Power and Limitations of Aggregation in Compound AI Systems
Abstract: When designing compound AI systems, a common approach is to query multiple copies of the same model and aggregate the responses to produce a synthesized output. Given the homogeneity of these models, this raises the question of whether aggregation unlocks access to a greater set of outputs than querying a single model. In this work, we investigate the power and limitations of aggregation within a stylized principal-agent framework. This framework models how the system designer can partially steer each agent's output through its reward function specification, but still faces limitations due to prompt engineering ability and model capabilities. Our analysis uncovers three natural mechanisms -- feasibility expansion, support expansion, and binding set contraction -- through which aggregation expands the set of outputs that are elicitable by the system designer. We prove that any aggregation operation must implement one of these mechanisms in order to be elicitability-expanding, and that strengthened versions of these mechanisms provide necessary and sufficient conditions that fully characterize elicitability-expansion. Finally, we provide an empirical illustration of our findings for LLMs deployed in a toy reference-generation task. Altogether, our results take a step towards characterizing when compound AI systems can overcome limitations in model capabilities and in prompt engineering.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Power and Limitations of Aggregation in Compound AI Systems — Explained Simply
Overview
This paper asks a simple question: if you use several copies of the same AI model and combine their answers, can you get better results than asking just one model? The authors study this idea using a careful, abstract framework and identify exactly when and how combining (aggregating) multiple models helps—and when it doesn’t.
They focus on LLMs and common multi-agent setups (like debate, ensembles, or prompt variations), and they provide both mathematical results and a small experiment with a reference-generation task.
Key Objectives and Questions
The paper explores:
- When does aggregating answers from multiple copies of the same model give you outputs you couldn’t get from a single model?
- What are the precise mechanisms (reasons) that make combining models powerful?
- What limits this power—are there cases where aggregation doesn’t help at all?
- Can we fully describe the conditions under which aggregation increases what the system designer can “elicit” (i.e., get the model(s) to produce)?
Methods and Approach (in everyday terms)
Think of a teacher (the “system designer”) asking identical students (the “agents,” which represent copies of the same AI model) to produce work. The teacher can give each student slightly different instructions (prompts) and then combine their work to build a final answer.
The paper models this using a principal–agent setup:
- Principal (teacher/system designer): Sets rewards and budgets (think “what gets praise” and “how much effort/time is allowed”) for each agent.
- Agents (models): Try to produce outputs that maximize their reward (what the teacher’s instructions encourage), but they have limitations.
Two kinds of limitations are modeled:
- Prompt/design limitations: The teacher can only express goals using “coarse features” (high-level signals) rather than controlling every fine-grained detail. In practice, this means prompts can’t precisely specify everything desired.
- Model capability limitations: The models have built-in trade-offs (like “to get more of X, you have to accept more of Y”). Mathematically, these are expressed as constraints that limit the kinds of outputs a single model can produce.
Aggregation rules (ways to combine outputs) include:
- Intersection (coordinate-wise minimum): Keeps only what multiple agents agree on; like taking the overlap between their answers.
- Addition (weighted sum): Mixes answers to synthesize a new one; like blending different contributions from each agent.
Finally, the paper defines “elicitability”: an output is elicitable if a single agent, with some prompt and budget, could produce it. Aggregation is “elicitability-expanding” if it allows the teacher to get outputs that no single agent could produce alone.
Main Findings and Why They Matter
The authors identify three core mechanisms that explain when aggregation increases power. If none of these mechanisms are active, aggregation doesn’t help—no matter how you prompt.
- Feasibility expansion:
- What it means: Combining outputs from different agents can produce an output that no single agent could create due to its built-in constraints.
- Everyday analogy: Two students can each safely carry 10 pounds; together they carry a 15-pound box by splitting it, even though no single student could carry it alone.
- Impact: Lets you achieve outputs beyond a single model’s capability envelope.
- Support expansion:
- What it means: Combining outputs that each cover a few “parts” (dimensions) can create a richer output covering more parts than any single model could be prompted to produce.
- Everyday analogy: One student writes about math topics, another about history; combined, you get a broader report with both.
- Impact: Overcomes the limitation that a single prompt often can’t make a model produce a broad, balanced output.
- Binding set contraction:
- What it means: Single agents might be “stuck” at the edge of what’s allowed (tight constraints). Combining their outputs can produce something safely inside the allowed region (less constrained).
- Everyday analogy: Two students each meet an exact word limit with rigid content; merging their best parts produces a shorter, more flexible piece that fits better.
- Impact: Reduces how many constraints are “tight” in the final output, making it easier to reach desired results.
Key theoretical results:
- Necessity: For aggregation to expand what you can elicit, at least one of the three mechanisms must occur. If none is happening, aggregation adds no power—regardless of prompt limitations.
- Strengthened versions: The authors give stronger, precise conditions that are both necessary and sufficient, fully characterizing when aggregation helps.
- Limits of common aggregation rules:
- Intersection can implement feasibility expansion and binding set contraction but cannot implement support expansion in general.
- Addition can implement support expansion and sometimes binding set contraction but not feasibility expansion in general.
- Translation: Not every way of combining outputs can trigger every mechanism.
Empirical illustration (toy LLM task):
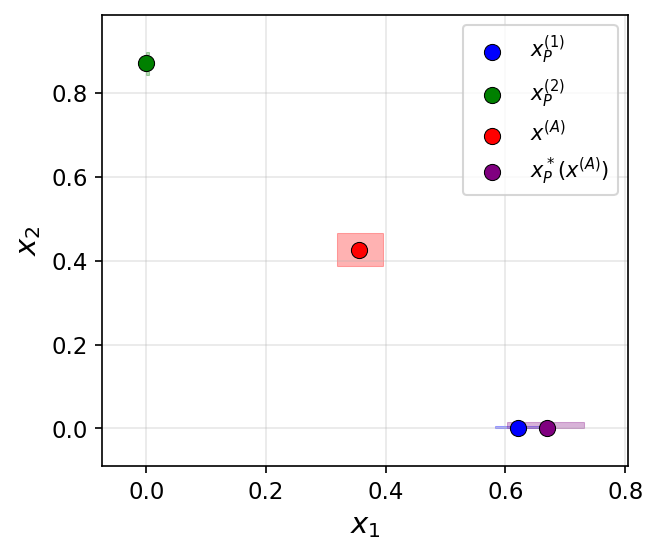
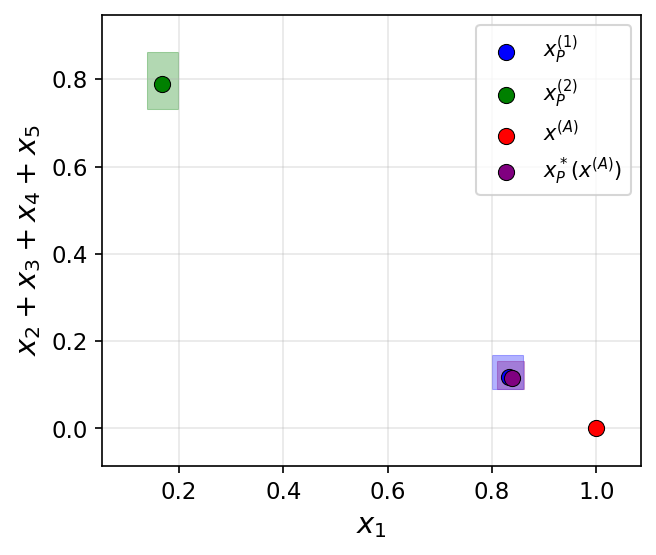
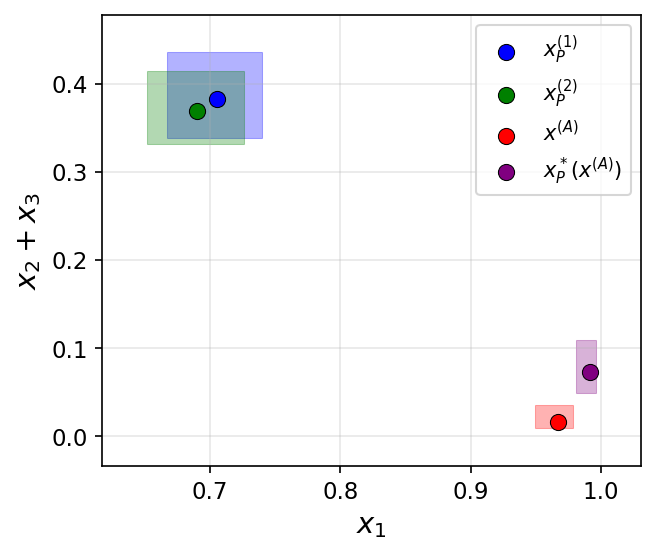
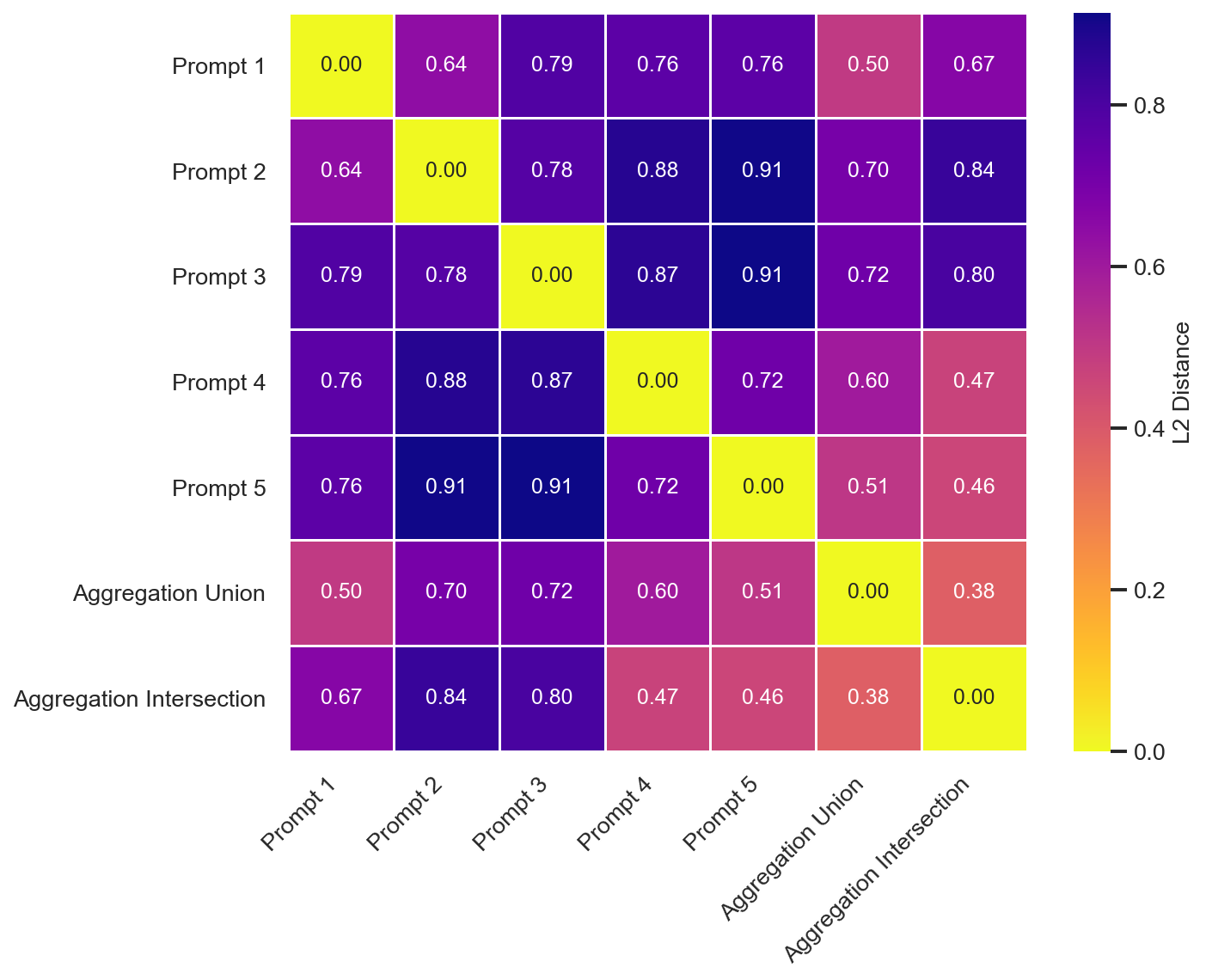
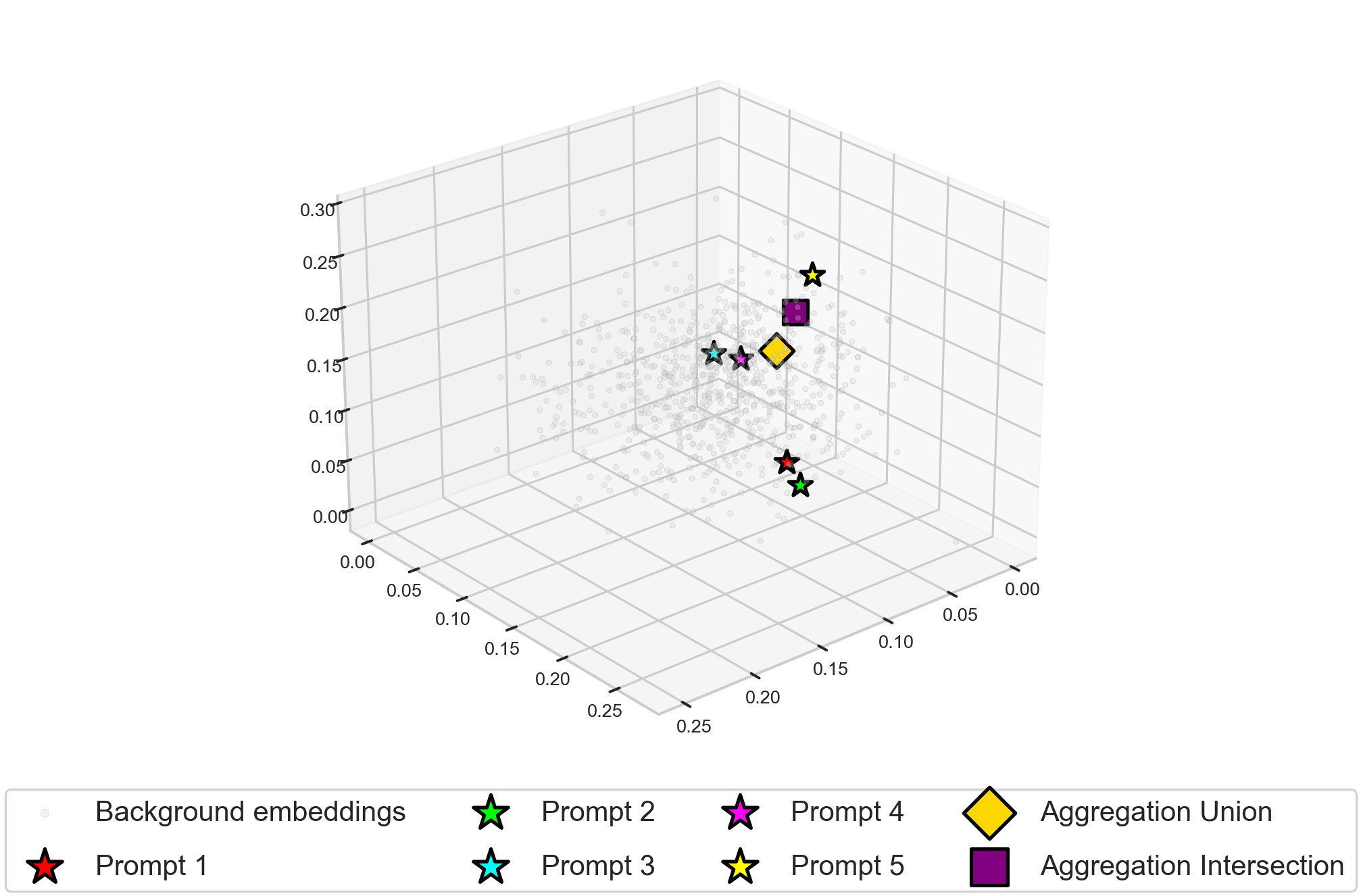
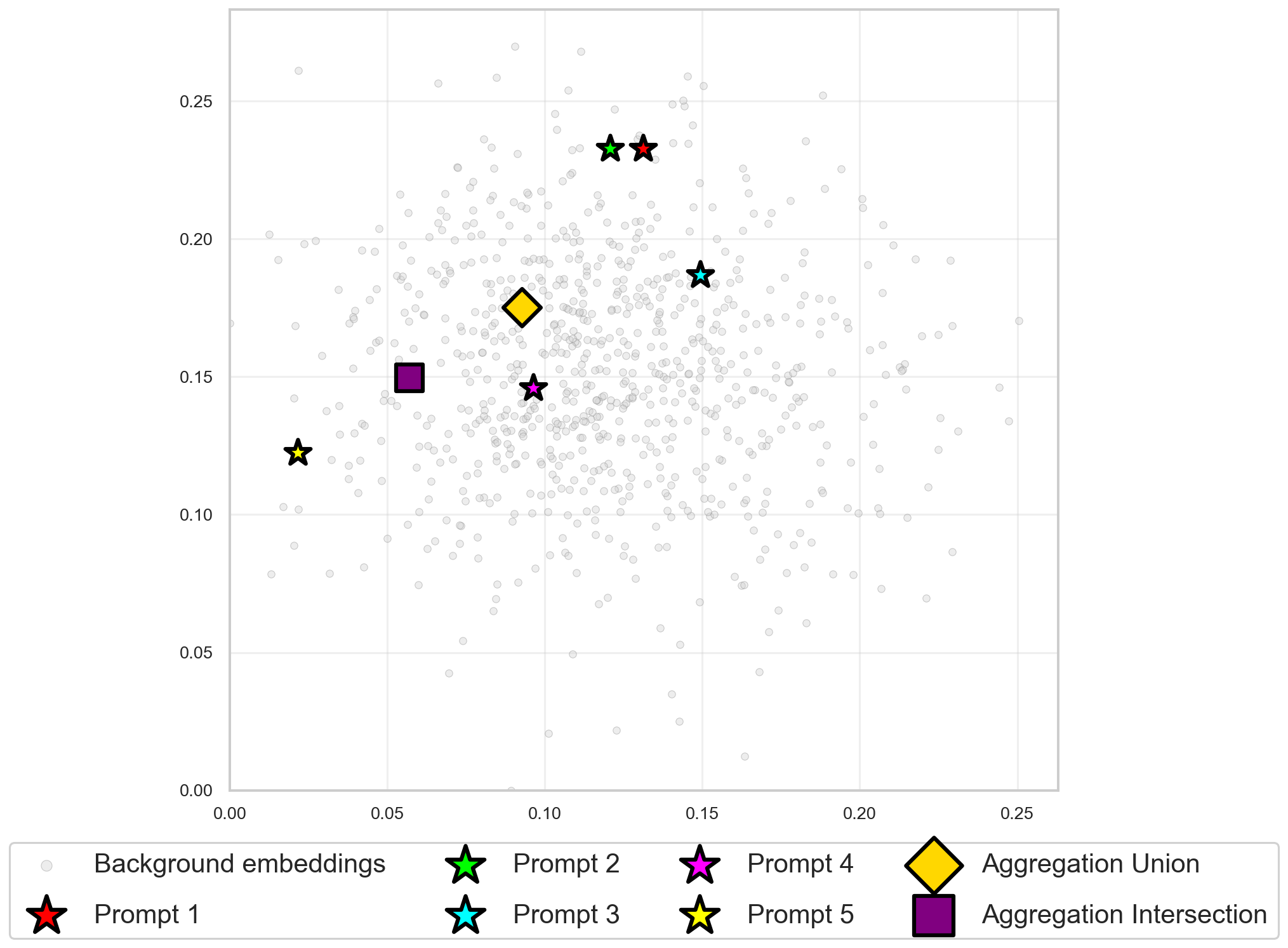
- Task: Generate paper reference lists with a desired balance of topics using GPT-4o-mini and sentence embeddings.
- Setup: Different prompts target different high-level topics; aggregation combines their lists (either by intersection-like filtering or addition-like synthesis).
- Observation: Aggregation produced outputs with balances or properties that no single prompt could achieve, illustrating the three mechanisms in practice.
Implications and Potential Impact
- Practical guidance for AI system designers:
- Aggregation can truly help—but only if it activates at least one of the three mechanisms.
- Choose aggregation strategies that match your goal:
- Want broader coverage? Use addition-style aggregation to aim for support expansion.
- Want safer, more reliable overlap? Use intersection-style aggregation to aim for binding set contraction or feasibility expansion.
- If none of the mechanisms apply to your setup, aggregation may be wasted effort.
- Better compound systems:
- Multi-agent debate, prompt ensembling, and tool-using agents can be designed to overcome prompt underspecification and model capability trade-offs.
- The theory explains why some aggregation setups succeed (and others don’t), which can save time and resources.
- Research significance:
- The paper gives exact theoretical conditions for when aggregation expands the set of achievable outputs.
- It connects real-world LLM behaviors (like hallucination reduction or topic coverage) to clean, general mechanisms.
- It helps bridge the gap between intuitive empirical successes and rigorous guarantees.
In short, combining multiple copies of the same model can be powerful—but only in the right way. This paper shows the exact reasons why aggregation works, the limits of those reasons, and how to design compound AI systems that actually overcome the challenges of prompting and model capabilities.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or left unexplored in the paper. Each point is intended to be concrete enough to guide future research.
- Formal-to-practical mapping of “reward functions” to prompts: The paper assumes the principal can specify monotone reward functions over a known feature map; it does not provide a method to translate desired reward specifications into actual prompts, nor to validate that prompts reliably induce the intended feature weights in real LLMs.
- Learnability of feature weights and constraints: The framework presumes access to the feature-weight matrix and conic constraints on outputs, but it does not address how a system designer could infer, estimate, or learn these objects from data, nor how estimation error affects elicitability-expansion.
- Robustness to stochasticity in LLM outputs: Agents are treated as deterministic optimizers of rewards and budgets; the analysis does not account for sampling variability, non-deterministic decoding, or stochastic multi-turn interactions that can change feasibility or binding sets.
- Generality beyond monotone, weakly concave features: Feature maps are assumed strictly increasing, smooth, and weakly concave; the paper does not analyze elicitability-expansion under non-monotone or non-concave features, interactions among features, or discrete/categorical features typical in text tasks.
- Non-negativity and conic constraints as modeling simplifications: Outputs are restricted to the nonnegative orthant with conic constraints; it remains unclear how well these restrictions capture real text-generation phenomena (e.g., categorical content, logical structure, or discourse-level properties), and what alternative constraint classes (e.g., non-convex, combinatorial) mean for aggregation.
- Budget modeled as an ℓ1 norm: The budget constraint is tied to the ℓ1 norm of the output vector; the paper does not justify or test whether this surrogate reflects real compute/time/interaction budgets, nor does it explore alternate budget forms (e.g., per-dimension costs, nonlinear or probabilistic budgets).
- Constructive design procedures: While strengthened mechanism conditions “fully characterize” elicitability-expansion, the paper does not provide constructive algorithms to (a) check the conditions on a given task instance or (b) design the reward functions, budgets, and aggregation rule that will achieve an inelicitable target.
- Quantifying “how much” power aggregation adds: Theoretical results establish possibility, necessity, and sufficiency, but do not quantify the magnitude of expansion (e.g., measure of newly elicitable outputs, dependence on number of agents K, or sensitivity to feature/constraint parameters).
- Minimal number of agents required: The analysis does not determine the smallest K needed to implement each mechanism or achieve a specific elicitability-expansion target, nor trade-offs between K, aggregation complexity, and reward/budget heterogeneity.
- Aggregation rule design space: Examples emphasize intersection and addition rules, but the paper does not systematically study other rules (e.g., learned aggregators, voting-style methods, quantile filters, median-of-experts, debate/consensus protocols) or characterize which rules can implement which mechanisms under broad conditions.
- Adaptive or learned aggregation: There is no exploration of aggregation rules that are learned from data or adapt to agent outputs at runtime; how learning-based aggregation interacts with the mechanisms and elicitability-expansion remains open.
- Heterogeneous agents and model diversity: Agents are modeled as homogeneous copies; the paper does not analyze how heterogeneity in model capabilities, tools, or training data affects feasibility/support/binding sets or enables stronger aggregation-driven expansion.
- Multi-turn, interactive protocols: The framework abstracts a single-shot aggregation of outputs; it does not study iterative, interactive, or debate-style protocols where agents exchange information, nor the dynamics of how such interaction changes binding constraints or support over time.
- Noise, errors, and adversarial behavior: There is no robustness analysis for aggregation under hallucinations, correlated errors across agents, adversarial agent behavior, or reward hacking; conditions under which aggregation reduces (or amplifies) such failures remain unknown.
- Practical implementability of mechanisms: Feasibility expansion can produce infeasible aggregated outputs by construction; the paper does not address how to implement these mechanisms in real systems without violating constraints such as safety, quality checks, or tool limitations.
- Detecting binding constraints in practice: Binding-set contraction relies on knowing which constraints are binding at a given output; the paper does not propose methods to detect or estimate binding constraints for language outputs in real tasks.
- Empirical scope and external validity: The empirical illustration is a toy reference-generation task with a single model (GPT-4o-mini), limited prompts, and embedding-based proxies; broader validation across tasks, models, datasets, and aggregation rules is missing.
- Metrics linking elicitability to utility: The paper focuses on elicitability of output vectors but does not define or evaluate task-relevant utility metrics (e.g., factuality, coverage, precision/recall), nor connect elicitability-expansion to measurable performance gains.
- Sensitivity analyses: There is no systematic sensitivity analysis on how elicitability-expansion depends on feature weights, constraint geometry, reward function class, or budget scales; robustness to misspecification is unknown.
- Computational complexity: The paper does not analyze the computational complexity of checking elicitability, solving agent optimization problems, or computing optimal aggregation under the proposed mechanisms.
- Trade-offs between mechanisms: It is unclear how the three mechanisms interact (e.g., whether support expansion may worsen binding constraints or vice versa), or how to balance them when they conflict on a given task.
- Safety and alignment implications: While mechanisms can expand elicitability, the paper does not explore whether such expansion may inadvertently enable undesirable outputs, nor how to constrain aggregation to respect safety and alignment objectives.
- From embeddings to semantics: The empirical example uses text embeddings as output vectors, but it does not validate that geometric differences map to meaningful semantic improvements; methods to connect vector-space analyses to human-judged quality are missing.
- Formal treatment of aggregation-induced infeasibility: When aggregation yields infeasible outputs (feasibility expansion), the operational meaning in real systems (e.g., post-hoc filtering, repair procedures) and its impact on performance and safety are left unexplored.
- Generalization to non-linear or compositional aggregations: The framework does not treat compositional pipelines (e.g., tool calling, retrieval augmentation) where aggregation maps outputs through non-linear transformations before synthesis.
- Guidelines for system designers: The paper does not provide actionable design heuristics (e.g., how to choose prompts/rewards to target mechanism implementation under budget or tool constraints), leaving a gap between theory and practice.
- Benchmarking against existing strategies: There is no comparative evaluation versus established ensemble methods (self-consistency, majority vote, best-of-n sampling, debate), so the practical advantage of the proposed mechanisms remains an open empirical question.
- Uncertainty quantification: The framework does not incorporate uncertainty (e.g., confidence over features or constraints), nor strategies to manage uncertainty in aggregation (e.g., risk-aware rules, distributionally robust design).
- Extension beyond coordinate-wise supports: Support expansion is defined over coordinate supports; how to generalize to structured outputs (graphs, programs, plans) or learned latent spaces is unresolved.
- Interaction with tool use and external knowledge: The model does not account for agents leveraging tools or retrieval; how tool-mediated capabilities alter constraint geometry or feature mappings—and thereby aggregation power—remains open.
Practical Applications
Immediate Applications
The following use cases can be deployed with current LLMs and orchestration tools by leveraging prompt diversity, aggregation rules (intersection/min and addition/weighted sum), and simple verification filters. Each item notes which mechanism(s) from the paper it operationalizes: feasibility expansion (FE), support expansion (SE), and binding set contraction (BSC).
- Multi‑prompt reference and content generation pipelines
- Sectors: software tooling, media, academia (literature reviews)
- What: Prompt the same model with diverse instructions (e.g., subtopics, styles, audiences), then:
- Union/weighted sum to broaden coverage (SE)
- Intersection/consensus to retain only items common to multiple prompts or validated by a verifier (BSC)
- Tools/workflow: prompt ensembling; self‑consistency; retrieval‑augmented generation; citation/URL verification; embedding-based de‑duplication; ranker/reward model
- Assumptions/dependencies: sufficient prompt diversity (temperature or instruction variation) to diversify supports; structured outputs (lists, JSON) to enable aggregation; access to fact validators or retrieval to implement filtering
- Hallucination and inconsistency reduction via multi‑agent consensus
- Sectors: customer support, healthcare summaries (non‑diagnostic), finance reports, legal drafting (non‑advisory)
- What: Generate multiple answers and filter to the intersection of claims supported by citations or external tools (BSC; sometimes approximates FE when post‑processing removes all “undesirable” parts that each single model tends to include)
- Tools/workflow: debate/consensus protocols; citation checkers; NLI/entailment models; tool‑augmented verification; ensemble voting
- Assumptions/dependencies: reliable verifiers; structured claim extraction; allowance for higher latency/cost; careful scoping to non‑safety‑critical settings unless validated
- Ensemble code generation with test‑driven selection
- Sectors: software engineering
- What: Parallel prompts specialized for functionality, performance, and security; accept only code that passes tests or multiple independent validators (BSC) and combine complementary modules (SE)
- Tools/workflow: unit/integration tests; fuzzers; linters; SAST tools; multi‑prompt code gen with test runner gating
- Assumptions/dependencies: comprehensive tests; deterministic environment for test execution; sandboxing; prompt specializations that yield diverse candidates
- Information extraction and document/contract parsing
- Sectors: enterprise ops, legal ops, healthcare admin
- What: Assign agents to extract different fields or use varied extraction patterns; union fields to increase recall (SE), then intersect based on cross‑agent agreement or regex/ontology validation (BSC)
- Tools/workflow: schema‑guided prompts; regex/ontology validators; weak supervision; majority voting
- Assumptions/dependencies: well‑defined schemas; validators for formats; diversification of prompts/templates; manageable noise in OCR/inputs
- Retrieval‑augmented generation with union‑then‑intersection
- Sectors: search, knowledge management
- What: Use multiple retrievers/prompts to gather evidence (union for recall, SE), then synthesize and keep only statements cited by multiple sources or validated by a QA checker (BSC)
- Tools/workflow: hybrid retrievers; answer‑supported‑by‑k‑citations gating; confidence/risk scoring
- Assumptions/dependencies: document quality and diversity; strong ranking/validation; latency budget for multi‑pass retrieval
- Lesson planning and assessment design
- Sectors: education/edtech
- What: Generate materials from multiple pedagogical lenses (inquiry‑based, mastery, culturally responsive), merge for breadth (SE), and filter against standards/rubrics (BSC)
- Tools/workflow: standards mapping; rubric‑based scoring evaluators; multi‑prompt lesson synthesis
- Assumptions/dependencies: access to aligned rubrics/standards; clear learning objectives; human-in-the-loop review
- Compliance and policy summarization with citation‑backed consensus
- Sectors: compliance, risk, governance, enterprise policy
- What: Multiple agents create summaries and justifications; accept only claims supported by multiple independent citations (BSC)
- Tools/workflow: citation trace extraction; cross‑agent agreement checks; source whitelists/blacklists
- Assumptions/dependencies: curated source lists; effective citation extraction; auditor oversight
- Mechanism‑aware aggregator selection for LLM orchestration
- Sectors: ML platforms, MLOps
- What: Choose aggregation rule to match the bottleneck:
- Need breadth/coverage → addition/union (SE)
- Need precision/robustness → intersection/consensus (BSC)
- Tools/workflow: orchestration SDKs (LangChain, LlamaIndex); A/B testing to detect elicitability expansion (target outputs achieved only via aggregation)
- Assumptions/dependencies: instrumentation for evaluation; task‑specific metrics; cost/latency budgets
- Practical “elicitability‑expansion tests” for compound systems
- Sectors: academia, industry R&D
- What: Construct targets demonstrably not elicitable via a single prompt but attainable via multi‑prompt aggregation; use as a performance metric and regression test
- Tools/workflow: controlled tasks (e.g., topic‑balanced lists); prompt ablations; unit tests for aggregation operators
- Assumptions/dependencies: task design with measurable support/constraint structure; reproducibility
- Personal productivity with manual union/intersection
- Sectors: daily life
- What: Ask an assistant the same question with multiple framings (e.g., trip planning: cost‑focus, time‑focus, family‑friendly), then manually merge (SE) or cross‑check common items (BSC)
- Tools/workflow: saved prompt variations; simple spreadsheet/notes for aggregation
- Assumptions/dependencies: user familiarity with prompt variation; willingness to curate results
Long‑Term Applications
These require further research, scaling, or development to realize the paper’s full characterization and strengthened conditions for elicitability‑expansion.
- Mechanism‑aware compilers for compound AI systems
- Sectors: ML platforms, enterprise integration
- What: Automatically synthesize sets of prompts (reward specs), budgets, and aggregation operators that provably implement strengthened mechanisms ensuring elicitability‑expansion for a given task model
- Dependencies: formal task modeling (outputs, features, constraints); search/optimization over prompts and weights; verification harnesses
- Learned aggregation operators beyond min/sum
- Sectors: software, robotics, decision support
- What: Design/train aggregators that explicitly target feasibility expansion (FE) and binding set contraction (BSC) while balancing safety and performance; e.g., verifier‑guided aggregators or differentiable selection modules
- Dependencies: availability of verifiers or simulators; safety constraints formalized as conic or similar; training data for aggregator behavior
- Feature‑space and reward‑specification learning
- Sectors: foundation models, enterprise AI
- What: Learn or adapt the coarse feature weights matrix to maximize the attainable set under aggregation; meta‑prompting to discover robust, monotone reward proxies
- Dependencies: datasets linking task outcomes to latent features; optimization under monotonicity and concavity constraints; monitoring for underspecification
- Verified aggregation for safety‑critical domains
- Sectors: healthcare, finance, automotive/robotics, energy
- What: Formal verification that aggregated outputs lie in safe “interior regions” (BSC) and that post‑processing removes unsafe components (approximating FE with tools/filters)
- Dependencies: formalized constraints and hazard models; deterministic pipelines; regulatory alignment; rigorous post‑deployment monitoring
- Cross‑model and market‑level aggregation
- Sectors: cloud AI, procurement, governance
- What: Aggregate heterogeneous models while guaranteeing alignment/coverage; contract structures that require demonstrable mechanism implementation for vendor ensembles
- Dependencies: standardized APIs; benchmarking for elicitability‑expansion; incentives for diversity and robustness
- Adaptive inference‑time compute allocation
- Sectors: inference platforms, edge/cloud
- What: Dynamically allocate budgets across agents based on marginal gains in support or binding‑set contraction; stop when expansion plateaus
- Dependencies: online estimators for marginal utility; latency‑cost trade‑off optimizers
- Benchmarks and diagnostics for elicitability‑expansion
- Sectors: academia, standards bodies
- What: Public tasks with known feasible sets and target supports; metrics to quantify expansion attributable to aggregation and not single‑prompt improvements
- Dependencies: task curation; open implementations of aggregation rules; community adoption
- Domain‑specific output‑space mappers
- Sectors: healthcare, legal, finance, scientific R&D
- What: Tooling to map outputs to non‑negative vector spaces (topics, quality dimensions, risk factors) and define domain‑relevant conic constraints
- Dependencies: ontologies/taxonomies; annotation pipelines; agreement on dimension semantics
- Governance and certification frameworks
- Sectors: policy, compliance
- What: Require system providers to show which mechanism(s) their aggregation relies on, when it yields gains, and failure modes when none apply
- Dependencies: reporting standards; third‑party evaluators; audit trails of prompts, budgets, and aggregation policies
- Safe control via aggregation in cyber‑physical systems
- Sectors: robotics, energy, manufacturing
- What: Combine specialized controllers/planners and aggregate to keep actions within safe interiors (BSC) or to synthesize capabilities not attainable by any single controller (FE via verified post‑processing)
- Dependencies: high‑fidelity simulators; real‑time verification; robust mapping of control outputs to constrained vector spaces
Notes on Feasibility and Dependencies (common across applications)
- Diversity is essential for support expansion: prompts, temperatures, tools, or retrievers should produce meaningfully different outputs.
- Aggregation benefits may vanish if none of the three mechanisms apply to the task; invest in diagnostics to detect this.
- Intersection‑style aggregation typically needs verifiers, consensus checks, or tests to realize binding set contraction in practice.
- Feasibility expansion often requires post‑processing that can “filter out” undesirable components (e.g., facts not supported by evidence), implying reliance on external tools or validators.
- Costs and latency increase with multiple agents; budget allocation and early‑exit strategies can mitigate this.
- Structured outputs (schemas, lists, JSON) make aggregation reliable; unstructured text may need parsing or embeddings to approximate the output vector space.
- Safety‑critical deployments require formalized constraints and verification; otherwise, use cases should remain advisory with human oversight.
Glossary
- Addition aggregation: An aggregation rule that outputs a weighted sum of agents’ outputs. "The second is addition aggregation, which takes a weighted sum of the vectors."
- Aggregation rule: A function that maps multiple output vectors to a single aggregated output. "An aggregation rule is a mapping from a list of output vectors to an aggregated output vector ."
- Binding constraint: A constraint that holds at equality for a given output, restricting feasible directions of improvement. "When a constraint is binding for an output vector, some reward-increasing directions become inaccessible to the agent, as these directions will lead to violation of the binding constraint."
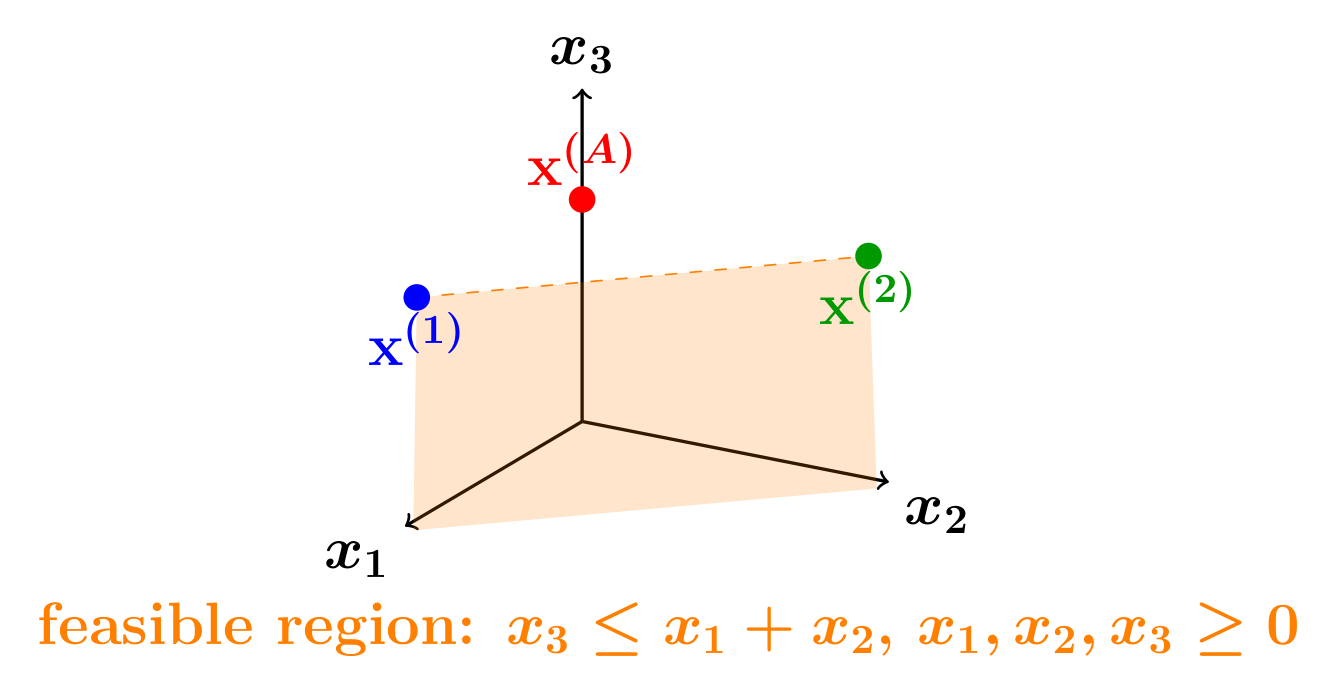
- Binding set contraction: A mechanism where aggregation reduces the set of constraints binding at the output, moving it toward the interior of the feasible region. "Binding set contraction captures when two vectors on the boundary of the feasible set are aggregated into a vector in the interior"
- Complementarity: A task interaction where effort on one task lowers the marginal cost of effort on another. "while complementarity occurs when effort on one task decreases it."
- Conic constraints: Cone-shaped linear constraints modeling capability limits on outputs. "We study restrictions requiring output vectors to satisfy conic constraints."
- Consensus game: A setup where agents attempt to reach agreement, often between generators and discriminators. "consensus games between generators and discriminators"
- Elicitability: The property that an output can be induced by some reward and budget specification. "does not expand elicitability on any problem instance"
- Elicitability-expansion: The phenomenon where aggregation enables inducing outputs that a single agent cannot produce directly. "We then formally connect these mechanisms to elicitability-expansion."
- Feasibility expansion: A mechanism where aggregating feasible outputs yields an output outside any single agent’s feasible set. "Feasibility expansion captures when two feasible vectors are aggregated into an infeasible vector"
- Feasible set: The set of outputs that satisfy all constraints. "two vectors on the boundary of the feasible set"
- Feasible, budget-reducing directions: Directions from a point that maintain feasibility while reducing the budget norm, used to analyze local elicitability. "The set of feasible, budget-reducing directions for an output vector depends on the sufficient statistics of the support and binding conic constraints indices of ."
- Feature map: A mapping from output dimensions to a lower-dimensional feature space used by reward functions. "Let the feature map be ."
- Feature weights matrix: The nonnegative matrix of coefficients that map outputs to features. "call this the feature weights matrix."
- Intersection aggregation: An aggregation rule that takes the coordinate-wise minimum across outputs. "The first is intersection aggregation, which is defined to be the coordinate-wise minimum of the vectors:"
- ℓ1 norm: The sum of absolute values of vector coordinates, used here as a budgeted measure of output size. "the norm of elicitable outputs"
- Monotone reward function: A reward that does not decrease when any feature increases. "We assume reward functions are monotone."
- Multi-agent debate: Protocols where multiple agents argue or seek consensus to improve output quality. "multi-agent debate protocols where different LLM agents seek consensus"
- Nonnegative orthant: The subset of space where all coordinates are nonnegative. "shifted to be in the nonnegative orthant."
- Principal-agent framework: A model where a principal designs incentives for agents who choose actions subject to constraints. "we investigate the power and limitations of aggregation within a stylized principal-agent framework."
- Prompt ensembling: Combining outputs from different prompts to improve performance. "prompt ensembling approaches where the outputs from different prompts are combined"
- Self-consistency: An inference method that samples multiple reasoning traces and selects consistent answers. "resampling the same model or reasoning trace and then selecting outputs via reward models, self-consistency, or synthesis"
- Strategic classification: Settings where individuals alter their features strategically to influence classification outcomes. "This model was originally developed in a strategic classification setting"
- Substitutability: A task interaction where effort on one task raises the marginal cost of another. "Substitutability occurs when effort on one task increases the marginal cost of effort on another,"
- Sufficient statistic: A reduced representation that fully determines elicitability properties. "the condition for whether is elicitable only depends on through the following sufficient statistic ."
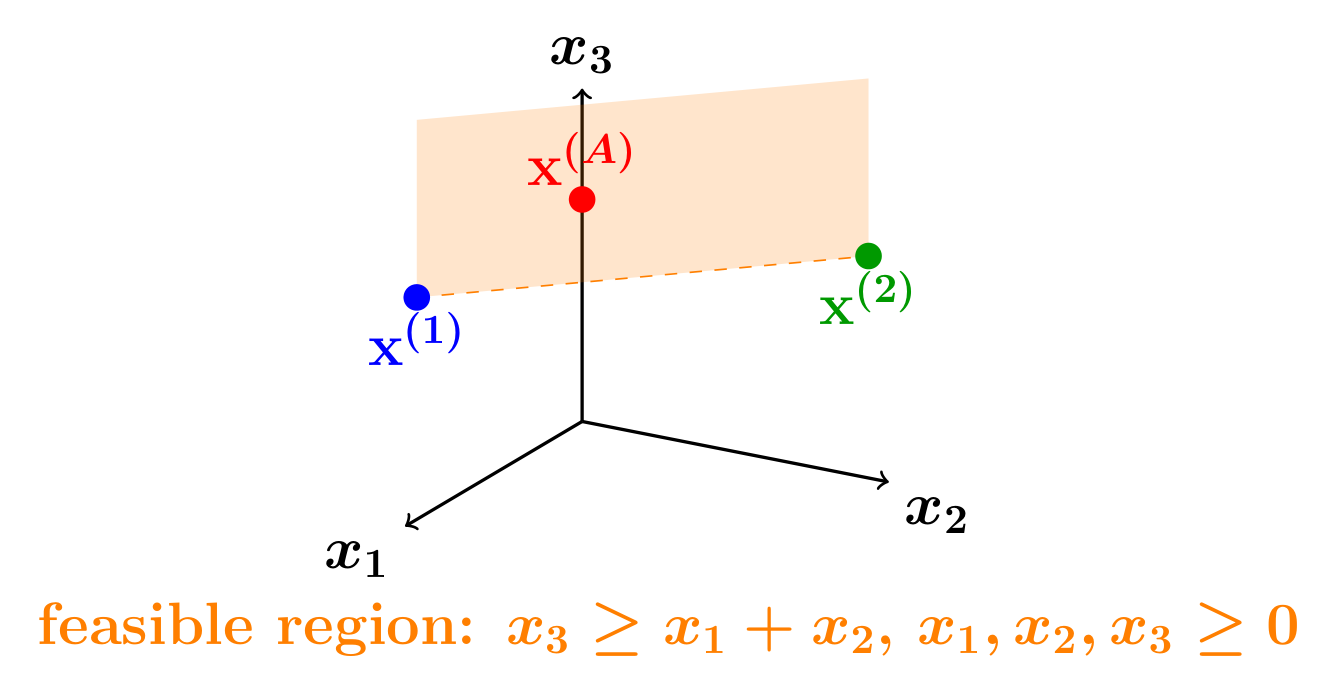
- Support (of a vector): The set of indices where a vector has strictly positive entries. "The first component denotes the support of ."
- Support expansion: A mechanism where aggregation yields an output with a richer (larger) support than any single agent’s output. "Support expansion captures when two vectors are aggregated into a vector with richer support"
Collections
Sign up for free to add this paper to one or more collections.