- The paper introduces an RL-driven framework that modularly aligns vision-language models by decoupling algorithm logic, architecture, and system execution.
- It achieves substantial performance gains on benchmarks like MAT-Search and MAT-Coding through off-policy policy gradient methods and flexible regularization techniques.
- The framework enables full-parameter RL training on consumer-grade GPUs, making multimodal model research more accessible and resource-efficient.
RLLaVA: An RL-Centric Modular Framework for Multimodal Model Alignment
RLLaVA introduces a reinforcement learning (RL)-driven framework tailored to the efficient development, alignment, and deployment of vision-LLMs (VLMs). The motivation stems from the unique challenges of applying RL to multimodal scenarios: handling joint sequential decision processes over text and vision, the need for scalable yet resource-efficient infrastructure, and the lack of extensible frameworks that decouple RL algorithm logic from model implementation and distributed execution. RLLaVA addresses these barriers by formulating the multimodal decision process as a unified MDP, where the state space encompasses visual and textual modalities, the action space is textual, and the reward function can flexibly reflect diverse multimodal objectives.
The policy πθ in RLLaVA is parameterized by a VLM comprising an LLM, vision encoder, and connector modules. RL-based fine-tuning is formulated via off-policy policy gradient objectives with pluggable regularization, supporting variants such as PPO, GRPO, RLOO, OPO, and GSPO. The framework natively accommodates regularization strategies including KL-to-reference, entropy-based bonuses, token-length normalization, and n-gram penalties.
Architecture and Design Principles
The core architectural contribution is a modular, role-based design that decouples three axes: RL algorithm logic, VLM model architecture, and system-level distributed execution. This enables seamless interchangeability and independent optimization of each, facilitating algorithmic research without entrenched system dependencies.
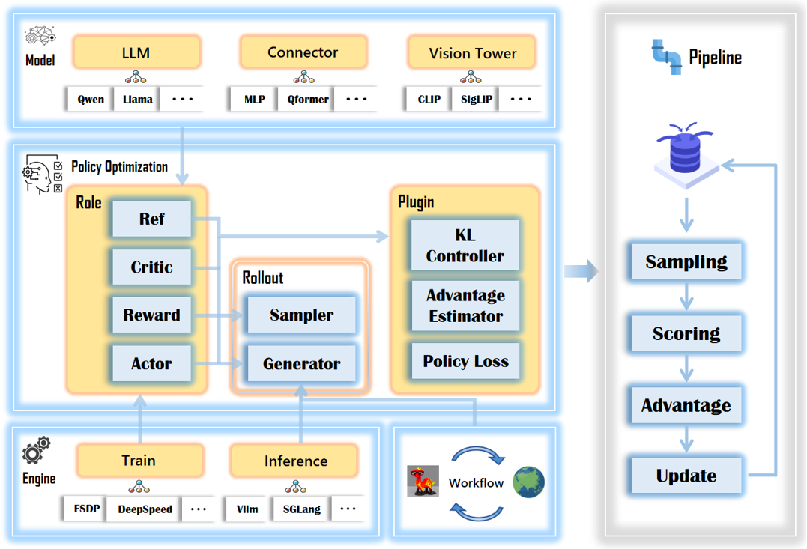
Figure 1: RLLaVA architecture decouples RL algorithmic logic, model architecture, and execution engines, supporting flexible composition and resource-efficient training.
Four primary roles—Actor, Critic, Reference, and Reward—encapsulate policy management, value estimation, inertia for KL regularization, and reward computation respectively. Multimodal components (vision encoders, LLMs, and connectors) are natively factory-registered, supporting a broad range of backbone architectures (e.g., CLIP, DINOv2, Qwen, Gemma). The system design separates training and inference engines, supporting FSDP/FSDP2, DeepSpeed for training, and vLLM/SGLang/HuggingFace for efficient rollout generation with explicit resource lifecycle management. This approach enables highly efficient memory utilization, supporting full-parameter end-to-end RL training of 4B models on a single 24GB GPU.
Pluggable RL Algorithm Implementation
RLLaVA’s plugin system enables rapid experimentation with a diverse suite of RL algorithms. Key advantage estimation methods (e.g., GAE, GRPO, RLOO, OPO) and policy loss functions (e.g., PPO, GSPO, vanilla policy gradient, CLIP-COV, KL-COV) can be composed, mixed, and swapped entirely via configuration—without code modification to the core training loop. This design is inspired by the extensibility paradigms of frameworks like veRL, yet is realized in a compact, researcher-focused, resource-constrained environment.
Algorithmic innovation is further facilitated by DataProto, a protocol for standardized communication between stages, supporting tensor and rich multimodal payloads. Rollouts are handled in a co-located, offloading-aware pipeline that multiplexes GPU memory between inference and optimization, further lowering the resource barrier for complex multi-modal RL research.
Experimental Evaluation
Comprehensive experiments verify RLLaVA’s effectiveness across a suite of established and new multimodal benchmarks—including mathematical reasoning (Geometry3K), visual perception (CLEVR-Count), referring expression grounding (RefCOCO/+/g, LISA), and complex agentic tasks (MAT-Search, MAT-Coding).
RL-based fine-tuning (primarily with GRPO) yields consistent and substantial gains over base models. The most dramatic improvements occur in multi-turn, agentic tasks: on MAT-Search, F1 improves from 4.4 to 27.1; on MAT-Coding, from 16.9 to 30.6. Perception-oriented tasks also show robust gains (e.g., +12 IoU on grounding). In all cases, RLLaVA-trained models match or surpass the performance of specialized frameworks such as Visual-ARFT, despite using more unified and modular training recipes.
Generalization and Extensibility
Out-of-domain evaluation on LISA highlights improved semantic generalization post-RL, with IoU improving by +11 points over the base model, indicating RL fine-tuning yields robust cross-distribution reasoning rather than mere in-domain adaptation.
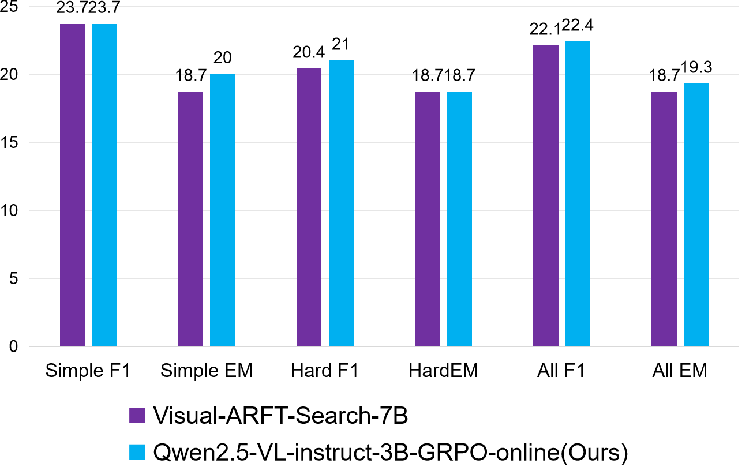
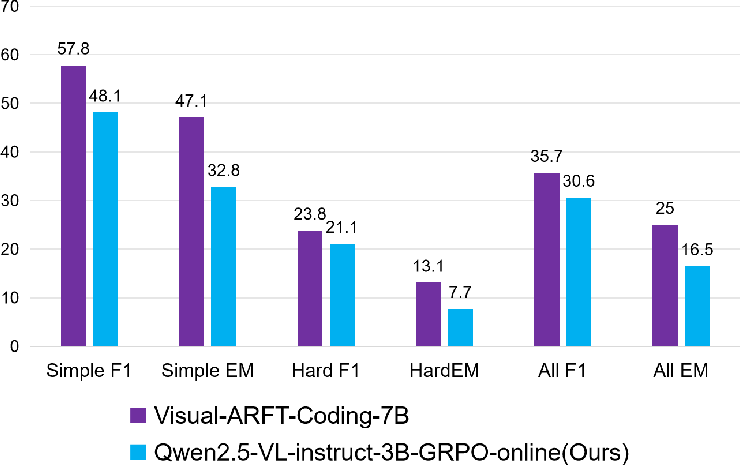
Figure 2: RLLaVA delivers strong performance boosts in multi-modal agentic search scenarios, approaching or exceeding prior state-of-the-art.
Resource Efficiency
Full-parameter RL training of models up to 4B parameters is feasible on consumer-grade hardware: peak GPU memory rarely exceeds 21–22 GB during rollout and optimization, owing to RLLaVA’s colocation and memory offloading strategies.
RLLaVA situates itself relative to existing scalable RL systems (veRL, OpenRLHF, AReaL, RLinf), which prioritize massive infrastructure over usability for small-scale research. Compared to prior works targeting multimodal RL (Visual-RFT, Visual-ARFT, DeepEyes), RLLaVA stands out for its systematic extensibility, unified pipeline, and researcher-centric efficiency.
Implications and Future Directions
Practically, RLLaVA lowers the computational and engineering barriers for research groups developing RL-aligned VLMs, supporting rapid iteration with diverse algorithmic variants in both text- and vision-grounded settings. Theoretically, the compositional abstraction over policy, reward, value, and reference enables principled study of RL algorithms’ specific effects in joint multimodal MDPs, informing best practices for scalable multimodal, agentic RL.
Future extensions, as suggested by the authors, include the integration of tool-use and embodied agent benchmarks, expanded vision/backbone architectures, and the development of more sophisticated reward modeling and credit assignment techniques (e.g., advanced critic-based algorithms, hierarchical credit assignment, or hybrid SFT+RL pipelines).
Conclusion
RLLaVA provides a highly modular, extensible, and resource-efficient framework for reinforcement learning research in multimodal and agentic language-vision models (2512.21450). Its clear separation of RL logic, multimodal model design, and system execution, combined with a comprehensive plugin system, enables both algorithmic innovation and practical deployment in standard computational environments. Experiments demonstrate consistent improvements across a wide spectrum of benchmarks, indicating RLLaVA’s viability for both research and advanced applications in multimodal RL.