Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
Abstract: The reliability of multilingual LLM evaluation is currently compromised by the inconsistent quality of translated benchmarks. Existing resources often suffer from semantic drift and context loss, which can lead to misleading performance metrics. In this work, we present a fully automated framework designed to address these challenges by enabling scalable, high-quality translation of datasets and benchmarks. We demonstrate that adapting test-time compute scaling strategies, specifically Universal Self-Improvement (USI) and our proposed multi-round ranking method, T-RANK, allows for significantly higher quality outputs compared to traditional pipelines. Our framework ensures that benchmarks preserve their original task structure and linguistic nuances during localization. We apply this approach to translate popular benchmarks and datasets into eight Eastern and Southern European languages (Ukrainian, Bulgarian, Slovak, Romanian, Lithuanian, Estonian, Turkish, Greek). Evaluations using both reference-based metrics and LLM-as-a-judge show that our translations surpass existing resources, resulting in more accurate downstream model assessment. We release both the framework and the improved benchmarks to facilitate robust and reproducible multilingual AI development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making better translations of AI test sets so we can fairly judge how good LLMs are in different languages. The authors build an automated translation pipeline that turns popular English benchmarks (like school-style quizzes for AI) into other languages without losing meaning or giving away answers by accident.
They focus on eight Eastern and Southern European languages: Ukrainian, Bulgarian, Slovak, Romanian, Lithuanian, Estonian, Turkish, and Greek.
What questions did the researchers ask?
They set out to answer three simple questions:
- Are current translated test sets (benchmarks) trustworthy across languages?
- If we let an AI try multiple translations and then pick or improve the best one, does translation quality get better?
- How can we translate tricky question-and-answer tests so the original logic, grammar, and difficulty stay the same in other languages?
How did they study it?
They built a fully automated translation pipeline that works for two kinds of content:
- Datasets (plain text)
- Benchmarks (question-and-answer tests where the choices must match the question perfectly)
They tested four translation strategies. Think of them like different ways a teacher might handle multiple student drafts.
The four strategies (with everyday analogies)
- SC (Self-Check)
- What it does: The AI translates once, then does a quick self-review.
- Analogy: You write an essay, then reread it once to catch mistakes.
- Best-of-N
- What it does: The AI makes several different translations and scores them, then we pick the best.
- Analogy: You ask five friends to translate a sentence and choose the best version.
- USI (Universal Self-Improvement)
- What it does: The AI makes several translations, then combines the best parts into one improved version.
- Analogy: You take the best sentences from each friend’s translation and stitch them together into one great answer.
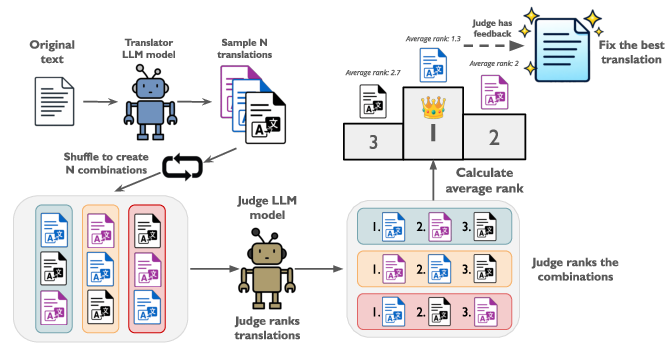
- T-RANK (Translation Ranking)
- What it does: The AI creates several translations, ranks them in multiple rounds (shuffling the order each time to avoid favoritism), and then polishes the winner.
- Analogy: A mini tournament where entries play against each other several times in different positions so the judge isn’t biased toward the first one they see. The champion gets a final edit pass.
Why focus on these languages and on benchmarks?
- These languages have complex grammar (like cases and gender) that can easily break a question if translated carelessly.
- Some answer choices in English don’t reveal the answer, but in another language, grammar endings might accidentally “leak” the right choice. The pipeline is designed to prevent this.
- Translating questions and answers together (in the same “context”) is crucial so the meaning and grammar agree across the whole item.
How did they check quality?
They used two kinds of evaluation:
- Automatic metrics (like COMET), which is a “grading robot” that compares translations to human references or estimates quality without references.
- LLM-as-a-judge, where an AI compares two translations and decides which is better.
They also checked whether models scored higher on tests after using the improved translations. If a model’s score goes up in a way that makes sense, it’s a sign the translation is clearer and fairer.
What did they find, and why is it important?
- Their translations were consistently better than existing ones.
- When an AI judge compared their versions against widely used translations (like Global-MMLU), their versions won many more head-to-head comparisons across multiple languages.
- USI and T-RANK usually produced the highest-quality translations.
- USI is efficient and strong for shorter or simpler texts.
- T-RANK is especially good at catching subtle errors in complex question-and-answer items.
- Better translations led to more accurate model scores.
- Popular open models (like Gemma, Qwen, Llama) scored higher on the improved benchmarks, especially on tasks where grammar could accidentally reveal the correct answer (like Winogrande). This suggests the tests became fairer and clearer, not just easier.
- Newer LLMs can already outperform classic tools (like Google Translate or DeepL) when used with these smarter “try multiple times and refine” strategies.
Why this matters: If the translation of a test is sloppy, it can make a model look smarter or dumber than it really is. High-quality translations give us fairer evaluations, which helps researchers and companies build better, safer, and more inclusive AI.
What does this mean for the future?
- Fairer multilingual AI: With reliable translations, we can judge AI models fairly across many languages, not just English.
- Less manual work: The pipeline is automated and configurable, so teams can scale to more languages and datasets quickly.
- Better research tools: The authors released their code and improved benchmarks, so others can reproduce and build on this work.
- Next steps: They plan to test more open-source models, adapt methods to the difficulty of each text, and expand beyond European languages.
In short, this paper shows a practical, scalable way to translate AI benchmarks so that tests stay fair and meaningful across languages. This helps everyone—researchers, developers, and users—trust multilingual AI evaluations more.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list outlines unresolved gaps, uncertainties, and open questions that the paper leaves for future research.
- Lack of human evaluation: No bilingual human assessments (e.g., MQM or DA) are reported to validate LLM-as-a-judge and COMET conclusions across languages.
- Judge reliability and bias: Single-family LLM-as-a-judge setups lack calibration, inter-judge agreement, and cross-family ensembles; no statistical tests of significance or robustness to judge prompts/settings.
- Positional bias quantification: T-RANK claims to mitigate positional bias, but there is no quantitative measurement of bias before/after nor comparison against alternative debiasing schemes.
- Limited language coverage: Evaluation focuses on eight mid-resource European languages; generalization to truly low-resource, typologically distant, RTL, morphologically rich, or polysynthetic languages remains untested.
- Directionality gaps: The framework is only evaluated for EN→X; performance for X→EN and X→Y directions (including when the source is not English) is unknown.
- Domain/length generalization: Benchmarks used (WMT24++, FLORES, MMLU subsets) underrepresent long-form discourse, coreference, dialog, and domain-specific jargon; robustness on long/contextual inputs is not assessed.
- Adaptive method selection: No automatic difficulty estimator or meta-policy to choose among SC/BoN/USI/T-RANK per item/language; features, training data, and evaluation for such a selector are missing.
- Cost–quality trade-off curves: Absence of systematic throughput, latency, and token-cost analyses across methods, candidate counts, and segment lengths; no Pareto frontiers to guide practitioners.
- Hyperparameter sensitivity: No ablations for temperature, number of candidates N, number of rounds/prompts p, or prompt templates; stability across these choices is unknown.
- Theoretical and empirical analysis of T-RANK: No formal justification or empirical study of ranking consistency, sample complexity, or comparisons with pairwise tournament/Elo/Bradley–Terry aggregation.
- Rewarded selection baselines: Best-of-N uses LLM scoring; no comparison to MT-specific reward models (e.g., COMETKiwi) or hybrid judges, nor to learned rerankers trained on QE signals.
- Structural integrity checks: No automated verification that answer keys, option ordering, and formatting remain consistent post-translation; risks of label drift or duplicate/invalid options are not quantified.
- Answer leakage auditing: No automatic detection/metrics for leakage via gender/number/case morphology; lack of pre/post leakage rates or mitigation procedures per language/benchmark.
- Psychometric properties: No item-response theory (IRT) or anchor-based analysis to quantify difficulty shifts and ensure comparable item characteristics across languages.
- Model ranking stability: Gains in raw accuracy are reported, but stability of model rankings and pairwise ordering across translations is not analyzed.
- “Higher scores” vs “higher quality”: Improved downstream accuracy may reflect easier translations; no controlled experiments to disentangle quality from difficulty reduction.
- Human-in-the-loop strategies: No exploration of targeted human post-editing on hard items, cost-effective sampling for review, or active learning to focus compute/humans where needed.
- Open-weight translators: Claims that open-weight models may benefit more are untested; a comprehensive evaluation across open-weight MT/LLM models is missing.
- Reproducibility under model drift: Closed-source API reliance, stochastic sampling, and evolving checkpoints reduce reproducibility; no fixed seeds, version pinning, or variance reporting.
- Error taxonomy and diagnostics: No systematic categorization/quantification of error types (agreement, named entities, negation, units, pragmatics), per method and language, to guide targeted fixes.
- Prompt engineering ablations: The impact of language-specific few-shot exemplars, instruction wording, and judge rubric variations is not studied.
- Cultural adaptation policy: Criteria for when to adapt vs literally translate culturally bound content (and its evaluation impact) are not specified or measured.
- Safety/toxicity shifts: No assessment of how translation alters harmful content, safety filters, or evaluation fairness across sensitive topics.
- Reference-free QE breadth: COMETKiwi QE is mentioned but not systematically reported across all languages/benchmarks or calibrated against human judgments.
- Robustness to code, math, and formatting: Handling of code snippets, LaTeX/math, units, and specialized notation (common in MMLU) is not evaluated for fidelity.
- Complex benchmark formats: Generalization to multi-hop QA, retrieval-augmented prompts, or multi-turn/dialog benchmarks is not demonstrated.
- Monitoring structural preservation at scale: No continuous integration tests or automatic validators to ensure question–answer coherence and metadata integrity during large-scale translation.
- Hybrid method design: Potential of combining USI and T-RANK (e.g., iterative fusion then tournament ranking) is unexplored; no early-stopping or fallback policies for very hard items.
- Generalization beyond Europe: Application to African, Indigenous, and under-documented languages (orthography variation, code-switching) remains an open direction with distinct challenges.
- Contamination risk: Translators/judges may be trained on benchmark content; no controls (e.g., held-out unseen items, paraphrase-based checks) to assess contamination effects.
- Legal/data governance: No discussion of licensing constraints for using closed APIs on benchmark content or strategies for fully offline, reproducible pipelines.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released codebase and multilingual benchmarks, with minimal adaptation. Each item lists relevant sectors, concrete workflows/products, and feasibility notes.
- Multilingual benchmark localization for model evaluation
- Sectors: AI/ML industry, academia, software tooling
- What: Use the released pipeline (SC, Best-of-N, USI, T-RANK) to translate existing evaluation suites (e.g., MMLU, HellaSwag, ARC, Winogrande) into target languages while preserving QA semantics and avoiding answer leakage (e.g., gendered endings).
- Tools/Workflows: Integrate the GitHub pipeline into eval harnesses (e.g., with Hugging Face Datasets). Add T-RANK/USI as a post-processing step in evaluation data prep.
- Assumptions/Dependencies: Access to frontier APIs (e.g., GPT-4o-mini, Gemini) or sufficiently strong open-weight models; API quotas/costs; permission to translate datasets.
- Internal capability assessments for multilingual AI products
- Sectors: Software, consumer AI, enterprise AI, ML Ops
- What: Build reliable multilingual eval dashboards to monitor model updates across regions, using improved localized benchmarks to avoid inflated or skewed scores.
- Tools/Workflows: CI/CD eval step that runs per-language test suites; LLM-as-a-judge for spot checks; COMET/QE for automated signals.
- Assumptions/Dependencies: Stable evaluation harness; calibration of LLM-as-a-judge and metric thresholds; budget for test-time sampling.
- High-quality translation of instruction datasets for fine-tuning
- Sectors: AI/ML industry, edtech, open-source communities
- What: Translate instruction/fine-tuning corpora into mid-resource languages with T-RANK/USI to reduce semantic drift and grammatical mismatches.
- Tools/Workflows: Data pipeline step for translation and self-refinement; dataset flattening for ingestion; judge-assisted candidate ranking.
- Assumptions/Dependencies: Source data rights; domain-specific prompt tuning; compute/latency budgets.
- Context-aware translation for i18n strings and UI copy
- Sectors: Software, product localization (L10n), developer tools
- What: Translate UI strings, help text, and FAQs with prompts that preserve placeholders and context, avoiding grammatical errors that leak meaning.
- Tools/Workflows: Batch translation with Best-of-N + ranking; guardrails to protect variables and formatting; regression checks using LLM-as-a-judge.
- Assumptions/Dependencies: String context availability; style guides per locale; integration into localization workflows (e.g., Crowdin, Lokalise).
- Safer multiple-choice content localization (no answer leakage)
- Sectors: Education, assessment, HR/testing platforms
- What: Translate quizzes/exams (MCQ/QA) while preserving option semantics and avoiding grammatical cues that reveal answers in target languages.
- Tools/Workflows: Benchmark mode of the framework; T-RANK for multi-round ranking and final correction; targeted prompts for gender/case handling.
- Assumptions/Dependencies: Human spot checks for high-stakes tests; exam IP/licensing; linguistic style choices aligned with local norms.
- Academic replication/extension of multilingual benchmarks
- Sectors: Academia, open research, evaluation consortia
- What: Generate reproducible, stronger multilingual versions of established benchmarks; compare evaluation artifacts to quantify translation-induced variance.
- Tools/Workflows: Use released multilingual benchmark collections; publish protocols for translation choices and judge settings; release diffs.
- Assumptions/Dependencies: Community-agreed evaluation practices; reporting on LLM-as-a-judge biases; availability of comparison baselines.
- Data vendor offerings: “localized benchmark packs”
- Sectors: Data providers, model validation services
- What: Curate and sell validated, high-quality translated benchmarks for specific language portfolios (e.g., Eastern and Southern Europe).
- Tools/Workflows: Productionized pipeline with T-RANK/USI profiles per language; LLM-as-a-judge audit reports; COMET/QE summaries.
- Assumptions/Dependencies: QA SLAs; licensing of source benchmarks; customer trust in LLM-based evaluation complemented by human audits.
- Compliance and training QA localization
- Sectors: Finance, healthcare, government, enterprise L&D
- What: Localize compliance question banks and scenario-based assessments without semantic drift; maintain consistent difficulty across languages.
- Tools/Workflows: Benchmark mode with answer-preserving prompts; multi-round ranking to catch subtle errors; audit trails of selection/corrections.
- Assumptions/Dependencies: Regulatory acceptance; human oversight for regulated content; domain-specific terminology glossaries.
- Improved MT post-editing without model retraining
- Sectors: Translation services, content operations
- What: Use USI or T-RANK as a zero-training post-edit step on top of baseline MT to achieve higher quality on mid-resource languages.
- Tools/Workflows: Pipeline that samples candidates from an MT engine, then applies USI/T-RANK consolidation and corrections.
- Assumptions/Dependencies: Access to candidate generation (via LLMs or NMT); cost-performance trade-offs; style consistency controls.
- Community/localization of open educational resources
- Sectors: Public education, NGOs, creators
- What: Translate MOOCs, worksheets, and community quizzes while preserving task structure and fairness across languages.
- Tools/Workflows: Batch processing with few-shot prompts for language-specific grammar; selective LLM-judge checks on complex items.
- Assumptions/Dependencies: Content permissions; volunteers for spot-checking; resource constraints in low-budget settings.
Long-Term Applications
These applications require additional research, scaling, or validation—e.g., broader language coverage, stronger open-weight models, automated difficulty-aware method selection, or policy/standards alignment.
- Difficulty-aware adaptive translation orchestration
- Sectors: AI/ML platforms, MLOps, localization tech
- What: Automatically predict translation difficulty per item and choose SC/Best-of-N/USI/T-RANK dynamically to optimize quality/cost.
- Tools/Workflows: Classifier for input complexity; dynamic routing; feedback loops using QE/human audits.
- Assumptions/Dependencies: Reliable complexity metrics; per-language profiles; robust monitoring of quality drift.
- Open-weight, on-prem multilingual translation QA
- Sectors: Enterprise, government, defense, healthcare
- What: Deploy USI/T-RANK with strong open models on-prem for privacy-sensitive data; reduce reliance on closed APIs.
- Tools/Workflows: Fine-tuned judge/evaluator models; vectorized batch inference; internal evaluation benchmarks.
- Assumptions/Dependencies: Availability of competitive open-weight models; GPU/infra capacity; internal governance.
- Benchmark-as-a-Service (BaaS) for multilingual evaluation
- Sectors: Model providers, auditors, regulators
- What: Managed service delivering curated, versioned, bias-audited multilingual benchmarks with per-language difficulty calibration.
- Tools/Workflows: SaaS portal; versioning and change logs; statistical comparability reports; LLM-judge and human QA pipelines.
- Assumptions/Dependencies: Market demand and trust; standard interfaces to eval harnesses; liability and reproducibility agreements.
- Standards and policy frameworks for multilingual AI evaluation
- Sectors: Policy, standards bodies, procurement, accreditation
- What: Codify requirements for translating and validating benchmarks (e.g., joint Q&A translation, leakage checks, judge protocols).
- Tools/Workflows: Reference profiles for T-RANK/USI; audit templates; compliance test packs for vendor evaluations.
- Assumptions/Dependencies: Multi-stakeholder consensus; evidence on judge bias mitigation; compatibility with procurement rules.
- Domain-specialized translation QA for regulated industries
- Sectors: Healthcare, finance, legal, critical infrastructure, energy
- What: Tailor prompts and ranking criteria to domain ontologies and risk profiles; ensure no semantic drift in high-stakes content.
- Tools/Workflows: Lexicon-aware prompts; terminology consistency checkers; human-in-the-loop escalation for flagged items.
- Assumptions/Dependencies: Access to domain experts; validation datasets; regulatory review/approval cycles.
- Real-time adaptive translation for user-facing assistants
- Sectors: Consumer AI, support automation, education
- What: Apply lightweight USI/T-RANK variants on-device or at edge for on-the-fly refinement of responses in target languages.
- Tools/Workflows: Low-latency sampling + ranking; caching and incremental refinement; preference learning for users/locales.
- Assumptions/Dependencies: Efficient inference; compact judge models; acceptable latency/compute envelope on devices.
- Cross-lingual fairness auditing and bias mitigation
- Sectors: AI ethics, governance, public-sector AI adoption
- What: Use consistent, high-quality multilingual benchmarks to detect performance gaps and culturally induced errors across languages.
- Tools/Workflows: Differential eval pipelines; subgroup analyses; automatic detection of answer leakage and cultural mismatches.
- Assumptions/Dependencies: Agreement on fairness metrics; coverage across underrepresented languages; integration with risk frameworks.
- Multimodal and multi-turn benchmark translation
- Sectors: Robotics, accessibility tech, multimodal assistants
- What: Extend methods to dialogue and multimodal tasks (images/audio with captions/prompts), preserving cross-turn and cross-modal coherence.
- Tools/Workflows: Conversation-aware ranking; alignment checks across modalities; human-in-the-loop for ambiguous cases.
- Assumptions/Dependencies: Strong multimodal LLMs; new evaluation metrics beyond COMET; dataset licensing for modalities.
- Public-sector exam and credential localization at scale
- Sectors: Civil service, education ministries, licensing bodies
- What: Large-scale, secure pipelines for localizing standardized tests with controlled difficulty equivalence across languages.
- Tools/Workflows: T-RANK with multi-round bias mitigation; psychometrics-informed calibration; audit trails for legal defensibility.
- Assumptions/Dependencies: Policy acceptance; psychometric validation budgets; stringent security and privacy controls.
- MT system enhancement via structured candidate fusion/ranking
- Sectors: MT providers, content platforms
- What: Integrate USI/T-RANK as a structured re-ranking/fusion layer across diverse MT engines and prompts to boost quality in difficult language pairs.
- Tools/Workflows: Multi-engine candidate generation; evaluator ensembles; domain-adaptive criteria weighting.
- Assumptions/Dependencies: Cross-engine interoperability; latency/cost constraints; continuous evaluation to avoid regressions.
- Personalized learning content generation across languages
- Sectors: Edtech, MOOCs, corporate L&D
- What: Generate and translate quizzes, explanations, and feedback per learner language/level while preserving pedagogy and difficulty.
- Tools/Workflows: Template-aware prompts; constraint checks (e.g., avoid clues via morphology); adaptive sampling intensity for complex items.
- Assumptions/Dependencies: Learner modeling data; pedagogical validation; moderation for cultural appropriateness.
Notes on feasibility and risks across applications:
- Dependency on LLM quality: Results depend on access to strong models (closed or open). Performance may degrade on low-resource languages or weaker judges.
- Bias and positional effects: Even with T-RANK, judge bias persists; multi-round strategies help but don’t eliminate it. Human audits remain important for high-stakes use.
- Metrics limitations: COMET/QE and LLM-as-a-judge can disagree with human preferences; triangulate with human evaluation for critical domains.
- Costs and latency: Test-time scaling increases inference calls; difficulty-aware routing and batching are needed for production.
- Legal/ethical constraints: Ensure rights to translate content; comply with data protection and regulatory requirements; document known limitations and QA results.
Glossary
- Adaptive Few-shot Prompting (AFSP): A translation prompting framework that dynamically selects semantically similar few-shot examples to reduce prompt sensitivity and improve output quality. "The Adaptive Few-shot Prompting (AFSP) framework addresses prompt sensitivity in machine translation by dynamically selecting suitable translation demonstrations."
- ARC: The AI2 Reasoning Challenge, a benchmark of challenging science question-answering tasks used to evaluate reasoning in LLMs. "We translate MMLU, Hellaswag, ARC, and Winogrande into Ukrainian, Romanian, Slovak, Lithuanian, Bulgarian, Turkish, Greek and Estonian."
- Best-of-N sampling: A test-time strategy that generates multiple candidate translations and selects the highest-quality one based on predefined criteria. "Best-of-N Sampling: This method generates multiple translation outputs and selects the best one based on predefined criteria."
- BLEU: A traditional machine translation metric based on n-gram overlap between candidate and reference translations. "demonstrating higher correlation with human judgments than traditional metrics like BLEU or chrF++"
- chrF++: A character n-gram F-score metric for machine translation that often correlates better than word-based metrics in certain settings. "demonstrating higher correlation with human judgments than traditional metrics like BLEU or chrF++"
- COMET: A neural machine translation evaluation metric that compares source, hypothesis, and reference and correlates strongly with human judgments. "We evaluate our proposed methods on English-Ukrainian translation using the COMET (Crosslingual Optimized Metric for Evaluation of Translation) metric."
- FLORES: A multilingual machine translation benchmark with professionally translated sentences enabling many-to-many evaluation across numerous languages. "FLORES. The FLORES benchmark evaluates machine translation systems across multilingual scenarios."
- Fusion-of-N: A method that synthesizes strengths from multiple candidate translations into a single output, often guided by an LLM judge. "Fusion-of-N synthesizes the most informative elements from multiple candidates into a single final output."
- Global-MMLU: A project translating the MMLU benchmark into many languages, combining machine translation with limited human verification for multilingual evaluation. "The Global-MMLU project represents a substantial effort to advance multilingual evaluation by translating the MMLU benchmark into 42 languages."
- Hellaswag: A commonsense reasoning benchmark with adversarial sentence completion tasks used to test LLM understanding. "We translate MMLU, Hellaswag, ARC, and Winogrande into Ukrainian, Romanian, Slovak, Lithuanian, Bulgarian, Turkish, Greek and Estonian."
- LLM-as-a-judge: An evaluation paradigm where an LLM assesses and ranks outputs (e.g., translations), serving as an automated judge. "Evaluations using both reference-based metrics and LLM-as-a-judge show that our translations surpass existing resources, resulting in more accurate downstream model assessment."
- MuBench: A large multilingual benchmark collection with 3.9M samples translated into 61 languages via an automated pipeline and quality checks. "A prominent example is the MuBench benchmark dataset introduced by \citet{han2025mubenchassessmentmultilingualcapabilities}, comprising widely used benchmarks (Hellaswag \citep{zellers2019hellaswagmachinereallyfinish}, ARC \citep{clark2018thinksolvedquestionanswering}, Winogrande \citep{sakaguchi2019winograndeadversarialwinogradschema}, MMLU \citep{hendrycks2021measuringmassivemultitasklanguage}, and others) translated into 61 languages with 3.9M samples."
- Okapi: A multilingual instruction-tuning framework that combines supervised fine-tuning with RLHF to align outputs with human preferences. "The Okapi framework \citep{lai2023okapi} introduces a novel approach to multilingual instruction tuning by leveraging Reinforcement Learning from Human Feedback (RLHF)."
- Positional bias: An evaluation bias where LLM judges favor candidates presented earlier, potentially skewing ranking results. "One notable issue is positional bias: LLMs tend to assign higher scores to candidates presented earlier in the sequence..."
- Quality Estimation (QE): Reference-free assessment of translation quality using learned models or metrics without gold-standard references. "such as Quality Estimation (QE) or reference-free machine translation evaluation."
- Reinforcement Learning from Human Feedback (RLHF): A training approach that optimizes model behavior using human preference signals incorporated via reinforcement learning. "Unlike traditional methods relying solely on supervised fine-tuning (SFT), Okapi combines SFT with RLHF to align model outputs more closely with human preferences across diverse languages."
- Self-Check (SC): A lightweight translation method where the LLM performs a zero-shot translation and optionally evaluates and corrects its own output. "SC (Self-Check): 0-shot simple translation with optional additional check from another judge LLM."
- Supervised Fine-Tuning (SFT): Training a model on labeled data to improve performance on target tasks, often preceding or complementing RLHF. "Unlike traditional methods relying solely on supervised fine-tuning (SFT), Okapi combines SFT with RLHF to align model outputs more closely with human preferences across diverse languages."
- Temperature (sampling): A generation parameter controlling randomness; higher temperatures produce more diverse candidate translations at inference. "Recent work shows that sampling multiple translation candidates at higher temperatures enhances translation quality, with test-time scaling methods like Best-of-N \citep{stiennon2020learning} and Fusion-of-N \citep{khairi2025makingtakingbestn} demonstrating improved performance across multilingual domains."
- Test-time compute scaling: Inference-time strategies (e.g., sampling, ranking, fusion) that increase computation to improve output quality without additional training. "We demonstrate that adapting test-time compute scaling strategies, specifically Universal Self-Improvement (USI) and our proposed multi-round ranking method, T-RANK, allows for significantly higher quality outputs compared to traditional pipelines."
- Translation Ranking (T-RANK): A multi-round competitive ranking approach that evaluates and refines candidate translations while mitigating positional bias. "our newly proposed Translation Ranking (T-RANK), which employs multi-prompt candidate sampling and multi-round competitive ranking to enhance error detection and achieve superior translation quality."
- Universal Self-Consistency (USC): A method where an LLM selects the most consistent answer among several candidates, improving open-ended generation tasks. "Universal Self-Consistency (USC) extends the concept of self-consistency by enabling LLMs to select the most consistent answer among multiple candidates without relying on answer extraction processes."
- Universal Self-Improvement (USI): A translation-specific self-refinement method that combines multiple candidates into a higher-quality output based on criteria. "Universal Self-Improvement (USI). Building on Universal Self-Consistency and Fusion-of-N, this method operates on the principle that the most consistent translation is not necessarily the best."
- Winogrande: An adversarial Winograd Schema benchmark for commonsense reasoning via pronoun resolution and sentence completion. "We translate MMLU, Hellaswag, ARC, and Winogrande into Ukrainian, Romanian, Slovak, Lithuanian, Bulgarian, Turkish, Greek and Estonian."
- WMT24++: A comprehensive machine translation benchmark covering 55 languages and multiple domains with human references and post-edits. "Results from the WMT24++ benchmark \citep{deutsch2025wmt24pp} further corroborate the efficacy of these methodologies, demonstrating that state-of-the-art LLMs outperform traditional machine translation tools across various language pairs."
Collections
Sign up for free to add this paper to one or more collections.