: academia, policy, open-source ML
- What to deploy: Add FLOP-based training cost, latent bpd, rFID/gFID/FVD, and PSNR to model cards and benchmarks; use UL’s interpretable bitrate bound to improve transparency
- Why: Enables fair comparisons and energy-aware decision-making across methods
- Dependencies/Assumptions: Community adoption; consistent FLOP accounting; acceptance of rFID/gFID conventions
- Edge/server split for content workflows (encode locally, decode centrally)
- Sectors: mobile apps, creator tools
- What to deploy: Lightweight UL encoder on device; upload small latent tensors; server-side diffusion decoding; optional post-processing
- Why: Reduces upstream bandwidth and storage while keeping high-quality output centralized
- Dependencies/Assumptions: On-device encoder feasibility; server compute for decoding; privacy controls and consent
- Targeted control of high-frequency detail for privacy or aesthetics
- Sectors: privacy/compliance, content moderation, design
- What to deploy: Adjust decoder weighting and c_lf to suppress or preserve high-frequency details (e.g., small text, fine textures) during reconstruction or generation
- Why: Practical control over information density can help anonymize sensitive features or achieve desired aesthetics
- Dependencies/Assumptions: Human perception may differ from FID/PSNR; require policy guidance and domain validation
Long-Term Applications
- Generative codecs for images and video (UL-based streaming)
- Sectors: media/telecom, cloud streaming, social platforms
- What to build: Standardized UL-style encoders with fast, distilled decoders for real-time playback; adaptive bitrate control using UL’s interpretable bpd
- Why: Potential to replace or complement traditional codecs with learned compression at higher perceptual quality
- Dependencies/Assumptions: Efficient decoders via distillation/acceleration; standardization and hardware support; robust QoS in diverse conditions
- Multimodal unified latents (text, audio, 3D, sensor data)
- Sectors: foundation models, AR/VR, creative tooling
- What to build: Cross-modal UL autoencoders with diffusion priors/decoders (continuous or discrete) to compress and condition across modalities in a single generative stack
- Why: Harmonized latent spaces can simplify training and enable richer multimodal generation
- Dependencies/Assumptions: New architectures and loss designs; large-scale datasets; careful ELBO weighting for discrete decoders
- Carbon-aware training and efficiency policy benchmarks
- Sectors: policy/regulation, sustainability, enterprise AI governance
- What to build: Industry benchmarks that tie reported FID/FVD to training zettaflops and latent bpd; guidelines for energy budgets and disclosure
- Why: UL provides clear levers for compute–quality trade-offs, supporting responsible AI development
- Dependencies/Assumptions: Broad stakeholder buy-in; reliable measurements and audits; legal frameworks
- Privacy-preserving synthetic data releases with controllable information content
- Sectors: healthcare, finance, public sector
- What to build: Pipelines that cap latent bitrate to reduce memorization risk; integrate differential privacy; release UL latents or generated datasets with documented bpd bounds
- Why: Enables data sharing while mitigating privacy risks
- Dependencies/Assumptions: Formal privacy guarantees required; domain-specific validation; regulatory acceptance
- Autoencoder-as-a-service (AEaaS) for domain-specific generative stacks
- Sectors: SaaS/MLOps, cloud providers
- What to build: Managed UL autoencoder/prior/decoder training and hosting; customers get latents and base models tailored to their data and budgets
- Why: Reduces integration friction and ensures expert tuning of bitrate vs quality
- Dependencies/Assumptions: Secure data handling; SLAs for reconstruction/generation quality; scalable compute
- Scaling-law-driven autotuning of latent bitrate and base model size
- Sectors: MLOps, academia
- What to build: Predictive models that select c_lf, sigmoid bias, channels/downsampling based on target budget and task; integrate with training orchestration
- Why: Automates a critical trade-off and avoids costly manual sweeps
- Dependencies/Assumptions: Robust, generalizable scaling laws across datasets and architectures
- Fast decoders via distillation or alternative generative families
- Sectors: real-time applications, edge computing
- What to build: Distilled diffusion decoders, or flow/GAN-based decoders that preserve UL’s bitrate control while reducing sampling cost
- Why: Addresses a key limitation (decoder cost) enabling broader deployment
- Dependencies/Assumptions: Maintain sample quality and avoid mode collapse; hardware-aware acceleration
- On-device generative compression for robots and IoT
- Sectors: robotics, autonomous systems, industrial IoT
- What to build: UL encoders on sensors/robots to compress streams; central servers decode for monitoring/simulation; use bitrate control for bandwidth budgeting
- Why: Reduces transmission load while preserving reconstructable details for situational awareness and training
- Dependencies/Assumptions: Resource-constrained deployments require efficient encoders; low-latency decoding; safety and reliability testing
- Federated generative training with UL latents
- Sectors: mobile, privacy-first analytics
- What to build: Clients encode data locally to UL latents; central aggregation trains base models without raw data; secure aggregation and audit trails via bpd reporting
- Why: Reduces data movement and improves privacy while enabling high-quality generative training
- Dependencies/Assumptions: Robust federated protocols; trust and compliance; consistent latent distributions across clients
- Standardized benchmarking suites and open-source references for UL
- Sectors: academia, industry consortia
- What to build: Public implementations with reproducible configs, dataset splits, and metric reporting (FID/FVD/rFID/gFID/PSNR/bpd/FLOPs)
- Why: Facilitates fair comparison and accelerates community adoption
- Dependencies/Assumptions: Funding and maintenance; legal access to datasets; contribution governance
Glossary
- Auto-encoder: A neural network that compresses inputs into latents and reconstructs them; here, it provides the latent space for diffusion modeling. "Previous work like Stable Diffusion uses a auto-encoder that is trained on another dataset than ImageNet."
- base model: The generative diffusion model trained in stage 2 on latents to produce samples, typically with reweighted objectives. "Because only a frozen encoder is required during this stage, the base model size and batch size can be much larger than in stage 1."
- bits per dimension (bpd): A measure of information content per latent dimension, indicating compression efficiency and capacity. "Additionally, because our models provide an upper bound on latent information, we report the estimated bits per dimension (bpd) in the latent space."
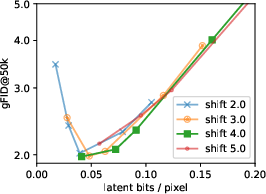
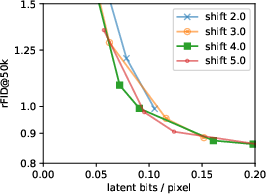
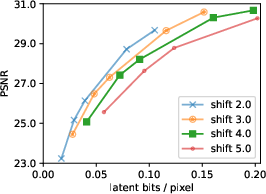
- bits/pixel: Latent bitrate measured per image pixel, used to relate information content to reconstruction and generation quality. "Image quality for various latent bitrates (FID vs bits/pixel) for a small model variant."
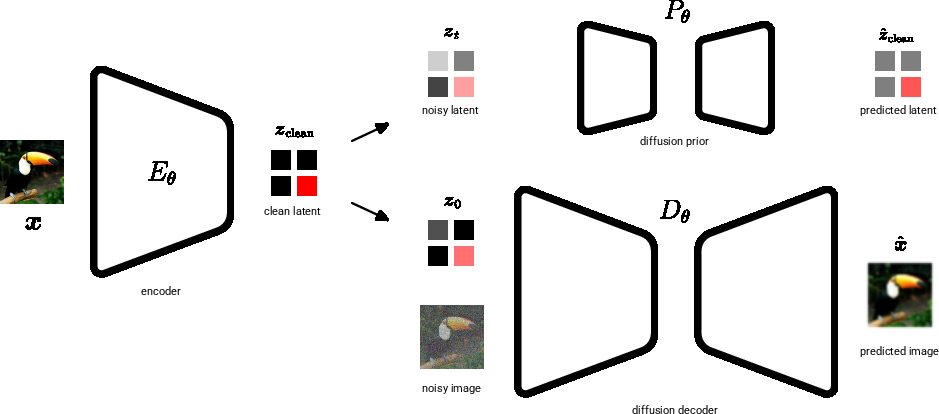
- conditioning: Providing auxiliary inputs (e.g., latents) to guide a model’s predictions. "The key distinction is that the decoder network conditions on both the noisy data and the latent ."
- decoder weighting: The noise-level-dependent weighting applied to the decoder’s diffusion ELBO to emphasize perceptually important frequencies. "Decoder weighting on in this case) and which noise levels are discounted."
- destruction process: The forward noising process in diffusion models that corrupts data according to a schedule. "Consider a data distribution and a destruction process with ."
- diagonal noise: Gaussian noise with a diagonal covariance used to sample latents at a fixed precision. "Thus, the latent is sampled using a learned mean and fixed diagonal noise."
- diffusion decoder: A diffusion model used as the decoder to reconstruct data from latents. "This is then used by a diffusion decoder to reconstruct the image."
- diffusion models: Generative models that learn to reverse a gradual noising process to sample from complex continuous distributions. "Diffusion models have become remarkably successful for image, video, and audio generation."
- diffusion prior: A diffusion model that serves as the latent prior, regularizing the encoder by modeling latents with a controlled noise level. "A diffusion prior models the path from pure noise to a slightly noisy latent ."
- distillation: A procedure to reduce sampling cost or model size by transferring knowledge to a more efficient model. "Without an additional distillation step for the decoder, the computational cost of using Unified Latents is significantly higher than a standard LDM."
- ELBO (Evidence Lower Bound): A variational objective that lower-bounds the log-likelihood, used to train latent-variable models. "Evidence Lower Bound (ELBO) on the log-likelihood when using a latent variable :"
- encoder entropy term: An additional term accounting for the entropy of the encoder distribution in diffusion-prior VAEs, often causing instability. "requires a separate encoder entropy term that introduces training instability."
- FID (Fréchet Inception Distance): A metric for image generation quality based on distributional distance in a feature space. "On ImageNet-512, our approach achieves competitive FID of $1.4$, with high reconstruction quality (PSNR) while requiring fewer training FLOPs..."
- FLOPs (floating-point operations): A compute metric counting floating-point operations, used to compare training and inference cost. "For computational cost, we count FLOPs for all linear projections and attention operations."
- forward-noised: Applying the diffusion forward process to a latent to reach a target noise level/time. "the encoder predicts a single deterministic latent $z_{\text{clean}$, which is then forward-noised to time ."
- FVD (Fréchet Video Distance): A metric for video generation quality based on distributional distance of video features. "On Kinetics-600, we set a new state-of-the-art FVD of $1.3$."
- gFID: FID computed on samples from the base model (generation FID), used to evaluate generative performance. "When sampling from a base model we denote the FID as gFID."
- GAN: Generative Adversarial Network; used in some latent diffusion approaches to train autoencoders with adversarial losses. "The original Latent Diffusion Model~\citep{rombach2022highresolution} uses a GAN-trained autoencoder with channel-bottlenecked latents..."
- gigaflops (GFlops): A measure of model complexity or cost equal to billions of FLOPs. "Model complexity (gigaflops per evaluation), ImageNet-512"
- guidance: A sampling technique (e.g., classifier-free guidance) that improves alignment or fidelity by steering generation. "text-alignment can be easily improved by applying guidance."
- Kinetics-600: A large-scale video dataset for action recognition, used here to evaluate video generation. "On Kinetics-600, we set a new state-of-the-art FVD of $1.3$."
- KL divergence (KL term): A divergence used to regularize the latent distribution toward a prior; central in VAE objectives. "Since the decoder lacks a likelihood-based loss, the weight of the KL term must be set manually, making it difficult to reason about the information content of the latents."
- latent bitrate: The information rate of the latent representation, controlling the reconstruction–generation trade-off. "we obtain a simple training objective that provides a tight upper bound on the latent bitrate."
- latent channels: The number of channels in the latent tensor, determining information capacity and reconstruction potential. "The number of latent channels therefore determines the information capacity: fewer channels yield easier-to-model latents at the cost of reconstruction quality, while more channels enable near-perfect reconstruction but require greater modeling capacity."
- Latent Diffusion Model (LDM): A diffusion framework operating in a learned latent space rather than pixels. "The original Latent Diffusion Model~\citep{rombach2022highresolution} uses a GAN-trained autoencoder..."
- latent representations: Compact encodings of data used to enable efficient modeling and sampling at higher resolutions. "We present Unified Latents (UL), a framework for learning latent representations that are jointly regularized by a diffusion prior and decoded by a diffusion model."
- logsnr schedule: A parameterization of the noise schedule using the log signal-to-noise ratio, controlling diffusion noise levels. "The level of destruction is defined by the logsnr schedule ."
- loss factor: A scalar that up-weights the decoder’s loss (equivalently down-weights the KL term) to prevent posterior collapse and tune bitrate. "For that reason, we up-weigh the decoder loss with a loss factor (which is equivalent to down-weighting the KL-term)."
- minimum noise level: The smallest noise level in the schedule; aligning the prior to it simplifies the KL and stabilizes training. "Align the prior diffusion model with the minimum noise level."
- mode-collapsing (mode collapse): A GAN training pathology where generated outputs lose diversity by collapsing to few modes. "However, the mode-collapsing nature of GAN training might help this class of models producing better looking images with better rFID scores."
- patching: Processing inputs by dividing them into patches to reduce compute and memory costs. "Our encoder and decoder models use 2x2 patching to save compute."
- posterior collapse: A VAE failure mode where a powerful decoder ignores the latents, reducing them to carrying little or no information. "Even with equal weighting, literature has shown that it is difficult to use the latent space in VAEs when the decoder is powerful, a phenomenon referred to as posterior collapse"
- PSNR (Peak Signal-to-Noise Ratio): A reconstruction quality metric comparing originals and reconstructions; higher is better. "We also use PSNR (Peak Signal-to-Noise Ratio) to measure how closely reconstructions match their originals."
- re-weighted ELBO: An ELBO modified with a noise-level-dependent weighting to favor perceptually important regions. "This re-weighted ELBO formulation has the added benefit that the weighting is invariant to the choice of schedule "
- rFID: FID computed on autoencoder reconstructions (reconstruction FID), indicating fidelity of reconstructions. "For reconstruction we use the term rFID and use the same samples from the dataset to compute reconstructions and the FID references."
- sigmoid loss: A specific weighting function over noise levels for diffusion training, typically sigmoid(λ − b). "we use the sigmoid loss \citep{kingma2023understandingdiffusion_vdmplus, hoogeboom2024sid2}, ."
- Unified Latents (UL): The paper’s method that co-trains a deterministic encoder with a diffusion prior and a diffusion decoder, linking encoder noise to prior precision. "We present Unified Latents (UL), a framework for learning latent representations that are jointly regularized by a diffusion prior and decoded by a diffusion model."
- UNet (SD): A U-Net architecture variant used in Stable Diffusion baselines for modeling latents. "The UNet (SD) baseline is a small model that uses an additional convolution stack instead of patching the SD latents."
- UVit: A U-shaped Vision Transformer architecture used as the diffusion decoder in this work. "The decoder is a UVit model \citep{hoogeboom2024sid2} with channel counts [128, 256, 512]..."
- variance-preserving noise schedule: A diffusion schedule with α2 + σ2 = 1, keeping variance constant across noise levels. "Additionally, we use for convenience."
- ViT (Vision Transformer): A transformer architecture operating on visual patches, used here for the prior and base models. "The prior model is a single level ViT with 8 blocks and 1024 channels."
- zettaflops: A unit of compute equal to 1021 FLOPs, used to measure large-scale training cost. "Training cost (zettaflops per model)"
Collections
Sign up for free to add this paper to one or more collections.