VGG-T$^3$: Offline Feed-Forward 3D Reconstruction at Scale
Abstract: We present a scalable 3D reconstruction model that addresses a critical limitation in offline feed-forward methods: their computational and memory requirements grow quadratically w.r.t. the number of input images. Our approach is built on the key insight that this bottleneck stems from the varying-length Key-Value (KV) space representation of scene geometry, which we distill into a fixed-size Multi-Layer Perceptron (MLP) via test-time training. VGG-T$3$ (Visual Geometry Grounded Test Time Training) scales linearly w.r.t. the number of input views, similar to online models, and reconstructs a $1k$ image collection in just $54$ seconds, achieving a $11.6\times$ speed-up over baselines that rely on softmax attention. Since our method retains global scene aggregation capability, our point map reconstruction error outperforming other linear-time methods by large margins. Finally, we demonstrate visual localization capabilities of our model by querying the scene representation with unseen images.










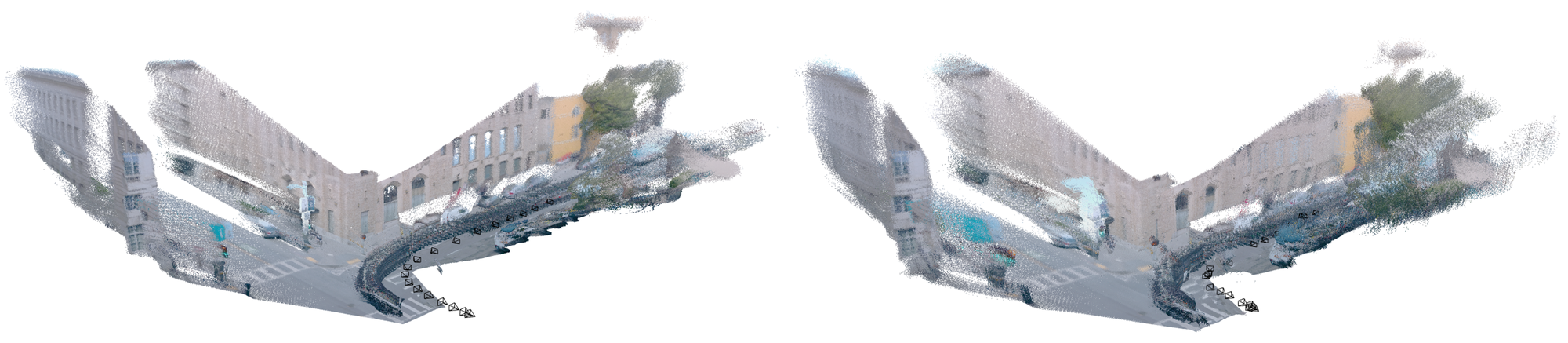
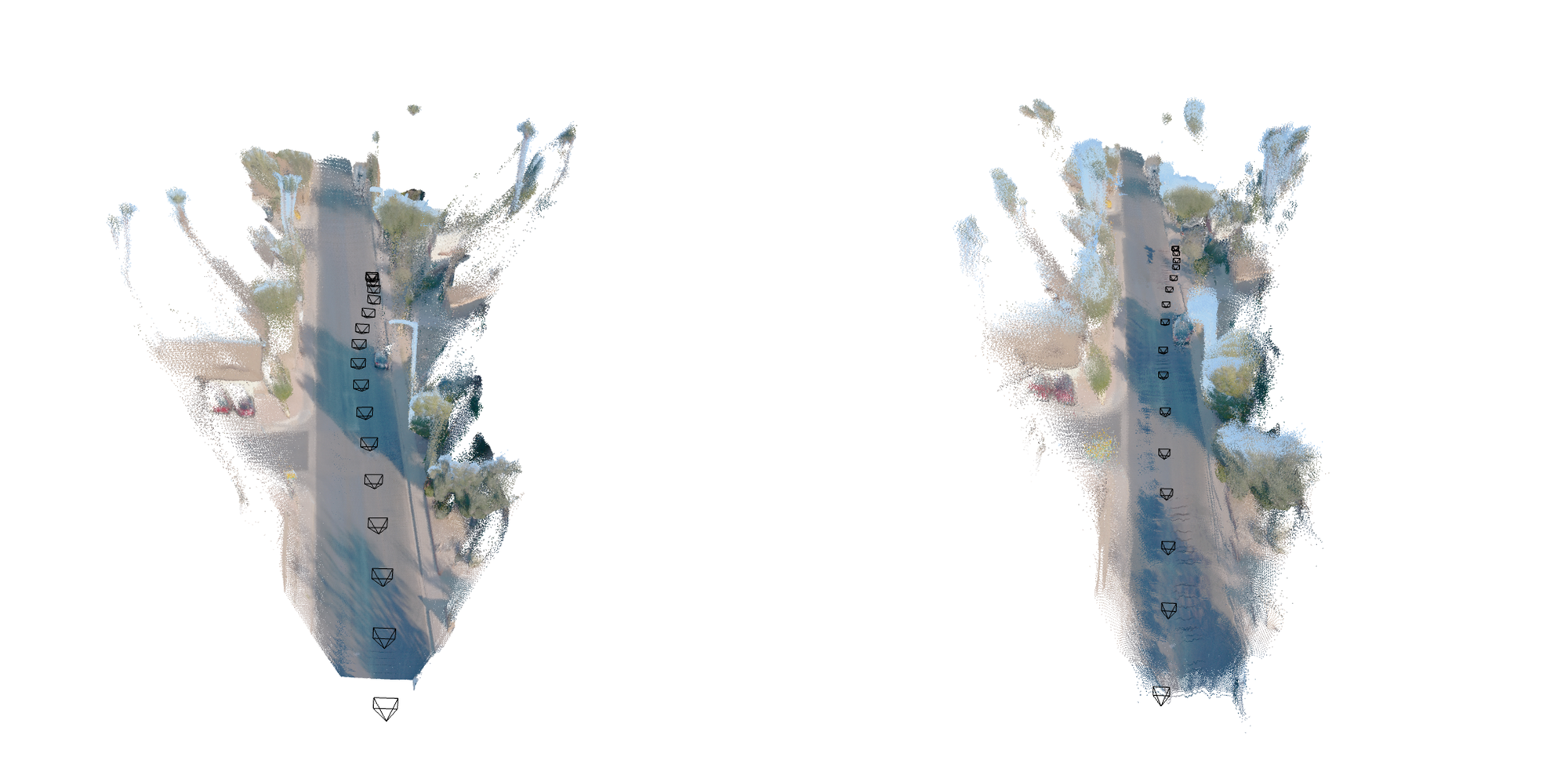



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “VGG‑T³: Offline Feed-Forward 3D Reconstruction at Scale”
1) What is this paper about?
This paper is about building 3D models of places from lots of regular photos (like pictures tourists take). Turning many 2D photos into a 3D scene is called 3D reconstruction. The big problem the paper tackles is speed and memory: most modern AI methods slow down a lot as you add more photos, because they keep comparing many things across all images.
The authors introduce VGG‑T³, a new way to reconstruct 3D scenes quickly, even with thousands of photos, without needing a supercomputer.
2) What questions are the researchers asking?
In simple terms, they ask:
- How can we make 3D reconstruction from many photos fast and memory‑efficient?
- Can we keep the good accuracy of powerful “global” models, but avoid the usual slowdowns?
- Can we store a scene in a compact form so we can also locate a new photo inside that scene later (visual localization)?
- Can we do all this on a single GPU and also speed up more with multiple GPUs?
3) How does their method work? (With easy analogies)
First, a quick picture of the usual approach:
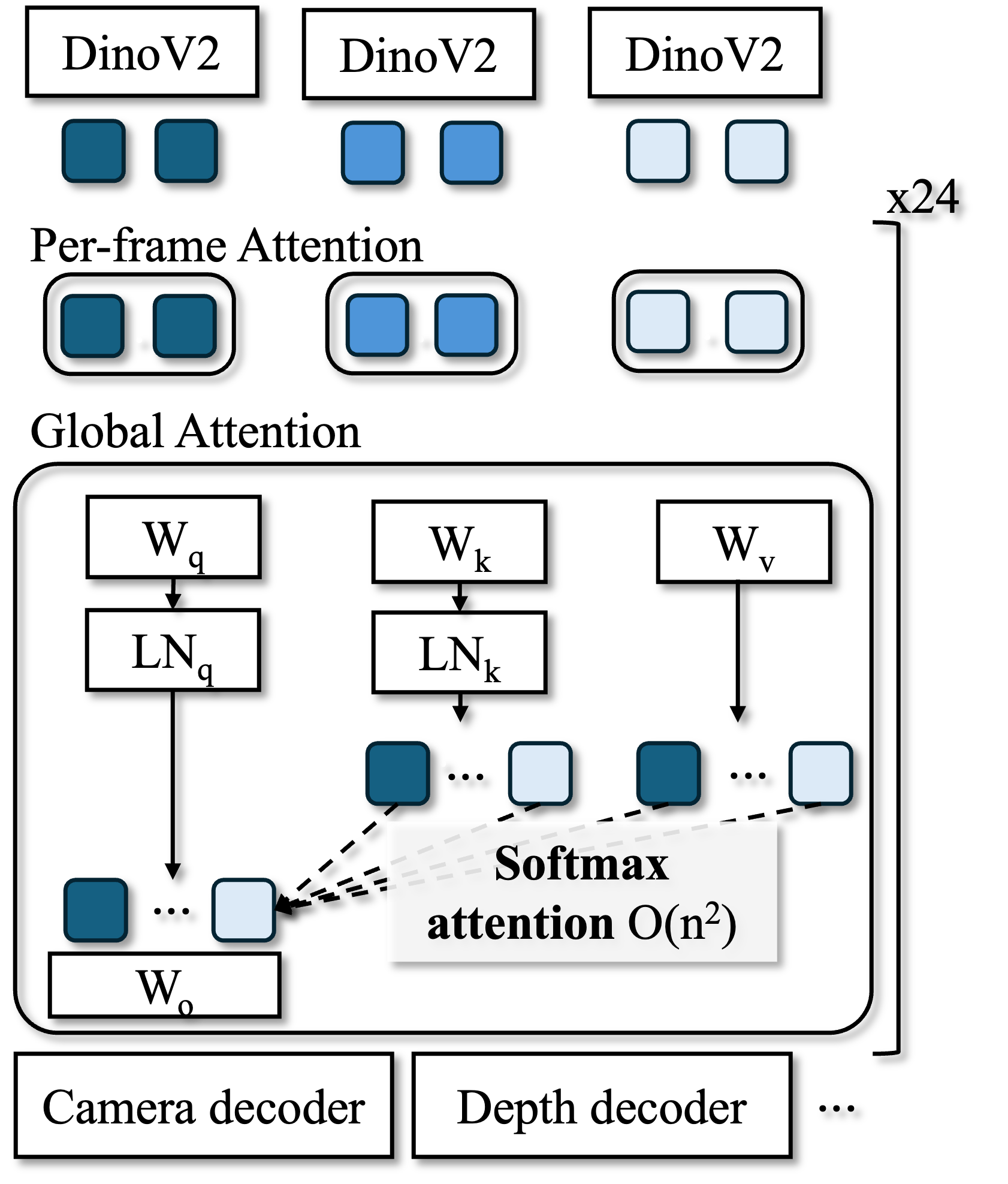
- Imagine each photo is turned into a bunch of “tokens” (little chunks of information).
- A popular model (a Transformer) tries to figure out how all these tokens from all photos relate. It does this with “attention,” which is like having a giant wall of sticky notes (a “Key‑Value” board) and, for every new question (a “Query”), scanning the whole wall to find matching notes.
- This scanning compares many pairs and gets very slow as you add more photos (time grows roughly with the square of the number of photos).
What VGG‑T³ changes:
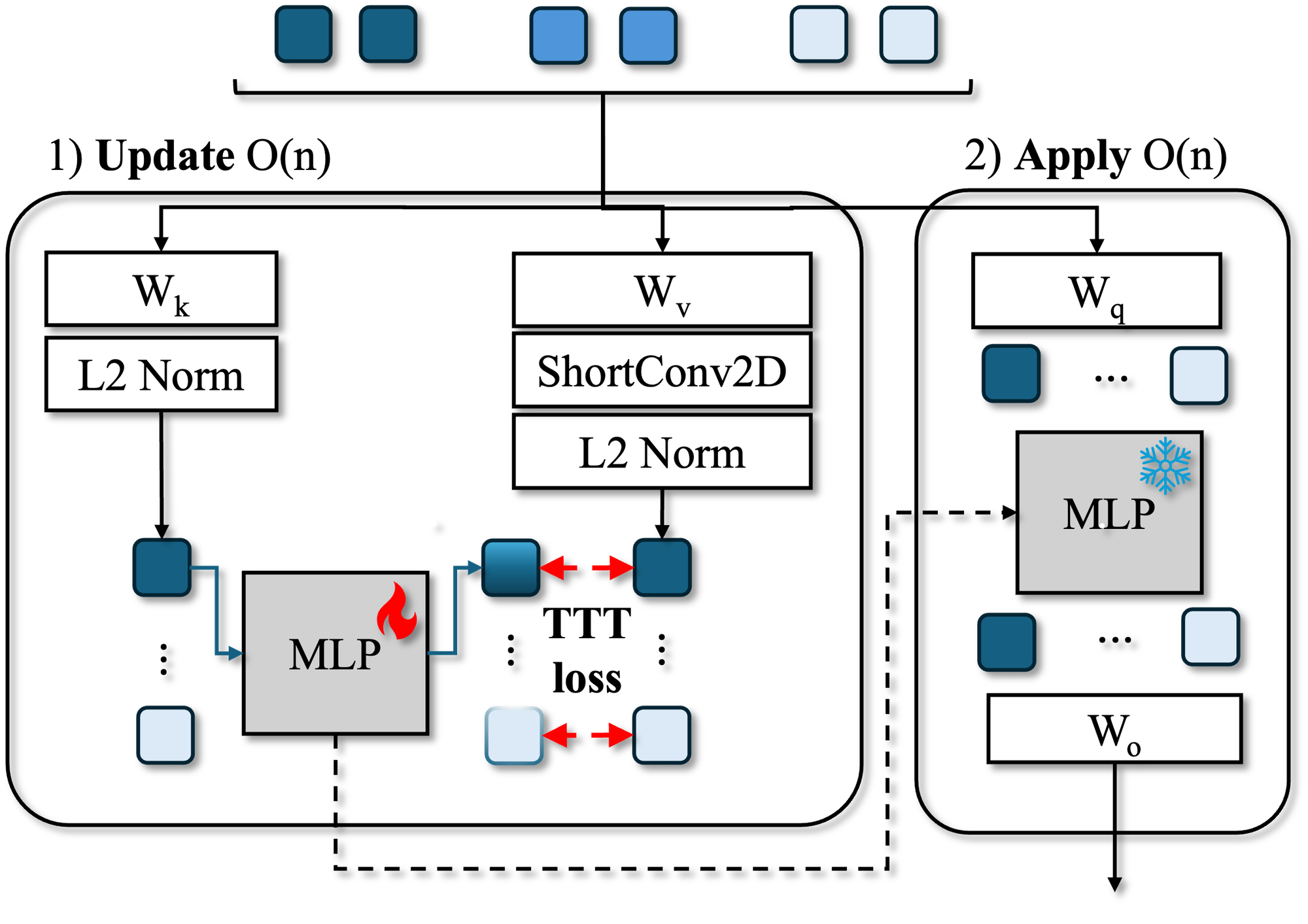
- Instead of keeping a huge wall of sticky notes that grows with your photo count, they compress everything into a small, fixed “handbook” about the scene. This “handbook” is a tiny neural network called an MLP (Multi‑Layer Perceptron).
- They create this handbook using a trick called test‑time training: right when you give the system your set of photos, it does a few quick “practice steps” to tune just this small MLP so it captures the scene’s important details. Think of it like building a compact index or map of the place from your photos.
- After that, answering questions (like predicting depth or camera position for each photo) is fast: instead of scanning a giant sticky‑note wall, you just look up answers in the small handbook. This makes the work grow linearly with the number of photos (add twice as many photos, take about twice as long), which is much better than the usual quadratic slowdown.
A few extra touches that help:
- Local mixing: They lightly “blend” nearby image features (a small 2D convolution) so the MLP learns richer, non‑trivial details instead of just copying inputs.
- Quick stabilization: They make small adjustments so the MLP learns quickly from a pre‑trained model.
- Scales with effort: For very big photo collections (like 1,000+ images), doing a couple more quick tuning steps at test time keeps quality high.
- Easy batching and multi‑GPU: Because the training objective is a simple sum over tokens, you can process photos in mini-batches on one GPU (or split across multiple GPUs) and combine the results, which saves memory and speeds things up.
4) What did they find, and why is it important?
Here are the key results in plain language:
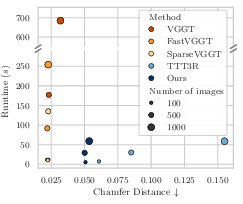
- Much faster at large scale: They reconstruct scenes with 1,000 images in under a minute, about 11.6× faster than a strong baseline that uses the usual attention.
- Linear scaling: Time and memory grow roughly in proportion to the number of photos, so you can handle much larger photo sets without running out of memory.
- Strong quality for geometry: Their 3D point maps and depth estimates are clearly better than other fast, linear‑time methods, and close to the slower, more expensive methods.
- Visual localization works: After building the scene “handbook,” you can feed in a new photo and the system can tell where that photo is in the 3D scene (it “localizes” the camera) without re‑training everything.
- Works on one GPU, faster on more: You can process huge photo sets on a single GPU by batching. If you have multiple GPUs, you get near‑linear speedups by splitting the work.
Why this matters:
- It makes city‑scale or landmark‑scale 3D reconstruction from lots of casual photos practical and fast.
- It reduces computing and memory costs, making this tech more accessible.
- It unifies mapping (building the 3D model) and localization (finding where a new photo fits) in one system.
A small caveat:
- For estimating camera poses, the method isn’t always as accurate as the heaviest, slowest models. But it’s still competitive, and it supports unordered photo collections (not just videos), which many fast methods struggle with.
5) What’s the bigger impact?
This approach shows that we can take accurate but slow 3D reconstruction models and “compress” their big memory into a small, scene‑specific brain at test time. That unlocks:
- Faster mapping of large places (tourist sites, campuses, museums) from crowdsourced images.
- Better scalability for AR/VR, robotics, and drones that need quick, reliable 3D understanding.
- A path to unified “map once, localize many times” systems that are simpler to use.
Looking ahead, the authors suggest improving how much detail the compact MLP can hold, aiming to match the very best (but slower) methods on every metric, including tricky camera‑pose cases.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Capacity and scaling laws for the fixed-size MLP scene representation:
- What is the maximum number of tokens/images (scene complexity) the MLP can reliably compress without losing essential global structure?
- How do accuracy and failure rates trade off with MLP width/depth, parameter count, and the number of global layers replaced?
- Develop empirical and theoretical capacity curves (error vs. tokens, baseline distribution, scene size).
- Convergence and stability of test-time training (TTT):
- No formal guarantees on convergence or stability across scenes; sensitivity to optimizer choice (Muon), learning rate, and initialization is uncharacterized.
- Automatic scheduling of TTT steps is missing; devise criteria or adaptive stopping rules tied to validation losses or gradient norms.
- Study robustness to noisy tokens and compute budget constraints (e.g., how many steps are needed under different scene sizes and content).
- Loss function design for K→V distillation:
- Dot-product loss is used without comparison to alternatives (e.g., contrastive, cosine, kernelized regression, NT-Xent, metric learning); benchmark which losses best preserve geometry and long-range dependencies.
- Investigate multi-objective formulations that incorporate downstream geometry consistency (e.g., depth consistency, epipolar constraints) during TTT.
- ShortConv2D spatial mixing design choices:
- Only a single-layer 2D conv is studied; ablate kernel sizes, strides, depth, residual connections, gated/SSM-style mixers, or multi-scale mixing.
- Theoretical justification is limited; analyze how mixing affects identifiability of the K→V mapping and mitigate trivial solutions formally.
- Handling heterogeneous tokens (camera vs image tokens):
- Camera pose estimation underperforms; test architectural variants (separate MLPs per modality, conditional/gated MLPs, cross-token adapters) to better memorize heterogeneous inputs.
- Quantify how heterogeneity disrupts K→V learning and whether modality-specific normalization or positional encoding helps.
- Visual localization scope and robustness:
- Evaluation is limited (Sim(3) alignment; 7Scenes/Wayspots); need tests on larger, more diverse, and cluttered outdoor datasets, including severe viewpoint/illumination changes, repetitive structures, and occlusions.
- Characterize failure modes, uncertainty estimates, and calibration of predicted poses; compare against strong SCR and feature-based baselines under identical constraints.
- Assess localization when queries are far outside mapped viewpoints and under scale ambiguities.
- Incremental/continual mapping and updating:
- The MLP is frozen after mapping; design and evaluate incremental updates (adding new images) without catastrophic forgetting.
- Explore merging multiple independent mapping sessions, conflict resolution, and memory management for long-term scenes.
- Generalization and domain shift:
- Linearization training is performed on a dataset “comparable to VGGT”; quantify cross-dataset/domain generalization (indoor→outdoor, synthetic→real, different cameras).
- Evaluate robustness to dynamic objects, non-pinhole intrinsics (e.g., rolling shutter, distortion), and adverse conditions (motion blur, low light).
- Scalability beyond 2k images and diverse in-the-wild collections:
- Teaser shows Rome landmarks; provide quantitative results on large, unordered tourist photo collections with weak overlap, including accuracy vs runtime and memory.
- Study linear scaling behavior under extreme sequence lengths (5k–50k images), including I/O and communication bottlenecks.
- Distributed inference characteristics:
- Analyze gradient synchronization overhead and throughput scaling (beyond 4 GPUs), including heterogeneous interconnects (PCIe vs NVLink) and all-to-all patterns.
- Provide guidelines for sharding strategies (by tokens vs images) and optimal batch sizes under memory constraints.
- Tokenization and resolution effects:
- The impact of tokenizer patch size (), image resolution, and token dimensionality on TTT convergence and final accuracy is not ablated.
- Investigate multi-scale tokenization to better capture wide-baseline contexts without overloading the MLP.
- Uncertainty and confidence in geometry/pose:
- No uncertainty estimation is provided; develop calibrated confidence for depth, point maps, and poses to enable downstream robust pipelines (PnP, BA).
- Integration with explicit geometric optimization:
- Explore hybrid pipelines that refine feed-forward outputs with lightweight BA/SfM, and measure runtime/accuracy trade-offs vs pure feed-forward.
- Determine whether the MLP state can initialize or inform explicit map representations (e.g., point clouds, meshes).
- Alternative linearization mechanisms:
- Compare TTT-based MLP compression against linear attention kernels, SSMs (S4, Hyena, Mamba), and gated variants within the same multi-view setting.
- Determine when each linearization family better preserves global aggregation and wide-baseline performance.
- Positional and relational encoding:
- Investigate positional encodings or graph/topology-aware mixing to help the MLP disambiguate repeated textures and long-range correspondences.
- Analyze collisions in K-space (similar keys for different geometry) and propose disambiguation mechanisms.
- Camera intrinsics estimation:
- The paper mentions intrinsics prediction but does not evaluate its accuracy; add dedicated metrics and analyze sensitivity to intrinsics errors.
- Effects of removing LayerNorm and using normalization:
- Provide a systematic study of normalization choices on training/inference stability, especially under domain shifts and high sequence lengths.
- Examine whether partial retention of LN (e.g., in value or output projections) improves convergence without harming linearization.
- Map compression vs fidelity trade-offs:
- Quantify what geometric details are lost during KV→MLP compression (fine structure, thin objects) and propose adaptive capacity (e.g., sparsity-aware MLP, mixture-of-experts) to preserve fidelity.
- Evaluation breadth and reproducibility:
- Expand benchmarks to include wide-baseline datasets (e.g., MegaDepth, PhotoTourism) and release code/metrics for standardized comparison.
- Report variance across seeds and runs for TTT, including sensitivity to initial MLP weights and number of optimization steps.
Glossary
- Absolute Relative Error (Abs. Rel.): A depth estimation metric that measures the average of absolute differences between predicted and ground-truth depths normalized by ground-truth depth. Example: "report the Absolute Relative Error (Abs. Rel.) as well as the percentage of predictions with ."
- Absolute Trajectory Error (ATE): A metric quantifying global drift in estimated camera trajectories compared to ground truth. Example: "ATE "
- All-to-all communication: A parallel computing pattern where every process or device exchanges data with all others, used here to synchronize small model parameters across GPUs. Example: "by performing all-to-all communication which is efficient due to their small size."
- Auto-regressive: A processing paradigm where each new output depends on previously processed inputs, often used for sequential data. Example: "Several methods process image sequences in an auto-regressive fashion."
- Block-sparse attention: An attention mechanism that restricts computations to predefined blocks of the attention matrix, reducing complexity and memory. Example: "SparseVGGT \cite{wang_faster_2025} employs block-sparse attention."
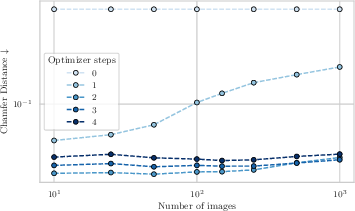
- Chamfer Distance: A symmetric distance measure between two point sets, commonly used to evaluate 3D reconstruction quality. Example: "using Chamfer Distance and Normal Consistency~\cite{wang_3d_2025} to assess the quality of the reconstructed points and surfaces, respectively."
- Distributed inference: Performing model inference across multiple devices (e.g., GPUs) to accelerate processing or handle larger inputs. Example: "perform distributed inference by sharding image tokens across multiple GPUs."
- FlashAttention: A memory-efficient algorithm for computing attention by tiling and reordering operations to reduce memory traffic. Example: "using FlashAttention~\cite{dao_flashattention_2022}"
- Global self-attention: A Transformer mechanism that allows each token to attend to all tokens across all inputs, enabling global context aggregation. Example: "the global self-attention layer."
- Key-Value (KV) space: The set of key and value vectors stored during attention that collectively serve as an implicit memory or scene representation. Example: "varying-length Key-Value (KV) space representation of scene geometry"
- KV caching: Storing previously computed keys and values for reuse to accelerate attention over long sequences. Example: "require memory-intensive KV caching to accelerate inference."
- LayerNorm (LN): A normalization technique applied across feature dimensions to stabilize and accelerate training in deep networks. Example: "LayerNorm (LN)"
- Linear attention: Attention mechanisms that replace the softmax kernel with linear feature maps to achieve linear-time computation with sequence length. Example: "Linear attention methods address this by replacing the softmax kernel with linear feature maps, yielding linear-time, constant-memory recurrences"
- Multi-Layer Perceptron (MLP): A feed-forward neural network composed of fully connected layers and nonlinear activations. Example: "fixed-size Multi-Layer Perceptron (MLP)"
- Normal Consistency: A metric assessing the consistency of surface normals between reconstructed and ground-truth geometries. Example: "using Chamfer Distance and Normal Consistency~\cite{wang_3d_2025} to assess the quality of the reconstructed points and surfaces, respectively."
- Perspective-n-Point (PnP) solver: An algorithm to estimate camera pose from n 3D-2D point correspondences. Example: "Perspective-n-Point (PnP) solver~\cite{ke2017p3p, kneip2011p3p} to compute the final camera pose."
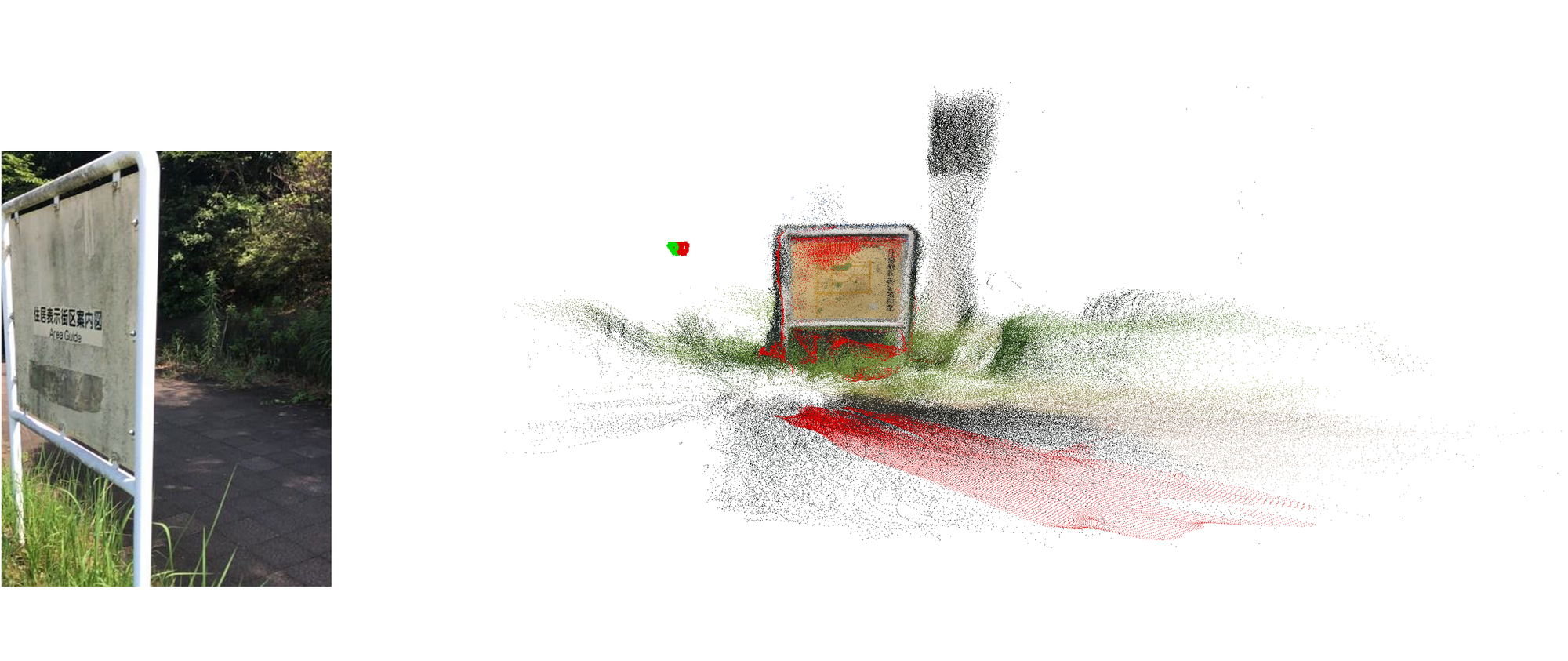
- Pointmap: A per-pixel mapping from image coordinates to 3D points, used to evaluate reconstruction fidelity. Example: "Pointmap estimation on dense (-D) and sparse (-S) split."
- Post-training linearization: Converting a trained Transformer into a linear-complexity model via adaptation or distillation without retraining from scratch. Example: "post-training linearization, converting pretrained transformers into linear-complexity models via lightweight adaptation or distillation"
- QK normalization: Normalizing query and key vectors (often with LayerNorm or L2 norms) to stabilize attention computations. Example: "performing QK normalization~\cite{dehghani_scaling_2023,henry_query-key_2020} to stabilize training."
- Query, key, and value (QKV) vectors: The three projected representations of tokens used in attention to compute similarity (QK) and aggregate information (V). Example: "query, key, and value (QKV) vectors"
- Ring attention: A context-parallel distributed attention approach that partitions and circulates context across devices to compute large-context attention. Example: "context-parallel implementations for softmax attention (e.g., ring attention~\cite{liu_ring_2023})"
- SE(3): The Special Euclidean group in 3D representing 3D rotations and translations (rigid motions). Example: "rotation "
- ShortConv2D: A short-range 2D convolution used for spatial mixing of token features to enrich local context before attention or mapping. Example: "we additionally apply an ShortConv2D on for non-linear spatial mixing."
- Sim(3) alignment: Alignment using a similarity transform in 3D (rotation, translation, and uniform scale) to compare predicted and ground-truth poses/maps. Example: "We perform Sim(3) alignment between the ground truth and predicted poses"
- Softmax attention: The standard attention mechanism that uses softmax-normalized similarity scores between queries and keys to weight values. Example: "softmax attention"
- State-space models (SSMs): Recurrent models that update a hidden state using structured linear dynamics to capture long-range dependencies. Example: "State-space models (SSMs) offer an alternative recurrent formulation"
- SwiGLU: A gated activation function (Switchable Gated Linear Unit) that improves MLP expressivity and training stability. Example: "our TTT layer uses a SwiGLU MLP~\cite{shazeer_glu_2020}"
- Test-time training (TTT): The procedure of adapting a model at inference time by optimizing a subset of parameters using self-supervised losses on the test input. Example: "test-time training (TTT)"
- Token merging: A technique to compress sequences by merging similar tokens to reduce computational cost while preserving information. Example: "token merging~\cite{shen_fastvggt_2025}"
- Visual localization: Estimating the pose of a query image within a known scene representation or map. Example: "feed-forward visual localization"
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, given access to the released VGGT checkpoint, modern GPU hardware, and typical photogrammetry/vision tooling. Each item includes key assumptions or dependencies that affect feasibility.
- Large-scale photogrammetry acceleration (architecture, construction, surveying)
- Use VGG‑T³ to ingest thousands of site photos (including unordered and unposed imagery) and produce dense depth maps, point maps, and estimated camera poses in minutes; post-process with existing meshing tools (e.g., Poisson reconstruction) to deliver CAD/BIM-ready assets.
- Workflow: photo collection → VGG‑T³ test-time training (TTT) compresses KV into scene MLP → depth/point map export → mesh generation and alignment → QA.
- Dependencies: sufficient view overlap and coverage; quality/stability of camera pose predictions (noted to be weaker than softmax-attention baselines); GPU access for linear-time inference; rights to imagery; pre-trained VGGT weights.
- Rapid cultural heritage reconstruction from crowd-sourced images (museums, tourism boards)
- Reconstruct landmarks (e.g., Rome examples) from large tourist photo collections under a strict time budget, enabling quick digitization and public dissemination.
- Tools/products: “Landmark Snapshot” service; integration with photogrammetry suites and digital archives.
- Dependencies: robust handling of unordered, uncalibrated photos; legal consent and licensing of public images; QA for geometric fidelity in wide-baseline scenarios.
- Emergency and disaster response mapping (public safety, policy)
- Rapidly create situational 3D maps from ad-hoc images captured by first responders or citizens, providing coarse yet timely scene understanding for coordination.
- Workflow: collect images → one-pass VGG‑T³ reconstruction → export point cloud for measurement and planning → share with command centers.
- Dependencies: minimal curation time, upstream image quality; data privacy/security protocols; acceptance of approximate camera poses for time-critical decisions.
- Drone and bodycam video-to-3D conversion (inspection, infrastructure)
- Convert long videos into dense depth/point maps with linear-time scaling, enabling near-real-time turnaround for structural inspection, site monitoring, or asset auditing.
- Tools/products: pipeline extension for existing UAV/bodycam platforms; automatic meshing and anomaly tagging downstream.
- Dependencies: adequate visual overlap; hardware acceleration; sequence chunking not required; post-processing tolerance for pose/metric scale alignment.
- Environment asset creation for media (film, gaming, VFX)
- Speed up environment capture from stills and mixed photo/video sets; use distributed inference across GPUs for studio-scale datasets.
- Tools/products: DCC plugins (Blender/Unreal) to import VGG‑T³ outputs; “Linear Recon Cloud” service tier for studio pipelines.
- Dependencies: GPU/cloud capacity; meshing and material authoring workflows; pose accuracy constraints for high-precision shots.
- AR anchor generation and feed-forward visual localization (retail, venue experiences)
- Precompute per-venue MLP “scene capsules” and enable on-site camera relocalization for new query images without database matching (unified mapping + localization).
- Tools/products: “Map Capsule” files for venues; SDK to query frozen MLP for single-image localization; coarse AR anchor placement.
- Dependencies: prior mapping phase (TTT optimization per scene); current limitations in pose accuracy (works for experiences tolerant to a few cm/deg error); scene updates require re-optimization.
- Warehouse/industrial guidance (operations, robotics-adjacent)
- Coarse visual relocalization from handheld or robot-mounted cameras relative to a prebuilt scene MLP to aid navigation and inventory checks in static environments.
- Tools/products: on-prem “SnapshotMap” for mapped zones; workflow to re-query frozen MLPs during shifts.
- Dependencies: scene stability; requirement for tighter pose accuracy for autonomous motion may still favor classical SLAM; routine remapping for layout changes.
- Cloud service for one-pass, linear-time reconstruction (software/SaaS)
- Offer VGG‑T³ inference as a service with auto-sharded, multi-GPU distributed TTT and CPU offloading, delivering linear speed-ups and avoiding OOM on large sets.
- Tools/products: API endpoints for upload → MLP optimization → export (depth, point map, camera poses); usage-based billing.
- Dependencies: scalable orchestration; gradient synchronization across GPUs; customer-provided image rights; standardized output formats.
- Academic research integration (computer vision, ML systems)
- Use VGG‑T³ as a testbed for post-training linearization and TTT-based memory compression in multi-view reconstruction; study sequence-length generalization via increased TTT steps.
- Tools/workflows: open checkpoints and scripts; benchmarks (NRGBD, 7Scenes, DTU, ETH3D, KITTI); ablation of ShortConv2D mixing and LN→L2 normalization choice.
- Dependencies: reproducible training/inference setup; access to datasets; comparative baselines.
- Energy- and cost-efficient compute (energy, sustainability, HPC operations)
- Replace quadratic-attention recon pipelines with linear-time VGG‑T³ to cut latency and cloud costs for large scenes, lowering compute-related carbon footprint.
- Tools/products: procurement guidance and ops dashboards showing speed/energy improvements.
- Dependencies: workload characteristics (image counts, scene complexity); quantifiable KPI alignment.
- Consumer/lifestyle room scanning on a GPU-enabled laptop
- Reconstruct rooms rapidly from phone photos for remodeling, furniture planning or virtual tours; export to common formats compatible with popular apps.
- Workflow: capture 50–300 images → local VGG‑T³ run → mesh export → share.
- Dependencies: local GPU (e.g., gaming laptops); sufficient overlap; pose accuracy tolerance for measurements; post-processing.
Long-Term Applications
These use cases are feasible with further research, scaling, or engineering—particularly in improving camera pose accuracy, handling wider baselines, dynamic scenes, and making on-device deployment practical.
- Real-time, on-device mapping and localization for AR glasses and mobile (AR/VR, consumer hardware)
- Push VGG‑T³’s compressed MLP state to low-power devices for continual query and lightweight updates; enable room- or venue-scale AR anchors without server-side retrieval.
- Needed advances: higher-precision camera pose heads; efficient kernels for TTT/ShortConv2D; model quantization; incremental MLP updates.
- City-scale reconstruction from social media and public imagery (urban planning, policy)
- Continuously aggregate crowd-sourced photos to maintain up-to-date 3D city models; snapshot MLPs for districts that can be queried by civic apps.
- Needed advances: robust wide-baseline performance; data governance for public imagery; deduplication and bias control; legal/privacy frameworks.
- Unified offline-to-online SLAM hybrid for robotics (robotics, autonomy)
- Use VGG‑T³ to build a high-quality global map offline, then provide the compressed scene memory to an online SLAM loop for drift-free navigation and re-localization.
- Needed advances: tighter and reliable pose estimation under motion blur and textureless scenes; handling dynamics; APIs for SLAM memory interchange.
- Queryable scene memory databases (software, search)
- Store per-scene MLP “capsules” in a registry; support direct feed-forward localization queries instead of feature matching, enabling instant location-aware services.
- Needed advances: standardized capsule format; indexing, versioning and security; cross-scene routing; compositional maps.
- Federated and privacy-preserving mapping (policy, software)
- Distribute TTT across edge devices; aggregate gradients centrally without sharing raw images; enable privacy-conscious mapping of sensitive spaces.
- Needed advances: secure gradient aggregation; differential privacy; device heterogeneity support; regulatory compliance.
- Edge AI acceleration and model compression (semiconductors, embedded)
- Develop specialized hardware paths and kernels for linearized attention + ShortConv2D; deliver high throughput with strict power budgets.
- Needed advances: compiler/runtime support; memory-efficient MLP representations; mixed-precision stability; hardware vendor ecosystem.
- Open standards for compressed scene representations (consortia, standards bodies)
- Define an interchange format for per-scene MLP states, camera/geometry outputs, and query protocols to plug into AR Cloud, GIS, and DCC tools.
- Needed advances: multi-stakeholder specification effort; reference implementations; conformance suites.
- Medical multi-view reconstruction (healthcare)
- Adapt the linearized approach to endoscopic or intraoperative imaging to reconstruct anatomy from limited, unposed views swiftly.
- Needed advances: domain-specific training, safety validation, regulatory approval (e.g., FDA/CE), robustness to occlusions and specularities.
- Education and training (academia, edtech)
- Develop interactive labs to teach attention linearization, test-time training, and multi-view geometry at scale; students can reconstruct real scenes with modest hardware.
- Needed advances: curricular material, managed cloud labs, streamlined dataset licensing.
- Property appraisal and remote inspections (finance, insurance)
- Use large photo sets to create 3D property models for rapid risk and value assessments.
- Needed advances: tighter metric fidelity and pose accuracy; standards for auditability; integration into underwriting workflows.
Cross-cutting assumptions and dependencies
- Pre-trained VGGT weights and access to GPUs (single or multi-GPU) for TTT and inference; CPU offloading helps single-GPU scenarios.
- Image collections must have reasonable visual overlap/connectivity; unordered inputs are supported but extreme wide-baseline setups may reduce accuracy.
- The compressed MLP’s expressivity is fixed; accuracy gaps vs. quadratic attention persist (especially in camera pose). Additional TTT steps improve scaling but not arbitrarily.
- Downstream meshing, alignment, and QA remain necessary; metric scale alignment (e.g., Sim(3)) may be required depending on use case.
- Legal and ethical considerations for using public or employee-captured imagery (consent, privacy, IP) must be addressed, particularly for city-scale and emergency deployments.
Collections
Sign up for free to add this paper to one or more collections.