XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
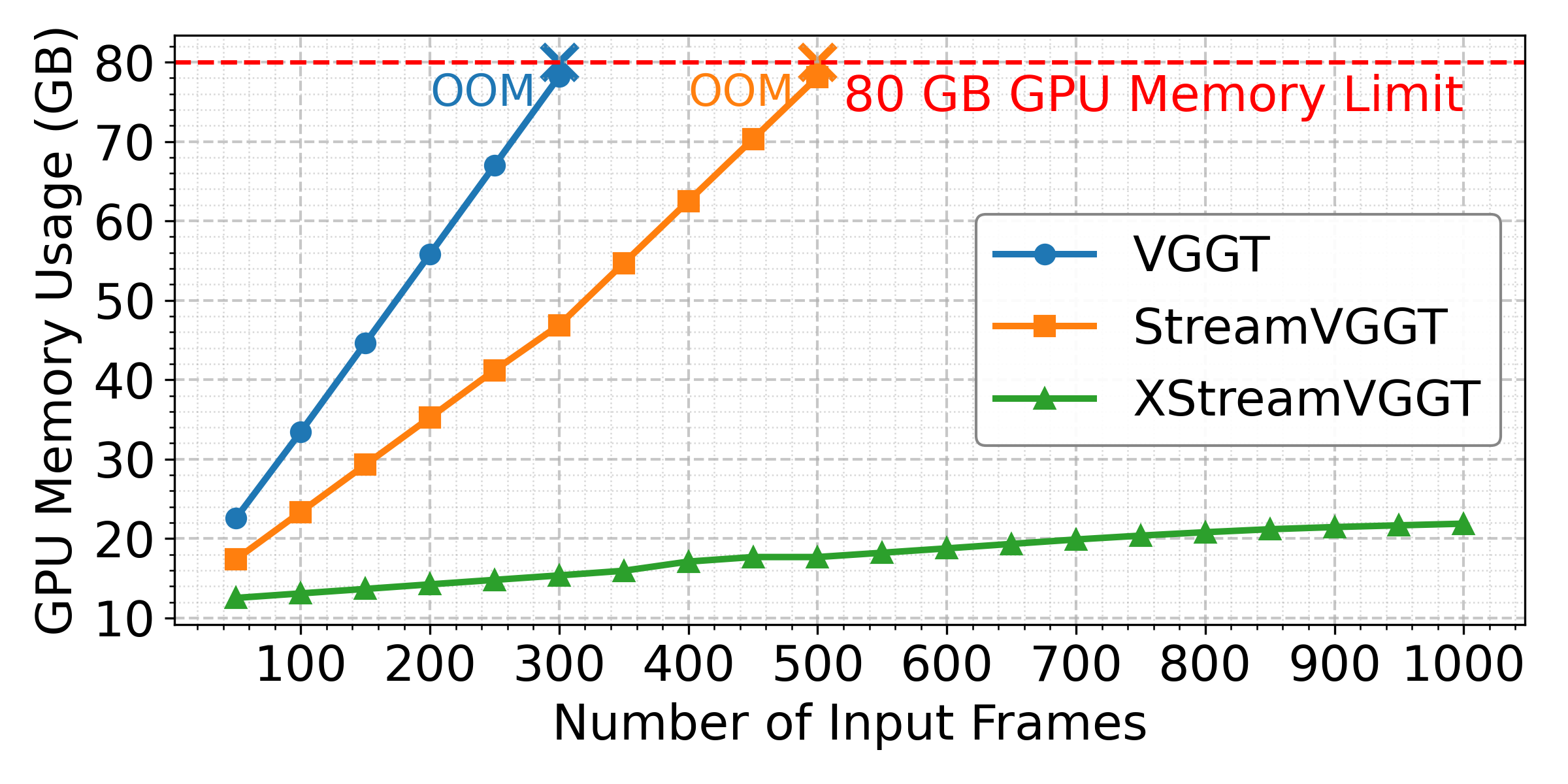
Abstract: Learning-based 3D visual geometry models have significantly advanced with the advent of large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention to deliver robust and efficient streaming 3D reconstruction. However, it suffers from unbounded growth in the Key-Value (KV) cache due to the massive influx of vision tokens from multi-image and long-video inputs, leading to increased memory consumption and inference latency as input frames accumulate. This ultimately limits its scalability for long-horizon applications. To address this gap, we propose XStreamVGGT, a tuning-free approach that seamlessly integrates pruning and quantization to systematically compress the KV cache, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs generated from multi-frame inputs are initially pruned to conform to a fixed KV memory budget using an efficient token-importance identification mechanism that maintains full compatibility with high-performance attention kernels (e.g., FlashAttention). Additionally, leveraging the inherent distribution patterns of KV tensors, we apply dimension-adaptive KV quantization within the pruning pipeline to further minimize memory overhead while preserving numerical accuracy. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42$\times$ and accelerating inference by 5.48$\times$, enabling practical and scalable streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces XStreamVGGT, a faster and more memory‑efficient way for computers to build 3D scenes from videos, frame by frame. It improves a powerful 3D vision system called StreamVGGT by shrinking its “memory” so it can handle long videos without slowing down or crashing.
Key Objectives
The researchers set out to:
- Stop the system’s memory from growing uncontrollably as it watches more video frames.
- Keep the 3D results accurate while using much less memory.
- Make the system run faster so it’s practical for real-time tasks like robotics or augmented reality.
How Did They Do It?
Think of StreamVGGT like a student taking notes while watching a video. For every frame, it writes “Key” and “Value” notes (KV) that help it remember what it saw. Over time, these notes pile up. The more frames it sees, the bigger its notebook gets—until it gets too heavy to carry (uses too much memory), and the student slows down.
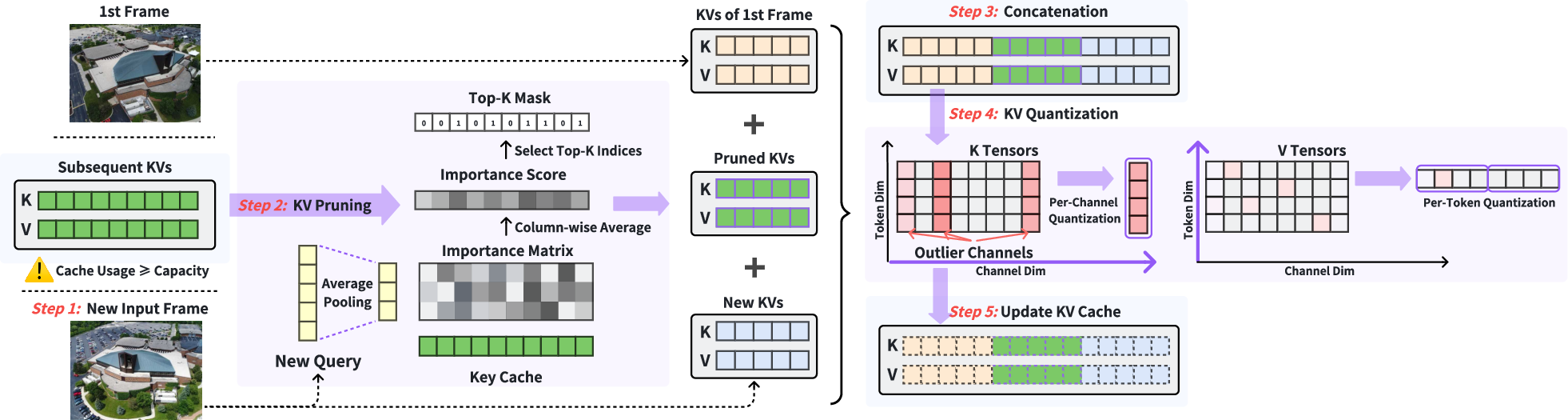
XStreamVGGT fixes this using two ideas: pruning and quantization.
- Pruning (keeping only the most useful notes)
- Imagine the student reviews the notebook and throws away pages that aren’t helpful anymore.
- The system quickly measures how important old notes are compared to what the current frame needs.
- It always keeps notes from the very first frame (as a reference for the scene) and from the current frame (the latest view), and then chooses only the most important notes from the middle frames.
- This puts a firm limit on notebook size, so memory stays under control even for long videos.
- Quantization (compressing the notes)
- Now imagine writing smaller, simpler numbers to save space—like rounding measurements to fewer digits but still keeping them useful.
- The system noticed that “Keys” (part of the notes) have some channels with unusually large values (called outliers), while “Values” are more evenly spread.
- So it uses different compression styles:
- Per-channel quantization for Keys: compress each channel separately to handle those outliers better.
- Per-token quantization for Values: compress each note (token) as a whole since Values don’t have big outliers.
- This smart compression saves memory while keeping accuracy high.
Together, pruning and quantization make the system lightweight without needing extra training or complicated tuning.
Main Findings
- Much lower memory use: 4.42× less than the original streaming system.
- Much faster: 5.48× speedup during inference (the part where the model makes predictions).
- Accuracy is mostly unchanged across key tasks:
- 3D reconstruction (building point clouds of scenes)
- Camera pose estimation (figuring out where the camera is and how it’s oriented)
- Depth estimation (how far things are from the camera), including both single images and videos
In short, the system runs faster and uses less memory while keeping the 3D results very close to the original.
Why It Matters
This research makes long, real-time 3D understanding practical. That’s important for:
- Robots navigating rooms or factories
- Augmented reality apps that place virtual objects in real spaces
- Self-driving cars and drones that need quick, reliable 3D perception
By controlling memory growth and keeping speed high, XStreamVGGT helps powerful 3D vision systems scale to long videos and complex scenes—without breaking or slowing down.
Knowledge Gaps
Below is a consolidated list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is phrased to be concrete and actionable for future work.
- Lack of baseline comparisons: No empirical comparison against alternative KV cache compression strategies (e.g., recency-based eviction, reservoir sampling, attention-score–based pruning with kernel modifications, RotateKV/AKVQ/other LLM quantizers) on 3D streaming models to contextualize the gains of XStreamVGGT.
- Limited evaluation scope for long-horizon accuracy: While efficiency is tested up to 1000 frames, accuracy is reported only for relatively short sequences (e.g., 90 frames for camera pose). Stability and drift over thousands of frames remain unmeasured.
- Static anchor frame policy: Always preserving the first-frame KVs may be suboptimal in dynamic or long sequences. No analysis or mechanism for adaptive anchor refresh (e.g., periodically updating the “reference” frame based on motion/scene change).
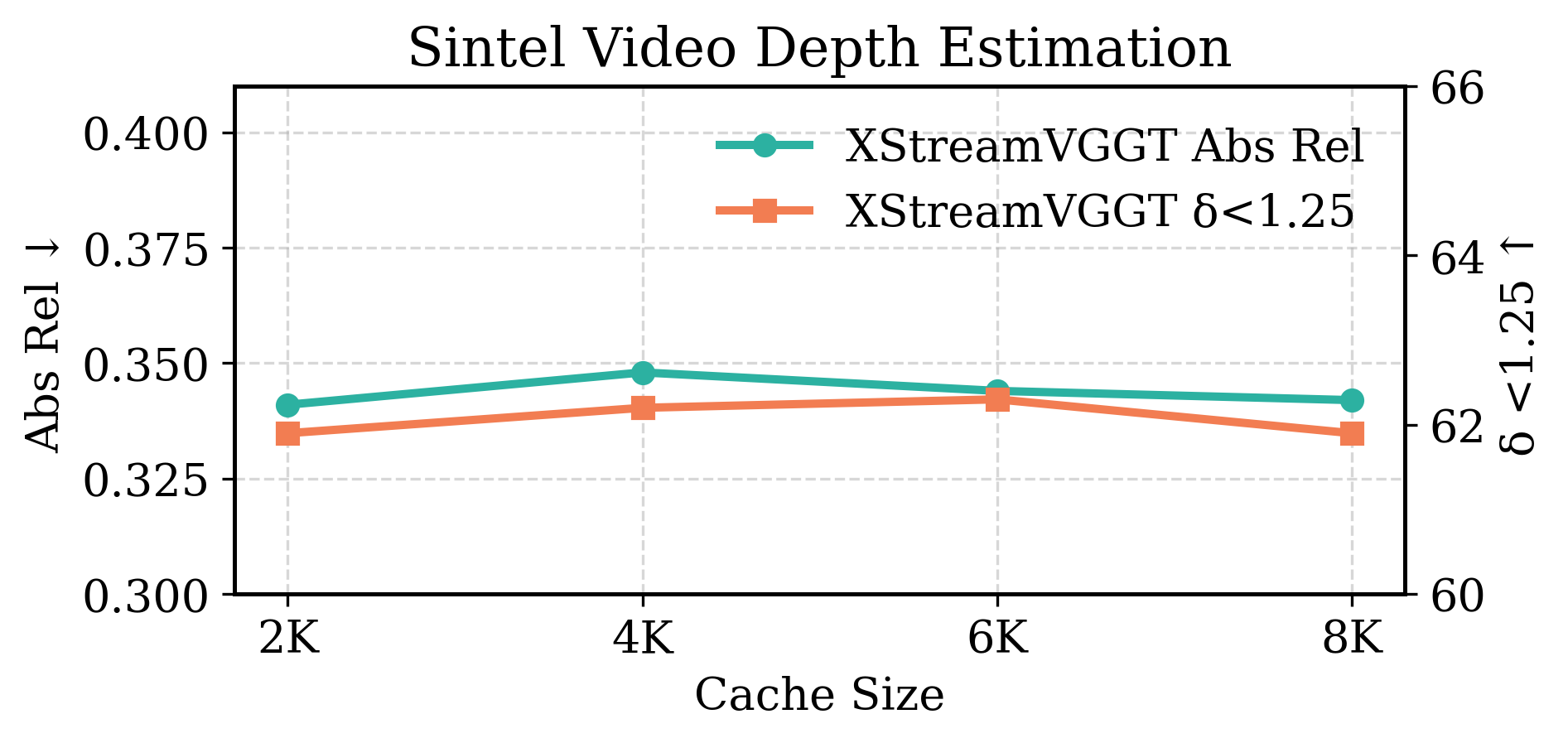
- Fixed cache budget and hyperparameters: Cache length (2K), query pooling size (g=16), and quantization group size (64) are fixed. There is no sensitivity analysis or adaptive strategy to tune these per scene, per layer, or over time.
- Token-type–aware pruning not studied: Camera and register tokens are treated uniformly in pruning for middle frames, despite their distinct roles. The impact of selectively preserving or pruning special tokens per task (pose/depth/pointmaps) is not evaluated.
- Importance scoring design not validated: Query-pooled inner-product scoring is adopted for compatibility with FlashAttention, but its efficacy versus alternatives (e.g., approximate attention scores, gradient-based saliency, diversity-aware selection) is not benchmarked or theoretically justified.
- Overhead of importance scoring unquantified: The compute/memory overhead of generating pooled queries, head-averaged keys, and inner-product scores (especially at high frame counts) is not isolated in the speedup analysis.
- Layer-wise heterogeneity ignored: Pruning is applied independently per layer with uniform logic and budget. Whether certain layers contribute more to performance and should receive larger budgets or different scoring is unexplored.
- Causes of Key channel-wise outliers: The observed outlier behavior in Key channels is characterized but not investigated (e.g., role of positional encoding, normalization, projection matrices). Model-side interventions to reduce outliers are not explored.
- Quantization calibration choices: Asymmetric min–max calibration is used; robust calibration methods (percentile clipping, histogram-based, log-domain scaling) and their effects on accuracy and stability are not evaluated.
- Integer-domain attention not leveraged: Dequantization precedes attention computation, leaving multiply–accumulate operations in floating point. Feasibility and benefits of integer-domain attention kernels (e.g., INT8 matmul with mixed-precision softmax) are unstudied.
- Lower bit-width viability untested end-to-end: While INT2 errors are measured offline, full system experiments with INT2 (and mixed-precision per layer/head) are absent; the practical accuracy–memory–speed trade-off for ultra-low bits remains unknown.
- Group size and per-head granularity: The chosen quantization group size (64) and head-averaging assumptions are fixed. Effects of varying group sizes, per-head/per-head-per-channel quantization, and cross-head heterogeneity are not analyzed.
- Diversity-aware retention for future relevance: The pruning policy favors tokens similar to current queries, potentially dropping rare or long-range context tokens needed in upcoming frames. Diversity/coverage-aware selection strategies are not considered.
- Task-specific effects of pruning/quantization: Drops are more noticeable for video depth and 7-Scenes NC, but root causes (temporal dependence versus sensitivity to token types) are not dissected; no per-task pruning/quantization policies are proposed.
- Breakdown of speed gains: The contributions of pruning, quantization, reduced KV IO, cache reallocation, and kernel-level effects to the overall 5.48× speedup are not disentangled, making it hard to prioritize optimizations.
- Hardware and deployment breadth: Experiments are limited to a single 80GB A100 GPU. Performance, memory, and latency on consumer GPUs, edge devices, multi-GPU setups, or CPU inference are not reported.
- Attention-kernel portability: Compatibility claims are centered on FlashAttention; portability to other efficient attention kernels and the minimal API required for importance scoring are not specified.
- Robustness across scene challenges: Behavior under rapid motion, severe occlusions, lighting changes, moving objects (e.g., Bonn dynamics), and camera shake is not systematically analyzed with stress tests specifically targeting pruning/quantization failure modes.
- Per-layer cache coordination: Indices are applied per layer independently; coordinated, global cache management across layers (e.g., allocating larger budgets to deeper layers) and its impact on performance is unexamined.
- Training-side strategies missing: Quantization-aware training or pruning-aware fine-tuning to reduce end-to-end degradation (especially for lower bit widths) is not investigated, despite being a common remedy in quantized systems.
- Generalization to other architectures: Applicability to other streaming 3D models (e.g., CUT3R, TTT3R, Point3R variants) and to non-VGGT transformer designs remains untested.
- Resolution and tokenization scaling: Effects of higher resolutions, different patch sizes, and alternative tokenization schemes on KV redundancy, pruning efficacy, and quantization stability are not assessed.
- Memory management details: Potential GPU memory fragmentation, cache reallocation overhead, and latency variance introduced by dynamic prune–quantize operations are not reported.
- Reproducibility details: Precise dataset splits, pretrained checkpoints, and kernel/driver versions required to reproduce OOM behavior and efficiency numbers are not fully specified, complicating independent verification.
Practical Applications
Immediate Applications
Below are actionable, deployment-ready use cases that leverage XStreamVGGT’s tuning-free KV pruning and dimension-adaptive quantization to enable memory-bounded, fast streaming 3D perception with minimal accuracy loss.
- Robotics (mobile, industrial, drones)
- Application: Real-time 3D perception (depth, point maps, camera pose) for navigation, SLAM, obstacle avoidance, and manipulation on edge GPUs and compact onboard computers.
- Tools/workflows: ROS2 node wrapping XStreamVGGT; pipeline “camera → patch embedding → streaming transformer → pose/depth/point map → planner”; integration with GPU-optimized attention (FlashAttention) and Triton/TensorRT for serving.
- Assumptions/dependencies: GPU or high-end edge compute with support for efficient attention kernels; availability of StreamVGGT/VGGT weights; camera calibration optional but beneficial; sequence quality similar to evaluated datasets.
- AR/VR on mobile devices
- Application: Room-scale scanning, occlusion-aware rendering, and persistent AR anchors with bounded memory over long sessions.
- Tools/products: Mobile SDK plugin for ARKit/ARCore; Unity/Unreal integration for live depth/point maps; background KV management with a fixed budget (e.g., 2K) and INT4 quantization.
- Assumptions/dependencies: Sufficient device compute; battery and thermal constraints; stable video capture at moderate resolutions; acceptable minor accuracy trade-offs.
- Autonomous driving (perception stack)
- Application: Low-latency camera pose and depth estimation for long-horizon driving scenes without OOM failures or FPS collapse.
- Tools/workflows: On-vehicle inference nodes with bounded KV cache; integration into perception fusion (e.g., multi-sensor SLAM); adherence to real-time latency budgets.
- Assumptions/dependencies: Automotive-grade GPUs/accelerators; robustness to motion blur and dynamic scenes; compliance with safety standards.
- Construction, inspection, and AEC
- Application: Continuous site scanning for progress monitoring and reality capture using handheld devices or drones, streamed to digital twin platforms.
- Tools/products: BIM platform connectors; “scan-as-you-go” workflows with memory-bounded streaming reconstruction; export of point maps for QA/QC.
- Assumptions/dependencies: Variable lighting/texture; large open spaces; network and storage pipelines for long sessions.
- Media production and VFX
- Application: On-set previz, live volumetric capture, and depth-assisted compositing (e.g., green-screen matte refinement) during extended takes.
- Tools/workflows: Unreal Engine plugin for streaming depth/point maps; bounded KV avoids GPU memory spikes; real-time monitor overlays for directors.
- Assumptions/dependencies: Studio-grade GPUs; consistent lighting; acceptable small performance differences from offline methods.
- Surveillance and smart cities
- Application: Long-duration 3D analytics from fixed cameras (scene layout, pedestrian flow, anomaly detection) with predictable memory footprint.
- Tools/products: VMS plugins that use XStreamVGGT for depth and pose; cost-containment via KV compression; edge deployment for privacy.
- Assumptions/dependencies: Legal/privacy compliance; camera placement and resolution; edge compute availability.
- Cloud inference and MLOps
- Application: Serving long video streams with bounded memory, reducing inference costs per stream and increasing throughput.
- Tools/workflows: Triton/TensorRT microservices with KV pruning/quantization; autoscaling policies using fixed KV budgets.
- Assumptions/dependencies: Integration with attention kernels; quantization configuration (e.g., INT4, group size 64) validated for target workloads.
- Academic research and education
- Application: Large-scale streaming 3D experiments without OOM failures; reproducible benchmarks in 3D reconstruction, depth, and camera pose.
- Tools/workflows: Open-source codebase; standardized KV compression configs; course labs demonstrating real-time 3D transformers.
- Assumptions/dependencies: Dataset availability (e.g., NRGBD, 7-Scenes, Sintel, KITTI, Bonn); GPU access; familiarity with PyTorch/FlashAttention.
- Consumer apps (daily life)
- Application: Smartphone 3D scanning for interior design (measurements, object placement), AR shopping, and video bokeh with live depth.
- Tools/products: Mobile apps with on-device memory-bounded streaming; cloud fallback for heavy scenes; depth-based UX features.
- Assumptions/dependencies: Device compute and battery limits; consistent camera motion; acceptance of small accuracy trade-offs.
- Energy and cost efficiency (operations)
- Application: Reduce GPU memory and latency (4.42× less memory, 5.48× faster on tested hardware), lowering energy usage and cloud costs.
- Tools/workflows: Cost dashboards tracking memory-bound inference; capacity planning for long streams; green AI initiatives in ops.
- Assumptions/dependencies: Energy savings correlate with reduced memory movement and faster inference; workload resembles tested profiles.
Long-Term Applications
These opportunities require further research, scaling, hardware co-design, or regulatory work to fully realize.
- AR glasses and wearables with on-device 3D mapping
- Application: Continuous spatial understanding on low-power NPUs for lightweight AR glasses and headsets.
- Tools/products: Hardware-accelerated per-channel Key and per-token Value quantization; lightweight attention kernels; firmware KV budget controllers.
- Dependencies: NPU support for asymmetric quantization; battery/thermal design; model miniaturization; scene-adaptive cache scheduling.
- Swarm drones for persistent 3D mapping
- Application: Multi-agent UAVs collaboratively building live maps in agriculture, disaster response, and infrastructure inspection.
- Tools/workflows: Distributed KV cache strategies; federated mapping; bandwidth-aware streaming fusion.
- Dependencies: Robust communications; synchronization protocols; fault tolerance; regulatory flight permissions.
- City-scale digital twins
- Application: Continuous 3D updates from thousands of cameras for traffic, construction, and urban planning.
- Tools/products: Edge-cloud pipelines with memory-bounded streaming; spatial databases; governance tools for data stewardship.
- Dependencies: Privacy/security frameworks; municipal policy; data standards; scalable storage and compute.
- Surgical navigation and medical robotics
- Application: Real-time 3D understanding from endoscopic video for navigation, robotic assistance, and AR overlays.
- Tools/workflows: Medical-grade inference pipelines; certified devices integrating bounded KV; surgeon UI overlays.
- Dependencies: Clinical validation; regulatory approvals; robustness to fluids/specularities; domain adaptation.
- Live 3D communications and social media
- Application: 3D video calls, interactive AR posts, and live volumetric events with efficient streaming geometry.
- Tools/products: 3D codecs that pair with memory-bounded inference; real-time compression standards; platform integration.
- Dependencies: Standardization of 3D formats; network QoS; cross-device compatibility; content moderation policies.
- Robotics manipulation with geometry-informed planning
- Application: Continuous geometry feeds to planners for dynamic grasping and assembly in factories and homes.
- Tools/workflows: Tight coupling of streaming depth/pose with motion planning; dynamic KV budgets based on task complexity.
- Dependencies: Safety certification; latency guarantees; domain-specific datasets; robust handling of occlusions.
- Standardized KV compression APIs and benchmarks
- Application: Cross-framework APIs for KV pruning/quantization and benchmarks for long-horizon vision transformers.
- Tools/products: Consortium-driven specs; open reference implementations; certification suites.
- Dependencies: Industry alignment; reproducible evaluation protocols; maintenance across evolving hardware stacks.
- Hardware co-design for KV compression
- Application: Memory systems and accelerators optimized for per-channel Key and per-token Value quantization, minimizing bandwidth and latency.
- Tools/products: Custom kernels; specialized SRAM buffers; quantization-aware scheduling.
- Dependencies: Chip vendor engagement; multi-year design cycles; software–hardware co-optimization.
- Adaptive cache budgeting and scene-aware controllers
- Application: Automatic tuning of KV budget based on motion, texture, and scene complexity to maximize accuracy under constraints.
- Tools/workflows: Controllers driven by attention sparsity metrics; RL or heuristic policies; feedback loops into inference servers.
- Dependencies: Reliable scene-complexity estimators; stability guarantees; further evaluation for edge cases.
- Privacy-preserving on-device mapping
- Application: Local-only 3D reconstruction with secure export of sanitized geometry (not raw video), meeting strict privacy regulations.
- Tools/products: On-device encryption; secure enclaves; policy-compliant data pipelines.
- Dependencies: Regulatory compliance; user consent flows; efficient privacy-preserving transforms (e.g., masking, differential privacy).
Notes on Assumptions and Dependencies (General)
- Accuracy trade-offs: “Mostly negligible” in reported benchmarks; some tasks (e.g., video depth in dynamic scenes) show small drops—validate per domain.
- Hardware: Benefits demonstrated on an A100; edge viability depends on GPU/NPU availability, kernel compatibility (e.g., FlashAttention), and quantization support (INT4/INT2).
- Model assumptions: StreamVGGT/VGGT architecture with Alternating-Attention and camera/register tokens; performance is tied to these design choices.
- Workflow integration: Memory-bounded KV requires careful engineering of cache budgets, grouping sizes, and quantization parameters (e.g., group size 64, per-channel Keys, per-token Values).
- Data characteristics: Performance generalizes across several datasets, but domain adaptation may be needed for specialized environments (medical, underwater, extreme lighting).
- Compliance: Applications in healthcare, public surveillance, and city-scale mapping require rigorous privacy, safety, and regulatory adherence.
Glossary
- Absolute Relative Error (Abs Rel): A scale-invariant depth metric measuring the average relative difference between predicted and ground-truth depths. "The evaluation metrics include Absolute Relative Error (Abs Rel) and (the percentage of predicted depths within a 1.25 factor of the ground-truth depth)."
- Absolute Translation Error (ATE): A camera pose metric quantifying the absolute deviation of predicted translation from ground truth over a trajectory. "We report Absolute Translation Error (ATE), Relative Translation Error (RPE\textsubscript{trans}), and Relative Rotation Error (RPE\textsubscript{rot}) as evaluation metrics."
- Accuracy (Acc): A 3D reconstruction metric measuring closeness of predicted points to ground truth. "We adopt Accuracy (Acc), Completion (Comp), and Normal Consistency (NC) as evaluation metrics."
- Alternating-Attention: A transformer design that alternates between spatial and temporal attention within layers. "adopting an Alternating-Attention design \cite{wang2025vggt}."
- Alternative-Attention: The specific attention mechanism used by VGGT that is modified in StreamVGGT for streaming. "replaces the global attention mechanism in Alternative-Attention of VGGT with frame-wise causal attention"
- Asymmetric uniform quantization: A quantization scheme using non-zero offsets (zero-points) and uniform steps to map floating-point values to low-bit integers. "we adopt the widely used asymmetric uniform quantization scheme \cite{liu2024kivi}"
- Attention kernels: Optimized implementations of attention operations designed for speed and memory efficiency. "maintains full compatibility with high-performance attention kernels (e.g., FlashAttention)."
- Attention scores: Numeric measures of relevance between query and key tokens used to weight value aggregation. "Attention scores have been widely used in previous studies to identify token importance \cite{ye2025fit,wu2024accelerating}."
- Autoregressive LLMs: Models that generate outputs token-by-token conditioned on past context, commonly using KV caches. "following a design philosophy similar to autoregressive LLMs \cite{team2025longcat1,team2025longcat2,team2026longcat}."
- Camera token: A special token inserted to encode global camera information for downstream camera parameter prediction. "StreamVGGT prepends a camera token to encode global camera-related information, which is later decoded by task-specific heads to predict camera parameters."
- Causal mask: An attention mask that restricts tokens from attending to future positions to enforce causality. "with a causal mask to prevent access to future frames."
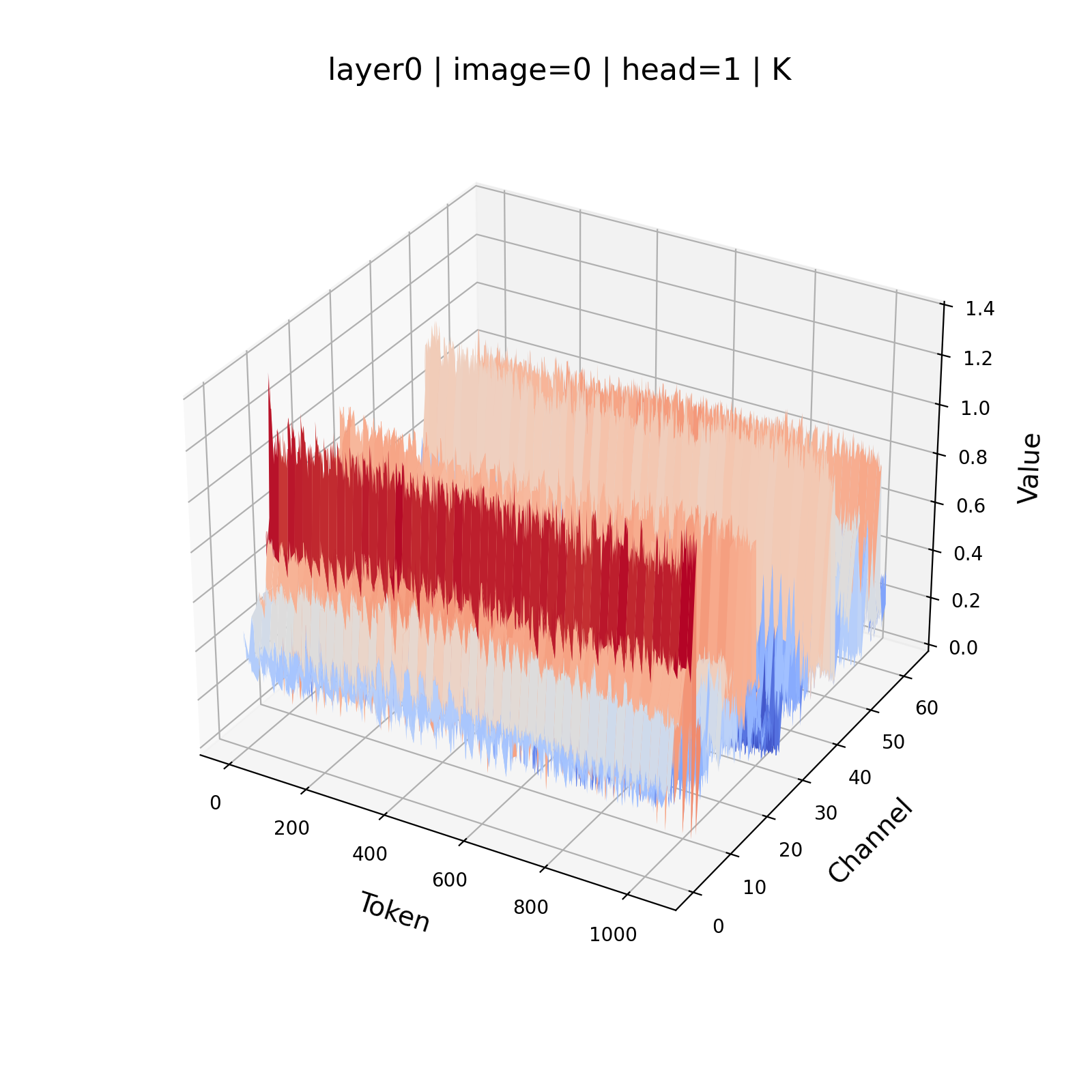
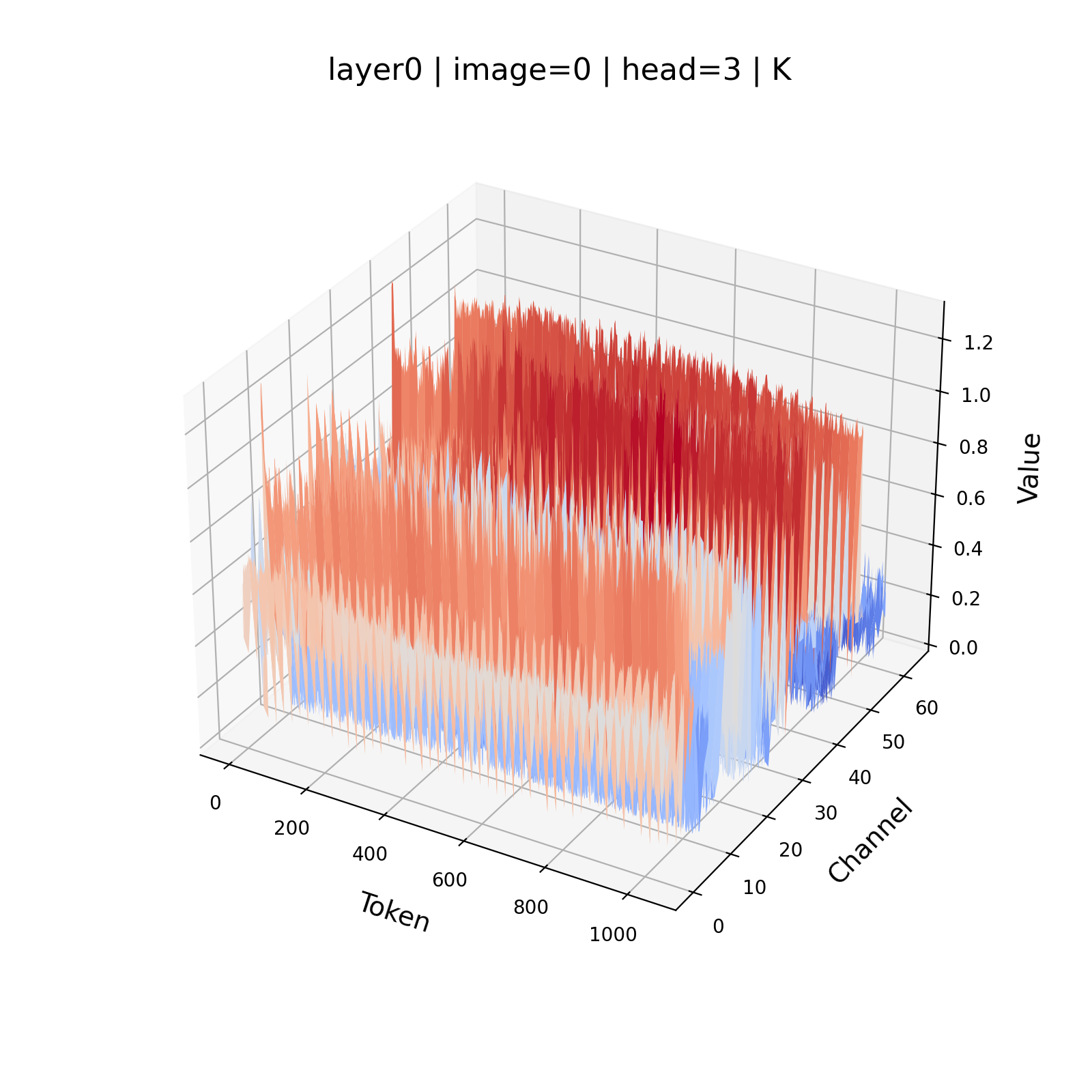
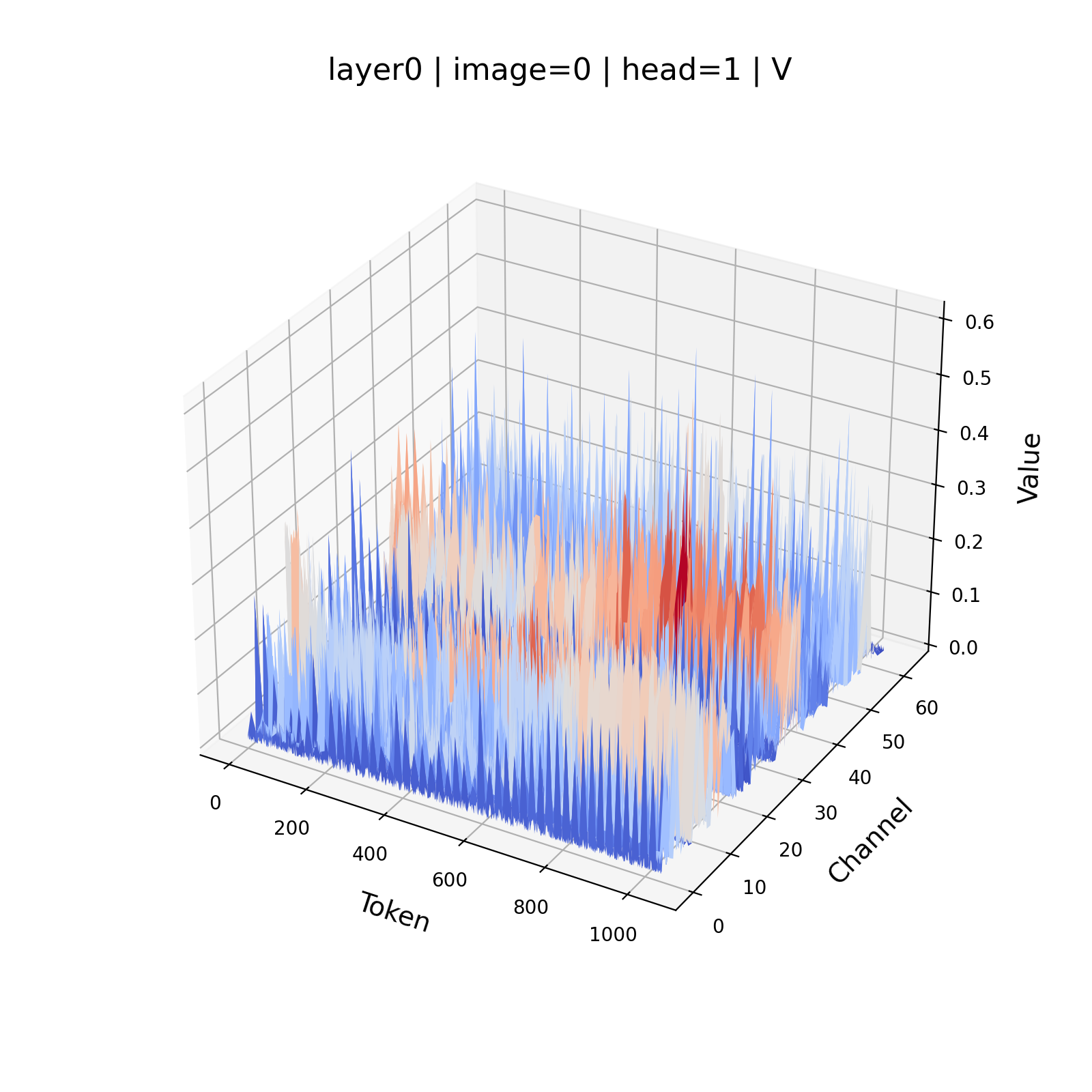
- Channel-wise outliers: Disproportionately large magnitudes confined to certain feature channels that distort quantization ranges. "the Key tensors exhibit significant channel-wise outliers, a behavior that is much less pronounced in the Value tensors."
- Dimension-adaptive KV quantization: A KV cache quantization strategy that chooses different granularities (per-channel for Keys, per-token for Values) based on distributional properties. "we develop a dimension-adaptive KV quantization scheme that incorporates per-channel Key and per-token Value quantization."
- FlashAttention: A high-performance attention kernel that improves speed and memory by optimizing attention computation. "high-performance attention kernels (e.g., FlashAttention)."
- Frame-wise causal attention: An attention strategy where each frame can attend only to past frames, enabling streaming. "StreamVGGT leverages frame-wise causal attention to deliver robust and efficient streaming 3D reconstruction."
- Frames per second (FPS): A measure of inference throughput indicating how many frames are processed per second. "XStreamVGGT consistently delivers significantly higher frames per second (FPS) without encountering OOM issues."
- Key-Value (KV) cache: Stored past key and value tensors enabling efficient causal attention without recomputing history. "it suffers from unbounded growth in the Key-Value (KV) cache due to the massive influx of vision tokens from multi-image and long-video inputs"
- KIVI: A tuning-free asymmetric low-bit quantization method for KV caches. "KV quantization is performed using KIVI with INT4 and a group size of 64 \cite{liu2024kivi}."
- KV pruning: Removing less important KV entries from the cache to reduce memory and computation. "KV pruning seeks to reduce memory and computational overhead by selectively discarding past KV entries deemed to have low importance."
- KV quantization: Compressing the KV cache by representing tensors in low-bit integer formats to save memory bandwidth and storage. "KV quantization compresses the cache by representing high-precision Key and Value tensors in low-bit formats, thereby reducing storage requirements and memory access costs~\cite{liu2024kivi,su2025rotatekv,su2025akvq,hooper2024kvquant}."
- Mean Squared Error (MSE): A metric measuring average squared difference, used to assess quantization error. "The errors are computed based on the Mean Squared Error (MSE) metric with a group size of 64."
- Multi-view stereo (MVS): Classical 3D reconstruction technique estimating dense geometry from multiple calibrated images. "multi-view stereo (MVS) \cite{gu2020cascade,furukawa2009accurate}."
- Normal Consistency (NC): A metric evaluating alignment between predicted and ground-truth surface normals. "We adopt Accuracy (Acc), Completion (Comp), and Normal Consistency (NC) as evaluation metrics."
- Out-of-memory (OOM): GPU memory exhaustion during inference leading to runtime failures. "StreamVGGT and VGGT exhibit significant FPS degradation and rapidly encounter out-of-memory (OOM) errors."
- Patch embedding: The process of converting image patches into token embeddings for transformer input. "using a patch embedding network"
- Per-channel quantization: Quantization where scale and zero-point are computed independently for each feature channel. "per-channel Key and per-token Value quantization."
- Per-token quantization: Quantization where parameters are computed per token across channels. "per-channel Key and per-token Value quantization."
- Point map regression: Predicting 3D point coordinates for each image pixel or patch directly. "including dense depth estimation, point map regression, and camera pose prediction~\cite{wang2025vggt}."
- Pruning: The removal of redundant model states or tokens to enforce memory budgets and efficiency. "Specifically, redundant KVs generated from multi-frame inputs are initially pruned to conform to a fixed KV memory budget"
- Register tokens: Auxiliary tokens designed to absorb attention responses and stabilize transformer processing. "The model also includes register tokens , which act as auxiliary latent slots to absorb redundant attention responses during transformer processing."
- Relative Rotation Error (RPE rot): A metric measuring rotational drift between consecutive camera poses. "We report Absolute Translation Error (ATE), Relative Translation Error (RPE\textsubscript{trans}), and Relative Rotation Error (RPE\textsubscript{rot}) as evaluation metrics."
- Relative Translation Error (RPE trans): A metric measuring translational drift between consecutive camera poses. "We report Absolute Translation Error (ATE), Relative Translation Error (RPE\textsubscript{trans}), and Relative Rotation Error (RPE\textsubscript{rot}) as evaluation metrics."
- Structure-from-Motion (SfM): A pipeline reconstructing 3D structure and camera motion from image sequences. "structure-from-motion (SfM) \cite{agarwal2011building,frahm2010building,wu2013towards}"
- Temporal attention: Attention that aggregates information across time steps (frames) under causal constraints. "In each transformer layer , the temporal attention module maintains a KV cache that stores token-level representations from all previous frames:"
- Test-Time Training (TTT): A strategy that adapts model parameters during inference based on the incoming data. "TTT3R \cite{chen2025ttt3r} incorporates a Test-Time Training (TTT) strategy that dynamically refines memory updates"
- Token importance: A measure of how relevant a cached token is to current queries for retention during pruning. "token-importance identification mechanism"
- Token saliency: A heuristic measuring a token’s influence, used to guide pruning decisions. "Importance is typically estimated using criteria such as attention scores, token saliency, or other heuristics~\cite{ye2025fit,wu2024accelerating}."
- Visual Geometry-Grounded Transformer (VGGT): A large transformer model jointly tackling multiple 3D vision tasks within a unified framework. "the Visual Geometry-Grounded Transformer (VGGT) consolidates multiple 3D vision tasks within a unified framework"
- Vision tokens: Tokenized representations of image patches used as transformer inputs in vision models. "massive influx of vision tokens from multi-image and long-video inputs"
Collections
Sign up for free to add this paper to one or more collections.