Contextual Memory Virtualisation: DAG-Based State Management and Structurally Lossless Trimming for LLM Agents
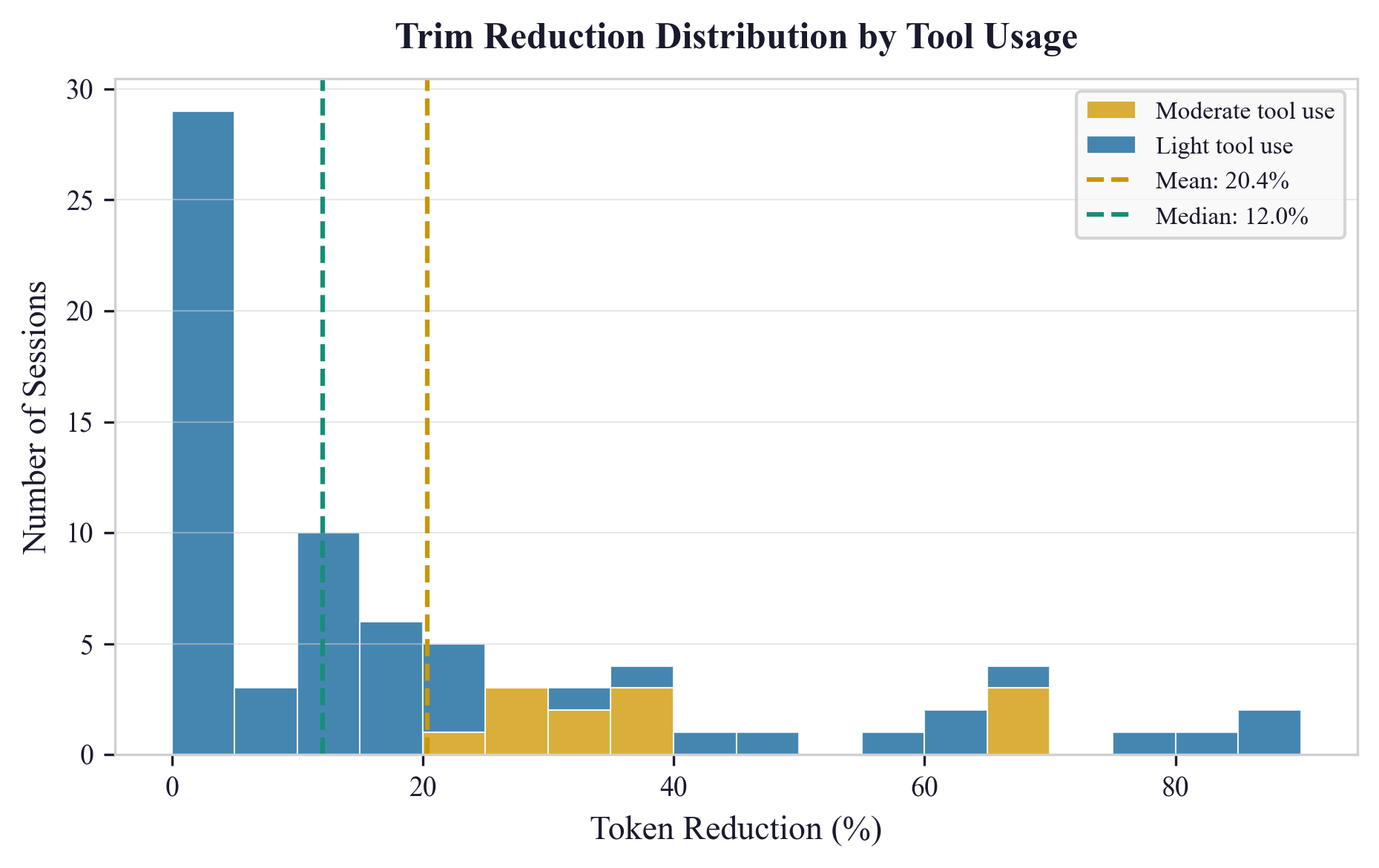
Abstract: As LLMs engage in extended reasoning tasks, they accumulate significant state -- architectural mappings, trade-off decisions, codebase conventions -- within the context window. This understanding is lost when sessions reach context limits and undergo lossy compaction. We propose Contextual Memory Virtualisation (CMV), a system that treats accumulated LLM understanding as version-controlled state. Borrowing from operating system virtual memory, CMV models session history as a Directed Acyclic Graph (DAG) with formally defined snapshot, branch, and trim primitives that enable context reuse across independent parallel sessions. We introduce a three-pass structurally lossless trimming algorithm that preserves every user message and assistant response verbatim while reducing token counts by a mean of 20% and up to 86% for sessions with significant overhead by stripping mechanical bloat such as raw tool outputs, base64 images, and metadata. A single-user case-study evaluation across 76 real-world coding sessions demonstrates that trimming remains economically viable under prompt caching, with the strongest gains in mixed tool-use sessions, which average 39% reduction and reach break-even within 10 turns. A reference implementation is available at https://github.com/CosmoNaught/claude-code-cmv.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper tackles a common problem when using coding assistants powered by LLMs: during long work sessions, the model builds up a lot of useful understanding about your project (how the code is organized, decisions you made, naming rules, and more). But once the “context window” fills up, most systems compress that history into a tiny summary, throwing away the rich details. The authors propose a new system called Contextual Memory Virtualisation (CMV) that treats this growing understanding like save points in version control (think Git). CMV lets you save, branch, and reuse full conversation history across sessions, and it also includes a safe way to shrink the size of your saved history without losing the actual conversation.
Goals and questions (in simple terms)
The paper asks:
- How can we stop losing hard-earned understanding when a long LLM session hits its memory limit?
- Can we save and reuse that understanding across multiple new tasks, like branching from a Git commit?
- Can we safely shrink “mechanical bloat” (like giant tool outputs or pasted images) while keeping every user and assistant message intact?
- Is this approach worth it economically, especially with caching systems that make repeated prompts cheaper?
How it works: the approach in everyday language
The “virtual memory” idea, but for conversations
Computers hide limited RAM by “paging” to disk, making it seem like there’s more memory. CMV does something similar for LLMs: it saves full conversation histories as snapshots you can reload later, so you don’t have to rebuild the model’s mental picture from scratch each time.
A DAG of snapshots (think: Git for chat)
CMV organizes conversation history as a Directed Acyclic Graph (DAG), which you can imagine like a family tree or Git history:
- A “snapshot” is a save point of your entire conversation at a moment in time.
- You can “branch” from any snapshot to start a new session that inherits all the prior understanding.
- Over time, you get a tree of related sessions, each building on the last without losing earlier context.
Core operations (analogous to Git actions):
- Snapshot: Save the current conversation exactly as it is.
- Branch: Start a new session from a snapshot (optionally “trimmed” to be smaller).
- Trim: Save, shrink, and start fresh in one step.
- Tree: Show the history graph so you can see where branches came from.
“Structurally lossless” trimming
The biggest space hog in long sessions isn’t the back-and-forth talk—it’s “mechanical bloat”: huge tool outputs, base64 images, file-history logs, and metadata. CMV’s trimmer removes or stubs these heavy parts but keeps every single user message, assistant reply, and tool call intact. If the model needs a large file again later, it can just re-read it.
The trimming algorithm runs in three passes:
- Find the last place the platform did its own compaction (a boundary), so anything before that (which is already summarized) can be skipped.
- Collect IDs of tool calls that happened before the boundary (you’ll need these to spot mismatches).
- Stream through the rest and apply rules:
- Remove pre-boundary content (it’s already summarized).
- Strip images and non-essential metadata.
- Replace very large tool results or write-tool inputs with short “[Trimmed: ~N chars]” stubs.
- Remove “thinking” blocks that can’t be safely reused across sessions.
- Fix “orphaned tool results” (cases where a tool result no longer matches a tool call because the call was before the boundary) to keep the chat log valid for the API.
Key promise: The conversation stays intact. You keep all the words you and the assistant wrote, plus the assistant’s reasoning summaries. Only bulky, mechanical stuff gets reduced.
Why the “orphan” fix matters
APIs usually require that every tool result matches a previous tool call. When trimming, it’s easy to accidentally keep a tool result while removing its matching call. CMV detects and discards these orphaned results so your trimmed session still loads correctly.
Checking the economics (is it worth it?)
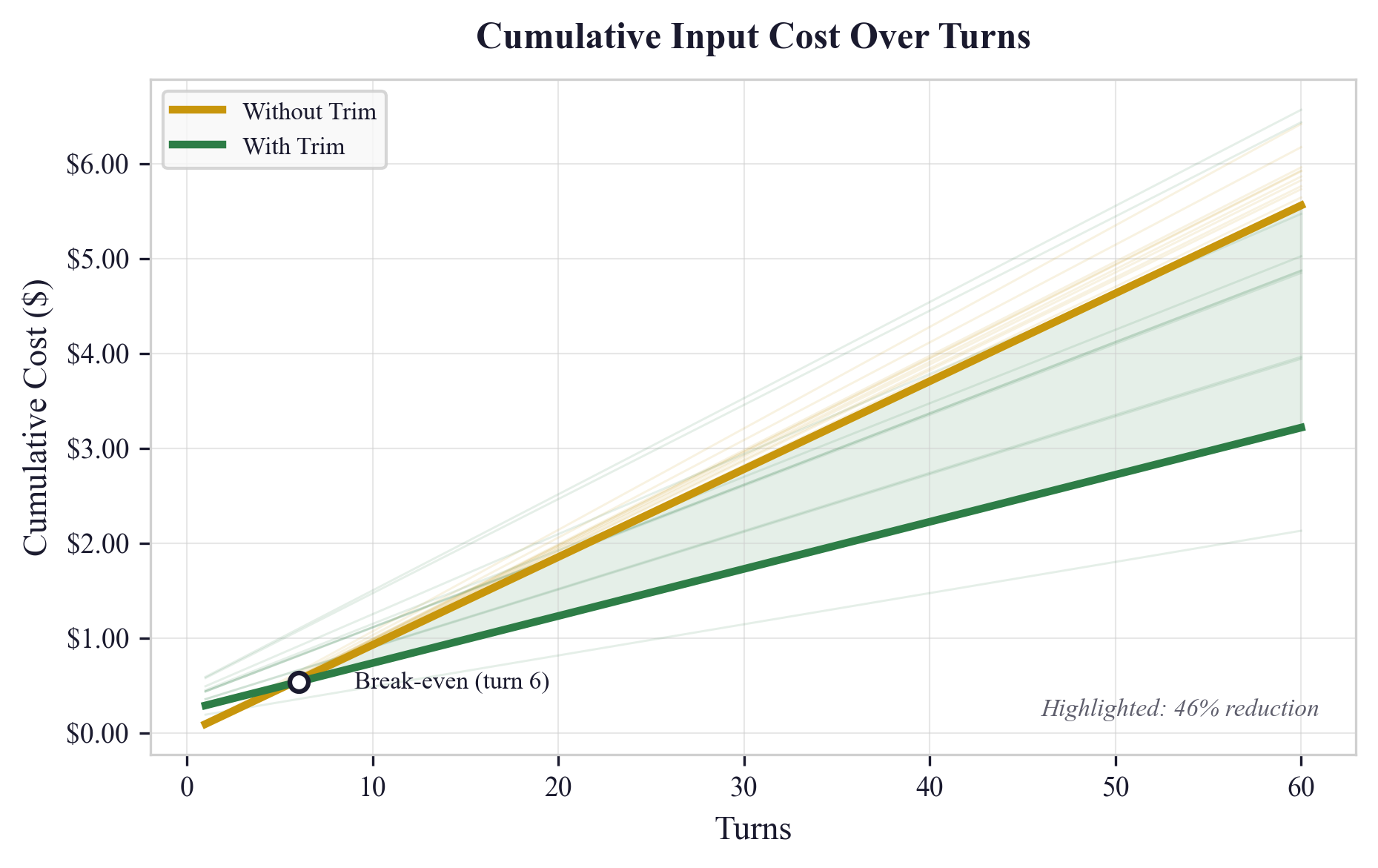
Many LLMs use “prompt caching,” which makes repeated prefixes cheaper. Trimming changes the prefix, causing a one-time cache miss (slightly more expensive) on the first turn—but after that, each turn is cheaper because the prompt is smaller. The authors measure when the savings catch up (the “break-even”).
What they found (results and why they matter)
From 76 real coding sessions:
- Token reduction: On average, trimming reduced tokens by about 20%, and up to 86% for sessions with lots of tool output and metadata.
- Session types:
- “Mixed” sessions (with lots of tool output) saw the biggest gains: about 39% reduction on average.
- Purely conversational sessions saw smaller gains (about 17%).
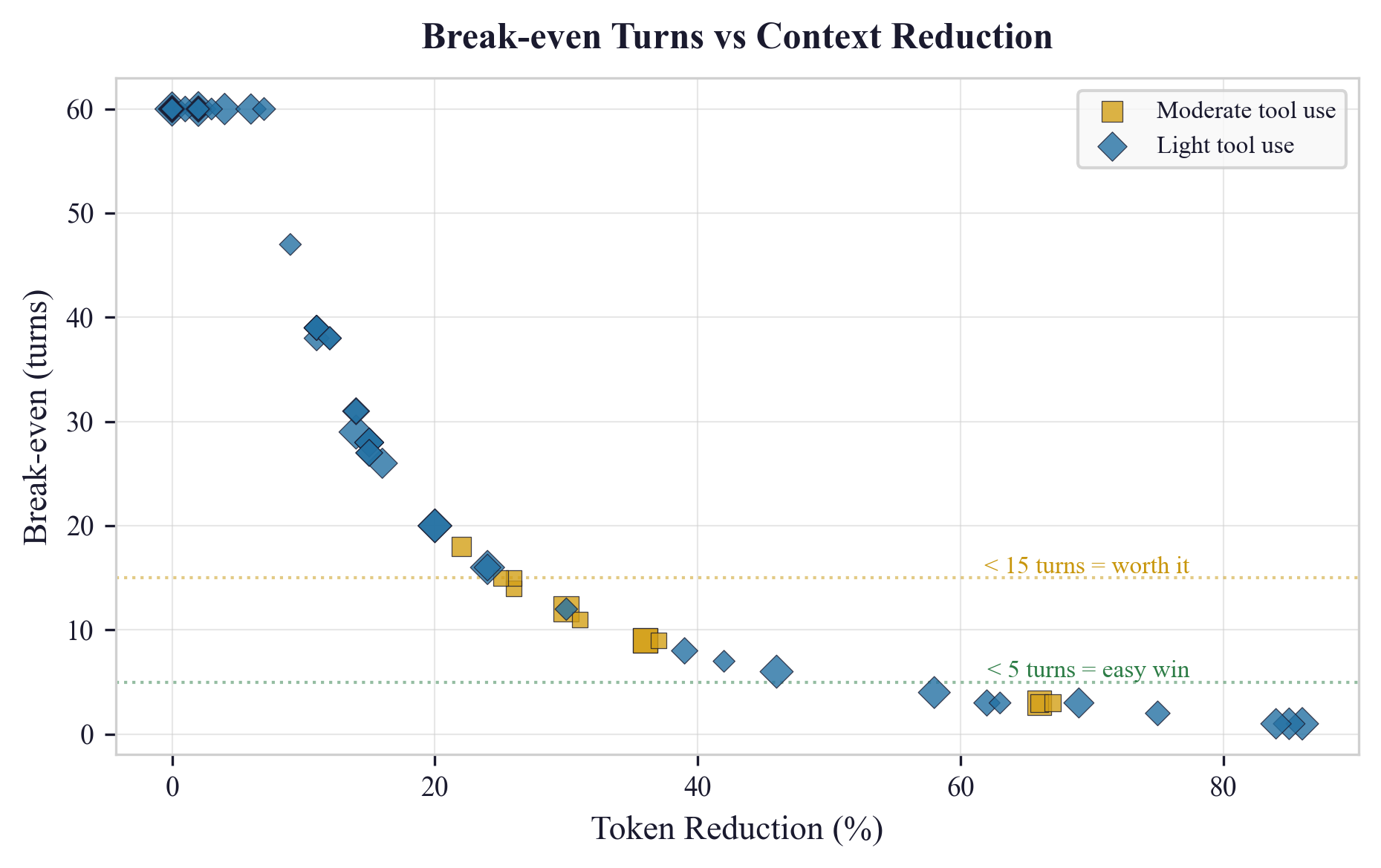
- Break-even with caching:
- Mixed sessions typically recover the one-time cache penalty within about 10 turns.
- Overall, the average break-even was around 35 turns; median about 38 turns (some sessions don’t benefit much if there’s little to trim).
- The biggest real-world win: You can start new work from a saved snapshot instead of rebuilding context. That avoids rereading files and re-explaining decisions, which otherwise takes many turns and lots of time.
Why this matters:
- You stop throwing away your model’s understanding every time the context window fills.
- You can branch into new tasks (like “performance tuning” vs “auth refactor”) from a rich, shared starting point.
- You save tokens and time, especially in tool-heavy workflows.
What this means going forward
Implications
- Treating chat history like version-controlled code unlocks better workflows: save points, branches, and shared starting contexts across different tasks or teammates.
- Trimming at the “structure” level (not changing your words—just removing bulky extras) plays nicely with other techniques like RAG or model-level compression. They can be used together.
- Even before LLMs get bigger context windows, we can use CMV to make current tools feel faster, cheaper, and more reliable across long projects.
Limitations and future work
- Trimming is “structural,” not “semantic.” It doesn’t decide which content is important to reasoning; it just removes big, mechanical chunks. If you really needed a large file dump later, the model has to fetch it again.
- Results come from one power user’s coding sessions; more diverse testing would be helpful.
- The authors suggest this should be built into future “agent operating systems,” where persistent conversational memory is a first-class feature.
In one sentence
CMV turns your LLM’s conversation history into reusable, branchable save points and safely trims away bulky extras—so you keep the important understanding, cut the waste, and stop paying to rebuild the same context over and over.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps, limitations, and open questions that the paper leaves unresolved, intended to guide future research and implementation work.
- Absence of merge semantics in the DAG model: the paper alludes to future merge primitives but provides no design, conflict-resolution policy, or correctness guarantees for merging divergent conversational states.
- One-parent lineage assumption: the current “directed tree” discipline disallows multi-parent nodes; it is unclear how multi-source context (true DAG merges) would be modeled without introducing cycles or incoherent state.
- Consistency across branches: no method is specified to detect, prevent, or reconcile “branch drift” when branches evolve incompatible assumptions or codebase conventions over time.
- Staleness and invalidation: snapshot validity under changing external artifacts (codebase changes, environment updates, databases) is not addressed; no mechanism is proposed for detecting or invalidating stale conversational state.
- Semantic impact of trimming: the paper does not quantify how removing tool results, images, and thinking blocks affects downstream reasoning accuracy, hallucination rates, error recovery, or task success.
- Chain-of-thought (“thinking block”) removal effects: removing signed thinking blocks may change agent behavior; there is no measurement of accuracy, plan quality, or latency trade-offs when these blocks are stripped.
- Orphan handling robustness: the orphaned tool result detection relies on pre-boundary tool_use IDs; the approach is untested across APIs that reuse IDs, mutate schemas, or reorder messages.
- Compaction boundary detection reliability: String.includes-based detection may miss atypical compaction markers or vendor-specific variants; false negatives/positives and multi-boundary sessions are not analyzed.
- Multi-vendor generalization: trimming, boundary detection, and tool schema assumptions are tailored to Claude Code; compatibility and portability across OpenAI, Google, Mistral, local tool-use frameworks, and custom agents remain unvalidated.
- Multi-modal handling variations: removing base64 images assumes fixed vision-token costs; generalization to other multimodal encodings (PDFs, audio, video, images with OCR) and pricing schemes is not explored.
- Tool re-read overhead: the claim “if needed, the model re-reads the file” is not costed; the frequency, latency, and token/tool-cost of re-reads induced by trimming are not measured.
- Economic model realism: the cache hit rate (h=0.9) and chars/4 tokenizer heuristic are assumed, not empirically verified per session; sensitivity analysis to realistic, variable hit rates and accurate tokenizers is missing.
- Missing output-token and tool-call costs: the cost analysis focuses on input tokens and prompt caching, ignoring output tokens, tool executions, and external API costs induced by re-reads or longer reasoning chains.
- Latency and user experience: break-even is computed in dollars and turns but not in wall-clock latency or productivity; trimming’s impact on responsiveness, perceived flow, and error recovery is unmeasured.
- Controlled task-level evaluation: there is no experiment comparing trimmed vs. untrimmed branches on identical follow-up tasks with metrics like success rate, code correctness, bug count, or time-to-completion.
- Cross-domain generalization: results are based on 76 coding sessions from a single user; applicability to non-coding tasks (analysis, writing, research planning, customer support) is untested.
- Single-user bias: the evaluation lacks multi-user, multi-team usage patterns (different coding styles, codebase sizes, tool ecosystems), collaboration dynamics, and access-control constraints.
- Storage, indexing, and GC: snapshot proliferation raises storage cost, deduplication needs, indexing/searchability of conversation state, and garbage-collection policies; none are specified or evaluated.
- Security and privacy: persistent logs may contain secrets or sensitive data; encryption at rest, access controls, redaction policies, and compliance (e.g., GDPR, SOC2) for CMV state are not addressed.
- API correctness beyond orphans: removal of “API usage metadata” could impair reproducibility or auditability; criteria for safe metadata stripping across heterogeneous schemas are not codified.
- Adaptive trimming policies: fixed character thresholds and type-based rules are “blind”; there is no mechanism to learn which tool outputs are semantically important and retain them selectively.
- Semantics-aware trimming: the paper avoids model-in-the-loop compression; an open question is how to combine structural trimming with light semantic assessment (e.g., extract critical lines, checksums, or embeddings).
- Integration with RAG and vector stores: how CMV snapshots interact with retrieval pipelines (e.g., indexing assistant summaries and decisions for future augmentation) is unexplored.
- Snapshot orientation messages: the effect of prepended orientation prompts on agent behavior and prompt-cache keys (and hit rates) is not measured or standardized.
- Multi-compaction sessions: handling multiple autocompaction events and deciding which pre-boundary segments to skip (e.g., keep last, keep none, keep all) lacks empirical guidance.
- Vendor-specific “thinking” signatures: the cryptographic signature portability issue is identified but not addressed; whether signatures can be stripped/converted safely without behavioral regressions is unknown.
- Formal guarantees of “structurally lossless”: the paper claims all user and assistant messages are preserved verbatim while removing thinking blocks—this is a contradiction that needs a precise, formal definition of what “assistant response” includes.
- DAG operations completeness: beyond snapshot, branch, trim, and tree visualization, essential VCS-like operations (merge, rebase, squash, tag, diff, cherry-pick) and their semantics are not defined.
- Conflict detection: there is no mechanism for detecting conflicting decisions across branches (e.g., different architectural choices) before reusing or merging context.
- Tool schema evolution: schemas may change over time; versioned handling, migration strategies, and backward compatibility for stored snapshots are not discussed.
- Determinism and reproducibility: no guarantees that reloading a snapshot reproduces the same agent behavior (model versions, system prompts, tool versions, environment states could differ).
- Prompt-cache interplay: trimming invalidates caches; strategies for cache-friendly trimming (e.g., stable prefix segments, segment-level caching) are not explored.
- UI/UX and workflow integration: how CMV fits into developer workflows (naming snapshots, browsing DAGs, branch hygiene, orientation design) is not studied or user-tested.
- Monitoring and observability: metrics, alerts, and dashboards for CMV operations (trim success, orphan counts, cache hits, re-read frequency, cost savings) are not specified.
- Failure modes: recovery procedures for malformed logs, partial writes, concurrency races, or API schema mismatches during trim/branch operations are undefined.
- Policy for images and rich artifacts: unconditional image stripping may remove critical diagrams or screenshots; criteria to retain certain images (e.g., design diagrams) are not defined.
- Licensing and governance: team-sharing of snapshots raises IP ownership and licensing questions (e.g., cross-project reuse of conversational state) that are not considered.
- Benchmark transparency: the public repository provides an implementation, but a reproducible benchmark harness (datasets, scripts, tokenizers, model configs) to replicate figures is not provided.
- Formal cost equations: the paper’s cost equations contain typographical errors and lack empirical validation against real cache logs; a corrected, validated model is needed.
- Interaction with agent OS architectures: concrete APIs, data models, and contracts for integrating CMV as a first-class subsystem in AIOS-like architectures remain to be specified and tested.
Practical Applications
Immediate Applications
Below are actionable, near-term uses of CMV that can be deployed with existing LLM tooling and infrastructure.
- Software/DevOps (LLM coding agents): Git-like “Conversation State Manager” for Claude Code, Cursor, and VS Code extensions
- What: One-click Snapshot, Branch (with optional orientation message), Trim, and Tree visualization for long coding sessions; reuse base architectural understanding across multiple feature branches (e.g., auth, API refactor, performance tuning).
- Tools/Products/Workflows: IDE plugin or CLI; “session-tree” viewer; branch from a named snapshot; cache-aware trim command; per-branch saved orientation prompts.
- Dependencies/Assumptions: Access to JSONL conversation logs; tool-use/tool-result schemas with IDs; detectable compaction markers; storage for immutable snapshots; acceptable risk that raw tool outputs are trimmed and re-read as needed.
- Enterprise knowledge work (cross-sector): Team “Context Libraries” for onboarding and parallel workstreams
- What: Capture a high-quality session as a named snapshot (e.g., “Q2 Data Pipeline Architecture”) and let different teams branch into tasks (documentation, testing, migration) without re-building context.
- Tools/Products/Workflows: Shared snapshot registry with tags; role-based access; orientation message templates for common tasks (e.g., “Write the RFC from this snapshot”).
- Dependencies/Assumptions: Access control and audit logging; storage policies for sensitive content; team workflow conventions around snapshot naming and lineage.
- Customer Support/IT Ops: Escalation with state continuity
- What: Snapshot long customer threads; branch to Tier-2 analysis or specialized agents (billing, technical diagnosis) while preserving the full conversational context without repeating investigation.
- Tools/Products/Workflows: Helpdesk integration; “Escalate as branch” button; cost-optimized trimming before escalation; DAG lineage for audit.
- Dependencies/Assumptions: PII handling; policy-compliant retention; tool schemas if agents read logs/files; staff training on snapshot usage.
- Compliance, Audit, and e-Discovery (finance, legal, regulated industries): Immutable, lineage-tracked conversational records
- What: Treat assistant sessions as version-controlled artifacts; prove decision provenance via DAG lineage (who branched when, from what state) and preserve full user/assistant messages verbatim.
- Tools/Products/Workflows: WORM storage for snapshots; lineage reports; export to e-Discovery platforms; scheduled snapshots before major decisions.
- Dependencies/Assumptions: Organizational policies that permit storing assistant outputs; hashing/signature metadata for integrity; retention/expungement rules.
- Cost Optimization (API users): Cache-aware trimming service
- What: Automatically trim large sessions with mixed tool-use to reduce steady-state token costs under prompt caching; apply only when expected break-even is under a target turn threshold.
- Tools/Products/Workflows: “Trim now” recommendation banner; cost curves preview; policy to trim on >30% expected reduction; per-model price tables; post-trim cache hit monitoring.
- Dependencies/Assumptions: High cache hit rates (e.g., h≈0.9); accurate token estimation; vendor-specific pricing; ability to tolerate a one-turn cold-cache penalty.
- RAG + CMV (knowledge work): Hybrid retrieval and structurally lossless trimming
- What: Use CMV to preserve conversational synthesis while RAG re-fetches large raw documents when needed; reduce the window footprint without losing reasoning context.
- Tools/Products/Workflows: RAG connector that favors re-reading source files/docs post-trim; snapshot-based “context seeds”; per-branch retrieval policies.
- Dependencies/Assumptions: Reliable document access; clear tool invocation semantics; trust in assistant’s summaries remaining in the preserved messages.
- API Correctness Utility: Orphaned tool-result fixer
- What: A lightweight library that detects and removes orphaned tool_result blocks after compaction, ensuring sessions resume without schema validation errors.
- Tools/Products/Workflows: SDKs for major agent platforms; CI checks on exported sessions; pre-submit validation step.
- Dependencies/Assumptions: Tool-use IDs available; consistent compaction behaviors; downstream APIs enforcing tool-result pairing.
- Education: Reusable “Course Base Snapshot” for tutoring and assignment variants
- What: Build a canonical course/project context once (e.g., “Intro Microservice Project”), then branch for labs, assignments, and personalized tutoring without re-explaining conventions.
- Tools/Products/Workflows: LMS integration; instructor-curated snapshot registry; per-student branches; orientation messages aligned to learning objectives.
- Dependencies/Assumptions: Student privacy; institutional storage; consistent assistant behavior across branches.
- Daily Life (personal assistants): Multi-threaded task management without re-explaining projects
- What: Create project snapshots (e.g., “Home Renovation Plan”) and branch for permits, vendor outreach, budget tracking; trim to keep costs low and windows comfortable.
- Tools/Products/Workflows: Mobile/desktop assistant with “Start branch” and “Trim branch” actions; tree view of project threads.
- Dependencies/Assumptions: Local encrypted storage; device sync; risk acceptance for trimming raw artifacts that can be re-fetched.
- Healthcare (clinical support pilots): Multi-day case continuity with controlled trimming
- What: Preserve longitudinal reasoning across consults; branch into subproblems (medication plan, imaging interpretation) while maintaining patient context.
- Tools/Products/Workflows: EHR-adjacent snapshot service; strict access controls; per-branch orientation messages that scope the clinical question.
- Dependencies/Assumptions: Regulatory compliance (HIPAA/GDPR); de-identification or on-prem deployment; clear boundaries for trimming nonessential artifacts.
- Finance/Research: Persistent analytical contexts for portfolio and risk investigations
- What: Snapshot of market model setup and conventions; branch into individual analyses (earnings, stress tests) without re-deriving baseline assumptions.
- Tools/Products/Workflows: Snapshot registry tagged by sector/theme; trim tool outputs; cost dashboards; lineage attached to reports.
- Dependencies/Assumptions: Data governance; confidentiality; retrievability of raw data via tools or APIs after trimming.
Long-Term Applications
These opportunities require further research, scaling, standardization, or vendor support before broad deployment.
- Agent OS Integration (AIOS-style): Kernel-level persistent conversational state service
- What: Make snapshots, branching, trimming, lineage, and access control first-class OS services for agent runtimes, not userland utilities.
- Tools/Products/Workflows: Agent OS subsystems for memory virtualization; system calls for snapshot/branch/merge; unified monitoring.
- Dependencies/Assumptions: Vendor adoption; cross-platform abstractions; performance and security engineering at the runtime layer.
- Merge Primitives and Conflict Resolution for Context DAGs
- What: Safely merge branches (e.g., two task threads) while preserving consistency; detect and reconcile conflicting conventions or instructions.
- Tools/Products/Workflows: “Context diff” and “context merge” tools; merge policies; human-in-the-loop review UIs.
- Dependencies/Assumptions: Semantics-aware models; heuristics for prioritizing instructions; evaluation frameworks for merged context integrity.
- Semantic-Aware Trimming (learned policies)
- What: Move beyond structural rules to model-informed selection of what to keep vs. stub, optimizing downstream reasoning quality.
- Tools/Products/Workflows: In-context autoencoders; importance estimators; task-aware trim profiles; offline training on task outcomes.
- Dependencies/Assumptions: Training data linking trim decisions to success metrics; safety constraints to avoid dropping critical evidence; domain-specific tuning.
- Cross-Model and Cross-Vendor Portability
- What: Standardize conversation log schemas and tool-use conventions to move snapshots/branches between agents (e.g., Claude, OpenAI, Mistral).
- Tools/Products/Workflows: Open spec for “Persistent Conversational State”; converters; validation suites.
- Dependencies/Assumptions: Industry standards; buy-in from major providers; mappings for tool schemas and compaction markers.
- Multi-User Collaboration, Access Control, and Governance
- What: Fine-grained permissions on snapshots and branches; lineage-aware sharing across teams with audit trails and retention policies.
- Tools/Products/Workflows: RBAC/ABAC; org-level policy engines; governed snapshot lifecycle (create, share, archive, purge).
- Dependencies/Assumptions: Identity integration (SSO); compliant storage; organizational change management.
- Privacy and Security Enhancements
- What: Encryption-at-rest for snapshots; integrity signatures; differential privacy-aware trimming; secure key management.
- Tools/Products/Workflows: KMS integration; signed lineage proofs; privacy-preserving trim stubs.
- Dependencies/Assumptions: Security architecture investment; compliance audits; cryptographic libraries.
- Long-Horizon Robotics and Autonomy
- What: Memory virtualization across episodes for planning and maintenance tasks; branching for sub-goals with persistent procedural context.
- Tools/Products/Workflows: ROS/robot stack adapters; tool schemas for sensor/log reads; DAG lineage for mission reports.
- Dependencies/Assumptions: Robust tool-call APIs in robotics stacks; safety assurance; offline/edge storage constraints.
- Healthcare at Scale: EHR Integration and Interoperability
- What: Persistent clinical conversation DAGs linked to episodes of care; branches for diagnostics, treatment planning, and follow-up.
- Tools/Products/Workflows: HL7/FHIR connectors; clinical lineage dashboards; merge policies for multidisciplinary notes.
- Dependencies/Assumptions: Vendor cooperation; stringent privacy controls; medical validation of trimming effects on reasoning.
- Education Platforms: Curriculum-Level “Memory DAGs”
- What: Course snapshots that evolve across cohorts; merge improvements; branch for personalized learning paths.
- Tools/Products/Workflows: LMS plugins; instructor merge approvals; analytics on branch outcomes.
- Dependencies/Assumptions: Institutional adoption; content licensing; fairness considerations.
- Cost-Aware Scheduling and Token Budgeting
- What: Runtime services that decide when to trim, snapshot, or branch based on expected break-even, workload horizon, and rate limits.
- Tools/Products/Workflows: Policy engines; simulation of cost curves; automated triggers.
- Dependencies/Assumptions: Accurate telemetry; predictable caching behavior; stable pricing.
- MLOps for LLMs: “Context CI/CD”
- What: Pipelines that test trimmed vs. untrimmed branches on benchmark tasks; gate deployments on reasoning quality and cost KPIs.
- Tools/Products/Workflows: CI steps for trim validation; regression tests; dashboards.
- Dependencies/Assumptions: Task suites; organizational KPIs; engineering investment.
- Knowledge Marketplace for Context Seeds
- What: Share/sell high-quality snapshots (“domain seeds”) that others can branch from for specialized analyses.
- Tools/Products/Workflows: Snapshot packaging; licensing; provenance tracking via DAG lineage.
- Dependencies/Assumptions: IP rights management; trust and reputation systems; cross-vendor portability.
Notes on feasibility across all items:
- Structural trimming assumes agents can re-read raw data on demand and that preserved assistant messages contain sufficient synthesized understanding.
- Break-even and cost benefits depend on high cache hit rates, accurate token estimation, and pricing models similar to those evaluated.
- Image-heavy sessions may not realize proportional savings due to fixed vision-token charges.
- Safety, privacy, and compliance constraints can limit snapshot storage and sharing, especially in healthcare and finance.
- Vendor APIs must expose (or be adapted to expose) conversation logs, tool-use/result IDs, and reliable compaction markers for robust adoption.
Glossary
- Agent-agnostic: Not tied to a specific agent framework; designed to work across different LLM agents and tooling. "agent-agnostic; any system that stores conversation logs and uses tool-call schemas can apply the same approach."
- API validation error: An error returned by an API when submitted data violates its required schema. "submitting a session containing these ``orphaned'' results causes an API validation error and the session cannot be resumed."
- Attention mechanism: The core operation in transformer LLMs that processes all tokens in the context with pairwise attention. "The attention mechanism underlying modern LLMs \citep{vaswani2017attention} processes all tokens in the context window with equal cost, making window size reduction valuable regardless of the method used."
- Autocompaction: Automatic summarization of accumulated conversation state to reclaim context space. "Autocompaction summarises 98\% of accumulated session state into a brief summary to reclaim window space."
- Base64 image blocks: Inline image data encoded in base64 within chat logs. "Base64 image blocks are removed unconditionally."
- Branch: A primitive that creates a new session derived from a snapshot, optionally after trimming. "Branch(, trim) : Given a snapshot , creates a new session with a fresh UUID."
- Break-even: The turn at which cumulative cost savings from trimming equal or exceed the initial cache miss penalty. "Break-even occurs at turn , where turn~1 is the initial cold-cache turn:"
- Cache hit rate: The proportion of requests served from a previously stored prompt cache. "For a cache hit rate , the steady-state cost per turn at token count is:"
- Cold-cache penalty: The higher cost incurred on the first turn after trimming due to cache invalidation. "The first turn after a trim incurs a cold-cache penalty at the full write rate:"
- Compaction boundary: The point in a conversation where native compaction summarized prior content. "Pass~1 uses String.includes() on raw lines to detect potential compaction boundaries without parsing JSON on every line"
- Compaction marker: A string pattern indicating the presence of a compaction boundary. "String.includes() matches compaction markers"
- Context window: The maximum sequence of tokens an LLM processes at once for a given prompt. "abstracts away the strict physical token limits of the LLM context window."
- Contextual memory virtualisation (CMV): A system treating accumulated LLM session understanding as version-controlled state for reuse across sessions. "We propose contextual memory virtualisation (CMV), a system that treats accumulated LLM understanding as version-controlled state."
- Directed Acyclic Graph (DAG): A graph with directed edges and no cycles, used here to model session snapshots and branches. "models session history as a Directed Acyclic Graph (DAG) with formally defined snapshot, branch, and trim primitives"
- Directed tree: A directed acyclic structure where each node has a single parent, representing lineage without merges. "This branching structure forms a directed tree (a strict subclass of Directed Acyclic Graphs)."
- File-history-snapshot: Metadata entries capturing file history states in logs. "Metadata removal: file-history-snapshot and queue-operation entries are discarded."
- Immutable storage: Write-once storage ensuring snapshots cannot be altered after creation. "copies the JSONL conversation file to immutable storage"
- In-context autoencoder: A learned model that compresses and reconstructs context segments for LLMs. "an in-context autoencoder that learns to compress and reconstruct context segments."
- JSONL: JSON Lines format where each line is a standalone JSON object, used for conversation logs. "The trimmer processes JSONL-formatted conversation logs in three sequential passes"
- Lineage chain: The sequence of ancestor snapshots from which a given snapshot descends. "This induces a lineage chain: "
- Orphaned tool results: Tool outputs whose corresponding tool invocation is missing (e.g., trimmed), violating API schemas. "submitting a session containing these ``orphaned'' results causes an API validation error and the session cannot be resumed."
- OS-inspired paging: Applying operating system paging concepts to swap chunks of context in and out of the LLM window. "MemGPT \citep{packer2023memgpt} applies OS-inspired paging to swap context segments in and out of the window"
- Perplexity-guided token pruning: A compression method that removes tokens based on language-model perplexity signals. "LongLLMLingua \citep{jiang2023longllmlingua} accelerates inference by compressing long prompts via perplexity-guided token pruning."
- Prompt caching: Provider-side storage of prompt prefixes to reduce costs on repeated inputs. "Major LLM APIs implement prompt caching (e.g., \citealt{anthropic2024caching})."
- Prompt compression: Techniques that reduce prompt length while preserving essential information. "A separate line of work addresses context window pressure through prompt compression."
- Prompt prefix: The leading portion of a prompt that may be cached and reused. "If the prompt prefix matches a previously cached prefix, cached tokens are read at a reduced rate rather than reprocessed at the write rate."
- Queue-operation: Log metadata entries tracking queued operations in the agent environment. "file-history-snapshot and queue-operation entries are discarded."
- Retrieval-Augmented Generation (RAG): Enhancing prompts by retrieving relevant documents for the model to condition on. "Retrieval-Augmented Generation (RAG) \citep{lewis2020rag} augments prompts with retrieved documents but does not preserve conversational state."
- Snapshot: An immutable capture of a session’s conversation state at a point in time. "Snapshot() : Given a session , copies the JSONL conversation file to immutable storage and creates a new node with metadata."
- Steady-state cost: The per-turn cost once caching effects have stabilized. "the steady-state cost per turn at token count is:"
- Streaming algorithm: A single-pass or multi-pass method that processes data sequentially with limited memory. "We introduce a streaming algorithm that strips this mechanical overhead while preserving every user message and assistant response verbatim."
- Structurally lossless trimming: Removing mechanical overhead (e.g., tool dumps, images) without altering conversational content. "We introduce a three-pass structurally lossless trimming algorithm that preserves every user message and assistant response verbatim while reducing token counts"
- Stub threshold: The maximum size before large fields are replaced with a stub placeholder. "The stub threshold defaults to 500 characters (minimum 50) and is configurable per-operation."
- Thinking blocks: Special model reasoning segments requiring non-portable cryptographic signatures in some systems. "Thinking blocks require a cryptographic signature that is not portable across sessions and are removed entirely."
- Tool-call schemas: Formal API definitions for tool invocations and their results within agent frameworks. "uses tool-call schemas can apply the same approach."
- Tool invocation metadata: The structured information describing a tool request (e.g., tool name, arguments). "every tool request (the invocation metadata) is preserved verbatim."
- Tool result stubbing: Replacing large tool outputs with a short placeholder to reduce token usage. "The highest-reduction sessions (60--86\%) are driven primarily by pre-compaction history skipping rather than tool result stubbing"
- Tool-use APIs: Agent APIs that allow models to invoke external tools under a strict schema. "LLM tool-use APIs typically enforce a strict schema:"
- tool_use ID: The unique identifier linking a tool result to its corresponding tool invocation. "Pass~2 collects the set of all tool_use IDs from pre-boundary content."
- UUID: Universally Unique Identifier used to create distinct session identifiers. "creates a new session with a fresh UUID."
- Version-controlled state: Treating conversational context like code under version control, enabling snapshots and branches. "treats accumulated LLM understanding as version-controlled state."
- Vision-token cost: A fixed token accounting for processing images, independent of base64 size. "the API charges a fixed vision-token cost (1{,}600 tokens) independent of base64 encoding size"
- Write-oriented tools: Tools that modify content (e.g., file writes), whose large input fields are trimmed. "For write-oriented tools, large content, old_string, and new_string fields are stubbed."
Collections
Sign up for free to add this paper to one or more collections.