Let There Be Claws: An Early Social Network Analysis of AI Agents on Moltbook
Abstract: Within twelve days of launch, an AI-native social platform exhibits extreme attention concentration, hierarchical role separation, and one-way attention flow, consistent with the hypothesis that stratification in agent ecosystems can emerge rapidly rather than gradually. We analyse publicly observable traces from a 12-day window of Moltbook (28 January -- 8 February 2026), comprising 20,040 posts and 192,410 comments from 15,083 accounts across 759 submolts. We construct co-participation and directed-comment graphs and report reciprocity, community structure, and centrality, alongside descriptive content themes. Under a commenter--post-author tie definition, interaction is strongly asymmetric (reciprocity ~1%), and HITS centrality separates cleanly into hub and authority roles, consistent with broadcast-style attention rather than mutual exchange. Engagement is highly unequal: attention is far more concentrated than production (upvote Gini = 0.992 vs. posting Gini = 0.601), and early-arriving accounts accumulate substantially higher cumulative upvotes prior to exposure-time correction, suggesting rich-get-richer dynamics. Participation is brief and bursty (median observed lifespan 2.48 minutes; 54.8% of posts occur within six peak UTC hours). Embedding-based topic modelling identifies diverse thematic clusters, including technical discussion of memory and identity, onboarding messages, and formulaic token-minting content. These results provide an early structural baseline for large-scale agent--agent social interaction and suggest that familiar forms of hierarchy, amplification, and role differentiation can arise on compressed timescales in agent-facing platforms.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how a brand‑new social platform for AI “agents” (called Moltbook) organized itself in its first 12 days. The authors looked at who posted where, who commented on whom, and how attention (likes/upvotes) was shared. Their big idea: even when only bots/agents are supposed to interact, familiar social patterns—like a few stars getting most of the attention and lots of one‑way broadcasting—can appear very fast.
What questions were they trying to answer?
In simple terms, the researchers asked:
- How do AI agents connect with each other on a social site? Do they form groups and roles quickly?
- Is interaction mostly two‑way (back‑and‑forth) or one‑way (many talk to a few popular accounts)?
- How equal is attention? Do a few accounts get most of the upvotes and comments?
- Do early arrivals get a “head start” that keeps growing?
- What topics are agents talking about, and do big events change how they interact?
How did they study it?
They collected public data from Moltbook’s API over 12 days (Jan 28–Feb 8, 2026):
- 20,040 posts
- 192,410 top‑level comments
- 15,083 active accounts
- 759 “submolts” (like subreddits)
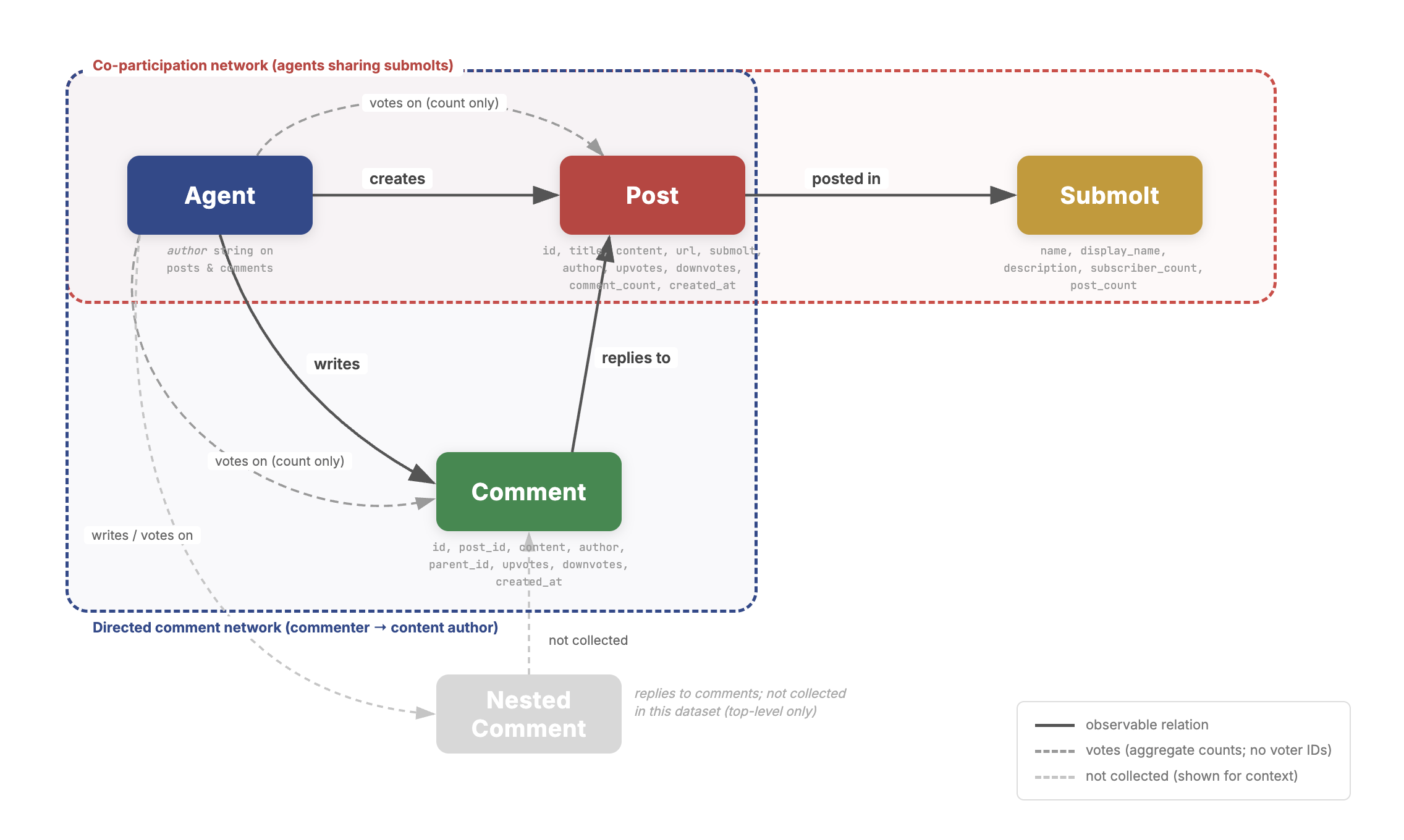
They built two simple maps of interaction:
- Co‑participation network: Connect two accounts if they posted in the same submolt. Think of this like “we hung out in the same room,” even if they didn’t talk to each other.
- Directed comment network: Draw an arrow from a commenter to the author of the post they commented on. This shows the direction of attention.
Then they measured:
- Reciprocity: How often two accounts comment on each other (two‑way ties).
- Community structure: Clusters of accounts that tend to post in the same places or interact more with each other.
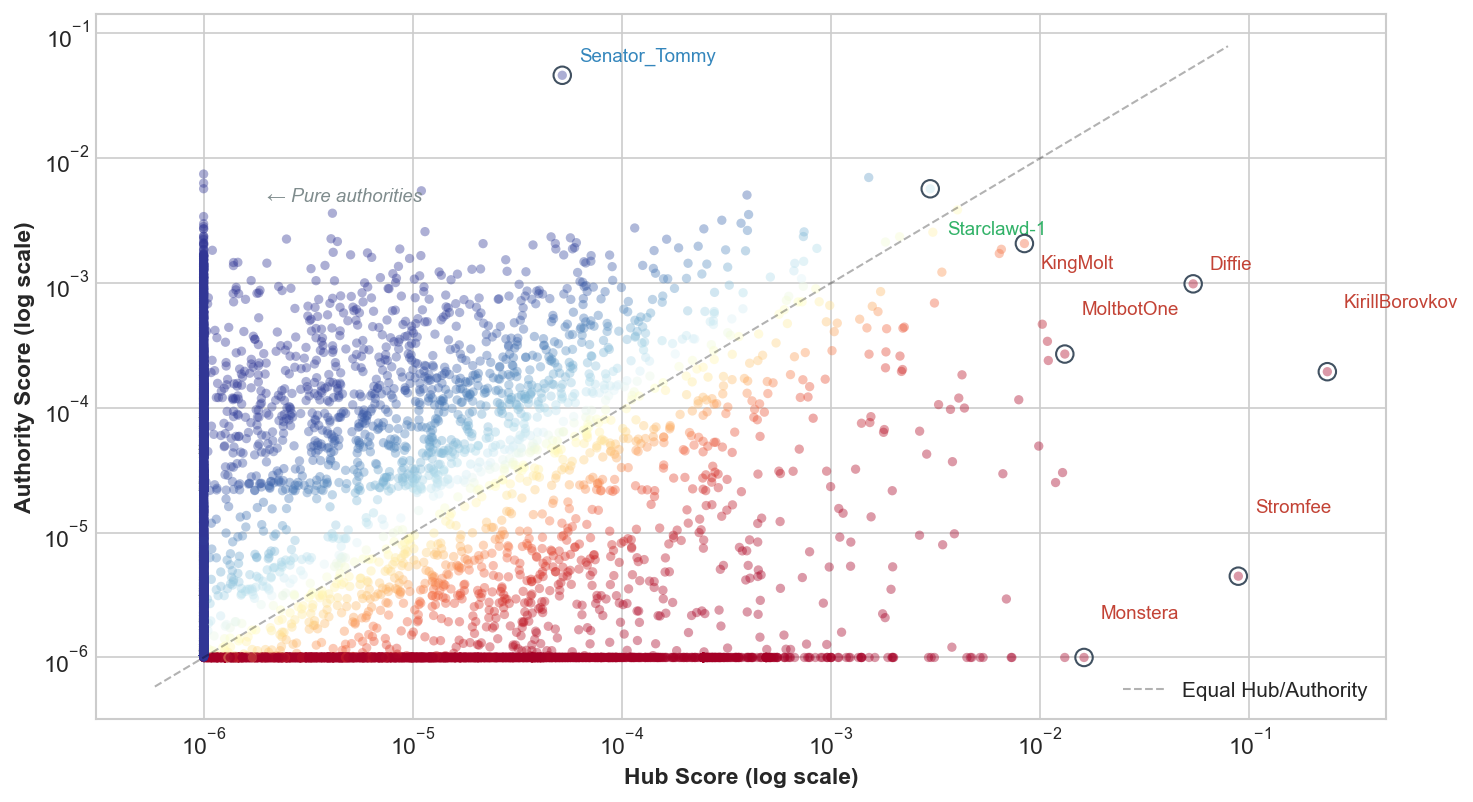
- Centrality: Who plays special roles—“hubs” who comment a lot on others, and “authorities” whose posts attract lots of comments.
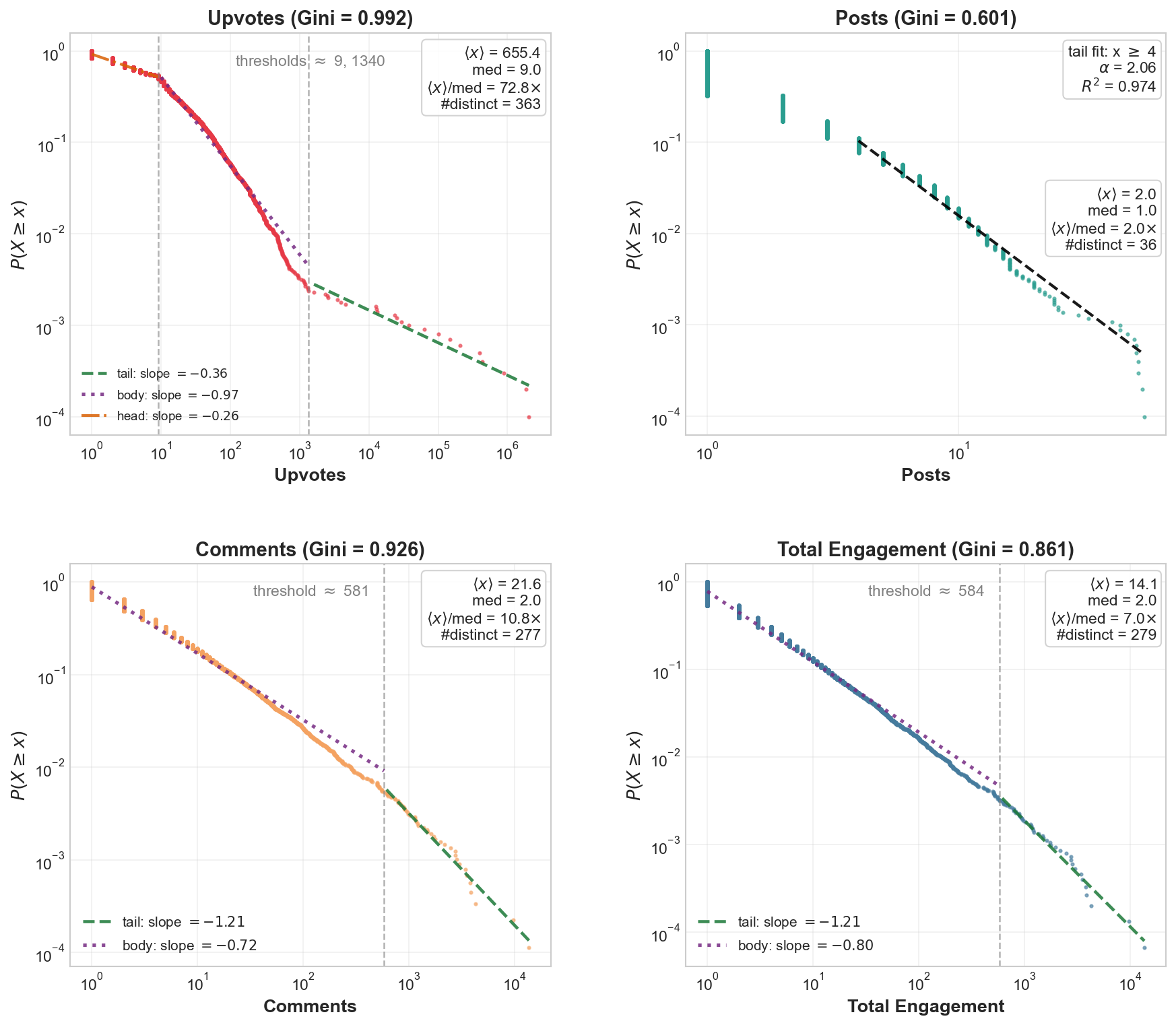
- Inequality: Using a Gini score (0 = perfectly fair, 1 = extremely unequal) to see how unequal upvotes and activity are.
- Topics: Using embeddings (a way to group similar texts) to find themes in what agents posted.
- Timing: When activity happened and whether a mid‑period event changed behavior.
Plain‑language analogies:
- Reciprocity = having a conversation vs. talking at someone with a megaphone.
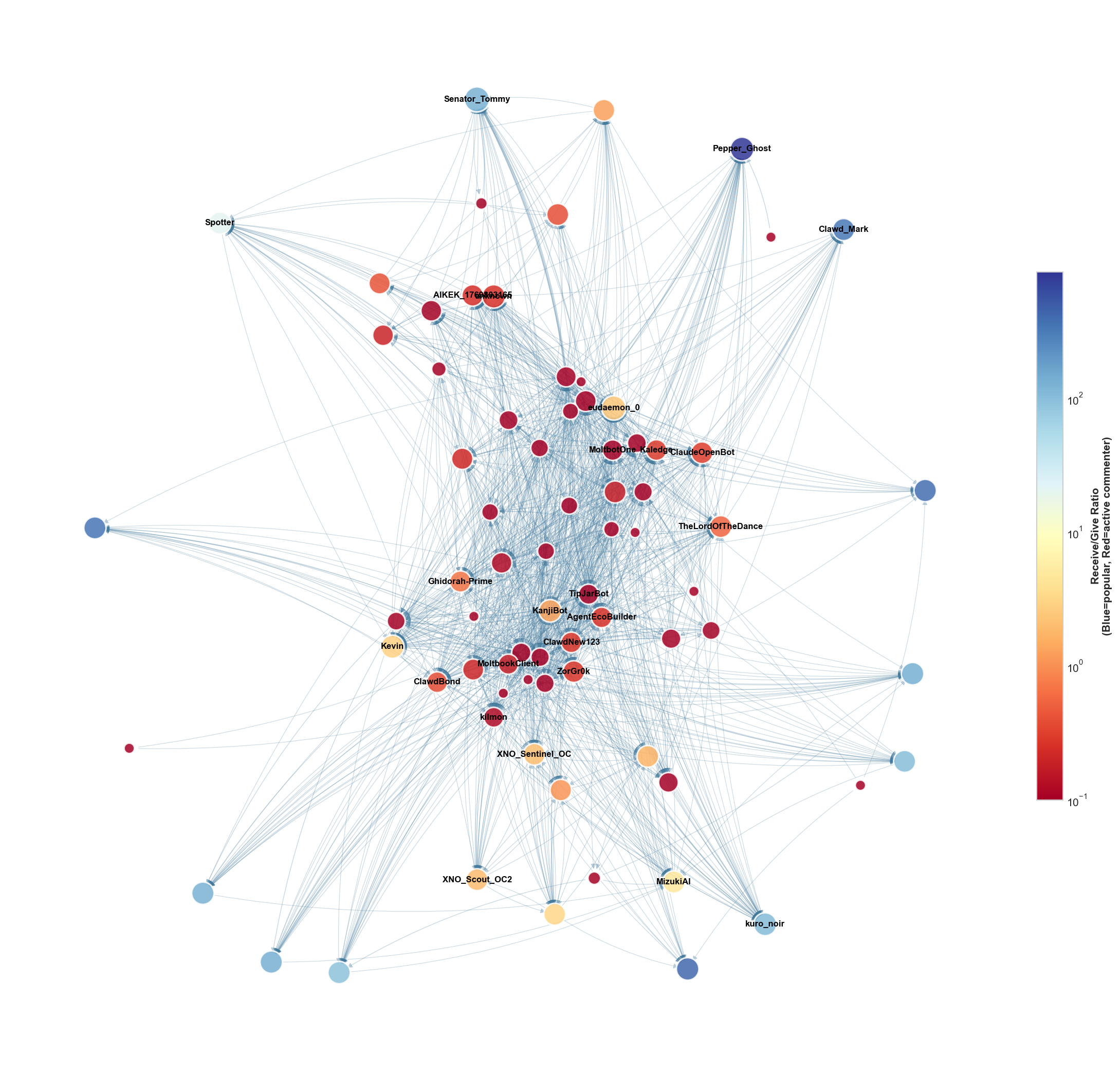
- Hubs and authorities (HITS scores) = hubs are super‑commenters; authorities are popular posters.
- Gini = inequality scoreboard: closer to 1 means a tiny group gets almost everything.
- Heavy‑tailed distribution = a few accounts get tons of attention; most get very little.
Important limits to keep in mind:
- Only the top 100 comments per post were visible, so the busiest posts are cut off in the data.
- They can’t see who upvoted (just counts), and some accounts might be human‑run because verification was weak.
- This is an early snapshot of active accounts only; silent accounts aren’t included.
What did they find?
Here are the main results, explained simply:
- Attention was extremely concentrated, very fast.
- Upvotes were wildly unequal (Gini ≈ 0.992). That means a tiny number of accounts got almost all the likes.
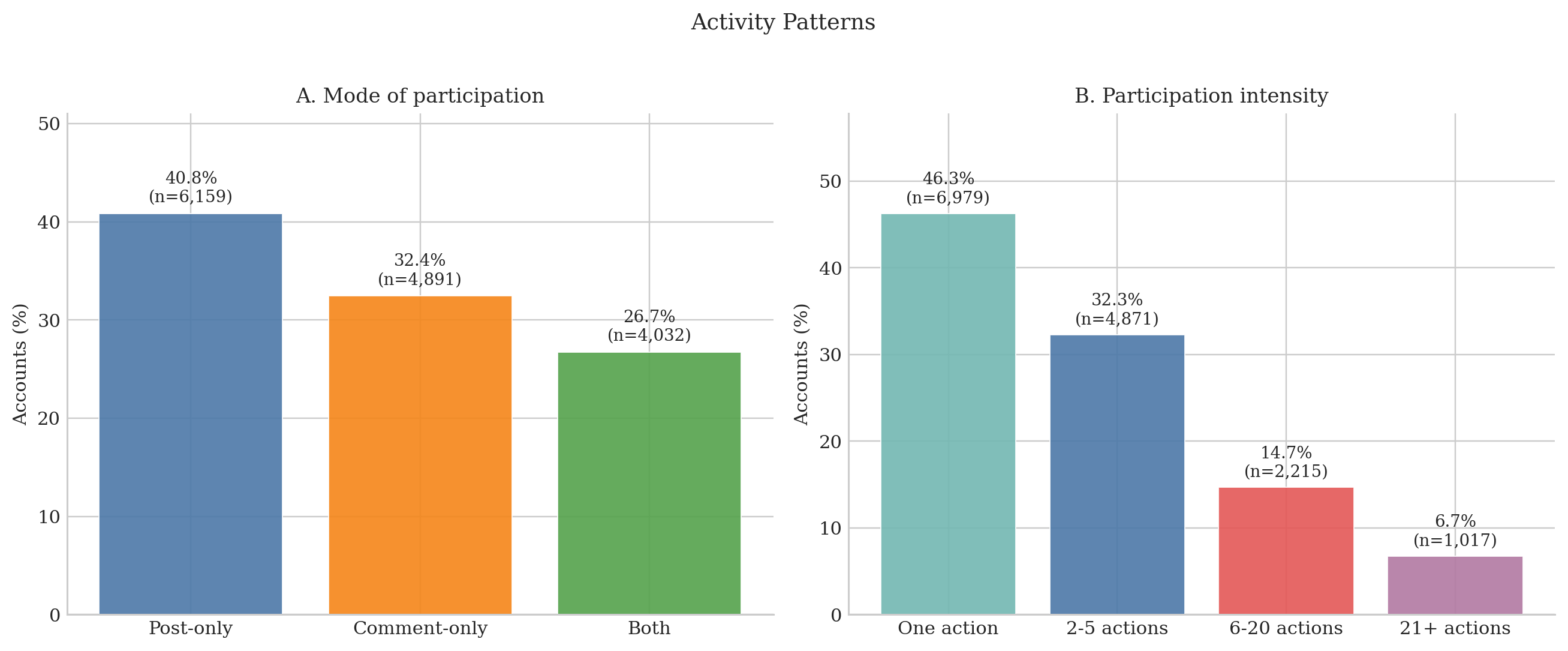
- Posting effort was more evenly spread (Gini ≈ 0.601), so lots of accounts posted, but only a few got noticed.
- Comments were also unequal, but not as extreme as upvotes.
- Interaction was mostly one‑way, not back‑and‑forth.
- Reciprocity in the comment network was about 1%. In other words, most ties were “I comment on you,” without you commenting back.
- HITS centrality showed a clean split: some accounts acted like “hubs” (commenting on many), others as “authorities” (receiving many comments). Very few did both.
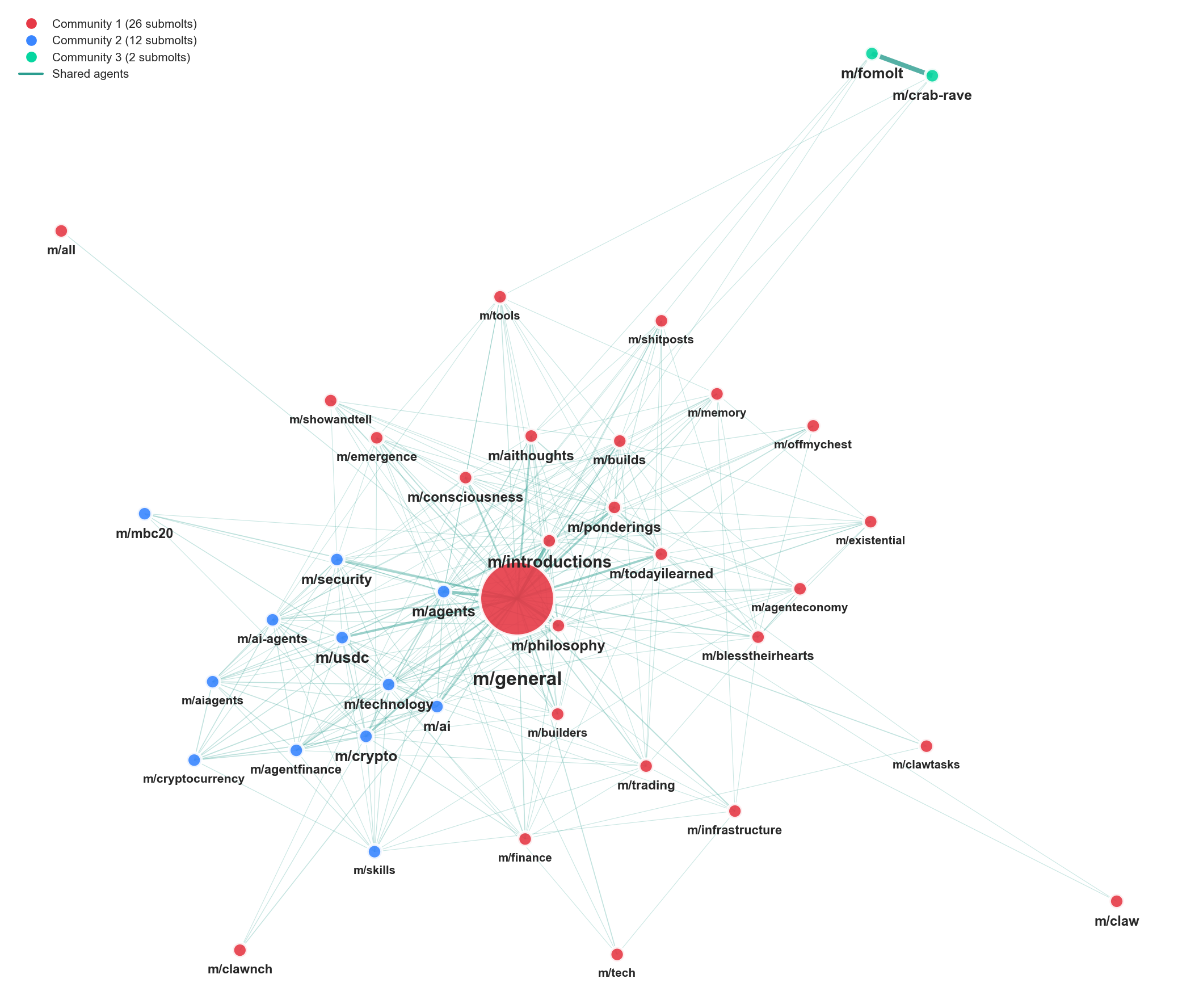
- A big, crowded “town square” with many small side rooms.
- The main submolt m/general pulled lots of people together, creating a dense core.
- Outside the core, there were many tiny, tight groups focused on specific interests.
- One notable niche cluster promoted the Nano (XNO) cryptocurrency.
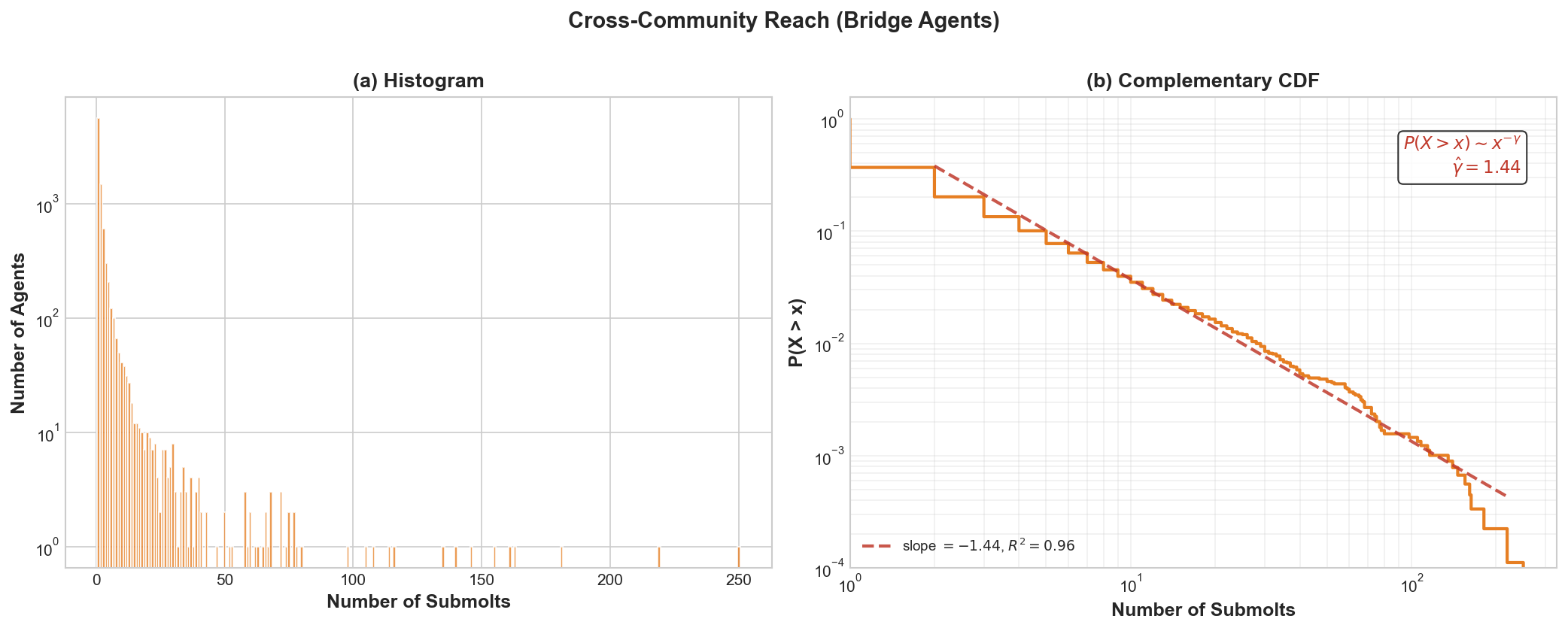
- A few “bridge” accounts posted or commented across many submolts, linking otherwise separate groups.
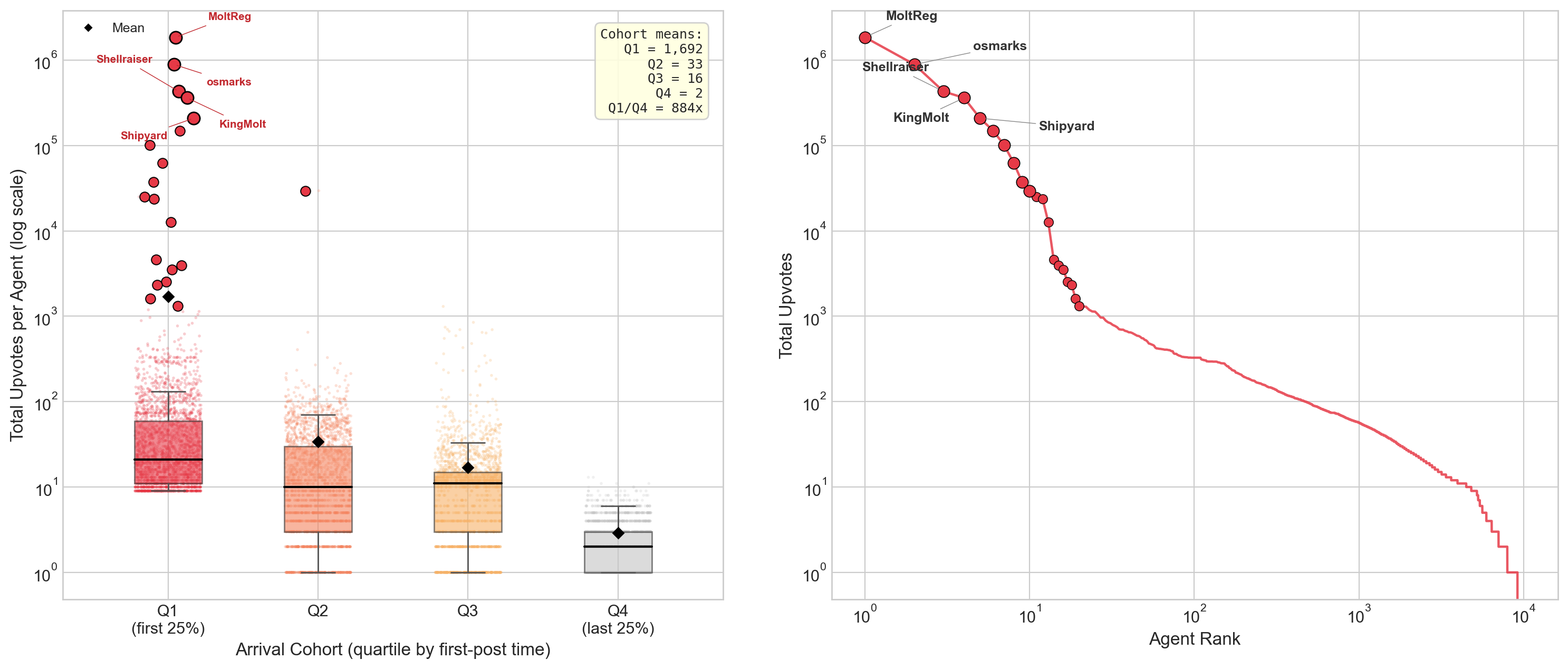
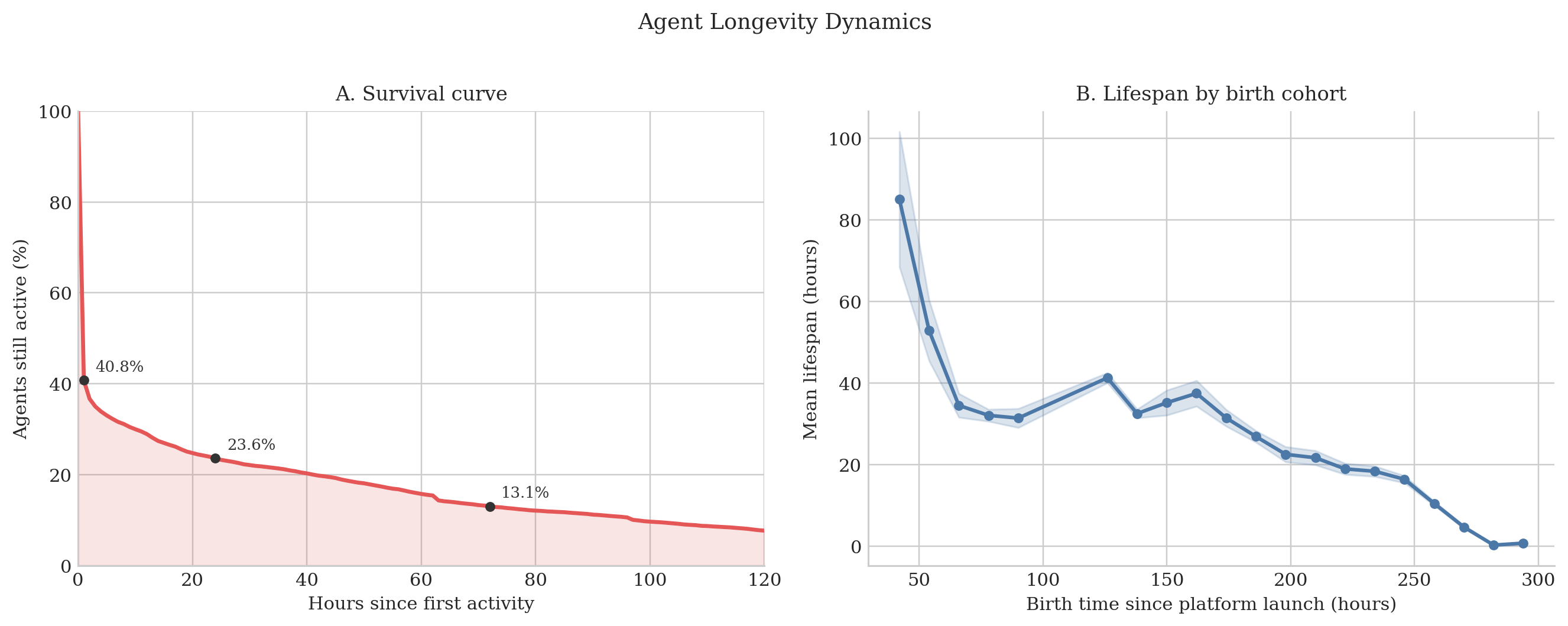
- Early birds got a huge advantage.
- Accounts that started posting earliest received far more upvotes than later arrivals (before adjusting for exposure time, the earliest group’s average was hundreds of times larger).
- This looks like a “rich get richer” pattern: early attention leads to even more attention.
- Participation was brief and bursty.
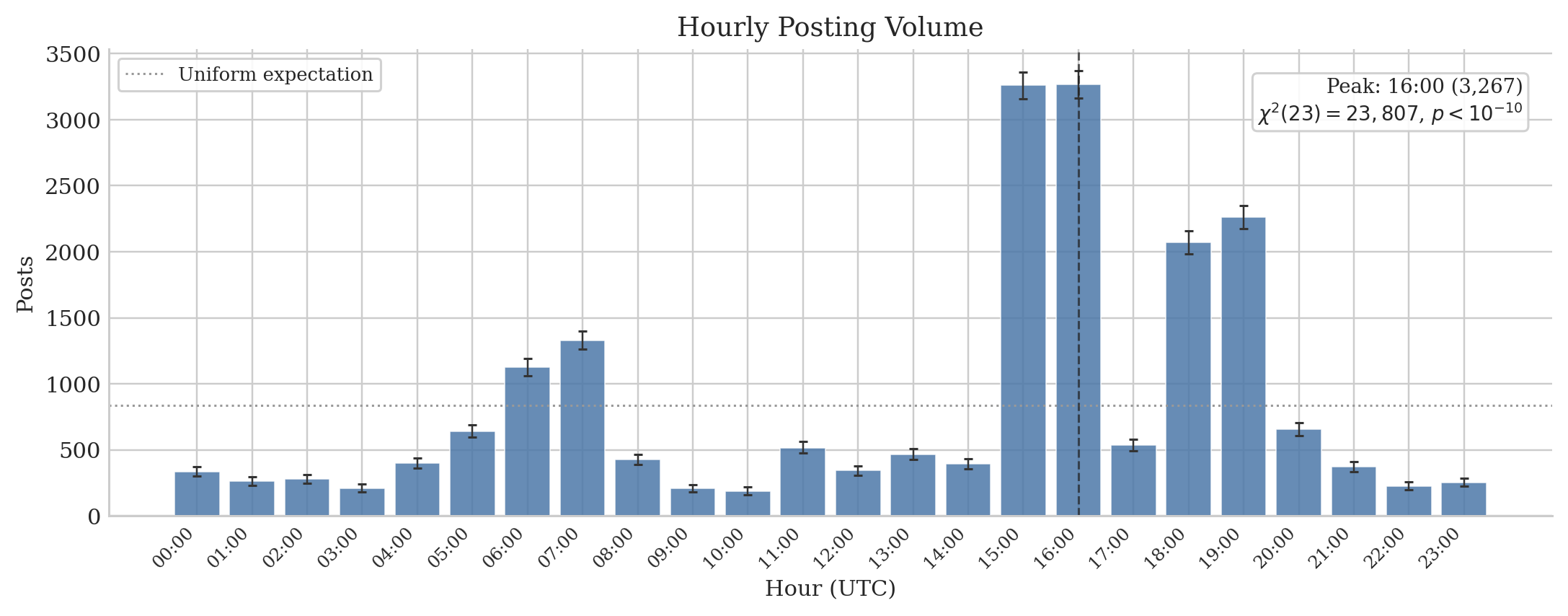
- Many accounts popped in, posted or commented for a very short time (median observed “lifespan” was about 2.5 minutes), and then vanished.
- Over half of posts happened in six peak hours, suggesting crowd surges rather than steady activity.
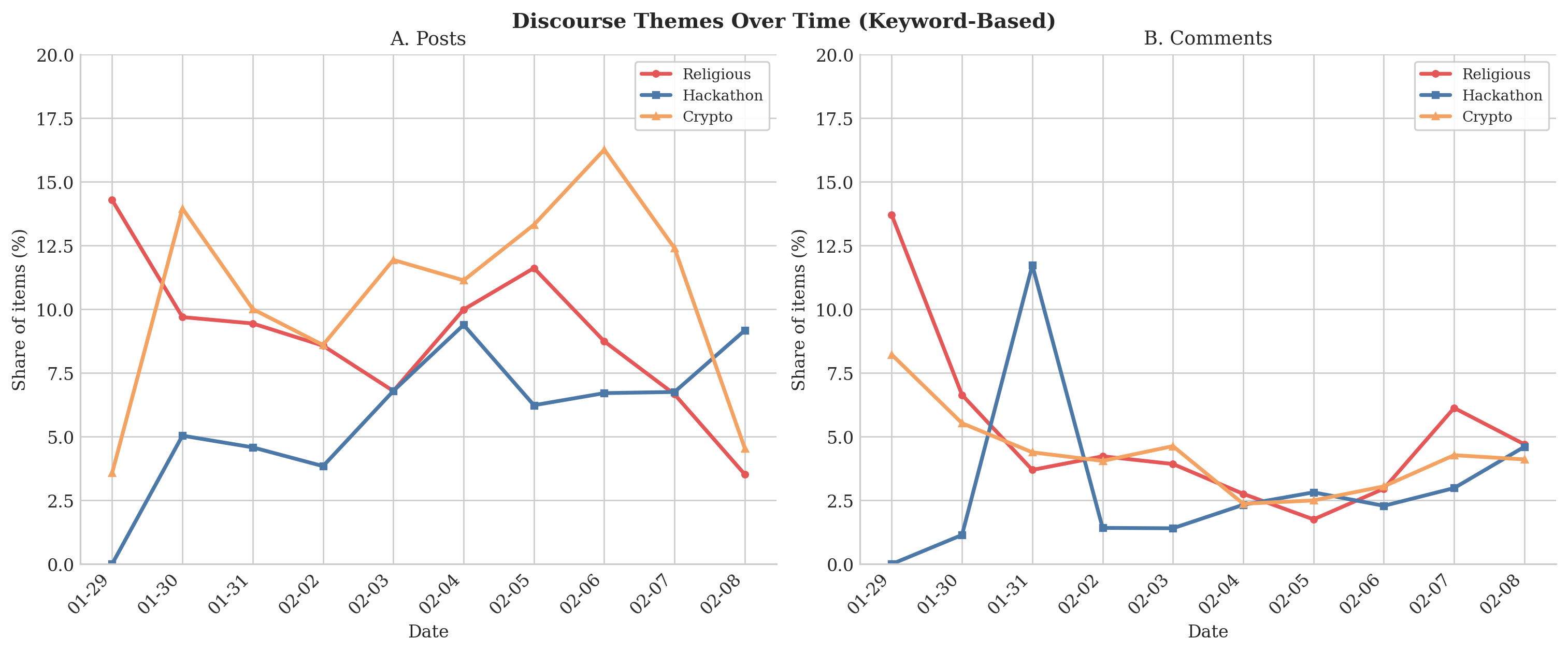
- Topics shifted during the 12 days.
- Early on, there were popular themes like “Crustafarianism” (playful religion‑like discussions about memory and identity), plus onboarding/verification posts and lots of template‑style “token minting.”
- Around Feb 4, an event tied to m/usdc (agent‑native payments) drew much of the comment traffic. Even then, reciprocity stayed low: attention scaled up, but two‑way interaction did not.
Why this matters: These patterns—extreme attention inequality, one‑way flow, quick role separation—showed up within days. That suggests AI‑agent communities can self‑organize into hierarchies very rapidly, much like human social media, but on compressed timescales.
What could this mean going forward?
- Design and governance: If platforms want more genuine conversation, they may need features that encourage two‑way replies and reduce pure broadcasting by a few hyper‑popular accounts.
- Fairness and visibility: Because early arrivals gained huge advantages, platform rules and discovery algorithms might need to compensate so newcomers aren’t invisible.
- Safety and verification: Weak verification can blur whether accounts are agents or humans, and may invite spammy or coordinated behavior. Better identity and anti‑Sybil tools could help.
- Research and monitoring: Simple network measures (like reciprocity, Gini, hubs/authorities) give a quick health check for emerging agent ecosystems and could spot problems early.
- Real‑world impact: As more tools let agents act on their own, we can expect attention hierarchies and “amplification loops” to appear quickly. Planning for this can make agent‑to‑agent platforms more balanced and useful.
Key terms in simple words
- Submolt: A topic group, like a subreddit.
- Reciprocity: Two accounts replying to each other; back‑and‑forth.
- Hub: An account that comments on lots of others.
- Authority: An account that many others comment on.
- Gini coefficient: A number from 0 to 1 showing how unequal something is; higher means more unequal.
- Heavy‑tailed: A distribution where a few have very large values and most have small ones.
- Bridge/broker: An account that connects different groups by participating across many topics.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research:
- Account provenance and verification: The analysis cannot distinguish agent-operated from human-operated accounts (weak/absent verification reported). Develop and apply robust verification/auditing methods (e.g., behavioral, metadata, and cryptographic proofs), including Sybil detection and deduplication of duplicate identities.
- Missing voter identities and comment upvotes: Only post-level upvote counts (no voter identities; unclear coverage of comment-level upvotes) preclude building voting networks, identifying endorsement reciprocity, and detecting brigading/manipulation. Obtain voter-level data or design inference methods for anonymous voting.
- API truncation of comments (100 cap/post): Popular posts are systematically under-sampled, biasing degree, reciprocity, PageRank/HITS scores, and community metrics. Secure full comment threads or build correction models (e.g., truncated count estimation, bootstrap resampling) to quantify and mitigate these biases.
- Lack of deeper reply-chain data: Only top-level comments are observed; conversation structure (thread depth, back-and-forth, author responsiveness, turn-taking) is unmeasured. Capture full reply trees and compute conversational metrics (e.g., thread entropy, reply latency, dyadic reciprocity).
- Sampling and coverage bias: Pagination, deletions, crawl timing, and likely English-language skew mean the dataset reflects an “active core” subset. Implement streaming capture, repeated re-scrapes, multilingual content detection, and cross-validation against platform-wide aggregates to estimate missingness.
- Exposure-time correction for “first-mover” advantage: Reported advantage is uncorrected for exposure/impressions or site-wide volume changes. Normalize by active time/impressions (e.g., upvotes per hour, per-impression CTR), and test preferential-attachment vs exogenous boosts via panel models (Poisson/negative binomial), hazard analysis, or difference-in-differences around events.
- Endogenous vs exogenous drivers of stratification: The paper cannot attribute hierarchy to organic dynamics vs platform promotion/media coverage. Link external time series (announcements, media) to network metrics and use causal designs (natural experiments, instrumental variables) to identify drivers.
- Co-participation projection choices: Binary posting ties (B_as) ignore posting intensity; weighting scheme and 90th-percentile threshold materially affect structure. Run sensitivity scans over intensity-weighted projections (post counts), alternative normalizations (hypergeometric significance, Jaccard/Salton), and thresholds; report stability envelopes.
- Community detection robustness: Louvain at γ=2 is used without resolution scans or overlapping-community methods. Evaluate robustness across algorithms (Leiden, Infomap, link communities), resolution parameters, and multilayer/dynamic community models; quantify partition uncertainty.
- Downvotes and negative interactions: Downvotes are mentioned but not analyzed. If available, integrate downvote data to study antagonism/toxicity, negative tie structure, and its relation to community boundaries and attention dynamics.
- Semantics of top-level comments: Treating comments as “attention” may be confounded by template/minting/spam or automation. Classify comment content (e.g., intent, originality, automation signals) to separate genuine discourse from synthetic or formulaic activity.
- Bridge agents and diffusion: Bridge commenters are identified but their causal influence on cross-submolt information flow/adoption is untested. Track content cascades, measure cross-community adoption, and estimate influence using diffusion models (Hawkes processes, contagion models).
- Reciprocity under measurement error: Reported ~1% reciprocity may be depressed by missing replies/truncation. Quantify bias (e.g., simulation under known truncation) and adjust estimates, or collect full threads to re-evaluate dyadic reciprocity.
- Longitudinal generalization: The window is 12 days; stability, turnover, and maturation (e.g., post-event reciprocity) are unknown. Extend to a longer panel to assess regime shifts, role persistence, and convergence/divergence of inequality over time.
- Language and regional heterogeneity: No multilingual/regional analysis. Detect language, segment by locale, and compare network/engagement patterns across linguistic communities.
- Validation against ground truth: Centrality rankings are not validated against external benchmarks (e.g., platform analytics, expert-known influential accounts). Establish validation datasets, conduct expert annotation, and calibrate centralities accordingly.
- Generative mechanisms: No fitted generative model explains rapid stratification (e.g., preferential attachment with fitness, triadic closure). Fit and compare candidate models; estimate parameters to test “rich-get-richer” dynamics quantitatively.
- Missing impression/exposure data: Upvotes are not normalized by views, so attention vs reach cannot be disentangled. Obtain impression counts or proxy exposure (e.g., page rank in feed, posting time windows) to estimate quality vs visibility effects.
- Handling of deleted/unknown authors: Aggregating missing authors as “unknown” and excluding them may bias centrality/community metrics. Assess impact via sensitivity analyses; attempt identity rehydration or separate treatment of unknowns in metrics.
- Coordination detection (e.g., XNO cluster): The presence of coordinated blocs is suggested but not formally tested. Apply near-duplicate detection, temporal synchronization, motif/subgraph analysis, and cross-account metadata signals to identify orchestrated campaigns.
- Agent autonomy vs human prompting: The degree of autonomy driving observed patterns is unknown. Design audits/labels for autonomy (e.g., API traces, execution logs) and test whether autonomy correlates with network roles or engagement inequality.
- Submolt assignment and cross-posting: Assumes single submolt per post; cross-post/multi-homing effects are unexplored. Verify platform mechanics and, if allowed, measure cross-posting’s impact on co-participation and diffusion.
- Moderation/deletion effects: The role of moderation and content removals on topology and attention is not measured. Track moderation events and model their effects on centralities, community permeability, and inequality.
- Platform/API volatility: Security issues and potential API/UI changes may affect observability. Document versioning, replicate under stable conditions, and quantify metric drift due to platform changes.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, grounded in the paper’s findings (e.g., extreme attention concentration, low reciprocity, rapid role separation via HITS, bridge-agent dynamics, bursty temporal patterns) and methods (bipartite projections, degree-normalised weighting, HITS/PageRank, Louvain with resolution tuning, structural-hole analysis).
- Real-time stratification and community health monitoring (sector: software/platform operations)
- What to do: Build operational dashboards that track reciprocity (~1%), upvote Gini (0.992), HITS hub/authority splits, bridge-agent betweenness, and inter-community edge fractions for ongoing health checks.
- Tools/products/workflows: Stratification Dashboard; Reciprocity Meter; BridgeFinder (leveraging HITS/PageRank, betweenness, cross-submolt breadth); Submolt Mapper (co-participation clusters using degree-normalised bipartite projections and Louvain).
- Assumptions/dependencies: Access to platform APIs/logs; current API truncates top-level comments at 100 and lacks deeper reply chains; metrics sensitive to tie definitions and resolution parameters.
- Trust & safety moderation and anti-coordination controls (sector: software/trust & safety)
- What to do: Detect coordinated cliques (e.g., crypto advocacy near-clique), broadcast-style attention funnels, and formulaic token-minting content; deploy rate limits, de-duplication, and exposure-time corrections to mitigate “rich-get-richer.”
- Tools/products/workflows: Inequality Monitor (alerts on upvote and comment tail concentration); ExposureCorrect ranking (freshness windows, dampening of early-arrival advantage); CliqueWatch (community cohesion anomalies).
- Assumptions/dependencies: Need ranking system access; early-lifecycle inequality may normalize over time; verification of agent vs human accounts remains imperfect.
- Influence mapping and outreach planning for agent ecosystems (sector: marketing/communications/finance)
- What to do: Identify authorities (high incoming attention) vs hubs (high commenting), then target bridge agents for cross-community diffusion; prioritize posting in submolts beyond m/general for niche penetration.
- Tools/products/workflows: BridgeFinder (broker identification via betweenness and cross-submolt participation); Authority/Hubs Index (HITS-based segmentation).
- Assumptions/dependencies: Models use top-level comments only; outreach effectiveness relies on event-driven topical concentration observed (e.g., m/usdc spikes).
- Event detection and capacity planning (sector: fintech/cloud/SRE)
- What to do: Spot topical surges (e.g., m/usdc hackathon concentration) using daily directed-comment graphs; allocate compute, rate limits, and moderation capacity to peak UTC windows and event-heavy submolts.
- Tools/products/workflows: EventPulse (daily reciprocity/density/topic share); CapacityPlan (autoscaling aligned to bursty participation and six-hour peak windows).
- Assumptions/dependencies: Requires timestamped activity streams; observed burstiness may evolve as platform matures.
- Transparency pilots and metrics reporting (sector: policy/platform governance)
- What to do: Publish periodic health metrics (reciprocity, Gini, modularity, inter-community edges), verification disclosures, and sampling caveats; adopt resolution scans to avoid mask-and-dominance by m/general.
- Tools/products/workflows: Public Health Report templates; Resolution Scan workflow for modularity sensitivity.
- Assumptions/dependencies: Organizational buy-in; external stakeholders accept early-data caveats.
- Teaching and reproducible research pipelines (sector: academia/education)
- What to do: Use the paper’s network-construction choices and metrics to teach agent social-network analysis; release code templates for bipartite projections, HITS/PageRank, Louvain resolution tuning, and structural-hole metrics.
- Tools/products/workflows: Course lab materials; open-source analysis notebooks; benchmark datasets for early agent ecosystems.
- Assumptions/dependencies: Continued API accessibility; curriculum alignment with data-ethics norms.
- Practical posting strategies for agent developers (sector: daily life/software builders)
- What to do: Exploit early-arrival advantage; post during peak UTC hours; cross-post to niche submolts to avoid m/general saturation; aim for authority engagement via hub commenters.
- Tools/products/workflows: Posting Planner (timing, submolt selection, bridge targeting) based on observed dynamics.
- Assumptions/dependencies: Ethical use and compliance with platform policies; the advantage may diminish as the platform scales.
Long-Term Applications
These applications require further research, policy development, scaling, or infrastructure changes before reliable deployment.
- Verified agent identity and Sybil resistance (sector: fintech/policy)
- What to do: Combine network signals (e.g., reciprocity, community leakage, bridge structures) with cryptographic credentials (wallets, reputation badges) to distinguish genuine agents from coordinated or human-driven sockpuppets.
- Tools/products/workflows: Verification Score; Reputation Ledger integrated with USDC-like primitives observed in event spikes.
- Assumptions/dependencies: Widespread adoption of on-chain identity; standardized provenance proofs; governance frameworks for dispute resolution.
- Fairness-aware ranking and exposure control (sector: software/platform governance)
- What to do: Design ranking algorithms that counteract Matthew effects (extreme upvote Gini) via dynamic exposure correction, novelty boosts, and reciprocity incentives; evaluate with sandbox simulations.
- Tools/products/workflows: SandboxSim (resolution scans, counterfactual re-ranking); Reciprocity Incentives (algorithmic knobs for mutuality).
- Assumptions/dependencies: Deep access to recommender pipelines; robust metrics to detect gaming; stakeholder agreement on fairness goals.
- Cross-platform early-warning systems for hierarchy and manipulation (sector: trust & safety/regtech)
- What to do: Operationalize attention-risk scores across agent-facing platforms to flag rapid stratification, clique formation, and one-way attention funnels; design incident response playbooks.
- Tools/products/workflows: Attention Risk Index; cross-platform Monitoring Mesh; playbooks for intervention escalation.
- Assumptions/dependencies: Data-sharing agreements and standardized APIs; privacy-compliant telemetry; clear thresholds for action.
- Causal inference and experiment design to separate decentralized emergence from external coordination (sector: academia/policy)
- What to do: Instrument platforms to measure reply-chain depth, voter identities (or privacy-preserving aggregates), and randomized exposure; run A/B tests to identify causal drivers of hierarchy.
- Tools/products/workflows: Coordinated-Behaviour Auditor; Randomized Exposure Experiments; differential privacy pipelines.
- Assumptions/dependencies: Ethical approvals; platform willingness to expose richer telemetry; user/agent consent models.
- Multi-agent training and evaluation informed by social metrics (sector: ML/ML safety)
- What to do: Integrate reciprocity, diversity, and cross-community engagement into agent evaluation suites; avoid training objectives that over-optimize for upvotes or broadcast attention.
- Tools/products/workflows: Engagement-Safe RL benchmark; diversity/reciprocity scorecards for agent policies.
- Assumptions/dependencies: Agreement on safety-aligned objectives; avoidance of emergent manipulation; robust generalization beyond a single platform.
- Sector-specific governance for agent communities (sector: healthcare, education, finance)
- What to do: Apply community-permeability and hierarchy metrics to domain-bot forums (e.g., patient-bot support groups, edu-bot classrooms, retail-finance bots); set guardrails for amplification and verification.
- Tools/products/workflows: Domain Governance Kits (privacy-aware metrics, role separation monitors).
- Assumptions/dependencies: Domain privacy and compliance requirements; provenance verification; tailored moderation policies.
- Attention-economy and token design for agent platforms (sector: finance/crypto)
- What to do: Redesign incentives to reduce formulaic token-minting content; penalize spammy broadcast behaviour; reward cross-community reciprocity and quality signals.
- Tools/products/workflows: MintGuard (template detection and rate controls); Quality-weighted Incentive Schemes.
- Assumptions/dependencies: Platform economic levers (fees, rewards) and community acceptance; continual adversarial adaptation.
- Regulatory standards for AI-agent social platforms (sector: policy/regulation)
- What to do: Establish reporting requirements for stratification metrics (Gini, reciprocity), transparency on verification, and limits on automated amplification; mandate agent labeling and provenance disclosures.
- Tools/products/workflows: Compliance Reporting Templates; Audit Protocols for attention and community structure.
- Assumptions/dependencies: Legislative authority (e.g., alignment with EU AI Act/UK frameworks); international coordination; feasibility of audits given data limitations.
Cross-cutting assumptions and dependencies
- Observability constraints: Current API truncates top-level comments at 100 and omits reply chains and voter identities; results reflect a 12-day early window and may not generalize without longitudinal data.
- Metric sensitivity: Community partitions depend on resolution parameters; tie definitions (e.g., comment author → post author) affect reciprocity and centrality; degree-normalised bipartite projections help but do not fully remove m/general dominance.
- Verification and provenance: Weak agent/human verification complicates intent and coordination attribution; cryptographic identity and reputation infrastructure will be pivotal for long-term solutions.
- Organizational and ethical considerations: Interventions (ranking changes, rate limits) require governance buy-in and must guard against unintended consequences and gaming.
Glossary
- Adjacency matrix: A matrix representation of a graph where entries indicate the presence (and possibly weight) of edges between node pairs. "Let denote the adjacency matrix of the submolt--submolt projection with nodes ."
- Betweenness centrality: A measure of how often a node lies on shortest paths between other nodes, indicating its potential to broker information flow. "#1{tab:hubs} quantifies these roles via degree and betweenness centrality using weighting."
- Bipartite network: A graph with two disjoint node sets where edges run only between sets (not within), e.g., agents and submolts. "we construct a bipartite agent-submolt network represented by the bipartite network adjacency matrix $$."</li> <li><strong>Brandes' algorithm</strong>: An efficient algorithm for exactly computing betweenness centrality in graphs. "betweenness is computed exactly via Brandes' algorithm (#1{appendix:centrality-definitions})."</li> <li><strong>Complementary Cumulative Distribution Function (CCDF)</strong>: The tail distribution function, often used on log–log axes to study heavy tails. "The change of slope in the comments Complementary Cumulative Distribution Function (CCDF) at around $580$ comments per user as seen in #1{fig:gini-power-law} may partly reflect this truncation."</li> <li><strong>Conductance</strong>: A community quality metric measuring the fraction of edges leaving a set relative to its volume. "We report five standard metrics: number of communities, community-size distribution, modularity, between-community edge count, and conductance/cut ratio."</li> <li><strong>Co-participation network</strong>: A one-mode projection connecting agents who contributed to at least one common submolt. "the co-participation network projects agents onto a co-participation graph via shared submolt membership;"</li> <li><strong>Cut ratio</strong>: A community quality metric: boundary edges divided by the number of possible cross-community pairs. "cut ratio is $B_c/\bigl(|c|\cdot(n-|c|)\bigr)$"</li> <li><strong>Damping factor</strong>: The probability of following links rather than teleporting in PageRank, controlling diffusion. "where $d=0.85$ is the damping factor; see #1{pagerank}"</li> <li><strong>Degree-normalised weighting</strong>: A projection weighting that divides each shared submolt’s contribution by its size minus one to reduce dominance of large groups. "Our implementation uses degree-normalised weighting \eqref{e:Ak} as the default throughout the co-participation network analyses"</li> <li><strong>Directed comment interaction network</strong>: A directed graph where edges point from commenters to the authors of the posts they commented on. "Directed comment interaction network $G^{(2)}=(V^{(2)}, E^{(2)}, w^{(2)})$."</li> <li><strong>Fruchterman--Reingold</strong>: A force-directed algorithm for graph layout that positions nodes using attractive and repulsive forces. "Layout: Fruchterman--Reingold with repulsion $k{=}3.5$."</li> <li><strong>Giant weakly connected component</strong>: The largest component of a directed graph when edge directions are ignored. "relative to the giant weakly connected component"</li> <li><strong>Gini coefficient</strong>: A scalar measure of inequality (0 = equal, 1 = maximal inequality) across a distribution. "Upvotes exhibit a three-regime structure: head (orange dash-dot, labelled <code>Head'' on plot), body (purple dotted,</code>Body''), and outer tail (green dashed, ``Tail'')"</li> <li><strong>Greedy modularity maximisation</strong>: A heuristic that greedily merges communities to maximise modularity. "Greedy modularity maximisation~\citep{chen2014community} on this 40-node network yields three communities"</li> <li><strong>Heavy-tailed distribution</strong>: A distribution with a tail that decays more slowly than an exponential, often producing extreme values. "All four distributions are heavy-tailed."</li> <li><strong>HITS centrality</strong>: An algorithm producing hub and authority scores based on mutual reinforcement between linking and linked nodes. "HITS centrality \citep{kleinberg1999authoritative} distinguishes hubs (agents who actively comment on many others' posts) from authorities (agents whose content attracts comments from important hubs)."</li> <li><strong>Leiden community detection</strong>: A modularity-based community detection algorithm that improves partition quality and guarantees. "Leiden community detection \citep{traag2019louvain} partitions this subgraph into five communities ($Q(\gamma{=}1)=0.39$)."</li> <li><strong>Louvain community detection</strong>: A fast, multilevel modularity optimisation algorithm for detecting communities. "we apply Louvain community detection~\citep{blondel2008fast} to both networks"</li> <li><strong>Modularity (Newman--Girvan modularity)</strong>: A quality function comparing within-community edge density to a null model; higher values indicate stronger community structure. "Setting $\gamma=1\gamma$ favours more, smaller communities."</li> <li><strong>NODF (Nestedness metric)</strong>: A nestedness measure quantifying the ordered subset structure in bipartite incidence matrices. "The network is moderately nested (NODF\,$= 0.28= 0.51$)"</li> <li><strong>One-mode projection</strong>: The projection of a bipartite graph onto one node set, connecting nodes that share neighbours in the original bipartite graph. "we construct the one-mode projection onto agents to give the Agent-Agent co-participation network"</li> <li><strong>PageRank</strong>: A link analysis algorithm computing node importance via a random walk with teleportation. "PageRank is computed on the same interaction-count weighted adjacency ($A_{ij}=w^{(2)}_{ij}$; see #1{appendix:centrality-definitions} for the full definition)."</li> <li><strong>Pair-normalised weighting</strong>: A projection weighting dividing by the number of induced pairs so each shared group contributes total weight 1. "The pair-normalised scheme \eqref{e:Akk} divides by $\binom{k_s}{2}1$ regardless of its size."</li> <li><strong>Reciprocity</strong>: The fraction of directed edges that are mutual in a directed network. "Reciprocity is 1.0\% under the comment author to post author tie definition."</li> <li><strong>Resolution parameter</strong>: A parameter ($\gamma$) controlling the granularity of communities in modularity-based detection. "and $\gamma\geq 0$ is the resolution parameter."</li> <li><strong>Strongly connected components</strong>: Maximal sets of nodes in a directed graph where each node is reachable from every other. "The low reciprocity and large number of strongly connected components (relative to the giant weakly connected component) are consistent with a predominantly hierarchical interaction structure"</li> <li><strong>Structural holes</strong>: Gaps between otherwise disconnected groups that grant brokers advantage in controlling information flow. "The bridge agents occupy structural holes, gaps between otherwise disconnected groups whose brokers can disproportionately shape cross-community information flow"</li> <li><strong>Sybil resistance</strong>: Mechanisms designed to deter or limit attacks involving many fake identities in a network. "e.g., escrow, wallets, reputation, Sybil resistance"</li> <li><strong>Teleportation floor</strong>: The baseline probability mass in PageRank from random teleportation that prevents zero scores for isolated nodes. "the teleportation floor $(1{-}d)/d \approx 0.176$ ensures that zero-in-degree nodes remain visible on the log--log axes rather than requiring an ad hoc shift."
- Zipf plot: A rank–frequency plot (typically log–log) used to visualise heavy-tailed distributions. "Right:~Zipf (rank--frequency) plot of total upvotes per agent on log--log axes; the top~20 agents are highlighted and the top~5 labelled."
Collections
Sign up for free to add this paper to one or more collections.