- The paper introduces Hexagon-MLIR, an open-source stack that unifies high-level representations into MLIR Linalg for optimized Qualcomm NPU execution.
- By leveraging techniques such as operator fusion, tiling, multi-threading, and double buffering, it achieves significant speedups, including a 63.9× acceleration for GELU operations.
- Its design reduces engineering overhead and streamlines the deployment of evolving operator DSLs, paving the way for robust AI compilation on mobile and embedded NPUs.
Hexagon-MLIR: A Comprehensive AI Compilation Stack for Qualcomm NPUs
Motivation and Architectural Context
Hexagon-MLIR introduces an open-source compilation stack built atop the MLIR infrastructure for targeting Qualcomm Hexagon NPUs. It enables automated compilation pathways from high-level representations—hand-written Triton kernels and PyTorch computational graphs—to binaries optimized for Hexagon NPU architectures. The stack addresses key limitations of library-based operator approaches, such as bandwidth bottlenecks resulting from intermediate DRAM roundtrips, inflexibility to rapidly evolving operator DSLs, and the considerable engineering cost of manual kernel deployment. By lowering both PyTorch models and Triton kernels through a unified MLIR-based pass pipeline, Hexagon-MLIR achieves fine-grained control over memory hierarchy, vectorization, multi-threaded hardware scheduling, and operator fusion, thereby aligning with the hardware’s TCM, HVX, and DMA characteristics.
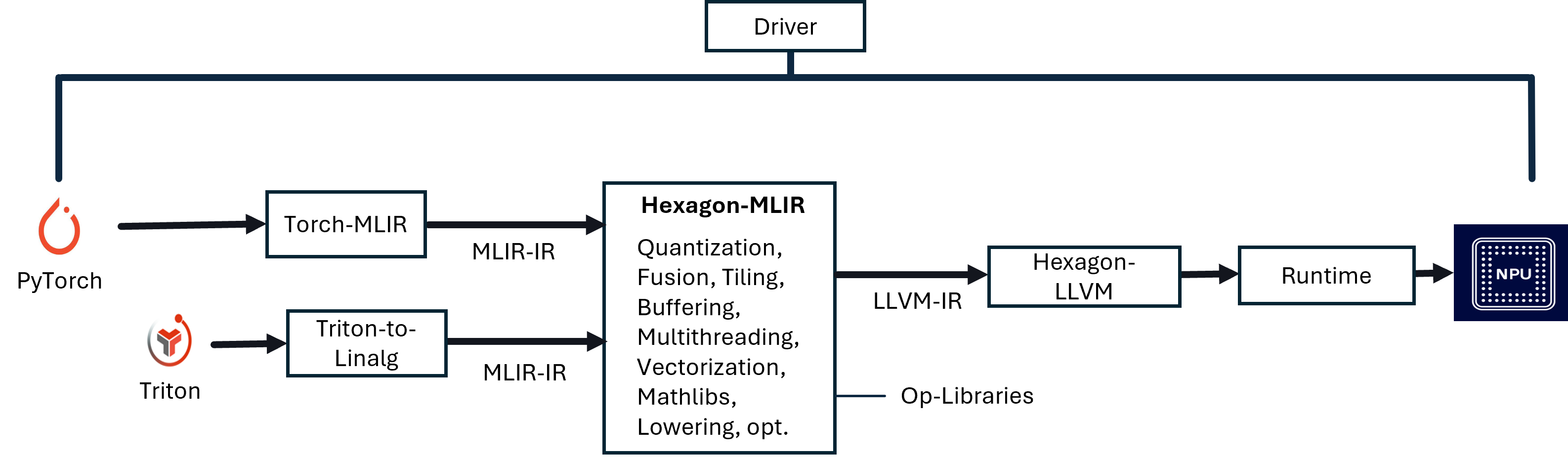
Figure 1: Hexagon-MLIR—AI Compilation Stack Overview, featuring translation of PyTorch and Triton into MLIR Linalg, followed by a structured lowering pipeline to NPU-specific binaries.
MLIR-Centric Compilation Workflow
At the foundation, Hexagon-MLIR leverages MLIR’s extensible IR ecosystem. PyTorch models are imported via Torch-MLIR and Triton kernels are converted to Linalg ops through triton-to-linalg. Both modalities ensure semantic equivalence at the Linalg representation, subject to approximate error if explicit quantization or hardware-specific choices intervene. The pass pipeline, modeled as a sequence of IR morphisms, supports canonicalization, operator fusion, vectorization, tiling, multi-threading, quantization, layout propagation, and explicit lowering steps to bufferized and target-specific IRs.
The stack’s design, with linalg.generic as the central abstraction, elegantly expresses affine memory accesses, structured iteration spaces, and computational payloads. Non-trivial operators such as softmax and TopK, which resist simple element-wise decomposition, are accommodated through richer loop and control IRs. The uniform lowering of PyTorch and Triton subgraphs into MLIR Linalg, with subsequent structured transformation, is critical for full-stack optimizations.
Core Technical Passes
Operator Fusion
Operator fusion is prioritized as a first-class transformation pass, fundamentally improving data locality and eliminating unnecessary tensor materialization. By aggressive fusion of linalg.generic ops, intermediate tensors are not written to DRAM, and producer results are consumed in-register or in fast local SRAM, maximizing reuse and allowing for composed optimization across fused subgraphs. This generative approach enables the automatic construction of “mega-kernels” from arbitrary-length operator chains—crucial for contemporary deep learning workloads with complex fusion patterns.
Tiling and Memory Hierarchy Exploitation
Tiling partitions working sets of large tensors such that slices are moved from DDR to TCM, enabling high-throughput compute with minimal transfer overhead. The transformation inserts explicit bufferization and load-store annotation for MLIR’s bufferization infrastructure. The tiling pass is aware of both the vectorizable dimensions and data movement costs, incorporating loop interchange to expose the innermost, TCM-resident computations.
Multi-threading and Asynchronous Scheduling
Hardware-level parallelism is extracted using MLIR’s Async dialect. The compilation stack first over-decomposes the iteration space into virtual threads and then lowers these to explicit fork-join IR, mapping tasks onto HVX vector contexts. The IR transformation preserves high-level parallel semantics while allowing for fine-grained scheduling, amortizing thread management and synchronization overhead across sufficiently large problem sizes.
Double Buffering and DMA Latency Hiding
Double buffering is implemented as a two-stage transformation—structural alternation of buffer accesses followed by explicit asynchronous DMA orchestration—enabling overlap of computation with data transfers. Ping-pong buffers on TCM are allocated, and all DMA start/wait points are injected into the IR, effectively concealing main memory latency when kernels are either compute/memory balanced or moderately memory-bound. This is essential for attaining high effective throughput as AI kernel complexity grows.
Specialized Math Library Integration
Transcendental and polynomial math ops are mapped to Qualcomm’s QHL vectorized math libraries, or, when unavailable, MLIR’s poly-approximation expansions are employed. These ensure that all non-linearities and reductions critical to DL models execute at near-peak hardware efficiency, regardless of data type (float16/32) or vector length.
Quantitative Evaluation
The empirical analysis demonstrates significant speedups attributable to distinct optimization passes. HVX vectorization alone yields up to 63.9× acceleration for GELU (float16), with substantial gains for RMS-norm, SiLU, and vector additions. Multi-threading exhibits regime-dependent speedups, with sublinear scaling for small tensors due to thread startup cost, but 2−4× speedup for larger working sets. Double buffering shows performance improvements by overlapping DMA with compute, whose benefit magnitude depends on compute-to-memory ratio.
A detailed breakdown of runtime for key representative kernels (GELU, Vec-Add, Exponent Series) demonstrates strong interactions between passes; sequential application of vectorization, multi-threading, and double buffering transitions kernels from compute-bound to bandwidth-bound. The idealized model for DB’s effectiveness, visualized as the fraction of runtime attributed to memory transfers, matches experimental findings: max speedup is achieved when computation and memory transfer times are moderately balanced.
Implications and Future Directions
On the practical front, Hexagon-MLIR lowers the barrier for bringing new PyTorch and Triton kernels to mobile/edge NPUs, reducing engineering turnaround for supporting novel ops and facilitating efficient deployment of rapidly evolving architectures, including LLMs and Mixture-of-Experts. The adoption of structured IRs and staged pipeline transformations provides a scalable foundation for integrating future AI DSLs, e.g., high-level PyTorch Inductor codegen, or new activation mechanisms such as PolyCom. Theoretically, the system affirms the relevance of explicit IRs and MLIR’s design for expressing both dataflow and hardware scheduling, extending to asynchronous execution and memory hierarchy mapping.
Potential developments include further integration with distributed compiler approaches that exploit native overlaps (as outlined in [TRITON_DISTRIBUTED]), automatic scheduling heuristics for deep fusion graphs, advanced mixed-precision and quantization schemes, and enhanced support for execution on heterogeneous SoC configurations. By providing open-source, fine-grained, and composable transformations, Hexagon-MLIR positions itself as a reference stack for AI compilation on embedded accelerators.
Conclusion
Hexagon-MLIR embodies a highly modular, MLIR-driven solution for compiling AI workloads targeting Qualcomm’s Hexagon NPUs. Through a pass pipeline integrating fusion, tiling, vectorization, multi-threading, and buffer management, it attains strong numerical and practical performance improvements on representative kernels. The stack’s extensibility and alignment with next-generation operator DSLs, combined with transparent optimizability using open IRs, establish a robust path forward for both research and industrial AI deployment targeting embedded and mobile NPUs.
Reference: "Hexagon-MLIR: An AI Compilation Stack For Qualcomm's Neural Processing Units (NPUs)" (2602.19762)