Analyzing Latency Hiding and Parallelism in an MLIR-based AI Kernel Compiler
Abstract: AI kernel compilation for edge devices depends on the compiler's ability to exploit parallelism and hide memory latency in the presence of hierarchical memory and explicit data movement. This paper reports a benchmark methodology and corresponding results for three compiler-controlled mechanisms in an MLIR-based compilation pipeline: vectorization (Vec), multi-threading (MT) across hardware contexts, and double buffering (DB) using ping--pong scratchpad buffers to overlap DMA transfers with compute. Using Triton/Inductor-generated kernels, we present an ablation ladder that separates the contribution of Vec, MT, and DB, and we quantify how MT speedup scales with problem size using GELU as a representative activation kernel. The results show that vectorization provides the primary gain for bandwidth-sensitive kernels, MT delivers substantial improvements once scheduling overhead is amortized, and DB provides additional benefit when transfers and compute can be overlapped (i.e., outside the extremes of purely memory-bound or purely compute-bound behavior).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about making small pieces of AI programs (called “kernels”) run faster on edge devices like phones. The authors focus on three ways a compiler (the software that turns code into something a chip can run) can speed things up:
- Vectorization (doing several operations at once with “wide” instructions)
- Multi-threading (using multiple “workers” at the same time)
- Double buffering (hiding wait time for memory by preparing the next data while computing the current one)
They test these ideas in a careful, step-by-step way to see exactly how much each one helps.
Key questions the researchers asked
They wanted to answer:
- How much speed-up comes from vectorization alone?
- How much extra speed-up do we get by adding multi-threading on top of vectorization?
- Does double buffering give even more speed by overlapping data movement with computing—and when does that help most?
- How do these effects change with the size of the problem (small vs. large inputs)?
How did they study it? (Simple explanation)
Think of cooking in a kitchen:
- The chip is the kitchen.
- The main memory (RAM) is the big pantry far away.
- A small, fast “scratchpad” is like a counter right next to you.
- Getting ingredients from the pantry to the counter takes time (that’s memory “latency”).
- A compiler is the head chef who decides how to organize the work.
The three techniques are like:
- Vectorization: using a wide spatula to flip several pancakes at once instead of one at a time.
- Multi-threading: several chefs cooking different pans in parallel.
- Double buffering: having two bowls (ping and pong). While you cook from one bowl, someone else is refilling the other from the pantry, so you never have to pause.
They use an advanced compiler framework called MLIR (a way to describe and transform code in clean, structured steps) and tools like Triton/Inductor to generate the kernels. Importantly, they:
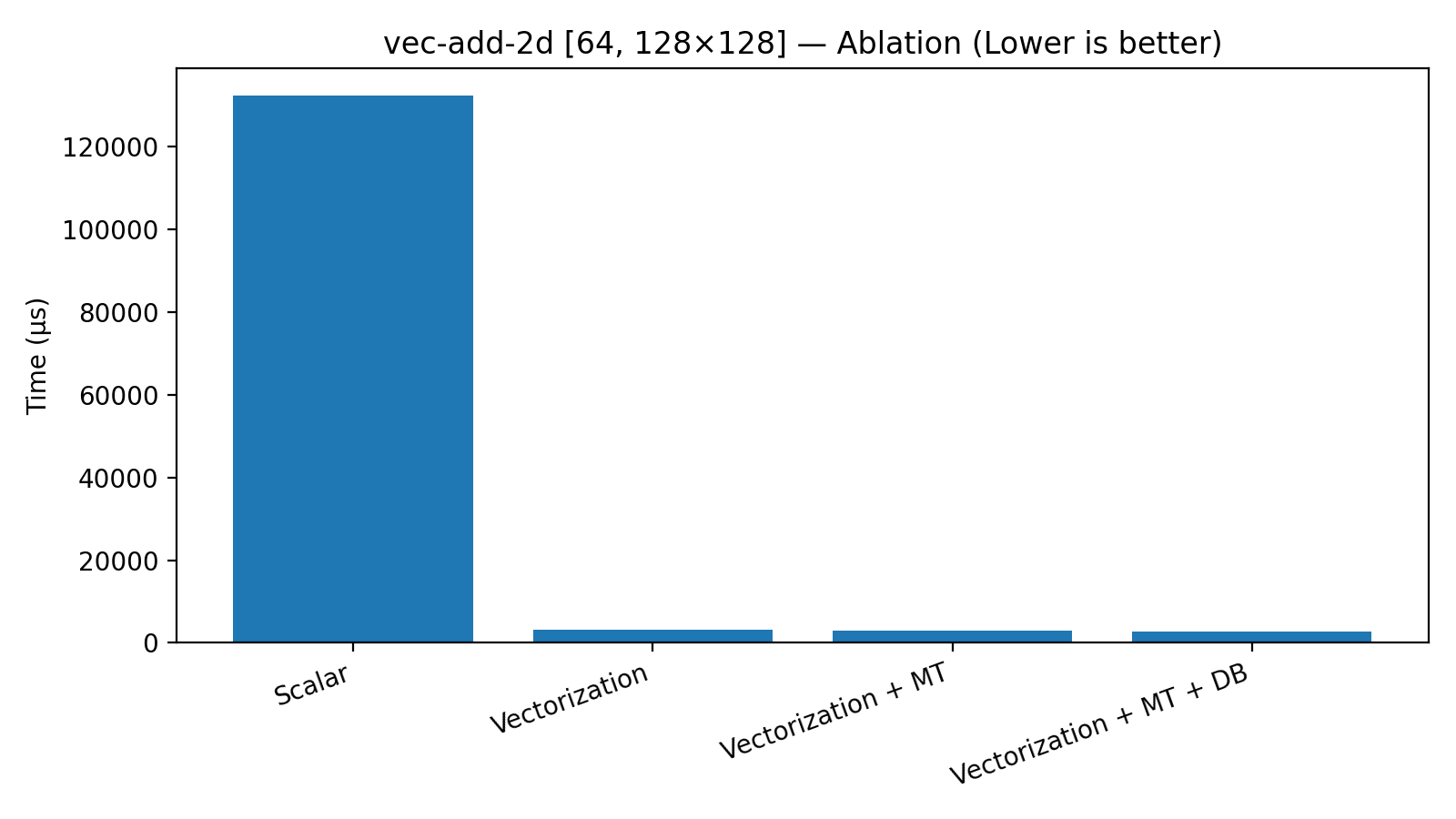
- Turn on the techniques one by one—like flipping switches—to see each one’s contribution. They call this an “ablation ladder”: Scalar → Vec → Vec+MT → Vec+MT+DB (Scalar means plain, no tricks; Vec means vectorization; MT means multi-threading; DB means double buffering.)
- Test two types of kernels:
- A 2D vector addition (very simple and mostly limited by how fast data can move).
- GELU, a common activation function in neural networks (used in transformers), which mixes math and memory.
They also explain, at a high level, how they build these features in the compiler:
- Multi-threading: First, they rewrite loops into a parallel form (like making a to-do list that many chefs can share). Later, they lower it to an “async” form—a fork-and-join plan with tickets and a final “everyone done?” check—so it’s easy to run on the hardware.
- Double buffering: First, they reorganize the loop so that every iteration fetches the next chunk of data into the “other bowl.” Then, they replace normal copies with asynchronous DMA (think of a delivery person who brings ingredients while you keep cooking). They add waits only where needed so the data is ready right before cooking.
What did they find, and why is it important?
Here is what stood out from their measurements:
- Vectorization is the biggest, first win for memory-heavy kernels.
- In the 2D vector-add test, time dropped from 132,479 μs to 3,210 μs—about a 41× speed-up—just by vectorizing. That’s like switching from a single spatula to a very wide one.
- Multi-threading helps once the work per thread is large enough to pay for the startup costs.
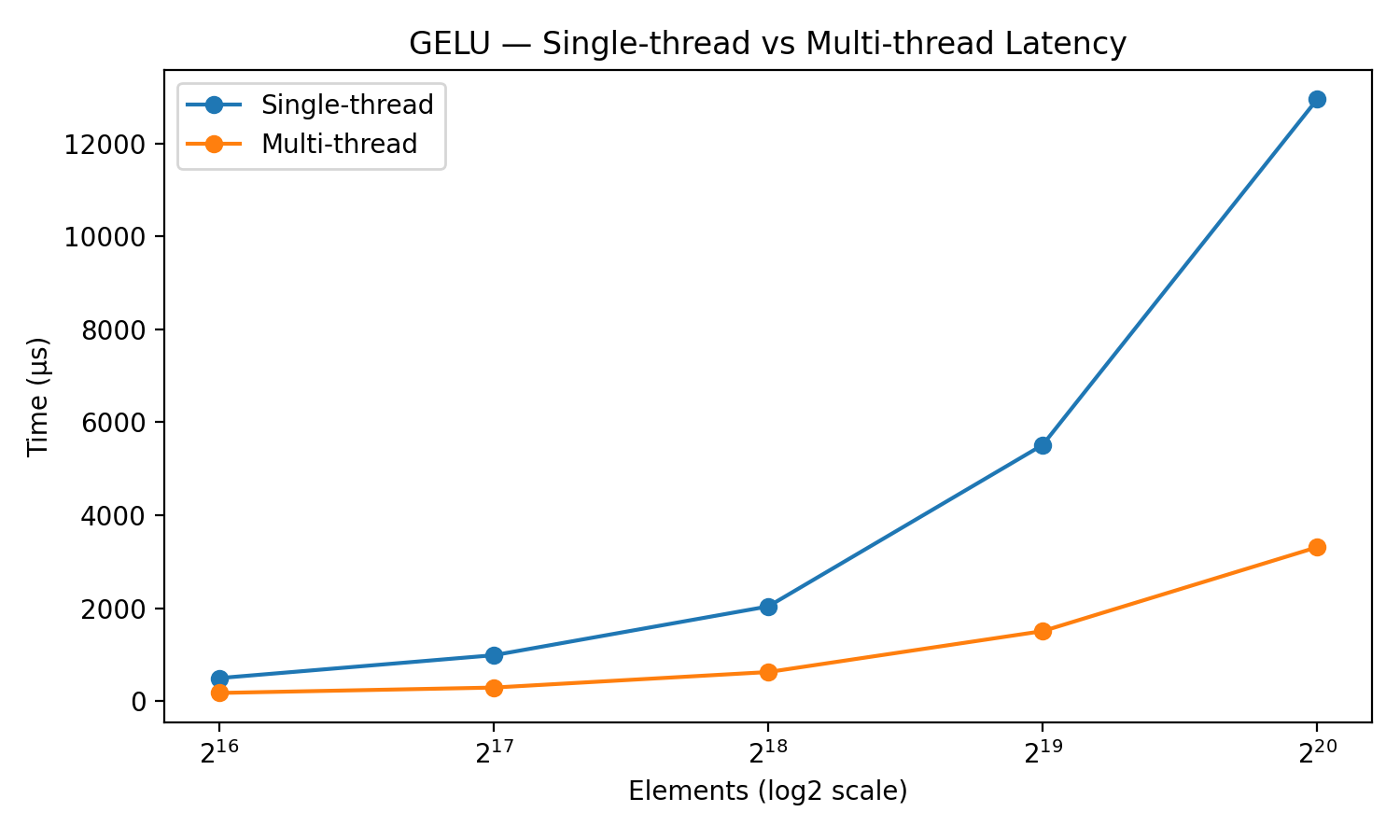
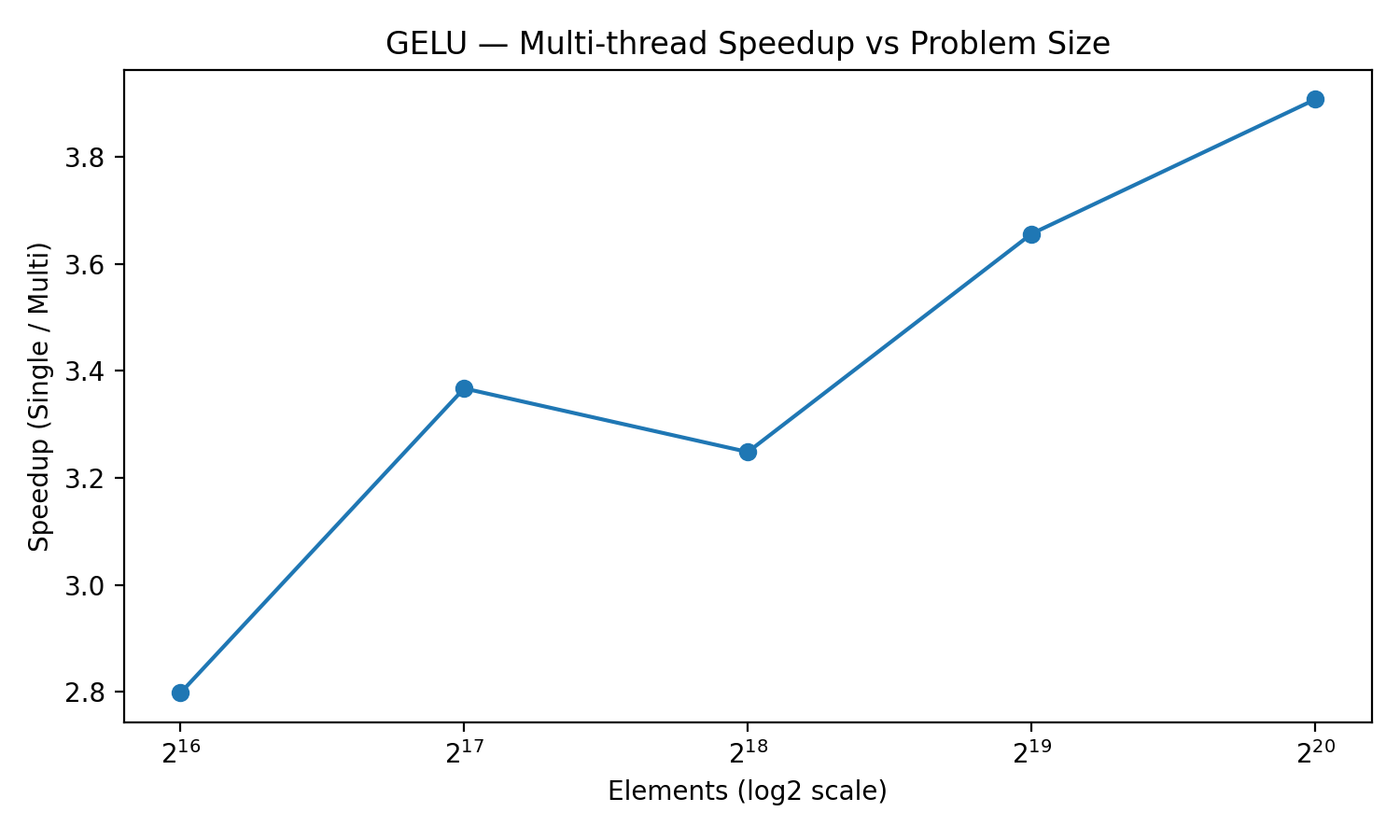
- For the same vector-add, adding multi-threading after vectorization shaved a bit more time (3,210 μs → 3,000 μs). For GELU, the benefit was larger and grew with input size: at 1,048,576 elements, multi-threading sped things up by about 3.9× (12,947 μs → 3,313 μs). This shows that the “organizing the team” overhead matters less when each chef gets a bigger job.
- Double buffering gives extra gains when compute and data movement can truly overlap.
- On vector-add, after Vec and MT, adding DB gave another bump (3,000 μs → 2,689 μs). But if a kernel is purely limited by memory bandwidth (the pantry is the bottleneck) or purely limited by math (the stove is the bottleneck), there’s less to overlap, so DB helps less.
In short:
- Vectorization = foundational (biggest jump).
- Multi-threading = strong gains when the problem is big enough.
- Double buffering = useful when both moving data and computing take significant time and can be overlapped.
Why this matters (implications)
- For edge devices (like phones and small AI chips), speed and efficiency are critical. These devices have fast small memories and slower large memories, and moving data around costs time.
- This paper gives a clear, repeatable way to measure exactly which compiler tricks help and by how much. That helps engineers focus on what matters most for real-world speed-ups.
- Practical guidance:
- Prioritize vectorization first.
- Add multi-threading when your workloads are big enough to offset scheduling overheads.
- Use double buffering when you can overlap data transfers and computation (and you have enough scratchpad space to do it).
- The authors plan to test more kernels (like RMSNorm and softmax) and build simple models to predict when overlapping will pay off based on transfer speeds and scratchpad size. That could make compilers smarter about picking the best strategy automatically.
Overall, the work moves us toward faster, more reliable AI on edge devices by showing which techniques matter most and when to use them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items identify what is missing, uncertain, or left unexplored in the paper, framed as concrete, actionable directions for future research.
- Generality across hardware: Results are reported for a single, unspecified NPU; there is no evaluation across different edge NPUs, GPUs, or CPUs to assess portability of the MT/DB approach and sensitivity to architectural parameters (e.g., vector width, number of hardware threads, DMA engines, scratchpad size, memory bandwidth).
- Hardware characterization: The paper does not disclose key hardware parameters (thread count, vector width, scratchpad capacity, DMA bandwidth/latency, queue depth, number of DMA channels), making it impossible to reproduce or model observed scaling and saturation behaviors.
- Predictive modeling of overlap: There is no quantitative model that predicts when double buffering is beneficial based on tile size, compute intensity, DMA throughput, and scratchpad capacity; the paper mentions this as future work but provides no preliminary formulation or validation plan.
- MT scheduling overhead quantification: Fork–join overheads (async token creation, group management, barrier latency) are not measured or broken down; a detailed overhead budget vs problem size and thread count is needed to guide MT profitability decisions.
- Sensitivity to MT distribution policy: The choice between block and block-cyclic distribution is heuristic and unvalidated; there is no analysis of load balance, cache locality, or contention across policies for uneven iteration spaces.
- Thread scaling limits: The maximum speedup achievable vs number of hardware contexts is not characterized (strong-scaling curves, Amdahl/Gustafson analysis); it remains unclear how performance scales as threads increase beyond the presented setting.
- DB effectiveness boundaries: The paper qualitatively states DB helps between extremes but does not identify quantitative thresholds (e.g., compute-to-transfer ratio) that separate memory-bound, overlap-effective, and compute-bound regimes.
- Composition side-effects (MT+DB): Potential contention between asynchronous DMA and multi-threaded compute (DMA queue saturation, scratchpad bank conflicts, tag management overhead) is not measured or modeled when MT and DB are combined.
- Storeback overlap: The transformation inserts dma_wait before compute but does not analyze or exploit overlap of storeback operations with subsequent prefetch/compute; opportunities for triple buffering or deeper software pipelines remain unexplored.
- Tile-size selection: There is no methodology for selecting tile sizes that jointly optimize vectorization efficiency, MT load balance, and DB residency given scratchpad constraints; auto-tuning or analytical tile-sizing is missing.
- Vectorization strategy details: The paper does not specify vector widths, alignment strategies, handling of tails, gather/scatter patterns, or how vectorization interacts with memory layout/strides—limiting reproducibility and generalization to irregular data layouts.
- Kernel coverage: Only a bandwidth-heavy vector-add microbenchmark and GELU are evaluated; kernels with reductions, halos, or inter-tile dependences (e.g., RMSNorm, softmax, attention, convolution) are not studied, leaving MT/DB applicability to dependent workloads unresolved.
- Cross-thread dependences: The MT approach assumes independent tiles; there is no support or evaluation for kernels requiring cross-thread synchronization (reductions, stencils), nor for correctness-preserving transformations in the presence of dependences.
- End-to-end pipeline effects: The methodology is kernel-centric; it does not address interactions across fused kernels, inter-kernel scheduling, or end-to-end model performance where DMA/compute overlap and threading decisions must be coordinated across operator chains.
- Runtime implementation details: The Async lowering target (e.g., coroutine/task runtime) is not described beyond MLIR patterns; there is no analysis of scheduler policies, work-stealing, or affinity, which can significantly impact fork–join overhead and scalability.
- Measurement rigor: Latency results lack variance/error bars, warm-up procedures, and system isolation details; repeatability and statistical confidence are not established.
- Data-type diversity: Experiments are limited to a single data type; the impact of precision (FP32/FP16/BF16/INT8) on vectorization, bandwidth, and MT/DB profitability is not evaluated.
- Memory hierarchy complexities: The approach is demonstrated for a single scratchpad level; it does not explore multi-level TCM, cache hierarchies, bank conflicts, or NUMA-like effects that could alter optimal tiling and overlap strategies.
- DMA semantics and limits: The paper does not report DMA queue depth, concurrency limits, tag reuse policies, or potential deadlock/starvation scenarios under high MT/DB concurrency.
- Heuristic transparency and tuning: Profitability heuristics for Form-Virtual-Threads and DB transformation stages are not specified or exposed; there is no auto-tuning or search over heuristic parameters to optimize performance across kernels/shapes.
- Boundary/tail handling: DB transformation correctness for partial tiles (tails), unaligned subviews, and edge conditions is not discussed or validated, especially under asynchronous DMA.
- Resource contention analysis: The impact of MT on per-thread vector register pressure, predicate state, and shared functional units is not analyzed; potential throughput degradation due to resource sharing is unquantified.
- Strided/irregular access patterns: The methodology targets regular tiles; performance and correctness for strided, non-contiguous, or sparse tensors (common in real models) are not evaluated.
- Alternative scheduling strategies: The paper focuses on fork–join and two-stage DB; alternative models (persistent threads, task graphs, dynamic scheduling, pipelining depth > 2, software prefetch without DMA) are not compared.
- Integration with Triton/Inductor: It is unclear how the MLIR passes compose with Triton/Inductor’s own scheduling and tiling decisions, or whether duplicate/contradictory transformations occur; a clear interface and division of responsibilities is missing.
- Portability validation: While structured IR is claimed to improve portability, the paper does not demonstrate the methodology across multiple MLIR backends or hardware targets to confirm portability and maintainability.
- Artifact availability: No code, IR dumps, or build/run scripts are provided; despite claims of reproducibility, external researchers cannot replicate the pipeline or results without implementation details and artifacts.
Practical Applications
Immediate Applications
The paper’s findings and MLIR-based methods (vectorization-first, structured fork–join multi-threading via MLIR Async, and DMA-backed double buffering) lend themselves to several deployable use cases. Below are practical, sector-linked applications with assumptions that affect feasibility.
- Compiler pass upgrades in edge-AI SDKs
- Sectors: software tooling, semiconductors, mobile/edge AI
- What to do: Integrate the two-stage MT lowering (scf.forall → Async fork–join) and two-stage DB (structural pipelining → async DMA) into MLIR-based compilers for NPUs/NPUs-like accelerators. Default to “Vec always,” enable MT above a problem-size threshold, and enable DB only when transfers and compute are comparable.
- Tools/products/workflows: MLIR pass libraries, NPU vendor SDK updates, PyTorch Inductor/Triton backends, CI performance baselines by ladder rung (Scalar → Vec → Vec+MT → Vec+MT+DB)
- Assumptions/dependencies: Target provides multi-threaded vector contexts and DMA-accessible scratchpad; MLIR Async dialect supported; kernels are tileable with minimal cross-thread dependences.
- Triage and profiling workflow for kernel performance debugging
- Sectors: software tooling, academic labs
- What to do: Use the ablation ladder to attribute performance to Vec, MT, and DB per kernel, accelerating diagnosis (e.g., if Vec dominates, MT/DB tuning has low ROI).
- Tools/products/workflows: Lightweight CLI to compile and run each rung; dashboards that surface per-rung latency and speedup; PR gating on rung-level regressions
- Assumptions/dependencies: Stable microbench harness; deterministic runtime; representative problem sizes.
- CI regression gates using rung-based benchmarks
- Sectors: software/tooling
- What to do: Add Scalar/Vec/Vec+MT/Vec+MT+DB tests to nightly CI to catch regressions in vector codegen, async lowering, and DMA pipelining.
- Tools/products/workflows: Benchmark suites (e.g., Triton-based kernels), MLIR optimization pipelines with pass fingerprints, data visualizations
- Assumptions/dependencies: Access to consistent test hardware; fixed DMA/runtime versions.
- Immediate acceleration of bandwidth-sensitive kernels in production inference
- Sectors: mobile/consumer (camera, voice), robotics, industrial IoT, automotive
- What to do: Prioritize aggressive vectorization; enable MT for larger activations (e.g., GELU, RMSNorm) where fork–join overhead is amortized; use DB for tiled ops transferring from DRAM to scratchpad where compute/transfer overlap is non-trivial.
- Tools/products/workflows: Prebuilt activation kernel libraries compiled with Vec+MT and conditionally DB; runtime knobs to toggle thread count
- Assumptions/dependencies: Scratchpad capacity for ping–pong tiles; kernels structured in normal form (alloc/copy/compute/copy-back); bandwidth not already saturated.
- On-device AI latency and energy improvements for apps
- Sectors: healthcare (wearables), finance (mobile biometrics/fraud on-device), AR/VR, smart cameras
- What to do: Recompile activation-heavy subgraphs (e.g., transformers, image enhancement) with Vec+MT and opportunistic DB; set problem-size thresholds so MT is used only when it pays off (as shown by GELU scaling).
- Tools/products/workflows: App-specific model builds; device-side A/B testing of MT thresholds; battery/performance dashboards
- Assumptions/dependencies: Model partitions that keep activations on-device; hardware supports async DMA and multi-threaded vector contexts.
- Guidance for kernel library authors (e.g., Triton kernels)
- Sectors: software (numerical libraries), education
- What to do: Adopt the paper’s “normal form” for tiled loops to make DB transformations predictable; expose tile sizes and distribution policies (block vs block-cyclic) as parameters.
- Tools/products/workflows: Triton templates annotated for MLIR passes; auto-generated IR anchors for prefetch/compute/storeback
- Assumptions/dependencies: Kernel authors accept small refactors to fit the normal form; consistent IR patterns across codegen.
- Vendor/customer procurement benchmarking
- Sectors: industry consortia, device OEMs
- What to do: Use rung-level measurements to compare compilers/hardware: quantify how much of the speedup comes from Vec vs MT vs DB on candidate NPUs.
- Tools/products/workflows: Microbench harness aligned with MLPerf practices; comparisons recorded per rung and per problem size
- Assumptions/dependencies: Access to competing toolchains and devices; common kernels and shapes.
- Teaching modules and reproducible labs on modern compiler techniques
- Sectors: academia, training programs
- What to do: Build hands-on labs that show scf.forall → Async lowering and normal-form-to-DB transformation; quantify overhead amortization with GELU size sweeps.
- Tools/products/workflows: MLIR-based lab notebooks, simple Triton kernels, visualization of fork–join schedules
- Assumptions/dependencies: Classroom access to GPUs/NPUs or simulators; stable MLIR distribution.
Long-Term Applications
These applications require additional research, scaling, or ecosystem development before broad deployment.
- Predictive, cross-target cost models for enabling Vec/MT/DB
- Sectors: software tooling, semiconductors
- What to build: A model that predicts overlap efficiency from DMA bandwidth, scratchpad size, and kernel arithmetic intensity; auto-enables DB only when profitable.
- Tools/products/workflows: Learned or analytic cost models integrated into MLIR passes; offline calibration pipelines
- Assumptions/dependencies: Accurate runtime counters for DMA and barrier costs; generalization across devices.
- Portable async runtime layer for MLIR Async
- Sectors: software/tooling, OS/runtime vendors
- What to build: A standardized coroutine/task runtime mapping MLIR Async to heterogeneous hardware (NPUs, GPUs, DSPs), simplifying fork–join execution portability.
- Tools/products/workflows: MLIR-to-runtime ABI, adapters for common RTOS/Linux environments
- Assumptions/dependencies: Community alignment on ABI; vendor support for task scheduling and token groups.
- End-to-end latency-hiding schedulers across fused graphs
- Sectors: edge AI frameworks, robotics, automotive
- What to build: Extend DB+MT from per-kernel to cross-op pipelines (prefetch next op’s data while current op computes) with graph-level scratchpad budgeting.
- Tools/products/workflows: Graph schedulers that co-optimize tiling, placement, and DMA overlap; IR passes that propagate residency guarantees
- Assumptions/dependencies: Fusable graphs; shared scratchpad and DMA across ops; accurate lifetime analysis.
- Energy-aware compilation policies
- Sectors: mobile/IoT, policy/standards (sustainability)
- What to build: Policies that trade peak speed for energy efficiency (e.g., fewer threads on small problems, DB disabled when DMA power dominates).
- Tools/products/workflows: Joule-per-inference models; compilation knobs exposed to power managers
- Assumptions/dependencies: Power telemetry APIs; validated energy models per device.
- Hardware–software co-design feedback loops
- Sectors: semiconductors, OEMs
- What to build: Use rung-level attribution to justify hardware features (e.g., more DMA channels, larger scratchpads, cheaper barriers) and to size vector contexts/thread counts.
- Tools/products/workflows: Design space exploration using ladder benchmarks; co-simulation frameworks
- Assumptions/dependencies: Early access to RTL/silicon simulators; cross-team workflow.
- Autotuning and learning-based schedulers
- Sectors: software/tooling, academia
- What to build: ML-guided selection of tile sizes, distribution policy (block vs block-cyclic), and MT/DB enablement thresholds driven by online/offline search.
- Tools/products/workflows: Bayesian/gradient-free tuners integrated into MLIR pipelines; caching of per-kernel configurations
- Assumptions/dependencies: Stable performance surfaces; reproducible measurements; low tuner overhead.
- Standardized microbenchmarks and reporting for MLPerf-like suites
- Sectors: industry consortia, policy
- What to build: A “kernel mapping” track that reports Vec, MT, and DB contributions separately to improve transparency of compiler/hardware capabilities.
- Tools/products/workflows: Open microbench kits, rung-based scorecards, submission rules
- Assumptions/dependencies: Consensus on kernels and sizes; governance for reporting.
- Developer-facing “kernel suitability” advisor
- Sectors: software/tooling, education
- What to build: A static/dynamic analyzer that classifies kernels as memory-bound vs compute-bound, predicts MT amortization, and recommends whether to enable DB.
- Tools/products/workflows: IDE plugins or CLI advisors reading MLIR; integration with Triton code templates
- Assumptions/dependencies: Reliable static features; quick profiling hooks.
- Broader kernel coverage (e.g., RMSNorm, softmax, attention blocks)
- Sectors: all deploying transformer inference
- What to build: Generalized transformations for more irregular access patterns and longer dependency chains; validated ladder data across these ops.
- Tools/products/workflows: Extended IR pattern matchers; specialized prefetch strategies for reductions
- Assumptions/dependencies: More complex correctness proofs for DB; careful barrier placement.
- Runtime-adaptive scheduling (problem-size and load-aware)
- Sectors: robotics, automotive, AR/VR
- What to build: At runtime, switch thread count and DB on/off based on input sizes and system load to meet latency SLAs.
- Tools/products/workflows: Feedback controllers in the runtime; per-operator performance tables
- Assumptions/dependencies: Low-latency reconfiguration; minimal warm-up overhead.
Glossary
- Ablation ladder: A benchmarking approach that progressively adds mechanisms to isolate their individual performance contributions. "we present an ablation ladder that separates the contribution of Vec, MT, and DB,"
- Async Dialect: An MLIR dialect that represents asynchronous operations and synchronization constructs. "using MLIRâs Async"
- async.add_to_group: An MLIR Async operation that adds an async token to a group for collective synchronization. "async.add_to_group %tok, %group"
- async.await_all: An MLIR Async operation that waits for completion of all tokens in a group. "async.await_all %group"
- async.execute: An MLIR Async construct that executes a region asynchronously and produces a completion token. "Each tile becomes an async.execute region that produces a token;"
- Barrier: A synchronization point that blocks progress until prior parallel tasks have completed. "and async.await_all forms a barrier before subsequent dependent computation."
- Block-cyclic distribution: A work distribution policy that assigns blocks of iterations in a cyclic manner to balance uneven ranges. "selects a distribution policy (block vs.\ block-cyclic) to balance work when ranges are uneven."
- Coroutine/task runtime: A runtime system capable of scheduling and executing coroutines or tasks for asynchronous parallel execution. "lower into a coroutine/task runtime"
- DMA: Direct Memory Access; hardware-supported data transfer that moves data between memory and devices without CPU intervention. "overlap DMA transfers with compute"
- Double buffering: A technique that alternates between two buffers to overlap data transfer and computation. "Double buffering is a software-pipelining strategy that overlaps transfers and compute by alternating between two scratchpad buffers (ping and pong)."
- Fork–join: A parallel programming pattern where tasks are spawned and later joined at a synchronization point. "and then introduces an explicit fork--join."
- GELU: Gaussian Error Linear Unit; a smooth activation function commonly used in transformer models. "The second is GELU, a common activation kernel representative of transformer inference subgraphs;"
- Hierarchical memory: A memory architecture organized in levels with different capacities and latencies (e.g., caches, scratchpads, DRAM). "hide memory latency in the presence of hierarchical memory"
- Inductor: A compilation backend (e.g., PyTorch Inductor) that generates optimized kernels, often paired with Triton. "Using Triton/Inductor-generated kernels,"
- Intermediate Representation (IR): A compiler-internal program form used to express and transform computation. "MLIR IR patterns"
- Latency hiding: Techniques that overlap computation with data movement to mask memory access delays. "hide memory latency"
- linalg.generic: An MLIR Linalg operation expressing generic element-wise or structured computations over tensors/memrefs. "a tiled kernel (e.g., linalg.generic)"
- memref.dma_start: An MLIR operation that initiates an asynchronous DMA transfer. "Prefetch paths are rewritten to memref.dma_start with distinct ping/pong tags,"
- memref.dma_wait: An MLIR operation that waits for an initiated DMA transfer to complete. "and memref.dma_wait is inserted immediately before compute to ensure tile residency in TCM."
- memref.subview: An MLIR operation that creates a view (slice) into a memref for tiled or subregion access. "memref.subview \rightarrow memref.alloc \rightarrow memref.copy,"
- MLIR: Multi-Level Intermediate Representation; a flexible compiler infrastructure for building domain-specific compilers. "Our implementation is built in MLIR"
- Modulo scheduling: A loop scheduling technique that creates a steady-state pipeline by overlapping iterations. "closely related to modulo scheduling and pipelined loop execution"
- Multi-threading (MT): Executing computation across multiple hardware threads or contexts to exploit parallelism. "multi-threading (MT) across hardware contexts,"
- NPU: Neural Processing Unit; specialized hardware accelerator for machine learning workloads. "On edge NPUs, performance is shaped by hierarchical memory,"
- Ping–pong scratchpad buffers: Two alternating scratchpad buffers used to pipeline data transfer and computation. "ping--pong scratchpad buffers to overlap DMA transfers with compute."
- Predicate state: Per-thread or per-lane boolean mask state used for predicated vector operations. "(e.g., vector register and predicate state)."
- Prefetch: Moving data into a nearer memory (e.g., scratchpad) ahead of its use to reduce stall time. "prefetches the first tile into ping buffers"
- Profitability heuristic: A compiler heuristic that estimates whether a transformation will yield performance benefits. "The pass uses a size-based profitability heuristic over the tile space"
- Prologue: The initial setup phase of a software-pipelined loop that prepares data and state before the steady-state. "It emits a prologue that prefetches the first tile into ping buffers,"
- Rematerializing subviews: Recomputing subview operations at the current loop index to reconstruct storeback paths. "reconstructs storeback by rematerializing subviews at the current induction variable."
- scf.forall: An MLIR Structured Control Flow operation that expresses parallel iteration over a range. "using scf.forall"
- Scratchpad buffer: A small, fast on-chip memory used to stage data for computation. "scratchpad buffers (ping and pong)"
- SIMD-style lowering: Compiler transformation that maps computations to Single Instruction, Multiple Data vector operations. "Vec isolates SIMD-style lowering,"
- Software pipelining: Rearranging loop operations to overlap stages (e.g., load, compute, store) across iterations. "Double buffering is a software-pipelining strategy"
- TCM: Tightly Coupled Memory; a fast, local memory region near compute units (e.g., scratchpad). "to ensure tile residency in TCM."
- Tiling: Partitioning an iteration space or data into tiles to improve locality and enable parallelism. "typically created by tiling:"
- Triton: A domain-specific language and compiler for efficient tiled kernel generation. "We use a Triton implementation of GELU as our concrete kernel instance."
- Vector context: The per-thread vector execution state, including registers and predicates, enabling independent vector threads. "vector context (e.g., vector register and predicate state)."
- Vector register: A hardware register that holds vector data for SIMD operations. "vector register and predicate state"
- Vectorization: Transforming scalar code to operate on multiple data elements per instruction via vector hardware. "vectorization provides the primary gain for bandwidth-sensitive kernels"
- Virtual threads: Compiler-created parallel partitions that behave like threads until lowered to runtime constructs. "scf.forall (virtual threads)"
- Write-back sequence: The phase that stores computed results from scratchpad or registers back to main memory. "and then a write-back sequence."
Collections
Sign up for free to add this paper to one or more collections.