DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference
Abstract: The performance of multi-turn, agentic LLM inference is increasingly dominated by KV-Cache storage I/O rather than computation. In prevalent disaggregated architectures, loading the massive KV-Cache from external storage creates a fundamental imbalance: storage NICs on prefill engines become bandwidth-saturated, while those on decoding engines remain idle. This asymmetry severely constrains overall system throughput. We present DualPath, an inference system that breaks this bottleneck by introducing dual-path KV-Cache loading. Beyond the traditional storage-to-prefill path, DualPath enables a novel storage-to-decode path, in which the KV-Cache is loaded into decoding engines and then efficiently transferred to prefill engines via RDMA over the compute network. DualPath combines this optimized data path -- which inherently avoids network congestion and avoids interference with latency-critical model execution communications -- with a global scheduler that dynamically balances load across prefill and decode engines. Our evaluation on three models with production agentic workloads demonstrates that DualPath improves offline inference throughput by up to 1.87$\times$ on our in-house inference system. It can also improve online serving throughput by an average factor of 1.96$\times$ without violating SLO.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about speeding up how big AI models (like chatbots) think and respond when they act like “agents” that do many steps in a row. In these long, multi-turn tasks, the main slowdown isn’t the model’s math but moving a lot of saved “memory” back and forth from storage. The authors build a system called DualPath that fixes this data-movement bottleneck so the model can run much faster.
The main questions the paper asks
- Why are agent-style AI tasks (many short turns with a long, growing history) slow on today’s servers?
- Where exactly is the bottleneck?
- Can we redesign the way we load the model’s saved memory (called KV-Cache) so we use all the available network and storage bandwidth, not just a small part of it?
- Can we do this without messing up other time-sensitive communications the model needs?
Key ideas and terms (explained simply)
Before the approach, here are the main pieces in everyday language:
- KV-Cache: Imagine the model takes notes as it reads your conversation. These notes help it answer future turns without rereading everything. That notebook is the KV-Cache. In agent tasks, you reuse almost all of the past notes each turn, so you have to reload a lot of them.
- Prefill vs. Decode: Prefill is the model “setting the stage” using the whole conversation so far. Decode is where it actually writes the next words. They use different parts of the computer and have different speed needs.
- Disaggregation (splitting the work): Servers often split work across two teams:
- Prefill Engines (PEs): focus on the heavy “read and set up” part.
- Decode Engines (DEs): focus on fast word-by-word generation.
- Two networks on the servers:
- Storage network: talks to disks (where the KV-Cache notes live).
- Compute network: connects GPUs to each other for fast communication.
- RDMA: A very fast, direct way to send data between computers (like a private express lane).
The problem today: only the Prefill Engines load most of the notes (KV-Cache) from storage. Their storage network pipes get jammed, while the Decode Engines’ storage pipes sit almost unused.
What DualPath does (the approach)
DualPath adds a second, smarter way to load the KV-Cache and schedules traffic so nothing gets stuck. Think of it like adding a second highway and a traffic cop that balances cars across both routes.
Here’s the core idea:
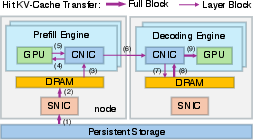
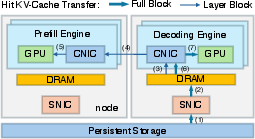
- Path 1 (the old way): Storage → Prefill Engine.
- Path 2 (the new way): Storage → Decode Engine → Prefill Engine over the fast compute network (RDMA).
By choosing between Path 1 and Path 2 for each request, the system uses all available storage bandwidth (not just on Prefill Engines) and avoids overloading one side.
To make this work in real systems, they add three pieces:
- A careful data path design: Moves KV-Cache in small chunks, timed to overlap with GPU work, and avoids creating new choke points.
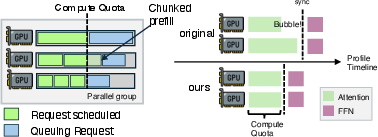
- Network “lane” control (traffic isolation): They send KV-Cache transfers over lower-priority lanes on the compute network, reserving the fast lanes for time-critical model communications. This stops slowdowns during decoding.
- A smart scheduler: It decides, in real time, which path (PE or DE) should load each request’s KV-Cache, and how to balance work across GPUs and network cards so no single part gets overloaded.
Analogy:
- Imagine a school with two copy rooms (storage connections). In the old setup, only one department (Prefill) used the copiers, causing lines. DualPath lets both departments (Prefill and Decode) make copies and then hand papers to each other over a fast hallway (compute network). A coordinator watches queues and sends people to the less busy copier. Fast lanes are kept clear for urgent deliveries.
How they tested it (methods, simply)
- They built DualPath on a modern AI serving system that already splits prefill and decode and does “layer-wise prefill” (like processing one chapter at a time to fit in memory).
- They ran real “agent” workloads: long conversations with many short turns, where most tokens are reused from KV-Cache (often 95%+ of the context).
- They measured:
- Offline throughput (how fast they finish a big batch of agent tasks, like in reinforcement learning rollouts).
- Online serving throughput and latency (like first-token time).
- They compared three setups:
- Basic (their original system).
- DualPath (their new system).
- Oracle (an idealized upper bound with no I/O overhead, just to see what’s theoretically possible).
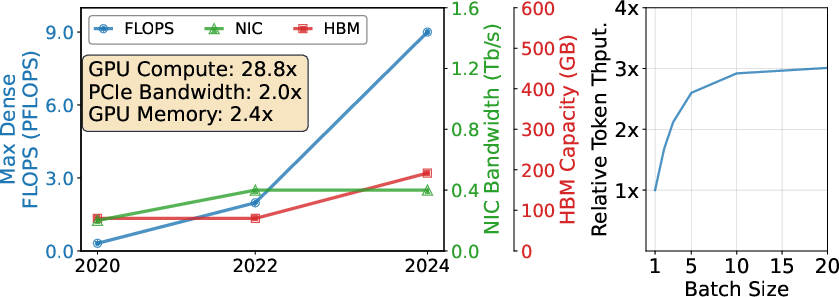
They also did a math check to show that, under common server setups, adding the second path won’t create new bottlenecks (for example, on GPU memory or the compute network), as long as you keep a sensible balance between how many Prefill and Decode machines you run.
What they found (results) and why it matters
- Faster throughput:
- Offline (batch) inference: up to 1.87× faster.
- Online serving: on average 1.96× more throughput without breaking latency promises (SLOs).
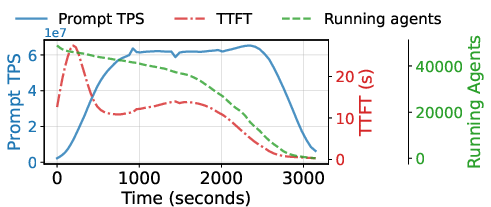
- Better first-token time: The system reduces the time to the first generated token, which is important for user experience in short responses.
- Balanced resource use: Storage bandwidth that used to sit idle on Decode machines now helps, so the whole cluster works more efficiently.
- Robustness: Their traffic isolation keeps latency-sensitive model communications smooth, even while moving lots of KV-Cache around.
Why this matters:
- Agent-style AI is becoming common (coding assistants, web agents, multi-step planners). These tasks are long and reuse lots of context. DualPath targets exactly the real bottleneck—loading reused context—so it delivers gains where users feel them.
- Hardware trends make this even more important: GPU compute keeps getting faster, but memory and network bandwidth don’t grow as quickly. That makes I/O the limiting factor unless you redesign data movement like DualPath does.
What this could change (implications)
- Cheaper, faster serving at scale: By squeezing more performance out of the same hardware, companies can handle more agent requests without buying lots of new gear.
- Better agent training (like RL rollouts): Faster rollouts mean quicker experiments and progress.
- A blueprint for future systems: The dual-path idea and lane-based traffic control could guide how other AI systems handle big, reusable data.
- Works with today’s data centers: The design matches how modern AI clusters separate storage and compute networks, and it uses standard QoS features (like virtual lanes) to keep everything smooth.
In short, DualPath turns a one-lane road into a two-lane highway for model memory, with a smart traffic cop. That keeps GPUs busy, responses faster, and servers more efficient—especially for long, multi-step agent tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
Architectural assumptions and generality
- Validate DualPath on hardware configurations without per-GPU CNICs or without PCIe co-location (e.g., single NIC per node, GPUs behind multiple PCIe switches), and characterize performance degradation and feasibility.
- Extend the bottleneck-free analysis beyond idealized assumptions (no compute-network congestion, perfect load balancing, storage fully utilized) to account for realistic contention and skew; provide sensitivity analyses to violations of these assumptions.
- Quantify how DualPath behaves when the compute network is consistently busy (e.g., heavy EP AllToAll patterns, larger TP/CP) rather than intermittently bursty, and determine thresholds where KV-Cache transfers begin to harm inference.
- Generalize DualPath to inference architectures beyond PD-disaggregation (e.g., monolithic engines, hybrid or pipelined designs) and quantify benefits or trade-offs.
Traffic management and QoS
- Provide empirical validation of the CNIC-centric H2D/D2H path’s QoS isolation under a range of collective patterns and utilization levels (including tail latency impacts), not just theoretical reasoning.
- Demonstrate deployment on RoCE and other fabrics (UEC, UnifiedBus), including concrete DSCP/TC configurations, switch/NIC queue mappings, and measured isolation vs. interference.
- Investigate dynamic QoS policies (e.g., adaptive VL/queue weights) that respond to real-time collective bursts rather than fixed 99/1 splits; evaluate latency, throughput, and fairness effects.
- Quantify the CPU cost and NIC-side overheads of doorbell batching and RDMA WR submission at scale (e.g., millions of small blocks per second), including effects on completion queues and interrupt moderation.
Scheduling and load balancing
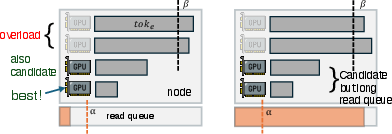
- Formalize and evaluate the choice of scheduler thresholds (α, β, the 1.05 multiplier for Z), including auto-tuning strategies and sensitivity analyses to workload and cluster conditions.
- Implement and evaluate the proposed split-read optimization (simultaneous PE and DE reads for a single request), including chunking granularity, per-layer splitting, and conflict resolution with per-node storage queues.
- Integrate additional load signals (HBM fragmentation, GPU memory headroom, per-model compute-per-token variability, per-expert activation skew in MoE) into inter-/intra-engine scheduling decisions, and quantify gains.
- Study stability and fairness under dynamic arrivals (online serving), including starvation risks for small-context requests when large-context batches dominate.
Storage and KV-Cache management
- Detail and evaluate Full Block vs. Layer Block layouts (block sizes, indexing, metadata overhead), and quantify their impact on random I/O, small-chunk transfer efficiency, and write amplification.
- Analyze end-to-end storage write costs (persisting generated KV-Cache every N tokens), including replication, durability, garbage collection, and consistency under failures or reordering.
- Compare SSD-based KV-Cache storage to alternative tiers (DRAM pools like Mooncake, NVMe-oF, object storage) with cost-performance modeling; identify when each tier is advantageous under agentic workloads.
- Explore KV-Cache compression/quantization trade-offs (e.g., FP8 vs. lower precision or compressed formats) on bandwidth, latency, and model quality; provide mechanisms for selective compression by layer or recency.
Performance evaluation scope
- Broaden model coverage (e.g., Llama-family dense models, encoder-decoder architectures, smaller latency-focused models) and quantify how architecture differences affect DualPath’s gains.
- Test extreme contexts (≫64K; up to 1M tokens as claimed) and lower KV-Cache hit rates (<95%), to map the operating envelope and failure modes when workloads deviate from agentic norms.
- Provide detailed online serving results (p50/p95/p99 TTFT/TTST, jitter), under varied concurrency and mixed request sizes, and show SLO compliance with tail latency under peak load.
- Include ablation studies for individual components (dual-path data flow, CNIC-centric transfers, scheduling) to attribute performance benefits and identify the most impactful levers.
Robustness, failure handling, and correctness
- Define and evaluate failure handling for partial reads/writes, DE/PE failures mid-transfer, storage timeouts, and network partitions; include retry, deduplication, and cache consistency semantics.
- Verify correctness and consistency of KV-Cache merging between hit/miss tokens across paths (PE-read vs. DE-read), especially under concurrent updates and layer-wise streaming.
- Assess the reliability characteristics of RDMA to GPU memory (QP scalability, retransmissions, flow control) at cluster scale, including recovery behaviors and their latency impacts.
- Evaluate NUMA effects and multi-socket DRAM bandwidth contention for PE/DE buffers, including placement policies and cross-socket penalties.
Portability and deployment constraints
- Quantify the minimal hardware requirements (per-GPU CNIC bandwidth, PCIe topology constraints, switch QoS capabilities) and provide a deployment guide for commodity clusters lacking DGX-like features.
- Study interactions with NVSwitch/NVLink fabric configurations (GH200, Blackwell) and determine if CNIC-centric paths remain optimal or if GPUDirect Storage variants can be QoS-isolated in future hardware.
- Evaluate coexistence with training jobs on the same fabric (multi-tenant clusters), including fabric-level fairness, QoS isolation between jobs, and impact on training collectives.
Privacy, security, and multi-tenancy
- Define security and isolation for RDMA to GPU memory (memory keys, protection domains), including multi-tenant risks and mitigations.
- Address KV-Cache persistence policies (encryption at rest, access control, data retention), especially for sensitive user contexts in production serving.
Cost, energy, and trade-offs
- Provide a cost-performance analysis comparing DualPath to simply provisioning more prefill-side storage bandwidth (e.g., additional SNICs) and to DRAM-based caching; include energy per token and operational complexity.
- Analyze the energy/network overhead of increased compute-network transfers vs. the throughput gains, and evaluate sustainability under large-scale deployment.
Explicitly stated future work
- Implement and evaluate concurrent reading of a single request from both PE and DE sides, including scheduling heuristics, block partitioning, and expected gains under different P/D ratios and queue lengths.
Glossary
- Agentic LLM: An LLM designed to autonomously plan, use tools, and interact over many turns with an environment. Example: "agentic LLM inference"
- AllGather: A collective communication primitive that gathers data from all participants and distributes the aggregated result to all of them. Example: "ReduceScatter/AllGather"
- AllToAll: A collective communication primitive where each participant sends data to and receives data from every other participant. Example: "AllToAll in expert parallel"
- Autoregressive decoding: Token-by-token generation where each new token is conditioned on previously generated tokens. Example: "autoregressive decoding"
- Cache-compute ratio: The ratio of KV-Cache data volume that must be loaded to the amount of computation, used to characterize I/O pressure. Example: "the cache-compute ratio"
- CNIC (Compute NIC): The network interface dedicated to the compute (east–west) fabric used for inter-GPU/node communication. Example: "compute NIC (CNIC, also known as east-west NIC)"
- CNIC-centric: A data/traffic management approach that routes GPU I/O through the GPU’s paired compute NIC to leverage network QoS for isolation. Example: "a CNIC-centric traffic management approach"
- Compute quota: A predefined upper bound on expected layer compute time used to cap batch assembly during prefill scheduling. Example: "compute quota"
- CUDA copy engine: A GPU hardware path for copying data between host and device memory via PCIe. Example: "CUDA copy engine"
- DE buffer: A DRAM buffer on decode engines used to stage KV-Cache before transfer to GPU memory. Example: "DE buffer"
- Decode engine (DE): A dedicated engine (GPU process) responsible for token generation in PD-disaggregated serving. Example: "decoding engines (DEs)"
- Differentiated Services Code Point (DSCP): An IP-layer field used to mark packets for QoS differentiation in Ethernet/roce networks. Example: "Differentiated Services Code Point (DSCP)"
- Doorbell batching: An RDMA optimization that amortizes submission overhead by batching work requests before ringing the NIC doorbell. Example: "doorbell batching"
- East-west NIC: A NIC used for inter-node compute traffic within the cluster (the compute fabric). Example: "east-west NIC"
- Expert parallel (EP): A parallelization strategy for MoE models where expert computations are sharded across devices and coordinated via collectives. Example: "expert parallel"
- Full Block: A KV-Cache block layout that contains all layers’ cache for a token block, used for storage interactions. Example: "Full Block"
- GPUDirect RDMA: A technology enabling NICs to directly read/write GPU memory, bypassing the host CPU. Example: "GPUDirect RDMA"
- GPUDirect Storage: A technology enabling storage devices to DMA directly to GPU memory without host copies. Example: "GPUDirect Storage"
- GQA: Grouped-Query Attention, an attention variant that reduces key/value redundancy by sharing K/V among grouped queries. Example: "GQA"
- H2D and D2H: Host-to-Device and Device-to-Host data transfers between CPU memory and GPU memory. Example: "H2D and D2H"
- HBM (High Bandwidth Memory): On-package memory with very high throughput used by GPUs. Example: "HBM capacity"
- I/O-compute ratio: The relative scaling between data movement capability (I/O) and computational throughput, used to reason about bottlenecks. Example: "I/O-compute ratio"
- I/O-bound: A workload characteristic where performance is limited by data movement rather than computation. Example: "I/O-bound"
- InfiniBand: A high-performance, low-latency network interconnect commonly used in AI clusters. Example: "InfiniBand-based network"
- Kernel bypass: An I/O technique that avoids kernel overhead by submitting operations directly from user space. Example: "kernel bypass"
- KV-Cache: Cached attention keys and values that allow reusing past computations across tokens/turns. Example: "KV-Cache"
- Layer Block: A KV-Cache block layout that contains cache for a single layer, used for layerwise streaming transfers. Example: "Layer Block"
- Layer-wise prefill: Executing prefill one layer at a time so only one layer’s KV-Cache lives in HBM, increasing effective batch size. Example: "layer-wise prefill"
- MMIO (Memory-Mapped I/O): A method of device communication via memory-mapped registers; in RDMA, used when submitting work requests. Example: "mmio writes"
- MoE (Mixture of Experts): A model architecture that routes tokens to specialized expert sub-networks for efficiency and capacity. Example: "an MoE model"
- NVLink: NVIDIA’s high-bandwidth interconnect linking GPUs within a node. Example: "NVLink"
- PD disaggregation: Architectural separation of prefill and decode phases onto different engine types for efficiency and scalability. Example: "PD disaggregation"
- P/D ratio: The ratio of prefill engines to decode engines in a deployment, affecting bandwidth and compute balance. Example: "P/D ratios"
- PCIe QoS: Quality-of-service mechanisms on PCI Express links (often unavailable on current GPUs), relevant to isolating traffic classes. Example: "PCIe QoS"
- QoS: Quality of Service; mechanisms to prioritize or reserve network bandwidth for specific traffic classes. Example: "QoS controls"
- RDMA: Remote Direct Memory Access, enabling direct memory operations across nodes with low latency and low CPU overhead. Example: "via RDMA over the compute network"
- RDMA over Converged Ethernet (RoCE): RDMA transport running over Ethernet, enabling RDMA semantics outside InfiniBand. Example: "RDMA over Converged Ethernet (RoCE)"
- RDMA Write: An RDMA verb that writes data directly into a remote memory region. Example: "RDMA Write"
- Read amplification: Extra storage reads incurred beyond what is strictly necessary due to system or data layout effects. Example: "read amplification"
- ReduceScatter: A collective that reduces data across participants and scatters disjoint reduced partitions back to them. Example: "ReduceScatter/AllGather"
- Reinforcement learning (RL): A training paradigm optimizing behavior via rewards; here used for agentic LLM training. Example: "reinforcement learning (RL) approaches"
- SLO: Service Level Objective; a target for service quality such as latency or throughput. Example: "SLO"
- SNIC (Storage NIC): The NIC connected to the storage fabric used for reading/writing datasets or KV-Cache. Example: "storage NIC (SNIC, also known as south-north NIC)"
- Sparse attention: An attention mechanism that prunes attention patterns to reduce compute/memory costs. Example: "sparse attention design"
- Tensor Core: Specialized GPU units (e.g., NVIDIA) for high-throughput tensor operations used in deep learning. Example: "Tensor Core"
- Tensor/context parallel: Parallelization strategies that shard tensor dimensions and/or context across devices, coordinated by collectives. Example: "tensor/context parallel"
- TTFT: Time to First Token; latency until the first generated token is produced. Example: "TTFT"
- TTST: Time to the Second Token; latency from start to the second output token, often reflecting steady-state decode. Example: "TTST (Time to the second token)"
- TPOT: Tokens Per Output Time (or similar throughput metric) used to evaluate serving performance. Example: "TPOT"
- Virtual lanes (VLs): Link-level traffic classes in InfiniBand that enable strict prioritization and isolation of flows. Example: "virtual lanes (VLs)"
- Weighted round-robin policy: A scheduling policy that assigns bandwidth shares to classes proportionally to weights. Example: "weighted round-robin policy"
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed now, leveraging DualPath’s findings to improve agentic LLM inference in real-world settings.
- Cloud LLM serving for agentic sessions
- Sector: software/cloud, SaaS
- What: Deploy DualPath’s dual-path KV-Cache loading and CNIC-centric traffic isolation in multi-turn, tool-using LLM services (e.g., coding copilots, autonomous task agents) to increase throughput (up to ~1.9×) and reduce time-to-first-token without violating SLOs.
- Tools/Products/Workflows: “DualPath-aware KV-Cache loader” within PD-disaggregated serving; scheduler tuned with token-count proxies and thresholds; InfiniBand/RoCE QoS configuration bundles; SSD-based KV storage (e.g., 3FS); layerwise prefill integration.
- Assumptions/Dependencies: Agentic workloads with ≥95% KV-Cache hit rate; PD-disaggregated architecture; RDMA-capable compute network (IB/RoCE) with QoS (VLs, DSCP/TC); GPUDirect RDMA and proper PCIe topology (GPU+CNIC under same switch); distributed storage that saturates SNICs; P/D ratios within derived bottleneck-free range.
- Accelerated RL rollouts for agent LLM training
- Sector: AI/ML, research & development
- What: Use DualPath during rollout phases to shorten job completion time and improve GPU utilization while relying on cost-effective SSD KV-Cache instead of DRAM pools.
- Tools/Products/Workflows: Rollout pipelines that schedule requests across prefill/decode engines using the inter- and intra-engine algorithms; token-count metrics to balance NIC/GPU load; per-group queues and leader engines; SSD-backed KV storage with kernel-bypass I/O (io_uring-like).
- Assumptions/Dependencies: Large trajectory working sets; limited DRAM due to optimizer/reward model states; consistent storage bandwidth; well-tuned scheduler thresholds (α, β); EP/DP configurations where attention is data-parallel.
- Enterprise on‑prem inference optimization
- Sector: enterprise IT, software
- What: Retrofit PD-disaggregated clusters with DualPath to pool storage bandwidth across prefill and decode engines, avoiding overloading prefill-side SNICs; produce an “agentic-optimized rack profile.”
- Tools/Products/Workflows: Playbooks to set P/D ratios within the provably bottleneck-free range; QoS config templates for IB/RoCE (VL/TC/DSCP); CNIC-assisted H2D/D2H path; block layouts (Full Block for storage, Layer Block for transfers).
- Assumptions/Dependencies: Physical separation of compute and storage networks; storage backend saturates SNIC; accurate per-node read queue metrics; low congestion on compute fabric; doorbell batching for RDMA submission.
- Multi-tenant traffic isolation for inference clusters
- Sector: data center operations, telecom
- What: Apply CNIC-centric transfer with QoS isolation (e.g., IB virtual lanes) to shield latency-sensitive model collectives (AllToAll, ReduceScatter/AllGather) from KV-Cache traffic.
- Tools/Products/Workflows: Network-wide VL arbitration (e.g., 99% bandwidth reserved for high-priority inference traffic); NIC and switch queue weights; RoCE TC/DSCP mapping equivalents; automation scripts to enforce QoS across tenants.
- Assumptions/Dependencies: Hardware QoS support in network stack; correctly mapped traffic classes; monitoring to prevent starvation of low-priority KV traffic.
- Cost and energy efficiency improvements
- Sector: finance (TCO), energy/sustainability
- What: Increase aggregate storage bandwidth utilization by using decode-side SNICs; reduce GPU idle time, energy per token, and overprovisioning of prefill-side NICs.
- Tools/Products/Workflows: TCO calculators that incorporate DualPath throughput gains; energy dashboards reporting watts/token and NIC utilization; capacity planning models that include pooled SNIC bandwidth.
- Assumptions/Dependencies: Measurable KV-Cache I/O bottleneck; sufficient decode-side SNIC headroom; accurate energy/utilization instrumentation.
- Framework integrations and libraries
- Sector: software/tools
- What: Integrate DualPath into serving stacks (e.g., vLLM, SGLang-like systems) as a pluggable KV-Cache loading/scheduling component that supports PD disaggregation and layerwise prefill.
- Tools/Products/Workflows: Open-source library for dual-path transfers (RDMA + QoS), schedulers with token-based balancing, storage adapters for SSD-backed KV-Cache (3FS-compatible), observability hooks.
- Assumptions/Dependencies: Alignment with framework parallelism (EP/DP/TP); consistent model block layouts; RDMA APIs and GPUDirect RDMA availability.
- Operations observability and scheduling governance
- Sector: DevOps/SRE
- What: Build dashboards and alarms around token-count proxies, per-node read queues, HBM headroom, and NIC utilization to steer the inter-/intra-engine schedulers and avoid imbalance.
- Tools/Products/Workflows: Metrics pipelines; leader-engine coordination; compute quotas for layerwise batches; policy to prefer nodes with shorter read queues and avoid overloaded engines.
- Assumptions/Dependencies: Accurate, low-latency telemetry; scheduler hooks; calibration/profiling for attention layer time vs. theoretical compute.
- End‑user responsiveness improvements in agentic assistants
- Sector: daily life, consumer-facing apps
- What: Users see faster first responses and steadier token streams during multi-turn tool use (web browsing, code execution) thanks to reduced KV-Cache I/O bottlenecks.
- Tools/Products/Workflows: Service tiers labeled “agentic-optimized”; A/B testing of TTFT/TTST improvements; backlog handling strategies for long-context sessions.
- Assumptions/Dependencies: Back-end deployment of DualPath; workloads dominated by KV reuse and short appends; SLO tracking for latency-sensitive paths.
Long-Term Applications
The following opportunities require further research, hardware support, or larger-scale development before broad deployment.
- Hardware–software co‑design for inference fabrics
- Sector: hardware vendors, cloud providers
- What: Incorporate PCIe QoS in GPUs/NICs and expose unified QoS controls across PCIe, RDMA, and storage stacks to natively isolate inference collectives from KV traffic; converge with Ultra Ethernet/UnifiedBus.
- Potential Products: “QoS-ready AI NICs” paired per-GPU; firmware/driver support for fine-grained lane arbitration; consolidated QoS APIs.
- Assumptions/Dependencies: Vendor support for PCIe QoS; standardization across IB/RoCE/UEC; firmware stability and cross-stack integration.
- Extending DualPath principles to training and fine‑tuning
- Sector: academia, AI/ML industry
- What: Apply dual-path pooling and CNIC-centric QoS to optimizer-state shuffling, activation offloading, and checkpoint I/O during large-scale training; reduce congestion across data and compute fabrics.
- Potential Workflows: Dual-path for activation paging; pooled SNIC utilization during gradient checkpointing; dynamic scheduling around bursty collectives.
- Assumptions/Dependencies: Training frameworks adapted for PD-like staged operations; compatibility with ZeRO/offload strategies; sufficient DRAM/SSD bandwidth.
- Zero‑copy and simultaneous dual‑side reads
- Sector: software/hardware co‑optimization
- What: Replace DRAM buffers with GPU Direct RDMA to DE HBM (where safe) and split KV reads across PE/DE concurrently to further cut TTFT and storage latency.
- Potential Tools: Smart block-splitting algorithms; NIC–GPU coalescing for small chunks; adaptive policies to minimize copy overheads.
- Assumptions/Dependencies: Robust RDMA-to-GPU memory semantics; careful QoS isolation; correctness in layerwise streaming with partial blocks.
- Agentic workload benchmarks and QoS profiles standardization
- Sector: policy/standards bodies, industry consortia
- What: Define benchmarks for multi-turn, short-append workloads and recommended QoS profiles (bandwidth reservations, arbitration weights) for inference clusters.
- Potential Products: Certification suites for “agentic-ready” clusters; reference P/D ratio calculators based on the bottleneck-free bounds; standard telemetry schemas.
- Assumptions/Dependencies: Community consensus; reproducible traces; vendor cooperation on QoS exposure.
- SSD KV‑Cache compression, deduplication, and indexing
- Sector: storage systems
- What: Reduce I/O volume with KV-Cache-aware compression and block-level dedup; build indexes tuned to layerwise streaming patterns to accelerate lookups.
- Potential Products: “KV-Cache-aware” storage engines; cache compaction services that preserve latency SLOs; block layout optimizers.
- Assumptions/Dependencies: Acceptable CPU overhead; minimal impact on latency-critical paths; compatibility with FP8/FP16 cache formats.
- Managed “Agentic‑Optimized LLM Endpoint” as a cloud offering
- Sector: cloud providers
- What: Productize DualPath with autoscaling of P/D ratios, QoS policy enforcement, and SLAs for TTFT/TPOT in agentic scenarios; expose knobs for context length and tool-use profiles.
- Potential Tools: Control planes that adapt engines/groups to load; per-tenant QoS allocations; billing models tied to energy-per-token and KV reuse.
- Assumptions/Dependencies: Mature orchestration, isolation, and observability; multi-tenant fairness policies; consistent RDMA performance across regions.
- Edge and on‑prem appliances with micro‑DualPath
- Sector: edge computing, enterprise appliances
- What: Adapt DualPath to smaller clusters (MIG partitions, fewer GPUs) to pool limited storage bandwidth across engines for long-context agents on-prem.
- Potential Products: “Agentic edge boxes” with validated P/D ratios; lightweight QoS stacks; simplified schedulers.
- Assumptions/Dependencies: RDMA-capable edge NICs; storage fabric capacity; reduced management complexity.
- Green AI reporting and compliance
- Sector: policy/sustainability
- What: Use DualPath’s efficiency gains to meet or exceed regulatory/voluntary targets on energy-per-token and data center utilization; provide standardized reporting.
- Potential Tools: Auditable energy dashboards; automated capacity planning with pooled SNIC modeling; sustainability scorecards for agentic services.
- Assumptions/Dependencies: Accepted measurement methodologies; integration with DCIM/telemetry; evolving regulatory frameworks.
Collections
Sign up for free to add this paper to one or more collections.