PyVision-RL: Forging Open Agentic Vision Models via RL
Abstract: Reinforcement learning for agentic multimodal models often suffers from interaction collapse, where models learn to reduce tool usage and multi-turn reasoning, limiting the benefits of agentic behavior. We introduce PyVision-RL, a reinforcement learning framework for open-weight multimodal models that stabilizes training and sustains interaction. Our approach combines an oversampling-filtering-ranking rollout strategy with an accumulative tool reward to prevent collapse and encourage multi-turn tool use. Using a unified training pipeline, we develop PyVision-Image and PyVision-Video for image and video understanding. For video reasoning, PyVision-Video employs on-demand context construction, selectively sampling task-relevant frames during reasoning to significantly reduce visual token usage. Experiments show strong performance and improved efficiency, demonstrating that sustained interaction and on-demand visual processing are critical for scalable multimodal agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces -RL, a way to train smart computer models that can look at pictures and videos, think step by step, and use tools (like small pieces of Python code) to solve harder problems. These models don’t just “read” visual inputs; they act like agents that can decide what to do next, such as zooming into an image or picking the right video frames to analyze. The goal is to keep these models actively using tools during multi-step reasoning, instead of getting “lazy” and giving short, low-effort answers.
The authors build two models using this approach:
- -Image for understanding images
- -Video for understanding videos
What questions did the researchers ask?
- How can we train open (publicly available) multimodal models to use tools over multiple steps without stopping or collapsing into short answers?
- Can letting the model pick only the parts of a video it needs (instead of reading the whole thing) make video reasoning both faster and more accurate?
- Do these agent-like behaviors actually improve performance on real tasks, like visual search, math with images, and spatial reasoning in videos?
How did they do it? (Simple explanation)
Think of the model as a student doing a project:
- The student can write notes (text) and run small Python programs (tools) to crop images, sample video frames, draw charts, or calculate things.
- After each tool run, the student sees the result (like a new picture or a number) and decides the next step.
- This loop repeats until the student gives a final answer.
Here are the key parts of their training approach, explained with everyday ideas:
- Reinforcement Learning (RL): Like giving points for good behavior. If the model answers correctly, it gets a reward. Over time, it learns what actions lead to higher points.
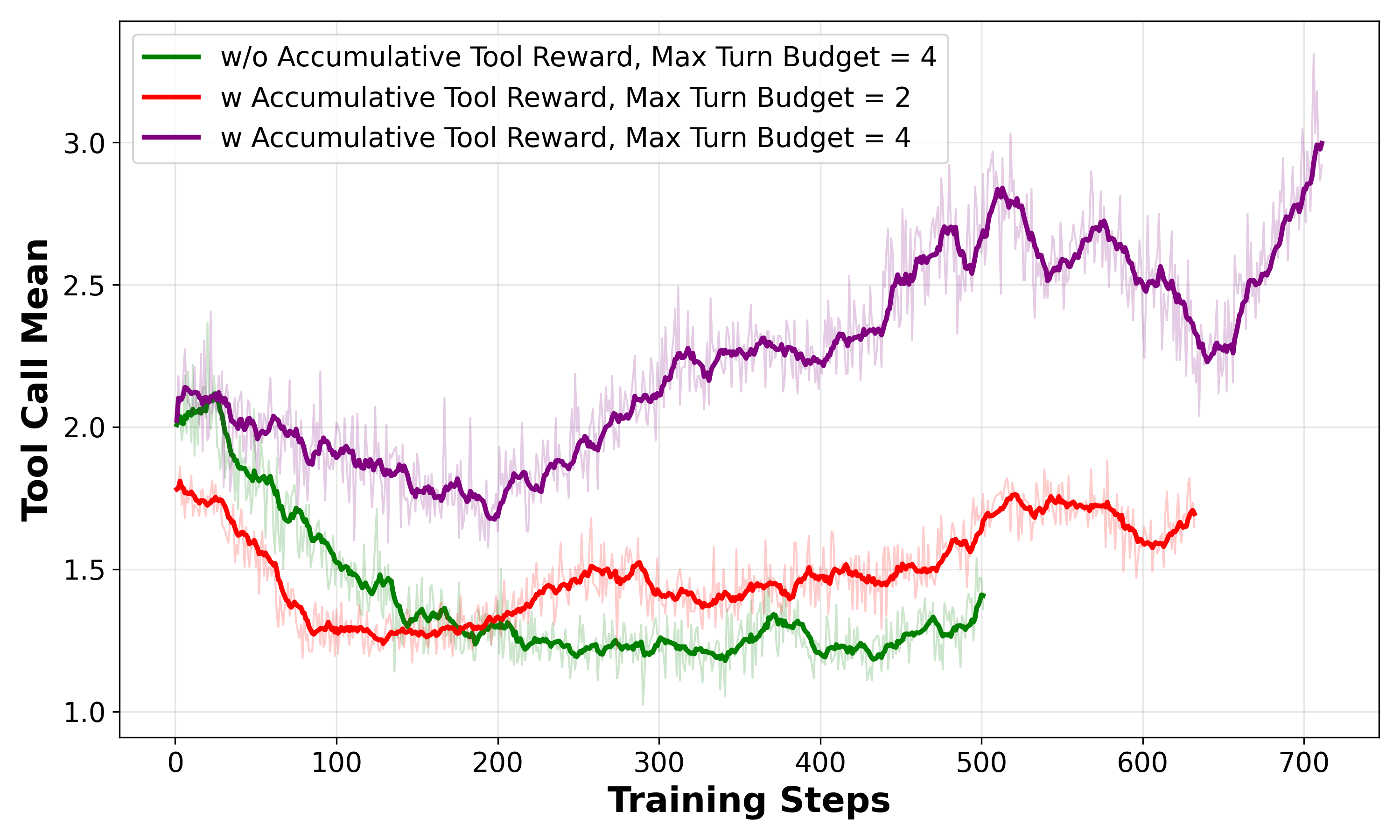
- Accumulative Tool Reward: Imagine you’re grading not only the final answer but also how well the student uses tools along the way. If the model uses tools multiple times and ends up right, it gets extra points. This encourages it to keep using tools when needed instead of quitting early.
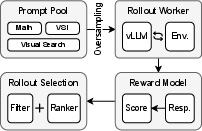
- Oversampling–Filtering–Ranking rollouts: A “rollout” is one full attempt at answering a question. The authors:
- Generate many attempts (oversampling).
- Filter out broken attempts (like code that crashed or didn’t run).
- Rank the remaining attempts by how useful they are for learning (favoring groups where some attempts succeed and others fail, because those teach the model more).
- This keeps training stable and focused on cases that help the model improve.
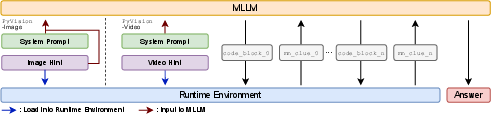
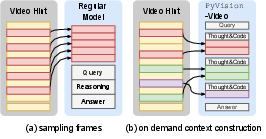
- On-demand context construction for video: Instead of feeding lots of frames from the whole video to the model, the video is loaded into a safe Python runtime first. The model then writes tiny pieces of code to fetch only the frames it needs, like “look at the last half” or “sample key moments.” It’s like skimming just the relevant pages of a book instead of reading every page.
- Base algorithm choice: They use GRPO (a practical RL method for LLMs) but remove a specific “normalization” step to make training smoother and more stable.
- Two training phases:
- SFT (Supervised Fine-Tuning): The model first practices with examples that show good multi-step tool use.
- RL (Reinforcement Learning): The model then continues learning by trying tasks and earning rewards, using the strategies above to keep tool use strong and stable.
What did they find, and why is it important?
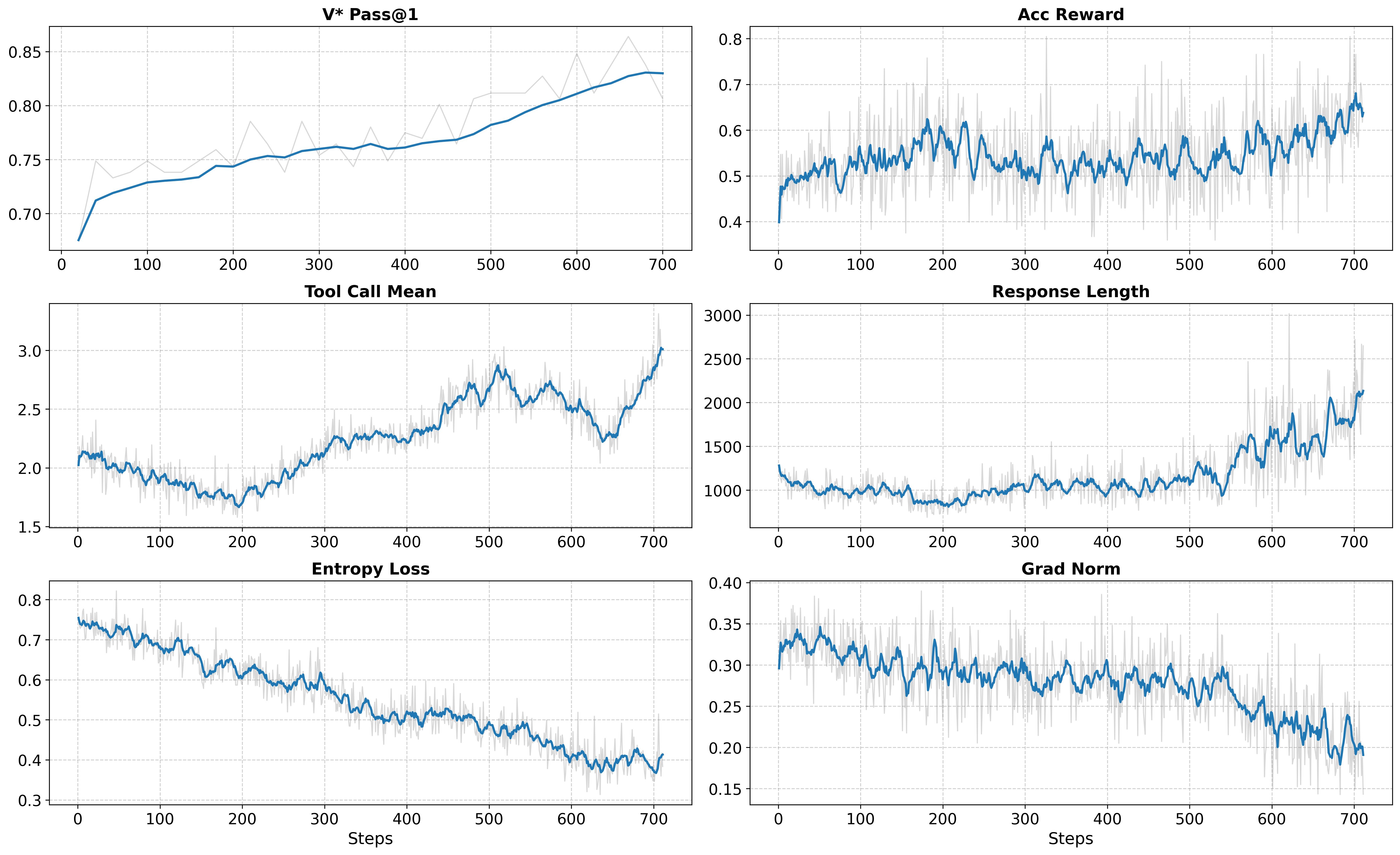
- Better image tasks: -Image achieves strong results across visual search and multimodal math reasoning. It consistently beats the base model (Qwen2.5-VL-7B) and other systems, showing that guided tool use improves careful visual analysis and calculation.
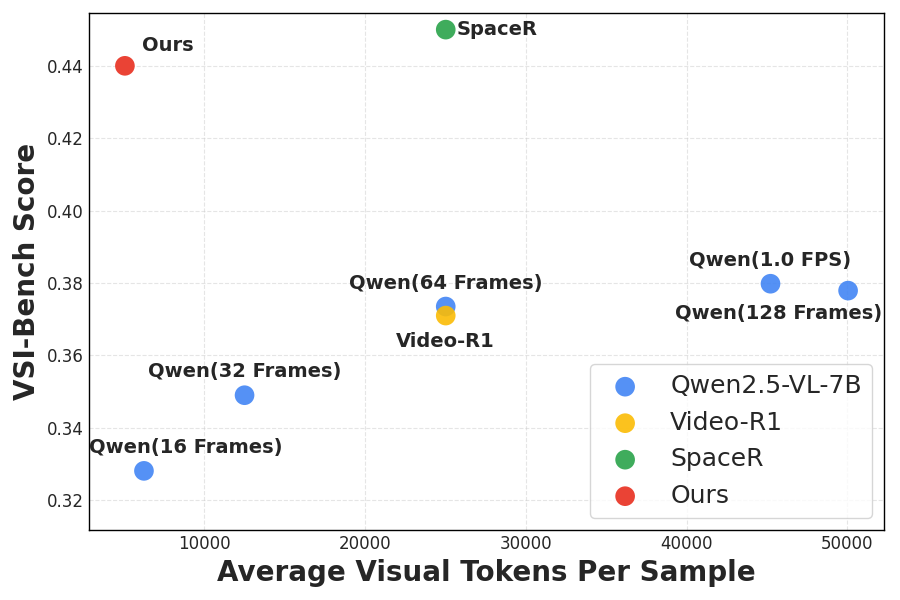
- Better video tasks with fewer tokens: -Video reaches about 44.0% accuracy on a spatial reasoning benchmark while using around 5,000 visual tokens per sample. A popular baseline (Qwen2.5-VL-7B) gets about 38.0% accuracy using roughly 45,000 tokens. In simpler terms, -Video is both more accurate and much more efficient because it only looks at the frames that matter.
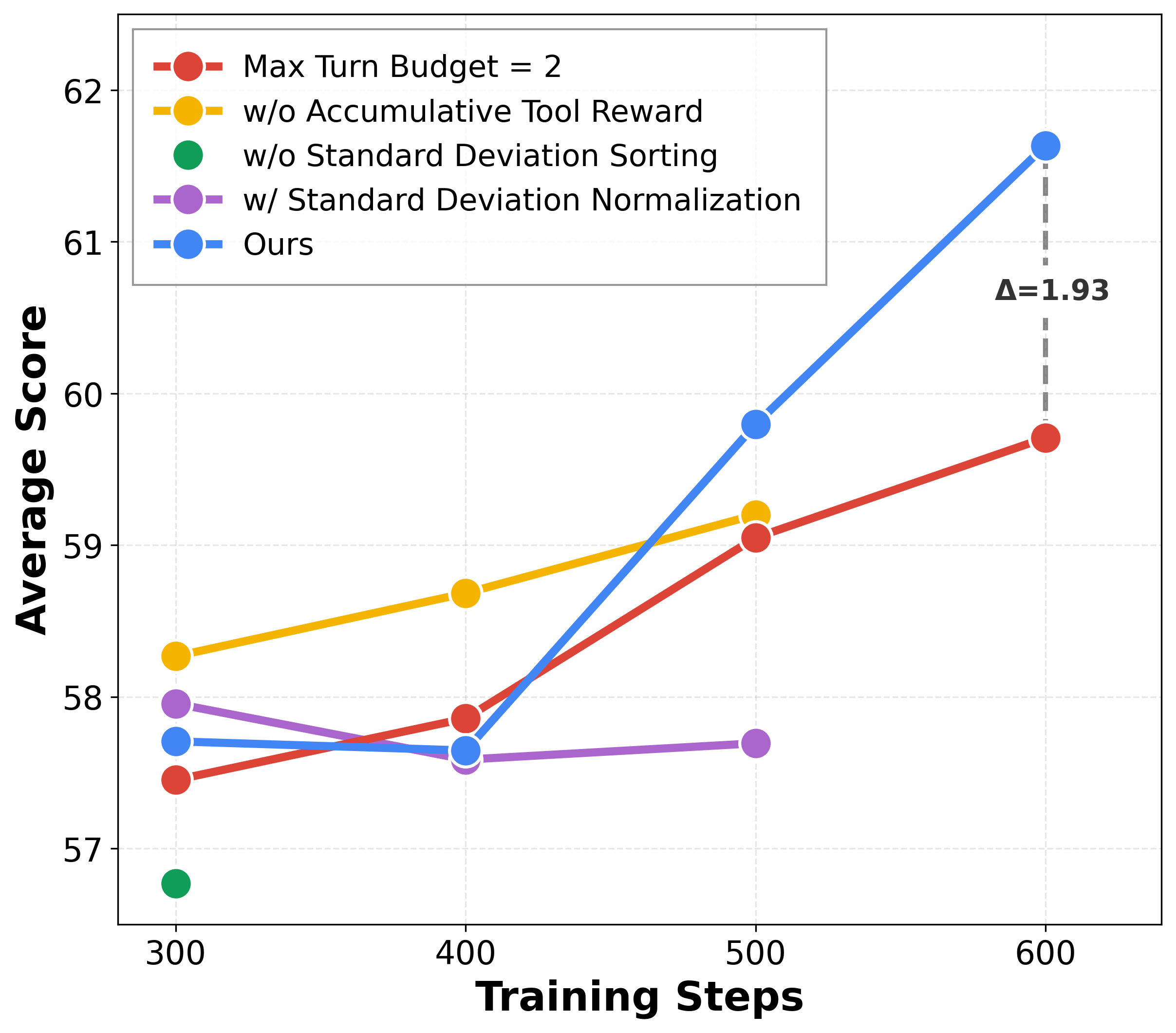
- Stable training and sustained interaction: The model keeps using tools more over time, writes longer, more thoughtful responses, and stays stable during training. This suggests the accumulative tool reward and the rollout ranking/filtering make a real difference.
Why it matters:
- Many real problems in images and videos need step-by-step actions, not just a one-shot guess.
- Being able to pick only relevant video frames cuts cost and speeds up reasoning.
- The approach works with open models, which helps the research community and developers build practical, transparent systems.
What does this mean for the future?
- Smarter multimodal agents: Models that reason in steps and use tools can tackle more complex tasks (like detailed visual search, charts, medical images, or spatial puzzles in videos) without needing huge compute.
- Better efficiency: On-demand video frame selection can make video AI faster and cheaper, which is useful for long security footage, sports analysis, or classroom videos.
- Safer deployment needed: Because the model runs Python tools, it should be sandboxed (isolated) so it can’t accidentally access or damage files. The authors note this is important when deploying these systems.
Overall, -RL shows that with the right training rewards and careful selection of learning examples, vision-LLMs can stay engaged, use tools wisely, and perform better—especially on tasks that need multiple steps and targeted visual focus.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Generality across backbones and scales: Results are limited to Qwen2.5-VL-7B; it is unclear whether -RL’s gains hold for larger models (e.g., 70B, MoE), different architectures (e.g., LLaVA, InternVL, Gemini-like MLLMs), or instruction-only LLMs with vision adapters.
- Sparse video evaluation: -Video is assessed only on VSI-Bench (spatial reasoning). Performance and efficiency on long-form video QA, temporal causality, action recognition, dense event tracking, and narrative understanding remain untested.
- Frame-selection robustness: The on-demand frame fetching policy is purely agent-driven via Python code with no guarantees of coverage; there is no analysis of failure modes when critical events are missed, nor mechanisms (e.g., fallback heuristics or coverage constraints) to avoid selection bias.
- Latency and systems overhead: Token efficiency is reported, but end-to-end wall-clock latency, interpreter overhead, I/O costs for loading long videos, and throughput under realistic deployment conditions are not measured.
- Reward shaping sensitivity: The accumulative tool reward uses a fixed linear coefficient (0.1 * n_tc) applied only when the final answer is correct; there is no study of coefficient sensitivity, per-tool weighting (quality vs quantity), diminishing returns, penalizing gratuitous/inconsequential tool calls, or step-wise/partial-credit rewards.
- Exploration vs correctness trade-off: By adding tool-use rewards only when the answer is correct, episodes with productive exploration but incorrect final answers receive zero reward; the impact on learning in difficult tasks and whether intermediate verifiers or partial-credit signals could help remains open.
- Ambiguity in reward equation: The RL objective’s LaTeX is malformed, obscuring exact implementation details. A clear, code-level specification of (including masking, edge cases, and normalization) is needed for reproducibility.
- Rollout filtering criteria: The paper filters “broken” interactions (timeouts, non-executable code, invalid visuals) but does not specify detection thresholds, retry strategies, auto-repair, or exception handling at inference time. A robust error-recovery protocol is missing.
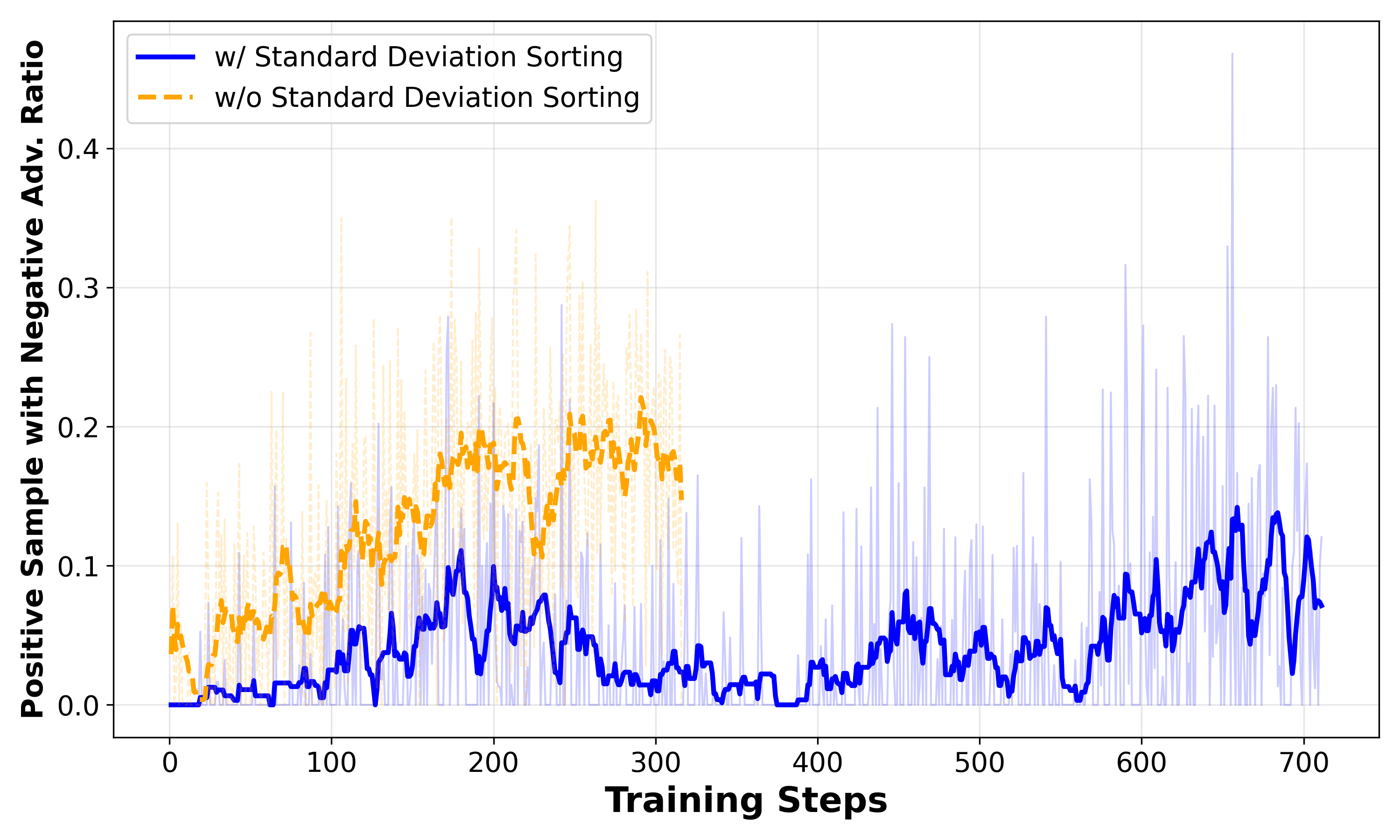
- Standard deviation sorting side effects: Ranking groups by reward variance may bias training toward particular sample types and reduce diversity. The effects on curriculum balance, domain coverage, and long-term generalization are not analyzed.
- GRPO variant generality: The method removes standard deviation normalization in GRPO; there is no comparison to alternative critic-free algorithms (e.g., GRPO variants, PPO adaptations, policy-gradient baselines) or to learned advantage estimators in this agentic multimodal setting.
- Turn budget mismatch and control: Training uses max-turn budget 4, evaluation 30; the effect of this mismatch on behavior, efficiency, and stability is not systematically analyzed, nor are policies for adaptive stopping, loop prevention, or budget-aware planning.
- Safety and sandboxing: The Python interpreter can access the host filesystem; beyond a brief note in the impact statement, there is no concrete sandbox design, syscall restrictions, network isolation, package governance, or code vetting to mitigate harmful or exfiltrative actions.
- Prompt-injection and adversarial robustness: The agent executes code derived from model outputs; resilience to prompt injection (in text, image, or video), adversarial visuals, malicious file names/metadata, and interpreter-level exploits is not evaluated.
- Data contamination and deduplication: SFT and RL datasets are aggregated from multiple sources (including GPT-4.1 synthesis). There is no audit for overlap, near-duplicate leakage, or test set contamination (e.g., WeMath, V*, MathVerse, SpaceR).
- Domain transfer: SFT data includes medical and chart tasks, but these domains are not evaluated; the paper does not quantify cross-domain transfer of tool-using behavior or identify domain-specific failure modes.
- Tool quality metrics: Rewarding the count of tool calls ignores the utility/quality of tool outputs (e.g., crop relevance, frame salience, visualization clarity). There is no metric or reward for effective tool outcomes versus mere invocation.
- Interpreter toolset scope: The paper does not specify allowed Python libraries, version pinning, GPU access, or restrictions (e.g., OpenCV, FFmpeg). The impact of toolset breadth on capability, security, and reproducibility is unaddressed.
- Efficiency beyond visual tokens: Visual token reductions are reported, but total token footprint (including language tokens), memory usage, VRAM/host RAM, and energy per sample are not quantified; the true cost-performance profile remains unknown.
- Benchmark variance and statistical rigor: Small benchmarks (e.g., V* avg@32) and single-seed reporting lack confidence intervals, statistical tests, or robustness across seeds. Sensitivity to decoding settings (temperatures/top-k) is not systematically studied.
- Qualitative error analysis: The paper lacks a taxonomy of failure cases (e.g., tool misuse, mis-localization, temporal confusion, code exceptions) and targeted diagnostics to guide future improvements.
- Integration with static toolsets: The paper compares against static tools but does not explore hybrid designs (dynamic Python plus curated high-performance visual ops) or quantify when static tools outperform model-synthesized code.
- Long-video scalability: Loading full videos into the runtime may be impractical for hours-long content; strategies for streaming, chunked processing, memory mapping, and indexing are not discussed.
- Security of video ingest: No evaluation of malformed/corrupted video inputs, container exploits, or defense-in-depth for media parsing pipelines.
- MoE and distributed training stability: While related work notes RL challenges for MoE, -RL’s stability on MoE backbones, multi-node training, and large-batch regimes is unexplored.
- Open-ended answer verification: The “accuracy reward” presumes reliable automatic checking; for open-ended multimodal responses, the paper does not specify verifiers, matching criteria, or handling of partially correct/ambiguous answers.
- Release readiness: Although code/models are announced, the paper does not document reproducible pipelines (data generation scripts, filters, sandbox configs, evaluator implementations), hindering exact replication.
Practical Applications
Overview
Based on the paper’s findings and innovations—dynamic Python tooling for multimodal agents, an RL recipe that prevents interaction collapse (oversampling–filtering–ranking with “Standard Deviation Sorting”), an accumulative tool reward, and on-demand context construction for video—below are actionable, real-world applications. Each item indicates sector(s), potential products/workflows, and key assumptions/dependencies, grouped by deployment horizon.
Immediate Applications
- Visual search and inspection assistants for high-resolution imagery (Manufacturing, E-commerce, Logistics)
- Use the -Image agent to dynamically crop/zoom, annotate, and verify defects, labels, or parts in product/packaging photos and warehouse imagery.
- Tools/products/workflows: “Agentic Visual QA” microservice; quality-control dashboard with code-interpreter-backed image probes; API that returns ROI-crops plus explanations.
- Assumptions/dependencies: Sandboxed Python (PIL/OpenCV) and GPU inference; image I/O/security hardening; clearly defined acceptance criteria for accuracy.
- Cost-efficient video analytics with on-demand frame selection (Security, Retail, Smart cities, Sports analytics)
- Replace uniform frame sampling with -Video’s selective frame fetching to answer spatial queries (counts, directions, region sizes) at a fraction of visual tokens.
- Tools/products/workflows: “Frame Selector” service for existing VLMs; NVR/VSaaS plugin that supplies only task-relevant frames to LLM context; billing model tied to token savings.
- Assumptions/dependencies: Reliable video I/O (ffmpeg/OpenCV), tight latency/timeout controls, workload profiling to quantify token and cost reduction.
- Business chart and infographic understanding (Finance, BI/Analytics, Enterprise Ops)
- Use dynamic Python tooling to parse/measure chart elements and verify claims in dashboards, reports, and investor materials.
- Tools/products/workflows: “Chart QA Agent” that outputs measurements, cross-checks, and annotated overlays; integration into BI platforms as a validation step.
- Assumptions/dependencies: Chart/image access; library support (matplotlib, numpy); provenance logging to support audits.
- Customer support triage via screenshot reasoning (Software, IT Ops)
- Interactively focus on UI regions (menus, error dialogs) to diagnose issues from screenshots and produce step-by-step guidance.
- Tools/products/workflows: Helpdesk plugin that requests targeted crops and runs simple code checks; knowledge-base linking for remediations.
- Assumptions/dependencies: Secure screenshot handling; redaction for PII; interpreter sandboxing.
- Research and development platform for agentic multimodal RL (Academia, ML/AI teams)
- Adopt the open pipeline (GRPO variant without std-dev normalization + accumulative tool reward + rollout oversampling/filtering/ranking) to train stable, tool-using MLLMs.
- Tools/products/workflows: “PyVision-RL” trainer; evaluation harness for token-efficiency vs. accuracy; curriculum via Standard Deviation Sorting to stabilize learning.
- Assumptions/dependencies: Compute availability (multi-GPU), curated SFT/RL datasets, safe interpreter execution in training loops.
- Document and ID verification workflows with visual evidence (Finance, Government services, Trust & Safety)
- Dynamic cropping and feature measurement to validate seals, MRZ zones, dates, or tamper signs on IDs and forms.
- Tools/products/workflows: “Vision Checker” API that returns localized evidence and verdict; queue-based human-in-the-loop review.
- Assumptions/dependencies: High-quality scans; explicit acceptance thresholds; strong audit logging; bias/false-positive monitoring.
- Drone/robot photo review for asset monitoring (Energy, Infrastructure)
- Prioritize and zoom into suspected anomaly regions from drone images of turbines, PV panels, pipelines, or bridges.
- Tools/products/workflows: “Agent-in-the-loop” inspector; event-driven workflow that triggers measurements when anomalies exceed thresholds.
- Assumptions/dependencies: Connectivity to image feeds; interpreter access to CV libraries; safety workflows for uncertain cases.
- Education assistants for diagram-heavy problem solving (Education)
- Use -Image to inspect and annotate geometry figures, plots, and lab diagrams with multi-turn reasoning and evidence.
- Tools/products/workflows: Classroom tooling that returns both answer and annotated figure; practice set generator using the same agentic scaffold.
- Assumptions/dependencies: Age-appropriate guardrails; content provenance; mitigation of over-reliance on solutions.
- Model-cost optimization for video LLM stacks (Software/Platforms)
- Integrate on-demand context construction as a drop-in “token budget optimizer” for existing video understanding pipelines.
- Tools/products/workflows: Middleware that decides which frames to materialize; per-query token cap with utility-aware frame selection.
- Assumptions/dependencies: API-level hooks in existing VLM services; monitoring to avoid missing critical frames.
- Reproducible agentic evaluation for sustained interaction (Academia, Benchmarks)
- Use the paper’s metrics (tool calls, response length, token use) to design evaluations that reward long-horizon, evidence-grounded reasoning.
- Tools/products/workflows: Benchmark harness capturing code blocks, execution artifacts, and final answers for replayability.
- Assumptions/dependencies: Standardized logging format; deterministic runtime seeds; accessible datasets.
Long-Term Applications
- Safety-critical medical imaging and video review (Healthcare)
- Agent plans targeted zooms/crops on radiology or pathology slides; for endoscopy/ultrasound videos, selective frame evidence to support findings.
- Tools/products/workflows: “Clinician Co-Pilot” that proposes regions-of-interest plus quantified measures; audit-ready logs of tool use.
- Assumptions/dependencies: Regulatory approval (FDA/CE), rigorous validation on clinical datasets, domain-tuned safety layers, PHI protection.
- On-device, privacy-preserving video reasoning (Consumer devices, Smart home, Automotive)
- Run agentic frame selection locally to answer queries while minimizing data transmission/storage.
- Tools/products/workflows: Quantized/edge variants; privacy modes that discard non-relevant frames; DP or secure enclaves for sensitive contexts.
- Assumptions/dependencies: Hardware acceleration; optimized interpreters; thermal and power constraints; strong privacy guarantees.
- Autonomous robots with compositional visual tool use (Robotics, Warehousing, Agriculture)
- Combine dynamic Python tooling with perception stacks to plan sensing actions (where to look next) and manipulate visual inputs for task execution.
- Tools/products/workflows: “Perception Controller” that requests targeted captures; closed-loop integration with mapping and manipulation modules.
- Assumptions/dependencies: Real-time constraints; safe tool invocation; robust error recovery; sim-to-real transfer.
- Regulatory/compliance frameworks for code-executing agents (Policy, Risk, Governance)
- Standardize sandboxing, capability scoping, audit trails, and incident response for agents that execute code against user-provided media.
- Tools/products/workflows: Certification checklists; red-teaming protocols; secure-by-default agent runtimes with granular policies.
- Assumptions/dependencies: Cross-industry consensus; alignment with data protection laws; third-party auditing ecosystem.
- Multi-agent vision systems coordinating selective evidence gathering (Security, Inspection networks)
- Swarms of agents that divide scenes/videos and share intermediate visual evidence to reduce total token budgets while improving coverage.
- Tools/products/workflows: “Coordinator” service for task allocation; shared evidence cache; consistency checks across agents.
- Assumptions/dependencies: Low-latency comms; conflict resolution strategies; global cost/utility optimization.
- Standardized curricula and difficulty-aware sampling for RLHF/RLAIF at scale (ML platforms)
- Generalize Standard Deviation Sorting to multi-domain agent training to prevent collapse and improve sample efficiency.
- Tools/products/workflows: Curriculum scheduler that prioritizes groups with informative reward variance; automated rollout sanitization.
- Assumptions/dependencies: Reliable reward instrumentation; scalable rollout orchestration; robust failure handling.
- Legal and financial document forensics with visual substantiation (LegalTech, Audit)
- Agents that pinpoint alterations, hidden content, or inconsistent figures across scanned documents, charts, and exhibits.
- Tools/products/workflows: “Forensic Lens” producing overlays and measurement logs suitable for court or regulatory review.
- Assumptions/dependencies: Chain-of-custody, evidentiary standards, human expert oversight.
- Creative media assistants for video editing and highlights (Media/Entertainment)
- Agentic selection of key frames/shots for highlight reels, continuity checks, or compliance (logo/rights) scanning.
- Tools/products/workflows: Editor co-pilot that proposes cuts and provides rationales; batch QC with selectable evidence frames.
- Assumptions/dependencies: Integration with NLEs; IP/compliance datasets; domain-tuned prompts.
- Sector-specific agentic tool ecosystems (Modular CV via Python)
- Prebuilt tool libraries (segmentation, detection, OCR, depth) invoked on-demand by the agent for domain tasks (e.g., construction, mining).
- Tools/products/workflows: “Vision Tool Market” with vetted Python operators and standardized outputs; policy-enforced loader.
- Assumptions/dependencies: Versioning and supply-chain security for Python packages; operator performance SLAs.
- Educational platforms emphasizing evidence-grounded reasoning (Education policy, EdTech)
- Curricula and assessments that require students to request/select visual evidence (frames/crops), mirroring the agent’s scaffold.
- Tools/products/workflows: Teacher dashboards showing students’ “evidence chain”; adaptive tasks tuned by difficulty variance.
- Assumptions/dependencies: Fairness and accessibility; prevention of over-reliance; clear pedagogical outcomes.
Notes on feasibility and risks across applications:
- The approach depends on secure, resource-governed code execution; deployments should enforce strict sandboxes (no filesystem/network by default, rate-limits, package allowlists) with full audit logging.
- Accuracy and robustness hinge on dataset coverage, reward design, and runtime reliability (code timeouts, image/video rendering errors). The paper’s rollout filtering and ranking mitigate but do not eliminate failures; safety-critical use requires additional guardrails and validation.
- Token and cost savings from on-demand video context are scenario-dependent; tasks requiring dense temporal detail may reduce the efficiency gains.
- Open-weight model quality and license terms, GPU availability, and compatibility with common CV libraries are practical dependencies for standing up these systems.
Glossary
- accuracy–efficiency trade-off: A balance between getting higher task accuracy and using fewer computational resources (e.g., tokens). "achieving a favorable accuracyâefficiency trade-off on VSI-Bench."
- accumulative tool reward: An RL reward component that increases with the number of tool calls (only when the answer is correct) to encourage sustained tool use. "we introduce an RL objective with an accumulative tool reward."
- advantage estimation: The process of estimating how much better an action is compared to a baseline in RL. "Several works propose improved advantage estimation schemes"
- agent–environment interaction: The iterative loop where an agent takes actions in, and receives feedback from, its execution environment. "A second challenge arises from the inherent uncertainty of agentâenvironment interaction."
- agentic frame fetching: Selecting and extracting only task-relevant frames from a video during reasoning, rather than processing all frames uniformly. "This agentic frame fetching strategy avoids uniform frame sampling"
- agentic reasoning: Multi-turn, tool-using reasoning behavior characteristic of agents rather than static predictors. "on agentic reasoning tasks requiring multi-turn tool usage"
- agentic scaffold: The structured prompting and execution setup that enables an LLM/MLLM to interleave reasoning with tool calls. "We design two agentic scaffolds for image and video understanding"
- critic-free RL algorithms: RL methods that optimize policies without learning a separate value function (critic). "Most of these approaches adopt critic-free RL algorithms."
- curriculum learning: A training strategy that orders samples by difficulty to improve learning efficiency. "First, from a curriculum learning perspective, group-level standard deviation serves as a proxy for sample difficulty."
- dynamic tooling: A paradigm where the model writes code to synthesize task-specific tools on the fly (often via Python), rather than relying on a fixed toolset. "dynamic tooling treats Python as a primitive tool"
- entropy loss: A regularization term encouraging exploration by penalizing overly confident policies. "Entropy loss and gradient norm decrease smoothly over training"
- GRPO: Group Relative Policy Optimization, an RL algorithm that normalizes rewards within rollout groups to stabilize updates. "We adopt GRPO~\cite{shao2024deepseekmath} as the base algorithm for RL training."
- group-level normalization: Normalizing rewards or advantages within a group of rollouts for the same prompt, which can affect gradient signals. "group-level normalization may assign negative advantages"
- group-level reward standard deviation: The variability of rewards within a rollout group, used here as a proxy for sample difficulty. "rank rollout groups by group-level reward standard deviation"
- interaction collapse: A training pathology where the model stops using tools or engaging in multi-turn reasoning. "often suffers from interaction collapse, where models learn to reduce tool usage and multi-turn reasoning"
- intra-group advantage: The per-rollout advantage computed relative to other rollouts in the same group for a given prompt. "remove the standard deviation normalization term in the intra-group advantage computation"
- long-horizon reasoning: Reasoning that spans many steps or tool calls, requiring sustained interaction. "Given the long-horizon reasoning capabilities induced by RL tuning"
- maximum turn budget: A cap on the number of reasoning-tool interaction turns allowed during an episode. "we set the maximum turn budget to 30"
- mixture-of-experts (MoE) models: Architectures that route inputs through subsets of specialized expert networks to improve capacity and efficiency. "stabilizing RL training for large mixture-of-experts (MoE) models"
- mode collapse: Convergence to a narrow set of behaviors (e.g., few or no tool calls) that reduces diversity and effectiveness. "often leading to a form of mode collapse"
- MLLM: Multimodal LLM; an LLM that processes and reasons over text plus visual inputs. "the MLLM is prompted to interleave natural language reasoning with executable code"
- on-demand context construction: Building the model’s visual context dynamically by fetching only relevant frames/images during reasoning. "we adopt on-demand context construction"
- on-demand visual processing: Selectively processing visual inputs as needed during reasoning instead of preloading them all. "sustained interaction and on-demand visual processing are critical for scalable multimodal agents."
- open-weight: Models whose parameters are publicly available for fine-tuning or analysis (as opposed to closed/proprietary weights). "a reinforcement learning framework for open-weight multimodal models"
- oversampling–filtering–ranking rollout strategy: A generation and selection pipeline that oversamples rollouts, filters unstable ones, and ranks groups to stabilize RL. "an oversamplingâfilteringâranking rollout strategy"
- policy model: The model that maps states (and context) to action distributions in RL. "Let denote the policy model"
- PPO-style clipping mechanism: A Proximal Policy Optimization technique that clips policy updates to stabilize training. "Others modify the PPO-style clipping mechanism to better accommodate LLM training"
- reward shaping: Modifying the reward function to guide learning, which can introduce optimization side effects if misapplied. "reward shaping can introduce subtle optimization issues."
- rollout: A full sampled trajectory consisting of the model’s actions (e.g., tool calls, text) and resulting observations until termination. "When extending vanilla GRPO from pure textual reasoning to agentic RL, rollout quality and distribution become a dominant factor"
- SFT: Supervised Fine-Tuning; initializing a model with labeled examples before RL. "We first obtain SFT models as a cold start"
- Standard Deviation Sorting: A rollout-group selection heuristic that prioritizes groups with higher reward variance. "We refer to this strategy as Standard Deviation Sorting."
- standard deviation normalization: Dividing by the group reward standard deviation in advantage computation; here it is removed for stability. "we remove the standard deviation normalization term in the intra-group advantage computation"
- test-time interaction scaling: Increasing the number or depth of interactions (e.g., tool calls or CoT steps) at inference to boost performance. "skepticism about the effectiveness of test-time interaction scaling for agentic visual understanding"
- tool invocation: The act of calling an external tool (e.g., Python code) as part of the model’s reasoning process. "tool-integrated multimodal reasoning explicitly incorporates tool invocation"
- uniform frame sampling: Selecting video frames at a constant rate regardless of content relevance. "prior work typically relies on uniform frame sampling to construct the visual input"
- video clipping tools: Predefined tools that extract temporal segments from videos to focus analysis. "predefined video clipping tools are used"
- visual token: A token representing visual content (e.g., an image patch or frame) in multimodal model contexts. "significantly reduce visual token usage"
Collections
Sign up for free to add this paper to one or more collections.