DiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion Enhancer
Abstract: Simulation is essential to the development and evaluation of autonomous robots such as self-driving vehicles. Neural reconstruction is emerging as a promising solution as it enables simulating a wide variety of scenarios from real-world data alone in an automated and scalable way. However, while methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results, they often exhibit artifacts particularly when rendering novel views, and fail to realistically integrate inserted dynamic objects, especially when they were captured from different scenes. To overcome these limitations, we introduce DiffusionHarmonizer, an online generative enhancement framework that transforms renderings from such imperfect scenes into temporally consistent outputs while improving their realism. At its core is a single-step temporally-conditioned enhancer that is converted from a pretrained multi-step image diffusion model, capable of running in online simulators on a single GPU. The key to training it effectively is a custom data curation pipeline that constructs synthetic-real pairs emphasizing appearance harmonization, artifact correction, and lighting realism. The result is a scalable system that significantly elevates simulation fidelity in both research and production environments.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “DiffusionHarmonizer”
What is this paper about?
This paper is about making computer-made videos look more realistic, especially for things like self‑driving car simulators. Today, 3D scene reconstructions (like NeRFs or 3D Gaussian Splatting) can turn real-world camera footage into a virtual world you can drive through. But when you look from new angles or add new moving objects (like cars or people), the videos often show problems: weird shapes, missing parts, wrong colors, no shadows, or lighting that doesn’t match. The authors built a tool called DiffusionHarmonizer that fixes these issues automatically, frame by frame, and keeps the video steady over time (no flicker).
What questions are the researchers asking?
In simple terms, they ask:
- Can we automatically clean up and “harmonize” (blend) simulation frames so the scene looks consistent and realistic?
- Can we do this fast enough to run “online” (while the simulator is running), on a single GPU?
- Can we keep the video stable from frame to frame, while fixing colors, lighting, shadows, and reconstruction glitches?
How did they do it? (Methods explained simply)
Think of their system as a smart, fast “video fixer” that:
- Corrects colors so foreground and background match,
- Adds believable lighting and shadows to inserted objects,
- Removes visual glitches caused by imperfect 3D reconstructions,
- Keeps everything consistent over time.
Here’s how it works, using everyday analogies:
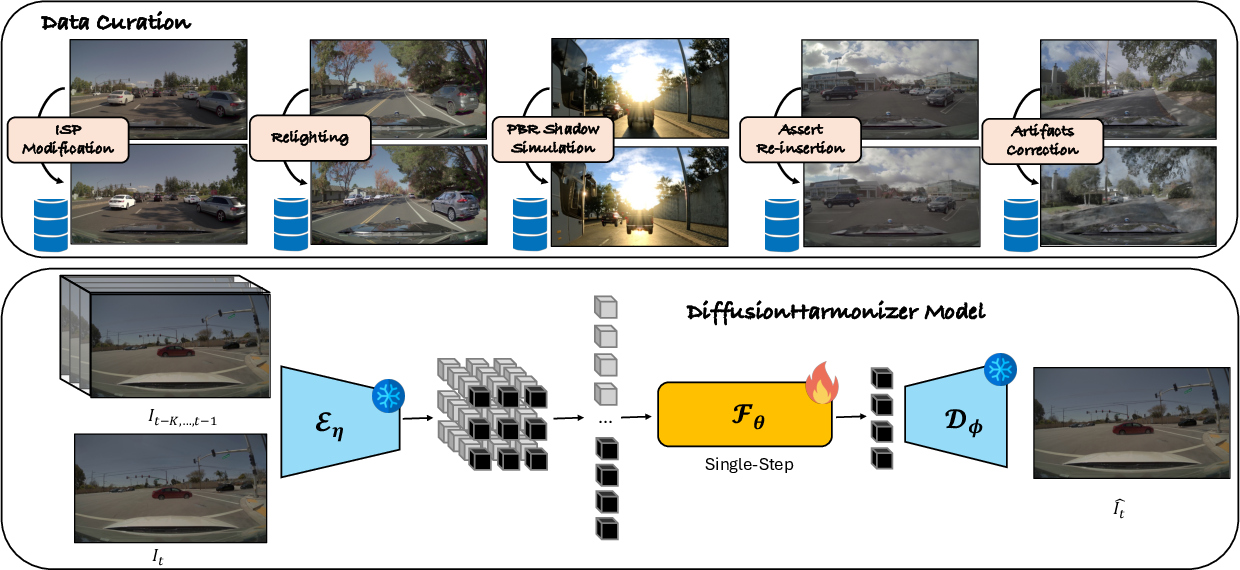
- Diffusion model as a cleaner: A diffusion model is like a very skilled photo restorer. Normally, it improves an image step by step. The authors convert a pre-trained diffusion model so it can do its fix in a single, quick step—like a one‑pass auto-correct filter—so it’s fast enough for live simulation.
- Memory of recent frames: To stop flicker, the fixer looks not only at the current frame but also at a few previous ones. It’s like checking the last few pages of a flipbook to make sure the next drawing matches smoothly.
- Stabilizing the “one-step” fixer: Because the original diffusion model was trained to work slowly over many steps, switching it to a one-step fixer can create tiny ugly patterns (like checkerboard artifacts). The authors solve this with a “multi-scale perceptual loss,” which is a fancy way of saying: they compare image patches at different sizes to a clean reference, so the fixer learns to keep both big shapes and fine details stable and natural.
- Keeping frames consistent over time: They use “optical flow” (think of it as tracking where each pixel moves from one frame to the next) and add a “temporal loss” that nudges the output to stay steady across frames where things should match.
- Training with realistic examples: To teach the fixer what “wrong” and “right” look like, they build a special training set. They create “before” images with specific problems and “after” images showing how it should look. This covers the most common issues in simulations:
- Reconstruction artifacts (blur, missing parts, ghosting),
- Camera processing differences (“ISP” changes like exposure, white balance, tone mapping) that cause mismatch between foreground and background,
- Relighting (same object under different lighting),
- Physically based shadows (what real shadows look like under different lights),
- Object re-insertion without shadows (so the fixer learns to add proper shadows and blend objects correctly).
The training pairs teach the model to harmonize color, fix artifacts, and add realistic shadows and lighting.
What did they find, and why does it matter?
- More realistic videos: The method makes frames look more believable—better colors, proper shadows, and fewer artifacts—while preserving the actual scene structure (it doesn’t hallucinate new geometry or distort the scene).
- Stable over time: Videos flicker less because the model uses recent frames and a temporal consistency loss.
- Fast enough for real use: It runs in about 0.2 seconds per frame on a single GPU, which is far faster than typical video diffusion models and suitable for online simulators.
- People prefer it: In user studies, over 84% of participants preferred the results from DiffusionHarmonizer compared to strong alternatives. It also did very well on quality tests that compare to ground‑truth references.
Why it matters: Realistic and stable simulation footage is crucial for testing and developing self‑driving cars and robots safely. If the simulated world looks real and behaves consistently, the AI trained and tested in that world is likely to perform better in the real world.
What’s the bigger impact?
- Better simulation tools: This approach can make large-scale, automatically built virtual scenes look much closer to real footage, which helps developers test and improve autonomous systems.
- Practical and scalable: Because it’s fast and runs on a single GPU, it’s practical for both research labs and companies that need real-time or near-real-time simulation.
- Broadly useful: Although the paper focuses on driving scenes, the same idea—harmonizing and stabilizing neural renderings—can help in robotics, AR/VR, and any application where virtual content must blend into real (or reconstructed) environments.
In short: DiffusionHarmonizer is like a smart, fast video “polisher” for simulated worlds. It fixes visual glitches, matches colors and lighting, adds realistic shadows, and keeps everything steady from frame to frame—making simulations more believable and useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or unexplored, and outline concrete directions future researchers could pursue:
- Real-time performance at production framerates and resolutions is untested: the reported 212 ms/frame at 1024×576 on a single H100 (~4.7 FPS) falls short of 30 FPS and 1080p/4K requirements; scaling strategies (model compression, distillation, multi-GPU, tensorRT, low-bit quantization) need to be evaluated.
- Long-horizon temporal stability and error accumulation are not analyzed: conditioning on previous enhanced frames can compound errors; drift and catastrophic accumulation over minutes-long sequences should be quantified and mitigated (e.g., keyframe resets, learned temporal consistency modules, motion-aware conditioning).
- Robustness to fast motion and occlusions remains uncertain: the temporal warping loss depends on RAFT, which can fail under large displacements or occlusions; alternative motion cues (scene flow, 3D geometry-aware warping, occlusion masks) and robustness in adversarial motion regimes need study.
- Physical correctness of synthesized shadows and lighting is not rigorously evaluated: beyond PSNR/SSIM/LPIPS and perceptual metrics, physically grounded measures (shadow geometry accuracy, contact shadow correctness, energy conservation, photometric consistency under known BRDFs and light directions) are lacking.
- Multi-view and 3D consistency is not addressed: the 2D enhancer could violate cross-view consistency and scene geometry; enforcing multi-view constraints (e.g., via epipolar consistency, neural rendering loops, 3D latent priors) and testing consistency across synchronized cameras is an open problem.
- Domain generalization is claimed but not validated: experiments focus on automotive scenes; evaluation across diverse domains (indoor, natural scenes, aerial, robotic manipulation) and conditions (night, rain/snow/fog, extreme backlight) is needed.
- Handling complex materials and volumetric effects is untested: specular/transparent objects, glossy floors, subsurface scattering, volumetric shadows/fog/haze are not covered; dataset curation and model design for these cases should be explored.
- Interaction between multiple inserted objects (mutual occlusion, overlapping shadows, interreflections) is not evaluated; models to reason about multi-object lighting interactions remain an open question.
- Dependence on curated paired data introduces bias and limits generalization: the pipeline relies on synthetic labels and internal reconstructions; investigating unpaired/self-supervised objectives, cycle-consistency, or physics-informed constraints could reduce reliance on curated pairs.
- Data and code availability is unclear: internal datasets and in-house asset extraction are not publicly accessible; reproducibility and standardized benchmarks (with public paired data and protocols) are needed.
- Fairness of baselines is limited: key comparators (e.g., DIFIX3D+, Flowr, 3DGS-Enhancer, Cat3D, recent video diffusion/editing with shadow-aware modules) are not included; a broader, stronger baseline suite and apples-to-apples configurations are required.
- Metric adequacy is questionable: FID/FVD/DINO-Struct-Dist and VBench++ flicker do not directly measure lighting/shadow correctness or structural preservation under manipulation; developing targeted metrics (shadow contact accuracy, relighting consistency, geometry distortion scores) is an open need.
- Failure mode analysis is missing: systematic characterization of where the enhancer over-edits, hallucinates content, or fails to harmonize (e.g., thin structures, reflective surfaces, heavy texture) is absent; collecting and reporting failure taxonomies would aid progress.
- Single-step conversion lacks theoretical grounding: fixing the timestep and conditioning to null and training with patch perceptual loss works empirically, but a principled analysis of noise-trajectory mismatch and conditions for artifact-free single-step behavior across architectures is needed.
- Generality across diffusion backbones is unproven: the approach is demonstrated on Cosmos 0.6B with a frozen VAE; replicating on other LDMs (SDXL/SD3, HQ-VAEs) and evaluating how encoder-decoder choices affect enhancement fidelity is an open question.
- Temporal context length and architecture choices are not explored: using K=4 and temporal attention is a single design point; ablations on context length, causal vs. bidirectional attention, memory modules, and motion-aware features could improve stability.
- Shadow supervision domain gap persists: PBR shadow data may not match real-world statistics; quantifying and reducing the gap (e.g., via environment-map distributions, material diversity, photometric calibration) and leveraging real paired shadow datasets would strengthen training.
- SAM2-based masks for ISP modification can be noisy; robustness to mask errors and mask-free harmonization across diverse segmentation qualities should be evaluated and improved.
- Impact on downstream autonomy tasks is unknown: measuring whether enhanced simulations improve perception (detection/tracking/segmentation), prediction, and planning performance compared to raw neural renders would substantiate practical value.
- Integration with upstream reconstruction is not addressed: studying the trade-off between fixing artifacts at the renderer vs. post-hoc enhancement, and co-training reconstruction with the enhancer under joint losses, could yield better overall fidelity.
- Structural preservation has no formal guarantees: while DINO-Struct-Dist is reported, explicit constraints (e.g., identity-preserving losses on static regions, geometry-aware masked editing) to prevent content hallucination should be investigated.
- Scene lighting control is not leveraged: the enhancer operates with null conditioning; exploring explicit controls (estimated light direction, exposure/white balance, HDR cues) could yield more predictable, physics-aligned corrections.
- Handling sensor diversity and ISP variability is limited: the ISP modification covers tone/exposure/white balance, but robustness across real cameras (rolling shutter, noise profiles, demosaic artifacts) and multi-sensor fusion (lidar/camera) remains open.
- Scalability to high resolution and multi-camera setups is untested: assessing performance on 4K, panoramic, and synchronized multi-view rigs, and optimizing memory/latency, is needed for production simulators.
- Evaluation under extreme novelty of viewpoints is limited: lateral shifts of 2–3 m are modest; stress-testing with larger deviations, sparse-view reconstruction, and extreme occlusions would reveal limits of artifact correction.
- Reliance on RAFT without occlusion handling specifics leaves ambiguity: detailing how valid correspondences set Ω is computed and evaluating robustness under occlusion-heavy sequences would clarify training stability.
- User study scale and design could be strengthened: 45 evaluators and 50 pairs each is modest; including cross-domain clips, blinded multi-model comparisons, and inter-rater reliability analyses would improve confidence.
- Licensing and adoption constraints of Cosmos 0.6B and other components are not discussed; assessing availability, legal permissibility, and alternatives affects real-world deployment.
- Security and safety considerations are absent: exploring whether enhancement could introduce misleading visual cues that affect human or machine decision-making (e.g., phantom obstacles, altered signage) is critical in autonomy contexts.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage DiffusionHarmonizer’s single-step, temporally conditioned enhancer, its loss design, and its curated training data strategy today. Each item notes the sector, a likely product/workflow, and feasibility caveats.
- Automotive and Robotics — Online simulation harmonization for perception and planning
- Use case: Post-process frames from neural reconstructions (NeRF/3DGS) in AV/robotics simulators to reduce novel-view artifacts, harmonize inserted agents, and synthesize shadows for more realistic, temporally stable closed- and open-loop tests.
- Tools/workflows: “Simulation Harmonization Module” plugin for CARLA, NVIDIA DRIVE Sim, LGSVL, or internal AV simulators; ROS node or gRPC microservice that wraps the enhancer and runs on a single GPU.
- Assumptions/dependencies: Requires a GPU (paper reports ~212 ms/frame at 1024×576 on an H100); quality depends on training data domain; relies on upstream neural reconstruction pipeline; temporal stability benefits from short history buffering.
- Synthetic data generation for perception model training (Automotive, Robotics, Security, Retail)
- Use case: Improve photorealism and lighting/shadow consistency in large-scale, scenario-diverse synthetic datasets composed via asset insertion, boosting downstream detector/segmenter robustness.
- Tools/workflows: “Synthetic Data Factory” that reconstructs scenes from fleet logs, inserts assets from databanks, then harmonizes frames in batch; scheduling on A100/H100 clusters.
- Assumptions/dependencies: Distribution shift risk if training data for enhancement differs from deployment domain; increased generation time (few FPS) may be acceptable in offline pipelines.
- VFX, Games, and Digital Twins — Post-render harmonizer for view synthesis and compositing
- Use case: Clean up 3DGS/NeRF novel views (ghosting, missing regions) and harmonize inserted CGI with real captures, including realistic shadows; reduce temporal flicker in shot sequences.
- Tools/workflows: Adobe After Effects/Nuke plugin; Unreal/Unity editor extension that calls the enhancer as a post-process; integration with Luma/Polycam-based captures.
- Assumptions/dependencies: Current speed favors offline or near-real-time rather than 30 FPS at 1080p; licensing for pretrained diffusion backbones must be cleared.
- AR/VR and Mobile — More realistic object insertion in live or recorded scenes
- Use case: Harmonize tone and lighting of virtual objects and synthesize shadows onto captured backgrounds for believable AR try-ons, home design, or telepresence at modest resolutions.
- Tools/workflows: ARKit/ARCore middleware module that runs the enhancer on a server edge and streams frames back; mobile apps offering “shadow-corrected AR recording.”
- Assumptions/dependencies: Latency and bandwidth constraints for edge round-trips; mobile on-device inference is not practical without model distillation/quantization and further speedup.
- Mapping/Surveying and Teleoperation — Stabilized, realistic reconstructions
- Use case: Improve visual fidelity of reconstructed environments from drones or ground robots to aid remote operators and analysts; reduce artifacts in novel viewpoints used for situational awareness.
- Tools/workflows: Add-on to photogrammetry/NeRF pipelines (e.g., RealityCapture + 3DGS) that runs the enhancer on synthesized camera paths for operations briefings.
- Assumptions/dependencies: Requires pre-rendered trajectories; any geometry distortion must be minimal for operational use (the method emphasizes structure preservation but still needs validation per workflow).
- Academic research — Paired data curation and single-step diffusion methodology
- Use case: Reuse the paper’s curated supervision streams (artifact degradations, ISP mismatches, relighting, PBR shadow data, asset re-insertion) to study harmonization, temporal coherence, and shadow synthesis; evaluate training with multi-scale perceptual loss for one-step conversion.
- Tools/workflows: Release and reproduce training scripts; benchmark against FID/FVD/DINO-Struct-Dist/VBench++ metrics on new domains (indoor scenes, manipulation labs).
- Assumptions/dependencies: Availability of similar curated data; access to base diffusion backbones (e.g., Cosmos 0.6B) and VAE tokenizer; compute for fine-tuning.
- Quality assurance and metrics for simulation pipelines (Industry and Academia)
- Use case: Insert an enhancement and evaluation stage that quantifies perceptual quality and temporal consistency (FID, FVD, VBench++ flicker) and reduces artifacts before delivery to downstream stakeholders.
- Tools/workflows: CI/CD hooks and dashboards for sim outputs; automatic regression tests that flag increases in artifacts or flicker after sim stack changes.
- Assumptions/dependencies: Metric thresholds need to be calibrated to domain/task; structural fidelity must be monitored to avoid altering ground-truth semantics.
- Creator tools and daily-life apps — Flicker-free, shadow-aware video edits without masks
- Use case: One-click harmonization and shadow synthesis for inserted subjects in videos (e.g., adding furniture, props, or vehicles), with temporal consistency and minimal user input.
- Tools/workflows: Consumer apps and web services integrating a “Temporal Harmonize” filter; extensions for DaVinci Resolve/Final Cut.
- Assumptions/dependencies: Cloud inference to meet latency; restrictions on commercial use of diffusion backbones and relighting models.
Long-Term Applications
The following use cases require further research, model scaling, optimization, or broader ecosystem support before widespread deployment.
- Real-time, high-resolution online simulation for AV/robotics
- Use case: Achieve 30–60 FPS at 1080p/4K with low latency to support fully online, closed-loop simulation where rendering, harmonization, and control run in sync on embedded or data-center GPUs.
- Tools/products: TensorRT- or CUDA-optimized single-step backbones; distillation to smaller backbones; hardware-aware architectures for Orin/Xavier or future automotive SOCs.
- Assumptions/dependencies: Substantial optimization and distillation; potential design of multi-scale tiling without temporal artifacts; memory bandwidth constraints.
- Mask-free, scene-aware AR/VR on-device
- Use case: On-device harmonization for AR glasses/phones that adaptively matches scene illumination and renders physically plausible shadows in real time for multiple virtual objects.
- Tools/products: AR SDKs with integrated enhancer and fast relighting priors; depth and lighting estimation fused with enhancer for stronger scene constraints.
- Assumptions/dependencies: Efficient on-device inference, robust on-board lighting estimation; power constraints; thermal budgets on mobile hardware.
- End-to-end simulators with learned harmonization in the loop for data generation and policy evaluation
- Use case: Couple neural reconstruction, dynamics, and harmonization with planning/learning loops to evaluate safety-critical behaviors in highly realistic scenarios at scale.
- Tools/products: “World-model + Harmonizer” simulators; automatic scenario generation and evaluation farms; integration with CARLA/Waymo/SV Benchmarks.
- Assumptions/dependencies: Clear evidence that enhanced realism improves policy transfer; standardized interfaces between harmonizer and sim engines; governance over synthetic scenario validity.
- Generalized domain coverage (indoor robotics, medical, industrial inspection)
- Use case: Apply the training recipe and enhancer to domains with different materials and lighting (e.g., glossy indoor scenes, surgical environments, manufacturing floors) to reduce artifacts and harmonize insertions.
- Tools/products: Domain-specific curated supervision (relighting and PBR shadow data tailored to materials/fixtures); tuned backbones per domain.
- Assumptions/dependencies: High-quality, domain-representative curated pairs; safety and regulatory approvals in medical/industrial settings.
- Physics-aware harmonization with explicit geometry and light transport constraints
- Use case: Hybrid models that combine enhancer outputs with differentiable rendering or learned geometry/light priors to guarantee physically plausible shadows/illumination and avoid artifact hallucination.
- Tools/products: Joint 3D-aware diffusion backbones; geometry/light field conditioning pipelines; consistency checks with inverse rendering.
- Assumptions/dependencies: Additional supervision (geometry, BRDFs, environment maps); more compute; algorithmic advances to keep single-step efficiency.
- Standards and certification for “simulation realism” in safety-critical policy and regulation
- Use case: Develop metrics and acceptance tests that include perceptual realism and temporal stability as certifiable criteria for simulation used in AV/robotics safety cases.
- Tools/products: Open benchmarks, auditing tools, and reporting formats; third-party certification services that test harmonizer-integrated simulations.
- Assumptions/dependencies: Multi-stakeholder consensus; demonstrated linkage between realism metrics and safety-relevant model performance.
- Privacy-preserving, shareable reconstructions with consistent appearance
- Use case: Generate shareable, photorealistic but de-identified reconstructions for data exchange between partners, where harmonization ensures stable, realistic outputs after redaction.
- Tools/products: Pipelines that pair anonymization (e.g., face/plate replacement) with post-harmonization; dataset release tools for research consortia.
- Assumptions/dependencies: Proven privacy techniques; governance over synthetic fidelity and potential re-identification risks.
- Intelligent asset banks and auto-harmonizing content libraries
- Use case: Asset repositories that store appearance priors and auto-suggest harmonization parameters or run enhancement when inserting assets into new scenes (games, films, training sims).
- Tools/products: “Asset Bank Harmonizer” service that tags assets with material/lighting descriptors and triggers harmonization jobs on composition.
- Assumptions/dependencies: Metadata standards for assets (materials, capture conditions); scalable scheduling; rights management for trained priors.
Cross-cutting assumptions and dependencies
- Model and data: Availability of a suitably licensed pretrained diffusion backbone and a curated, domain-matched training set (including PBR shadow and relighting pairs) is critical for quality and generalization.
- Compute and latency: Single-step design enables near-real-time, but production targets (e.g., 30 FPS at high resolution) need further optimization, distillation, and possibly specialized hardware.
- Structural fidelity: While the method emphasizes preserving scene geometry, safety-critical uses require validation that enhancements do not alter semantic cues or ground-truth labels.
- Integration: Stable online operation depends on robust temporal conditioning (previous frames) and reliable optical flow for temporal loss during training; upstream reconstruction quality still matters.
- Licensing and governance: Commercial deployment requires due diligence on model licenses, training data provenance, and compliance with content production and privacy regulations.
Glossary
- 3D Gaussian Splatting: A neural scene representation that renders scenes using collections of 3D Gaussians for fast, high-quality view synthesis. "methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results"
- Asset Re-Insertion: Replacing or compositing extracted/reconstructed foreground assets back into a scene, often used to create training pairs for harmonization and shadow synthesis. "(v) asset re-insertion composites where reconstructed objects are reinserted without shadows"
- Cast shadows: Shadows projected by objects onto other surfaces, crucial for realistic lighting and depth cues. "Accurate cast shadows are critical for realism but are difficult to annotate in real data."
- Checkerboard artifacts: Undesired grid-like patterns that can appear due to upsampling or mismatched denoising trajectories. "Indeed, naively fine-tuning a pretrained multi-step diffusion model in a single denoising step introduces high-frequency checkerboard artifacts."
- Diffusion model: A generative model that learns to reverse a noise-adding process, iteratively denoising to synthesize data. "we convert a pretrained non-distilled image diffusion model into a single-step, temporally conditioned enhancement model"
- DINO-Struct-Dist: A feature-space distance metric based on DINO features, used to assess structural preservation between input and output. "structural preservation using {DINO-Struct-Dist}, which measures feature-space similarity between input and output"
- Ego trajectory: The motion path of the “ego” agent (e.g., a vehicle/camera) used for rendering or evaluation. "We reconstruct both static scenes and dynamic objects (\eg, pedestrians and vehicles), then render novel views by laterally shifting the ego trajectory by 2\,m."
- Environment maps: Image-based representations of surrounding illumination used in rendering to simulate realistic lighting. "We randomly vary the environment maps in synthetic scenes to modify the direction, softness, and intensity of the light source"
- FID: Fréchet Inception Distance, a metric that measures perceptual similarity between sets of images. "We evaluate perceptual quality using {FID} and {FVD}"
- FVD: Fréchet Video Distance, a metric for assessing perceptual quality and temporal coherence of videos. "We evaluate perceptual quality using {FID} and {FVD}"
- Image relighting: Changing or synthesizing lighting in an image while preserving geometry and texture. "we use an image relighting diffusion model~\cite{DiffusionRenderer} to regenerate selected regions under randomly sampled lighting conditions"
- Image Signal Processing (ISP): The camera pipeline (e.g., tone mapping, exposure, white balance) that transforms raw sensor data into images. "Object captures from different devices often exhibit image signal processing (ISP) induced tone and color inconsistencies"
- Latent Diffusion Models (LDMs): Diffusion models that operate in a compressed latent space via an encoder–decoder, improving efficiency. "Latent Diffusion Models (LDMs) \cite{ldm} greatly improve computational and memory efficiency by operating on a lower dimensional latent space."
- Latent video diffusion model: A diffusion-based video generator that operates in a latent space for efficiency and temporal modeling. "GenCompositor~\cite{yang2025gencompositor} employs a latent video diffusion model to harmonize inserted objects."
- LPIPS: Learned Perceptual Image Patch Similarity, a deep-feature-based metric for perceptual similarity between images. "we further calculate {PSNR}, {SSIM}, and {LPIPS} on the region of interest"
- Multi-scale perceptual loss: A training loss that compares features at multiple spatial scales to better capture perceptual fidelity and suppress artifacts. "we introduce a multi-scale perceptual loss computed on randomly sampled squared patches of varying sizes."
- NeRF: Neural Radiance Fields, a neural representation that models view-dependent appearance and density for photorealistic novel view synthesis. "methods such as NeRF and 3D Gaussian Splatting can produce visually compelling results"
- Noise schedule: The timetable of noise levels across diffusion timesteps that defines the forward and reverse processes. "arising from the noise-trajectory mismatch which emerges due to the discrepancy between the multi-step noise schedule used during pretraining and the single-step mode at inference time."
- Noise-trajectory mismatch: A discrepancy between the training and inference denoising paths (e.g., multi-step vs. single-step), often causing artifacts. "arising from the noise-trajectory mismatch which emerges due to the discrepancy between the multi-step noise schedule used during pretraining and the single-step mode at inference time."
- Optical flow: A per-pixel motion field describing the apparent movement between consecutive frames. "we estimate the optical flow using RAFT~\cite{teed2020raft}."
- Physically based renderer (PBR): A renderer that simulates light transport according to physical principles for realism. "we use a physically based renderer to synthesize cast shadows under controllable light configurations."
- PSNR: Peak Signal-to-Noise Ratio, a distortion metric measuring the fidelity of a reconstructed image to a reference. "we further calculate {PSNR}, {SSIM}, and {LPIPS} on the region of interest"
- RAFT: A state-of-the-art optical flow estimation network based on recurrent all-pairs field transforms. "we estimate the optical flow using RAFT~\cite{teed2020raft}."
- Score distillation sampling: A training technique that leverages diffusion model scores to guide optimization of another model or representation. "Nerfbusters~\cite{Nerfbusters2023} incorporate the prior from a pretrained 3D diffusion model into the scene by using a density score distillation sampling loss~\cite{poole2022dreamfusion}."
- Single-step temporally-conditioned enhancer: A diffusion-based enhancer executed in one denoising step with temporal context to stabilize video frames. "At its core is a single-step temporally-conditioned enhancer that is converted from a pretrained multi-step image diffusion model, capable of running in online simulators on a single GPU."
- SSIM: Structural Similarity Index Measure, an image quality metric capturing structural and luminance similarities. "we further calculate {PSNR}, {SSIM}, and {LPIPS} on the region of interest"
- VAE tokenizer: The encoder–decoder (VAE) module that “tokenizes” images into latents and back for latent diffusion models. "which contains 0.6B parameters in the diffusion backbone and 0.14B parameters in the VAE tokenizer."
- VBench++: An evaluation benchmark/metric suite for video quality, including temporal flicker measurements. "temporal flickering score measured by {VBench++}."
- VGG network: A deep convolutional neural network architecture often used as a feature extractor for perceptual losses. "where denotes features from the -th layer of a VGG network and are layer-wise weights."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs to assess or generate content. "we additionally conduct the user study and, following recent practice \cite{kirstain2023pick, liu2024evalcrafter, lin2025controllable, bai2025qwen2}, employ a pretrained vision-LLM (VLM) to assess overall quality."
Collections
Sign up for free to add this paper to one or more collections.