Actor-Curator: Co-adaptive Curriculum Learning via Policy-Improvement Bandits for RL Post-Training
Abstract: Post-training large foundation models with reinforcement learning typically relies on massive and heterogeneous datasets, making effective curriculum learning both critical and challenging. In this work, we propose ACTOR-CURATOR, a scalable and fully automated curriculum learning framework for reinforcement learning post-training of LLMs. ACTOR-CURATOR learns a neural curator that dynamically selects training problems from large problem banks by directly optimizing for expected policy performance improvement. We formulate problem selection as a non-stationary stochastic bandit problem, derive a principled loss function based on online stochastic mirror descent, and establish regret guarantees under partial feedback. Empirically, ACTOR-CURATOR consistently outperforms uniform sampling and strong curriculum baselines across a wide range of challenging reasoning benchmarks, demonstrating improved training stability and efficiency. Notably, it achieves relative gains of 28.6% on AIME2024 and 30.5% on ARC-1D over the strongest baseline and up to 80% speedup. These results suggest that ACTOR-CURATOR is a powerful and practical approach for scalable LLM post-training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to teach LLMs using reinforcement learning (RL). Instead of randomly picking practice problems, the method—called Actor-Curator—automatically chooses the most helpful problems at each step so the model learns faster and more steadily. It’s like having a smart coach (the “Curator”) who picks the best drills for the player (the “Actor,” the LLM) based on what will most improve the player right now.
What questions does the paper try to answer?
The paper focuses on simple, practical questions:
- How can we automatically pick training problems that help an LLM improve the most?
- How do we balance trying new types of problems (exploration) with sticking to known helpful ones (exploitation)?
- How can this work when the dataset is huge, diverse, and changing over time?
- How can we avoid hand-made difficulty labels or manual sorting of tasks?
How does the method work?
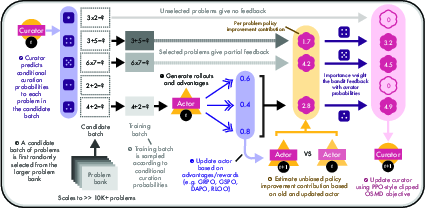
Think of training as a loop with two roles:
- The Actor: the LLM that learns to solve problems.
- The Curator: a small neural network that chooses which problems the Actor should practice on.
Here’s the simple idea, with a short list to make the steps clear:
At each training step:
- The Curator picks a set of problems for the Actor to practice.
- The Actor tries those problems and updates its strategy.
- The system estimates how much each problem helped the Actor improve.
- The Curator learns from that signal and gets better at choosing problems next time.
To make this reliable and scalable, the paper uses a few key ideas explained in everyday terms:
- Bandit problem (slot machine analogy): Imagine a row of slot machines (each “arm” is a problem). You don’t know which machine pays out most today, and it can change over time. You must decide whether to try new machines (explore) or keep playing the best-known machine (exploit). The Curator faces this same choice with problems.
- Partial feedback: You only see results from the problems you actually selected—no info about the ones you didn’t try.
- Policy improvement (measuring “how much did this help?”): After the Actor updates, the system compares performance “before vs. after” to estimate how much each chosen problem contributed to improvement. That estimate becomes the Curator’s training signal.
- Online stochastic mirror descent (gentle re-weighting): This is a way of adjusting the Curator’s problem-selection probabilities smoothly over time, nudging them toward problems that likely help most, while still keeping some exploration.
- Two-stage sampling (shortlist first, then pick): Because the dataset is huge, the Curator first draws a small candidate shortlist from a broad proposal, then re-weights that shortlist to pick the final training batch. This keeps things efficient without losing fairness.
- Proximal clipping (safety rails): Similar to a well-known RL trick (PPO), the Curator’s updates are clipped so they don’t change too fast in one go, which helps training stay stable.
Overall, the Curator is a learned function (a neural net) that outputs scores for problems. Those scores become probabilities for sampling, and they are updated based on how much each problem actually improved the Actor.
What did they find, and why does it matter?
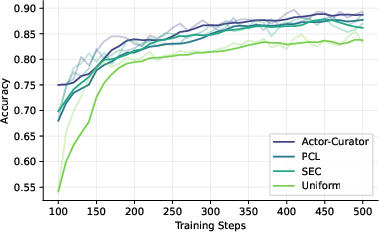
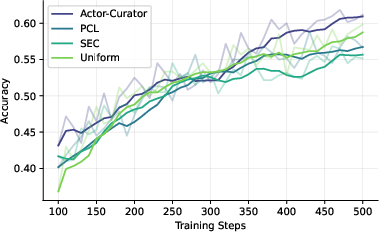
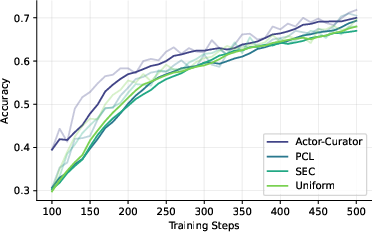
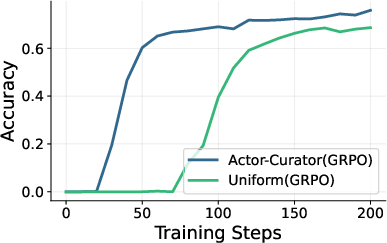
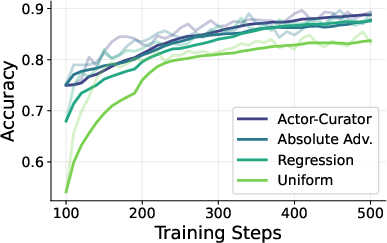
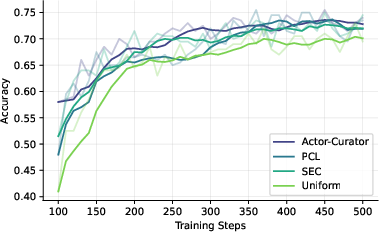
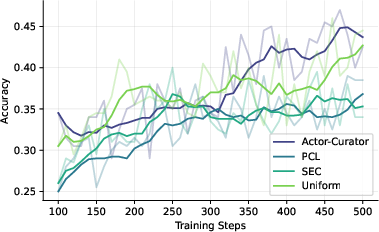
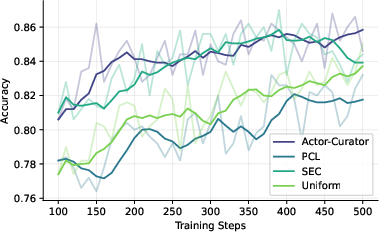
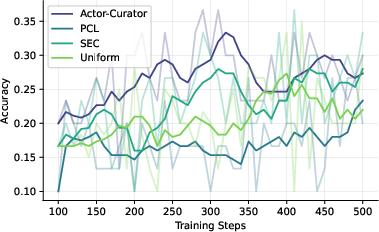
Across several tough reasoning benchmarks (Countdown, Zebra puzzles, MATH, AIME 2024, and ARC-1D), Actor-Curator:
- Beats uniform random sampling and strong learning-based baselines.
- Learns faster: up to 80% speedup to reach similar performance.
- Achieves higher peaks: about 28.6% relative gain on AIME 2024 and 30.5% on ARC-1D compared to the strongest baseline.
- Stays more stable: it keeps improving even after other methods plateau.
- Adapts difficulty over time: it tends to pick easier problems early and gradually shifts to harder ones, like a good training plan.
- Works across different RL update methods, showing it’s broadly useful.
Why this matters:
- In large, messy datasets, choosing the right training problems is crucial.
- Automating curriculum selection reduces the need for manual labels or hand-crafted buckets.
- Better training efficiency means less compute cost and faster improvement on challenging tasks.
What is the impact and what are the limitations?
Implications:
- Data selection itself can be learned and optimized, not just the model. This makes training pipelines more flexible and better suited to evolving datasets.
- The method provides a principled, scalable way to do curriculum learning for LLMs, especially in domains with clear right/wrong answers (like math, logic, and code).
- It could help build training systems that adapt in real time, making better use of large problem banks.
Limitations to keep in mind:
- It relies on a reliable reward signal (you need a way to score answers), so it’s best for tasks with verifiable correctness.
- If the Actor’s RL updates are unstable, no curriculum can fully fix that.
- There’s a small computational overhead for running the Curator (about 9% more wall-clock time in the experiments), though this is offset by faster learning and better results.
In short: Actor-Curator is like pairing a strong learner with a smart coach who picks the right practice problems at the right time. That teamwork helps the learner improve faster, more steadily, and reach higher performance—without manual labels or hand-crafted curricula.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list distills what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research.
- Theoretical guarantees under function approximation are absent: the regret bound is stated for tabular OSMD with unbiased bandit feedback, but there is no analysis for neural curator parameterization, PPO-style clipping, or non-convex optimization (e.g., approximation error, bias from clipping, convergence/stability).
- Non-oblivious feedback is not treated theoretically: utilities depend on the actor update induced by the curator’s own selections, violating standard bandit assumptions. No regret or stability guarantees are given for this coupled (non-oblivious) setting.
- Per-problem “policy improvement” credit relies on small policy updates, but conditions linking step size/KL constraints to estimator validity are not formalized; no sensitivity study to larger step sizes is provided.
- The unbiasedness claim for the utility estimator assumes exact knowledge of inclusion probabilities and the evaluation distribution; finite-sample error and variance bounds are not derived.
- High-variance importance weights (π{t+1}/πt) can destabilize utility estimation in practice; no variance-reduction strategy (e.g., control variates, clipping analysis, doubly robust estimators) is analyzed or ablated.
- The approach presumes a known evaluation distribution p_X(x); the paper does not show how to estimate or approximate p_X when unknown, nor study sensitivity to misspecification or distribution shift between evaluation and available training data.
- Two-stage sampling requires known marginal inclusion probabilities q(x) and q_min > 0; the paper leaves open how to compute/estimate q(x) under non-uniform or system-dependent proposals and the impact of errors in q(x) on bias/regret.
- The surrogate updates rely on conditional distributions over candidate sets; there is no analysis of whether optimizing conditionals consistently updates the global curator distribution over the entire corpus, especially with very large or evolving datasets.
- The method maximizes immediate (one-step) policy improvement; longer-horizon (non-myopic) curriculum objectives and their trade-offs are not modeled or evaluated.
- Exploration–exploitation is handled implicitly via entropy regularization and lower-bound clipping, but there is no principled schedule or analysis for exploration rates, nor ablations on the exploration floor α and its effects.
- The choice and design of the proposal distribution for candidate sampling is underexplored: how proposal bias, candidate set size, or retrieval strategies affect coverage, regret, and final performance is not systematically studied.
- Clipping ranges in the proximal curator objective are chosen heuristically; there is no guidance or sensitivity analysis connecting clip values to stability, bias, and downstream performance.
- Advantage estimation depends on limited rollouts per problem; the effect of rollout budget on utility estimator variance, sample efficiency, and overall performance is not characterized.
- Extension beyond single-turn, verifiable-reward settings is untested: multi-turn dialogues, tool-augmented policies, or sparse/subjective reward domains (e.g., alignment tasks) remain open.
- Robustness to reward misspecification and label noise is unaddressed; it is unclear how curator decisions behave under imperfect or adversarial rewards common in RLHF/RLAIF.
- The framework is evaluated on static problem banks; how it performs with streaming or continually growing datasets (which the motivation highlights) is not demonstrated.
- Diversity and coverage risks are not measured: the curator may over-exploit narrow subsets of problems. There are no diagnostics or constraints to prevent sampling collapse or forgetting of underrepresented skills.
- Compute accounting is incomplete: the reported “up to 80%” speedup is in steps, not tokens or wall-clock, and curator overhead is only given as an average (+~9%); detailed profiling (tokens/sec, memory, batching effects) and scaling behavior to larger models/datasets are missing.
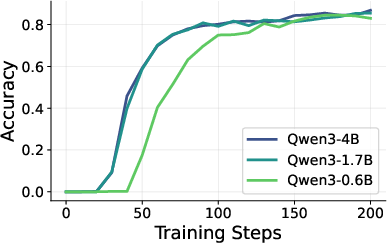
- Generality across model scales is unclear: results are shown for ~3B models (with a 0.6B curator). It is unknown if gains persist or change for larger actors (e.g., 7B–70B) or smaller ones.
- Baseline coverage is limited: comparisons with alternative bandit strategies (e.g., EXP3, UCB/TS with partial monitoring), dataset reweighting methods, or search-driven curricula are not provided.
- Statistical robustness is not reported: there are no confidence intervals, standard deviations across seeds, or statistical tests; sensitivity to random seed and initialization is unknown.
- A negative result (MATH500 underperformance) is not analyzed; failure modes (when curation hurts) and diagnostics to detect/mitigate them are missing.
- Interplay with actor update methods is only partially explored (GRPO/GSPO); applicability to other RLHF/RLVR paradigms (e.g., PPO-based RLHF, DPO, offline RL, self-play, search-augmented training) is an open question.
- Practical details on curator initialization and transfer are limited: the impact of starting from different pretraining checkpoints, training the curator from scratch, or cross-domain reuse is not evaluated.
- Handling of duplicates/near-duplicates and data hygiene in large corpora is not discussed, yet could bias utility estimates and curation behavior.
- Integration with retrieval pipelines and indexing is not addressed: how to efficiently score/select from millions of problems and maintain q(x) estimates at web scale remains open.
- Compatibility with other efficiency techniques (e.g., selective rollouts, adaptive per-problem budgets) is not explored; joint optimization of “which problems” and “how many rollouts per problem” is an open avenue.
- The method’s impact on learned representations (e.g., which skills are strengthened or neglected) and interpretability of the curator’s selections is not analyzed.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams already performing RL-based post-training, especially on tasks with verifiable rewards (math, code, logic). Each item includes sector(s), actionable workflow ideas, and feasibility notes.
- Adaptive data selection for RL post-training of reasoning LLMs
- Sectors: software/AI, education
- What to do: Replace uniform/random sampling in existing GRPO/GSPO/GRPO-like pipelines with Actor-Curator’s two-stage sampling and OSMD-based curator. Instrument per-problem policy-improvement estimates via importance ratios and advantages; train the curator with the proximal clipped objective.
- Tools/workflows: Integrate into VERL or similar RLHF/RLVR frameworks; stand up a “Curator-as-a-Service” microservice that exposes sampling APIs to training jobs; add dashboards for per-problem utilities and difficulty progression.
- Assumptions/dependencies: Verifiable reward model (e.g., correctness checkers); access to large problem banks; stable actor updates; coverage guarantees (q(x) ≥ q_min); modest extra compute (~9% overhead reported).
- Test-driven code generation RLVR with curated challenges
- Sectors: software, developer tools
- What to do: Use unit tests as rewards (pass/fail). Feed coding tasks through the curator to prioritize those that yield the largest expected policy improvement for the current model; continuously retrain assistants used in IDEs and CI systems.
- Tools/workflows: Automatic harvesting of coding tasks and test suites; per-task advantage estimation; CI-integrated retraining cycles.
- Assumptions/dependencies: High-quality unit tests; robust importance sampling estimates between pre/post policy; contained evaluation distribution.
- Math and logic tutoring models with curated curricula
- Sectors: education
- What to do: Post-train math/logic tutors (K–12, competition math, test prep) using curated problem banks where correctness can be automatically graded; deploy improved models in tutoring platforms.
- Tools/workflows: Problem ingestion pipeline with two-stage sampling; learning progress monitoring via per-problem utilities; difficulty progression tracking.
- Assumptions/dependencies: Reliable auto-graders for correctness; appropriate evaluation distribution aligning with real student tasks.
- Analytics and spreadsheet assistants with verifiable arithmetic
- Sectors: finance, enterprise productivity
- What to do: Curate finance-relevant tasks (PnL reconciliation, formula translation, unit conversions) with exact-check rewards; post-train assistants to reduce arithmetic errors and hallucinations.
- Tools/workflows: Task banks with reference answers; bandit curator service; continuous training loops with guardrails.
- Assumptions/dependencies: Strong, unambiguous reward signals; manageable domain coverage.
- Safety/compliance-focused post-training via curated red-teaming prompts
- Sectors: policy/governance, enterprise AI safety
- What to do: Build red-teaming prompt banks with pass/fail rule-based checkers (e.g., prompt injection defenses, PI leakage, prohibited content). Use Actor-Curator to focus training on prompts that maximize safety policy improvement.
- Tools/workflows: Safety checker APIs; curated sampling scheduler; compliance dashboards tracking safety utilities.
- Assumptions/dependencies: Quality of automated safety checkers; ongoing coverage of evolving threat prompts.
- MLOps efficiency and energy reduction
- Sectors: energy/operations, platform engineering
- What to do: Adopt curated sampling to reach target performance with fewer steps (reported up to 80% speedup), lowering compute cost and energy consumption.
- Tools/workflows: Training orchestration that toggles curated vs. uniform sampling; cost/performance tracking; autoscaling tied to convergence.
- Assumptions/dependencies: Comparable convergence criteria; correct calibration of clipping/hyperparameters to avoid instability.
- Research benchmarking and curriculum learning studies
- Sectors: academia
- What to do: Use Actor-Curator to study non-stationary bandits and curriculum learning; replicate regret analysis under partial feedback; compare policy-improvement targets vs. difficulty proxies.
- Tools/workflows: Open-source integration and experiment harnesses; ablation suites; reporting on dynamic regret and variance.
- Assumptions/dependencies: Access to diverse, evolving datasets; reproducible actor update configs.
Long-Term Applications
These applications extend the approach to new domains or add constraints. They typically require further research, scaling, or validation (e.g., safety, regulatory compliance).
- Curators for multi-turn agentic LLMs and tool-use tasks
- Sectors: software/AI, automation
- Vision: Generalize policy-improvement estimation to multi-step dialogs, tool calls, and search/planning (RLVR with complex trajectories).
- Potential products: “Agent Curator” for task orchestration; sampling of tool-invocation tasks most likely to improve agent performance.
- Dependencies: Multi-turn performance difference identities; trajectory-level advantage estimation; stable actor updates in long horizons.
- Personalized human learning curricula inspired by policy-improvement bandits
- Sectors: education, EdTech
- Vision: Adapt OSMD-based curation to human learners, selecting practice problems that maximize learning gains rather than model improvement.
- Potential products: LMS plugins that recommend problems with dynamic exploration–exploitation; individualized progress dashboards.
- Dependencies: Reliable proxies for human “learning advantage”; ethical data use; longitudinal studies; personalization models.
- Healthcare decision-support training on verifiable micro-tasks
- Sectors: healthcare
- Vision: Curated RLVR training on micro-tasks with exact checks (dose calculations, risk scores, unit conversions) to build safer clinical assistants.
- Potential products: Hospital-grade post-training pipelines; regulatory-ready audit trails showing policy improvement focus on safety-critical tasks.
- Dependencies: Clinical validation; regulatory compliance; robust medical reward models and checkers; defensive coverage against distribution shifts.
- Robotics task curricula under non-stationary utilities
- Sectors: robotics, manufacturing
- Vision: Extend curation to embodied RL tasks (sim-to-real, multi-goal learning), selecting tasks that maximize policy improvement while balancing exploration.
- Potential products: Task schedulers for robot training; automated curriculum generation across manipulations and navigation.
- Dependencies: Verifiable reward shaping; sim fidelity; safety constraints; efficient importance sampling in continuous control.
- Continual learning with streaming data and shift-aware curation
- Sectors: software/AI platforms
- Vision: Deploy Actor-Curator in pipelines that ingest new tasks continuously, tracking utility drift (V_T) and adapting sampling for robustness.
- Potential products: Shift-aware sampling services; drift dashboards; auto-retuning of curator temperatures/clipping.
- Dependencies: Streaming evaluation distributions; drift detection; scalable two-stage sampling with guaranteed minimal coverage.
- Curation-as-a-Service marketplaces and shared curator models
- Sectors: AI ecosystem, data platforms
- Vision: Offer curator models pre-trained on meta-features of tasks; vendors supply task banks with inclusion probability guarantees.
- Potential products: Curator model zoo; marketplace scoring APIs; interoperable sampling standards.
- Dependencies: Standardized task metadata; governance for data rights and fairness; mechanisms to prevent mode collapse on popular tasks.
- Constrained safety/fairness-aware curation objectives
- Sectors: policy/governance, responsible AI
- Vision: Augment OSMD with constraints (coverage, fairness, risk limits), ensuring the curator optimizes improvement while meeting policy targets.
- Potential products: Compliance-grade sampling schedulers; certifiable training reports (coverage bounds, fairness audits).
- Dependencies: Measurable safety/fairness metrics; constrained optimization tooling; policy-aligned reward definitions.
- Integration with retrieval-augmented generation and search-based RLVR
- Sectors: software/AI
- Vision: Curate not only problems, but also retrieval contexts and search branches that maximize policy improvement signal.
- Potential products: Retrieval curator components; branch-pruning schedulers in self-training/search systems.
- Dependencies: Verifiable rewards over retrieved contexts; stable estimation of improvement across retrieval noise.
- Compute/carbon governance frameworks referencing adaptive curricula
- Sectors: policy
- Vision: Regulators and organizations encourage efficient training via adaptive sampling to reduce carbon footprint while maintaining quality.
- Potential products: Best-practice guidelines; certification programs for energy-aware post-training.
- Dependencies: Accepted efficiency benchmarks; traceable energy/performance reporting; multi-stakeholder agreement.
- Curator distillation and low-footprint deployment
- Sectors: software/AI infrastructure
- Vision: Distill the curator to lightweight models for edge-training or low-resource labs, reducing overhead while retaining gains.
- Potential products: Tiny-curator libraries; parameter-efficient fine-tuning kits.
- Dependencies: Effective distillation methods; robust performance under constrained compute; calibration protocols.
Common Assumptions and Dependencies Across Applications
- Verifiable rewards: Strong, objective reward signals (pass/fail, exact numeric checks) are crucial; subjective domains need new reward modeling.
- Stable actor updates: Benefits depend on reliable RL post-training (GSPO/GRPO or similar) and small-to-moderate update steps to make policy-improvement estimates meaningful.
- Coverage and exploration: Two-stage sampling must ensure minimal inclusion probability (q(x) ≥ q_min) to avoid excluding valuable tasks and to control bias.
- Monitoring and guardrails: Practical deployments need dashboards for utilities/difficulty, clipping bounds, and drift (V_T) to manage non-stationarity and partial feedback.
- Compute trade-offs: Curator adds overhead but typically pays off via fewer steps and faster convergence; careful engineering keeps the net gain positive.
Glossary
- Advantage (function): In reinforcement learning, the relative value of an action compared/logged sample compared to a baseline under a policy. "absolute mean advantage"
- Autoregressive LLM: A model that generates each token conditioned on previous tokens. "Let denote a pretrained autoregressive LLM"
- Bandit feedback: Feedback setting where only selected actions (arms) reveal their outcomes. "The curator observes bandit feedback only on selected problems"
- Boltzmann transform: A softmax-based mapping that converts scores into a probability distribution using a temperature parameter. "converted into a sampling distribution via a Boltzmann transform with temperature "
- Dynamic regret: Regret measured against a time-varying comparator sequence in online learning. "Then the cumulative dynamic regret satisfies"
- Evaluation distribution: The fixed distribution over data points used to assess performance. "Let $p_{\mathcal{X}$ be a fixed evaluation distribution over ."
- Exponentiated-gradient update: A multiplicative-weights update arising from mirror descent with negative-entropy regularization. "This yields the exponentiated-gradient update"
- Exploration--exploitation trade-off: Balancing trying uncertain options vs. leveraging known good ones. "Exploration--exploitation trade-off."
- Function approximation: Using a parameterized model (e.g., a neural network) to represent a distribution or policy instead of a table. "we derive a function-approximation variant of OSMD that trains the curator as a neural network"
- GRPO: A group-based policy optimization method for RL post-training of LLMs. "e.g., GRPO~\citep{shao2024deepseekmath} or GSPO~\citep{ahmadian2024back})."
- GSPO: Group Sequence Policy Optimization; a stabilized variant of GRPO for RL post-training. "Unless otherwise specified, the actor is trained using GSPO, a stabilized variant of GRPO"
- Importance ratio: The ratio of probabilities under new vs. old distributions used to reweight samples. "Define the importance ratio and sub-objective as"
- Importance sampling: A technique to reweight samples from one distribution to estimate expectations under another. "Applying importance sampling yields"
- KL-regularized objective: An optimization objective augmented with a Kullback–Leibler divergence penalty to constrain updates. "Directly optimizing the KL-regularized objective in~\eqref{eq:curator_surrogate} can be unstable with neural network parameterization"
- Marginal inclusion probability: The probability that an item appears in a candidate set after the first sampling stage. "Here denotes the induced marginal inclusion probability"
- Metropolis--Hastings: A Markov chain Monte Carlo method for sampling from complex distributions. "e.g., Metropolis--Hastings"
- Negative-entropy regularizer: A mirror map/regularizer using negative entropy that induces multiplicative updates. "Given bandit feedback, the curator is updated with a negative-entropy regularizer:"
- Non-stationary stochastic bandit: A bandit problem where reward distributions change over time. "We cast curriculum learning as a non-stationary stochastic bandit problem"
- On-policy: Using data generated by the current policy for learning. "The curator is trained online and on-policy alongside the actor"
- Online stochastic mirror descent (OSMD): An online optimization method using mirror maps (e.g., negative entropy) with stochastic feedback. "using online stochastic mirror descent (OSMD)~\cite{banditalgorithm}"
- Performance difference identity: A result expressing performance change between policies in terms of expected advantages. "the performance difference identity~\citep{kakade2002approximately}"
- Policy improvement: The increase in expected return resulting from updating a policy. "directly maximize a policy improvement objective"
- PPO-style proximal clipping objective: A clipped objective that limits update magnitude to improve stability, inspired by PPO. "we introduce a PPO-style proximal clipping objective to stabilize curator optimization in practice."
- Proximal policy optimization (PPO): A policy gradient method using clipped surrogate objectives for stable training. "Following proximal policy optimization (PPO)~\citep{schulman2017proximal}, we adopt a clipped surrogate objective."
- Proposal distribution: A distribution used to draw candidate items prior to adaptive selection. "a candidate set of problems is sampled from a fixed proposal distribution."
- Regret guarantees: Theoretical bounds on the performance gap between an algorithm and a benchmark strategy. "and establish regret guarantees under partial feedback."
- Reward model: A function that scores model outputs to provide learning signals in RL. "A reward model assigns a scalar score to each solution."
- Rollout: Generating trajectories or samples from a policy for training or evaluation. "The actor is rolled out on to collect trajectories"
- Surrogate objective: An auxiliary optimization objective that approximates a desired update, often easier to optimize. "we optimize the following surrogate objective:"
- Two-stage sampling: Sampling a candidate set from a proposal, then selecting a training subset with the learned curator. "We therefore adopt a two-stage sampling scheme that separates coverage from adaptive curation while preserving unbiased utility estimation."
- Unbiased estimator: An estimator whose expectation equals the true quantity being estimated. "The unbiased two-stage estimator corresponding to \cref{eq:x_contribution_estimated} is"
Collections
Sign up for free to add this paper to one or more collections.

