- The paper introduces a uniqueness-aware RL formulation that rewards rare, correct solution strategies by inversely weighting policy advantages within grouped rollouts.
- The method achieves systematic improvements in AUC@K across domains like mathematics, physics, and medicine while preserving pass@1 performance.
- The approach leverages an LLM judge for clustering strategies, sustaining exploration dynamics and enhancing human-like solution diversity.
Motivation and Background
Reinforcement learning (RL) has become the de facto method for post-training LLMs with the goal of improving their ability to solve complex, multi-step reasoning tasks. However, conventional RL paradigms induce exploration collapse, wherein the policy converges on a narrow set of high-reward reasoning trajectories, resulting in excessively concentrated solution modes and eroded rollout-level diversity. This manifests as improved pass@1 but stagnation or degradation of pass@k at moderate or large sampling budgets, especially in domains such as mathematics, physics, and medicine where users depend on diverse approaches.
Previous efforts to counteract exploration collapse have largely focused on token-level entropy regularization, low-probability token amplification, or pass@k-inspired objectives. However, these methods primarily induce surface-level diversity—altering the syntactic or low-level presentation of solutions—but are ineffective at sustaining genuine diversity in solution strategies (i.e., the set of distinct high-level reasoning approaches). The deficiency of such diversity-aware objectives highlights a discrepancy between the RL optimization target and the set-level requirements of robust creative problem solving.
Methodology: Uniqueness-Aware RL
The key innovation in "Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs" (2601.08763) is the introduction of an RL formulation that grants elevated learning signal to correct rollouts that instantiate rare, high-level solution strategies for a particular problem. The method operates as follows: for each training problem, multiple rollouts are sampled and grouped by an LLM-based "judge" into clusters of semantically equivalent solution strategies, disregarding superficial variation. The cluster size—i.e., the number of rollouts sharing a strategy—is used to inversely weight the policy advantage for each rollout. Thus, correct but uncommon solutions are promoted, while dominant strategies are downweighted, directly optimizing the policy for strategy-level diversity.
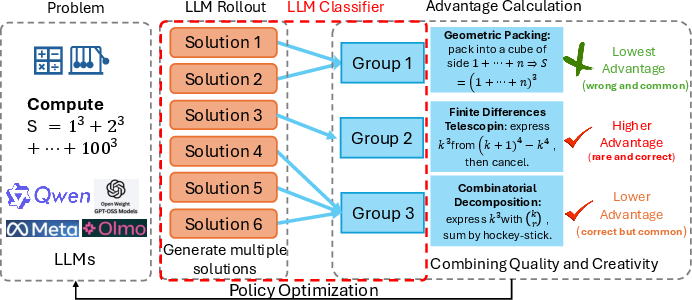
Figure 1: Uniqueness-Aware RL pipeline: rollouts are sampled, grouped by an LLM judge into clusters sharing solution strategies, and advantages are inversely reweighted using cluster sizes to encourage rare but correct solution modes.
The technical foundation builds on Group Relative Policy Optimization (GRPO), with the core modification being the reweighting of the group-normalized advantage by the uniqueness factor. The uniqueness weight is defined as wm,k=1/fm,kα, where fm,k is the size of the strategy cluster containing rollout k, and α is a tunable parameter controlling the strength of the diversity bias. This adjustment allows gradient updates to amplify learning signals for rare but valid solution plans.
Empirical Benchmarks and Results
Experiments were conducted on Qwen2.5-7B, Qwen3-8B, and OLMo-3-7B using hard subsets of mathematics (AIME, HLE), physics (OlympiadBench), and medical reasoning (MedCaseReasoning) datasets. The evaluation protocol involves sampling k rollouts at test time and computing pass@k across a range of k.
Key numerical findings include:
- Systematic improvement in AUC@K (area under the pass@k curve): Across all domains and models, the uniqueness-aware RL policy consistently outperforms both instruction-tuned and strong RL (GRPO) baselines, with the gains being most prominent in medium- and high-sampling regimes (e.g., on Qwen2.5-7B AIME at K=128, AUC@K increases from 0.184/0.207 to 0.242).
- No degradation of pass@1: The method attains higher or matched pass@1 compared to baselines, indicating that encouraging rare strategies does not sacrifice head performance.
- Outperforms other exploration-promoting methods: Uniqueness-aware RL exceeds DAPO and Forking Token approaches in both global pass@k and solution diversity coverage metrics across model families.
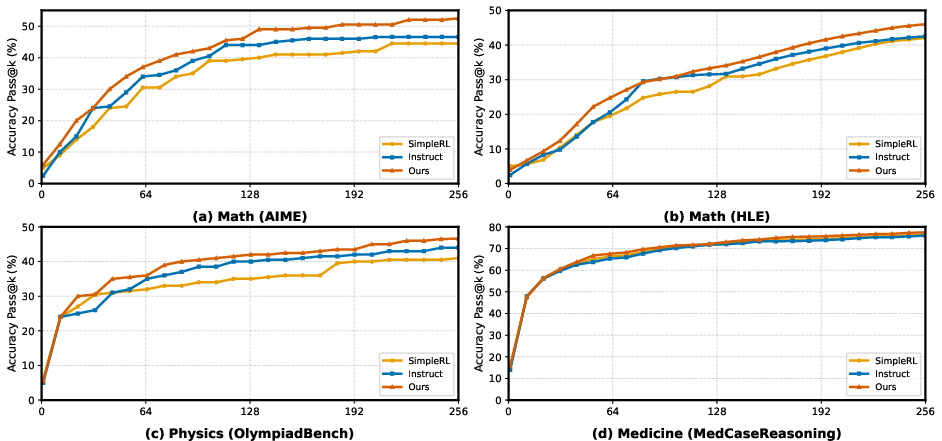
Figure 2: Pass@k accuracy curves for math, physics, and medicine benchmarks, demonstrating superior scaling of coverage with sampling budget using uniqueness-aware RL.
Sustaining Entropy and Exploration Dynamics
A critical failure mode of standard RL is the progressive collapse of the policy entropy during training, which signals the concentration of probability mass onto a limited set of solution trajectories. The proposed approach mitigates this trend, as evidenced by persistently higher and more stable actor entropy during optimization compared to GRPO and entropy-clipping baselines. This sustains the exploration potential of the policy throughout training and prevents premature narrowing to canonical strategies.
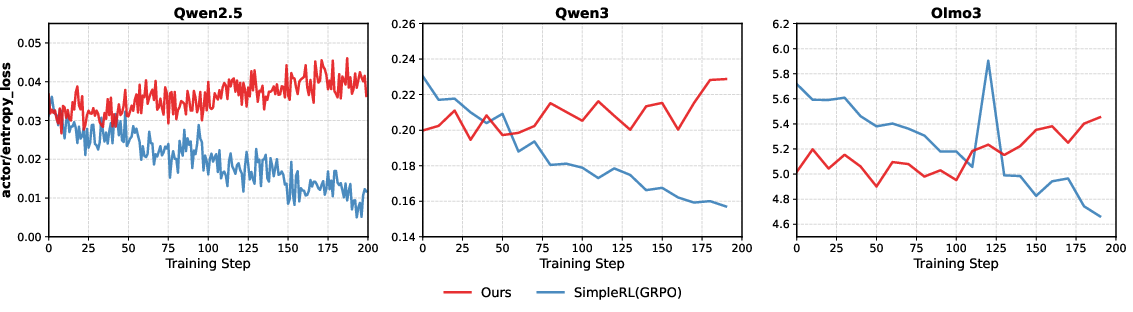
Figure 3: Entropy loss over training steps for several model families, showing that uniqueness-aware RL preserves exploration compared to the monotonic collapse observed with vanilla RL.
Analysis of Human Strategy Coverage
To quantify the practical effect on reasoning diversity, the authors introduce the cover@n metric, which measures the fraction of canonical human solution strategies recovered in the top n correct rollouts for a problem. Manual annotation and normalization of solution ideas were employed for challenging AIME problems. Uniqueness-aware RL models attain full or near-full cover@32 on complex problems, systematically recovering rarer, high-insight strategies (e.g., Symmedian Similarity or alternative combinatorial decompositions) that are absent in baseline outputs.
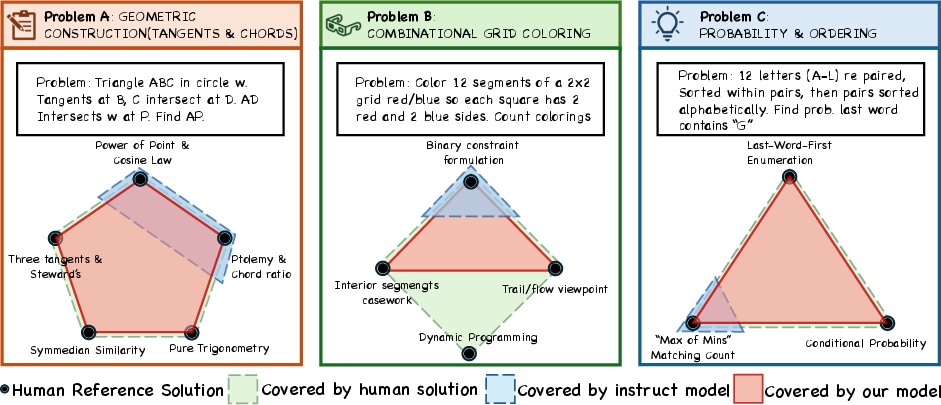
Figure 4: Visualization of solution diversity coverage (cover@32) on AIME problems, showing baseline models concentrate on low-complexity methods while uniqueness-aware RL recovers rare, human-annotated high-insight strategies.
Theoretical and Practical Implications
From a theoretical perspective, this work demonstrates that RL policies for LLMs can be efficiently regularized to exhibit desirable set-level properties—specifically, strategy diversity—without sacrificing primary performance objectives. The increased coverage of human-like strategies suggests a move toward policies that are more faithfully aligned with the creative and exploratory capacities demanded in advanced scientific, mathematical, and medical problem solving.
On a practical level, the use of an LLM as a judge to partition solution strategies is both scalable (by leveraging available larger models as inference-time oracles) and model-agnostic. The proposed method is compatible with established RL pipelines and introduces minimal additional computational overhead. The advancements offer direct utility in applications requiring robust generation of diverse problem-solving strategies, such as in educational contexts, scientific research assistants, or clinical decision support.
Limitations and Future Directions
The dependence on an LLM judge for strategy clustering introduces both computational costs and potential inconsistency, especially on problems where solution categorization is ambiguous. Additionally, the current formulation promotes uniqueness only within single-problem rollout sets and does not establish cross-problem or long-horizon novelty. Addressing these limitations via global rarity metrics, reducing judge reliance, or developing learned strategy representation modules are plausible avenues for advancing uniqueness-aware objectives.
Conclusion
Uniqueness-aware RL introduces an explicit, solution-strategy-level diversity bias into LLM post-training, preventing exploration collapse and inducing robust improvements in both coverage and diversity of complex reasoning processes across domains. The method reorients RL optimization toward practical goals—increasing the probability of users obtaining both correct and conceptually distinct solutions—and substantiates the feasibility of aligning LLM training objectives with creative human problem-solving behaviors. This trajectory opens further opportunities for principled diversity control, efficient judge-free implementations, and broadening the scope of RL-augmented LLM reasoning systems.