- The paper identifies GRPO's rank bias that favors high-probability proofs, leading to suboptimal large-N performance in reinforcement learning.
- It introduces an unlikeliness reward that penalizes common correct solutions, effectively uplifting low-probability proofs and improving pass@N metrics.
- Additional experiments show that increasing PPO epochs further mitigates bias, enhancing sample diversity and overall problem-solving capacity.
Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening
Introduction
This work systematically examines the multi-sample performance limitations of Group Relative Policy Optimization (GRPO) in reinforcement learning (RL) fine-tuning of LLMs, specifically in formal theorem proving. Contrary to the expectation that RL should systematically uplift all correct solutions, the analysis reveals a pronounced rank bias: GRPO predominantly reinforces high-probability solutions, neglecting rare—but correct—proofs. This bias induces distribution sharpening and impairs pass@N performance, especially for large values of N, which is critical for settings like theorem proving where verification is exact and the practical protocol involves extensive sampling.

Figure 1: Schematic depiction of GRPO’s rank bias, where model updates reinforce already probable solutions but fail to uplift low-probability correct solutions; the proposed unlikeliness reward explicitly mitigates this bias.
GRPO and Pass@N: Diagnosing the Rank Bias
Empirical Characterization
Empirical studies on a Lean-based theorem proving task demonstrate that fine-tuning DeepSeek-Prover-V1.5-SFT with standard GRPO protocol results in significant gains in pass@N for small N (e.g., pass@1 to pass@16), but deteriorates performance for large N compared to the base model. The implication is clear: GRPO sharpens the model’s distribution, increasing the likelihood of already probable solutions but failing to improve the mass on rare, correct completions. This narrowing effect becomes detrimental under protocols that rely on diversity through extensive sampling.
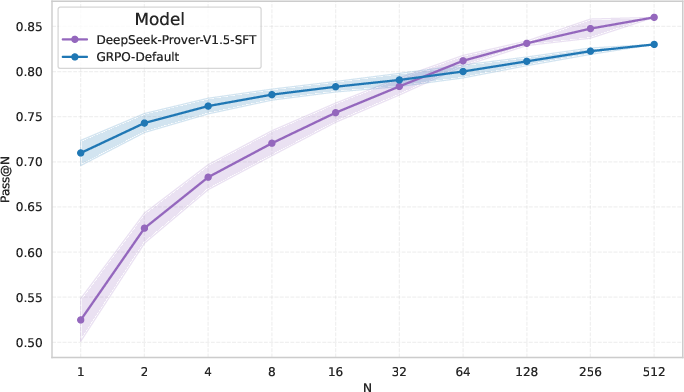
Figure 2: GRPO training leads to improved pass@N at small values but underperforms the base SFT model for large N.
Theoretical analysis reveals that optimizing pass@N for large N demands the RL objective not just increase the probability of top solutions, but also specifically uplift low-probability correct responses. Simulations confirm that a marginal ×(1 + ϵ) increase in correct solution probability only brings meaningful improvements in pass@N when those probabilities are in the O(1/N) regime.
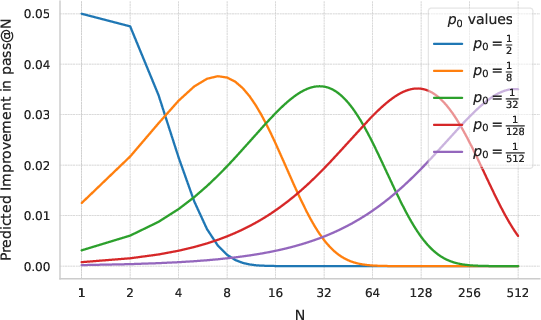
Figure 3: Analytical relationship between initial solution probability p0, the RL-induced multiplicative improvement, and the expected pass@N gain; significant improvements at large N require uplifting rare solutions.
Quantifying Rank Bias
To isolate the source of the suboptimal pass@N, the authors introduce the uplift rate uj, measuring the tendency of GRPO to increase model probability for each rank among positive (correct) samples. The analysis unambiguously shows that GRPO almost never uplifts the model probability of the lowest-ranked (i.e., rarest) correct samples, confirming the existence and severity of rank bias.
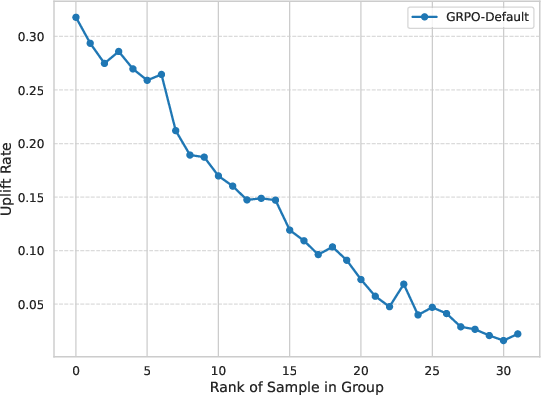
Figure 4: Uplift rate uj as a function of proof rank—GRPO disproportionately boosts high-probability correct samples and neglects rare ones.
Mitigating Rank Bias: Unlikeliness Reward and PPO Epoch Tuning
Unlikeliness Reward
To counteract rank bias, the work proposes the unlikeliness reward, which modifies the reward assignment by penalizing high-probability correct solutions and up-weighting low-probability ones. Specifically, the reward for a correct sample is scaled by a monotonic function of its inverse rank among policy outputs. This intervention directly incentivizes exploration and distributional diversity without impacting the expected gradient direction for correct samples.
Effect of Additional PPO Epochs
A complementary finding is that increasing the number of PPO epochs per batch attenuates rank bias. As high-probability solutions quickly saturate the PPO clipping bound, subsequent optimization steps emphasize low-probability samples, providing them with stronger learning signals. However, this approach brings a substantial increase in computational cost and potential instability, making unlikeliness reward the more sample-efficient and robust mitigation.
Experimental Validation
Main Results
Experiments on a Lean theorem proving benchmark compare several GRPO variants—including ones with unlikeliness reward and increased PPO epochs. Both modifications yield substantial improvements in pass@N for large N, with the unlikeliness reward being particularly effective. These improvements are not accompanied by significant degradation in single-sample accuracy, and overall, the total number of problems solved during training increases.
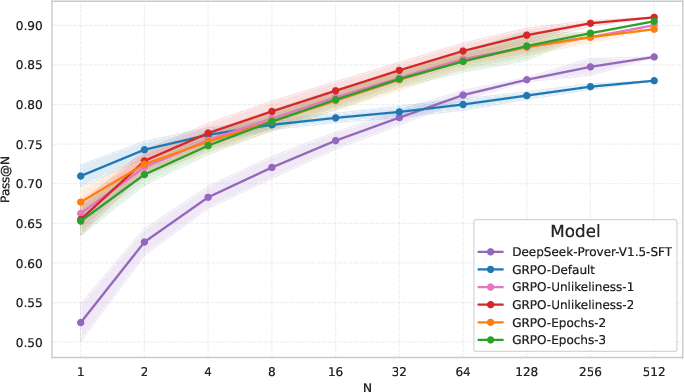
Figure 5: Pass@N performance across GRPO variants on the validation set; the unlikeliness reward and increased PPO epochs both markedly improve large-N accuracy.
Rank Bias and Sample Diversity Analysis
Extending the uplift rate analysis to GRPO variants, unlikeliness reward not only neutralizes the original bias but actually reverses it for the lowest-probability correct solutions. Furthermore, tracking the number of unique proofs generated shows that unlikeliness reward substantially increases sample diversity—a key factor for high pass@N.
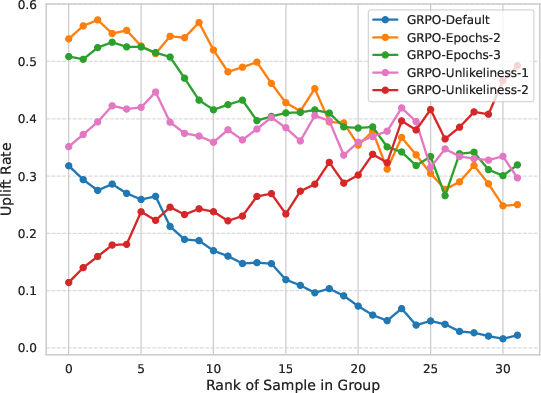
Figure 6: Uplift rate by rank for GRPO variants; the unlikeliness reward dramatically increases reinforcement for rare, correct samples.
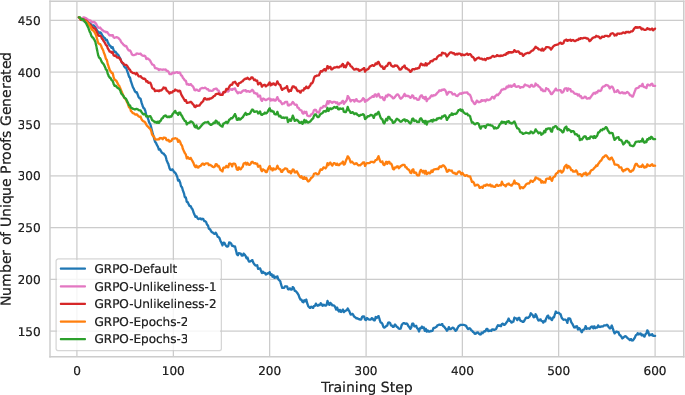
Figure 7: Evolution of unique proof diversity during training; unlikeliness reward yields a pronounced resurgence in diversity.
Large-scale Benchmarking
When scaling to a larger and more challenging Lean problem set, the GRPO-Unlikeliness-2 method achieves pass@32 and pass@128 metrics competitive with the strongest published RL models (DeepSeek-Prover-V1.5-RL) on the MiniF2F-test benchmark, establishing the practical efficacy of this simple modification to reward engineering.
Theoretical and Practical Implications
This work clarifies a central deficit in the application of RL to structured, verifiable reasoning tasks: by default, standard objectives like GRPO are misaligned with the desiderata of multi-sample discovery because they reinforce exploitation over exploration. The introduction of the unlikeliness reward directly connects reward structure to pass@N objectives, offering a methodologically principled and empirically validated solution.
The finding that PPO epoch count affects rank bias also suggests broader implications for the optimizer’s role in RL distributional behavior, motivating future research at the intersection of optimization schedules and reward shaping.
Conclusion
The analysis in "Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening" (2506.02355) identifies and remedies the critical distribution sharpening and rank bias of GRPO in formal theorem proving RL pipelines. The unlikeliness reward emerges as a lightweight yet powerful intervention, enabling models to achieve state-of-the-art or near state-of-the-art multi-sample performance while sustaining sample diversity and maintaining efficiency. This work establishes a new baseline methodology for RL fine-tuning in settings where diversity and exploration are critical, with implications extending to other structured generation tasks where exact verification enables large-scale sampling and evaluation.