DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
Abstract: Reinforcement learning with verifiers (RLVR) is a central paradigm for improving LLM reasoning, yet existing methods often suffer from limited exploration. Policies tend to collapse onto a few reasoning patterns and prematurely stop deep exploration, while conventional entropy regularization introduces only local stochasticity and fails to induce meaningful path-level diversity, leading to weak and unstable learning signals in group-based policy optimization. We propose DSDR, a Dual-Scale Diversity Regularization reinforcement learning framework that decomposes diversity in LLM reasoning into global and coupling components. Globally, DSDR promotes diversity among correct reasoning trajectories to explore distinct solution modes. Locally, it applies a length-invariant, token-level entropy regularization restricted to correct trajectories, preventing entropy collapse within each mode while preserving correctness. The two scales are coupled through a global-to-local allocation mechanism that emphasizes local regularization for more distinctive correct trajectories. We provide theoretical support showing that DSDR preserves optimal correctness under bounded regularization, sustains informative learning signals in group-based optimization, and yields a principled global-to-local coupling rule. Experiments on multiple reasoning benchmarks demonstrate consistent improvements in accuracy and pass@k, highlighting the importance of dual-scale diversity for deep exploration in RLVR. Code is available at https://github.com/SUSTechBruce/DSDR.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning”
1) What is this paper about?
This paper is about teaching LLMs to reason better—especially on math and logic problems—using a training method called reinforcement learning with verifiers (RLVR). The authors found that during training, models often get stuck using just a few similar solution styles and stop exploring other correct ways to solve problems. To fix this, they created DSDR, a new training strategy that encourages the model to discover and maintain multiple good, different ways of reasoning while also keeping each way flexible rather than overly rigid.
2) What questions are the authors trying to answer?
The paper asks simple but important questions:
- How can we get an LLM to explore different correct solution paths during training, instead of collapsing to one style?
- How can we keep the model’s reasoning flexible within each correct style, so it doesn’t become too confident in a narrow pattern and miss nearby correct variations?
- Can we do both at the same time—explore broadly and stay flexible—without hurting correctness?
3) How does their method work? (Explained with everyday analogies)
Think of solving a maze:
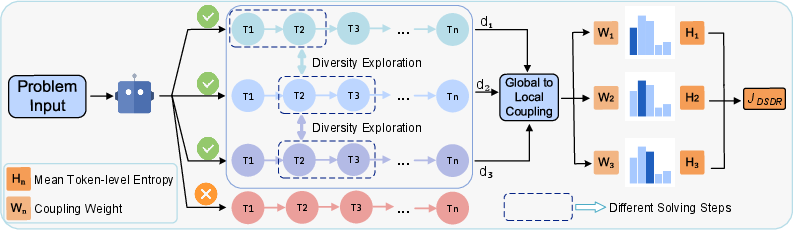
- Global diversity: This is like encouraging the explorer to try different main routes through the maze (not just tiny wiggles on the same path). The model gets extra credit for finding correct solutions that are meaningfully different from other correct ones in the same group.
- Local diversity: This is like keeping some healthy “wiggle room” within a chosen route, so the explorer doesn’t walk the exact same footsteps every time. In model terms, that means adding a bit of randomness to word-by-word choices, but only for solutions that are correct.
Now, how is this done during training?
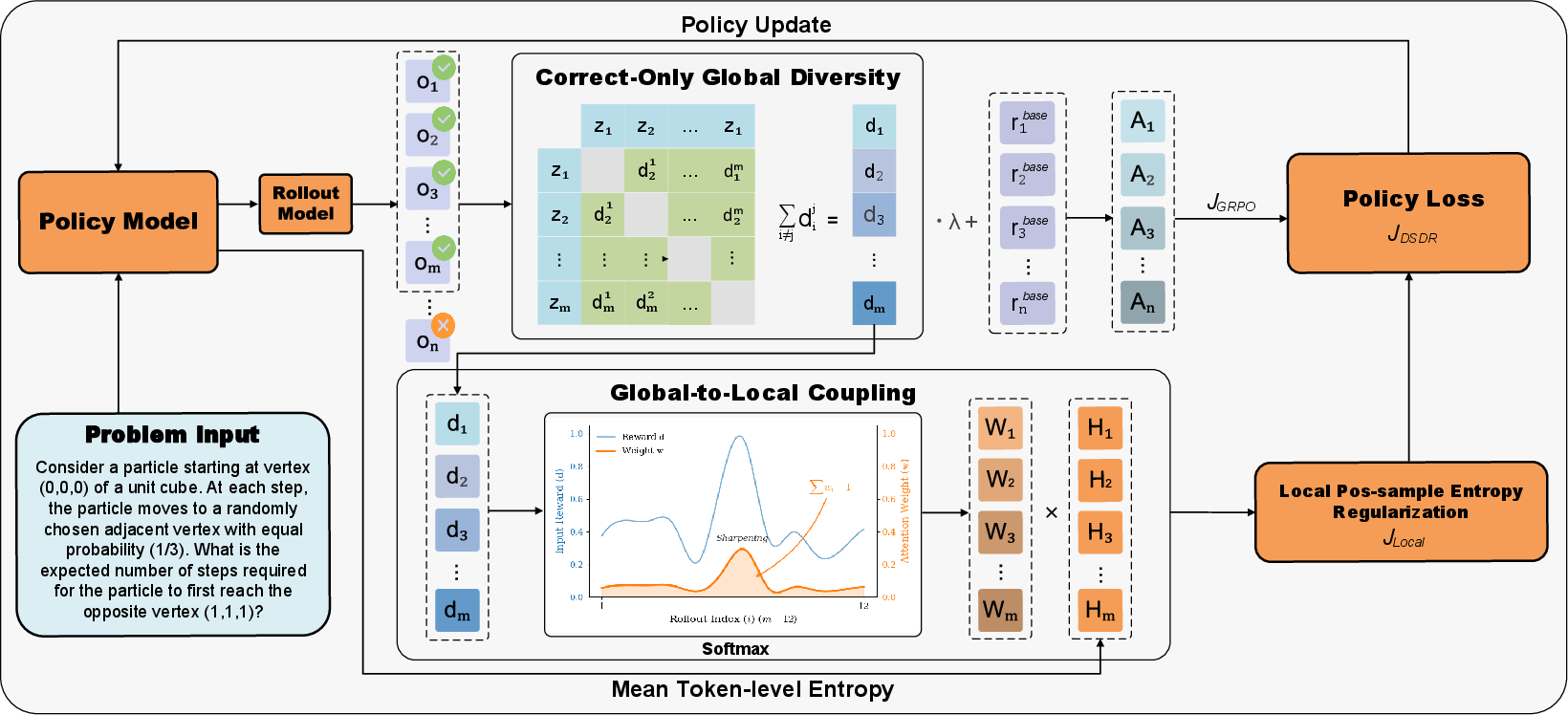
- Group-based training (GRPO): For each problem, the model writes several answers. A “verifier” checks whether each answer is correct (like a teacher grading). The training then compares these answers within the group to decide how to update the model.
- Global diversity score: The model is rewarded a little more if a correct answer is different from other answers—both in overall meaning (semantic differences) and in math formulas used (symbolic differences).
- Local entropy regularization: Entropy is a technical word for “keeping some randomness.” Here, it’s applied at the token (word) level, and averaged across the answer length so long answers don’t get a free pass. Importantly, this randomness is only applied to correct answers, so we don’t encourage mistakes.
- Coupling the two: The most distinctive correct solutions get more of this local randomness. That means the model expands the promising, unique paths instead of sprinkling randomness everywhere. You can think of it as “invest more exploration in the routes that add new coverage of the maze.”
Key terms in simple language:
- Verifier: Checks if an answer is correct (like an auto-grader).
- Diversity: Answers that follow different reasoning styles or use different formulas.
- Entropy: Encouraging small, controlled randomness in choices, so the model doesn’t become too rigid.
- Pass@k: If the model tries k times per problem, pass@k is the chance it solves the problem at least once.
The authors also provide theory showing:
- Adding this local randomness in the right way does not reduce the ability to find correct answers.
- Adding global diversity rewards keeps the learning signal strong (important when many answers in a group are already correct).
4) What did they find, and why is it important?
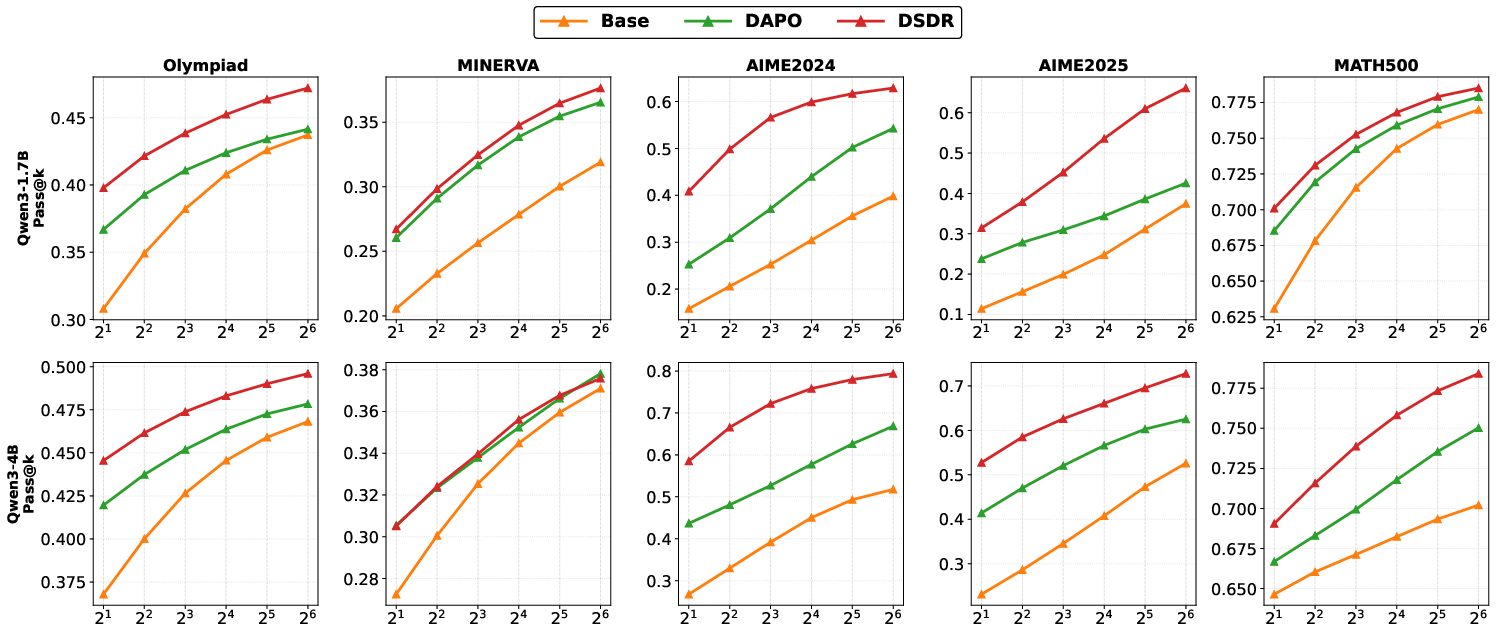
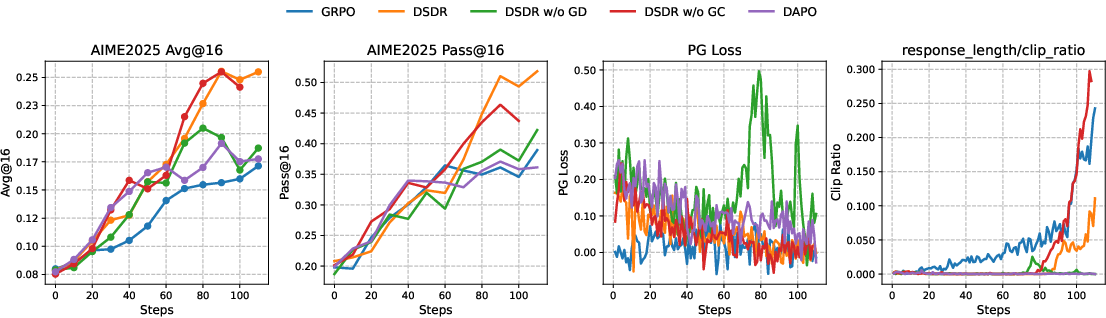
Across multiple math benchmarks (like AIME 2024/2025, Olympiad, MATH500, and Minerva) and different model sizes, DSDR:
- Increased accuracy (more correct answers on the first try).
- Improved pass@k (the chance of getting a correct answer when trying multiple times).
- Made training more stable (less chance of getting stuck in one way of solving).
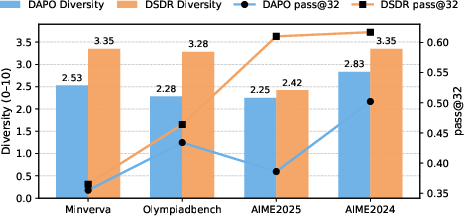
- Produced more diverse correct solutions (not just different wording, but different reasoning and formula use).
Why this matters:
- If a model only learns one rigid pattern, it struggles with new or tricky problems. By keeping multiple correct styles and staying flexible inside each style, the model can handle a wider range of tasks and generalize better.
5) What is the bigger impact?
The approach helps LLMs become better “thinkers,” not just better “parrots.” It teaches them to:
- Explore many valid reasoning paths.
- Avoid getting stuck in a single template.
- Stay correct while being flexible.
This can benefit real-world uses where careful step-by-step reasoning matters, such as math tutoring, coding help, scientific problem solving, and other tasks where there’s more than one right way to reach the answer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work:
- Early-stage sparse positives: Because local entropy is applied only to correct rollouts, exploration may be starved when few or no correct samples are produced. How should DSDR be adapted for low-reward regimes (e.g., warm-start curricula, partial-credit gating, or confidence-weighted verifiers)?
- Noisy or imperfect verifiers: The method assumes reliable binary rewards. How robust is DSDR to verifier noise, false positives/negatives, or partial-credit signals? Evaluate with controlled label noise and probabilistic verifiers.
- Applicability beyond math: The formula-level diversity component is math-specific. How does DSDR generalize to code, logical proofs, scientific reasoning, or multimodal tasks where “formula uniqueness” is undefined? Identify task-appropriate structural diversity proxies (e.g., ASTs, proof trees, program traces).
- Diversity metric sensitivity: The global diversity score uses a frozen sentence encoder (all-MiniLM-L6-v2) and simple formula extraction. How sensitive are gains to the encoder choice, domain mismatch, or embedding drift? Benchmark stronger/alternative encoders and task-tuned embeddings.
- Reliability of formula extraction: Errors in extracting S(o_i) directly affect D_eq(o_i). Quantify extraction accuracy, its impact on training, and compare multiple parsers or symbolic normalizers; assess behavior when S(o_i)=0 frequently.
- Reward hacking via superficial diversity: Models may inflate embedding distance or produce spurious “unique” formulas without genuine reasoning diversity. Develop and test more robust trajectory-level metrics (e.g., CoT graph distances, equivalence-class checks, normalization of algebraic forms).
- Degeneracy when few correct rollouts: The global-to-local softmax allocation requires at least one positive. What fallback allocation (e.g., uniform over all, near-correct, or heuristic diversity) preserves exploration when |𝒫|∈{0,1}?
- Exploration on near-correct trajectories: Correct-only gating ignores incorrect but promising paths. Can verifier confidence or graded rewards enable local entropy allocations that nurture near-correct modes without degrading correctness?
- Variance and bias in the local entropy estimator: The importance-sampling form ρ_{i,t}·log π may have high variance and off-policy bias. Assess and mitigate with per-step ratio clipping, self-normalized estimators, control variates, or doubly robust alternatives.
- Interaction with PPO-style clipping and KL regularization: The joint effects of local entropy, GRPO clipping, and the reference KL penalty are not analyzed. Provide theory/ablation on stability and performance across β, ε_c, and entropy strength.
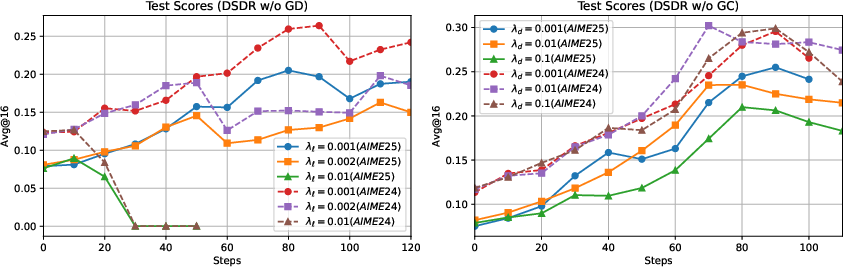
- Hyperparameters beyond λ_ℓ and λ_d: The paper does not probe τ (softmax temperature), σ_d (diversity clip), group size G, or rollout sampling temperature. Study principled schedules, adaptive tuning, and their stability impact.
- Compute and memory scaling: Pairwise diversity computation and formula uniqueness checks are O(G²). Quantify wall-clock overhead at larger G and longer outputs, and evaluate approximations (e.g., kernel sketches, sub-sampling, ANN).
- Length and verbosity effects: Averaging entropy over tokens aims for length invariance, but entropy incentives can still elongate outputs via exploration. Measure changes in response length, conciseness, and the trade-off with correctness.
- Out-of-distribution and compositional generalization: Beyond pass@k, does DSDR improve generalization to novel compositions, harder distributions, or domain transfer? Include OOD splits and compositionality benchmarks.
- Inference-time synergy: Interactions with decoding strategies (temperature, nucleus/top-k, diverse beam, best-of-N reranking) are unreported. Study whether DSDR complements or substitutes test-time diversification.
- Alternative global diversity formulations: The simple average of embedding and formula signals may not align with true “mode” diversity. Compare edit distances over reasoning steps, proof/program structural metrics, and learned trajectory embeddings.
- Sensitivity to reference policy choice: How does the choice of π_ref and KL strength β affect DSDR’s gains? Can DSDR reduce dependence on a strong KL anchor without sacrificing stability?
- Stress tests with adversarial or ambiguous prompts: Does diversity shaping amplify spurious “correct” solutions under flaky verifiers? Evaluate robustness under adversarial inputs and ambiguous tasks.
- Continuous rewards and learned reward models: Extend correct-only gating to continuous or learned reward settings (e.g., RM-trained verifiers). How should diversity bonuses be calibrated with graded reward scales?
- Multi-task/multi-domain training: Can a single diversity encoder and allocation rule serve varied tasks, or is task-conditioned diversity modeling required? Explore shared vs. per-task diversity modules.
- Practical bounds for correctness preservation: Theoretical guarantees rely on “bounded regularization.” Provide empirical diagnostics and concrete parameter ranges that ensure correctness is preserved in practice.
- Finer-grained local allocation: Local entropy is applied uniformly across tokens of a correct trajectory. Would step- or module-aware allocation (e.g., higher entropy on early strategic decisions or branching points) be more effective?
- Dependence on rollout sampling temperature: Diversity scores and allocations depend on group composition shaped by sampling temperature. Characterize this dependence and recommend robust settings.
- Diversity evaluation reliability: The LLM-as-a-judge diversity metric is subjective and model-dependent. Validate with human studies or task-grounded automatic metrics to ensure diversity reflects distinct solution modes.
- Safety considerations: Encouraging diversity can increase off-distribution or unsafe generations in open domains. Define filtering/safety mechanisms compatible with DSDR’s exploration incentives.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging DSDR’s dual-scale diversity regularization within reinforcement learning with verifiers (RLVR) for LLM reasoning.
- Bolden RLVR training pipelines with DSDR (AI labs, model providers; Software) Description: Integrate DSDR’s correct-only global diversity bonus and diversity-weighted local entropy into existing GRPO/DAPO-style training to improve pass@1 and pass@k, stability, and generalization. Tools/products/workflows: “DSDR Trainer” module; DiversityScore component (semantic embedding + optional symbolic extractor); Correct-only entropy regularizer; dashboards for group reward variance and diversity. Assumptions/Dependencies: Verifiable rewards for tasks (unit tests, checkers, solvers); batch/group sampling budget (G rollouts per prompt); a lightweight encoder for semantic diversity; careful tuning of λd, λℓ, τ; KL and clipping remain stable.
- Higher-quality code assistants via unit-test–verified RL (Developer tooling; Software) Description: Train/code-tune assistants against unit tests as verifiers to produce multiple distinct correct implementations, improving top-k suggestion quality and robustness. Tools/products/workflows: DSDR-tuned Copilot-like engines; test-driven RL loops; pass@k-aware UI that surfaces diverse correct solutions. Assumptions/Dependencies: Reliable unit tests/coverage; compute budget for group sampling; domain-specific diversity extractors beyond formulas (e.g., AST/IR differences).
- Math tutoring and assessment with multiple correct strategies (EdTech; Education) Description: Produce step-by-step solutions that deliberately explore and present several correct methods (algebraic, geometric, numeric), improving learning and assessment robustness. Tools/products/workflows: DSDR-tuned math tutors; multi-solution explainers; teacher dashboards showing solution-mode coverage. Assumptions/Dependencies: Verifiers (answer checkers, symbolic solvers); light-weight formula extraction; bias control so diversity remains pedagogically relevant.
- Safer SQL/ETL generation under schema and constraint verifiers (Data platforms; Software) Description: Generate diverse but valid SQL/ETL pipelines that satisfy schema/type constraints and unit checks, improving success rates and pass@k utility. Tools/products/workflows: Schema/type checkers as verifiers; diversity-aware candidate generation; top-k reranking by cost/latency. Assumptions/Dependencies: Strong verifiers (schema, constraints, test tables); embedding choices that capture plan-level differences, not just surface text.
- Interactive RAG reasoning with calculators/solvers as verifiers (Enterprise assistants; Software) Description: Couple RAG chains with verifiers (calculators, rule engines) to maintain multiple correct reasoning paths, improving reliability of multi-step answers. Tools/products/workflows: DSDR-tuned chain-of-thought; diversity-aware beam/sampling; pass@k aggregation across verified chains. Assumptions/Dependencies: Verifiable sub-steps; cost control for multi-rollout sampling; prevention of spurious diversity via clipping.
- Automated theorem assistance with diversified correct sketches (Research tooling; Academia) Description: Generate multiple correct proof sketches (or proof-search heuristics) verified by proof assistants (Lean/Isabelle/Coq) to reduce brittleness and mode collapse. Tools/products/workflows: Verifier bridge to proof assistants; symbolic diversity metrics (tactics used, lemma sets). Assumptions/Dependencies: Stable verifier integration; careful reward shaping to avoid over-optimizing for trivial proof scripts.
- Multi-solution UX for end-users (Daily life; Education/Software) Description: “Show me 3 correct ways” features for math, code snippets, and puzzles; increased pass@k means the assistant can safely offer diverse correct options. Tools/products/workflows: Top-k display with solution-mode tags; user feedback to preference-rank modes. Assumptions/Dependencies: Correctness verification for tasks; sensible diversity labels users can interpret.
- Evaluation and procurement protocols emphasizing diversity among correct solutions (Policy, MLOps; Cross-sector) Description: Add pass@k and “diversity among correct” metrics to model evaluations to avoid brittle single-mode models and improve generalization. Tools/products/workflows: Diversity dashboards (semantic/formula-level); LLM-as-a-judge diversity audits (with guardrails). Assumptions/Dependencies: Calibrated judges or domain-specific metrics; avoidance of reward hacking via clipping and correct-only shaping.
- Training-stability monitors for group-based RL (MLOps; Software) Description: Monitor group reward variance and correct-only diversity to detect/mitigate signal degeneracy; auto-tune λd, λℓ, τ when variance collapses. Tools/products/workflows: “Variance watchdog” and “Entropy watchdog”; auto-schedulers that increase local entropy only around globally distinctive positives. Assumptions/Dependencies: Reliable telemetry from training; safe hyperparameter ranges; compatibility with PPO/GRPO clipping/KL.
- Domain-adapted diversity scoring (Industry research; Software) Description: Swap in domain-specific descriptors (e.g., control-flow graphs for code, plan graphs for planning) for more faithful global diversity than raw text embeddings. Tools/products/workflows: Pluggable diversity backends; schema to define what “distinct mode” means per domain. Assumptions/Dependencies: Cheap extraction of domain features; bounded/clipped bonus to preserve correctness.
Long-Term Applications
These applications are promising but require further research, verification infrastructure, or scaling.
- Robotics and industrial planning with simulator/verifier feedback (Robotics/Manufacturing) Description: Train planners to maintain multiple correct task plans validated in simulation (collision-free, resource-feasible), improving reliability and avoiding local optima. Tools/products/workflows: Sim-as-a-verifier; plan-graph diversity scoring; pass@k execution-time selection. Assumptions/Dependencies: High-fidelity simulators; cost-efficient group rollouts; safety constraints and domain-specific diversity measures.
- Clinical decision support with guideline/pathway verifiers (Healthcare) Description: Diversify correct clinical reasoning under verifiable constraints (dosage ranges, contraindications), increasing robustness of suggestions while staying within safety boundaries. Tools/products/workflows: Guideline/rule engines as verifiers; multi-path care-plan generation; human-in-the-loop triage. Assumptions/Dependencies: Strong, auditable verifiers; regulatory approvals and rigorous evaluation; careful control of exploration to avoid unsafe drift.
- Financial scenario generation and portfolio construction under constraints (Finance) Description: Produce multiple correct, constraint-satisfying strategies (risk limits, regulatory rules) that pass solver checks, improving pass@k for decision support. Tools/products/workflows: Optimization solvers as verifiers; scenario generators with diversity-aware sampling. Assumptions/Dependencies: Precise formalization of constraints; partial-credit/graded verifiers for noisy objectives; robust out-of-distribution handling.
- Scientific discovery assistants generating diverse, testable hypotheses (Science/Pharma) Description: Encourage multiple correct, non-redundant hypotheses or experimental plans that satisfy known constraints and mechanistic checks. Tools/products/workflows: Knowledge-graph/causal-check verifiers; lab-automation loops selecting among pass@k. Assumptions/Dependencies: Formal hypothesis/constraint encoding; partial verifiers and probabilistic rewards; expensive feedback loops.
- Multi-agent systems with correctness-aligned diversity (Agents; Software) Description: Train ensembles/roles with DSDR so globally distinctive, correct proposals receive more local exploration, improving team coverage and collaboration. Tools/products/workflows: Diversity-weighted role assignment; correct-only cross-agent credit. Assumptions/Dependencies: Verifiers for team outputs; coordination protocols; scaling costs.
- Multimodal reasoning with verifiable subgoals (Vision+Language, Geo/Diagram math) Description: Extend global diversity scoring to multimodal embeddings and symbolic diagram constraints, preserving multiple valid multimodal reasoning paths. Tools/products/workflows: Multimodal encoders for diversity; diagram/geometry solvers as verifiers. Assumptions/Dependencies: High-quality multimodal verifiers; robust, cheap embeddings; task-specific symbol extraction.
- Energy and logistics scheduling under hard constraints (Energy/Supply chain) Description: Generate multiple feasible schedules (unit commitment, routing) validated by constraint solvers/simulators; improve resilience by maintaining diverse feasible plans. Tools/products/workflows: MILP/CP/SAT solvers as verifiers; plan-diversity metrics (resource, topology differences). Assumptions/Dependencies: Strong solvers; long-horizon verification costs; partial-credit reward shaping for near-feasible solutions.
- Standards and policy for “diversity among correct” in AI evaluation (Policy/Standards) Description: Codify pass@k and correct-only diversity as procurement and certification criteria to reduce brittleness and mode collapse in reasoning systems. Tools/products/workflows: Public benchmark suites with diversity metrics; auditing protocols to detect reward hacking. Assumptions/Dependencies: Community consensus on metrics; robust open verifiers; safeguards against gaming embedding-based diversity.
- Open-source DSDR SDKs and hardware-optimized training recipes (AI tooling; Software) Description: Mature libraries that package global-to-local coupling, domain-specific diversity modules, and training monitors, optimized for multi-GPU/TPU clusters. Tools/products/workflows: SDK with plug-ins for verifiers and diversity backends; recipes for scaling group size G without destabilizing PPO/GRPO. Assumptions/Dependencies: Broad task verifiers; compatibility across frameworks; community maintenance and benchmarking.
Notes on feasibility and risks across applications:
- DSDR is most effective on verifiable tasks (binary or graded); tasks without reliable verifiers may not benefit or could be destabilized.
- Embedding-based global diversity must reflect path-level differences; domain-specific representations often outperform generic sentence embeddings.
- Clipping and correct-only shaping are essential to prevent reward hacking; hyperparameters (λd, λℓ, τ) require careful tuning to preserve correctness.
- Compute costs rise with group sampling; budget-aware implementations (e.g., adaptive group sizes, cached embeddings) improve practicality.
Glossary
- advantage: A normalized signal measuring how much a sampled response’s reward exceeds the group mean, used to guide policy updates. "Specifically, the advantage for each response is computed as"
- autoregursive factorization: A way to model sequence probability as a product of conditional token probabilities. "following autoregressive factorization"
- Avg@16: An evaluation metric that averages correctness over 16 independent rollouts per problem. "We report Pass@1 and Avg@16 () accuracy across different model scales."
- cosine distance: A bounded measure of dissimilarity between normalized embedding vectors, defined from cosine similarity. "we define their embedding dissimilarity via cosine distance."
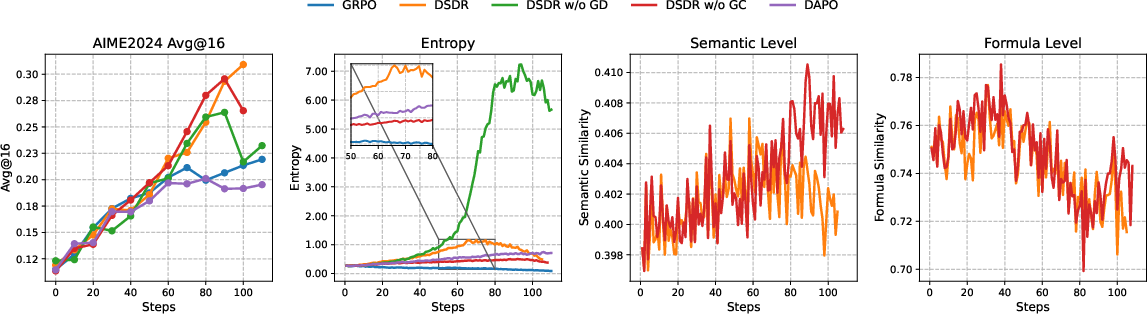
- diversity shaping: Modifying rewards to encourage diversity, applied only to correct solutions to align exploration with correctness. "Accordingly, DSDR applies diversity shaping exclusively to positive rollouts"
- diversity-weighted softmax: A softmax weighting over diversity scores used to allocate local regularization among correct rollouts. "We allocate local regularization strength via a diversity-weighted softmax over correct responses:"
- entropy collapse: Premature reduction of token-level uncertainty within a reasoning mode, leading to brittle, overconfident behavior. "preventing entropy collapse within each mode while preserving correctness."
- entropy regularization: Adding an entropy bonus to encourage stochasticity in the policy. "Entropy regularization~\cite{shen2025entropy, chen2025pass, agarwal2025unreasonable}, widely used in RL and RLVR, injects token-level stochasticity"
- global-to-local allocation mechanism: A coupling strategy that allocates local regularization intensity based on global distinctiveness of correct trajectories. "these two scales are coupled through a global-to-local allocation mechanism, which prioritizes local regularization for more distinctive correct trajectories."
- Group Relative Policy Optimization (GRPO): A group-based variant of PPO that normalizes rewards within sampled sets to stabilize training. "Group Relative Policy Optimization (GRPO)~\cite{guo2025deepseek}"
- group-based policy optimization: Methods that use relative comparisons within sampled groups to stabilize RL training. "Group-based policy optimization methods, such as GRPO~\citep{guo2025deepseek}, further improve training stability by exploiting relative comparisons among sampled solutions"
- group-normalized RLVR: An RLVR setting where reward normalization within groups can weaken preference signals when many rollouts are correct. "and in group-normalized RLVR this concentration weakens within-group preference signals"
- group-relative learning signal: The informative signal formed by normalizing rewards within a group to compute advantages. "To obtain a group-relative learning signal, rewards are normalized within each group to form advantages."
- importance ratio: The ratio of target-policy to behavior-policy probabilities for a sampled token, used in off-policy objectives. "define the token-wise importance ratio $\rho_{i,t} = \pi_\theta(o_{i,t}\mid q,o_{i,<t}) / \pi_{\theta_{\text{old}(o_{i,t}\mid q,o_{i,<t})$."
- importance sampling: Estimating expectations under one distribution using samples from another via weighted re-expression. "We therefore re-express the inner expectation using standard importance sampling~\cite{precup2000eligibility, sheng2025espo, yao2025diversity}"
- KL regularization: Penalizing divergence from a reference policy using the Kullback–Leibler term to constrain updates. "β controls the KL regularization strength"
- lagged behavior policy: The older policy used to sample rollouts for group-based optimization. "from a lagged behavior policy $\pi_{\theta_{\text{old}$"
- Pass@1: Accuracy computed from a single rollout per problem. "We report Pass@1 and Avg@16 () accuracy across different model scales."
- Pass@k: The probability that at least one of k sampled solutions is correct. "Pass@k performance across five benchmarks for both Qwen3-1.7B and Qwen3-4B."
- policy entropy: The entropy of the policy’s action distribution, indicating its stochasticity. "policy entropy"
- policy gradient: The gradient of the objective with respect to policy parameters used to update the policy. "Then the policy gradient of admits the form"
- PPO-style clipped surrogate objective: A stabilized objective that clips importance ratios to limit overly large policy updates. "Optimization is performed using a PPO-style clipped surrogate objective at the token level."
- reference policy: A fixed policy used as an anchor in KL regularization. "$\pi_{\text{ref}$ is a fixed reference policy."
- Reinforcement learning with verified reward (RLVR): A training paradigm where a verifier provides outcome-based rewards to guide reasoning. "Reinforcement learning with verified reward (RLVR)~\citep{liu2024deepseek, shao2024deepseekmath} has recently emerged as a powerful paradigm"
- reward hacking: Exploiting the reward function to gain undesired advantages without genuine task improvement. "To prevent reward hacking~\cite{pan2022effects}"
- rollout: A full sequence generated by the policy for evaluation or training. "we sample a group of rollouts "
- self-normalized Monte Carlo: An estimator that uses normalized weights to compute expectations from samples. "the self-normalized Monte Carlo form of~\eqref{eq:tilted_pg} assigns weights"
- temperature parameter: A scalar controlling the concentration of the softmax weighting. "where is a temperature parameter."
- time-averaged conditional entropy: Entropy computed per time step and averaged over the sequence length to avoid length bias. "We start from the time-averaged conditional entropy:"
- token-level entropy regularization: An entropy bonus applied at the token level to encourage local stochasticity in generation. "a length-invariant, token-level entropy term applied exclusively to correct solutions."
- verifier: A component that evaluates completed sequences and returns a scalar reward. "A verifier provides a scalar reward "
Collections
Sign up for free to add this paper to one or more collections.