Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models
Abstract: Compositional generalization, the ability to recognize familiar parts in novel contexts, is a defining property of intelligent systems. Although modern models are trained on massive datasets, they still cover only a tiny fraction of the combinatorial space of possible inputs, raising the question of what structure representations must have to support generalization to unseen combinations. We formalize three desiderata for compositional generalization under standard training (divisibility, transferability, stability) and show they impose necessary geometric constraints: representations must decompose linearly into per-concept components, and these components must be orthogonal across concepts. This provides theoretical grounding for the Linear Representation Hypothesis: the linear structure widely observed in neural representations is a necessary consequence of compositional generalization. We further derive dimension bounds linking the number of composable concepts to the embedding geometry. Empirically, we evaluate these predictions across modern vision models (CLIP, SigLIP, DINO) and find that representations exhibit partial linear factorization with low-rank, near-orthogonal per-concept factors, and that the degree of this structure correlates with compositional generalization on unseen combinations. As models continue to scale, these conditions predict the representational geometry they may converge to. Code is available at https://github.com/oshapio/necessary-compositionality.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models”
Overview
This paper asks a big question: how can AI recognize familiar things in new situations it has never seen before? For example, an AI might see many photos of “a cat next to a person,” but almost never “a person standing on a cat.” We still want it to answer “Is there a person?” correctly in both cases. The authors argue that for this kind of “mix-and-match” understanding (called compositional generalization), the way images are represented inside the AI must follow a special shape: the representation should be a simple sum of parts (linear), and different kinds of parts should not interfere with each other (orthogonal, like directions at right angles). They back this up with theory and tests on popular vision models like CLIP, SigLIP, and DINO.
Key objectives and questions
The paper focuses on three easy-to-understand goals for models that claim to generalize to new combinations of familiar concepts:
- Can the model “see” all the pieces? (Divisibility)
- Do simple classifiers learned from some examples work on unseen combinations? (Transferability)
- If you retrain the model on a different but still valid slice of data, do its predictions stay steady? (Stability)
Main questions:
- If a model succeeds at these goals using common training methods, what must its inner representations look like?
- Are those representation shapes not just necessary, but also sufficient to get good generalization?
- How many dimensions (slots in the embedding vector) are needed to represent all the pieces reliably?
How they studied it (methods, in everyday terms)
Think of an image as made from several “concepts,” like:
- Concept 1: object type (cat, person, car, …)
- Concept 2: color (red, blue, …)
- Concept 3: action (sitting, running, …)
Together, these form a big grid of all possible combinations (like a giant multiplication table of concept values). In practice, the training data only covers a small part of this grid, often missing rare combinations.
The authors set up a framework to analyze when a model can learn from a small part of the grid and still get the rest right. They look at models that:
- Turn each image into an embedding (a vector of numbers).
- Use simple, linear classifiers on top of embeddings to read out concept values (like “Is there a person?”). In CLIP-like systems, text prompts such as “a photo of a person” act like these linear classifiers.
They define three practical requirements:
- Divisibility: The embedding space and readout have enough capacity so every possible combination of concepts can be separated if needed.
- Transferability: A classifier trained on some combinations still works on all combinations, even unseen ones.
- Stability: If you retrain on a different valid slice of data, the model’s per-concept predictions don’t swing around.
Then they analyze what standard training (gradient descent with cross-entropy loss, a very common recipe) forces the embeddings to look like if these three requirements are met. They also provide dimension bounds and test the predictions on real vision models (CLIP, SigLIP, DINO) and with synthetic experiments.
Key ideas explained simply:
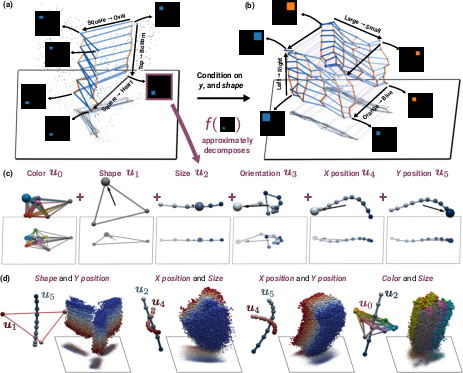
- Linear factorization: The embedding of an image should be like stacking Lego blocks, one block per concept. Change the “color” block and you change only the color part of the embedding, without messing up the “object” block.
- Orthogonality: Blocks for different concepts should point in independent directions, like arrows at right angles. That way, changing one concept doesn’t accidentally change another.
- Dimension bound: You need at least one independent “direction” per concept so the model can keep them separate.
Main findings and why they matter
- If a model learns with common methods and still generalizes to new combinations while staying stable across data slices, then:
- The image embedding must be a sum of per-concept pieces (linear factorization).
- The differences for different concepts must be orthogonal (independent, non-overlapping directions).
- These conditions aren’t just nice-to-have; they are necessary. In many realistic cases, they’re also sufficient to achieve good generalization.
- There are dimension limits: to keep concepts separate, the model needs at least as many embedding dimensions as it has concepts.
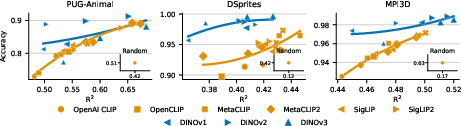
- In real models (CLIP, SigLIP, DINO), the authors find “partial” versions of this structure:
- Embeddings often split into low-rank, almost-orthogonal per-concept components.
- The more a model’s embeddings look like this ideal shape, the better it tends to perform on tests that require compositional generalization.
- This supports the “Linear Representation Hypothesis,” which says that the linear structure often seen in neural networks isn’t an accident—it’s a consequence of wanting to generalize compositionally.
What this means going forward (implications and impact)
- Design target: If we want AI that handles never-seen-before combinations of familiar parts, we should train and build models that create linear, orthogonal representations. Think “independent sliders” for each concept.
- Better training and evaluation: The three requirements (divisibility, transferability, stability) provide a checklist for datasets and training setups intended for generalization.
- Scaling outlook: As models and datasets get bigger, we should expect their internal representations to move closer to this linear-and-orthogonal geometry.
- Practical benefit: Clearer, more modular representations make it easier to read out and recombine concepts, improving zero-shot and few-shot performance on challenging, unusual scenarios.
In short, to get strong mix-and-match intelligence, the inside of the model should look like Lego: simple additive parts that don’t interfere with each other.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is articulated to be actionable for future research.
- Extension beyond binary concepts: The necessity and sufficiency results are proven primarily for binary concept grids. It remains unclear how the theory generalizes to multi-valued concepts with , including exact conditions, required sample sizes, and training supports.
- Approximate vs. exact stability: Stability is assumed as exact equality of posterior distributions across valid supports, which is unrealistic in practice. A principled, quantitative relaxation (metrics, tolerances, and generalization guarantees under approximation) is not provided.
- Loss functions beyond (binary) cross-entropy: The theoretical results hinge on GD with logistic/CE losses (and the max-margin implicit bias). It is unknown whether the same geometric necessities hold under common alternatives (e.g., InfoNCE, sigmoid contrastive loss used by CLIP/SigLIP, hinge losses, triplet losses).
- Optimization algorithms and implicit bias: The analysis assumes gradient descent. Modern training uses Adam/AdamW, momentum, and weight decay. Whether those optimizers yield the same max-margin geometry and the same linear/orthogonal necessity is not established.
- Non-linear readouts: The paper focuses on linear readouts (or absorbing non-linear parts into the encoder). Conditions under which non-linear heads can maintain compositional generalization without trivial memorization (e.g., with regularization or architectural constraints) are not characterized.
- Contextual inference and conditioning: The scope excludes contextual models (e.g., prompt-conditioned visual encoders, batch-dependent inference). What geometric constraints are necessary when image representations depend on context, prompts, or other inputs remains unexplored.
- Relational and binding structure: The framework explicitly does not model binding of attributes to objects or spatial relations. The required geometry for relational compositionality (e.g., role-filler binding, structured representations, tensor products) is left open.
- Continuous concepts: The theory assumes discrete concept values. Generalization of the necessity/sufficiency results to continuous-valued attributes (e.g., hue, pose, scale) and the corresponding geometric constraints (e.g., manifolds, local linearity, curvature) are not addressed.
- Dependence structure among concepts: Validity rules assume sampling regimes (e.g., random subsets, minimal cross coverage) but do not analyze correlated concept distributions (long-tail biases, co-occurrence skew). How correlation affects necessary geometry and sample complexity is unclear.
- Label noise and weak supervision: Real web-scale training includes noisy captions and imperfect labels. The robustness of the claimed necessary geometry (linearity/orthogonality) under label noise and the required noise levels for stability are not analyzed.
- Tight and general dimension bounds: Only a preliminary bound ( for affine readouts) is stated. Tight bounds for multi-valued concepts, non-orthogonal factors, continuous attributes, and practical constraints (e.g., normalization on spheres) are missing.
- Thresholds for “near-orthogonality”: Empirically observed “near-orthogonality” is reported, but there is no quantified tolerance (angles, coherence bounds) linking deviation from orthogonality to provable generalization guarantees.
- Causality vs. correlation: Empirical findings show correlation between degree of factorization/orthogonality and compositional generalization. Interventional experiments (e.g., enforcing orthogonality via penalties/architectures to demonstrate causal improvement) are not presented.
- Text-encoder probe geometry: The conditions required on the text-encoder embeddings/probes (e.g., how probe design, prompt phrasing, and text geometry influence the necessity/sufficiency and stability) are not theoretically or empirically characterized.
- Prompt-set dependence: Zero-shot readouts depend on the chosen prompt set. The sensitivity of compositional generalization and inferred geometry to prompt diversity, lexical choices, and prompt templates is not studied.
- Sample complexity for generalization: Beyond the specific counts (e.g., and for binary cases), general sample complexity results relating training support size/structure to guaranteed transferability and stability are not derived.
- Architectural sources of geometry: While the paper frames linearity/orthogonality as necessary for compositional generalization, the contributions of architecture (e.g., attention, residual structure, layer normalization) in inducing this geometry independent of downstream demands remain open.
- Regularization effects: The role of explicit regularizers (weight decay, orthogonality constraints, representation decorrelation, whitening) in achieving or improving the necessary geometry is not investigated.
- Spherical embedding constraints: CLIP-like models often use normalization. How the unit-sphere constraint affects the necessity/sufficiency (e.g., angles vs. inner products, spherical codes) is not analyzed.
- Robustness to distribution shift: The analysis focuses on unseen combinations of familiar concepts but does not examine robustness when the visual distribution changes (e.g., styles, domains, occlusions), nor how geometry interacts with domain shift.
- Token-space vs. pooled embeddings: Parallel work suggests structured geometry in token spaces (e.g., Minkowski sums). The paper’s necessity claims are framed at the pooled embedding level; whether similar constraints hold at token-level and how pooling affects compositionality is unresolved.
- Practical diagnostics: The empirical metrics for linearity and orthogonality are indicative but not standardized. A robust, reproducible diagnostic toolkit (with thresholds and calibration to generalization targets) for evaluating compositionality-related geometry is not provided.
- Extension to other modalities: The necessity claims are argued for vision encoders (and vision-language). Whether analogous constraints apply to audio, video, or multimodal sequence models is not addressed.
- Training-time enforcement and trade-offs: Methods to explicitly enforce the necessary geometry during training (losses, constraints) and the potential trade-offs with performance on non-compositional tasks are not explored.
- General constructive sufficiency (multi-valued, non-orthogonal): The paper alludes to constructive sufficiency beyond binary orthogonal cases but does not provide full algorithms, assumptions, and guarantees for multi-valued or non-orthogonal factor recoverability.
Practical Applications
Overview
This paper establishes necessary—and in key regimes also sufficient—geometric conditions for vision embedding models to generalize compositionally to unseen combinations of familiar concepts. Under standard gradient-descent training with cross-entropy and linear readouts (as in CLIP/SigLIP/DINO), compositional generalization requires that embeddings linearly factorize into per-concept components and that per-concept difference directions are orthogonal across concepts. The authors introduce three desiderata—divisibility, transferability, and stability—and show how these induce constraints on representation geometry, provide dimension bounds, and empirically validate partial emergence of this structure in modern models.
Below are actionable applications derived from these findings, organized by near-term deployability and longer-term development horizons.
Immediate Applications
These can be adopted with existing VLMs (e.g., CLIP, SigLIP) and standard toolchains.
- Compositionality auditing and diagnostics (software; industry/academia)
- Build “Compositional Geometry Dashboards” that measure:
- Linearity: R² of additive factorization across concepts.
- Orthogonality: cosine similarity of per-concept difference directions.
- Stability: posterior agreement when retraining readouts on multiple valid supports.
- Use results to gate model releases (ML Ops), select models for production, and identify data gaps.
- Dependencies/assumptions: linear readouts; concept schemas; access to retraining subsets; non-contextual encoders; metrics approximate in practice.
- Prompt/probe engineering for CLIP-style zero-shot (software; industry/academia)
- Construct per-concept “probe banks” (text prompts) that are mutually near-orthogonal across concepts to improve transferability to rare compositions.
- Calibrate prompts/weights and use margin-maximizing linear heads (SVM-style) to stabilize per-concept logits.
- Dependencies: high-quality prompt design; text encoder reliability; linear probing; concept schema alignment with downstream tasks.
- Data collection policies guided by validity rules (policy; industry/academia)
- Adopt sampling strategies that ensure coverage of concept values:
- Minimal “cross” datasets (≈1 + k(n−1)) or binary regime supports (≈2k−1+1) depending on constraints.
- Ensure joint marginals cover at least two values per concept (for practical collectability).
- Integrate these rules into dataset governance and documentation (e.g., data cards).
- Dependencies: ability to tag concept values; feasibility of collecting/augmenting rare combinations; label noise management.
- Training regularizers that enforce factorization and orthogonality (software; industry/academia)
- Add penalties that reduce cross-concept correlation in per-concept logits/features (orthogonality/separation regularizers).
- Use multi-label logistic heads with decoupled per-concept classifiers and constraints to promote additive structure.
- Dependencies: model access for finetuning; reliable concept labels; risk of over-regularization (monitor accuracy).
- Benchmarking and evaluation workflows for compositional generalization (academia/industry)
- Create held-out test sets with unusual recombinations (e.g., attribute-object inversions) to assess transferability.
- Report compositional metrics alongside standard accuracy; track correlation between geometry and CG performance.
- Dependencies: benchmark curation; careful prompt/probe selection; consistent protocols.
- E-commerce product tagging and search (retail/finance; industry/daily life)
- Use concept-level probes (e.g., category, material, color, pattern) to tag items correctly even in rare attribute combinations.
- Improve retrieval ranking by separating concept signals and reducing spurious co-occurrence biases.
- Dependencies: taxonomy mapping to concept space; coverage of attribute prompts; potential domain adaptation.
- Content moderation and safety detection (policy/software; industry)
- Deploy per-concept detectors (e.g., object types, symbols) that remain reliable under atypical contexts or combinations (memes, edits).
- Use stability checks to ensure predictions don’t flip under retraining samples; reduce false negatives in rare compositions.
- Dependencies: clearly defined concept inventory; legal/compliance review; robustness to adversarial content.
- Robotics perception and manipulation (robotics; industry/academia)
- Evaluate and finetune perception stacks to robustly recognize objects and attributes independently (e.g., object identity vs. pose/texture).
- Use orthogonal heads to minimize interference between concept detectors and improve behavior in novel scenes.
- Dependencies: domain-specific concept schemas; real-world sensor variations; closed-loop testing.
- Healthcare imaging triage and tagging (healthcare; industry/academia)
- Multi-attribute tagging (modality, anatomy, finding type, severity) with decoupled per-concept probes to handle unusual combinations (rare comorbidities).
- Dependencies: strict clinical validation; regulatory oversight; careful handling of label noise and domain shift.
- Autonomous driving and mapping perception (robotics/energy; industry)
- Concept-separated detection (e.g., traffic sign type, state, occlusion) to maintain performance in rare environmental combinations.
- Dependencies: domain-specific coverage; safety qualification; calibration under weather/lighting conditions.
- Industrial visual inspection (energy/manufacturing; industry)
- Defect detection pipelines with per-concept separation (defect type vs. material/finish) to generalize across new product lines.
- Dependencies: consistent imaging; concept inventory; integration with QC standards.
Long-Term Applications
These require further research, scaling, or ecosystem development to realize fully.
- Architecture design for subspace-separated embeddings (software/robotics; academia/industry)
- Develop models that explicitly enforce linear factorization and cross-concept orthogonality (e.g., mixture-of-subspaces, concept-whitened layers).
- Outcomes: more reliable compositional generalization at scale; better control and interpretability.
- Dependencies: training stability; balancing constraints with expressivity; evaluation on diverse domains.
- Capacity planning via dimension bounds (software; academia/industry)
- Use derived dimension requirements (e.g., d ≥ k in affine readout regimes) to plan embedding sizes relative to concept counts.
- Outcomes: principled scaling strategies; resource-aware model design.
- Dependencies: accurate concept inventories; trade-offs with downstream tasks.
- Cross-modality compositional generalization (audio/video/text; academia/industry)
- Extend geometric constraints and desiderata to multimodal encoders (audio events + visual scenes + language).
- Outcomes: robust multimodal systems that retain concept reliability under novel cross-modal compositions.
- Dependencies: multimodal datasets with aligned concept labels; training recipes for decoupled heads.
- Controllable generation and editing via concept directions (software/creative tools; industry/daily life)
- Leverage per-concept directions for precise edits (e.g., change color without altering shape; alter background without affecting object).
- Outcomes: reliable content creation tools; safeguards against unintended attribute changes.
- Dependencies: generative models aligned to factorized embeddings; guarantees against entangled edits.
- Standards and certification for compositional reliability (policy; industry/academia)
- Define compliance criteria (divisibility, transferability, stability thresholds; dataset validity rules) for critical applications (healthcare, automotive).
- Outcomes: procurement standards; risk classification; auditability.
- Dependencies: consensus across stakeholders; regulatory frameworks; reproducible metrics.
- Curriculum/data acquisition strategies that optimize concept coverage (software/policy; industry/academia)
- Adaptive sampling to close gaps in concept value coverage and improve orthogonality with minimal data.
- Outcomes: efficient data collection; improved performance on rare compositions.
- Dependencies: data pipelines; labeling infrastructure; privacy and ethical constraints.
- Robustness to spurious correlations and bias reduction (policy/software; industry/academia)
- Use orthogonalization and factorization to prevent leakage between demographic attributes and task-relevant concepts.
- Outcomes: fairer systems; reduced reliance on co-occurrence statistics.
- Dependencies: careful concept selection; fairness audits; domain expertise.
- Explainability via factorized concept subspaces (software; academia/industry)
- Provide user-facing explanations that attribute predictions to specific concept components and their directions.
- Outcomes: better trust in AI systems; actionable debugging signals.
- Dependencies: stable factorization; interface design; user education.
- Scientific methodology for compositional learning (academia)
- Standardize experimental designs (validity classes, stability checks) and benchmarks for compositional generalization.
- Outcomes: comparable results; clearer progress tracking across labs.
- Dependencies: community buy-in; shared datasets and tooling.
- Domain-specific concept libraries and feature stores (software; industry)
- Maintain vetted sets of concept prompts/directions for sectors (e.g., radiology findings, retail attributes).
- Outcomes: reusable building blocks for rapid deployment; consistent performance across teams.
- Dependencies: ongoing curation; governance; versioning and provenance.
Key Assumptions and Dependencies Affecting Feasibility
- Linear readouts and gradient-descent training with cross-entropy; proofs most direct in binary grids.
- Non-contextual encoders (embedding depends only on the input); practical systems may include context/prompting.
- Availability and correctness of concept schemas and labels; label noise can degrade factorization.
- Stability (posterior invariance across valid retrainings) is an idealization; approximate stability may suffice.
- Near-orthogonality is measured, not guaranteed; regularizers help but may trade off accuracy.
- Text prompts must consistently map to concept values; prompt quality and text encoder alignment matter.
- Dataset validity rules (e.g., minimal supports) require collectability; synthetic augmentation may be needed.
- Dimension bounds inform capacity but do not capture all practical constraints (compute, latency, domain shifts).
Glossary
- Affine readout: An affine (linear plus bias) mapping from embeddings to logits used for classification. "It is linearly compositional if can be taken affine $h(z)=\bW z+b$."
- Argmax classification rule: The decision rule that selects the class with the highest logit for each concept. "using argmax classification rule"
- Binary cross-entropy (BCE): The logistic loss used for binary classification tasks. "binary cross-entropy (logistic) loss."
- Binary grid: A concept space where each concept takes values in {0,1}. "under the binary grid "
- Cartesian product: The operation combining concept-value sets into all possible tuples. "The concept space is the Cartesian product"
- Combinatorial space: The exponentially large set of all possible input or concept combinations. "combinatorial space of possible inputs"
- Compositional generalization: The ability to recombine learned parts to handle novel concept combinations. "Compositional generalization, the ability to recognize familiar parts in novel contexts, is a defining property of intelligent systems."
- Compositional Risk Minimization (CRM): A framework that targets extrapolation to the full concept grid from minimal samples. "as in Compositional Risk Minimization framework"
- Contrastive objective: A learning objective that pulls matched pairs together and pushes mismatched pairs apart. "gradient descent on a cross-entropy or contrastive objective"
- Cosine similarities: Similarities computed as dot products between -normalized vectors. "so that inner products are cosine similarities"
- Cross-concept orthogonality: A geometric constraint requiring difference directions for different concepts to be orthogonal. "with cross-concept orthogonality"
- Cross-entropy loss: The multi-class classification loss used to train readouts. "Under gradient descent with the cross-entropy loss"
- Divisibility: A desideratum requiring the readout to have capacity to represent every concept combination. "Divisibility is necessary but not sufficient"
- GD+CE: Shorthand for gradient descent optimization with cross-entropy loss. "given by GD+CE."
- Hypothesis class: The set of allowable readout functions considered by the learning algorithm. "the readout hypothesis class is linear"
- LAION-400M: A web-scale image–text dataset used to train vision–LLMs. "LAION-400M"
- Linear factorization: A representation that decomposes additively into per-concept components. "linear factorization with near-orthogonal concept directions"
- Linear Representation Hypothesis: The hypothesis that neural representations exhibit approximately linear structure. "the Linear Representation Hypothesis"
- Linear subspaces (in VLMs): Low-dimensional linear structures within vision–LLM embeddings. "linear subspaces in VLMs"
- Linear probing: Training a linear classifier on fixed embeddings to read out target concepts. "linear probing"
- Logits: Pre-softmax scores output by a model for each class. "a model's logits are exactly equal to for the matches"
- Max-margin SVM: A support vector machine solution that maximizes the classification margin. "GD+CE converges to a max-margin SVM"
- Minkowski-sum hypothesis: The proposal that token-space representations combine via Minkowski sums. "propose a Minkowski-sum hypothesis for token space"
- Near-orthogonal (per-concept) factors: Per-concept directions that are approximately orthogonal to each other. "near-orthogonal per-concept factors"
- Posterior (per-concept posterior): The softmax-derived probability distribution over a concept’s values. "the per-concept posteriors agree across supports"
- Power set: The set of all subsets of a given set. "the power set of "
- Readout: The downstream mapping from embeddings to per-concept logits used for prediction. "We refer to as the readout."
- Stability: A desideratum requiring predictions (posteriors) to be invariant across valid training supports. "We refer to this as Stability."
- Support vector: A training point that lies on the margin and determines the SVM decision boundary. "makes each point a support vector"
- Training support: The subset of concept tuples observed during training. "A training support is any subset ."
- Validity class: The collection of training supports deemed valid under data-collection constraints. "Validity class is a collection "
- Validity rule: A criterion that determines whether a given training support is valid. "Validity class is specified by a validity rule"
- Vision-LLMs (VLMs): Models that align visual and textual representations in a shared space. "large vision-LLMs such as CLIP"
- Zero-shot classifiers: Classifiers that use text-derived weights to recognize concepts without task-specific training data. "CLIP-style zero-shot classifiers"
- Zero-shot transfer: The ability to generalize to tasks or combinations never seen during training. "achieve impressive zero-shot transfer on many tasks"
Collections
Sign up for free to add this paper to one or more collections.