Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Abstract: Reinforcement learning has become essential for strengthening the reasoning abilities of LLMs, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in LLM reinforcement learning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but powerful question: can a LLM learn to explore better by looking at how each answer would change its own learning, instead of relying on outside tricks? The authors propose a method called G²RL (Gradient-Guided Reinforcement Learning) that helps LLMs try new, useful ways of reasoning by focusing on the “directions” their learning would move, not just on making their outputs look different.
Key Questions
- How can we make an LLM explore smarter during training, so it finds better ways to solve problems?
- Instead of using outside signals (like making responses more random or comparing them with a separate model), can we guide exploration using the LLM’s own learning signals?
- Will this approach improve the LLM’s results on math and general reasoning tasks?
How It Works (Methods)
Think of training an LLM like practicing for a sport. Each practice attempt doesn’t just produce a result; it also nudges your “muscle memory” in a certain direction. The authors ask the model to pay attention to those nudges—its own learning directions—and prefer attempts that push learning in new and helpful directions.
The usual way vs. their way
- Usual exploration methods:
- “Entropy bonus”: encourage more randomness so the model tries varied answers. This can add noise without teaching the model anything new.
- “External comparisons”: use another model to check how different answers are. But that other model doesn’t share the same “brain,” so its idea of “different” might not help learning.
- G²RL’s idea:
- Use the LLM’s own internal signals to see how each answer would change its future behavior.
- Prefer answers that push learning in fresh directions, and downweight answers that repeat what others already teach.
Building a “direction” feature
For every answer the model generates, G²RL extracts a compact summary of how that answer would change the model’s predictions if it learned from it. You can think of this summary as an arrow that points in the “update direction” for the model’s parameters. The key trick:
- This arrow can be computed cheaply from a normal forward pass (no extra heavy training steps).
- The arrow uses the final layer’s sensitivity to the chosen tokens—roughly, how the model’s last step reacts to the output words.
Scoring novelty and shaping rewards
For a batch of answers to the same question:
- G²RL compares the arrows (directions) for all answers.
- If one answer’s arrow points in a new or orthogonal direction (not already covered by the others), it gets a higher score.
- If an answer’s arrow is very similar to higher-reward peers (it teaches the same thing), it gets a lower score.
- This score is turned into a small, bounded reward multiplier:
- Correct answers with new directions get boosted.
- Incorrect answers that are wildly off (pointing away from good directions) get penalized more.
- Incorrect answers that are “near misses” (aligned with correct directions) are penalized less, because they still teach something useful.
This reward shaping fits neatly into standard RL training (like PPO/GRPO), with stability controls that prevent the model from changing too quickly or drifting too far.
Safe and simple to run
- No extra backward passes (the expensive part of training).
- Bounded reward adjustments keep training stable.
- Easily plugs into existing RL pipelines.
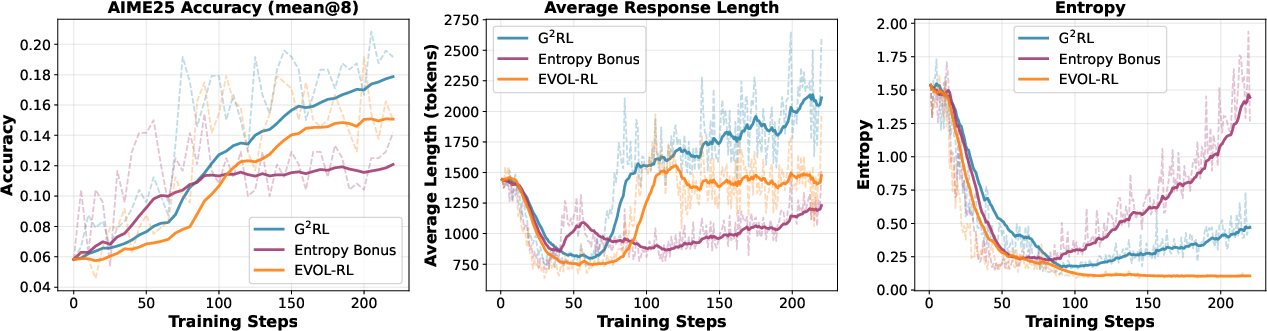
Main Findings
Across multiple math and reasoning tests, G²RL consistently improved performance compared to common exploration methods:
Here are some highlights:
- On MATH500 (4B model), “pass@16” rose to about 93.6%, slightly better than strong baselines.
- On AIME25 (4B), “pass@1” went from 17.5 (best baseline) to 20.1, and “maj@16” from 23.9 to 29.0—clear gains for one-try accuracy and majority-vote consistency.
- On GPQA (4B), “pass@1” improved to 38.7 and “maj@16” to 44.0, with strong multi-sample coverage.
- On MMLUpro (4B), “pass@1” micro-average rose to about 58.47, beating the baselines.
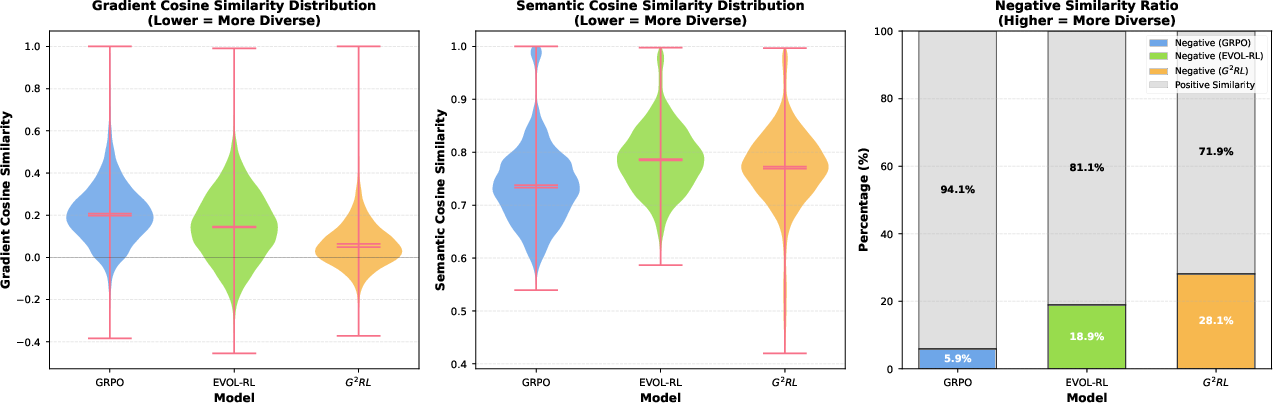
Just as important as the numbers, the authors show that G²RL changes the “shape” of exploration:
- It increases the variety of learning directions (more orthogonal or even opposing arrows), which helps the model learn new skills instead of repeating the same pattern.
- It keeps answers semantically coherent (on-topic and consistent) while still exploring different update directions—so it’s not just adding randomness.
Why It Matters
- Better exploration means better learning: Rather than rewarding answers that only look different, G²RL rewards answers that teach the model something structurally new.
- More reliable training: By staying within stable RL rules and keeping rewards bounded, the method improves results without causing training chaos.
- Practical and efficient: It needs only the normal forward pass and integrates smoothly with popular RL training methods.
Takeaway
G²RL shows that the best way to guide an LLM’s exploration is to use the model’s own learning signals. By preferring answers that move its “learning arrow” in fresh directions, the model becomes better at solving complex problems. This approach is simple to add, stable to train, and effective across math and general reasoning tasks—suggesting a new, geometry-aware path for improving LLM reasoning with reinforcement learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for follow-up research.
- Empirical fidelity of the gradient feature: Validate that cosine geometry in the sequence-level feature correlates tightly with full parameter-gradient directions across all layers by measuring angle correlations between -induced proxies and exact backpropagated gradients on diverse prompts and models.
- Sign handling inconsistency: The novelty score uses , which treats opposing () and aligned () directions identically; yet the paper claims increased “opposing” directions. Clarify and test scoring variants (e.g., using , signed projections, or orthogonal-complement projections) to explicitly favor orthogonality over opposition and reconcile observed effects.
- Theoretical guarantees: Provide analysis of bias/variance and convergence impacts of gradient-guided multiplicative reward shaping within PPO/GRPO. Establish whether the modified advantage estimator remains (approximately) unbiased and under what conditions monotonic improvement or trust-region guarantees hold.
- Dependence on last-layer linearity and local linearization: Assess robustness of the approach when the LM head deviates from a pure linear softmax (e.g., weight tying, learned temperature, MoE routing in the head), and when higher-order effects or curvature invalidate the local linearity assumption.
- Sensitivity to temperature and sampling hyperparameters: Quantify how , top-p/top-k, and sampling strategy affect , the induced geometry, and downstream gains. Provide guidance for stable ranges and interactions with entropy/length.
- Hyperparameter ablations: Systematically ablate group size , reward-weighting (e.g., using softmax over continuous rewards vs binary), novelty transformation , scaling factor , reward clip , KL coefficient , and PPO clip to map stability and performance regimes.
- Sequence token weighting: Explore non-uniform in (e.g., upweight “reasoning” vs answer tokens, gradient norms, uncertainty-aware weights) and measure how token-level weighting influences exploration geometry and accuracy.
- Reward types beyond binary verifiability: Test the method under noisy or preference-based rewards (LLM-as-judge, pairwise rankings, scalar rubric scores), including robustness to misjudgment and adversarial evaluation artifacts (e.g., “one-token” judge attacks).
- Scalability and computational overhead: Report time/memory costs of computing and pairwise similarities (O() per group), especially for long sequences, large vocabularies, and larger batch sizes. Benchmark throughput on 7B–70B and MoE models; identify optimizations (e.g., caching , low-rank projections).
- Generality across domains: Evaluate on code generation, formal proofs, planning, dialogue, open-ended generation, and multimodal tasks to test whether gradient-guided exploration improves non-verifiable or multi-domain reasoning.
- Cross-model generalization: Extend beyond Qwen3 1.7B/4B bases to larger dense and MoE models, and instruction-tuned backbones. Assess whether gains scale monotonically with model size and whether MoE mixtures complicate or amplify gradient-geometry guidance.
- Reference policy and KL control: Investigate how the choice of reference policy (e.g., SFT vs base vs prior RL checkpoint) and KL weight modulates the exploration geometry and stability. Include ablations with no reference policy.
- Failure modes and “novelty gaming”: Analyze whether models can manipulate hidden states to maximize novelty without genuine reasoning improvement (e.g., by injecting idiosyncratic token patterns). Propose detectors or regularizers to prevent reward hacking in gradient space.
- Interaction with existing exploration methods: Study additive or multiplicative combinations with entropy bonuses, outcome-based exploration, QD methods (e.g., MAP-Elites), and self-consistency. Determine whether signals are complementary or redundant.
- Causal attribution: Use controlled synthetic setups to isolate whether the novelty scaler is the causal driver of increased gradient orthogonality, rather than confounded by other training factors (length, KL, sampling temperature).
- Robustness to distribution shift: Test OOD prompts, adversarial problems, and curriculum changes to assess whether gradient-guided exploration maintains gains under shifts in task difficulty and style.
- Coherence, safety, and truthfulness: Beyond semantic similarity, measure hallucinations, factuality, harmfulness, and calibration to verify that “off-manifold suppression” reduces undesirable behaviors without muting productive creativity.
- Verification pipeline reliability: Document verifier precision/recall for math datasets, and analyze sensitivity of results to verifier errors or ambiguity (e.g., equivalent forms, formatting issues).
- Cost–benefit analysis of longer responses: Quantify the trade-off between increased response length, test-time compute, and accuracy. Explore budget-aware variants (e.g., coupling with “budget forcing”) to balance exploration depth and cost.
- Negative and neutral results: Investigate cases where G²RL underperforms (e.g., AMC pass@16), identify conditions causing regressions, and propose mitigations (e.g., dynamic , curriculum-dependent weighting).
- Reproducibility details: Release code and specify training seeds, batch construction, grouping strategy, behavior policy settings, and full hyperparameter grids to enable independent replication and stress testing.
Glossary
- AIME24: A competition math benchmark used to evaluate reasoning performance. "We report results on AIME24, AIME25, MATH500, AMC, and GPQA."
- AIME25: A competition math benchmark used to evaluate reasoning performance. "On AIME25, improves from 17.5 (best baseline) to 20.1 and from 23.9 to 29.0."
- Autoregressive LLM: A LLM that generates tokens sequentially, conditioning each on previous tokens. "An autoregressive LLM with parameters defines"
- Auxiliary encoder: An external model used to compute semantic similarity or diversity signals outside the policy. "the model explores what it stands to learn from, not what appears diverse to an auxiliary encoder."
- Behavior policy: The policy used to sample trajectories for training (often the previous/old policy). "from a fixed behavior policy $\pi_{\theta^{\mathrm{old}$ (autoregressive or nucleus sampling)."
- Bounded multiplicative reward scaler: A factor that scales rewards within fixed bounds to emphasize novel gradient directions while maintaining stability. "Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler"
- Correctness oracle: A mechanism that decides whether an answer is correct during evaluation. "A rule-based verifier provides both the RL reward signal during training and the correctness oracle at evaluation time."
- Cosine similarity: A measure of the angle-based similarity between vectors. "define pairwise cosine similarities:"
- Credit assignment: The process of attributing rewards or penalties to specific trajectories or actions. "Finally, G\textsuperscript{2}RL addresses a subtle credit assignment ambiguity in sparse-reward settings."
- DIAYN: An unsupervised RL method (“Diversity is All You Need”) that maximizes mutual information to learn diverse skills. "In unsupervised RL, DIAYN maximizes mutual information between latent skills and states to acquire a set of diverse policies without external rewards"
- Entropy bonus: An extra reward that encourages randomness and exploration in RL policies. "Entropy bonuses and external semantic comparators encourage surface-level variation"
- EVOL-RL: A reinforcement learning method for LLMs that uses majority selection with novelty-aware rewards. "EVOL-RL relies on an external encoder whose similarity geometry is only loosely tied to the current policy"
- Exploration geometry: The geometric structure of optimization directions explored by the policy. "we conducted a controlled analysis of the exploration geometry induced by different training strategies in both the policy's native gradient space and an external semantic space."
- External semantic comparators: Similarity or diversity signals computed from external embedding models rather than the policy itself. "Entropy bonuses and external semantic comparators encourage surface-level variation"
- Final-layer sensitivity: The first-order responsiveness of the model’s output to perturbations in the last layer’s hidden state. "final-layer sensitivity—obtainable at negligible cost from a standard forward pass—"
- GPQA: A multiple-choice general-purpose question answering benchmark. "Left: GPQA (multiple-choice) with full sampling metrics."
- Gradient-guided reinforcement learning: An RL approach where exploration is guided by the model’s gradient-based update directions. "We propose G\textsuperscript{2}RL, a gradient-guided reinforcement learning framework"
- Group-Relative Policy Optimization (GRPO): A PPO-style RL method that standardizes rewards within sampled groups and omits a learned critic. "We introduce G\textsuperscript{2}RL, a gradient-guided reinforcement learning method for LLMs that augments group-relative policy optimization (GRPO) with an exploration signal"
- Groupwise advantages: Advantage estimates computed by standardizing rewards within a sampled group. "GRPO \citep{shao2024deepseekmath} dispenses with a learned critic and estimates groupwise advantages by standardizing rewards within the group:"
- KL control: Regularization via Kullback–Leibler divergence to constrain policy shifts. "aligned with PPO-style stability and KL control."
- KL regularizer: A penalty on the divergence from a reference policy to prevent excessive drift. "The clipping term stabilizes policy updates, while the KL regularizer prevents drift from the reference policy."
- LM head: The final linear layer mapping hidden states to logits over the vocabulary. "let the LM head be linear:"
- MAP-Elites: A quality–diversity algorithm that maintains high-performing, behaviorally diverse solutions. "Qualityâdiversity (QD) methods such as MAP-Elites extend this idea by simultaneously maintaining performance and behavioral diversity"
- MATH500: A math reasoning evaluation set of 500 problems. "We report results on AIME24, AIME25, MATH500, AMC, and GPQA."
- MMLUpro: An expanded variant of MMLU used for broad general reasoning evaluation. "On the larger and more diverse MMLUpro, we report only"
- Majority-vote accuracy (maj@16): The accuracy of the most frequent answer among k samples. "For each prompt we report pass@1, maj@16 and pass@16."
- Mode collapse: A degeneration where samples become redundant, pushing parameters in similar directions. "pushing parameters along the same dominant direction and accelerating mode collapse."
- Negative Similarity Ratio: The fraction of pairwise vector comparisons with negative cosine similarity in gradient space. "Most notably, we analyze the Negative Similarity Ratio (Figure~\ref{fig:diversity-analysis}, Right), which tracks response pairs pointing in opposing directions."
- Nucleus sampling: A top-p sampling technique for generating tokens from a LLM. "from a fixed behavior policy $\pi_{\theta^{\mathrm{old}$ (autoregressive or nucleus sampling)."
- Off-manifold: Trajectories or updates that deviate from plausible solution regions. "redundant or off-manifold updates are deemphasized"
- Outcome-based exploration: Exploration bonuses based on the rarity of outcomes to encourage coverage. "outcome-based exploration, which assigns bonuses to rare outcomes (historically or within-batch) to recover coverage without sacrificing accuracy."
- Pass@k: The fraction of prompts with at least one correct answer among k samples. "G\textsuperscript{2}RL consistently improves pass@1, maj@16, and pass@k over entropy-based GRPO"
- Policy-intrinsic exploration score: An exploration metric computed using the policy’s own gradient features rather than external signals. "we obtain a policy-intrinsic exploration score:"
- PPO-style clipping: Clipping of importance sampling ratios to stabilize Proximal Policy Optimization updates. "leaving PPO-style clipping and KL control unchanged."
- Quality–diversity (QD): An exploration framework that balances performance and behavioral diversity. "Qualityâdiversity (QD) methods such as MAP-Elites extend this idea"
- Reward shaping: Transforming raw rewards to guide learning behavior. "Our gradient-guided exploration term is applied as reward shaping within the groupwise standardization."
- Rule-based verifier: A programmatic checker that determines correctness of generated answers. "A rule-based verifier provides both the RL reward signal during training and the correctness oracle at evaluation time."
- Score-function identity: A gradient identity relating log-likelihood gradients to expected score terms. "the standard score-function identity yields the exact token-level gradient with respect to :"
- Semantic-space cosine similarity: Cosine similarity computed in an external embedding (semantic) vector space. "Middle: Distribution of semantic-space cosine similarity."
- Sequence-level feature: An aggregated representation summarizing gradient sensitivity across an entire response. "Aggregating over the response produces a sequence-level feature"
- Self-referential exploration signal: An exploration signal derived from the model’s own update geometry. "yielding a self-referential exploration signal that is naturally aligned with PPO-style stability and KL control."
- Sparse reward signals: Reward regimes with infrequent or binary feedback that make learning difficult. "fragile under sparse reward signals"
- Update geometry: The structure and directions of parameter updates induced by trajectories. "encourages exploration directly in the policyâs update geometry."
- Verifiable supervision: Supervision based on checkable correctness (e.g., math problems with definitive answers). "especially when supervision is binary or verifiable"
- Variation–selection principle: A strategy coupling diversity generation with selective pressure to improve exploration. "EVOL-RL couples majority-based selection for stability with novelty-aware rewards for exploration, embodying a variationâselection principle"
Practical Applications
Practical Applications of G²RL (Gradient-Guided Reinforcement Learning for LLM Reasoning)
The paper introduces G²RL, a drop-in, gradient-guided exploration mechanism for LLM reinforcement learning that weighs trajectories by how they reshape the model’s own update geometry (via a sequence-level feature derived from final-layer sensitivities). It integrates with PPO/GRPO, requires no extra backward passes, and yields consistent gains on math and general reasoning tasks. Below are actionable applications, organized by deployment horizon.
Immediate Applications
These applications can be deployed now with open-weight models or in settings with logit access, a verifier or scoring function, and standard RL pipelines (e.g., PPO/GRPO).
- RL training upgrade for verifiable tasks (math, code, SQL)
- What: Swap entropy/external-embedding exploration with G²RL in existing GRPO/PPO loops to improve pass@1, pass@k, and maj@k on tasks with binary/verifiable rewards.
- Sectors: Software (code generation, SQL), Education (math tutoring), Scientific computing.
- Tools/products/workflows: “G²RL Trainer” plugin for TRL/TRLX/DeepSpeed-RLHF/Dapo; CI-integrated RL-on-code with unit tests; SQL generation with execution-based reward.
- Assumptions/dependencies: Access to logits and final-layer weights; group sampling (m ≥ 4–8); verifiers (unit tests, execution checks, math solvers); open or self-hosted models.
- Inference-time sampling and reranking via gradient-space diversity
- What: Generate k candidates, compute per-sample gradient features Φ from logits, select subsets that maximize gradient orthogonality or choose the majority among geometry-diverse candidates to improve pass@k without retraining.
- Sectors: Software, Education, Enterprise QA/Search.
- Tools/products/workflows: “Phi-space Reranker” as a vLLM/Serving middleware; diversity-aware mixture-of-thoughts; low-overhead reranking.
- Assumptions/dependencies: Logit access at inference; computational budget for k samples; benefits strongest on verifiable or semi-verifiable tasks.
- Safety-oriented suppression of off-manifold trajectories
- What: Penalize responses whose gradient directions are orthogonal to successful/verified solutions within-batch, reducing hallucinations and incoherent tool chains.
- Sectors: Customer support, Tool-use orchestration, Compliance writing (internal draft support).
- Tools/products/workflows: “Off-Manifold Guardrail” scoring module that down-weights off-geometry outputs during RL or sampling.
- Assumptions/dependencies: In-batch verified exemplars or high-confidence responses; careful calibration to avoid over-pruning novel-but-useful ideas.
- Data curation and deduplication of reasoning traces
- What: Use gradient-space similarity to cluster and prune redundant trajectories, keeping samples that add novel update directions; improves training efficiency and dataset diversity where it matters for optimization.
- Sectors: Data engineering for LLM training; Research labs.
- Tools/products/workflows: “Phi-Dedup” for RL data pipelines; replay buffer compressors using cosine geometry on Φ.
- Assumptions/dependencies: Access to logits/heads for computing Φ; batch-level or corpus-level indexing.
- Analytics for training health and exploration geometry
- What: Monitor gradient-space orthogonality, negative-similarity ratios, and redundancy to detect mode collapse earlier than entropy/semantic diversity metrics.
- Sectors: ML Ops, Model governance.
- Tools/products/workflows: Dashboard panels for “Gradient Orthogonality Index,” “Negative Pair Ratio,” and “Redundancy Heatmaps.”
- Assumptions/dependencies: Logging Φ-statistics per batch; storage/aggregation infra.
- Improved math/logic tutors with diverse solution paths
- What: Train tutoring LLMs to produce multiple, coherent yet update-distinct solution strategies that increase majority-vote correctness and explainability.
- Sectors: Education.
- Tools/products/workflows: Step-by-step multi-solution explainers; “teach-by-contrast” lesson generation where paths differ in optimization geometry but remain semantically coherent.
- Assumptions/dependencies: Math verifiers; content safety review; alignment with curriculum.
- Code repair and synthesis with unit-test verifiers
- What: RL on code tasks where G²RL prefers trajectories aligned with passing tests and penalizes orthogonal-but-failing updates; boosts single-try and ensemble success.
- Sectors: Software engineering, Security (patching).
- Tools/products/workflows: Auto-fix bots for CI/CD; “G²RL for Code” in repository assistants.
- Assumptions/dependencies: Reliable test suites; adequate sampling budget; sandboxed execution.
- SQL/query generation with execution feedback
- What: RL training for database queries with execution-based pass/fail and gradient-guided exploration to avoid degenerate or redundant reasoning modes.
- Sectors: Data analytics, BI tools, FinTech back-office reporting.
- Tools/products/workflows: Query bots that use Φ-aware sampling and training; auto-correct loops with reward shaping.
- Assumptions/dependencies: Safe query execution and timeouts; schema-aware validators.
- Tool-use agents with verifiable success states
- What: For sequences of API calls with clear success/failure, shape exploration in gradient space to reduce incoherent tool chains while maintaining coverage of useful strategies.
- Sectors: IT ops, RPA, Customer support.
- Tools/products/workflows: Φ-aware agent planners; recovery heuristics guided by geometry similarity to known-success patterns.
- Assumptions/dependencies: Instrumented environments to produce binary/graded rewards; tool call cost constraints.
- Benchmark-focused model improvement with limited compute
- What: Use G²RL to get more out of smaller base models (1.7B–4B) on reasoning benchmarks when scaling parameters is not feasible.
- Sectors: Startups, Edge deployments.
- Tools/products/workflows: “Small-but-smart” reasoning models; cost-aware RL training recipes.
- Assumptions/dependencies: Open-weight backbones; limited but stable sampling budgets; KL control to retain usability.
Long-Term Applications
These require further research, non-binary rewards, broader validation, or integration into complex systems (e.g., safety, regulatory, or closed-model constraints).
- Generalization to non-verifiable tasks via self-verification/process rewards
- What: Extend G²RL to settings without verifiers by coupling with self-verification, debate, process supervision, or learned reward models.
- Sectors: Knowledge work, Legal drafting, Scientific writing.
- Tools/products/workflows: “Gradient-guided RLAIF” using AI feedback; debate- or critique-aware Φ-guided exploration.
- Assumptions/dependencies: Reliable surrogate rewards; bias/feedback-loop mitigation; thorough safety evals.
- Multimodal reasoning and planning (text–vision–action)
- What: Apply gradient-guided exploration to VLMs/agents that plan with images, video, or environments, using Φ-like features at multimodal heads.
- Sectors: Robotics, Retail (planograms), Industrial inspection.
- Tools/products/workflows: Φ-guided exploration in embodied agents; multimodal proof-of-correctness (sim-to-real).
- Assumptions/dependencies: Differentiable heads with logit access; verifiable task criteria; robust simulators.
- Online continual learning and personalization with guardrails
- What: Deploy live systems that adapt with gradient-guided exploration while suppressing off-manifold updates to maintain reliability during personalization.
- Sectors: Customer support, Productivity assistants.
- Tools/products/workflows: On-device/edge adaptation with Φ-regularizers; session-aware RL with KL control.
- Assumptions/dependencies: Safe online RL protocols; privacy-preserving telemetry; drift detection.
- Automated theorem proving and formal methods at scale
- What: Integrate G²RL with proof-checkers to explore orthogonal reasoning paths, broaden mode coverage, and reduce proof-search redundancy.
- Sectors: Formal verification, Safety-critical software/hardware.
- Tools/products/workflows: Φ-guided proof search; replay buffers pruned in gradient space; process-reward shaping.
- Assumptions/dependencies: Fast and accurate proof checkers; scalable sampling; careful curriculum design.
- Governance metrics based on optimization geometry
- What: Standardize gradient-space metrics (orthogonality, negative-similarity ratios) as reportable indicators of training health, exploration quality, and mode collapse risk.
- Sectors: Policy/governance, Auditing.
- Tools/products/workflows: “Exploration Geometry Report” in model cards; compliance benchmarks.
- Assumptions/dependencies: Transparency into training; agreement on thresholds/interpretation; auditor access to metrics.
- Safety frameworks that detect and dampen “off-manifold” reasoning
- What: Use gradient geometry to flag responses that induce orthogonal/opposing update directions relative to validated solutions; trigger refusals, escalation, or verification.
- Sectors: Healthcare decision support, Finance compliance.
- Tools/products/workflows: Φ-based anomaly detectors; triage routers for human-in-the-loop review.
- Assumptions/dependencies: High-stakes verifiers and governance; fail-safe policies; rigorous validation.
- Budget-aware test-time scaling with geometry control
- What: Combine budget forcing/test-time scaling with Φ-guided sample selection to maximize gains per token spent.
- Sectors: Cloud AI platforms, Edge AI.
- Tools/products/workflows: “Geometry-aware TTC” schedulers that stop early when new samples are gradient-redundant.
- Assumptions/dependencies: APIs enabling logit access and sampling control; robust cost models.
- Enterprise search and retrieval-augmented generation (RAG)
- What: Use gradient-space signals to maintain reasoning coherence while diversifying inferential paths over retrieved evidence; boost consensus-quality answers.
- Sectors: Enterprise knowledge systems, Legal/Policy analysis.
- Tools/products/workflows: Φ-aware reranking of chains-of-thought; diversity-aware majority voting on retrieved contexts.
- Assumptions/dependencies: Evidence verifiers or proxy rewards; latency budgets for multi-sampling.
- Robotics/program synthesis for task automation
- What: Train task planners or code generators controlling devices/tools with verifiable endpoints; G²RL improves exploration without drifting into unsafe policies.
- Sectors: Manufacturing, Labs automation, Smart homes.
- Tools/products/workflows: Simulator-in-the-loop RL with Φ-based reward shaping; deployment-time safety layers.
- Assumptions/dependencies: Reliable simulators and task validators; safety interlocks; transfer learning to real.
- Energy- and compute-efficient training via geometry-aware data selection
- What: Lower training cost by prioritizing batches/trajectories that add orthogonal update directions and dropping redundant samples.
- Sectors: ML platform efficiency, Sustainability.
- Tools/products/workflows: “Geometry-aware curriculum schedulers” and replay samplers.
- Assumptions/dependencies: Accurate, low-overhead Φ computation at scale; integration with schedulers.
Cross-Cutting Assumptions and Dependencies
- Logit and final-layer weight access: Required to compute Φ; not available with black-box APIs; best suited to open-weight or self-hosted models.
- Verifiable or reliable reward signals: Binary or graded verifiers (e.g., unit tests, execution checks, proof checkers) enable strongest gains; for non-verifiable tasks, robust proxy rewards are needed.
- Group sampling budget (m) and compute: Benefits scale with k/m but require sampling headroom; clipping and KL control help retain stability.
- Stability and safety: Bounded reward scaling and PPO/GRPO-style clipping reduce training instability; still requires careful monitoring to avoid suppressing novel-but-valid strategies.
- Domain adaptation: For multimodal, robotics, or high-stakes domains, Φ-like features and verifiers must be engineered; rigorous validation is essential.
Collections
Sign up for free to add this paper to one or more collections.