- The paper introduces SIFormer, a transformer-based framework that enhances instance awareness by correlating 2D camera cues with 3D BEV radar features.
- It overcomes sparse and noisy 4D radar data by unifying BEV-level and perspective-level fusion through dedicated modules like SSI, CVC, and IEA.
- Empirical results on benchmarks like VoD and nuScenes demonstrate state-of-the-art detection performance and robustness to sensor calibration issues.
Boosting Instance Awareness via Cross-View Correlation with 4D Radar and Camera for 3D Object Detection
Introduction and Motivation
This paper addresses a central limitation in 3D object detection for autonomous driving: the weak geometric cues in 4D radar severely impede reliable instance activation, particularly in the context of radar-camera fusion. While 4D millimeter-wave radar offers high robustness under adverse conditions (poor lighting, inclement weather) and is economical, its point clouds are fundamentally sparse and noisy, unlike dense, geometrically informative LiDAR or semantically rich images. As a result, prior fusion paradigms—namely, BEV-level fusion (which excels at holistic scene understanding but exhibits weak instance discrimination) and perspective-level fusion (which mines instances but lacks global spatial context)—each suffer from inherent blind spots.
The SIFormer framework directly targets this dichotomy, proposing a transformer-based pipeline that bridges both fusion strategies. Its core innovation is a cross-view correlation mechanism that injects perspective-view instance cues into the BEV domain, thereby enhancing instance awareness and correcting for radar's geometric weaknesses. This dual-level scene-instance awareness is further empowered by targeted feature filtering and dedicated multimodal fusion modules, culminating in strong empirical results across diverse real-world datasets.
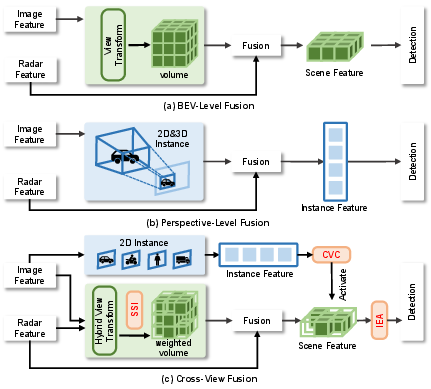
Figure 1: Fusion paradigms: (a) BEV-level, (b) perspective-level, (c) unified SIFormer bridging both for enhanced instance awareness.
Technical Approach
Sensor Fusion Limitations
The fundamental challenge in radar-camera fusion stems from the geometric sparsity of radar—visualized directly in radar vs. LiDAR comparative figures—which impairs reliable instance mining using standard BEV projections.

Figure 2: Visualization on VoD: LiDAR delivers strong geometry, whereas 4D radar only weak geometric evidence.
Earlier methods, such as IS-Fusion, proposed extracting instance features directly from BEV features, leveraging LiDAR geometry. However, in radar-based setups, view transformation significantly blurs feature localization, necessitating an alternative mechanism that prioritizes instance awareness via complementary semantic (camera) signals.
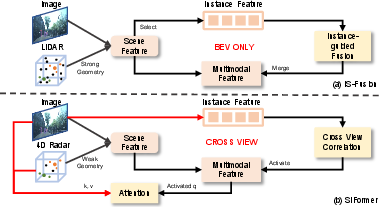
Figure 3: (a) IS-Fusion mines instance features from blurred radar-based BEV. (b) SIFormer activates instances using 2D cues via cross-view correlation.
The SIFormer pipeline consists of four sequential blocks:
- Feature Extraction: Images are encoded using a ResNet50-FPN backbone, and radar features are mapped to the BEV domain using RadarPillarNet, augmented with radar’s kinematic cues and depth projections.
- Instance Initialization within Scene: This stage employs hybrid view transformation, supervised by sparse scene integration (SSI), to suppress background interference and produce a scene feature map emphasizing regions of interest. SSI utilizes camera-based segmentation (SGW) and radar-guided depth localization (DGW), filtering features during the BEV projection to favor foreground objects and reliable depth estimates.
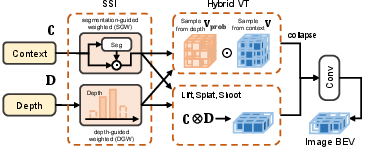
Figure 4: SSI-based instance initialization—hybrid feature fusion and view transformation with geometry/semantics filtering.
- Instance Awareness Enhancement: Central to SIFormer is the cross-view correlation (CVC) module, which connects perspective (2D) and BEV (3D) representations. 2D proposals extracted using Cascade Mask R-CNN serve as explicit instance queries. A learnable token, supported by feature disentanglement, facilitates bi-directional alignment between proposals and BEV features. The resulting correlation maps, supervised by occupancy and similarity losses, sharpen instance activation across the spatial field.
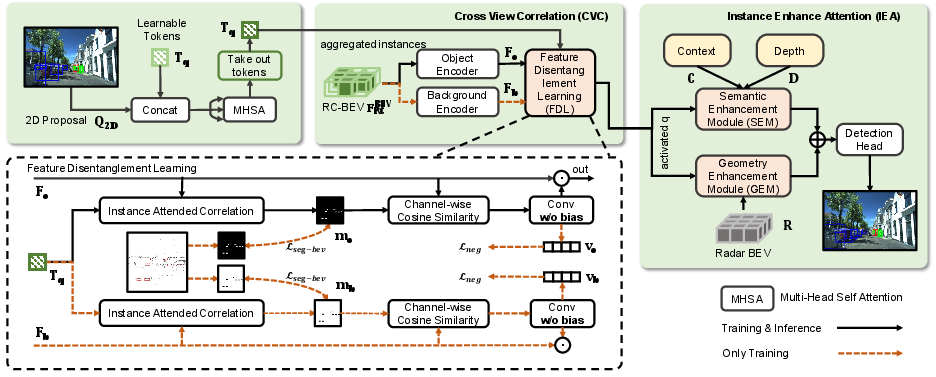
Figure 5: CVC links perspective proposal features with BEV feature maps, activating instance-aware regions.
This is followed by the Instance Enhance Attention (IEA) module, which further aggregates semantic and geometric information. IEA leverages 3D deformable cross-attention and radar-centric multi-scale fusion, ensuring that the final BEV representation is both instance-rich and sensor-robust.
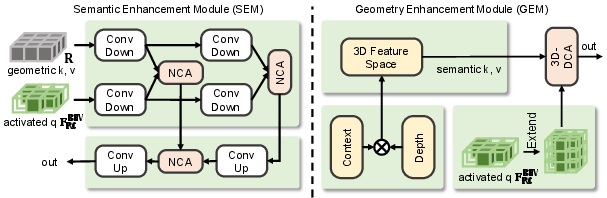
Figure 6: The IEA module: decoupled semantic and geometric enhancement via transformer attention.
- Detection Head: The instance-boosted BEV feature is processed via a 3D object detector (PointPillars backbone), subject to detection, depth, segmentation, and correlation-based losses for both initialization and enhancement stages.
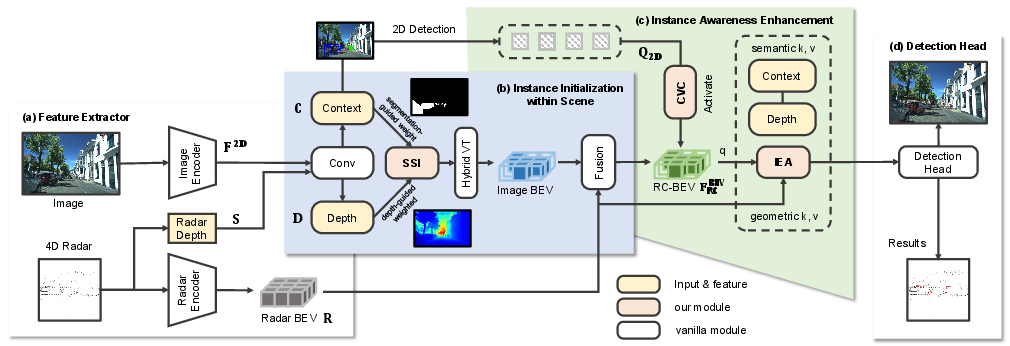
Figure 7: SIFormer architecture: parallel branches, region-of-interest filtering, cross-view fusion, and output head.
Empirical Evaluation
Benchmark Results
SIFormer establishes new state-of-the-art (SOTA) performance on View-of-Delft (VoD), TJ4DRadSet, and nuScenes. Specifically, on VoD, SIFormer (with extra LiDAR depth supervision) outperforms all prior radar-camera fusion methods in mean Average Precision (mAP) for the car, pedestrian, and cyclist classes. Even without LiDAR, SIFormer matches or beats previous bests leveraging only 4D radar and camera.
Competing approaches (e.g., SGDet3D, LXL, RCBEVDet) show clear inferiority both in comprehensive detection and in robustness to modality failures, as quantified in the experimental tables. Qualitative results further demonstrate SIFormer’s superior instance discrimination, especially under challenging or ambiguous settings.
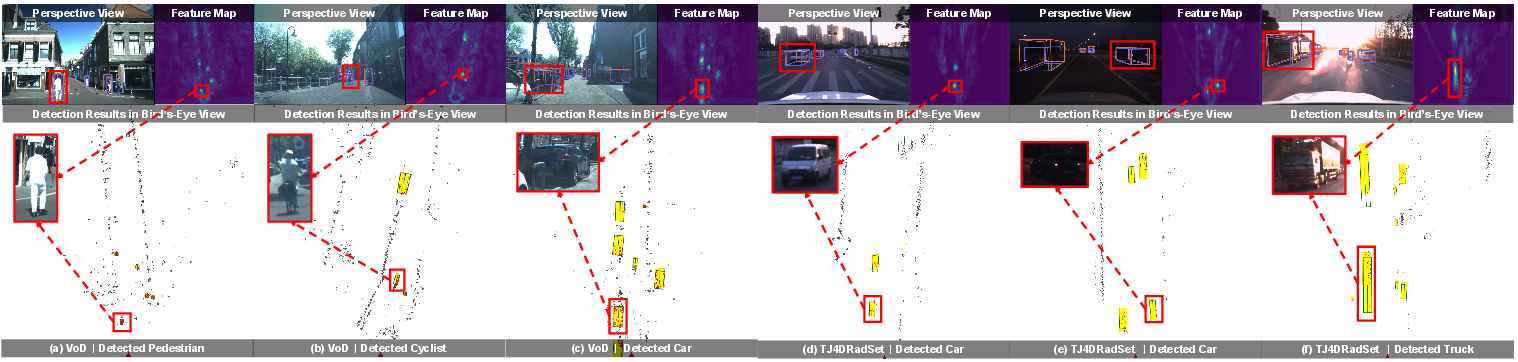
Figure 8: Qualitative detection examples on VoD and TJ4DRadSet; predictions visualize perspective/BEV agreement and instance localization.

Figure 9: Comparison of SIFormer’s predictions to ground truth; radar points and their velocity attributes are visualized.
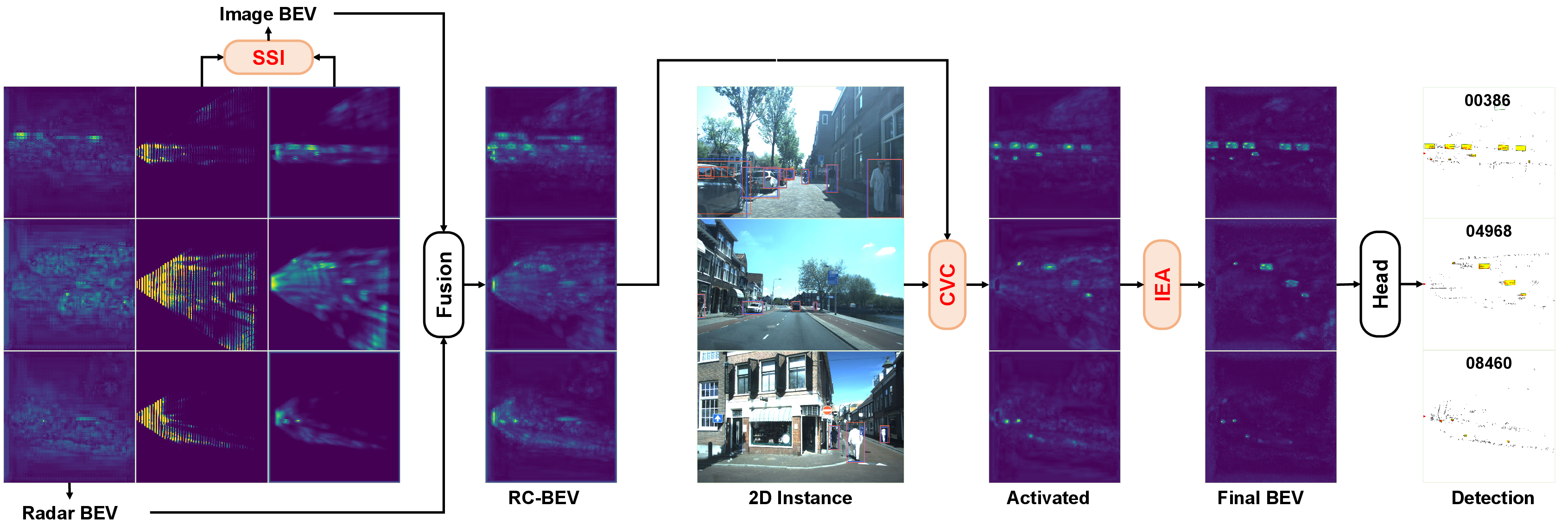
Figure 10: Progressive activation and fusion stages in SIFormer, highlighting the denoising and instance enhancement introduced by SSI, CVC, and IEA.
Ablation and Robustness
Ablation experiments isolate the impact of SSI, CVC, and IEA modules. The combination yields the largest performance gains, with SSI improving object-background contrast and CVC/IEA compensating for BEV blurring. Further, optimal selection of top-25% radar depth bins during SSI maximizes instance localization, suppressing background noise.
Distinctly, SIFormer demonstrates improved robustness to calibration perturbations between radar and camera, a key practical concern. Under artificially introduced pose or translation noise, SIFormer maintains meaningful performance margins over LXL, indicating that the dual-view instance activation pipeline mitigates reliance on perfect calibration.
Theoretical and Practical Implications
- Cross-View Correlation: By fusing 2D semantic proposals into the BEV, SIFormer effectively supplements radar's geometric deficiencies, yielding better instance discrimination even with sparse point clouds. This mechanism reflects a broader trend toward bridging "scene-level" and "instance-level" reasoning in multimodal perception.
- Noise/Failure Resistance: The region-of-interest filtering and dedicated module-level aggregation endow SIFormer with resilience to sensor outages and calibration drift—critical for real-world autonomy applications.
- Generality: While designed for 4D radar, SIFormer adapts to 3D radar (nuScenes), albeit with the greatest impact in 4D settings where geometric weakness is maximal.
Broader Impact and Future Directions
This work delivers clear advances in radar-camera fusion for 3D object detection, addressing crucial practical limitations in automotive perception with weak-geometry sensors. The introduction of explicit cross-view activation marks a shift from passive fusion toward aggressive, semantics-driven instance mining, and the transformer-based IEA module further unlocks deep modality complementarity.
SIFormer’s methodological contributions—instance-tuned scene filtering, learnable cross-view alignment, and robust multimodal attention—are broadly applicable beyond automotive, with potential extensions to maritime, aerial, and warehouse robotics scenarios using heterogeneous sensors. Future work should address inference acceleration (e.g., via pruning/distillation) and explore temporal SIFormer variants for robust sequential perception in dynamic conditions.
Conclusion
SIFormer introduces a dual-level, cross-view correlation strategy for 3D object detection using 4D radar and camera, substantially improving instance awareness and outperforming previous fusion paradigms. Its unified pipeline, combining segmentation- and depth-guided filtering, learnable cross-modal alignment, and decoupled semantic/geometric enhancement, establishes new performance standards while maintaining resilience to calibration and sensor dropout. The approach provides a blueprint for instance-centric, geometry-agnostic sensor fusion in future intelligent perception systems.
(2602.20632)