- The paper introduces a unified model architecture using a modality-specific mixture-of-experts strategy that integrates audio and video tokens via shared self-attention to enhance cross-modal interaction.
- It employs Temporal-Aligned Rotary Position Encoding (TA-RoPE) to enforce precise temporal synchronization, effectively mitigating misalignment challenges.
- The proposed Audio-Video Direct Preference Optimization (AV-DPO) leverages human and synthetic feedback to refine quality and consistency, achieving superior benchmark performance.
JavisDiT++: Unified Modeling and Optimization for Joint Audio-Video Generation
Introduction and Motivation
Joint audio-video generation (JAVG) remains a core artificial intelligence challenge, crucial for scenarios that require the synthesis of temporally synchronized, semantically rich video with coherent audio given textual descriptions. Existing open-source systems for JAVG exhibit significant limitations compared to proprietary systems (e.g., Veo3), notably in generation quality, temporal alignment, and alignment with human preferences. Addressing these gaps, "JavisDiT++: Unified Modeling and Optimization for Joint Audio-Video Generation" (2602.19163) introduces a scalable and efficient architecture that advances JAVG by tightly integrating model design, synchronization mechanisms, and preference-driven optimization, achieving state-of-the-art performance on several rigorous benchmarks.
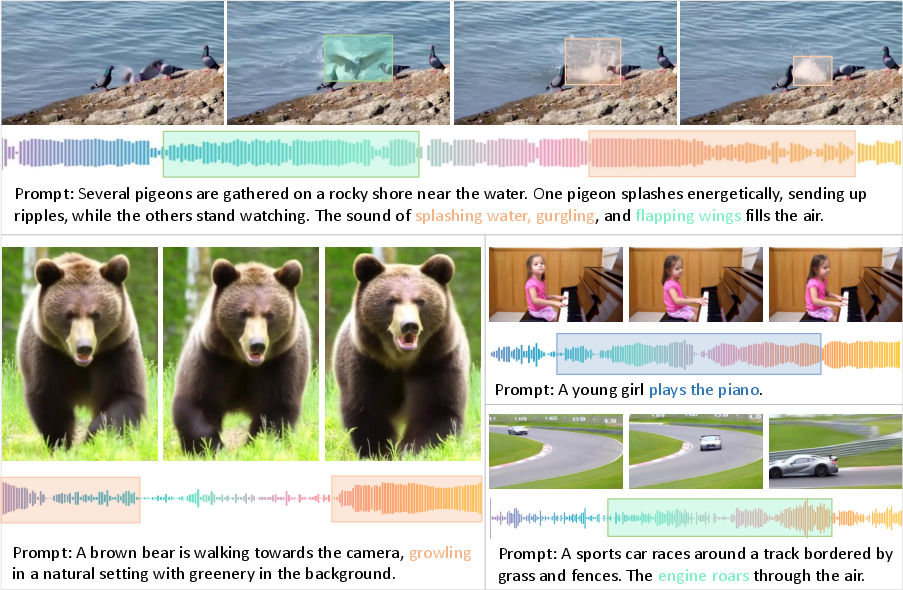
Figure 1: Realistic and diversified joint audio-video generation examples by JavisDiT++.
Model Architecture and Temporal Synchronization
JavisDiT++ presents a unified architecture grounded in a modality-specific mixture-of-experts (MS-MoE) strategy. Unlike previous dual-stream or asymmetrical approaches, JavisDiT++ concatenates video and audio tokens, passing them through shared self-attention layers for cross-modal interaction. Modality-specific FFNs follow, enabling intra-modal feature aggregation and preventing modality interference during feature transformation. This design not only preserves backbone model efficiency (e.g., from Wan2.1-1.3B) but simultaneously expands representational capacity without increasing per-token computational cost.
The model employs frozen VAEs for both modalities: the Wan2.1 video VAE and the AudioLDM2 audio VAE. By maintaining these pretrained VAEs and only training specific modular heads and LoRA-injected adapters, transfer learning is maximally exploited with minimal parameter updates.
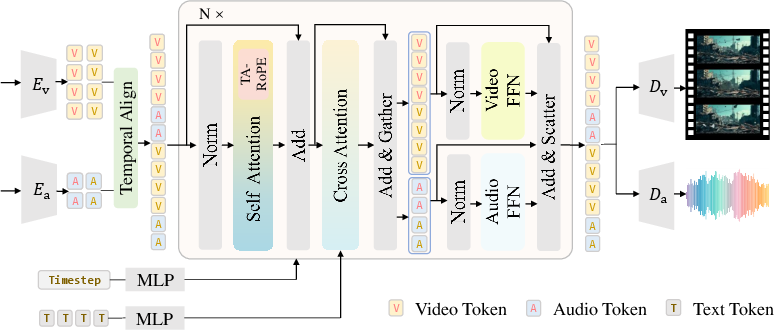
Figure 2: Architecture of JavisDiT++, highlighting shared attention and modality-specific FFN pathways, with explicit temporal alignment via TA-RoPE.
To solve the persistent problem of temporal misalignment, JavisDiT++ introduces Temporal-Aligned Rotary Position Encoding (TA-RoPE). By explicitly enforcing congruence between audio and video token temporal position IDs along the shared global timeline axis, cross-modal frame-level synchrony is achieved. The system carefully offsets spatial and frequency position IDs to avoid overlap, circumventing pitfalls seen in other RoPE schemes (e.g., Qwen2.5-Omni) that suffer from position ID collisions. This results in expedient and robust token interactions, ensuring strict temporal coupling without the inefficiencies of explicit token interleaving or causal masking.

Figure 3: Illustration of temporal-aligned rotary position encoding for tight synchronization of video and audio tokens.
Audio-Video Direct Preference Optimization (AV-DPO)
Recognizing that raw model outputs often diverge from nuanced human notions of quality, temporal alignment, and semantic harmony, JavisDiT++ introduces Audio-Video Direct Preference Optimization (AV-DPO). This algorithm integrates human and synthetic preference data into the training loop, aligning model outputs with desirable perceptual and synchrony targets across quality, consistency, and synchrony metrics.
AV-DPO utilizes a tri-modal reward suite: AudioBox for audio quality, VideoAlign for video, ImageBind embeddings for alignment, and SyncFormer for fine-grained synchrony estimation. Preference data is constructed by sampling candidate generations, including ground-truth pairs, and curating win-loss pairs via normalized, modality-aware multi-dimensional ranking. DPO loss is applied in a modality-disentangled manner, with adaptive β for branch divergence. Ablation experiments confirm the critical impact of modular, normalized, ground-truth-anchored pair selection.
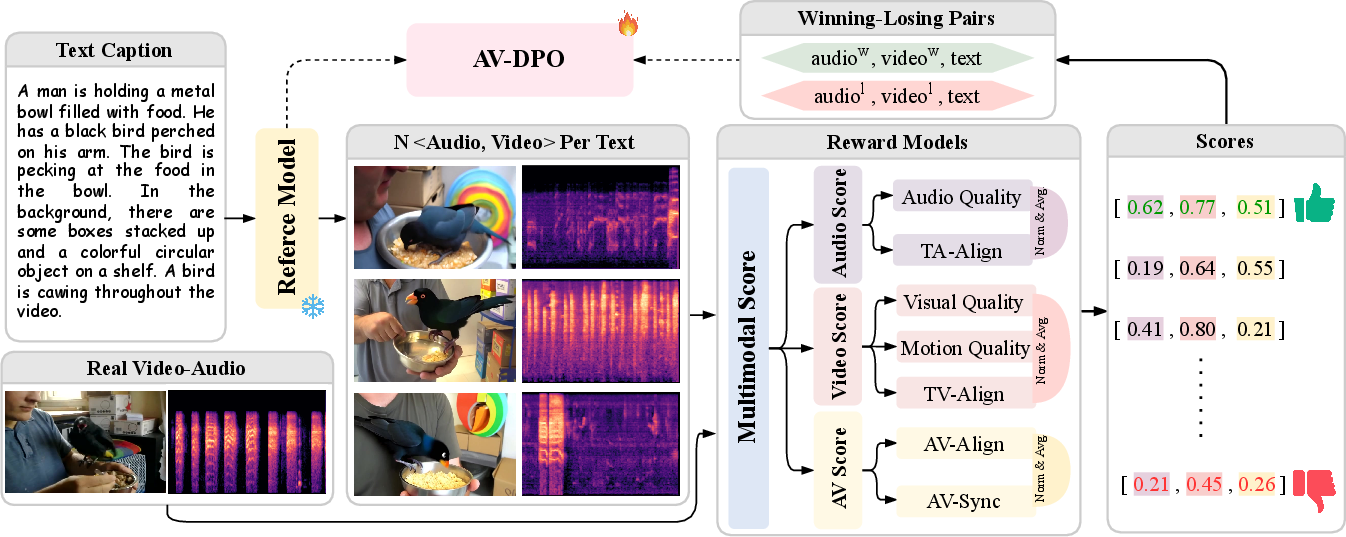
Figure 4: Illustration of the data collection and training pipeline for the AV-DPO algorithm.
Experimental Results and Ablation Studies
JavisDiT++ demonstrates substantial advancements over contemporary systems across all evaluated axes—including quality (FVD, FAD), text consistency (ImageBind/CLIP/CLAP-based), semantic alignment, and temporal synchrony (DeSync, JavisScore). On JavisBench, the method surpasses JavisDiT, UniVerse-1, and other pipelines by substantial margins (e.g., achieving FVD of 141.5 and DeSync of 0.832, while introducing only 1.6% additional inference overhead relative to Wan2.1), demonstrating both superior efficacy and efficiency.
Qualitative human evaluation indicates a more than 70% human preference rate over competitive baselines for generation realism and synchrony. The AV-DPO alignment alone provides an additional 25% preference gain, demonstrating the practical significance of preference-driven fine-tuning.
Comprehensive ablations validate architectural, training, and synchronization choices. MS-MoE is essential for maintaining video and audio generation quality in the transfer setting; LoRA rank and placement strategies are analyzed for adaptation effectiveness. Synchronization studies show TA-RoPE as the only method balancing synchrony improvements and computational overhead. Preference optimization analyses further confirm that modality-aware, normalization-anchored selection is requisite for cross-modal gains.
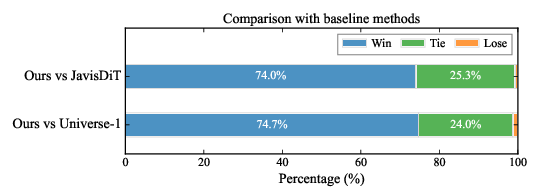
Figure 5: Subjective human comparison of JavisDiT++ with baseline models.
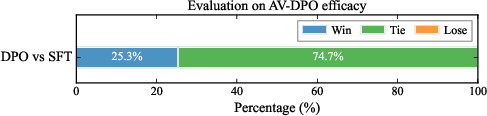
Figure 6: Effectiveness of the AV-DPO strategy as measured by human preference.
Architectural and Methodological Comparisons
Relative to prior models such as Uniform, JavisDiT, and UniVerse-1, JavisDiT++ is architecturally simpler yet achieves better cross-modal interaction without the cost, memory footprint, or inference latency incurred by two-stream or asynchronous cross-attention mechanisms. The explicit avoidance of position ID collision (see TA-RoPE) addresses critical synchrony failures in previous RoPE-based systems. Additionally, preference alignment—previously limited to single-modality or post-hoc reward refinement—has, for the first time, been directly integrated and empirically validated within JAVG.
Implications and Future Directions
The unified architecture and optimization strategy of JavisDiT++ sets a new standard for open-source, high-quality JAVG. The demonstrated sample efficiency (exploiting <1M public training samples) and the modular training regime (progressive adaptation, LoRA-based tuning) have major implications for scalable multimodal foundation models. The separation yet coupling of modeling and preference optimization establishes a blueprint for future generative models that require not just high-fidelity outputs but alignment to flexible, evolving user-defined metrics.
Several experimental findings indicate essential directions:
- Expansion to larger, more diverse multimodal datasets may further enhance generalization and temporal grounding.
- Exploration of more fine-grained and hierarchical control (e.g., musically or linguistically responsive video/sound generation).
- Extension of the unified framework to more generalized cross-modal and conditional generation (e.g., A2V, V2A, AI2V).
- Further scaling efficiency via full-parameter tuning or advanced mixture-of-experts routing schemes.
Conclusion
JavisDiT++ provides a formal, systematic, and empirically validated solution to joint audio-video generation, integrating architecture, position encoding, and preference optimization into a seamless workflow. The approach achieves state-of-the-art results with high sample efficiency and practical scalability, establishing a benchmark for subsequent research in unified, preference-driven multimodal generative modeling.