IRIS: Learning-Driven Task-Specific Cinema Robot Arm for Visuomotor Motion Control
Abstract: Robotic camera systems enable dynamic, repeatable motion beyond human capabilities, yet their adoption remains limited by the high cost and operational complexity of industrial-grade platforms. We present the Intelligent Robotic Imaging System (IRIS), a task-specific 6-DOF manipulator designed for autonomous, learning-driven cinematic motion control. IRIS integrates a lightweight, fully 3D-printed hardware design with a goal-conditioned visuomotor imitation learning framework based on Action Chunking with Transformers (ACT). The system learns object-aware and perceptually smooth camera trajectories directly from human demonstrations, eliminating the need for explicit geometric programming. The complete platform costs under $1,000 USD, supports a 1.5 kg payload, and achieves approximately 1 mm repeatability. Real-world experiments demonstrate accurate trajectory tracking, reliable autonomous execution, and generalization across diverse cinematic motions.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces IRIS, a low-cost robot arm designed specifically to move a camera smoothly for filmmaking. Instead of relying on expensive industrial machines, IRIS is 3D‑printed, costs under $1,000, and learns how to move by watching how human camera operators do it. The goal is to make professional-looking, repeatable camera shots accessible to more people, like small studios, indie creators, and researchers.
What the researchers set out to do
The paper focuses on three simple goals:
- Build a robot arm that’s strong and precise enough for camera moves but still affordable.
- Teach the robot to move the camera smoothly and intelligently by learning from human demonstrations (no complicated math programming needed).
- Test the full system in the real world to see if it can perform reliable, cinematic shots, including ones with obstacles.
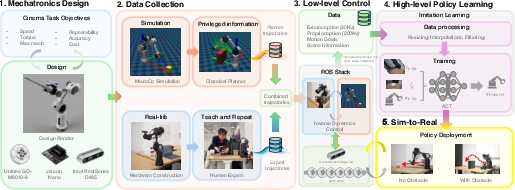
How the system works (methods and approach)
Think of IRIS like a robotic camera assistant that learns by watching a pro.
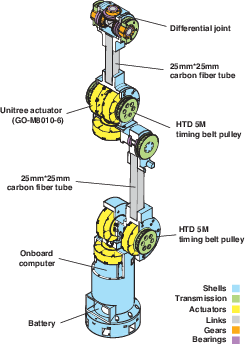
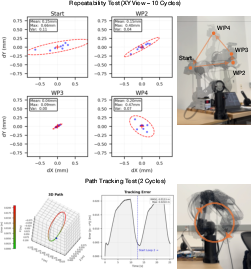
- Hardware: IRIS is a 6‑DOF robot arm (DOF means “degrees of freedom,” or how many independent ways it can move). It’s mostly 3D‑printed, uses lightweight parts, and can carry a camera up to about 1.5 kg. It’s designed so most heavy motors are near the base, making the wrist light and easier to move smoothly. “Repeatability” (how closely it can perform the same motion again) is about 1 mm—very precise for filmmaking.
- Camera and sensing: A small RGB camera (Intel RealSense) is mounted at the tip (the end effector) so the robot “sees” what it’s filming as it moves.
- Control (low-level): The motors use a method called “impedance control,” which is like giving the robot “springs and dampers” in software—firm enough to be accurate, but flexible enough to feel smooth. Commands are filtered to avoid sudden jerks.
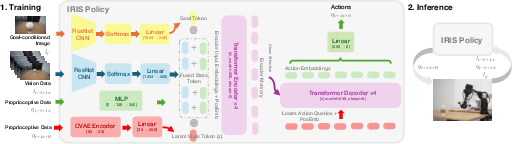
- Learning (high-level):
- Imitation learning: Instead of writing the motion rules by hand, the robot learns from recordings of a human expert guiding the camera. This is like watching a tutorial and then copying the technique.
- Visuomotor control: The robot looks at images from its camera and uses those visuals to decide how to move its joints. “Visuo” = vision (images), “motor” = movement (joints).
- Goal image: To tell IRIS what shot you want, you give it a single target photo (for example, a close‑up of a cup). IRIS then tries to move so the live camera view matches that goal image.
- ACT (Action Chunking with Transformers): Transformers are a type of AI model that’s good at understanding sequences (like text or time series). Here, the model predicts a short sequence of future joint positions—small “chunks” of action—to keep the motion steady and smooth.
- CVAE (Conditional Variational Autoencoder): This adds a “style” factor to the model. Imagine there are multiple valid ways to do a push‑in shot (fast vs. slow, slightly left vs. right). CVAE helps the model understand and represent those different styles learned from the expert.
- Together, the goal-conditioned ACT + CVAE lets the robot generate obstacle-aware, human-like camera motion directly from images, without hand-crafted geometry or maps.
- Simulation and ROS: Before real-world tests, the team built a physics simulation (MuJoCo—think of it like a very realistic game engine for robots) and used ROS (Robot Operating System) to connect all parts. This helps test and compare classic planning methods safely before trying on the physical robot.
Main results and why they matter
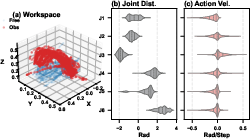
- Cost and capability: IRIS costs under $1,000, supports a 1.5 kg payload, and achieves about 1 mm repeatability. That’s impressive for a 3D‑printed, accessible system aimed at filmmaking.
- Real-world performance: In tests where the robot performs a “push‑in” shot toward a cup:
- The learned policy (ACT–CVAE) succeeded in 90% of trials, much better than a classical planner (10%), especially when obstacles were present.
- The motion was smoother than a human expert’s movements (lower “jerk,” which means fewer sudden changes). This helps avoid shaky footage.
- It tracked and framed the subject well using only vision and learned behavior, showing strong “object awareness” without needing a detailed map or hand-written rules.
- Limitations observed:
- Responsiveness: The robot’s motion is very smooth, but sometimes less reactive than a human in keeping the subject centered every moment.
- Diversity: The dataset focused mainly on a specific shot type (push‑in on a cup), so broader scenes and shot styles need more training data.
- Hardware flex: As with many 3D‑printed systems, some structural flex can appear under high loads, which could be improved with stiffer parts.
These results matter because they show you don’t need extremely expensive gear to get reliable, repeatable, cinematic movement. A learning-based, camera-aware system can deliver professional-like shots at a fraction of the cost.
What this means for the future
- Accessibility: Filmmakers, students, and researchers could use IRIS to create complex camera moves without mastering industrial robotics or spending tens of thousands of dollars.
- Ease of use: Instead of programming exact paths, you can give the robot a goal image and let it figure out a smooth, obstacle-aware route—more intuitive for creative work.
- Next steps:
- Stronger hardware to reduce flex and handle heavier payloads.
- Larger, more varied datasets (different objects, scenes, and shot types) so the robot can learn more styles, like crane moves, pans, and compound shots.
- Better real-time responsiveness while keeping the smoothness.
In short, IRIS points toward a future where smart, low-cost robots can learn cinematic movement from humans and make high-quality camera work much more accessible.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is phrased to be actionable for future research.
- Hardware repeatability and accuracy are only reported for position; orientation (pan/tilt/roll) repeatability, steady-state orientation error, and orientation jitter across the workspace remain unmeasured.
- Structural stiffness, vibrational modes, and belt/differential backlash are not quantified; no frequency response or modal analysis is provided to relate mechanical flexion to observed trajectory smoothness and jitter.
- Payload claims (1.5 kg) are not validated with a representative cinema camera and lens (e.g., mirrorless + gimbal); effects of heavier payloads on tracking accuracy, repeatability, and safety are unknown.
- End-effector vibration and motion-induced blur with real optical systems (variable focal lengths, heavier lenses) are not characterized; no camera- or lens-specific stabilization integration (e.g., gimbal, isolation mounts).
- Long-duration reliability (thermal behavior, actuator heating, battery endurance, mechanical wear, drift) is not evaluated; no continuous-operation stress tests or hour-scale stability studies.
- Acoustic noise and operational ergonomics (important on sets) are not measured; potential impact of BLDC and belt transmissions on sound stages is unclear.
- Depth sensing from the RealSense D435 is unused in control; whether incorporating depth (or RGB-D fusion) improves obstacle awareness, generalization, and safety is unexplored.
- Visual perception is limited to a frozen ResNet-18 trained on ImageNet; the impact of domain adaptation, fine-tuning, or specialized cinematic features (lighting, motion blur, low light) is not analyzed.
- Robustness under challenging visual conditions (low light, strong highlights, reflections, clutter, partial occlusions, changing FOV, moving subjects) remains untested.
- The policy is controlled at 10 Hz while low-level impedance runs at 200 Hz; the trade-off between control rate, smoothness, and responsiveness (e.g., SRR) is not systematically explored.
- Hyperparameters for deployment (EMA smoothing, clamp limits, lookahead) are not ablated; their effects on responsiveness, safety, and aesthetic smoothness are unknown.
- Numeric IK solver behavior near kinematic singularities and at workspace boundaries is not analyzed; no metrics on solver stability, convergence rate, or failure modes under aggressive maneuvers.
- Success criteria rely on an ad hoc visual alignment threshold (); sensitivity of success rates to thresholds and embedding choices is unexamined.
- Cinematic quality metrics are simplistic (jerk, pixel-center error, SRR); no evaluation of composition (rule of thirds), framing stability, horizon alignment, pacing/easing profiles, or shot aesthetics preferred by camera operators.
- Dataset diversity is limited (single object: cup; two scene variants; one shot type: push-in); generalization to other subjects, environments, and shot styles (pan, tilt, crane, orbit, compound moves) is not demonstrated.
- Multi-goal or keyframe sequencing (time-parametrized shot plans) is unsupported; how to encode and execute long-horizon, multi-stage cinematic sequences remains open.
- The CVAE’s latent “style” is not used at inference (set to z=0); whether sampling or conditioning the latent enables controllable style variation (e.g., pace/ease-in/out, framing preferences) is untested.
- The comparison lacks strong baselines for closed-loop visual servoing (IBVS/PBVS), model predictive control with image-based objectives, and modern diffusion/transformer policies; fairness and completeness of baselines are limited.
- Planner baselines use offline joint-space RRT* with simulated obstacles; no evaluation of map-based geometric planners with accurate environment models or real-time re-planning in closed loop.
- Obstacle tests are static and simple (single cube); performance against dynamic obstacles, multiple obstacles, and partial occlusions is not evaluated.
- Safety is limited to timeouts and clamps; no predictive safety filtering, formal verification, or certified collision handling, especially in human-populated sets.
- Homing with incremental encoders introduces startup dependency; robustness to encoder drift, loss of reference, or power cycles mid-shot is not studied.
- Sim-to-real fidelity is qualitatively described; quantitative validation of the MuJoCo model (parameter identification, tracking of step responses, distributional mismatch) and its predictive power for policy transfer is lacking.
- Latency is reported for inference only; end-to-end system latency (sensor capture, ROS sync, preprocessing, IK, command transmission) under load is not measured, nor its impact on shot timing.
- Control uses absolute joint targets; while incremental outputs failed, root causes (compliance, estimator drift) are hypothesized but not diagnosed via controlled experiments.
- The learned policy’s lower SRR vs. human experts suggests responsiveness limits; strategies to improve subject retention without sacrificing smoothness (e.g., adaptive smoothing, hybrid controllers) are not explored.
- No failure-case analysis is provided (e.g., collision, lost target, poor alignment); structured error taxonomy and recovery strategies (re-plan, hold, retract) are absent.
- Reproducibility and cost assumptions depend on educational pricing for actuators; sensitivity of BOM cost, part availability, and print tolerances across sites is not assessed.
- Calibration workflows (camera intrinsics/extrinsics, wrist differential, encoder offsets) are described but not benchmarked for accuracy and repeatability; impact of calibration errors on framing is unknown.
- Orientation control relative to subject (maintaining horizon, roll constraints, parallax management) and camera optical parameters (FOV changes, zoom, focus pulls) are not integrated into the control objective.
- Human-in-the-loop interfaces (goal specification UX, shot preview, correction tools) are unspecified; how operators author, adjust, and validate shots with IRIS is left open.
- Real-world deployment on embedded compute (Jetson Nano) is claimed but not evaluated; performance, latency, and reliability on resource-constrained hardware are unknown.
- Energy use, battery life, and mobile/untethered operation on set are not characterized; feasibility of long takes and high-speed moves on battery remains unclear.
- No quantitative comparison of IRIS’s motion smoothness and repeatability to commercial cinema robots under matched payload and trajectory conditions.
- Legal and safety compliance for on-set use (e.g., standards, certifications, emergency stops) are not addressed; requirements and gaps for professional deployment remain unknown.
Practical Applications
Immediate Applications
The following applications can be deployed with the IRIS system as described in the paper, leveraging its <$1,000 hardware, ROS/MuJoCo stack, and goal-conditioned ACT–CVAE visuomotor policy trained from human demonstrations.
- Low-cost motion-control for independent filmmakers and content creators — sector: media/entertainment, advertising, social media; tools/workflows: 3D‑printed IRIS arm, Intel RealSense camera, ROS nodes for bring-up/calibration, goal-image driven shot specification, quick “teach-by-demonstration” data capture (minutes of demos), offline training, on-set deployment; assumptions/dependencies: 1.5 kg payload (mirrorless/small cinema cameras), stable mounting/base, basic safety practices (keep-out zones), GPU/Jetson for inference, limited shot repertoire initially (push-in, simple arcs), requires environment-specific demonstrations.
- Repeatable product videography and e-commerce content automation — sector: advertising, retail/e-commerce; tools/workflows: repeatable multi-pass shots for lighting and background variants, shot templates saved as policies, fallback “teach-and-repeat” mode, MuJoCo previsualization to validate collision-free paths before filming; assumptions/dependencies: controlled tabletop scenes, consistent lighting and object placement, ROS-based calibration each session, operator oversight to manage obstacles.
- VFX multi-pass alignment in small studios — sector: visual effects, post-production; tools/workflows: log and replay joint trajectories with sub-millimeter repeatability, goal-image nudging to correct final framing, integration into shot databases; assumptions/dependencies: rigid camera/lens setup with fixed focal length, careful homing each session, belt tension and mechanical maintenance to reduce flexion, current payload/speed constraints vs. high-speed VFX rigs.
- Micro-studio live streaming and broadcast framing assistance — sector: broadcast, creator economy; tools/workflows: goal-image set by “last best frame,” closed-loop adaptation to maintain framing, optional object detection (YOLOv8 Nano) for centroid tracking, on-the-fly policy swapping per segment; assumptions/dependencies: single-subject scenarios, safe arm positioning away from talent, SRR lag vs. human operator (policy smoothness trades responsiveness), latency <10 ms on modest GPU.
- Robotics/AI education and lab testbed — sector: education, academic research; tools/workflows: hands-on curricula in ROS, MuJoCo, joint impedance control, goal-conditioned imitation learning with ACT, ablation experiments on action spaces and modalities; assumptions/dependencies: campus safety protocols, access to commodity GPUs, periodic hardware maintenance, faculty TA support for setup and training.
- Visuomotor imitation learning benchmarking — sector: academia/software research; tools/workflows: use IRIS datasets, metrics (visual alignment, jerk, framing error, SRR), and open-source code to benchmark transformer/diffusion IL methods and sim-to-real transfer; assumptions/dependencies: reproducible training splits, standard camera/lens, consistent workspace geometry.
- Automated documentation and inspection filming in labs/workshops — sector: industrial/lab operations; tools/workflows: repeatable camera paths to record procedures, time-lapse, and comparison shots, shot libraries per station; assumptions/dependencies: benign environments (no heavy machinery), clear obstacle maps or human demos that include avoidance, arm anchored securely.
- Hobbyist home content capture (cooking, DIY, time-lapse) — sector: daily life/consumer; tools/workflows: smartphone or action-camera mount, simple UI that selects a goal image and records one or two demos, periodic replay for series content; assumptions/dependencies: light payloads only, parental supervision in households, simplified software installers (preconfigured ROS nodes) to lower setup friction.
Long-Term Applications
The following applications are plausible extensions that require further research, scaling, and productization (e.g., broader datasets, hardware stiffening, additional safety systems, and richer policy capabilities).
- Professional cinema-grade motion control at scale — sector: media/entertainment; tools/products/workflows: higher-stiffness chassis, higher payload gimbals/lenses, redundant sensing, certified safety filters, on-set UI for shot authoring via sequential goal images and natural-language cues; assumptions/dependencies: mechanical redesign for >10 kg payloads, compliance with studio safety standards, collaborative operation with grips and camera department.
- Complex shot sequencing and autonomous “shot assistant” — sector: media/entertainment, software; tools/products/workflows: multi-goal sequencing (compound dolly, crane, pan), constraint-aware planners mixed with learned policies, director’s tablet app to storyboard goal frames, runtime retiming and pacing controls; assumptions/dependencies: larger and more diverse demonstration datasets, multimodal goal conditioning (text + image), robust obstacle perception and dynamic avoidance.
- Multi-robot volumetric capture and synchronized rigs — sector: media/entertainment, XR; tools/products/workflows: network-synchronized IRIS units around a set, shared timing and calibration, automated multi-pass capture for virtual production and photogrammetry; assumptions/dependencies: precise timecode sync, cross-robot calibration tools, collision coordination, studio-grade safety protocols.
- Integration with virtual production (LED volumes, Unreal Engine) — sector: media/entertainment, software; tools/products/workflows: plugin bridging IRIS trajectories with virtual cameras and digital doubles, live goal-image generation from previs; assumptions/dependencies: tight latency budgets, standardized APIs with game engines, reliable tracking markers.
- Medical imaging and endoscopic camera assistance (method transfer) — sector: healthcare; tools/products/workflows: adapt goal-conditioned visuomotor control to camera/navigation in minimally invasive procedures, procedure-specific demonstrations; assumptions/dependencies: specialized sterilizable hardware, sub-millimeter accuracy with higher stiffness, regulatory approval (FDA/CE), clinician-in-the-loop safety constraints.
- Industrial inspection and quality assurance camera automation — sector: manufacturing; tools/products/workflows: learned repeatable camera paths around complex assemblies, dynamic obstacle handling on lines; assumptions/dependencies: ruggedized hardware, integration with MES/PLCs, safety cages/light curtains, retraining per product line.
- Consumer productization (plug-and-play camera robot) — sector: consumer electronics; tools/products/workflows: turnkey kit with mobile app, cloud training, presets for popular shots, voice commands (“push-in on the plate”), Home/Studio safety features; assumptions/dependencies: simplified onboarding and calibration, reliable customer support, cost control at scale.
- Generalizing the IL framework to broader robot tasks — sector: robotics/software; tools/products/workflows: apply goal-conditioned ACT to non-camera tasks (e.g., gentle manipulation, studio lighting rigs, boom arm control), shared datasets and benchmarks; assumptions/dependencies: task-specific sensors, richer multimodal goals, domain-specific safety filters.
- Standards and policy for robots on set — sector: policy/regulation; tools/products/workflows: industry guidelines for low-cost robotic camera systems (risk assessment, training, insurance), certified safety filters in controllers; assumptions/dependencies: cross-industry working groups, incident reporting frameworks, compliance testing labs.
- STEAM outreach and global accessibility — sector: education/policy; tools/products/workflows: open hardware kits for schools and makerspaces, grants for community studios, curricula on safe robot cinematography; assumptions/dependencies: funding programs, localized support materials, low-friction distribution channels.
Common assumptions and dependencies that affect feasibility
- Hardware limits: current payload (1.5 kg), stiffness/flexion under high torque, belt-driven transmissions require maintenance; scaling up needs redesign.
- Safety: on-set and consumer use require risk assessments, physical keep-out zones, fail-safes (timeouts, safety filters), and operator training.
- Data and generalization: policies trained on scene-specific human demos; broader robustness needs diverse datasets covering more shot types and environments.
- Compute and software: ROS familiarity, calibration/homing at startup, GPU or Jetson-class device for low-latency inference; desire for simplified UI to reduce technical overhead.
- Environment control: best performance in structured spaces (tabletop sets, micro-studios); dynamic, cluttered environments demand stronger perception and avoidance.
- Reliability: regular mechanical checks (belt tension, joint wear), stable mounting/base, consistent camera/lens setups to maintain repeatability.
Glossary
- 6-DOF: Six degrees of freedom; a manipulator or robot arm that can move in three translational and three rotational axes. "a task-specific 6-DOF manipulator"
- A: A graph-search algorithm for optimal path finding using heuristics. "A, RRT*, CHOMP, and TrajOpt"
- Ablation studies: Experimental analyses that remove or alter components to assess their contribution to performance. "We validate our architecture design through two ablation studies, with 10 trials for each policy."
- Action Chunking with Transformers (ACT): A transformer-based policy architecture that predicts temporally extended action sequences. "By employing a goal-conditioned adaptation of Action Chunking with Transformers (ACT), IRIS learns to execute object-aware, perceptually smooth trajectories"
- Armature inertia: The effective inertia of motor components reflected at the joint, influencing dynamic response. "Joint parameters (damping, armature inertia, friction) are tuned"
- Back-drivable: Property of an actuator or mechanism that allows it to be easily driven by external forces, enabling compliant interaction. "back-drivable, low-impedance dynamics."
- Backlash: Mechanical play between mating components (e.g., gears) that introduces positioning error. "introduce cogging, backlash, and limited control bandwidth."
- Belt-driven architecture: A transmission approach using belts to relocate or couple actuation, often reducing distal inertia. "a QDD, belt-driven architecture"
- BLDC: Brushless DC motor, offering high efficiency and precise control. "Unitree GO-M8010-6 BLDC motors"
- Capsule-based collision checking: Collision detection using capsule primitives to approximate robot links or obstacles. "capsule-based collision checking (7.5\,cm safety radius)"
- CHOMP: Covariant Hamiltonian Optimization for Motion Planning; a trajectory optimization method for smooth, collision-free paths. "A*, RRT*, CHOMP, and TrajOpt"
- Closed-loop visuomotor control: Control that continuously uses visual feedback to correct motion during execution. "the advantage of closed-loop visuomotor control."
- Conditional variational autoencoder (CVAE): A generative model that learns latent variables conditioned on inputs to capture multi-modal behaviors. "augmented with a conditional variational autoencoder (CVAE)."
- Cross-attention: A transformer mechanism that lets the decoder attend to encoder outputs to condition predictions. "via cross-attention."
- Daisy-chained: A wiring topology where multiple devices are connected in series on a single bus. "six actuators daisy-chained over a half-duplex RS-485 bus"
- DAgger: Dataset Aggregation; an imitation learning algorithm that mitigates distribution shift by iteratively collecting on-policy data. "dataset aggregation (DAgger)"
- Damped least squares: A regularized inverse method for solving ill-conditioned systems, common in IK near singularities. "via damped least squares"
- DETR-style: Following the Detection Transformer paradigm that uses transformers for set prediction. "a DETR-style ACT"
- Differential wrist: A wrist mechanism where two motors combine outputs to control multiple rotational axes. "a differential wrist."
- End effector: The tool or device at the end of a robot arm that interacts with the environment. "An end-effector-mounted camera captures a target object"
- Exponential moving average (EMA): A smoothing filter that weights recent values more heavily to reduce noise. "an exponential moving average (EMA) filter"
- Field-oriented control (FOC): A control strategy for AC/BLDC motors that regulates torque and flux in a rotating reference frame. "integrated field-oriented control (FOC)."
- Forward kinematics: Computing the end-effector pose from joint states. "forward kinematics solver"
- Homing sequence: An initialization routine to establish absolute references from incremental encoders. "a startup homing sequence is required"
- Impedance control: A control strategy that regulates the dynamic relationship between motion and force to achieve compliant behavior. "joint-space impedance control"
- Inverse dynamics: Computing the joint torques required to follow a desired motion. "executes inverse-dynamics control"
- Inverse kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "inverse kinematics (IK) solutions."
- Inverse reinforcement learning (IRL): Infers a reward or cost function from expert demonstrations. "Inverse reinforcement learning (IRL) and guided cost learning extend this paradigm"
- Jacobian: The matrix relating joint velocities to end-effector velocities, central to differential kinematics. "We use a numerical Jacobian-based IK solver"
- Jerk: The third derivative of position with respect to time; measures rapid changes in acceleration affecting motion smoothness. "Measures physical stability via the magnitude of the end-effector jerk"
- KL divergence: A measure of difference between probability distributions used to regularize variational models. "using KL divergence"
- Latent variable: An unobserved variable capturing hidden factors or styles in a generative model. "we introduce a latent variable "
- Li-Po battery: Lithium polymer battery; lightweight, high-discharge power source. "3S Li-Po battery (24\,V nominal)"
- Low-pass filter: A filter that attenuates high-frequency components to smooth signals. "first-order low-pass filter ()"
- MuJoCo: A physics engine for accurate simulation of articulated systems. "A high-fidelity MuJoCo simulation of IRIS is developed"
- Open-loop planner: A planner whose trajectory is executed without feedback corrections during run time. "While the open-loop planner fails against unmodeled sim-to-real gap"
- Partially observable Markov decision process (POMDP): A decision process where the agent only has partial observations of the underlying state. "goal-conditioned partially observable Markov decision process (POMDP)."
- Penultimate layer: The layer just before the final output layer in a neural network, often used for feature embeddings. "from the penultimate layer of a pre-trained ResNet-18"
- Planetary reduction: A compact gear train providing torque amplification via a planetary arrangement. "a 6.33:1 planetary reduction"
- Potential-field planner: A planning method that treats goals and obstacles as attractive/repulsive fields to guide motion. "A classical potential-field planner generates collision-free reference paths"
- Proprioception: Internal sensing of the robot’s joint states (e.g., positions, velocities). "then fuse with proprioception into temporal tokens."
- Quasi-Direct Drive (QDD): Low gear-ratio, high-torque actuation enabling backdrivability and low impedance. "To address the conflicting requirements of high-speed and high accuracy, we use Quasi-Direct Drive (QDD)"
- Receding-horizon strategy: Executing only the first step of a predicted trajectory and replanning at each time step. "We employ a receding-horizon strategy"
- Reflected inertia: Apparent inertia seen at the output due to upstream masses/transmissions. "To reduce reflected inertia at the end effector"
- ResNet-18 backbone: A convolutional neural network used as a fixed feature extractor. "A frozen ResNet-18 backbone encodes the observation history and goal image"
- Robot Operating System (ROS): A middleware framework for robot software development and communication. "We develop a custom ROS package for IRIS"
- Root mean square error (RMSE): A standard metric for average magnitude of error over time. "the root mean square error (RMSE)"
- RRT: Rapidly-Exploring Random Tree Star; an asymptotically optimal sampling-based motion planner. "A, RRT*, CHOMP, and TrajOpt"
- RS-485: A serial communication standard supporting multi-drop, long-distance links. "RS-485 bus"
- Sim-to-real transfer: Deploying policies trained or validated in simulation on physical hardware with minimal performance loss. "enabling smooth, obstacle-aware cinematic motion via sim-to-real transfer."
- Spatial Softmax: An operation that converts spatial feature maps into coordinate-aware feature representations. "and Spatial Softmax to preserve spatial coordinates"
- Teach and Repeat: A replay method that repeats recorded expert trajectories without adaptation. "Human Expert Replay, which utilizes a direct \"Teach and Repeat\" replay of expert demonstrations"
- Time-parameterized splines: Smooth trajectories parameterized by time for motion execution. "time-parameterized splines"
- TrajOpt: Trajectory optimization framework that solves for collision-free, smooth paths via convex optimization. "A*, RRT*, CHOMP, and TrajOpt"
- Transformer decoder: The decoding component in a transformer that generates sequences conditioned on encoded context. "A transformer decoder predicts the 15-step joint trajectory"
- Visuomotor control: Control that maps visual inputs directly to motor commands. "visuomotor control"
- YOLOv8: A real-time object detection model used for target tracking and framing metrics. "via YOLOv8 (Nano)"
- Zero-torque actuation mode: A mode where motors apply no torque, allowing manual guidance of the arm. "in the zero-torque actuation mode."
- Kinematic coupling: Interdependence between translational and rotational motions due to mechanism geometry. "reducing kinematic coupling and allowing faster and more stable inverse kinematics (IK) solutions."
- Cogging: Torque ripple in motors or transmissions due to magnetic or gear tooth interactions. "introduce cogging, backlash, and limited control bandwidth."
- Control bandwidth: The range of frequencies over which a control system can effectively track commands or reject disturbances. "limited control bandwidth."
- Differential wrist transformation: The kinematic mapping from dual motor inputs to wrist pitch/roll outputs. "and does the differential wrist transformation."
Collections
Sign up for free to add this paper to one or more collections.