- The paper demonstrates an MLIR pipeline that automatically lowers high-level stencil computations to Cerebras’s WSE, eliminating manual rewriting.
- It introduces specialized MLIR dialects and optimizations—such as bufferization and actor mapping—achieving up to 38.1% performance uplift on WSE3.
- Experimental evaluations reveal significant speedups over GPU/CPU clusters while reducing development effort by 10–35× compared to hand-crafted code.
MLIR-Based Automatic Lowering of Stencil Kernels for Wafer-Scale Architectures
Introduction
The paper "An MLIR Lowering Pipeline for Stencils at Wafer-Scale" (2601.17754) addresses the formidable challenge of mapping high-level stencil computations—ubiquitous in HPC scientific applications—onto the Cerebras Wafer-Scale Engine (WSE), a massively parallel dataflow architecture. The work demonstrates that domain-specific abstraction coupled with compiler automation enables highly performant execution of stencil codes on WSE without manual rewriting or algorithmic modification at the application level. By architecting a multi-stage MLIR-based lowering pipeline and introducing specialized intermediate dialects, the authors achieve competitive, sometimes superior, throughput compared to hand-tuned CSL code and facilitate direct portability across hardware generations.
Cerebras WSE Architecture and Programming Model
The WSE comprises a systolic array with over 900,000 PEs, interconnected via cardinal links and supporting an aggregate fabric bandwidth exceeding 200 Pb/s. Each PE is single-threaded, with local SRAM and explicit message-passing communication, supporting four cardinal directions and utilizing a "wavelet" protocol for data flow. The programming interface is provided by the CSL language, exposing architectural primitives such as asynchronous tasks, domain-specific routing, and low-level buffer management.
Key complexities arise from the WSE's asynchronous actor-like execution model. Rather than bulk synchronous parallelism, algorithms must be restructured to employ a callback-driven flow, assigning functionality to tasks triggered by the completion of inter-PE communication events. Classical control constructs (loops, barriers, await) are inapplicable, requiring decomposition into a graph of asynchronous activations.
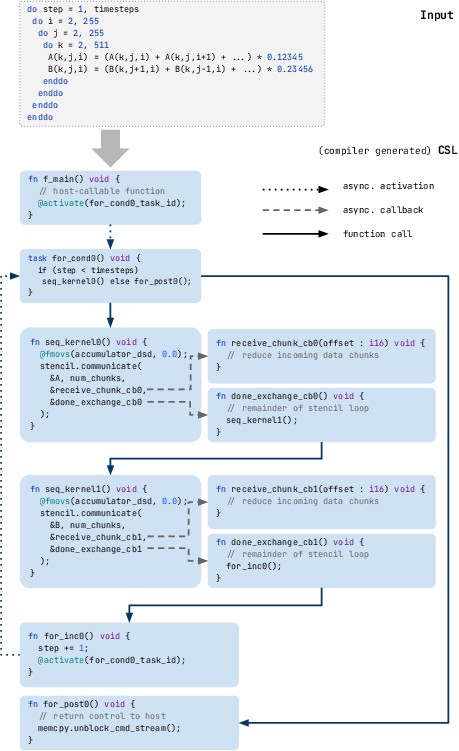
Figure 1: A time-step loop in CSL, illustrating the explicit management of asynchronous data exchanges and task callbacks required for inter-PE communication.
MLIR-Based Lowering Pipeline
The authors introduce a suite of MLIR dialects to bridge the semantic gap between stencil abstractions and WSE's actor-based execution:
- stencil: Architecture-agnostic, mathematical description of the computation.
- csl-stencil: Explicitly specifies the communications and operations required on WSE; supports region-based partial reduction and chunk-wise communication for buffer efficiency.
- csl-wrapper: Encapsulates global layout and specialization metaprogramming, supporting CSL's staged compilation.
- csl-ir: Direct representation of CSL constructs in MLIR for back-end codegen.
Progressive lowering transforms the input DSL/Fortran code through these dialects, preserving high-level information (such as stencil shapes, reduction axes, and dependency patterns) longer than on CPU or GPU flows. The pipeline enables optimizations at multiple levels—bufferization, partial reduction, communication-compute overlap, coefficient fusion, and actor mapping—before finally generating high-efficiency CSL source for the WSE.
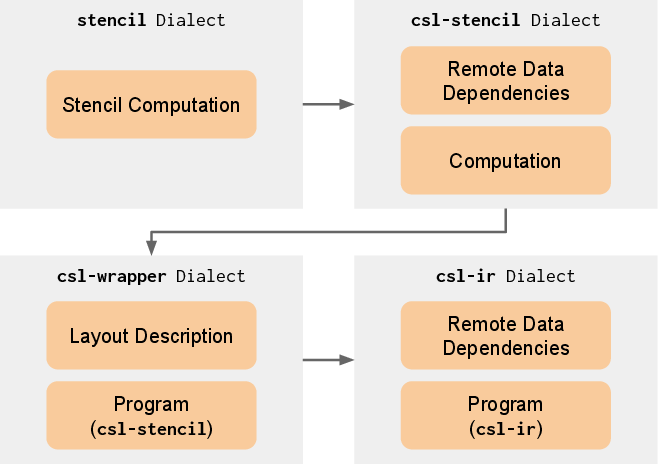
Figure 2: Dialect conversion sequence incrementally lowers from stencil semantics to the actor-based execution required by the WSE.
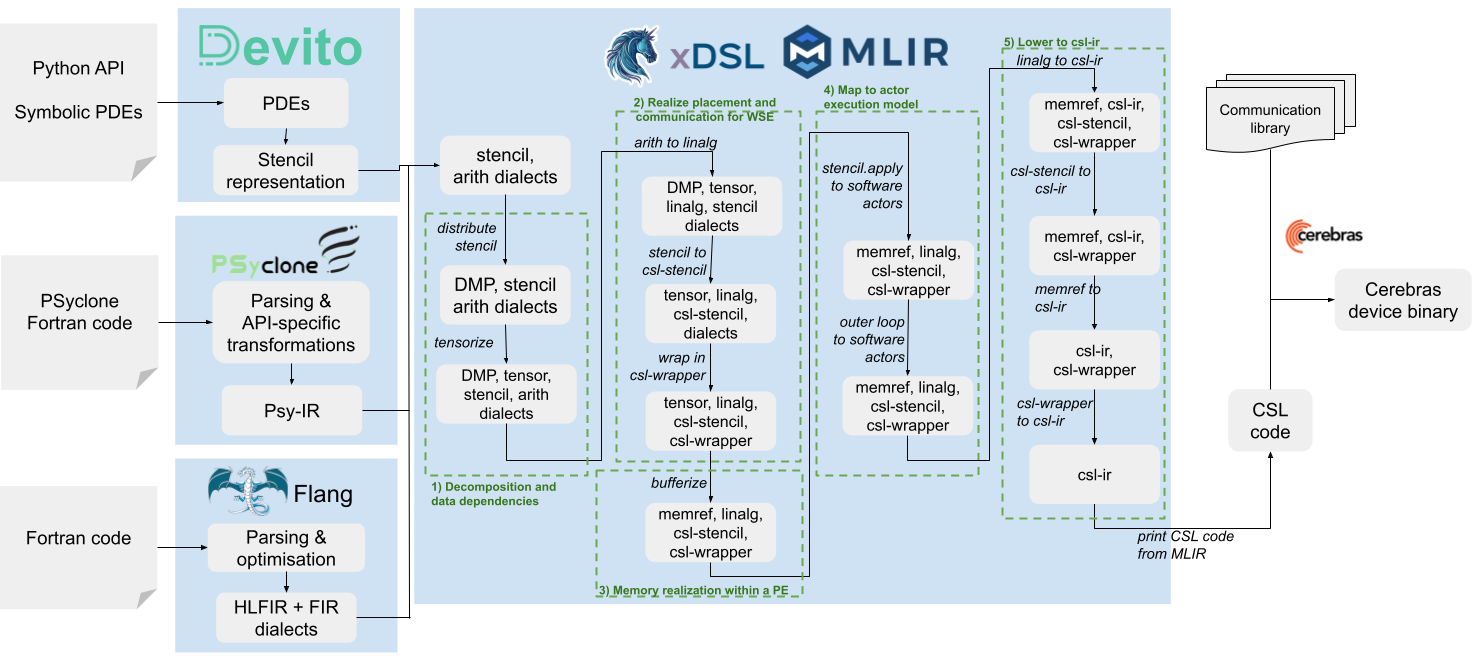
Figure 3: Staged compilation pipeline employing MLIR/xDSL, showing frontend IR conversion, dialect lowering steps, and integration with Cerebras SDK tools.
The pipeline executes decompositions (mapping multidimensional stencils to 2D PE grids and tensorizing remaining dimensions), explicit communication scheduling (breaking exchanges into optimal chunks), reference semantic conversion for buffer materialization, and actor mapping (splitting control flow into asynchronous task graphs). Key optimization passes include stencil fusion, arithmetic operator reduction (varith), multiply-add fusion, broadcast-based reduction, and communication-compute interleaving—all informed by retained stencil-specific abstractions through MLIR's flexible IR.
Experimental Evaluation
Evaluation spans five stencil kernels (Jacobian, Diffusion, Acoustic, 25-Point Seismic, UVKBE) using three HPC DSLs (Devito, PSyclone, Flang) and compares performance across WSE2, WSE3, and traditional large-scale HPC platforms (128 Nvidia A100 GPUs and 128 CPU nodes of ARCHER2).
- The MLIR-generated code matches or outperforms hand-crafted CSL on WSE2, with up to 7.9% higher throughput and more efficient memory/task management.
- When ported to WSE3, the same pipeline (with updated communication library exploiting new hardware features) yields up to 38.1% performance uplift relative to WSE2.
- For Devito's acoustic benchmark, WSE3 achieves a 14× speedup over 128 A100 GPUs and 20× over 128 CPU nodes for a representative large problem size. No application-level code changes were required.
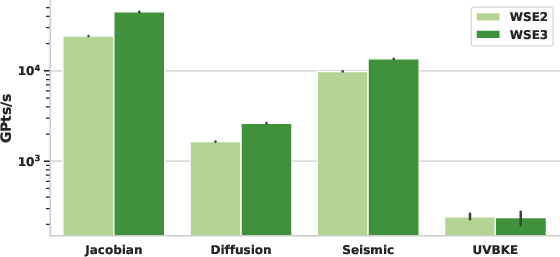
Figure 4: Throughput (GPts/s) comparison of WSE2 and WSE3 using MLIR codegen for large stencil kernels; WSE3 improvements are strictly due to architectural advances and codegen exploitation.
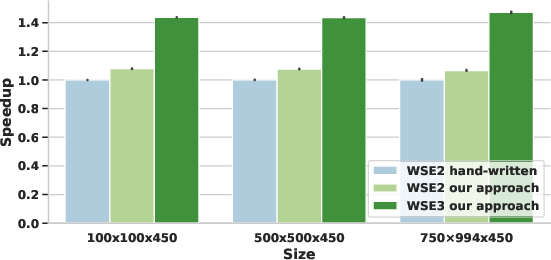
Figure 5: Compiler-generated seismic benchmark outperforms hand-crafted CSL; task management and communication optimization explained.
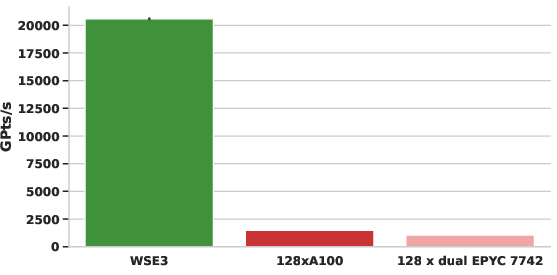
Figure 6: Devito acoustic benchmark on WSE3 surpasses clusters of A100 GPUs and CPU nodes, highlighting the time-to-solution benefit of wafer-scale acceleration.
Roofline Analysis
All stencil codes generated with this pipeline on WSE3 are compute-bound under local memory accesses; even under worst-case (fabric) access patterns, most remain compute-bound, whereas the A100 GPU executions are memory-bound.
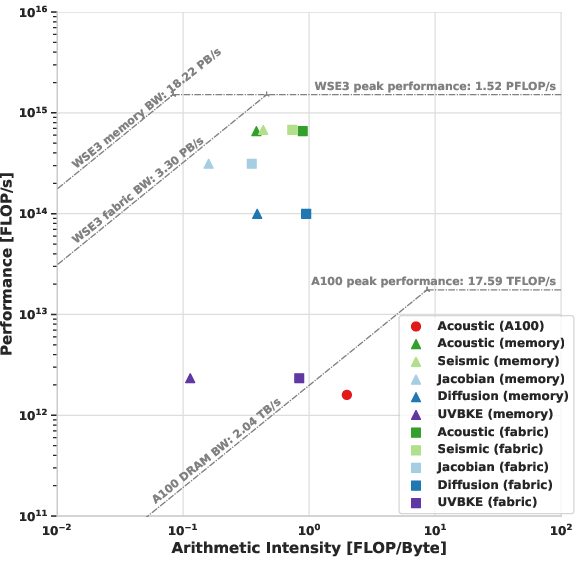
Figure 7: Roofline analysis of benchmark kernels: WSE3 executions approach the compute-bound regime, in contrast with GPU implementations that saturate the memory bandwidth ceiling.
Productivity Metrics
The approach delivers a drastic reduction in programmer effort: the required DSL code (via domain-specific abstraction and automatic codegen) is 10–35× shorter than corresponding manual CSL implementations, with full algorithmic fidelity.
Implications and Future Directions
The presented MLIR lowering pipeline establishes a systematic framework for exploiting complex dataflow architectures in scientific computing without altering user-level code. The architecture-agnostic preservation of high-level semantics enables potent optimizations, including communication-compute overlap and memory footprint reduction, relevant both to WSE and other emerging CGRA/classic HPC accelerators. By decoupling frontend DSLs from hardware-specific backend transformation, research can focus on algorithmic development and expand WSE adoption in scientific domains historically reliant on CPU/GPU clusters.
The pipeline’s modular nature and MLIR/xDSL foundation suggest immediate applicability for targets beyond the WSE, such as spatial dataflow languages and next-generation AI hardware from AMD, Tenstorrent, and others. Future work should consider automated routing pattern synthesis, robust actor-model control-flow abstractions, and deeper integration with machine learning workloads—particularly those employing dynamic or adaptive stencil computation.
Conclusion
This work demonstrates that domain-specific IR combined with MLIR-driven lowering pipelines enables the automatic, high-performance deployment of stencil codes on wafer-scale architectures. The authors provide evidence of performance parity and portability against tuned manual code, superior throughput versus contemporary HPC clusters, and dramatic improvements in developer productivity. The open-source implementation and extensible design form a basis for future compiler research targeting highly parallel, asynchronous hardware architectures in scientific computing.