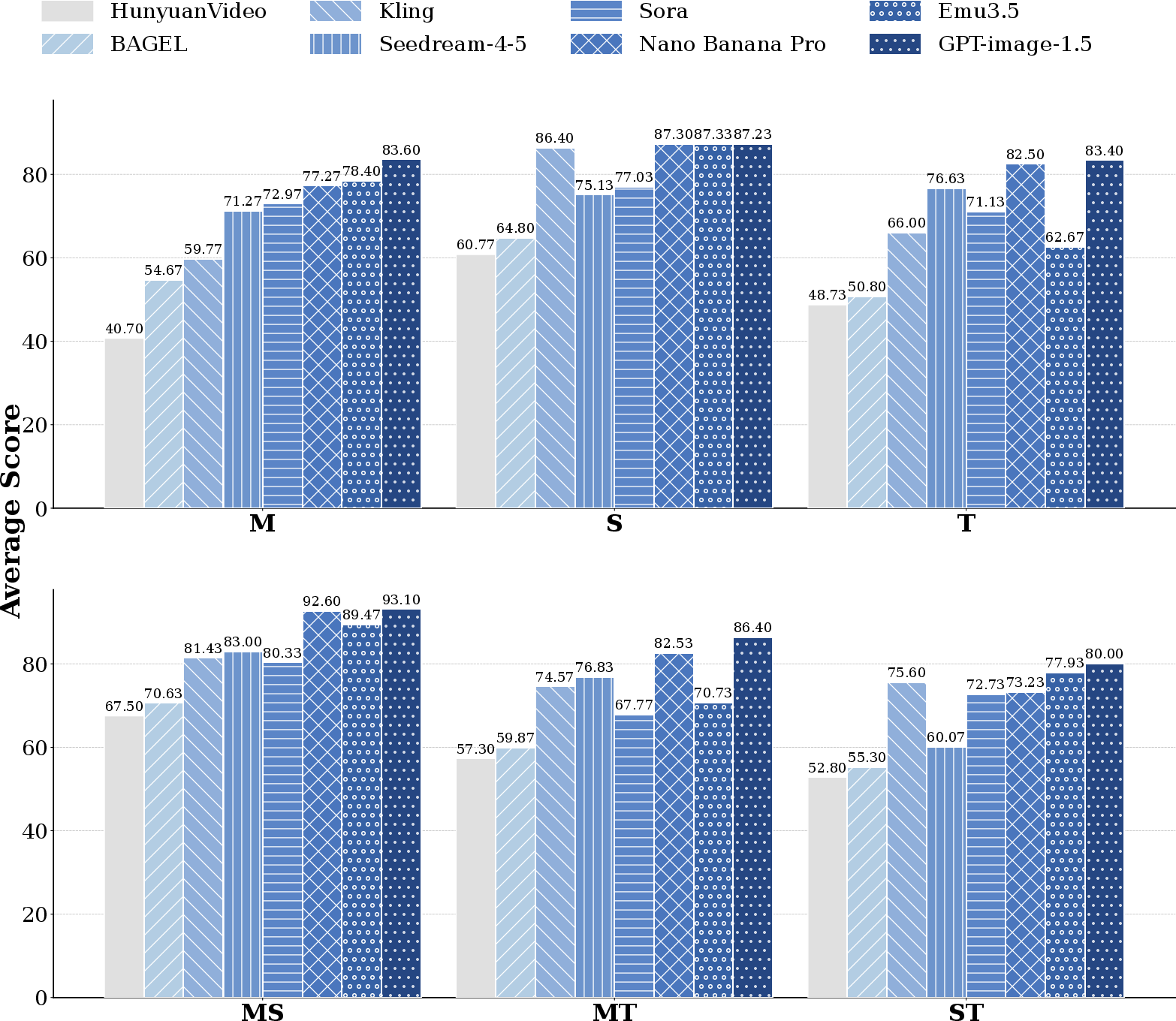
- The paper introduces the Trinity of Consistency by emphasizing joint modal, spatial, and temporal coherence as critical for general world models.
- It systematically examines failures in current generative systems and details the shift from specialized modules to unified multimodal architectures.
- It proposes CoW-Bench, a comprehensive benchmark that evaluates world model consistency through atomic checks across semantic, geometric, and causal dimensions.
The Trinity of Consistency as a Defining Principle for General World Models
Introduction and Motivation
This work introduces a formal, tripartite conceptual framework—the Trinity of Consistency—for the theoretical and practical development of general-purpose world models in AI. The core premise is that any model deserving the designation "world model" must jointly satisfy modal consistency (semantic alignment), spatial consistency (geometric coherence), and temporal consistency (logical-causal evolution). This principle is proposed as a response to limitations observed in current large-scale generative systems: despite impressive statistical power and scaling, such models often lack fundamental grounding in physical reasoning, leading to phenomena such as structural hallucinations, modality misalignment, and violations of basic causality.
The work systematically analyzes the distinct challenges and technical evolution trajectories of each consistency axis, culminating in a critique of existing evaluation methods and the introduction of the CoW-Bench benchmark—explicitly designed to probe and quantify model consistency failures across all three axes and their intersections.
The Trinity of Consistency: Modal, Spatial, and Temporal Axes
The authors decompose the requirements for general-purpose world modeling into three orthogonal but interacting axes:
- Modal Consistency: The alignment of information across modalities (text, image, audio, etc.) into a unified, physically-complete semantic space, supporting refined instruction following, in-context feedback, and intent alignment.
- Spatial Consistency: The enforcement of geometric, topological, and 3D constraints—spanning micro-scale smoothness (Lipschitz continuity) to macro-scale epipolar consistency—across single frames, multiple views, and dynamic 3D scenarios.
- Temporal Consistency: The maintenance of identity, causality, and rule-conformant evolution across time, including preservation of object permanence, scene dynamics plausibility, and compliance with sequential logic.
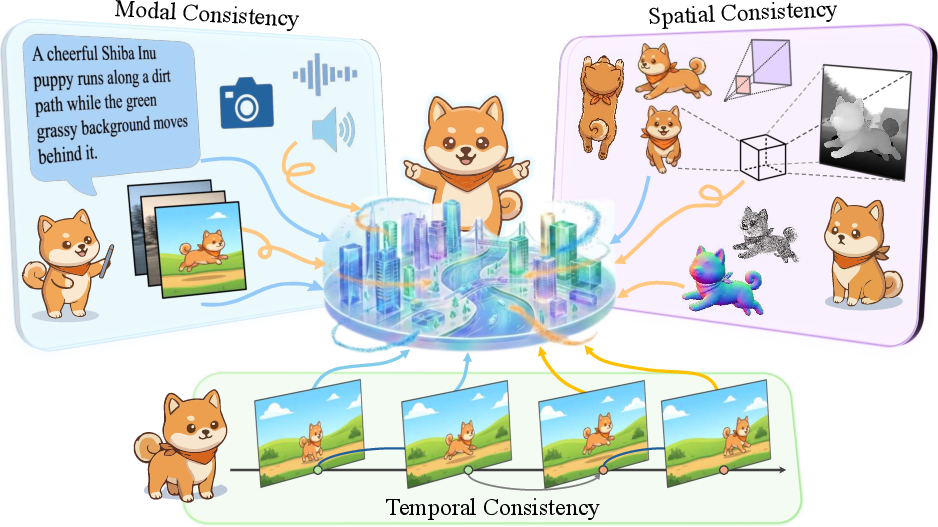
Figure 1: The Trinity of Consistency in world models: Modal Consistency (Semantics), Spatial Consistency (Geometry), and Temporal Consistency (Causality).
A key emphasis is that, while each dimension can be optimized independently in narrow settings, their joint satisfaction is essential for models seeking to simulate or reason about physical and causal phenomena.
Technical Trajectory: From Specialization to Unified World Simulators
The evolution of generative AI is categorized as a trajectory from loosely coupled specialized modules (ad hoc combinations of modality-specific and geometric engines) to architectural unification via Unified Multimodal Models (UMMs), Diffusion Transformers (DiT), and advanced spatiotemporal AI. The work presents detailed reviews and critiques of existing approaches in each axis:
Modal Consistency
- The text-to-image alignment problem is formalized as a joint inverse projection from shadows (multimodal observations) to latent world variables, confronting entropy and topological asymmetry.
- The limitations of Dual-Tower (contrastive) and Early Fusion architectures are made explicit, including the inefficacy of linear projections (as in LLaVA) for recovering high-frequency visual information.

Figure 2: Modal consistency aims to project heterogeneous inputs (Text, Image, Video, Audio) into a unified, physically-aligned latent space.
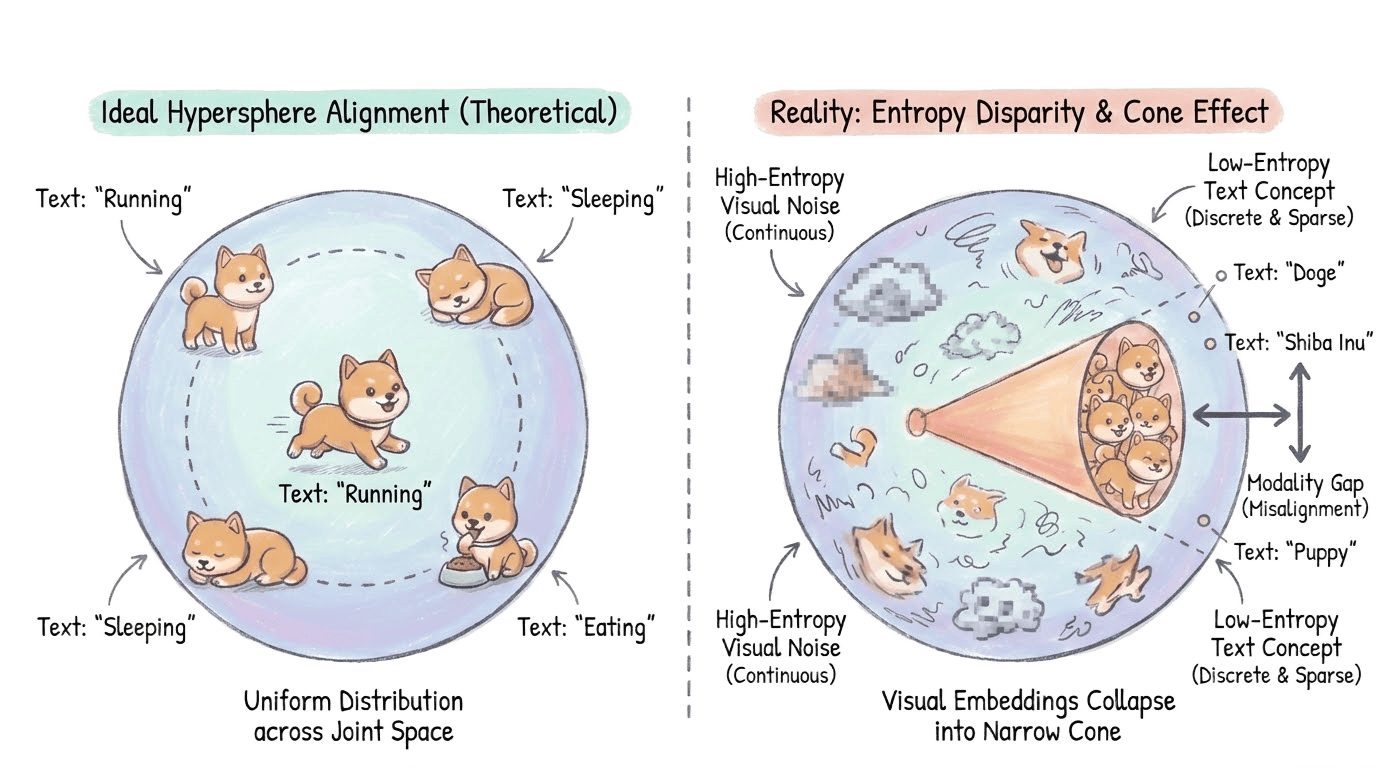
Figure 3: Modal gap: entropy disparity causes visual embeddings to collapse into a narrow "cone," leading to topological mismatch with discrete text tokens.
- The emergence of orthogonally decoupled architectures (e.g., MM-DiT, Emu-3, PixArt-α, Stable Diffusion 3.5) with block-diagonal Hessians, data exchange via joint-attention only, and reduction in gradient conflict is emphasized as current best practice.
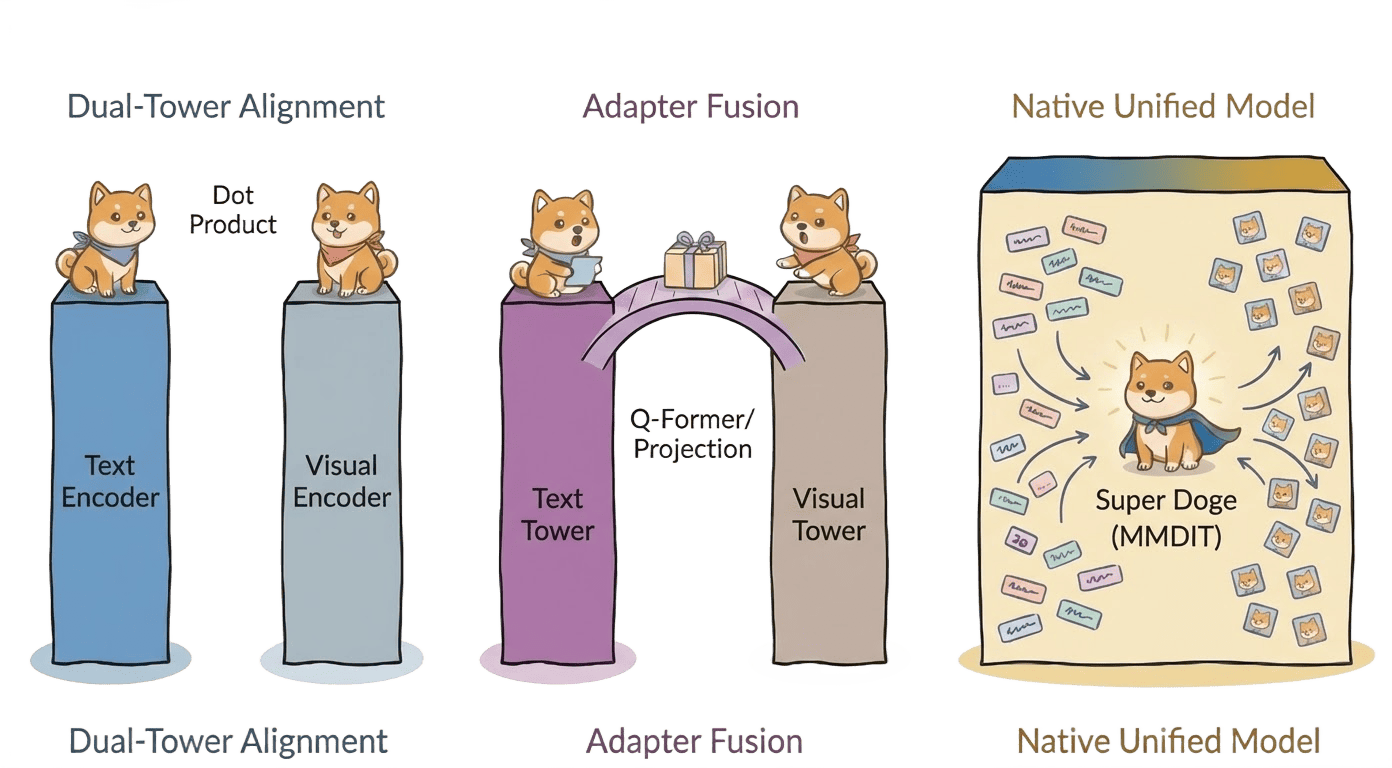
Figure 4: Evolution of Multimodal Fusion Paradigms: from geometric isolation to early fusion to orthogonally decoupled, natively unified MM-DiT architectures.
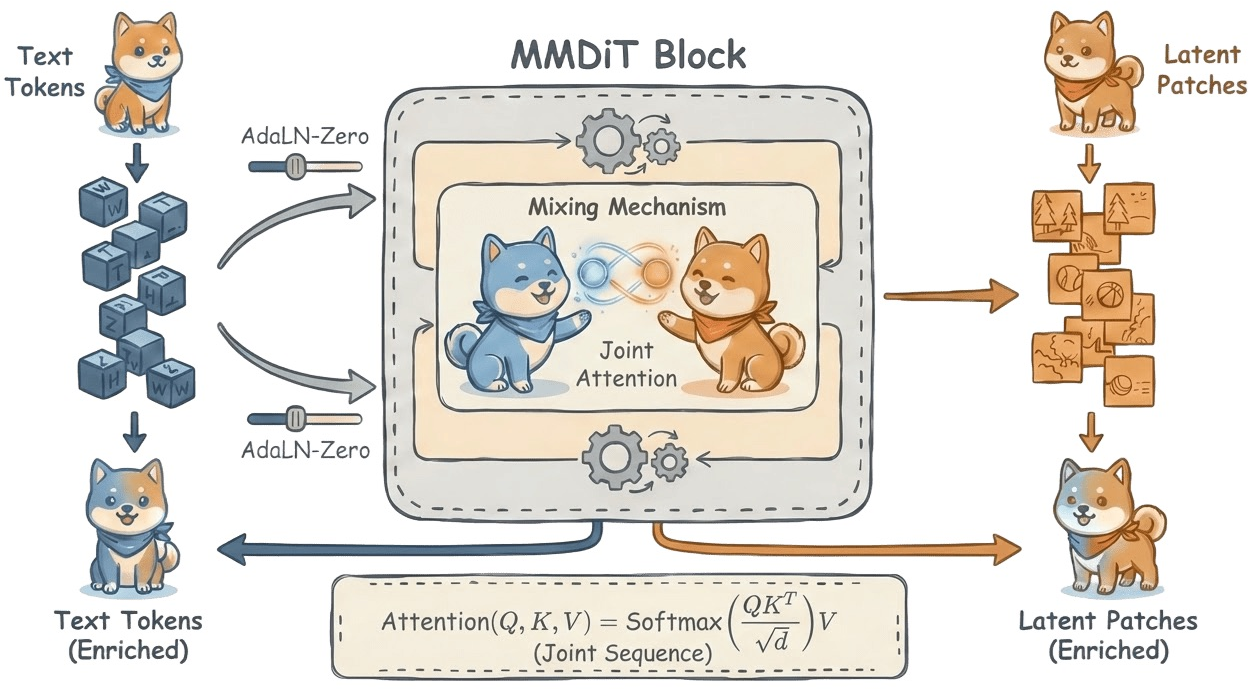
Figure 5: MM-DiT Architecture efficiently resolves modality conflict through independent weights and attention-based data exchange.
Spatial Consistency
- Early 2D manifold proxies (e.g., video prediction, ConvLSTM) are argued to be inherently limited by their inability to encode or reconstruct the SE(3) group structure of 3D scenes.
- The field’s progression to implicit continuous fields (NeRF, SDF) and finally to explicit Lagrangian primitives (3D Gaussian Splatting, 3DGS), with highly efficient rasterization and explicit gradient flow, is traced in detail.
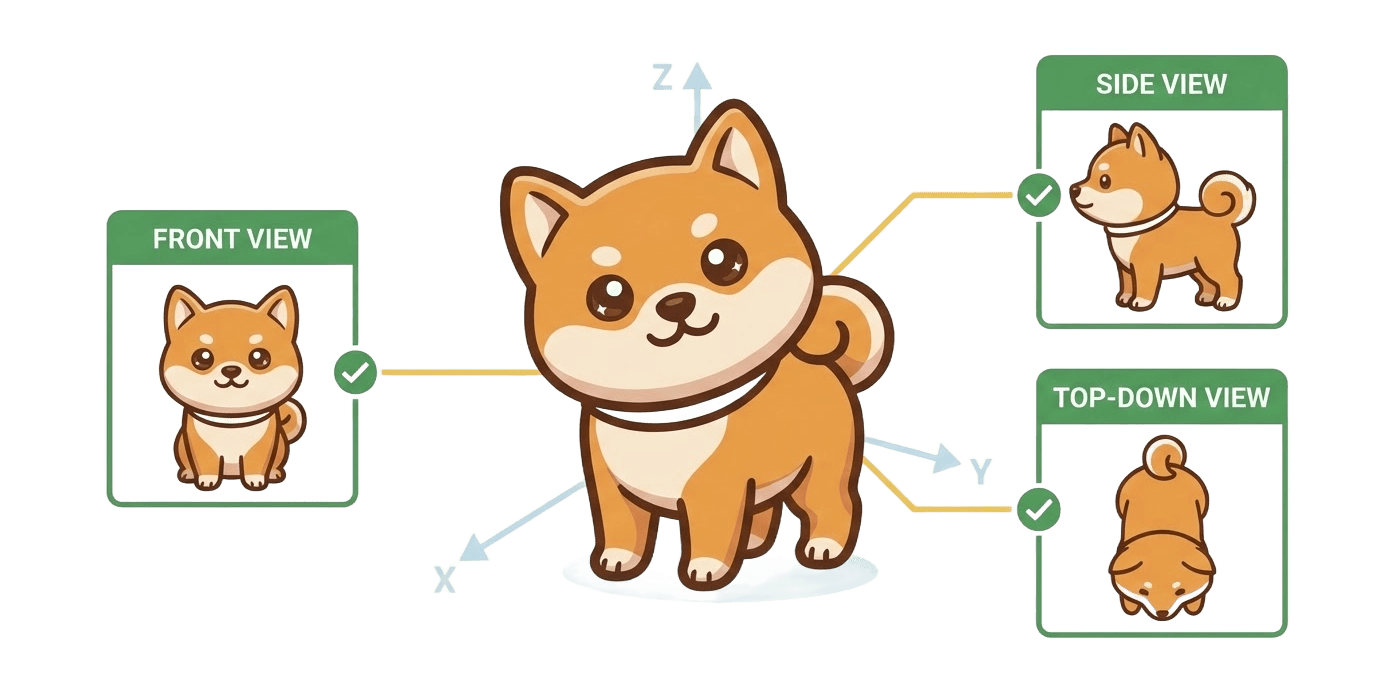
Figure 6: Multi-view constraints—ensuring geometric coherence across views—enable the model to prevent Janus and other coherence failures.
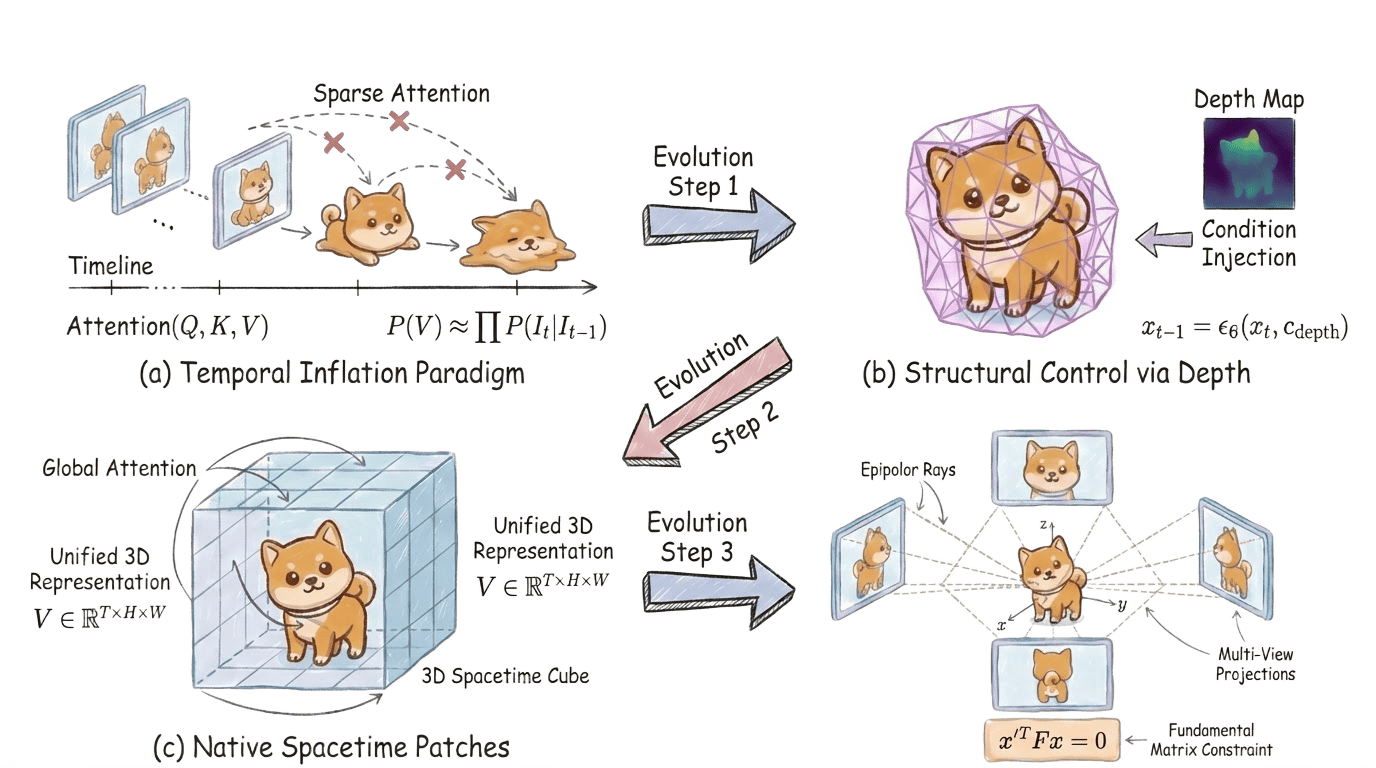
Figure 7: Evolution of Spatial Consistency paradigms, from 2D proxies to implicit fields, Lagrangian primitives, and generative diffusion priors.
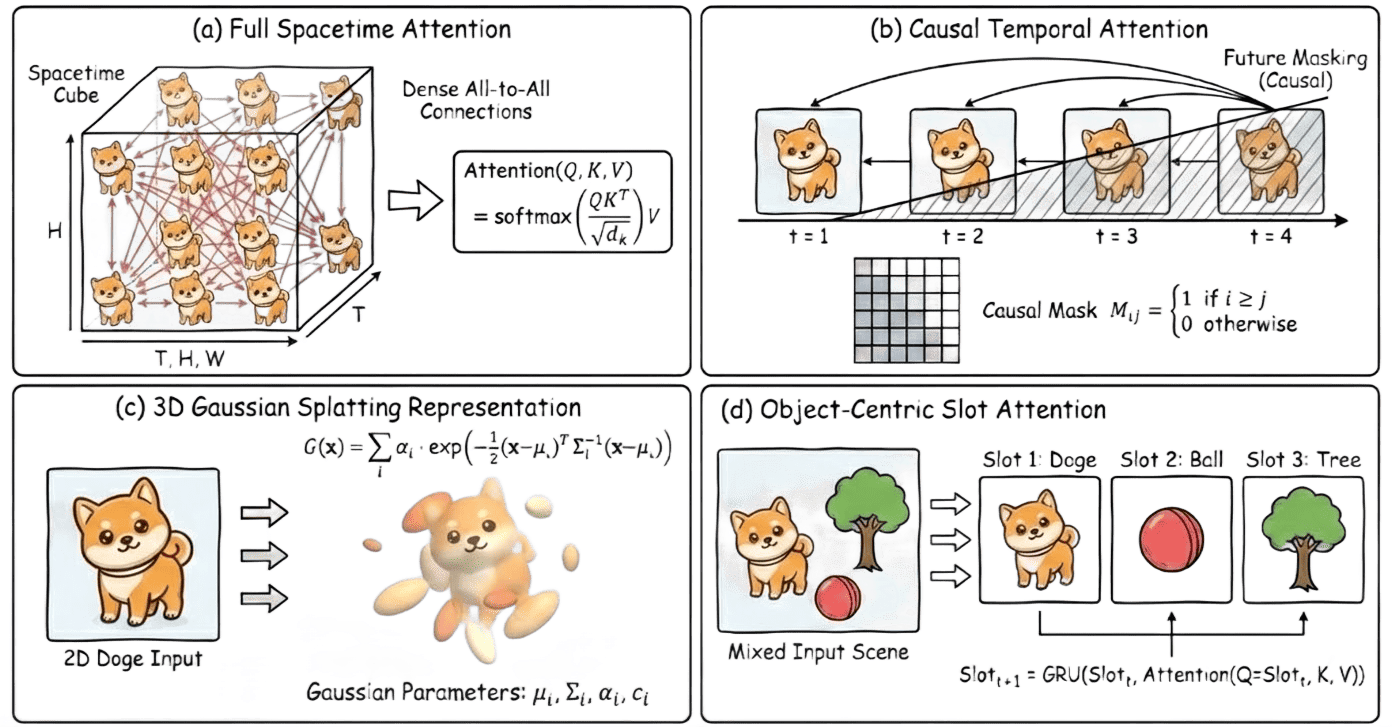
Figure 8: Taxonomy of advanced spacetime modeling: Full Spacetime Attention, Causal Masking, 3D Gaussian Splatting, Object-Centric Slots.
Temporal Consistency
- The field’s early reliance on inflationary paradigms (e.g., AnimateDiff, Text2Video-Zero) is shown to achieve only first-order Markov continuity and to suffer from error amplification and semantic drift for longer sequences.
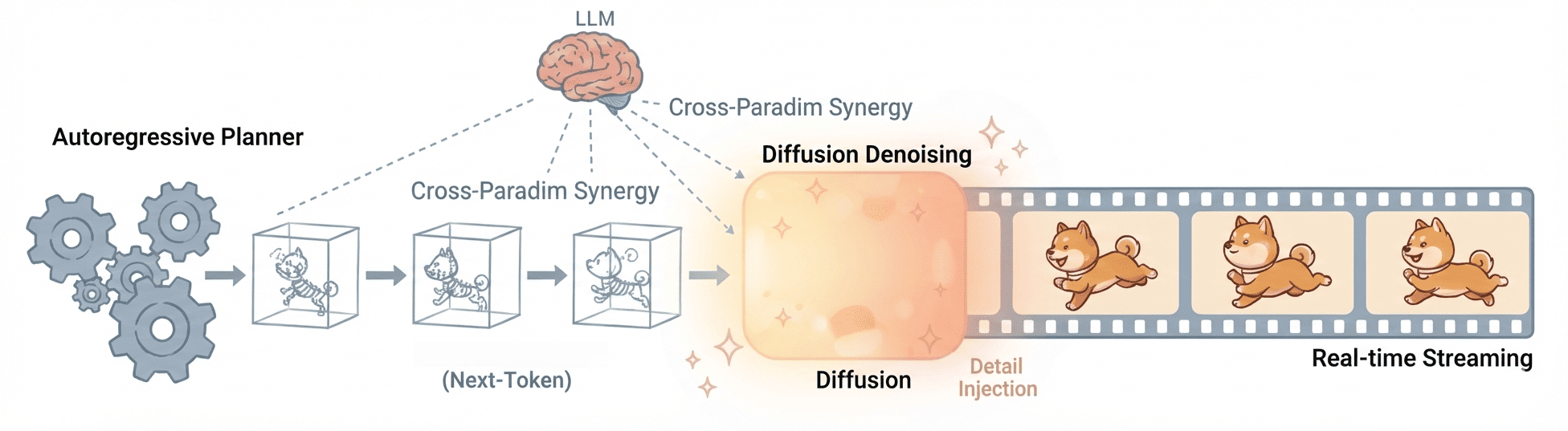
- The work highlights that attention-based architectures trained on 3D patches (e.g., Sora, HunyuanVideo, Video-TTT), especially those employing full joint spatiotemporal attention, establish new benchmarks by enforcing both visually and logically faithful evolution over minutes-long durations.
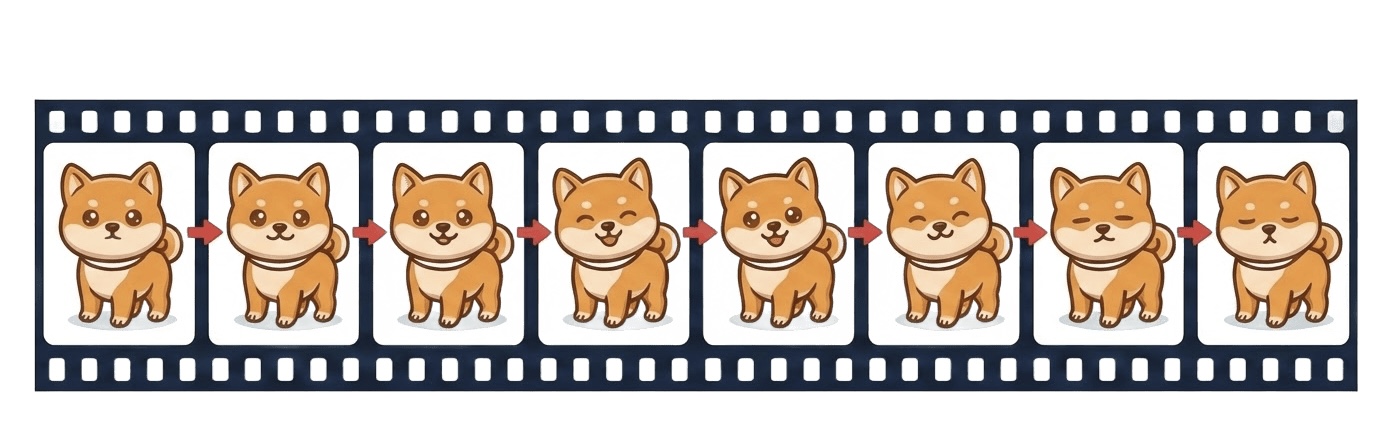
Figure 9: The temporal attention mechanism ensures identity preservation and controls both physical and causal constraints across frames.
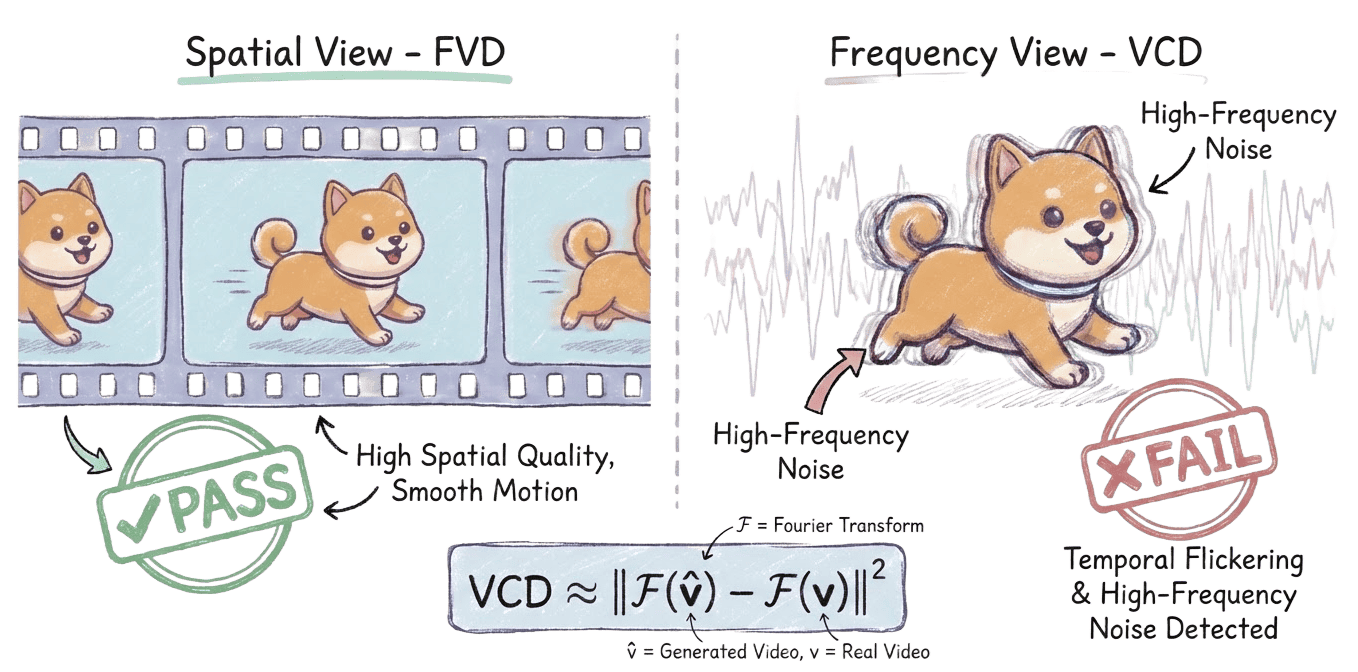
Figure 10: VCD metric: analyzes the Fourier spectrum to detect high-frequency flicker artifacts, surpassing FVD and similar spatial metrics.
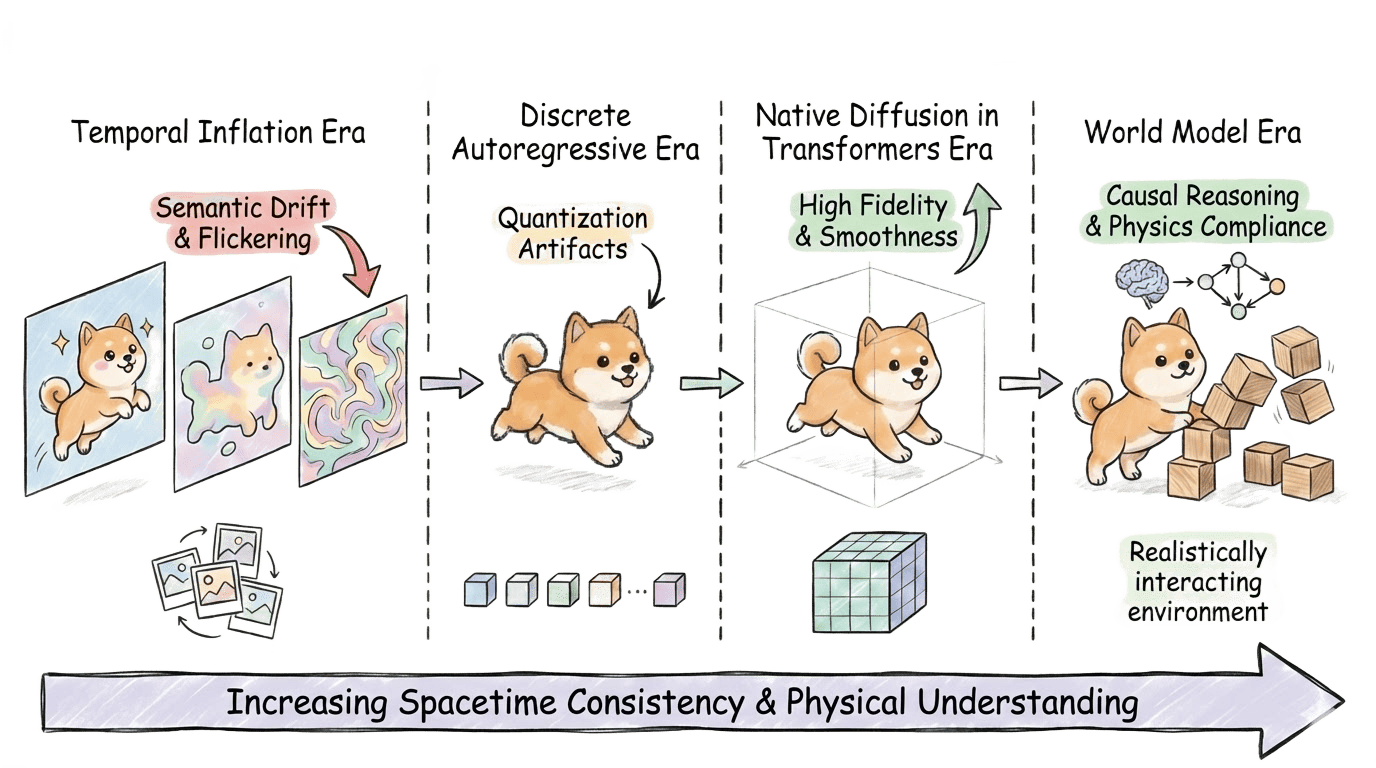
Figure 11: Evolution from Temporal Inflation and Discrete AR to full spatiotemporal DiT enables true world modeling capabilities.
Architectural Integration and Agentic Loops
A major contribution is the formalization of integration between consistency axes, moving from isolated optimization to synergistic constraint satisfaction:
- Modal + Spatial: Prompt-to-pixel control that grounds semantics in explicit scene structure, e.g., language-driven spatial binding, modular attention injection for structure-preserving editing.
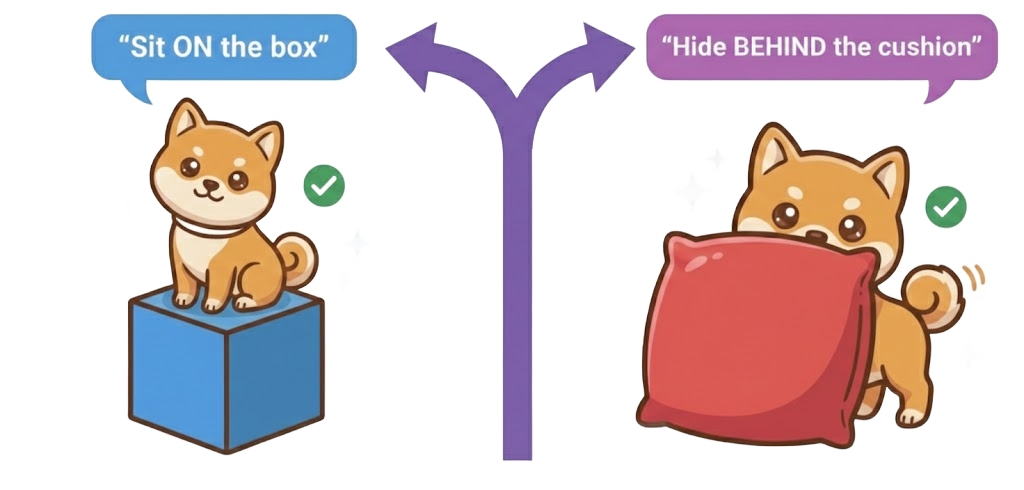
Figure 12: Language-driven spatial control—integrating modal and spatial consistency for precise spatial relation fulfillment.
- Modal + Temporal: Semantic-driven programmatic evolution (e.g., executing temporal attribute schedules, event-triggered transitions) is explicitly illustrated.

Figure 13: Language controls the time evolution process, dynamically maintaining consistency as instructed events unfold over time.
- Spatial + Temporal: Persistent geometric identity under dynamic occlusions and topological changes (i.e., dynamic object permanence) is a defining test of genuine world-simulation capacity.
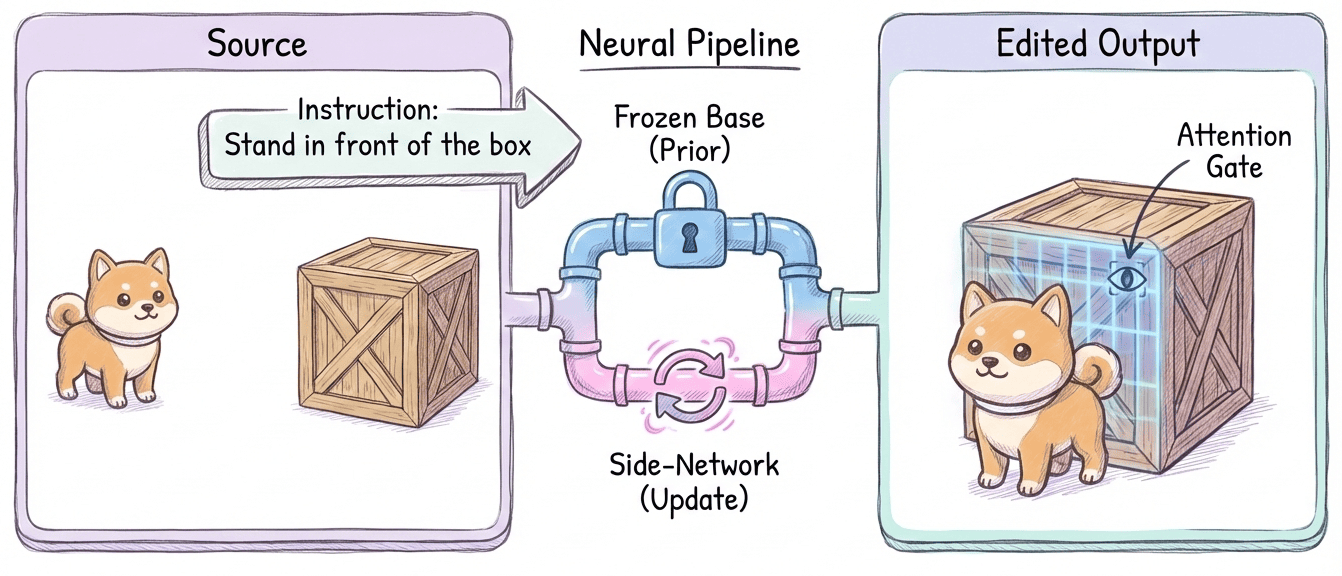
Figure 14: Instruction-driven, structure-preserving image editing—maintaining spatial consistency under semantic manipulation.
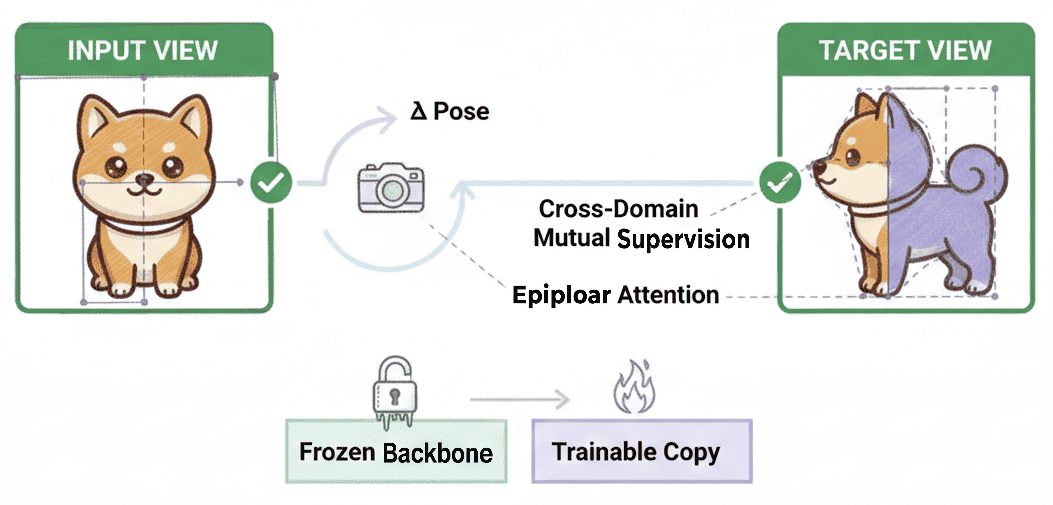
Figure 15: Pose-aligned view synthesis—epipolar attention and mutual supervision for geometric accuracy across views.
The CoW-Bench Benchmark: Comprehensive Evaluation of Consistency
The work addresses substantial limitations of existing benchmarks, including their reliance on superficial perceptual similarity, lack of process/evolution verification, and inability to capture causal or constraint violations. The proposed CoW-Bench benchmark:
Strong Results, Limitations, and Empirical Insights
The empirical evaluation identifies several key observations:
Theoretical and Practical Implications
Theoretically, this work frames the problem of world modeling as the joint satisfaction of three constraint manifolds, each with their own mathematical and empirical challenges. Crucially, it suggests that scaling alone (in data or model parameters) cannot suffice—architectural and objective-level innovations are required to resolve cross-consistency failures.
Practically, the introduction of CoW-Bench establishes a reproducible and rigorous test for model claims of "world understanding". This is especially impactful in settings (robotics, simulation, digital twins) where correct multimodal, physical, and causal reasoning is non-negotiable.
The work concludes that the next frontier in world modeling is a shift from texture synthesis and feed-forward mapping to agentic, constraint-satisfying, and process-verifiable simulation, where semantic prompts are compiled into executable, persistent, and causally consistent spatiotemporal dynamics.
Future Directions and Outlook
Conclusion
By formalizing the Trinity of Consistency and constructing rigorous, multi-constraint benchmarks, this paper establishes the analytical and empirical conditions under which generative AI can legitimately claim world modeling capabilities. The evolution from passive perception and local texture synthesis toward interactive, agentic world simulation marks a paradigmatic divide for the next generation of AI systems. The field's progress will be measured not only by scaling laws but by the degree to which models internalize and satisfy the joint physical, semantic, and logical constraints that constitute reality.
Figure 1: The Trinity of Consistency: Modal (semantic), Spatial (geometric), and Temporal (causal) as the three defining axes for world models.