TAPE: Tool-Guided Adaptive Planning and Constrained Execution in Language Model Agents
Abstract: LLM (LM) agents have demonstrated remarkable capabilities in solving tasks that require multiple interactions with the environment. However, they remain vulnerable in environments where a single error often leads to irrecoverable failure, particularly under strict feasibility constraints. We systematically analyze existing agent frameworks, identifying imperfect planning and stochastic execution as the primary causes. To address these challenges, we propose Tool-guided Adaptive Planning with constrained Execution (TAPE). TAPE enhances planning capability by aggregating multiple plans into a graph and employing an external solver to identify a feasible path. During execution, TAPE employs constrained decoding to reduce sampling noise, while adaptively re-planning whenever environmental feedback deviates from the intended state. Experiments across Sokoban, ALFWorld, MuSiQue, and GSM8K-Hard demonstrate that TAPE consistently outperforms existing frameworks, with particularly large gains on hard settings, improving success rates by 21.0 percentage points on hard settings on average, and by 20.0 percentage points for weaker base models on average. Code and data available at here.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
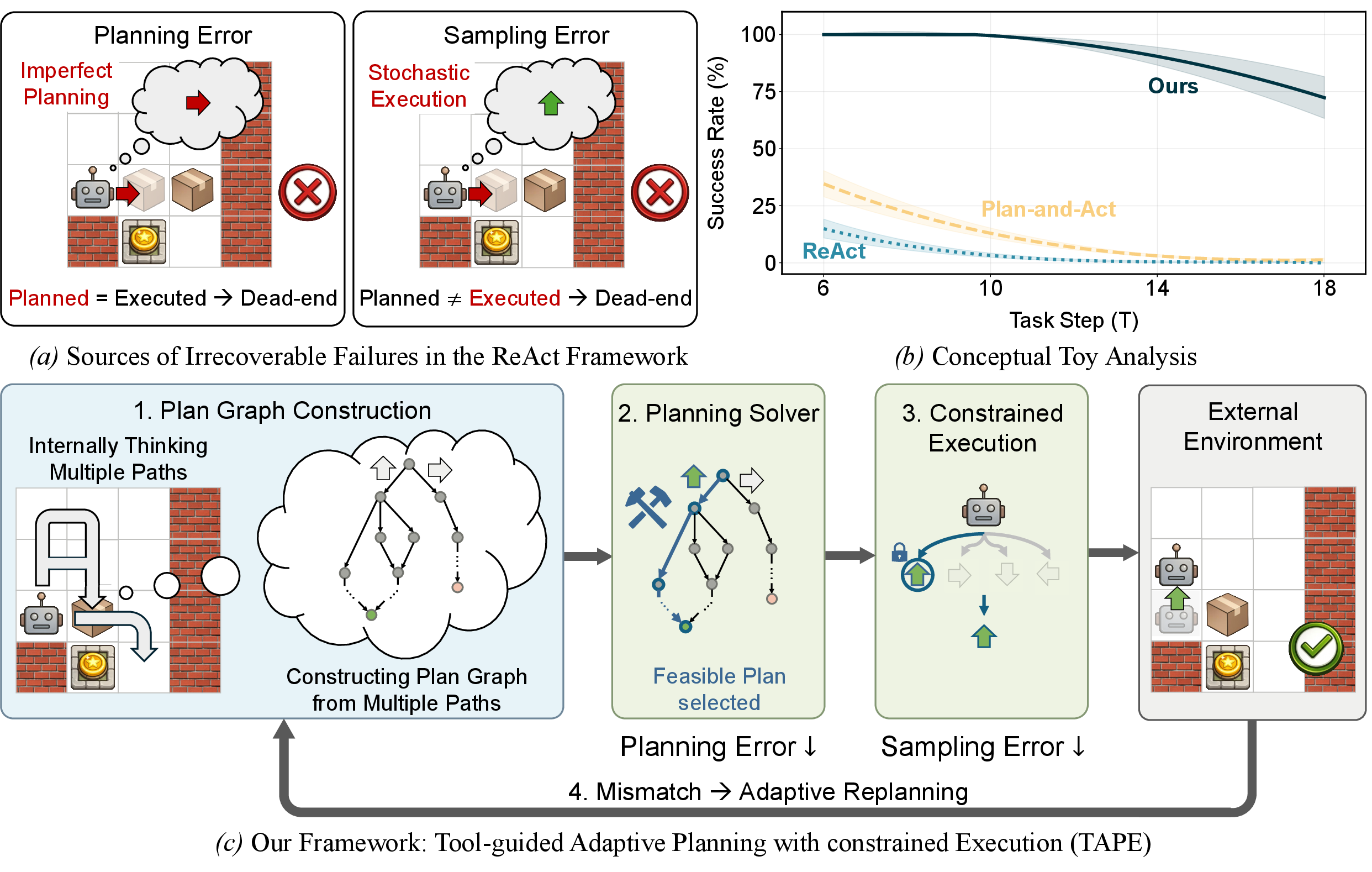
This paper introduces TAPE, a new way to help AI “agents” (smart programs powered by LLMs) plan and carry out tasks more safely and reliably. The authors focus on situations where one mistake can ruin everything—like a puzzle where a wrong move traps you—or where strict limits (time, money, number of tool uses) mean you can’t retry endlessly.
Key Goals and Questions
The paper asks a simple question: How can we make AI agents succeed more often when mistakes are hard or impossible to recover from?
To answer that, the authors:
- Identify two common failure types: planning errors (bad decisions) and sampling errors (random execution mistakes).
- Design TAPE to reduce both kinds of errors so agents can solve tasks more consistently, even under strict constraints.
How the Research Was Done
The authors first analyze where existing agent systems fail, then build TAPE to fix those weak spots. Here’s how TAPE works, explained in everyday terms:
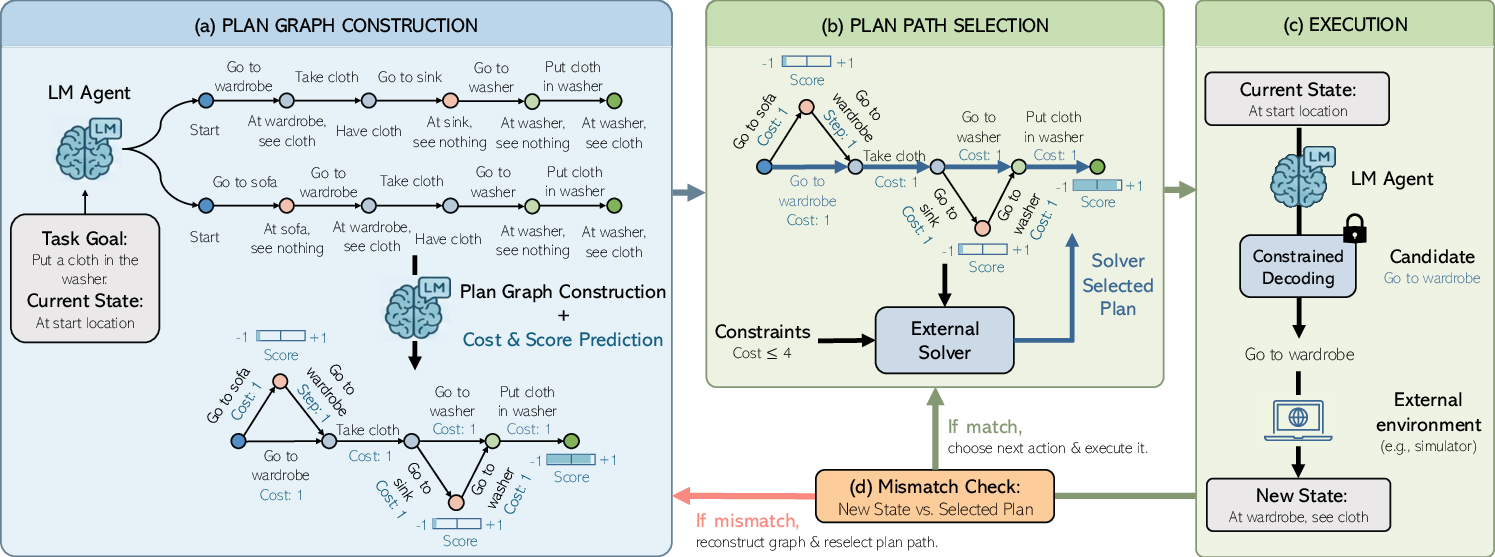
Step 1: Build a “plan graph”
Imagine solving a maze or a level in a puzzle game (like Sokoban, where you push boxes onto target spots). A LLM can think ahead and suggest several possible plans. TAPE takes multiple plans and merges them into a “graph,” which is like a map of all promising paths. Each point (node) is a state you might be in, and each arrow (edge) is a move you can make. It also attaches scores (how good a state is) and costs (how much time or budget a move uses).
Analogy: Think of this like asking several friends for different routes to school, then putting all their ideas onto one big map.
Step 2: Use a solver to pick the best path
TAPE uses an “external solver” (a math tool called ILP—Integer Linear Programming) to pick the best route through the map that:
- Reaches the goal,
- Follows the rules (like budget limits),
- Avoids dead ends.
Analogy: It’s like using a GPS that checks traffic, fuel, and road rules to pick the safest, fastest route from your map of options.
Step 3: Constrained execution (follow the chosen path exactly)
Even when the plan is good, LLMs can sometimes “drift” and produce a different action than intended (this is sampling error). TAPE stops that by “constrained decoding,” which forces the model to output the exact next action chosen by the solver—no surprises.
Analogy: If the GPS says “turn left now,” TAPE makes sure the driver actually turns left, not right.
Step 4: Check for mismatches and replan if needed
If the environment doesn’t behave as expected—like a door is locked even though the plan assumed it was open—TAPE checks for mismatches and rebuilds the plan graph with updated information, then re-selects a feasible path.
Analogy: If you hit road construction, the GPS instantly recalculates a new route that still respects your time and fuel limits.
About the technical terms
- Planning error: The AI thinks up a move that turns out to be a bad idea (like pushing a box against a wall in Sokoban when you can’t pull it back).
- Sampling error: The AI meant to do the correct move, but randomness made it output a different one (like a “typo” in action-taking).
- ILP (Integer Linear Programming): A math tool that picks the best combination of choices under rules, like choosing steps that fit your budget and lead to the goal.
- Constrained decoding: A way to make the AI only say/do allowed actions, like locking the keyboard to only let you type certain commands.
Main Findings
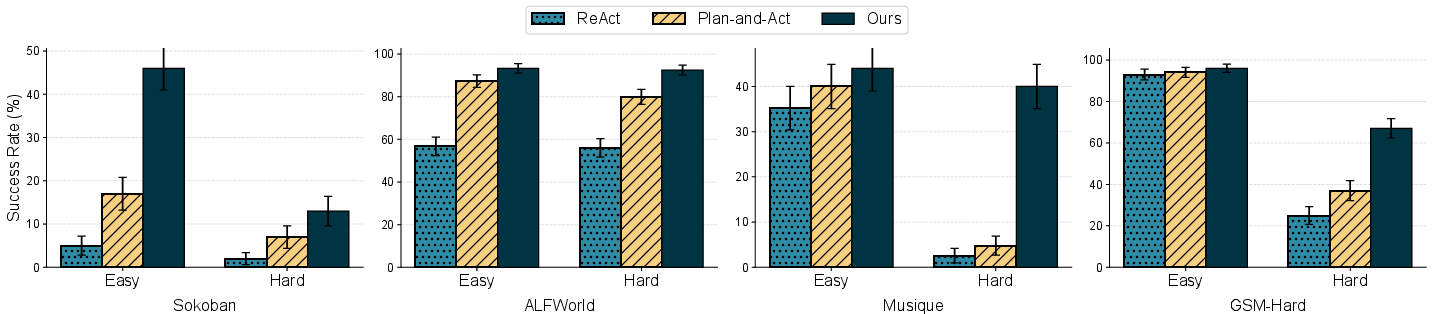
The authors tested TAPE on four kinds of challenging tasks:
- Sokoban (puzzle game),
- ALFWorld (virtual home tasks, like finding and cleaning items),
- MuSiQue (multi-step question answering using search tools),
- GSM8K-Hard (tough math problems using calculation tools).
What they found:
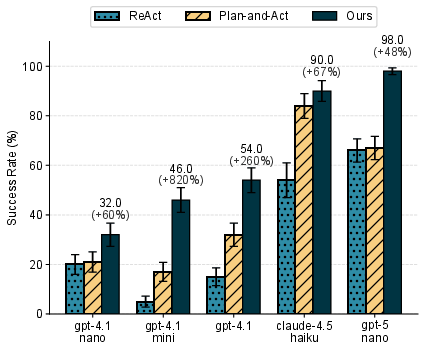
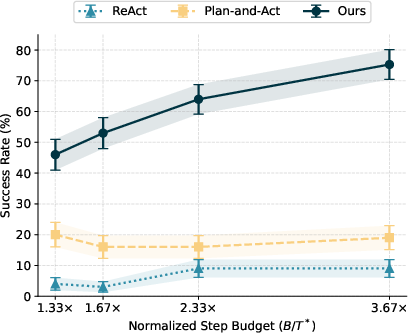
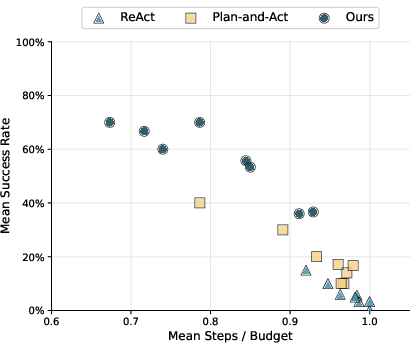
- TAPE consistently beat other popular agent methods (ReAct and Plan-and-Act).
- The improvements were especially big on “hard” versions of tasks and with weaker LLMs.
- On average, TAPE increased success rates by about 21 percentage points on hard tasks and by about 20 points when the base LLMs were weaker.
- TAPE reduced planning mistakes by picking better paths from multiple options and almost eliminated execution randomness by forcing the exact next action.
They also ran detailed analyses (including a theoretical study) showing why errors multiply over long tasks and how TAPE’s approach—multiple plans + solver + constrained execution—reduces both types of errors.
Why This Is Important
In real-world settings, AI agents often face limits: time deadlines, costs for calling tools or APIs, or safety rules. A single wrong move can use up your budget or put you in a place you can’t recover from. TAPE helps agents:
- Plan smarter by considering multiple options and picking the best,
- Stick to the plan exactly to avoid random mistakes,
- Adapt quickly if the environment changes.
This means more reliable results and fewer wasted resources—especially valuable for coding assistants, automation tools, robotics, and complex reasoning tasks.
Implications and Potential Impact
- Safer, more dependable AI agents: Useful in areas with strict rules (like robots that must avoid dangerous moves or systems with limited tool calls).
- Cost-aware automation: Better control of budget and time in tasks like code generation or data retrieval.
- Helps smaller or cheaper models: TAPE’s method can make weaker LLMs perform closer to stronger ones by reducing their planning and execution errors.
Potential challenges:
- Building a good plan graph depends on the model’s ability to structure states correctly—errors here can hurt performance.
- Picking and configuring the right solver for different tasks may need extra engineering.
Overall, TAPE is a practical step toward AI agents that plan better, act more carefully, and succeed more often when mistakes are costly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide follow-on research.
- Formalization and training of the state-merging function f_theta: How exactly are abstract states merged, what heuristics or learning signals are used, and what are the false-merge/false-split rates across domains?
- Calibration of the internal world model (P_theta, R_{g,theta}, C_theta): How accurate are predicted transitions, rewards, and costs; how can uncertainty be estimated and propagated to planning?
- Robust path selection under model uncertainty: Can ILP be extended to handle uncertainty sets or chance constraints when costs/rewards are misestimated?
- Scalability of solver-based planning: What are the runtime/memory profiles as graph size, branching factor, and horizon L_max grow, and which solvers (ILP, CP-SAT, heuristic search, DP) work best in large-scale settings?
- Horizon selection and optimality: How should L_max be chosen for unknown/long horizons; what are the optimality gaps introduced by finite-horizon time-expanded formulations and how to mitigate them (e.g., anytime planning, terminal constraints)?
- Graph completeness and coverage metrics: How to quantify whether the plan graph adequately covers viable action sets; what sampling strategies (e.g., diversity-promoting decoding, exploration objectives) maximize coverage for a fixed planning budget?
- Handling stochastic and partially observable environments: How to extend TAPE to POMDPs, belief-state planning, and observations with noise or ambiguity (including probabilistic mismatch checks)?
- Mismatch detection criteria: What exact tests determine v_{t+1} ≡ v_{t+1}{π*}; how sensitive are they to tool output variability; what are the impacts of false positives/negatives on success and cost?
- Generality of constrained decoding: How to enforce constraints when actions contain open-ended parameters (e.g., code snippets, SQL queries, long-form inputs) beyond tool choice and template formats?
- Safety guarantees: How to encode and verify hard safety constraints in the solver and during decoding; can formal verification or runtime monitors certify constraint satisfaction?
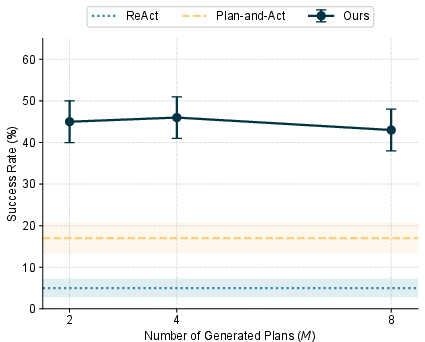
- Compute and budget overheads: What are the end-to-end time, API, and monetary costs of generating M plans, graph construction, solving, and replanning; can we adapt M and solver precision online under strict budgets?
- Evaluation breadth and baselines: How does TAPE compare against stronger search/reflection systems (e.g., ToT, RAP, MCTS-based methods, classical planners) under matched compute on real-world tool-use tasks (browsing, code, software control, robotics)?
- Open vs. closed models: How robust are gains with open-source LMs; does fine-tuning for planning/abstraction improve outcomes; how sensitive are results to prompt variants and decoding settings?
- Estimating planning/sampling errors without oracles: Outside Sokoban, what reliable proxies can estimate these errors, and how well do they correlate with success across domains?
- Theoretical assumptions and bounds: Can the constant, time-invariant, independence assumptions be relaxed; how do results change with time-varying errors, correlated failures, and nonzero decoding errors?
- Objective design in the ILP: The current reward definition uses terminal-node rewards but sums per step—does this double-count or misalign with true task rewards; what alternative objectives (shortest feasible path, success likelihood, multi-objective cost–reward trade-offs) perform best?
- Robustness to tool/API drift: How to adapt when tool schemas, latencies, or failure modes change; can TAPE auto-infer schemas and recover from unexpected tool errors gracefully?
- Learning better abstractions: Can symbolic/state abstractions be learned from interaction data (e.g., contrastive or program-synthesis methods) with guarantees on minimality and correctness?
- Continuous/parameterized action spaces: How to extend constrained decoding and solver-based selection to continuous or high-dimensional actions common in robotics and control?
- Replanning policy optimization: When should replanning be triggered; can partial/incremental graph updates reduce overhead; what hysteresis or confidence thresholds minimize churn?
- Security and adversarial robustness: How vulnerable are plan graphs and constrained decoding to prompt injection or adversarial tool outputs; what defenses are effective?
- Reproducibility assets: Detailed release of prompts, solver configs, seeds, and logs is needed to facilitate replication and fair comparison across frameworks.
- Multi-agent extensions: How to coordinate joint planning/execution with shared budgets or constraints in cooperative/competitive settings (shared graphs, decentralized execution)?
- Learning to plan/select: Can learned optimizers or meta-controllers choose M, L_max, solver parameters, or even replace ILP; can RL improve P_theta and f_theta over time?
- Risk-sensitive and chance-constrained planning: How to incorporate CVaR or chance constraints for budgets and safety under uncertainty in costs and transitions?
- Failure analysis and diagnostics: Systematic taxonomy and tooling to detect whether failures stem from graph omissions, merge errors, cost miscalibration, solver infeasibility, or decoding mismatches.
- Scaling laws and sample complexity: How do success rates scale with M, branching factor d(v_t), horizon, and compute; where are diminishing returns and how to allocate planning budget optimally?
- Advanced graph construction: Beyond simple merging, can and–or graphs, subgoal lattices, or canonicalization improve recombination quality; can learned embeddings with guarantees reduce spurious merges?
- Formal verification integration: Can SMT/constraint solvers be used to certify safety/feasibility of selected plans before execution, complementing ILP-based selection?
Practical Applications
Immediate Applications
The following applications can be deployed today by integrating TAPE’s plan-graph construction, external solver–based path selection (e.g., ILP), constrained decoding, and adaptive replanning into existing LM-agent workflows.
- Software engineering and coding assistants (Software)
- Use case: Auto-debugging and tool execution under time/API-cost budgets (e.g., compile → run → test cycles), selecting minimal-cost fix sequences and preventing off-plan tool calls.
- Potential tools/products/workflows: TAPE Planner SDK integrated with agent toolchains (LangChain, OpenAI function calling), OR-Tools/CBC/Gurobi for ILP, constrained-decoding libraries that enforce function-call schemas, budget monitors (e.g., per-call cost tracking).
- Assumptions/dependencies: Accurate per-action cost estimates; structured tool interfaces; solver availability and reasonable latency; model support for constrained decoding (function calling/JSON schemas).
- RPA and IT operations for UI automation (Software)
- Use case: Reliable desktop/browser automation under quotas/time windows (e.g., change settings, submit forms), merging UI states into nodes (e.g., “on settings page”) and enforcing exact clicks/keystrokes to avoid misnavigation.
- Potential tools/products/workflows: UI state abstraction schemas, ILP solver for path selection, execution guards to constrain permissible UI actions.
- Assumptions/dependencies: Robust state-merging for heterogeneous UI feedback; instrumentation to detect mismatches; deterministic tool APIs.
- Retrieval QA and customer support agents (Education/Software)
- Use case: Multi-hop retrieval (MuSiQue-like) and ticket resolution under API quotas or rate limits, selecting feasible query chains and enforcing strict request formats.
- Potential tools/products/workflows: Vector DB/search APIs; ILP-based query-path selection; constrained function calls; quota trackers and replan triggers.
- Assumptions/dependencies: Reasonable cost prediction for retrieval steps; reliable observation parsing; structured API contracts.
- Data engineering and MLOps orchestration (Software/Energy)
- Use case: Pipeline agents scheduling ETL/validation/model deployment steps under compute or runtime budgets; replan when resource availability deviates.
- Potential tools/products/workflows: Integration with Airflow/Dagster; ILP/MILP task scheduling; constrained CLI invocations; resource monitors.
- Assumptions/dependencies: Accurate task cost models; well-defined constraints; consistent CLI/tool schemas.
- Finance back-office automation and reporting (Finance)
- Use case: Report generation and reconciliation workflows that must respect licensed API usage, audit constraints, and cost budgets.
- Potential tools/products/workflows: ILP-based plan selection with compliance constraints; constrained-decoding policy gates; audit and logging plugins.
- Assumptions/dependencies: Clear compliance rules mapped to constraints; deterministic outputs; accurate budget tracking.
- Educational math coaches and step-by-step solvers (Education)
- Use case: Math tutoring agents (GSM8K-Hard-like) using calculators/symbolic tools with bounded calls; suppress stochastic deviations from planned solution steps.
- Potential tools/products/workflows: Calculator/symbolic engine wrappers; constrained-decoding to enforce step format; replan on error detection.
- Assumptions/dependencies: Trustworthy tool outputs; accurate detection of state progression; teacher-facing oversight for correctness in edge cases.
- Policy-compliant agent gating (Policy/Software)
- Use case: Enforce action allowlists/denylists and budgets (safety constraints) across agent tool ecosystems; fail closed on mismatch and replan.
- Potential tools/products/workflows: Governance layers encoding constraints; constrained-decoding as an enforcement mechanism; external solver for feasible plan selection.
- Assumptions/dependencies: Well-specified constraint schemas; monitoring/logging; alignment between abstract states and policy states.
- Robotics simulation and warehouse task planning (Robotics)
- Use case: Sim-level task agents (ALFWorld/Sokoban analogs) handling limited manipulations or tool calls; select safe feasible sequences and adapt on unexpected transitions.
- Potential tools/products/workflows: Simulator integration; MILP/ILP for discrete plan selection; constrained high-level action execution.
- Assumptions/dependencies: High-fidelity simulation; reliable abstract state merging; bounded solver time relative to control loop.
- Agent reliability benchmarking (Academia/Software)
- Use case: Construct constrained variants of benchmark tasks to measure success under irrecoverable failure modes; use TAPE as a strong baseline.
- Potential tools/products/workflows: Benchmark suites; plan-graph visualization; error estimators for planning/sampling errors.
- Assumptions/dependencies: Reproducible environments; access to the released TAPE code/data; standardized evaluation protocols.
Long-Term Applications
The following vision applications require further research, scaling, validation, or domain adaptation before broad deployment.
- Safety-critical physical robotics and autonomous systems (Robotics)
- Use case: On-robot agents that plan under safety constraints (e.g., collision, energy budgets) and enforce execution determinism; integrate with MPC and safety monitors.
- Potential tools/products/workflows: ROS integration, certified constraint solvers (MILP/MPC), safety layers that constrain actuation commands.
- Assumptions/dependencies: Real-time solvers and low-latency constrained-decoding; verified abstract-state mapping; formal safety guarantees and certification.
- Clinical decision support and EHR agents (Healthcare/Policy)
- Use case: Multi-step workflows (query EHR, check guidelines, propose orders) constrained by safety/policy; deterministic actions and auditability.
- Potential tools/products/workflows: FHIR-compatible tool wrappers; ILP selection with clinical constraints; constrained-decoding aligned to order-entry semantics.
- Assumptions/dependencies: Rigorous validation; regulatory approval; robust internal world models of clinical processes; data privacy/security controls.
- Autonomous cloud resource management (Energy/Software/Finance)
- Use case: Agents optimizing cloud spend and performance (scaling, snapshotting, backups) under cost/risk budgets, with adaptive replanning when telemetry deviates.
- Potential tools/products/workflows: Cloud APIs (AWS/GCP/Azure), cost predictors, MILP resource schedulers, constrained-decoding for infra commands.
- Assumptions/dependencies: Reliable cost models; safe execution guards; multi-agent coordination; strong observability.
- Energy grid and microgrid operations (Energy/Policy)
- Use case: Feasible switching/dispatch plans under safety margins and regulatory constraints; strict adherence to action formats and sequencing.
- Potential tools/products/workflows: Power-system MILP optimizers, digital twin simulations, constrained action gating.
- Assumptions/dependencies: High-fidelity models; domain-certified constraints; regulator-approved processes; real-time performance.
- Risk-aware trade execution and portfolio operations (Finance)
- Use case: Agents executing order sequences under risk budgets and compliance rules; enforce deterministic API calls and replan on market feedback mismatches.
- Potential tools/products/workflows: Broker APIs; risk controllers; MILP for order scheduling; constrained-decoding against execution schemas.
- Assumptions/dependencies: Low-latency control; robust market models; compliance/audit readiness.
- Smart manufacturing and assembly line planning (Robotics/Energy)
- Use case: Multi-step assembly/test/transport sequences with resource/safety constraints; prevent off-plan actions that cause downtime or defects.
- Potential tools/products/workflows: ILP schedulers; digital twin state abstractions; constrained control messages to machines/robots.
- Assumptions/dependencies: Device-level reliability; precise state-merging; integration with industrial protocols.
- Standardization and policy for constrained agentic systems (Policy/Academia/Industry)
- Use case: Define cross-industry schemas for budgets/safety limits and actionable formats for constrained decoding; promote auditability and governance.
- Potential tools/products/workflows: Constraint-specification standards; certification programs; open-source compliance toolkits.
- Assumptions/dependencies: Cross-stakeholder consensus; robust open standards; legal/regulatory alignment.
- Agent orchestration platforms with TAPE modules (Software/Industry)
- Use case: Productize plan-graph construction, solver integration, mismatch detection, and constrained execution as a reusable layer for enterprise agents.
- Potential tools/products/workflows: Visual plan-graph editors; observability dashboards; plug-in solver backends; policy authoring GUIs.
- Assumptions/dependencies: Scalability (large graphs); seamless integration costs; user training and change management.
- Human-in-the-loop safety and oversight workflows (Industry/Healthcare/Finance)
- Use case: Agents propose solver-selected plans with explicit constraints, and humans approve/modify before deterministic execution; replan on deviations.
- Potential tools/products/workflows: Approval UIs; explainability for plan selection; audit trails; fallback protocols.
- Assumptions/dependencies: Effective plan explanations; operator training; clear escalation paths; latency budgets for approval cycles.
Glossary
- Abstract state: A simplified representation of the interaction history that retains only essential execution-status (and budget) information for internal planning. "operates on an abstract state"
- ALFWorld: A simulated household environment for embodied agents used to evaluate language-model agents. "Sokoban, ALFWorld, MuSiQue, and GSM8K-Hard"
- Best-of-N: A selection strategy that samples N candidates and picks the best according to some criterion. "compare against Best-of-"
- Budget constraints: Limits on resources (e.g., time, cost, tool calls) that plans must satisfy. "If there exist budget constraints, we can formulate the optimization problem by adding the budget constraints"
- Budget vector: A vector specifying allowable budgets across multiple resource dimensions. "a budget vector "
- Constrained decoding: A decoding method that restricts an LM’s outputs to adhere to a prescribed action or format during execution. "implemented via constrained decoding"
- Constrained execution: Executing only the prescribed next action (e.g., via decoding constraints) to suppress stochastic deviations. "enforces constrained execution to suppress sampling errors"
- Constrained G-MDP: A goal-conditioned MDP extended to track and enforce resource budgets in the abstract state. "In a constrained G-MDP"
- Cost function: A mapping from state-action pairs to resource costs, potentially multi-dimensional. "a cost function "
- Dead-end state: A state from which the goal cannot be reached regardless of subsequent actions. "enters a dead-end state"
- Directed walk: A sequence of directed edges in a graph that represents a possibly revisiting path through nodes. "selects a single directed walk"
- External solver: An optimization tool outside the LM (e.g., ILP) used to select an optimal feasible path. "uses an external solver (e.g., Integer Linear Programming (ILP)"
- Feasibility constraints: Requirements (e.g., budgets or safety) that must not be violated for a solution to be acceptable. "particularly under strict feasibility constraints."
- Goal-conditioned Markov Decision Process (G-MDP): An MDP where the objective is conditioned on a specified goal provided at the episode start. "goal-conditioned Markov Decision Process (G-MDP)"
- Goal-dependent reward function: A reward function parameterized by the goal that indicates task success. "is a goal-dependent reward function"
- GSM8K-Hard: A hard subset of the GSM8K math word-problem benchmark used to assess reasoning with tools. "GSM8K-Hard"
- Integer Linear Programming (ILP): An optimization framework with linear objectives and constraints over integer variables. "Integer Linear Programming (ILP)"
- Internal world model: The agent’s learned or approximate model of transitions, rewards, and costs used for planning. "internal world model"
- MuSiQue: A multi-hop question answering dataset emphasizing compositional reasoning. "MuSiQue"
- Oracle shortest-path planner: An idealized planner that returns optimal shortest paths in the environment. "admits an oracle shortest-path planner"
- Plan graph: A graph whose nodes represent abstract states and edges represent actions aggregated from multiple plans. "plan graph"
- Plan path selection: Choosing a feasible, high-reward path through the plan graph using an external solver. "plan path selection"
- Plan-and-Act (PA) framework: A framework that first plans a full abstract trajectory and then executes it step-by-step. "Plan-and-Act (PA) framework"
- Planning error: An error where the agent’s internal planning recommends a non-viable action. "A planning error occurs"
- ReAct framework: A paradigm that interleaves reasoning (“Think”) and action (“Act”) at each step in tool-using agents. "ReAct frameworks"
- Replanning: Updating or regenerating the plan when observed outcomes deviate from predictions. "re-planning whenever environmental feedback deviates from the intended state."
- Sampling error: A deviation where the executed action differs from the planned action due to stochastic generation. "A sampling error can occur even when the agent's internal reasoning is correct"
- Sokoban: A puzzle environment where the agent pushes boxes onto targets without creating irreversible deadlocks. "Sokoban"
- Success probability: The probability that an agent reaches the goal without violating viability or constraints. "the success probability"
- Terminal node: A goal node in the plan graph indicating successful task completion. "terminal nodes"
- Time-expanded formulation: A modeling technique that unrolls a graph across time to encode paths with step-indexed decision variables. "using a time-expanded formulation."
- Transition dynamics: The probabilistic rules that determine the next state given the current state and action. "P denotes the transition dynamics"
- Viable action set: The set of actions from a state that keep open at least one path to eventual success. "Define the viable action set as"
Collections
Sign up for free to add this paper to one or more collections.