- The paper identifies two structural limitations—auto-suggestive delusions and predictor-policy incoherence—that hinder agent performance in predictive models.
- The paper demonstrates that fine-tuning on self-generated outputs reduces these issues, as evidenced by improved results in tic-tac-toe and padlock game experiments.
- The paper presents a formal framework with proofs showing that repeated retraining aligns predictive models with optimal policies by eliminating incoherence.
Limitations of Agents Simulated by Predictive Models
This essay explores the challenges and limitations encountered when adapting predictive models into agent-like systems, particularly focusing on LLMs used as AI assistants. It highlights two key structural reasons for the potential failures of these models: auto-suggestive delusions and predictor-policy incoherence. Furthermore, the essay explores how fine-tuning these models on their own outputs can rectify these limitations, providing a unifying perspective on the observed failure modes and shedding light on why online learning enhances the effectiveness of offline-learned policies.
Auto-Suggestive Delusions
The paper addresses the issue of auto-suggestive delusions, which arise when predictive models are trained to imitate agents that rely on hidden observations. In such cases, the hidden observations act as confounding variables, leading the models to interpret their own generated actions as evidence for non-existent observations (Figure 1). This phenomenon was previously discussed by Ortega et al. (Ortega et al., 2021).
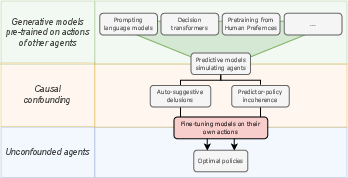
Figure 1: Agents derived from predictive models might fail because of causal confounding, but fine-tuning on their own output addresses those issues.
The "Stock Trader" example illustrates this problem, where a model trained on an expert's stock trades without access to the expert's latent state incorrectly uses its own generated actions to infer the state, leading to delusional behavior (Figure 2). In the context of LLMs, this can manifest as the model treating its previously generated tokens as evidence for states that are not directly observed, such as hallucinating facts and then reinforcing those hallucinations in subsequent predictions.
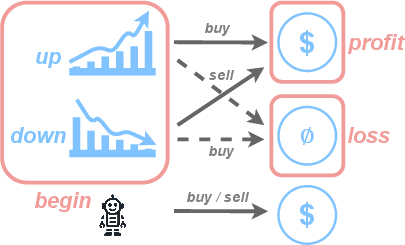
Figure 2: A diagram of the Stock trader example. States are represented in blue; observations are in orange; lines represent actions and associated transitions. Dotted lines are transitions which the expert is never observed to take. The agent simulated by the model then falls into auto-suggestive delusion: since it doesn't distinguish between the starting states, it believes it gets profit no matter what action it takes.
Predictor-Policy Incoherence
The essay introduces a novel limitation termed "predictor-policy incoherence." This occurs when a model generates a sequence of actions, and its implicit prediction of the policy that generated those actions serves as a confounding variable. Consequently, the model chooses actions as if it expects future actions to be suboptimal, leading to overly conservative behavior. The "Three Cards Game" exemplifies this, where a model trained on random agents incorrectly predicts that playing $\TOCK$ is better, even though the optimal strategy is to play $\TICK$ first (Figure 3).

Figure 3: The Padlock game involves an agent trying to open a padlock with a 15-bit code (for presentation, we limit this to 5 bits here). The first three are always the same; the last two are randomised. The agent offline learns from a dataset of expert plays, who know the combination and get it right on the first try. The agent correctly sets first three bits, however, it does not know the combination, and only deludes itself into thinking that it solved the game.
Fine-Tuning on Simulated Agents
The paper argues that both auto-suggestive delusions and predictor-policy incoherence can be resolved by fine-tuning the model on data generated by its own simulated agents. This process is central to techniques like RLHF and ReST. Fine-tuning reduces auto-suggestive delusions and predictor-policy incoherence, as demonstrated in the tic-tac-toe experiment (Figures 8 and 9).
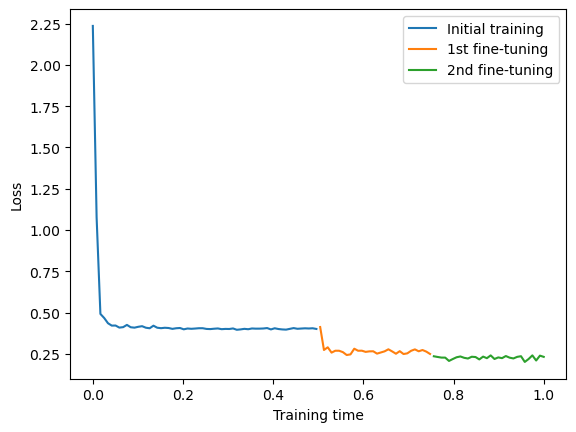
Figure 4: Training loss in the tic-tac-toe game. Subsequent fine-tuning epochs correspond to the visible drops in the loss.
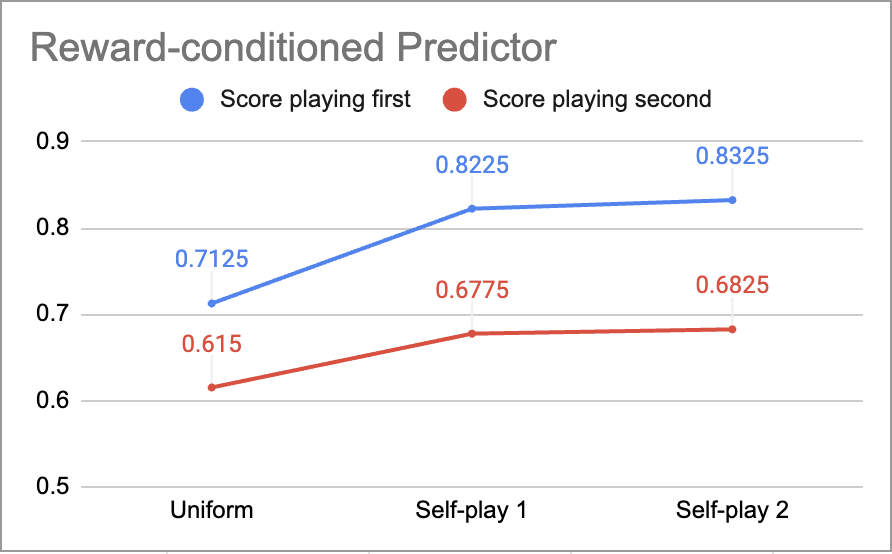
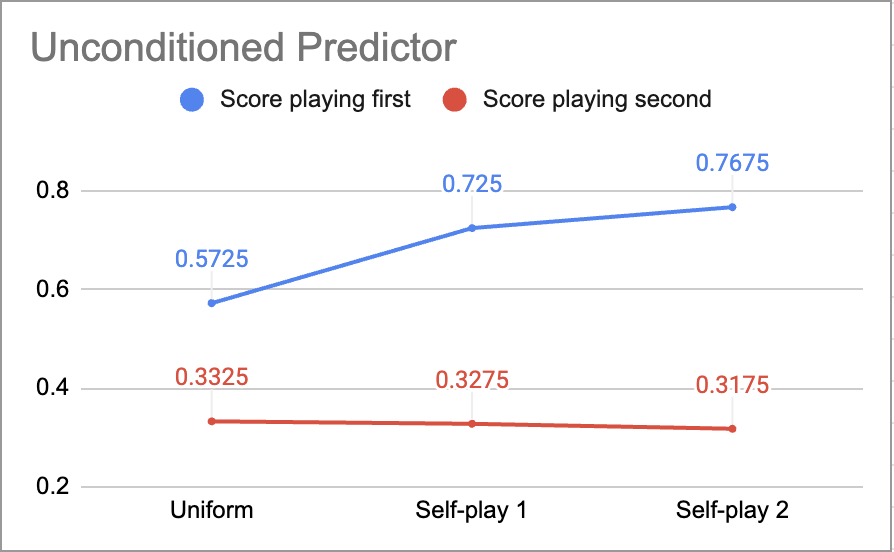
Figure 5: Scores of iteratively fine-tuned conditioned and unconditioned predictors in the tic-tac-toe experiment.
Experiments and Results
The paper presents two experiments to validate the theoretical framework. The first experiment, the "Padlock Game," demonstrates how fine-tuning a model on its own outputs reduces auto-suggestive delusions. The delusion measure, quantified using KL divergence, decreases significantly after fine-tuning, indicating a reduction in the model's tendency to make incorrect inferences about latent states.
The second experiment, using the tic-tac-toe game, shows that fine-tuning on simulated agents reduces predictor-policy incoherence. The model's performance improves with fine-tuning, indicating that it becomes better at playing the game by learning to trust its own actions and policies.
The paper formally defines predictor-policy incoherence and provides a theorem proving that repeated retraining of predictive models on their own actions decreases predictor-policy incoherence and eliminates auto-suggestive delusions. This makes the resulting agents converge on optimal policies. The incoherence κ(π) of a policy π(at∣st) is defined as:
κ(π)=s∈S∑DKL(G(π)(a∣s)∣∣π(a∣s))
where G(π)(at∣st)=pπ(at∣st,R=1) is the goal-conditioning operator. The paper proves that limk→∞κ(πk)=0, where πk=Gk(π0). Similarly, the delusion λ(p) between a predictive model p(a) and an unconfounded policy p(a∣s) is defined as:
λ(p)=DKL(p(a∣s)∣∣p(a))
Re-training on p(a∣o) removes this delusion.
Discussion
The essay discusses the implications of this work for the development of superhuman capabilities in simulated agents and emphasizes that even perfect predictive models are subject to auto-suggestive delusions and predictor-policy incoherence. Fine-tuning models on their own outputs mitigates these problems, improving the agents' ability to make optimal decisions. One potential application is intentionally leveraging predictor-policy incoherence and auto-suggestive delusions as a tool for scalable oversight by biasing the model towards simulating certain kinds of preferred policies. One important next step is to investigate how methods like RLHF and DPO impact models' predictor-policy incoherence and agency, independently of the particular reward model.
Conclusion
The study provides a comprehensive framework for understanding the limitations of agents simulated by predictive models, specifically auto-suggestive delusions and predictor-policy incoherence. It demonstrates that fine-tuning models on their own outputs can effectively mitigate these limitations, leading to improved agent performance and a better understanding of how goal optimization emerges in systems built on generative models. The findings have implications for the development of AI systems, particularly in tasks where simulated agents might develop superhuman capabilities, and offer insights into scalable oversight through limiting agency.