Understanding World or Predicting Future? A Comprehensive Survey of World Models
Abstract: The concept of world models has garnered significant attention due to advancements in multimodal LLMs such as GPT-4 and video generation models such as Sora, which are central to the pursuit of artificial general intelligence. This survey offers a comprehensive review of the literature on world models. Generally, world models are regarded as tools for either understanding the present state of the world or predicting its future dynamics. This review presents a systematic categorization of world models, emphasizing two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making. Initially, we examine the current progress in these two categories. We then explore the application of world models in key domains, including generative games, autonomous driving, robotics, and social simulacra, with a focus on how each domain utilizes these aspects. Finally, we outline key challenges and provide insights into potential future research directions. We summarize the representative papers along with their code repositories in https://github.com/tsinghua-fib-lab/World-Model.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a big review of “world models,” which are kinds of AI that try to build an inner understanding of the world and/or predict what will happen next. Think of a world model like a smart inner simulator or mental map that helps an AI make sense of what it sees and plan ahead—like imagining the next frames of a movie or the next moves in a game. The authors explain two main jobs of world models:
- Understanding how the world works right now (building a compact “mental map” of it)
- Predicting how the world will change in the future (simulating what might happen)
They also look at how these ideas are used in self-driving cars, robots, and digital societies, and they point out what’s hard and what researchers should try next.
What questions does the paper ask?
The paper focuses on a few simple questions:
- What exactly is a “world model,” and what are its core purposes?
- How do different AI systems learn to understand the world and predict the future?
- How are world models used in real areas like autonomous driving, robotics, and social simulations?
- What are the current limits of these models, and where should research go from here?
How did the authors study it?
The authors didn’t run a single new experiment. Instead, they surveyed and organized lots of recent research to make the big picture clearer. Here’s how they approached it:
- They created a two-part categorization:
- Internal representation: models that build an inner summary of the world (a compact “mental map”) to support decisions.
- Future prediction: models that simulate future states, often by generating video-like sequences that show what could happen.
- They explained key techniques using everyday ideas:
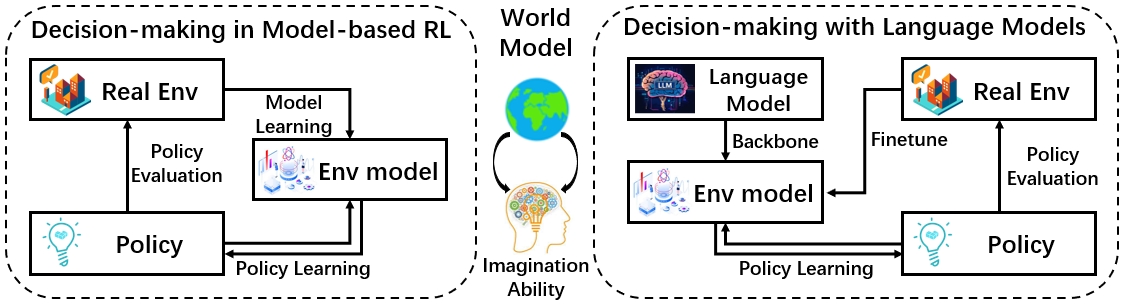
- Model-based reinforcement learning (MBRL): like practicing moves in a simulator before trying them in real life. The “world model” learns how the environment responds to actions, so the agent can plan ahead safely.
- LLMs and multimodal LLMs (MLLMs): these are AIs trained on lots of text (and sometimes images or video). They store common sense and world knowledge and can help plan actions or describe what’s happening.
- Video generation models (like Sora): these create realistic videos that often follow physical rules, acting like a visual future simulator.
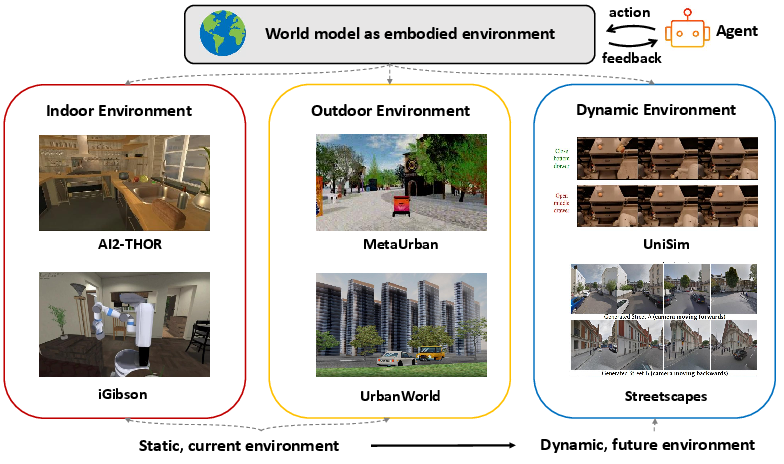
- Embodied environments: virtual worlds (indoor rooms, outdoor cities, or dynamic scenes) where agents can “live,” move, and interact, learning from realistic feedback.
- They reviewed applications in:
- Autonomous driving: perceiving roads and predicting traffic behavior
- Robotics: navigating spaces, manipulating objects, and planning tasks
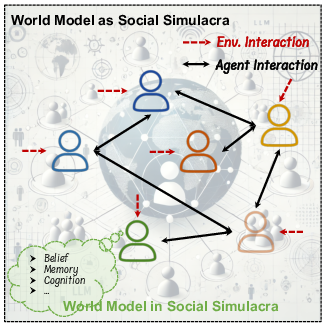
- Social simulacra: modeling human interactions and decision-making
Quick explanations of technical terms
- World model: an AI’s inner “mental model” or simulator of how the world works.
- Latent variables: hidden, compact features the AI uses to represent important information (like secret notes that summarize what really matters).
- Reinforcement learning (RL): learning by trial and error to get better rewards (like learning to play a game).
- Model-based RL: using a learned simulator to plan actions before trying them for real.
- JEPA (by Yann LeCun): a design idea for AI that focuses on building efficient internal representations—like a brain’s perception and reasoning pipeline.
- Multimodal: handling more than one kind of data, like text plus images or video.
- Embodied: involving an agent that “exists” in a space and can act physically (even if it’s virtual).
What did they find, and why is it important?
The paper’s main takeaways highlight how the field is evolving and what’s promising:
- Two core roles of world models:
- Understanding now: build a compact, useful internal picture of the world to make decisions faster and smarter.
- Predicting next: simulate future events to guide planning and action.
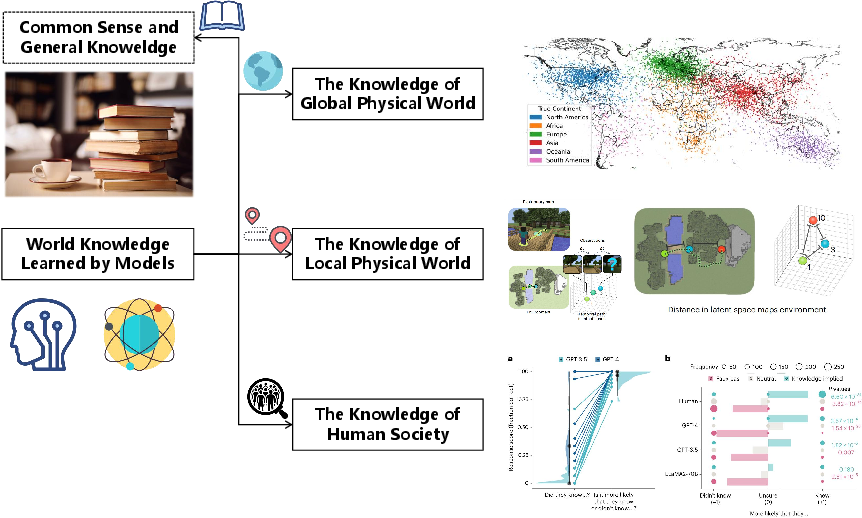
- LLMs can hold world knowledge:
- LLMs often learn common sense, spatial and temporal concepts (like how places relate to each other or how events unfold), and even social reasoning skills (Theory of Mind: guessing what others think).
- This knowledge can help with planning, navigation, and interpreting scenes, but it’s sometimes rough or biased and needs improving for specific cities or tasks.
- Video world models are a major step:
- Models like Sora can generate strikingly realistic videos that often follow physical rules, hinting at powerful future simulators.
- Limitations remain: they struggle with true cause-and-effect reasoning, consistently correct physics, and interactive control.
- New research is pushing for longer, more consistent videos, better physics, multi-modal inputs, and interactivity—so users (or robots) can influence what happens.
- Embodied environments are growing:
- There are many virtual indoor and outdoor worlds where agents can learn to navigate, manipulate objects, and interact.
- A new trend is dynamic, first-person, generative environments that change over time, providing realistic training and feedback for agents.
- Different fields need different strengths:
- Self-driving needs instant perception plus short-term prediction of traffic.
- Robotics needs precise understanding of spaces and objects plus trial-and-error in safe simulations.
- Social simulations need models that handle human behavior, norms, and intentions.
What does this mean for the future?
This survey suggests that building truly helpful world models will involve combining strong understanding with reliable prediction. If we get this right, we can:
- Make safer, smarter self-driving systems that anticipate tricky situations
- Train robots that learn faster and act more reliably in homes, factories, and hospitals
- Simulate complex societies to study policies, teamwork, or ethical questions
- Move closer to general-purpose AI (AGI) by giving models richer, more grounded “common sense”
To reach those goals, researchers need to improve:
- Causal reasoning (understanding what causes what)
- Long-term prediction and temporal consistency
- Accurate physical laws in simulations
- Interactive control so models can respond to actions in real time
- Multimodal learning that blends text, images, video, actions, and rewards
In short, the paper argues that the most powerful world models will be part mental map, part future movie, and part interactive playground—helping AI understand what’s going on and confidently plan what to do next.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper surveys world models from two perspectives—implicit understanding and future prediction—but leaves several concrete issues unresolved that future research could address:
- Lack of an operational definition: No precise, testable, and widely accepted definition of a “world model” that reconciles the dual goals of understanding (latent representation) and prediction (simulation); need a formal taxonomy with measurable capabilities and failure modes.
- Unified evaluation protocol: Absence of standardized benchmarks and metrics that jointly assess representation fidelity, long-horizon prediction, interactivity, and task utility across domains (autonomous driving, robotics, social simulacra).
- Measuring “understanding”: No agreed-upon metrics to verify whether internal latent variables capture causal, compositional, and physically meaningful structure (beyond next-token/frame prediction performance).
- Physical law adherence: No standardized, physics-grounded test suites (rigid/soft bodies, fluids, collisions, lighting) with quantitative metrics for evaluating generative models’ compliance with physical constraints.
- Causal reasoning and counterfactuals: Unclear pathways to imbue video world models (e.g., Sora-like) with causal structure, action conditionality, and counterfactual prediction; need methods to learn intervention-aware dynamics and evaluate causal consistency.
- From video generation to control: Open question of how to turn passive, unconditional video models into action-conditioned, closed-loop simulators suitable for planning and control with guarantees on stability and latency.
- Compounding error in model-based RL: Limited discussion of multi-step rollout errors, model bias, partial observability, and methods (e.g., uncertainty-aware planning, conservative imagination) to mitigate degradation over long horizons.
- Reward modeling: Most decision-making settings assume known rewards; missing coverage of inverse RL/preference learning to infer latent rewards aligned with human goals in complex, real-world tasks.
- Uncertainty quantification: Need principled approaches for calibrated aleatoric and epistemic uncertainty in high-dimensional generative dynamics and their integration into risk-aware planning.
- Bridging LLM knowledge and sensorimotor control: No concrete methodology for grounding textual world knowledge in continuous control spaces (e.g., mapping language abstractions to actionable state representations with verifiable semantics).
- Veracity and bias of LLM world knowledge: Evidence of coarse or inaccurate geospatial/urban knowledge; missing protocols for auditing, correcting, and continuously updating LLMs with authoritative, localized data while mitigating geographic and social biases.
- Multiscale world knowledge integration: No framework for unifying global (macro) and local (micro) physical knowledge with social cognition (ToM) into a coherent, queryable, and actionable world model.
- Social simulacra validity: Limited pathways to validate Theory-of-Mind behaviors as genuinely model-based (vs prompt artifacts); need datasets, perturbation tests, and causal probes that distinguish true mental-state modeling from pattern matching.
- Memory and persistence: Open problem of building persistent, queryable world state (object permanence, identity, long-term dynamics) that supports lifelong reasoning and reduces drift across long episodes.
- Object-centric and compositional modeling: Lacking robust, scalable methods to learn disentangled, factorized dynamics (objects, relations, constraints) that generalize compositionally to novel scenes and tasks.
- Interactivity metrics: No agreed metrics for controllability, responsiveness to actions, latency/jitter in closed-loop use, and “decision leverage” (how model quality translates to better policies).
- Sim2real transfer: Missing systematic evaluation pipelines and adaptation methods (e.g., online adaptation, representation alignment) that ensure world models trained in simulation or web data transfer reliably to real sensors and actuators.
- Data and compute efficiency: Limited discussion of sample-efficient learning, curriculum/active data collection, and efficient architectures (compression, distillation) for training and updating large world models.
- Modality alignment and timing: Open challenges in aligning and temporally synchronizing heterogeneous modalities (vision, language, audio, lidar, actions) with consistent semantics for prediction and control.
- Safety and reliability: No concrete safety benchmarks for world models in safety-critical domains (autonomous driving, robotics) covering OOD robustness, adversarial perturbations, and fail-safe behaviors.
- Governance, privacy, and licensing: Unaddressed issues around dataset provenance for large video models, privacy-preserving training, legal compliance, and responsible deployment in social simulation contexts.
- Reproducibility barriers: Heavy reliance on closed models (e.g., Sora) and proprietary datasets hinders reproducibility; need open baselines, datasets, and standardized reporting for fair comparison.
- Planner–model interfaces: Unclear best practices for integrating planners with world models (MPC, MCTS, differentiable planning) and for exposing actionable interfaces (state abstractions, gradients, affordances).
- Continual and non-stationary learning: Open question of how to support continual updates without catastrophic forgetting while tracking non-stationary real-world dynamics and concept drift.
- Domain-specific benchmarks: Gaps in domain-tailored suites (e.g., city-scale planning, household manipulation, multi-agent social dynamics) that stress-test both understanding and prediction over long horizons and under constraints.
Glossary
- Actor-critic algorithm: A reinforcement learning approach that learns a policy (actor) and a value function (critic) jointly. "The policy learning stage utilizes an actor-critic algorithm purely based on the previously generated multimodal representations."
- Aleatoric uncertainty: The inherent randomness in outcomes that cannot be reduced by gathering more data, often modeled probabilistically. "Chua et al.\cite{chua2018deep} further model the aleatoric uncertainty with the probabilistic transition model."
- AGI: A hypothetical form of AI with the ability to understand, learn, and apply knowledge across a wide range of tasks at human levels. "in pursuit of AGI~\cite{lecun2022path}."
- Autoencoder: A neural network architecture that learns compressed representations (encodings) by reconstructing inputs. "Ha and Schmidhuber\cite{ha2018recurrent} adopt an autoencoder structure to reconstruct images via latent states."
- Bayesian adaptive Markov decision processes (MDPs): MDPs that incorporate Bayesian updates to handle uncertainty in model parameters during learning and planning. "further cast reasoning in LLMs as learning and planning in Bayesian adaptive Markov decision processes (MDPs)."
- Causal reasoning: The ability to infer cause-and-effect relationships within systems or environments. "One key limitation concerns causal reasoning~\cite{zhu2024sora,cho2024sora}, wherein the model is limited in simulating dynamic interactions within the environment."
- Cognitive chains: Structured sequences of reasoning steps that explicitly encode cognitive processes or theories for inference. "COKE, which constructs a knowledge graph to help LLMs explicitly using theory in mind through cognitive chains."
- Cognitive map: An internal representation of spatial relationships and environments used for navigation and planning. "We first introduce the concept of the cognitive map~\cite{tolman1948cognitive}, which illustrates how the human brain models the external world."
- Encoder-decoder frameworks: Neural architectures with an encoder to compress inputs and a decoder to generate outputs, widely used in sequence and generative modeling. "Sora leverages a combination of powerful neural network architectures, including encoder-decoder frameworks and transformers, to process multimodal inputs and generate visually coherent simulations."
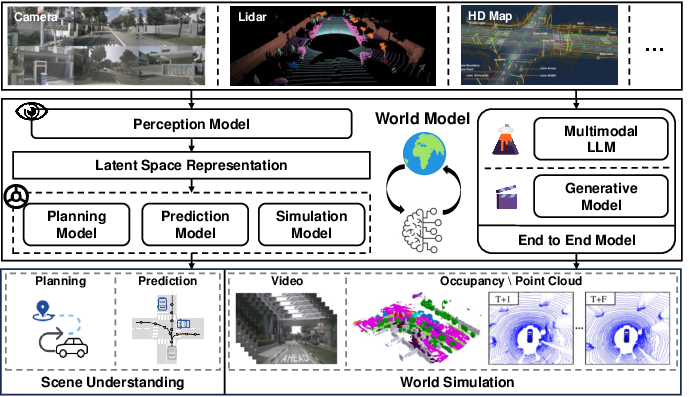
- Embodied environments: Simulated or real settings where agents perceive, act, and learn through physical or virtual embodiment. "The development of world models for embodied environments is crucial for simulating and predicting how agents interact with and adapt to the external world."
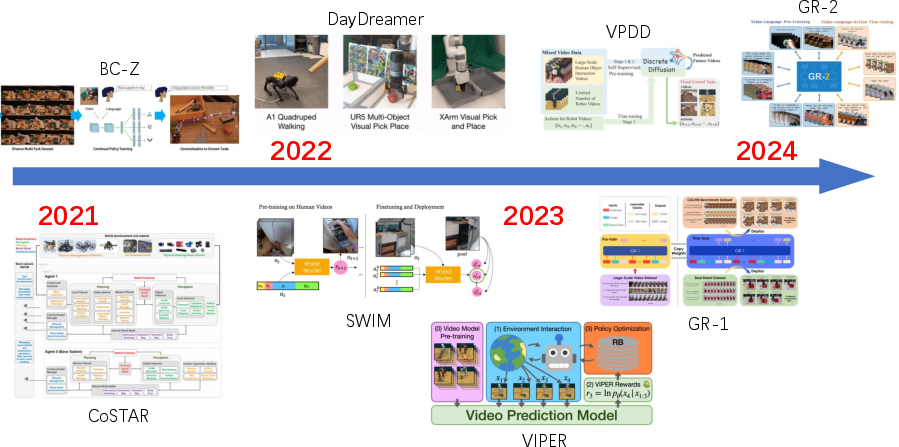
- Few-shot transfer: The capability of a model to adapt to new tasks using only a few examples. "Such a method enables a strong few-shot transfer ability to unseen tasks."
- Generalist model: A single model designed to perform across multiple tasks or domains rather than being specialized. "Such a scheme exhibits the potential of obtaining one generalist model for decision models on several tasks with other data modalities."
- Goal-conditioned planning schema: Planning methods that condition policies or plans on explicit goals to guide action selection. "they propose a goal-conditioned planning schema where Monte Carlo Tree Search (MCTS) is utilized to search for the true embodied task goal."
- Joint Embedding Predictive Architecture (JEPA): A framework that learns predictive representations by embedding observations into a joint space for forecasting. "Yann LeCun introduced the Joint Embedding Predictive Architecture (JEPA), a framework mirroring the human brain's structure."
- KL divergence: A measure of difference between two probability distributions, often used to fit probabilistic models. "The objective is to minimize the KL divergence between the transition models,"
- Knowledge graph: A structured representation of entities and their relationships, used to support reasoning and retrieval. "introduce COKE, which constructs a knowledge graph to help LLMs explicitly using theory in mind through cognitive chains."
- Latent dynamics: Hidden or learned transitional rules governing how latent states evolve over time. "propose to learn visual encoder and latent dynamics for visual control tasks,"
- Latent variables: Hidden variables that capture essential factors of variation in data while abstracting away redundancies. "It models the state of the world using latent variables, which capture key information while filtering out redundancies."
- Mean squared prediction error: A regression loss measuring the average squared difference between predicted and actual values. "the most straightforward approach is to leverage the mean squared prediction error on each one-step transitions"
- Model Predictive Control (MPC): A planning/control method that optimizes action sequences over a finite horizon using a predictive model. "one most straightforward way to generate a corresponding policy is model predictive control (MPC)\cite{kouvaritakis2016model}."
- Model-based Reinforcement Learning (MBRL): RL approaches that learn and exploit a model of the environment’s dynamics for planning and policy learning. "This methodology closely mirrors the Model-based Reinforcement Learning (MBRL) method,"
- Monte Carlo method: A sampling-based technique used to estimate quantities or optimize decisions by random sampling. "Nagabandi et al.\cite{nagabandi2018neural} adopts a simple Monte Carlo method to sample action sequences."
- Monte Carlo Tree Search (MCTS): A search algorithm that uses Monte Carlo sampling to build a search tree for decision-making. "Another popular approach to generating world model policies is the Monte Carlo Tree Search (MCTS)."
- Multimodal LLMs (MLLMs): LLMs extended to process and integrate multiple modalities (e.g., text, images, video). "the rapid growth of LLMs, especially LLM and MLLM, benefits development in many related applications."
- Next-token-prediction paradigm: Modeling approach where sequences are learned by predicting the next token given prior context. "representing the MDP with a next-token-prediction paradigm~\cite{janner2021offline} using transformer architectures."
- Omni-graph: A unified graph representation capturing multi-modal or multi-entity relationships in an environment. "They propose an omni-graph to capture the structure of the local space as the world model for the navigation task."
- Open-vocabulary detection: Object detection that can recognize categories beyond a fixed training set based on language or semantic cues. "further combine LLMs and open-vocabulary detection to construct the relationship between multi-modal signals and key information in navigation."
- Probabilistic transition model: A model that predicts state transitions as probability distributions, capturing uncertainty in dynamics. "Chua et al.\cite{chua2018deep} further model the aleatoric uncertainty with the probabilistic transition model."
- Representation learning: Techniques for learning useful feature representations from data to improve downstream tasks. "representation learning is widely adopted to improve the effectiveness of world model learning in MBRL."
- State transition dynamics: The rules or probabilities governing how an environment moves from one state to another given actions. "the world model here consists of , the state transition dynamics and , the reward function."
- Temporal consistency: The property that generated or predicted sequences remain coherent and stable over time. "Several studies have worked to enhance the smoothness of action transitions, improve the accuracy of physical laws, and maintain temporal consistency~\cite{yang2024worldgpt, cai2023diffdreamer,ren2024consisti2v, yan2023temporally}."
- Theory of Mind: The capacity to attribute mental states to oneself and others to explain and predict behavior. "One such related theory is the Theory of Mind~\cite{premack1978does}, which explains how individuals infer the mental states of others around them."
- Transformer architectures: Neural networks based on self-attention mechanisms, widely used for sequence and multimodal modeling. "representing the MDP with a next-token-prediction paradigm~\cite{janner2021offline} using transformer architectures."
- Value prediction network: A model that predicts future rewards or state values to guide decision-making. "Oh et al.~\cite{oh2017value} proposed a value prediction network that applies MCTS to the learned model to search for actions based on value and reward predictions."
- Video world model: A model that predicts future world states by generating sequences of visual frames conditioned on past observations and actions. "A video world model is a computational framework designed to simulate and predict the future state of the world by processing past observations and potential actions within a visual context~\cite{sora2024}."
- Visual predictive coding: A predictive learning paradigm where models learn to anticipate future visual inputs, aiding representation and planning. "learning through spatial cognitive map construction using visual predictive coding in a simplified Minecraft world."
- World simulator: A system capable of simulating realistic dynamics of the physical or virtual world over time. "OpenAI introduced Sora model~\cite{sora2024}, a video generation model that is largely recognized as a world simulator."
Practical Applications
Below is an overview of practical applications grounded in the paper’s survey of world models—spanning implicit representation and future prediction—with guidance on sectors, tools/workflows, and feasibility considerations.
Immediate Applications
These applications can be piloted or deployed with current methods, datasets, and tooling, often within constrained domains or supervised settings.
- Model-based control and planning with learned dynamics
- Sector: robotics, manufacturing, energy (process control), software (optimization)
- What: Train world models of transition dynamics (MBRL) from logs; run MPC or MCTS for action planning in robotic arms, mobile robots, pick-and-place, warehouse routing, HVAC optimization, and industrial process control.
- Tools/Workflow: Supervised dynamics learning (deterministic/probabilistic); MPC (sampling/trajectory ensembles); MCTS and actor-critic; visual encoders (Dreamer/DreamerV2); representation learning for high-dimensional states.
- Assumptions/Dependencies: Accurate and well-covered transition data; reliable reward functions; sim-to-real transfer; safety and fail-safes in closed-loop control; bounded distribution shift.
- LLM-augmented navigation and manipulation
- Sector: robotics, smart home, education (robotics labs), software (agentic frameworks)
- What: Use LLM/MLLM to build structured “world knowledge” (e.g., omni-graphs, global semantic graphs) from multi-modal observations; perform few-shot planning and action generation for navigation/manipulation in constrained environments.
- Tools/Workflow: Open-vocabulary detection + LLM (omni-graph); multi-expert LLM decision discussion; imaginative assistants and reflective planners; compositional video world models for few-shot transfer.
- Assumptions/Dependencies: Robust perception; prompt engineering; guardrails for hallucination; continuous evaluation vs. ground truth; task-specific fine-tuning improves reliability.
- Synthetic data generation for training perception and planning
- Sector: autonomous driving, robotics, computer vision (R&D), media/content
- What: Generate long, consistent videos and interactive sequences to augment training datasets for detection, tracking, motion forecasting, and planning; reduce rare-event scarcity.
- Tools/Workflow: WorldDreamer/GAIA-1/Genie-like generative models; ConsistI2V for temporal coherence; UniSim/iVideoGPT for interactive rollouts; careful curation and domain adaptation.
- Assumptions/Dependencies: Distribution alignment and labeling; physical plausibility; IP/licensing for generated assets; robust evaluation to prevent “synthetic overfit.”
- Urban intelligence assistants and city analytics
- Sector: policy, urban planning, transportation, civic tech
- What: Use GeoLLM/CityGPT/CityBench-like approaches to answer city queries, analyze mobility patterns, and triage policy options; prompt and fine-tune LLMs for city-specific knowledge.
- Tools/Workflow: Geospatial prompts; city-specific fine-tuning; integration with sensor feeds (traffic, mobility); dashboards for planners and policymakers.
- Assumptions/Dependencies: LLM world knowledge is coarse unless adapted; risk of geographic bias; require high-quality local datasets and validation protocols.
- Embodied environment platforms for reproducible research and prototyping
- Sector: academia, robotics startups, edtech
- What: Use standardized simulators (AI2-THOR, Habitat, iGibson, VirtualHome, Holodeck, AnyHome, LEGENT) to develop, benchmark, and iterate robot skills, curricula, and evaluation suites.
- Tools/Workflow: Task scripting; physics-enabled 3D assets; curriculum learning; multi-modal sensors; continuous integration with sim tests.
- Assumptions/Dependencies: Gap to real-world dynamics; asset fidelity; transfer learning pipelines; compute resources for large-scale simulation.
- Social simulacra for conversational agents and training
- Sector: customer support, education, HR training, safety research
- What: Leverage ToM-related methods (COKE, SimToM) to improve perspective-taking, social reasoning, and error detection in chatbots, tutors, and training simulators.
- Tools/Workflow: Knowledge graphs for cognitive chains; staged prompting; targeted ToM benchmarks; fine-tuning on role-play datasets.
- Assumptions/Dependencies: ToM performance on benchmarks may not equal real-world generalization; ethics and privacy; guard against stereotype amplification.
- Interactive previsualization and marketing content
- Sector: media, advertising, entertainment
- What: Use image-to-video and long-form generation (ConsistI2V, Sora-like pipelines) to storyboard, prototype scenes, and generate product demos with temporal consistency.
- Tools/Workflow: Prompt-based control; keyframe conditioning; iterative refinement; physics plausibility checks.
- Assumptions/Dependencies: Limitations in causal fidelity and physical correctness; brand safety; watermarking and disclosure.
- Curriculum design and teaching aids for STEM
- Sector: education (K–12, higher ed), edtech
- What: Use simulated environments and predictive videos to illustrate physics/robotics concepts, reinforce understanding via cognitive-map-inspired activities.
- Tools/Workflow: Visual predictive coding demonstrations; interactive labs in simulators; scaffolded tasks with feedback.
- Assumptions/Dependencies: Clear disclaimers when physics is approximate; age-appropriate oversight; accessibility considerations.
- Decision support for logistics and operations
- Sector: supply chain, warehousing, mobility services
- What: Apply learned models plus MPC/MCTS to plan picking routes, storage policies, and fleet scheduling; simulate downstream effects of local changes.
- Tools/Workflow: Transition modeling from operational logs; constrained MPC with safety requirements; scenario testing in sim; integration with ERP/WMS.
- Assumptions/Dependencies: Stable data pipelines; domain-specific reward shaping; human-in-the-loop approvals.
Long-Term Applications
These require advances in physics fidelity, causal modeling, multi-agent interaction, scaling, and regulatory or safety frameworks.
- Generalist world models that unify understanding and prediction
- Sector: cross-sector (software, robotics, education, healthcare)
- What: JEPA-like architectures combined with interactive video world models to support planning, simulation, and transfer across tasks and modalities.
- Tools/Workflow: Joint perception–cognition stacks; latent variable modeling; multimodal transformers; scalable training with curriculum and self-play.
- Assumptions/Dependencies: Reliable causal reasoning; compositionality; robust evaluation standards; substantial compute; safety/alignment.
- End-to-end autonomous driving trained in interactive video world models
- Sector: automotive, mobility policy
- What: Train and validate perception–prediction–planning pipelines in high-fidelity, interactive simulators with controllable dynamics; cover rare events and policy stress tests.
- Tools/Workflow: GAIA-1/MUVO/UniWorld-like models; Pandora/PEEKABOO-style spatiotemporal control; sensor fusion; formal safety cases.
- Assumptions/Dependencies: Physics accuracy; real-time constraints; regulatory approval for synthetic training; scenario coverage; strong sim-to-real methods.
- Household and service robots with robust semantic planning
- Sector: consumer robotics, healthcare, hospitality
- What: LLM-based world models for task decomposition, long-horizon planning, and error recovery; generalization across home layouts (AnyHome/Holodeck).
- Tools/Workflow: World-model rollouts (Dynalang/RAFA); memory and recall frameworks; 3D asset libraries; multimodal policy learning.
- Assumptions/Dependencies: Dexterous manipulation; reliable perception under clutter; safety certification; privacy in home settings.
- City-scale digital twins for real-time policy evaluation
- Sector: public sector, utilities, transportation, climate resilience
- What: Dynamic world models of urban systems to simulate transportation policy, zoning changes, emergency response, and infrastructure investments.
- Tools/Workflow: GRUTopia/MetaUrban/UrbanWorld-like platforms; streaming data integration; counterfactual analysis; multi-objective optimization.
- Assumptions/Dependencies: Data-sharing agreements; governance and transparency; stakeholder buy-in; bias mitigation; standardization across modalities.
- Social policy labs using agent-based simulacra with Theory of Mind
- Sector: governance, economics, public health
- What: Test interventions in synthetic societies with agents exhibiting ToM-like capabilities; explore effects on misinformation, polarization, resource allocation.
- Tools/Workflow: Structured social environments; cognitive chains (COKE); multi-agent RL; causal inference pipelines for policy impact assessment.
- Assumptions/Dependencies: Ethical oversight; representativeness of agent behavior; risk of unintended amplification; validation against empirical data.
- Physics-consistent interactive simulation for engineering design
- Sector: aerospace, manufacturing, energy
- What: Use physically faithful video world models to explore design spaces, test control policies, and co-simulate human–robot collaboration.
- Tools/Workflow: Physics-augmented generative models (PhysDreamer-like); differentiable physics; co-simulation with CAD/CAE tools.
- Assumptions/Dependencies: Verified physical laws; domain-specific solvers; integration with engineering workflows; IP protection.
- Personalized tutors and training in embodied environments
- Sector: education, corporate training, safety compliance
- What: Adaptive curricula in interactive simulators that model learner trajectories and predict knowledge gaps; practice complex procedures safely.
- Tools/Workflow: Embodied envs (LEGENT, AVLEN) with multi-modal feedback; learner modeling; scenario branching; certification pipelines.
- Assumptions/Dependencies: Validated learning gains; fairness and accessibility; content governance; data privacy.
- Healthcare assistance and simulation
- Sector: healthcare (clinical training, assistive robotics)
- What: Simulate clinical scenarios and procedural training; plan assistive tasks in hospitals or eldercare using LLM-based world models.
- Tools/Workflow: High-fidelity embodied envs with medical assets; task planning under uncertainty; human-in-the-loop oversight; safety monitoring.
- Assumptions/Dependencies: Regulatory approval; strict privacy; robust perception in complex environments; interdisciplinary validation.
- Finance and macroeconomic scenario modeling via social world models
- Sector: finance, public policy
- What: Explore market dynamics and policy shocks using agent-based simulations with improved social reasoning; test risk and compliance strategies.
- Tools/Workflow: Multi-agent simulacra; causal analysis; calibrated behavior models; stress testing frameworks.
- Assumptions/Dependencies: Alignment with real-world data; adversarial robustness; governance of model risk; ethical constraints on deployment.
- Standards and governance for synthetic environments and evaluation
- Sector: policy, standards bodies, industry consortia
- What: Develop protocols for benchmarking physical fidelity, causal correctness, and safety; certify use of synthetic data in regulated domains.
- Tools/Workflow: Shared benchmarks (CityBench, GPT4GEO-like); audit trails; disclosure and watermarking; incident reporting.
- Assumptions/Dependencies: Multi-stakeholder coordination; evolving regulatory landscapes; international harmonization.
Collections
Sign up for free to add this paper to one or more collections.